이 논문의 주요 키워드
- Representation Learning
- Self-supervised Learning
이 논문을 깊게 이해하려면 다음 지식이 필요합니다.
- Self-supervised representation learning에 대한 이해
- SimCLR (주영님 리뷰)
- Barlow Twins (유진님 리뷰)
- Contrastive Self-Supervised Learning: A Survey on Different Architectures (재연님 리뷰)
안녕하세요. 백지오입니다.
스물 여덟 번째 X-REVIEW는 뉴욕대학교의 정수연 교수님 연구팀이 발표한 Self-Supervised Representation Learning 방법인 Maximum Manifold Capacity Representation (MMCR)에 대한 논문입니다. 정수연 교수님 연구팀은 코어 ML을 연구하는 연구진 중에서도 뇌과학과 신경망 매니폴드 기반의 접근에 일가견이 있는 연구진인데요. 본 논문에서 제안한 MMCR은 우리가 흔히 아는 SimCLR, SimSiam 등 기존의 SSL 방법들과 완전히 다른 접근 방식으로 강력한 성능을 보여주어, 많은 관심을 받았습니다. 특히 얀 르쿤 교수님 연구진도 NIPS 2023과 함께 진행된 UniReps 워크샵에서 이 방법론에 대한 분석을 진행할 정도라, 과연 어떤 연구일까 궁금하여 논문을 읽어보았습니다.
기하학, 뇌과학, 열역학 등 온갖 처음보는 개념들과 영문학적으로 굉장히 멋있으면서 어려운 표현들이 많이 등장해서 쉽지 않은 논문이었으나, 최대한 잘 풀어내려고 노력하였으니 즐겁게 봐주셨으면 좋겠습니다. 컴퓨터공학도에게 낯선 개념들의 경우 참고 링크와 설명을 많이 달아두었으니, 중간중간 참고하시면서 보시면 좋습니다. 그럼, 리뷰 시작하겠습니다.
효율적인 코딩 가설(Efficient coding hypothesis)은 생물의 감각계가 입력된 감각 신호들의 통계적 특성을 반영하여 환경 신호와 그들의 representation들 사이의 mutual information을 최대화한다고 가정합니다. 쉽게 말해 우리의 뇌가 어떤 감각 신호(시각이나 청각 등)를 입력받으면, 이를 처리하기 위해 어떤 부호로 만드는 과정을 거치는데, 이때 부호화를 효율적으로 수행하기 위해 어떤 규칙을 형성한다는 것입니다. 이러한 관점은 컴퓨터공학을 포함한 다양한 분야에서 흔히 다뤄지는 정보 이론에 기반하는데, 저자들은 정보 이론이 우아하고 멋진 이론이지만 측정(measure)하거나 최적화(optimize) 하기 어렵기로 악명 높기 때문에, 정보 이론 기반의 많은 연구들이 근사(approximation)나 제한(bound), 치환(substitutes) (e.g., reconstruction error) 등에 의존한다는 점을 지적합니다.
한편, 최근에 개발된 coding efficiency 척도(measure)인 manifold capacity는 선형 분리 가능하게 표현될 수 있는 객체 범주(object category)의 수를 측정하는데, 이를 계산하기 위해서는 많은 반복 연산으로 대량의 컴퓨팅이 요구되어 objective로 사용하기에는 제약이 있었다고 합니다. 저자들은 이러한 manifold capacity의 계산 방법을 단순화하여 direct optimization 형태로 만들고, 이를 통해 Maximum Manifold Capacity Representations (MMCRs)를 학습하는데 활용하여 기존 Self-Supervised Learning (SSL) 방법들과 견줄만한 성능을 보였으며, neural predictivity 벤치마크를 통해 이 방법이 영장류의 ventral stream과도 견줄만한 성능임을 보였다고 합니다.
Manifold: 국소적으로 유클리드 공간을 닮은 공간을 의미합니다. 곡선(1차원) 혹은 곡면(2차원)을 고차원에서 일반화한 개념으로 볼 수도 있습니다.
Ventral stream: 뇌가 시각 정보를 두 가지 경로로 처리한다는 two-streams hypothesis에서 등장하는 개념으로, 시각 정보를 처리하는 두 경로 중 물체의 식별과 인식(what)을 담당하는 경로를 의미합니다.
Introduction
생물학적인 시각계는 대규모의 라벨링된 예시 없이도 세상의 복잡한 정보들을 폭넓게 인지하는 능력을 학습합니다. 효율적인 코딩 가설은 이러한 능력이 감각 표현(sensory representation)을 입력 신호의 통계적 특성에 맞게 조정하여 반복성(redundancy)이나 차원(dimensionality)을 감소시켜 가능하다는 이론입니다. (반복성과 차원을 감소시킨다는 것은 결국 정보 이론에서 정보를 압축하는 것과 동일한 의미입니다.) 우리의 눈에서 얻어지는 시각 신호들은 명백하게 반복적인 성질을 가지고 있습니다. 시각 신호는 시간이 흐름에 따라 천천히 변화하는데, 인접한 시점에 입력된 시각적 신호는 대게 같은 장면의 다른 관점(view)에 대응되며, 다른 장면에서의 view보다 유사한 특징을 갖습니다. 이렇게 같은 장면에 대한 변종들은 대부분 시점이나 광원 등 적은 수의 파라미터 변화로 나타나며, 그렇기에 본질적으로 저차원적인 특징을 갖습니다.
많은 기존 연구들이 신경 회로(neural circuits)들이 어떻게 자연환경 상의 구조들을 잘 처리할 수 있는지 보였는데, 다양한 모달리티에서의 연구들이 behavioral task들과 연관된 neural data의 기하학적 구조를 식별하고, 이 구조들을 평가하기 위한 지표를 탐색했습니다. 최근 연구된 “manifold capacity theory”는 이러한 neural representation과 그들의 coding capacity 사이의 더욱 명백한 연관성을 보여주는 이론으로, 각 모달리티에서 생물학적 혹은 인공적 신경망의 효율성을 측정하는 데 사용됩니다. 그러나 이를 모델 representation을 구축하기 위한 디자인에 활용한 연구는 아직 진행되지 않았었다고 합니다.
저자들은 이러한 관측들을 근거로, 같은 장면을 나타내는 다른 관점(view)들을 포함한 매니폴드는 작고 저차원이게 유지하면서, 다른 장면을 나타내는 매니폴드와의 분리는 최대화되는 표현 방식을 학습하고자 하였습니다. 저자들의 연구 내용은 아래와 같습니다.
- 학습의 목적 함수로 사용가능한 형태의 Manifold Capacity를 설계하였습니다.
- 저자들의 Maximum Manifold Capacity Representation (MMCR)은 고수준의 object recognition이 가능합니다. (linear evaluation 시 SSL SOTA와 동등)
- 내부 표현과 학습 신호 분석을 통해 unsupervised 목적함수에서 semantically relevant feature의 등장에 어떤 메커니즘이 작용하는지 분석하였습니다.
- 학습된 표현을 원숭이의 시각 피질에서 얻어진 neural data와 비교하여 MMCR의 효과를 분석하였습니다.
저자들은 이를 통해 영장류의 ventral stream과 동등한 수준의 효율성과 정확성을 갖는 representational efficient한 모델을 만들고자 하였습니다.
