안녕하세요. 허재연입니다. 평소처럼 Active Learning 논문을 가지고 왔습니다. 평소에 Active Learning과 Self-supervised learning을 결합시킨 방법론은 없을까 막연하게 궁금했었는데 관련 논문이 있어 읽어보게 되었습니다. Active Learning의 적용에 있어 사전학습이 어떻게 영향을 미치는지, 그리고 기존의 어떤 한계점을 개선하는지를 보여줍니다. 일반적인 Active Learning 상황을 가정하지 않고 spurious correlation을 가정하는것이 특이합니다. NeurIPS2022 논문인데 다른(수식으로 도배되어 난해한..) NeurIPS 논문들과는 약간 다르게 실험 위주의 논문이고 길이도 않습니다. 바로 리뷰 시작하도록 하겠습니다.

Introduction
우선 Active Learning이 어떤 task인지 짚고 넘어가겠습니다. Active Learning은 데이터 부족 문제를 해소하기 위한 연구 분야로 라벨링 예산이 한정되어 있을 때 가장 효율적으로 모델을 학습시킬 수 있는, 모델 학습에 도움이 되는 데이터를 선별하기 위한 방법을 연구합니다. 수집한 이미지 데이터 100,000장이 있을 때, 예산 부족으로 딱 10,000장만 annotation 할 수 있다면 모델 학습에 도움이 되는(학습 효율이 좋은) 고가치 데이터 10,000장을 선별하여 학습시키는 것이 효과적일 것입니다. 따라서 AL 연구자들은 고가치 데이터를 선별하는 다양한 습득함수(acquisition function)를 제안하려고 합니다.
![Active learning cycle [2]](https://www.researchgate.net/profile/Gabor-Szucs-9/publication/326669808/figure/fig1/AS:971585791983616@1608655512045/Active-learning-cycle-2.png)
Active Learning의 학습 사이클을 살펴보면 위와 같습니다. 일단 초기에 initial labeled set을 가지고 모델을 학습시킵니다(finetuning). 학습 시킨 모델에 대해 습득함수를 적용 시켜 unlabeled data pool에서 고가치 데이터를 annotation이 가능한 예산(budget)만큼 선별합니다. 선별한 고가치(모델 성능 향상에 효율이 좋을 것이라고 기대되는) 데이터들은 orcle이라는 human annotator에게 라벨링을 맡기고, 라벨링한 데이터는 이제 labeled pool에 추가합니다. 그 이후에는 다시 업데이트 된 labeled pool의 데이터들로 모델을 fine-tuning 시키고 습득함수로 unlabeled pool에서 데이터를 선별하고 라벨링하고 labeled pool에 추가하고..의 반복입니다.
데이터의 가치를 판단하고 선별하는 수많은 습득함수(Acquisition Function)가 있지만, 크게 1. uncertainty 기반 방법론 계열과 2. diversity 기반 방법론 계열로 나눌 수 있습니다. 1.uncertainty 기반 방법론은 모델이 어려워하는 데이터가 학습 효율이 높은 데이터일 것이라는 관점으로 문제를 해결하고자 하며, 2.diversity 기반 방법론에서는 전체 데이터셋의 분포를 잘 반영하는 subset을 추출하고자 합니다. 이 둘을 함께 결합한 hybrid 기반 방법론들도 있습니다. 몇가지 대표적인 방법론들을 소개해 드리자면 다음과 같습니다 :
- Least Confidence, Margin Sampling, Entropy Sampling : 가장 기본적인 uncertainty 기반 방법입니다. classification task에서 모델의 예측 confidence(이미지 분류 CNN 모델을 예로 들면 softmax output의 분포) 및 Shannon의 entropy를 기준으로 불확실성이 높은 데이터를 선별합니다. 방법론이 간단하면서도 성능이 좋아서 AL에서 baseline으로 자주 등장합니다. 하지만 classification 이외의 task에는 적용하기 힘들다는 단점이 있습니다. 이 논문의 introduction에서는 softmax의 output이 진자 확률밀도함수가 아니며, 현대 신경망 모델의 confidence calibration 관점에서도 이슈가 있다며 한계점을 지적합니다.