Related Work
Geometry of Neural Representations. 지난 연구들에서는 participation ratio(공분산 행렬의 고윳값의 $l_1, l_2$ norm의 squared ratio) 등의 스펙트럼 양(spectral quantities) 등으로 측정되는 표현 기하학(representation geometry)이 다운스트림 테스크에서의 성능에 어떤 영향을 주는지 파악하고자 노력하였는데, Elmoznino and Bonner는 ANN representation의 고차원성이 neural data의 예측과 unseen category에 대한 일반화에 영향을 준다는 것을 발견하였습니다. Stringer et al.은 쥐의 신경망 속 자연 이미지에 대한 representation spectrum이 decay coefficient가 1에 가까운 멱법칙(power law)을 따름을 발견했는데, Agrawal et al. 은 artificial representation에서 spectral decay coefficient가 얼마나 1에 가까운지가 (artificial) representation의 다운스트림 테스크에서의 일반화 성능이 얼마나 좋을지 예측하는데 효과적임을 관측하였습니다. Agrawal의 연구가 인공 신경망에 관한 것이니 확언은 불가능하지만, 쥐의 신경망이 downstream task에 매우 효과적인 neural representation을 가지고 있다는 것처럼 보이네요.
Self-Supervised Learning. 저자들이 제안하는 방법론은 contrastive self-supervised representation learning (SSL)에서 많은 영감을 받았으나, 기존의 방법론들과는 확연히 다른 접근과 공식을 취합니다. CPC, SimCLR, CMC, AMDIM 등 많은 최신 SSL 프레임워크들은 같은 물체의 다른 관점(views)에 대한 representation 사이의 mutual information을 최대화하는 방식, 즉 Contrastive Learning을 활용하고 있습니다. 그러나 고차원 feature space에서 mutual information을 추정하는 것은 어려운 일이며 (MINE) mutual information을 잘 근사하는 것이 곧 representation을 개선하는지도 명확하지 않은 상황이라고 합니다.(Wang et al.) 한편, 스핀 유리 이론에 기반한 capacity measure는 “large N (열역학) limit”에 기반하여 설계되었기 때문에, 대규모의 환경 공간(large ambient dimension)에서도 잘 작동하리라 여겨지는데요. 저자들은 지금까지는 representation의 품질을 측정하기 위해 사용되었던 capacity가 SSL의 목적함수로써도 적합한지 확인해보고자 합니다.
스핀 유리 이론(Spin Glass Theory): 비자성 물질에 장성 불순물이 혼합된 저밀도 무질서 자석인 스핀 유리는 기존의 통계물리학적 방법으로 물리량을 엄밀하게 계산할 수 없는데, 이탈리아 물리학자 Parisi가 제안한 스핀 유리의 물리량을 계산할 수 있는 계산 방법을 의미합니다. 추후 이 방법이 스핀 유리의 물리량 계산뿐 아니라, 인공신경망을 비롯한 복잡계의 물리학적 해석에 유용하게 사용될 수 있음이 판명되어, 다양한 분야에서 널리 응용되고 있다고 합니다. (참고: 서강대 김도현 교수님, 명지대 권철안 교수님) 이 논문에서는 제안하는 capacity measure 방법이 이러한 이론적 토대를 가지기 때문에 신경망에서도 잘 동작할 수 있다는 근거 정도로 이해하면 될 것 같습니다.
Maximizing Mutual Information: Contrastive Learning의 목표는 다른 관점(서로 다른 augmentation 등)의 이미지라도 같은 물체(i.e., positive pair)를 나타낸 이미지라면 유사한 representation을 갖도록 하는 것 입니다. 이는 representation에 있어 두 이미지의 세부적인 정보(augmentation으로 변형된 픽셀 정보 등)가 아니라, 두 이미지가 가진 공통적인 정보 즉, mutual information의 영향을 최대화하는 것을 의미합니다. 그러나 이러한 방식으로 mutual information을 최대화하는 것이 다운스트림 task의 성능, 나아가 representation의 효율을 개선하는 것과 동치인지는 명확하지 않은 상황입니다.
많은 SSL 방법론들이 같은 이미지에서 얻어진 다른 augmented view들의 representation을 최소화함과 동시에 trivial solution (e.g., repulsion of negative pairs (SimCLR), or feature space whitening(Barlow Twins, VICReg, Ermolov et al.))으로의 붕괴를 막는 방식으로 학습을 진행하였습니다. 하나의 pairwise distance comparison을 사용하는 것의 한계는 SwAV의 “multi-crop” 전략과 CMC의 contrastive multiview coding 접근 방식에서 드러나는데, 저자들의 접근 방식은 이미지의 다른 관점(view)이 우리가 압축하고자 하는 continuous manifold를 형성할 것이라는 추론에 기반합니다. 저자들은 각 이미지 view의 셋을 spectrum of singular values of their representation으로 특정하고, nuclear norm을 manifold size와 dimensionality의 combined measure로 사용합니다.
nuclear norm: 특이값이 $\sigma$인 어떤 $n\times m$ 행렬 $A$에 대하여, nuclear norm은 다음과 같이 정의됩니다.
$$||A||_* = \sum_{i=1}^{\min(m,n)}\sigma_i$$
Nuclear norm은 representation of data 속 low rank structure를 추론하거나 유도하는 데 사용된 바 있으며(Hénaff et al., LORAC, OLÉ), 특히, LORAC에서는 InfoNCE loss의 regularizer로 nuclear norm을 사용하였습니다. 저자들의 접근 방식은 기존 InfoNCE loss보다 더욱 급진적인 접근이라 볼 수 있는데, Logistic regression 기반 우도를 이용한 low-rank prior 간의 pair 대신, high rank 우도를 위한 더욱 symmetric 한 방법을 취한 것입니다. 이를 통해 목적 함수가 명시적으로 SSL의 well-known issue인 dimensional collapse를 방지할 수 있다고 합니다.
Maximum manifold capacity representations
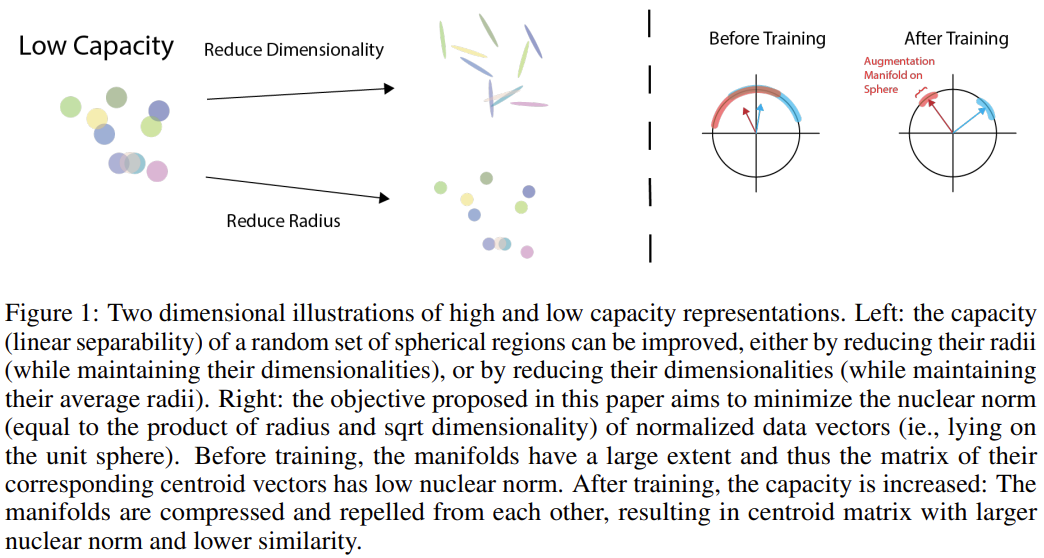
그림 1은 low capacity, high capacity representation을 각각 2차원에 나타낸 예시입니다. 좌측의 그림부터 살펴보면, 어떤 클래스에 속한 이미지들이 그림과 같이 매니폴드를 형성할 때, 이 매니폴드들의 capacity(linear separability)를 늘리는 방법은 두 가지입니다. 매니폴드의 차원을 줄이거나, 반경을 줄이는 방식입니다. 우측 그림은 논문의 목표인 normalized data vector의 nuclear norm을 최소화하는 것을 나타낸 것입니다. 이때, nuclear norm은 매니폴드의 반경과 차원의 제곱근을 곱한 것과 같습니다. 학습 이전에는 매니폴드들이 넓은 범위를 가지므로, 대응되는 centroid vector들의 행렬이 작은 nuclear norm을 갖는 반면, 학습 후에는 capacity가 증가하고 매니폴드가 압축됨에 따라 centroid matrix가 큰 nuclear norm과 낮은 유사도를 갖게 됩니다. (centroid vector들의 행렬의 nuclear norm은 최대화, normalized data vector의 nuclear norm은 최소화하는 것입니다.)
Manifold Capacity Theory
$D$차원의 feature space에 임베딩된 각 클래스 라벨에 해당하는 $P$개의 매니폴드들이 있다고 할 때, manifold capacity theory는 해당 매니폴드들에 대하여 임의의 이진 분류를 수행할 수 있는 분리 초평면이 (높은 확률로) 존재하는 $\frac{P}{D}$의 최댓값을 찾고자 합니다. 이때, 최근 연구에 따르면, manifold capacity $\alpha_C$에 대하여, $\frac{P}{D}<\alpha_C$일 경우 분리 초평면이 존재할 확률이 1에 수렴하며, $\frac{P}{D}>\alpha_C$일 경우 그 확률이 0에 수렴한다고 합니다. 결국 manifold capacity $\alpha_C$가 높을수록 더 적은 차원으로 더 많은 클래스를 잘 임베딩할 수 있다는 뜻이죠.
Manifold capacity $\alpha_C$는 세 가지 값을 이용해 정확하게 예측할 수 있는데, (1) 매니폴드의 중심과 원점의 거리인 반경 $R_M$, (2) 매니폴드가 특징적으로 범위를 갖는(extent) 차원(dimensionality) $D_M$, (3) 매니폴드 중심들의 상관(correlation)입니다. 매니폴드 중심들의 상관이 적을 때는 manifold capacity를 $\phi(R_M\sqrt D_M)$과 같이 근사할 수 있습니다. ($\phi$는 단조 감소 함수)
어떤 매니폴드들의 반경과 차원은 각 매니폴드 상에서 임의의 “앵커 포인트”들을 정의하고, 이들을 랜덤 하게 투영한 결과의 통계를 구하는 과정을 반복하여 구할 수 있습니다.(관련 논문) 이러한 과정은 많은 연산을 필요로 하며, 미분도 불가능하기 때문에 목적 함수로는 적합하지 않습니다. (이에 관련한 더 자세한 설명은 논문의 Appendix C. 에 있습니다.)
한편, 만약 매니폴드를 타원의 형태라고 가정할 경우, 매니폴드들의 반경과 차원은 모두 아래와 같이 분석적으로 계산할 수 있게 됩니다.
$$ R_M = \sqrt{\sum_i \lambda_i^2}, D_M = \frac{(\sum_i\lambda_i)^2}{\sum_i\lambda_i^2}$$
$\lambda_i^2$는 매니폴드의 공분산 행렬의 고윳값입니다. 이러한 분석적 방법은 매니폴드들의 반경과 차원을 100개의 128차원 매니폴드에서 100개의 포인트를 샘플 하여 계산할 경우, 기존의 반복적 방법 대비 약 500배 빠른 속도를 갖습니다.
이러한 정의를 활용하여 매니폴드들의 반경과 차원을 구할 경우, manifold capacity를 $\alpha_C=\phi(\sum_i\sigma_i)$ 꼴로 간단히 나타낼 수 있습니다. ($\sigma_i$는 매니폴드 상의 포인트들의 행렬의 고윳값이자 공분산 행렬의 고윳값들의 제곱근) 이러한 형태에서, $\sum_i\sigma_i$는 고윳값들의 $L_1$ norm이 되고 이는 행렬의 Nuclear Norm을 의미합니다. 빌드업 미쳤네요.
이렇게 구해진 manifold capacity를 목적 함수로 활용하게 되면, 그 결과는 낮은 차원에 상응하는 sparse solution (대부분의 값이 0으로 이루어진)을 선호하게 됩니다.
제안된 방법을 공분산 행렬의 행렬식(역시 행렬의 크기를 측정하는 값입니다.)을 목적 함수로 사용하는 것과 비교해 보면, 행렬식 역시 고윳값들의 크기와 비례하기는 하지만, Nuclear Norm에서 얻을 수 있는 차원의 감소 효과가 부족하다고 합니다. 특히, 행렬식은 고윳값 중 하나라도 0이 포함되면 0이 되기 때문에, 어떤 차원에서 zero-volume인 매니폴드를 다루지 못합니다. 한편, Lossy coding rate (entropy)도 가우시안 모델 상의 공분산 행렬의 log 행렬식의 단순화를 통해 compactness를 측정할 수 있는데, 이 경우 행렬식을 구하기 전에 공분산 행렬에 단위행렬을 더하여 차원 문제를 해결할 수 있습니다.
Optimizing Manifold Capacity
앞서서 manifold capacity를 목적 함수로 사용하기 위해 매니폴드를 타원형으로 가정하고 계산식을 정의하였는데요. 이제 본격적으로 SSL을 위한 목적 함수를 정의할 차례입니다. 각 입력 이미지 $\mathbf x_b\in \mathbb R^\mathbb D$에 대하여 대응되는 매니폴드에 몇 가지의 랜덤 augmentation을 적용하여 $k$개의 샘플을 생성하여 매니폴드 샘플 행렬 $\tilde{\mathbf X}_b \in \mathbb R^{D\times k}$를 만들어줍니다. 각 증강된 이미지들은 파라미터 $\theta$로 정의되는 비선형 함수 $f(\mathbf x_b;\theta)$인 DNN에 의하여 $d$차원의 unit sphere로 투영되어 매니폴드 출력(response) 행렬 $\mathbf Z_b\in \mathbb R^{d\times k}$를 형성합니다. 이어서 출력 행렬의 column 평균을 통해 centroid $\mathbf c_b$를 근사합니다. 결과적으로 이미지 집합 $\{ \mathbf x_1, \cdots , \mathbf x_B \}$로부터 정규화된 출력 행렬 집합 $\{ \mathbf Z_1, \cdots, \mathbf Z_B \}$를 얻고, 이들의 centroid들의 행렬 $\mathbf C\in \mathbb R^{d\times B}$를 얻었습니다.
MMCR loss는 centroid들을 이용하여 아래와 같이 정의됩니다.
$$ \mathcal L = -||\mathbf C||_*$$
$|| \cdot ||_*$은 nuclear norm을 의미합니다. 이 loss는 명시적으로 centroid 매니폴드의 범위(extent)를 최대화합니다. 즉, 각 매니폴드의 centroid들 사이의 거리를 최대화하는 것입니다. 저자들은 놀랍게도 이것만으로도 유용한 representation을 학습하는데 충분하다고 합니다. $||\mathbf C||_*$를 최대화하는 것은 암묵적으로 $||\mathbf Z_b||_*$로 구해지는 각 매니폴드의 범위를 최소화하는 효과가 있습니다. 아래에서 자세한 설명이 이어집니다.