- Bayesian 방법 : 베이지안 네트워크를 active learning에 응용한 uncertainty 기반 방법론입니다. 논문 ‘Deep Bayesian Active Learning with Image Data’에서 Bayesian Uncertainty Estimation을 사용하는 방법론을 제안했습니다. (이 방법이 제안된 image classification에서는)학습 시킬 때 모든 convolution layer 뒤에 MC dropout을 붙여서 학습 시킨 다음, inference 할 때도 dropout을 끄지 않고 N번 feedforward를 진행합니다. 그리고 이 N개 prediction의 variance를 이용해 uncertainty를 측정합니다. 이 또한 강력한 방법이지만, 모든 convolution 계층 뒤에 dropout을 붙이다 보니 학습 수렴이 매우 느리다는 단점이 있습니다. practical하지는 않은 편입니다.
- Ensemble : 이름 그대로 앙상블을 이용한 uncertainty 측정 방법입니다. 동일한 구조의 network를 다르게 초기화 한 후 학습시켜 prediction의 variance를 측정해서 이를 기반으로 uncertainty를 측정합니다. 이 방법도 많은 모델을 학습시켜야 하기 때문에 학습 코스트가 큰 편이라 한계가 명확합니다.
- Expected Model change : 모델을 가장 많이 변화시키는 데이터가 학습 효율이 높을 것이라는 관점의 접근법입니다. gradient의 크기를 예측하거나, 모델의 파라미터를 많이 업데이트 할 것으로 예상되는 데이터를 선별합니다.
- Core-set : diversity 기반 방법론인 core-set은 주변 데이터를 대표할 수 있는 중심점(core)들을 선별해서 전체 데이터 분포를 대표할 수 있는 subset을 추출하고자 합니다. 신경망의 feature space에만 의존하므로 classification이든 regression이든 Learning Loss처럼 task-agnostic하다는 장점이 있지만, 어려워하는 샘플을 전혀 고려하지 않고, unlabeled dataset의 크기가 너무 커지면 optimization이 굉장히 무거워진다는 단점이 있습니다.
- Learning Loss : 본 논문에서 언급된 방법은 아니지만 대표적인 방법론 중 하나이기에 짚고 가려 합니다. LL4AL은 CVPR 2019에서 제안된 간단하면서도 강력한 uncertainty 방법으로, 딥러닝 학습이 결국 하나의 Loss값에서 시작된다는 점과 Loss가 큰 데이터는 uncertainty가 높을 것이라는 아이디어에서 착안해 제안된 방법론입니다. 본래 목적의 모델 아래 작은 loss prediction module을 붙여서 데이터의 loss값을 예측하도록 학습한 뒤, 데이터의 예상 loss를 기반으로 데이터의 불확신도를 판별합니다. 위 두 방법과 달리 (딥러닝은 어떤 task를 수행하더라도 loss값에서 경사하강법으로 역전파가 진행되니) 특정 task에 구애 받지 않으며, 학습에 필요한 computational cost도 낮다는 장점이 있습니다. 성능도 준수해서 이 또한 baseline으로 자주 등장합니다.
본 논문의 목적은 새로운 습득함수를 제안하는것이 아닌, 사전학습이 AL에 미치는 영향을 분석하는 것이므로 간단한 uncertainty sampling 방법 중 하나인 least confidence 방법을 사용합니다. 그 중에서도 일반적인 active learning 상황을 고려하지 않고 spurious correlation이 발생하는, task ambiguous한 상황에 대하여 분석합니다.