Compression by Maximizing Centroid Nuclear Norm Alone. 각 centroid 벡터는 대응되는 매니폴드에 속한 단위 벡터의 평균으로 구해지기 때문에, centroid 벡터의 norm은 아래와 같이 해당 단위 벡터들의 평균 코사인 유사도와 선형 연관성을 가지게 됩니다.
$$ ||\mathbf c_b||^2 = \frac{1}{K} + \frac{2}{K^2}\sum^K_{k=1}\sum^{k-1}_{l=1} \mathbf z^\top_{b,k} \mathbf z_{b,l}$$
$\mathbf z_{b, i}$는 이미지 $x_b$의 $i$번째 augmentation을 의미합니다.
이어서 각 열 벡터의 pairwise similarity와 singular vector들의 분포가 어떤 연관이 있는가에 대한 분석을 진행할 수 있는데, 임의의 행렬의 고윳값에 대한 closed form solution은 존재하지 않기 때문에, 아래와 같이 두 개의 열 벡터로 구성된 행렬로 예시를 들어보면 유용한 직관을 얻을 수 있다고 합니다. $\mathbf C=[\mathbf c_1, \mathbf c_2], \mathbf Z_1 = [\mathbf z_{1, 1}, \mathbf z_{1, 2}], \mathbf Z_2 = [\mathbf z_{2, 1}, \mathbf z_{2, 2}]$라 할 때, $\mathbf C, \mathbf Z_i$의 고윳값은 아래와 같습니다.
$$ \sigma(\mathbf C)=\sqrt{\frac{|| \mathbf c_1||^2 + || \mathbf c_2||^2 \pm ((|| \mathbf c_1||^2 – || \mathbf c_2||^2)^2 + 4( \mathbf c_1^\top \mathbf c_2)^2)^{1/2}}{2}}$$
$$ \sigma(\mathbf Z_i) = \sqrt{1\pm \mathbf z^\top_{i, 1} \mathbf z_{i, 2}}$$
따라서, $||\sigma(\mathbf C)||_1 = || \mathbf C||_*$은 centroid 벡터들의 norm이 최대화(단위 벡터들의 centroid이므로 최대 1)되고 서로 직교할 때 최대화되게 됩니다. 앞서 centroid norm이 매니폴드 내부 similarity와 선형 관계를 갖는 것을 확인했는데, 이와 유사하게 $||\sigma( \mathbf Z_i)||_1= || \mathbf Z_i||_*$ 역시도 매니폴드 내부 similarity가 최대화될 때 최소화됩니다. 따라서 $|| \mathbf C||_*$ 하나의 값만 목적 함수로 활용하더라도 contrastive learning에 요구되는 모든 핵심 요소인 centroid 매니폴드 범위의 최대화와 각 매니폴드 범위의 최소화를 동시에 수행할 수 있는 것입니다.
저자들은 이어서 $|| \mathbf C||_*$를 최대화하는 것을 통해 유용한 representation이 학습됨을 시연하는데, 이때 contrastive learning을 위해 positive pair가 필요하게 됩니다. 만약 positive pair가 없다면 centroid를 활용할 수 없게 되고, 모델이 유용한 representation을 학습하지 못한다고 합니다. 또한 저자들은 Appendix F에서 $|| \mathbf Z_b||_*$를 명시적으로 최소화하도록 목적 함수를 수정한 것과 비교를 통해, $|| \mathbf C||_*$만 최소화하는 것이 정말 manifold capacity를 결정하는 세 가지 요소인 반경, 차원, centroid correlations를 모두 조정함을 보였다고 하니, 궁금하신 분들은 읽어보면 좋을 것 같습니다.
Computational Complexity. 제안된 loss 함수를 구하기 위해서는 $ \mathbf C\in \mathbb R^{d\times B}$에 특잇값 분해를 수행해줘야 합니다. 이때 batch size $B$, 출력 차원 $d$에 대하여 $\mathcal O(Bd\times \min(B, d))$의 복잡도가 요구되는데, 일반적인 contrastive learning 방법들이 배치 내부의 pairwise distance를 계산하기 위해 $\mathcal O(B^2d)$의 복잡도를 요구하며, 공분산 구조를 규제하는 non-contrastive 방법들은 $\mathcal O(Bd^2)$의 계산복잡도를 갖기 때문에, 기존 방법들의 중간 정도의 복잡도를 갖는다고 볼 수 있습니다. 이때, 제안된 방법은 사용된 view(augmentation)의 수에 선형적인 연산량이 요구되는 반면, 기존 방법들은 view 개수에 대해 quadratic 한 연산이 요구되어 본 방법이 더 적은 연산을 요구합니다. 또한, 계산에 $\mathcal O(B^2d\times \min(B, d))$의 연산이 요구되는 $\sum^B_{b=1} || \mathbf Z_b||_*$를 계산할 필요 없이 $|| \mathbf C||_*$만 연산하여 효율적이라고 하네요.
Conditions for Optimal Embeddings
최근, HaoChen et al. 은 SSL의 다운스트림 task에서의 linear probing 성능을 이론적으로 보장해 주는 spectral decomposition 기반의 프레임워크인 “population augmentation graph”를 제안하였습니다. Balestriero와 LeCun은 이 방법을 발전시켜 다양한 SSL objective에 적용하였고, 저자들은 MMCR에도 이를 적용해보고자 합니다.
데이터셋 $ \mathbf{X’}=[ \mathbf x_1, \cdots, \mathbf x_n]^\top \in \mathbb R^{N\times D’}$가 주어질 때, 저자들은 $k$개의 랜덤 하게 augmentation 된 view를 통해 $ \mathbf X = [\text{view}_1( \mathbf X’), \cdots, \text{view}_k( \mathbf X’)] \in \mathbb R^{Nk\times D}$를 생성하였습니다. 이러한 방식을 통해, 동일한 데이터포인트에 대한 서로 다른 view들이 의미론적으로 유사하다는 지식을 활용할 수 있게 됩니다. 이러한 유사성을 symmetric matrix $\mathbf G\in \{0, 1\}^{Nk\times Nk}$에서 데이터 $i$와 $j$과 의미론적으로 유사할 경우, $G_{ij}=1$로 나타내는 방식으로 표현할 수 있는데요. 이 행렬의 행과 열의 합이 1이 되도록 정규화 과정을 거쳐줍니다. (따라서 $\mathbf G$의 한 행은 $k$개의 $1/k$의 값으로 채워진 sparse 벡터가 됩니다.)
이제 $\mathbf Z\in \mathbb R^{Nk\times d}$를 augmented dataset의 임베딩이라고 할 때, $ \mathbf{GZ} = [ \mathbf C, \cdots, \mathbf C]^\top$을 얻을 수 있습니다. ($ \mathbf C$는 앞서 소개된 centroid matrix) $ \mathbf{GZ}$는 $ \mathbf C$가 $k$번 반복된 형태인데, $\sigma([ \mathbf C, \cdots, \mathbf C]) = \sqrt k \sigma ( \mathbf C)$이므로 MMCR의 손실 함수는 아래와 같습니다.
$$\mathcal L = – ||GZ||_*$$
이를 통해 아래와 같은 정리가 가능해지며, 증명은 논문의 Appendix A에 되어 있습니다.
Theorem: 제안된 loss를 통해, optimal embedding의 left singular vector $\mathbb Z^*$는 $ \mathbf G$의 고유벡터가 되며, $\mathbf Z^*$의 고윳값은 $ \mathbf G$의 top $d$ 고윳값에 비례한다.
Results
Architecture. 저자들이 수행한 모든 실험은 ResNet-50을 백본으로 사용하였습니다. (이때, CIFAR에서 학습된 모델들의 경우 max pooling layer를 제거했습니다.) SimCLR를 따라, 저자들은 ResNet의 average pooling 계층 이후에 작은 퍼셉트론을 붙여 $z_i = g(h(x_i))$와 같이 임베딩을 수행했습니다. ($h$는 ResNet, $g$는 MLP) ImageNet-1k/100에 대해 각각 차원이 $[8192, 8192, 512]$, $[512, 128]$인 MLP를 사용하였습니다.
Optimization. 저자들은 BYOL에서 제안된 augmentation들을 사용하였습니다. ImageNet에서는 LARS optimizer에 learning rate 4.8, 첫 10 에포크에 대해 linear warmup을 적용하고, 이후로는 cosine decay를 적용했습니다. batch size는 2048, 사전학습은 100 에포크 진행했습니다. 저자들이 보고한 성능들은 기본적으로 batch size 2048을 기준으로 하지만, 256의 batch size에서도 충분히 합리적인 성능을 얻을 수 있다고 합니다. 추가로 ImageNet 사전학습에 momentum encoder를 적용하였고, 모든 view는 online network로 입력되었다고 합니다. 추가 network는 online network를 따라 파라미터가 slowly moving average로 업데이트됩니다. momentum encoder를 통해, 다운스트림 classification 성능이 소폭 향상되었으며, CIFAR-10에서는 더 작은 batch size와 더 많은 view (40개), Adam optimizer에 고정 learning rate로 학습을 진행했습니다. 더 자세한 학습 디테일은 Appendix D에 있다고 합니다.
Transfer to Downstream Tasks
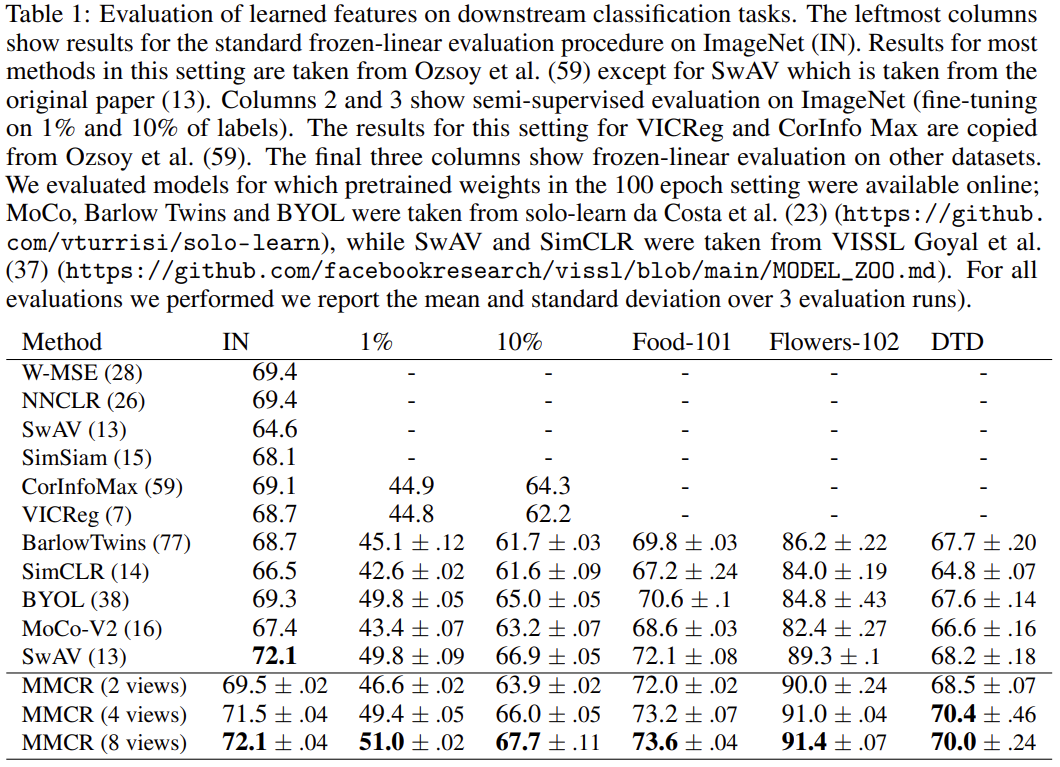
저자들은 사전학습된 모델을 freeze 하고 끝에 선형 분류기를 추가하여 지도학습을 진행하는 일반적인 linear probing 방식과, 모델 전체를 소량의 데이터로 fine tuning 하는 준지도학습 방식으로 평가를 진행했습니다. 또한, Flowers-102와 Food-101, Describable Textures Dataset을 통해 out-of-distribution에 대한 일반화 성능도 확인했습니다. 표 1을 보면, 제안한 MMCR이 기존의 SSL 방법들과 같거나 더 높은 성능을 보여줌을 확인할 수 있습니다. 이게 놀라운 것이, 기존 방법들은 기존에 연구된 접근 방향을 토대로 발전해 나가서 달성한 성능을 Manifold Capacity Maximization이라는 완전히 새로운 방식으로 한 번에 뛰어넘었기 때문입니다. 이 방법도 기존 방법들만큼 추가 연구가 진행된다면 어디까지 발전할 수 있을지 기대되는 부분입니다.
이어서 저자들은 MMCR을 Pascal VOC 2007 데이터셋에서의 Object Detection task에 적용해 보았는데요, Faster R-CNN head와 C-4 백본을 활용하여 mAP 54.6을 달성하여 베이스라인 53.1~56.0 수준의 성능을 보임으로써 이 방법이 Classification에서만 활용가능하지 않음을 보였습니다.
Analyses of Learned Representation
저자들은 학습된 representation이 다른 SSL 방법으로 학습된 representation과 어떻게 다른지 분석하기 위한 실험을 진행하였습니다. 효율적인 실험을 위해 이 실험은 CIFAR-10 데이터셋으로 수행했다고 합니다.