Task ambiguity는 사용자가 의도한 task와 다르게 데이터가 가지는 특성만 고려하면 사용자의 의도와 다르게 task가 정의되는 현상을 말합니다. 위의 그림에서 모양을 분류하는 task로 모델을 시켰는데, 정작 모델은 색상 정보에 집중해서 학습을 진행했을수도 있습니다. 저자들의 주장은, 사전학습 모델을 활용하면 데이터에 대한 특징을 어느정도 더 잘 추출할 수 있는 능력을 가질 수 있다는 것입니다. 결국 데이터가 부족해서 다양한 문제(small dataset에서 발생하는 가짜 상관관계나 data에 대한 distribution 변화)가 일어날 수 있는 Active Learning 적용 상황에서 사전학습을 활용해 이런 문제점을 완화해 사용자가 의도한 방향대로 Active Learning을 가져가자는 것입니다.
Dataset
task ambiguity를 고려하므로 데이터셋도 기존의 일반적인 benchmark 데이터셋이 아닌, 다른 데이터셋이 필요합니다. 실험에 사용하는 데이터셋은 다음과 같습니다.
Distinguishing causal from spurious features (small dataset에서 발생하는 가짜 상관관계)
waterbirds : 해당 데이터셋은 칼텍에서 수집한 200개 종이 있는 새 데이터셋과 배경이 있는 place dataset을 활용해 두 데이터셋을 합성해 distribution shift가 있는지를 확인하기 위한 데이터셋입니다. 물새(waterbird)와 육상새(landbird)를 구별하는 2진 분류 문제로, training datset에서 waterbird의 경우 새의 배경이 물인 경우가 95%이고 landbird의 배경이 육지인 경우가 95%인 편향된 데이터입니다(배경만 보고 찍어도 95%의 정확도가 나오니 object가 아닌 배경에 집중하는 task ambiguity가 발생할 수 있겠죠). validation set에서는 배경이 반반입니다.
Treeperson : waterbirds dataset이 합성하여 만든 데이터셋이기에 편집하지 않은 이미지에 대한 데이터셋도 고려합니다. 사진에 사람이 있는지 없는지 분류하는 데이터셋이며, training set에 사람이 있는 경우 90%가 빌딩이 배경이고, 10%만 사람과 나무가 있는 사진입니다. test set에서는 사람-나무와 사람-빌딩이 각각 50%씩 있다고 합니다.
Measuring robustness to distribution shift (data에 대한 distribution이 바뀌었을 때 사전학습 모델을 사용하면 AL에서 얼마나 roubst한 결과가 나오는가)
train data와 test data의 분포가 다를 때 distribution shift가 발생합니다. 사진을 찍은 위치/시간이 바뀐다거나 텍스트 데이터의 경우 텍스트 소스의 주제나 저자를 변경하는 경우를 예시로 들 수 있습니다. 이렇게 발생한 distribution shift은 성능 저하의 원인이 될 수 있습니다. 이를 고려하기 위해서는 다음 데이터셋을 고려합니다.
iWildCam2020-WILDS : 이 데이터셋은 동물 종에 대한 분류를 수행하기 위해 CCTV로 야생동물을 촬영해 취득된 데이터셋으로 대부분 사진에 동물이 포함되지 않은 imbalance dataset입니다. test set에는 train set과 다른 동물 종과 camera location에 대한 matching이 다르게 분포됩니다.
Amazon-WILDS : 위 데이터셋들은 이미지 데이터셋이었는데, 이 데이터셋은 아마존 리뷰로 평점을 예측하는 text classification dataset입니다. training set과 test set의 리뷰어가 다르게 구성된다고 합니다.
Experiment
vision 실험에서는 백본 모델로 BiT-M-R50x1 model이라는, resnet-v2를 기반으로 ImageNet-21k데이터셋에 사전학습된 모델을 사용하며, text 실험에서는 RoBERTa-Large라는 사전학습 모델을 사용합니다.