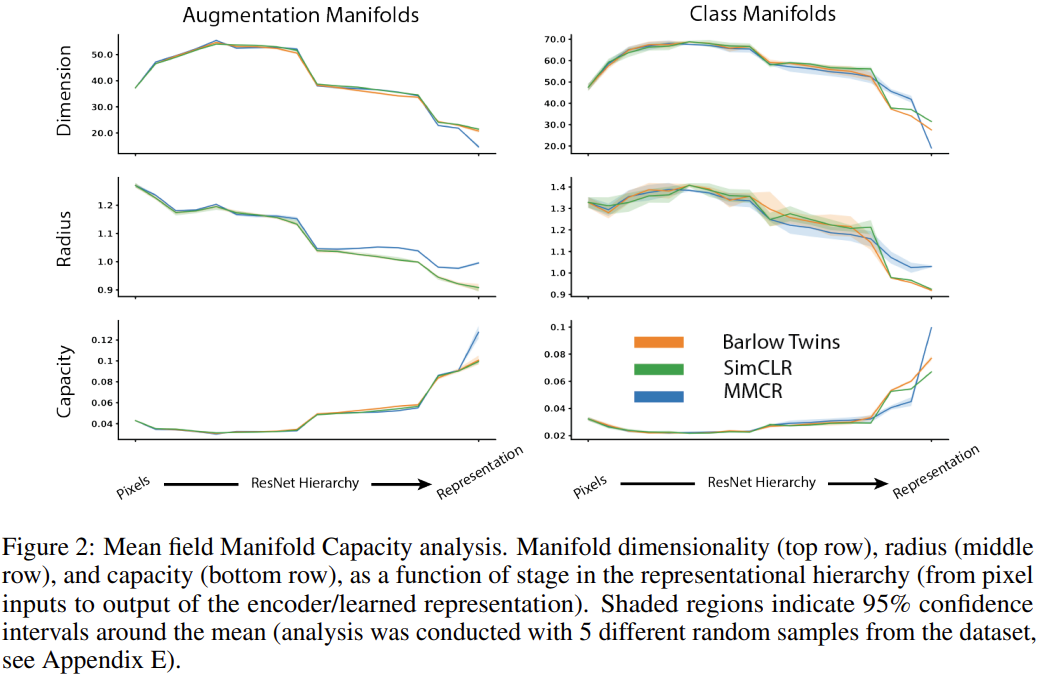
Mean Field Theory Manifold Capacity. 그림 2를 보면, 타원형 매니폴드를 가정하는 MMCR이 기존 방법들에 비해 확연히 높은 capacity를 갖는 것을 확인할 수 있습니다. 저자들은 같은 클래스에 속한 데이터포인트들로 구성되는 클래스 매니폴드에 대한 분석도 수행하였는데, 이를 통해 MMCR이 augmentation manifold capacity를 최대화하고 class manifold는 압축 및 분리하여 유용한 representation을 학습함을 볼 수 있었습니다. 흥미롭게도 MMCR은 capacity를 증가시키기 위해 베이스라인 방법과는 다르게, class와 augmentation 매니폴드의 반경을 크게 만들고 차원은 감소시키는 전략을 취했습니다. 매니폴드의 반경은 줄이는 게 좋다고 생각했는데 오히려 키운다는 게 의외네요. (저자들도 이러한 일이 발생하는 이유는 찾지 못했다고 합니다.) 이러한 특징들은 ResNet의 뒤쪽 레이어에서 등장하고, 앞쪽에서는 다른 방법들과 별 차이가 없는 것도 주목할 점입니다.
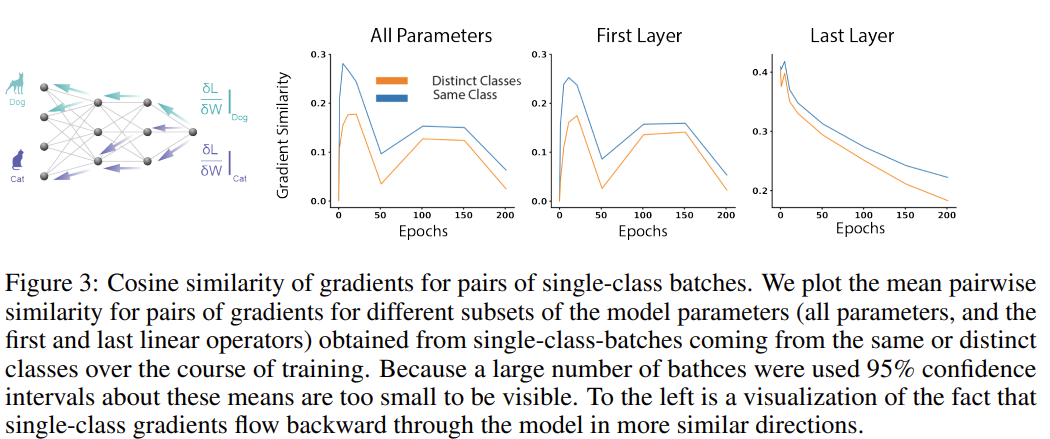
Emergence of neural manifolds via gradient coherence. 저자들은 MMCR의 클래스 구별력이 같은 클래스에 속하는 예시들에 대한 augmentation 매니폴드를 압축하는 방식이 다른 클래스에 속하는 예시들에 대한 방식보다 유사함에서 비롯된다고 보았습니다. 다시 말해, 클래스 매니폴드뿐 아니라 augmentation 매니폴드의 압축 과정에서도 클래스 간의 구별력이 학습된다는 것인데요. 이를 확인하기 위해 같은 클래스의 입력에서 비롯된 그래디언트와 다른 클래스의 입력에서 비롯된 그래디언트를 분석한 결과, 같은 클래스에서 비롯된 그래디언트의 유사도가 확연히 높게 나타났습니다.
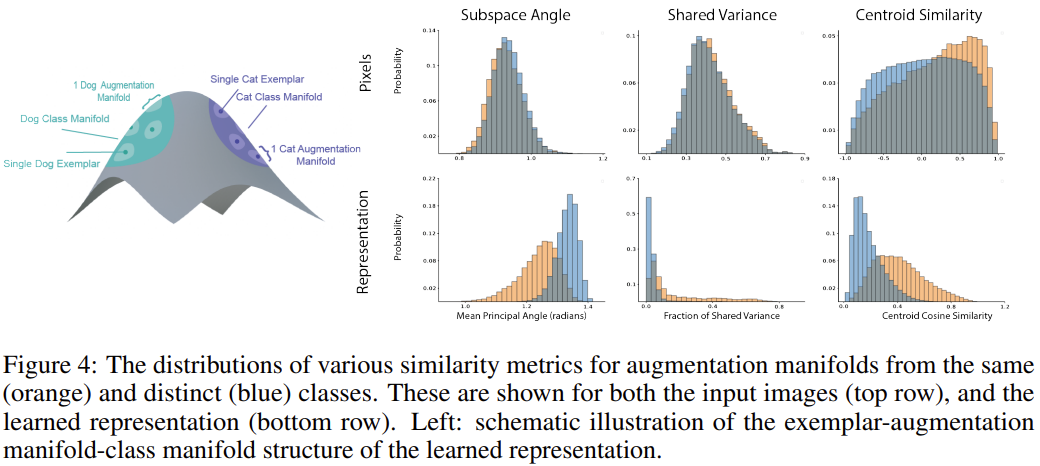
Manifold subspace alignment. 동일 클래스의 그래디언트가 클래스 구별력에 대한 그럴듯한 기계적 설명을 해주기는 하지만, 왜 같은 클래스의 샘플들이 유사한 압축 전략을 갖게 되는지는 모릅니다. 따라서 이를 확인하기 위해, pixel domain에서의 augmentation 매니폴드의 기하학적 특성을 분석하였습니다. 이를 통해, 같은 클래스의 유사도 분포와 다른 클래스의 유사도 분포 사이에 작지만 확연한 차이가 있음을 알 수 있었는데요. 그림 4의 상단을 보면, augmentation 매니폴드의 기하학적 특성에 약간의 차이가 있어, 앞서 확인한 그래디언트의 차이를 유발함을 알 수 있습니다. 이 때문에, augmentation 매니폴드는 그림의 하단 차트들과 같이, 동일 클래스와 다른 클래스 사이에 차이가 발생하게 되고, 결국 클래스들 간의 분리가 일어남을 알 수 있습니다. 동일한 클래스 매니폴드들은 centroid의 유사도가 더 높을 뿐 아니라, subspace나 variance의 유사도 역시 높음을 알 수 있습니다.