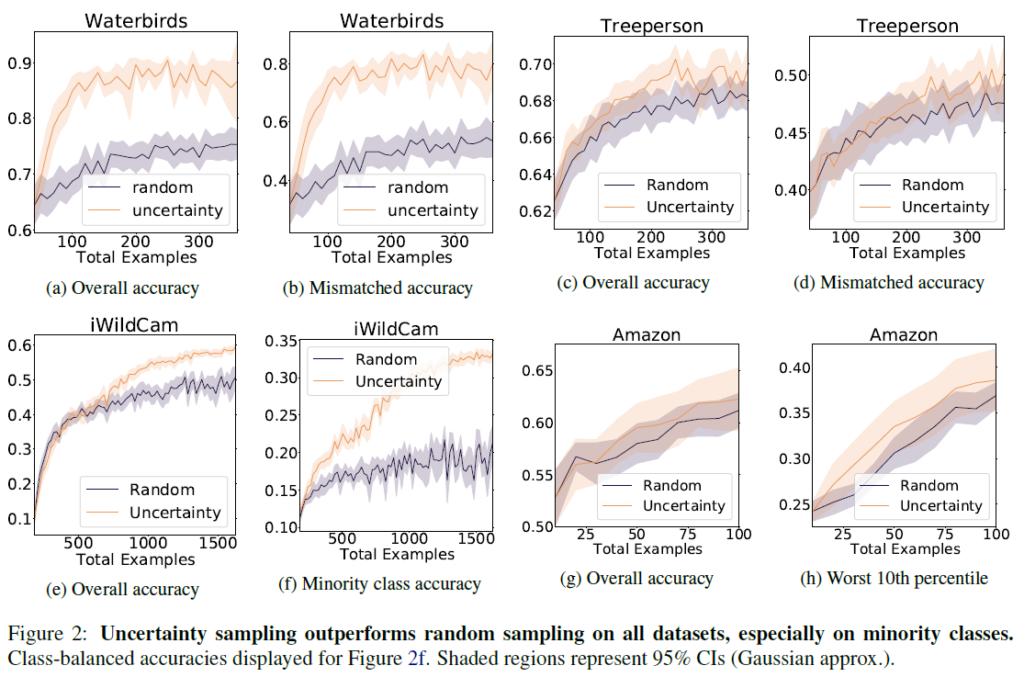
baseline으로는 AL을 적용하지 않은 random sampling과 비교했습니다. 사전학습하지 않은, 일반적인 초기화 버전도 함께 비교했으면 좋았을텐데 아쉽네요. mismatched accuracy는 spurious correlation에 해당하는 데이터에 대한 accuracy라고 보면 됩니다. 각 데이터들이 상당히 편향된 상태로 학습했음에도 불구하고 좋은 AL 성능을 보여줍니다. Waterbirds에서는 새와 배경이 일치하지 않는 것을 oversampling한다고 합니다. 저자들은 모델이 spurious feature(가짜 특징.배경)과 causal feature(인과 특징.새 종류)간 일치하지 않는 데이터들을 식별한다고 해석합니다. Treeperson과 Amazon dataset에서도 동일하게 긍정적인 경향성을 보인다면서, 저자들은 사전학습 모델의 긍정적인 효과가 다양한 modality에 확장 가능한 것으로 기대한다고 합니다.
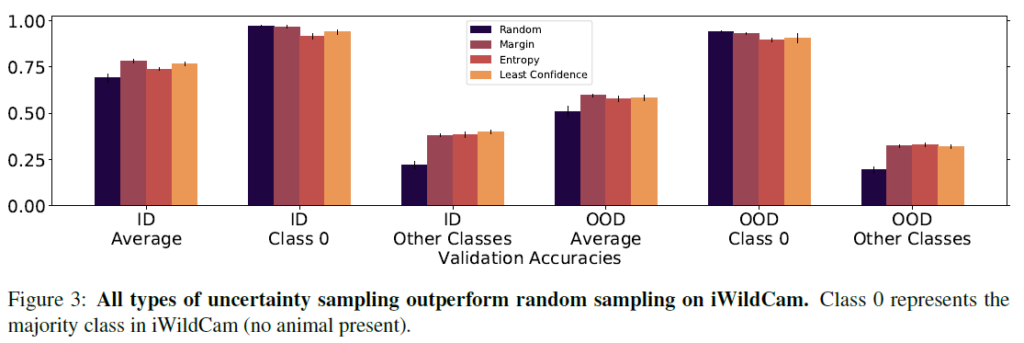
iWildCam에서는 margin sampling, entropy sampling, least confidence sampling의 3가지 uncertainty sampling이 모두 random을 뛰어넘는 성능을 보였습니다. Class 0의 경우는 동물이 촬영되지 않은 majority class임을 감안하고 보시면 됩니다.