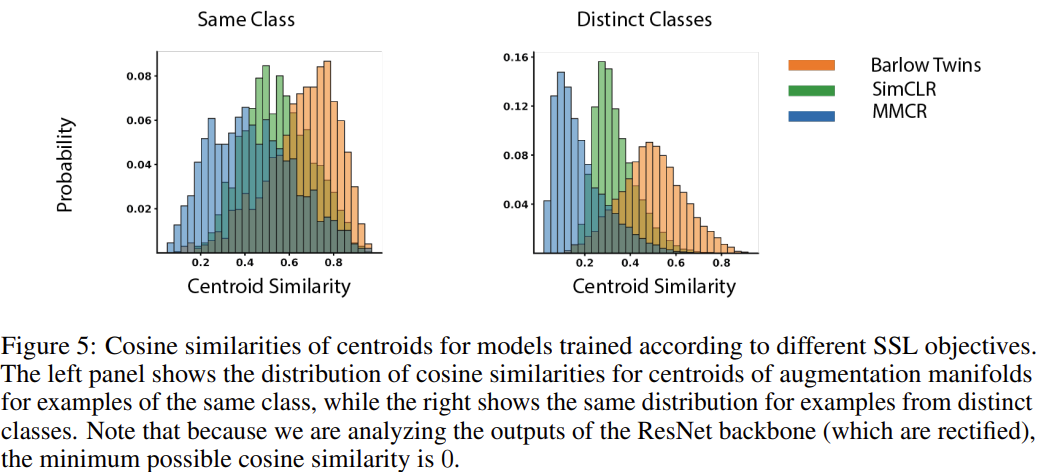
저자들은 이어서 MMCR로 학습된 representation이 다른 SSL로 학습된 representation과 어떻게 다른지 분석하였습니다. MMCR은 centroid들이 직교하도록 장려하는 반면, InfoNCE loss는 negative pair들이 최대한 유사하지 않아 지도록 합니다. 이는 유사하지 않은 샘플들(negative pair)이 같은 subspace의 반대편 공간으로 배치됨을 의미합니다. 한편, MMCR은 아예 다른 매니폴드들이 각각의 subspace를 구성하도록 합니다. Barlow Twins loss는 batch dimension에서 feature vector의 유사도를 명시적으로 활용하지 않습니다. 대신 individual feature들이 correlated 되도록, distinct feature들이 uncorrelated 되도록 합니다. 그림 5를 보면 이러한 것들이 잘 나타나 있는데, MMCR은 augmentation 매니폴드 centroid들이 다른 두 베이스라인 방법보다 확연히 직교하도록(유사도가 낮도록) 만듭니다.
Biological relevance
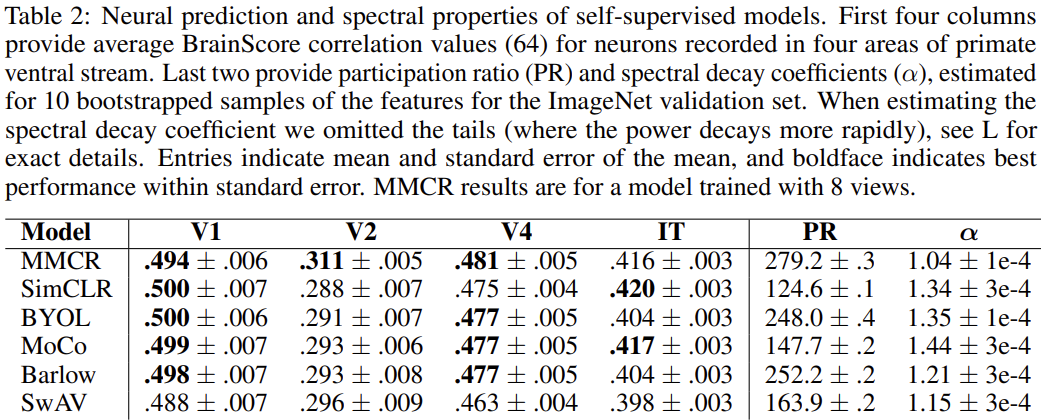
신경과학(neurosciece)은 ANN의 개발에 많은 motivation을 제공해 주었습니다. SSL이 뉴런이나 생물학적 시각계의 행동을 모방할 수 있는가 하는 것 역시 많은 관심을 받는 분야에 속합니다. 표 2에는 이와 관련한 간단한 실험 결과가 나와있는데, 제안된 MMCR과 다른 SSL 모델들의 BrainScore 성능입니다. MMCR이 영장류의 V2, V4 cortex (뇌에서 시각 신호를 처리하는 부분입니다.)의 neural data를 가장 잘 설명하였고, V1과 IT 영역에서는 2위의 성능을 달성했습니다. BrainScore가 뭔지 정확히는 이해하지 못하였지만, 실제 생물학적 시신경의 활성화를 예측하는 지표인 것 같습니다.
추가로, 저자들은 최근 소개된 general response spectral characteristics에 관한 분석도 수행하였는데요. (신경과학 관련 영역이라 최대한 이해한 만큼 설명해 보겠습니다.) Stringer et al. 은 V1 영역에서의 population activity에 대한 공분산 행렬의 eigenspectrum이 decay coefficient가 1에 근사하는 power law decay를 따른다는 것을 발견하였습니다. ($\lambda_n$이 $n$번째 고윳값을 의미할 때, $\lambda_n \propto n^{-\alpha}, \alpha \approx 1$) 이어진 연구(1, 2)에서는 신경망이 이러한 decay spectrum을 가질수록 adversarial perturbation에 대한 robustness가 증가하고 일반화 성능이 증가함을 보였습니다. 추가로, 몇 가지 최근 연구(1, 2)에서는 representational dimensionality와 neural predictivity의 상관관계를 밝히기도 하였으며, Elmoznin와 Bonner는 high intrinsic dimensionality (participation ratio of the representation covariance로 계산되는)가 neural activity를 예측하는 능력과 연관이 있음을 보고했습니다. 표 2에 ImageNet validation set에서의 participation ratio (PR)과 covariance spectrum의 decay coefficient가 함께 보고되어 있는데, MMCR의 PR이 가장 높으며, 가장 1에 가까운 decay coefficient를 가짐을 확인할 수 있습니다.
저자들은 각 모델이 linear regression 과정에서 굉장히 비슷한 fraction of neural variance를 보임을 발견하였는데, 이는 저자들이 앞선 실험들에서 각 SSL 방법론들의 representation들이 유의미하게 다른 구조(geometry)를 형성한 것(PR과 decay coefficient의 차이에서 알 수 있듯이)과 대비됩니다. 이는 최근 연구들에서 지적한 것처럼, model-to-brain comparison에 주로 사용되는 방식이 모델들을 잘 구별하지 못함을 의미합니다. 따라서 저자들은 모델 간의 중요한 차이를 잘 포착할 수 있는 geometrical measures와 같이 모델과 데이터를 비교하기 위한 새로운 지표가 필요함을 지적합니다.
Discussion
저자들은 manifold capacity theory에 기반한 새로운 self-supervised learning 알고리즘인 MMCR을 제안하였습니다. 기존의 SSL 방법들은 contrastive 방법이든 non-contrastive 방법이든 embedding gram이나 공분산 행렬에 제약조건을 부과하여 collapse 문제를 피하는 기법을 활용해 온 반면, 저자들이 제안한 새로운 프레임워크는 임베딩 행렬의 특잇값을 최적화하여 문제를 해결합니다. 이러한 population level feature (spectrum)를 바로 최적화함으로써, single-term objective만 가지고도 feature의 정합과 uniformity를 동시에 유도할 수 있었습니다. 또한, 제안된 방법은 인스턴스 간, 혹은 차원 간의 대규모의 pairwise 비교를 수행할 필요가 없어 효율적인 학습이 가능합니다. 덕분에 MMCR은 큰 batch size와 large embedding dimension을 부담 없이 활용할 수 있고, 결과적으로 최소한의 연산량 증가로도 큰 성능 향상을 이룰 수 있습니다.
MMCR은 매니폴드 구조가 타원형(elliptical)이라 가정하여 연산량을 줄이면서도 manifold capacity를 높이기 위한 충분한 학습 신호를 줄 수 있습니다. 저자들은 manifold capacity analysis를 통해 MMCR과 기존 방법론들을 분석하였는데, MMCR이 Barlow Twins나 SimCLR에 비하여 augmentation과 class 매니폴드의 차원을 낮게 만드는 반면, 반경은 더 크게 만드는 경향이 있었습니다. 저자들은 이 부분에 대해서는 이유를 찾지 못하였지만, 이러한 차이가 capacity analysis를 통해 다양한 SSL 방법론들의 인코딩 전략을 분석하기에 유용한 도구임을 보여준다고 합니다.
마지막으로 저자들은 이상적인 neural representation의 spectral properties에 관하여 최근 제안된 이론들에 대한 분석을 진행했는데, 비교한 모델 중 spectral decay coefficient가 1에 가까운 모델들일 수록 within-distribution task 성능과 unseen 데이터셋에 대한 일반화 성능이 우수하였습니다. 한편, 차원이 높은 것이 꼭 좋은 neural predictivity를 의미하지는 않음을 발견하였는데, SimCLR는 낮은 차원을 가짐에도 neural predictivity 성능이 좋았습니다. 이는 어쩌면 당연하게도, 영장류의 ventral stream의 뉴런들의 성질을 설명하기에 global dimensionality만 높아서는 도움이 되지 않음을 시사합니다.
저자들은 마지막으로 인공신경망을 개선하기 위한 방법 중 하나로 생물학적으로 그럴듯한 학습(biologically plausible)에 주목해 볼 만하다고 언급합니다. 예를 들면, 학습 데이터를 생태학적인(ecological) 데이터로 정합되도록 학습시키는 방법이 있을 수 있는데, augmentation invariance를 이용하는 현재 방식이 아니라, temporal invariance를 활용하는 방식이 생물학적으로 더 말이 된다는 것입니다. 저자들은 시간적 변화에서 MMCR objective가 짧은 시간적 변화의 평균을 이용해 centroid를 형성하고, 긴 시간적 변화에 대해 population activity의 특이값을 형성하는 방식으로 잘 작동할 것이라 예상합니다.
신경과학은 예로부터 인공신경망 분야에 많은 영감을 주고 있으며, 저자들은 신경과학에서 얻어진 통찰을 통해 이미지의 abstrat representation을 학습하기 위한 목적함수를 설계하였습니다. 저자들은 이러한 모델들의 설계와 분석, 평가를 더 잘 수행할 수 있는 실험 방식을 디자인할 필요가 있다고 future work를 제안하며 논문을 마칩니다.
Single column 10 페이지라는 그다지 길지 않은 분량에도 불구하고, 읽고 이해하는데 역대급으로 시간이 많이 걸린 논문이었습니다. 그럼에도 읽으면서 굉장히 재밌고 흥미로웠던 논문인데요.
읽는 과정에서 모르는 개념들이 워낙 많이 등장해 참고문헌도 유심히 살펴보게 되었는데, 앞서 언급한 것처럼 인공지능 거장이라 불릴만한 교수님들이 대부분 self-supervised representation learning에 관심을 두고 계시다는 점이 새삼 눈에 띄었습니다. (대표적으로 SimCLR는 제프리 힌튼 교수님, MoCo는 카이밍 허 교수님, Barlow Twins는 얀 르쿤 교수님이 참여한 연구입니다.) 당장 SSL을 연구하지는 않더라도, 항상 follow up은 하고 있어야겠습니다.
논문을 읽으면서 흥미로웠던 점을 되짚어보자면, 기존의 SSL 방법론들이 negative pair 역시도 같은 매니폴드 상에 임베딩하고 있었다는 것입니다. 최근 흔히 사용되는 InfoNCE loss는 negative pair의 유사도를 최소화합니다. 즉, 코사인 유사도를 -1로 만드는 것 입니다. 그러나 아시다시피, 코사인 유사도가 -1이라는 것은 두 벡터가 무관하다는 것이 아니라 반대 방향을 가진다는 것으로, 상관성 측면에서 보면 오히려 굉장히 큰 상관이 있는 상황입니다.
지금까지 InfoNCE loss를 많이 접하기도 하고, 사용하기도 하면서도 유사도가 -1이 되는 것은 생각을 안 하고 있었는데, 정말 충격적이었던 것 같습니다.
본 논문이 작년 12월 NIPS 2023에 발표되어 아직 후속 연구가 많지는 않은데, 기회가 된다면 올해 중으로 한번 실험이라도 돌려봐야겠습니다.
감사합니다.
안녕하세요, 백지오 연구원님, 좋은 리뷰 감사합니다. 이전에 세미나에서 한번 들었는데, 다시 읽봐도 어렵고 흥미로운 주제네요. 대체 이런 연구 소스들은 어떻게 생각해내는건지.. 볼때마다 신기합니다. 내용이 쉽지 않기 때문에, 몇가지 질문 남기겠습니다.
1. 앞부분에 neural representation에 대한 설명이 나오는데, 이해하기 쉽지 않네요. neural representation이 무엇인지 좀 더 설명해주실 수 있을까요?
2. manifold capacity가 높을수록 더 적은 차원으로 더 많은 클래스를 잘 임베딩 할 수 있다는 점에서 manifold capacity가 높을수록 표현에 대한 효율이 좋다는 것으로 이해했습니다. 그리고 논문의 목표가 manifold capacity를 loss로 하여 최적화하는것으로 보이는데요, 하지만 manifold가 뭔지, manifold capacity가 정확히 뭔지 잘 와닿지가 않습니다(매니폴드가 타원형으로 가정한다는 부분도 왜 그런 것인지 잘 모르겠네요..). 이에 대한 추가적인 설명 주신다면 감사하겠습니다.
3. 결국 manifold capacity optimizing 학습의 인코더로 ResNet을 사용하여 사전학습 한 후, downstream task에서 성능을 측정하는것 같은데, 맞을까요?
감사합니다.
안녕하세요. 허재연 연구원님.
1. neural representation은 생물의 뇌가 어떤 정보를 처리하기 위해 변환한 표현(마치 인공신경망에서의 feature)이라고 보시면 되는데요. 자세한 내용은 여전히 연구중이고, 생물학적인 부분이라 저도 자세히는 모르지만 본 논문에서는 neural representation을 연구할 때 사용되는 지표인 manifold capacity를 신경망의 representation에 적용하였다 정도로 이해하시면 될 것 같습니다.
2. manifold는 쉽게 표현하자면, 어떤 범주의 데이터들을 모델로 임베딩하였을 때, 임베딩된 포인트들이 존재할 수 있는 subspace라고 이해하시면 될 것 같습니다. 예를 들어, 강아지 클래스의 이미지들의 임베딩은 강아지 manifold, 고양이 클래스의 이미지들은 고양이 manifold 위에 위치하게 되는데, 이 두 manifold가 겹치지 않고 구별되게 존재한다면 linear classifier가 더 잘 분류할 수 있게되는 것이죠.
이 때문에 논문에서 manifold capacity를 최대화하여 이러한 manifold들이 잘 구분되도록 하는 것 입니다.
manifold를 타원형으로 가정하는 것은, 만약 manifold가 복잡한 형태를 가지고 있다면 반경과 차원 등을 계산하기가 상당히 어렵지만 타원의 반경과 차원을 구하는 것은 공식이 존재하기 때문입니다. (단순히 복잡하게 생긴 도형의 면적이나 반지름을 구하는 문제를 생각해보면 됩니다.)
3. 맞습니다.
감사합니다.