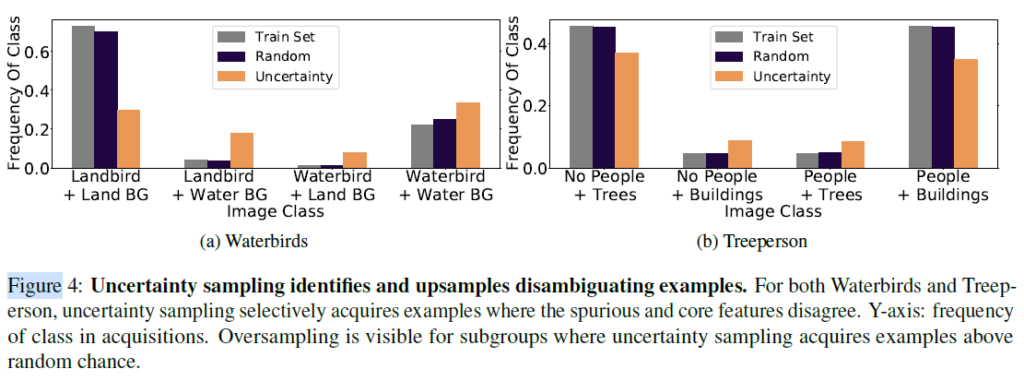
Figure 4를 보시면, random sampling의 경우 train set과 유사한 비율로 데이터를 샘플링하지만, uncertainty 습득함수를 적용하면 background보다는 object 자체를 더욱 고려해 데이터를 더 잘 수집하는것을 확인할 수 있습니다. 결국, 사전학습을 이용하면 uncertainty sampling을 적용할 때 사용자가 의도한 task에 맞춰서 AL을 수행할 수 있다고 해석할 수 있다고 합니다.
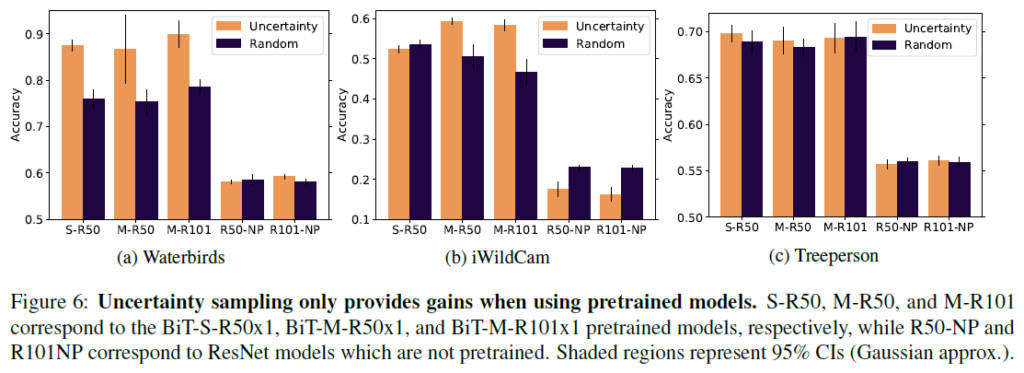
Figure 6은 사전학습 유무에 따른 accuracy 차이를 나타냅니다. NP라고 표시된 것이 사전학습 되지 않은 버전입니다. 사전학습 모델을 AL에 적용할 때, uncertainty sampling을 통해 random보다 개선된 정확도를 보일 수 있습니다. iWildCam의 경우 사전학습을 적용하지 않은 경우 오히려 Active Learning 적용 버전이 random sampling보다 성능이 현저히 낮은 것을 확인할 수 있습니다.
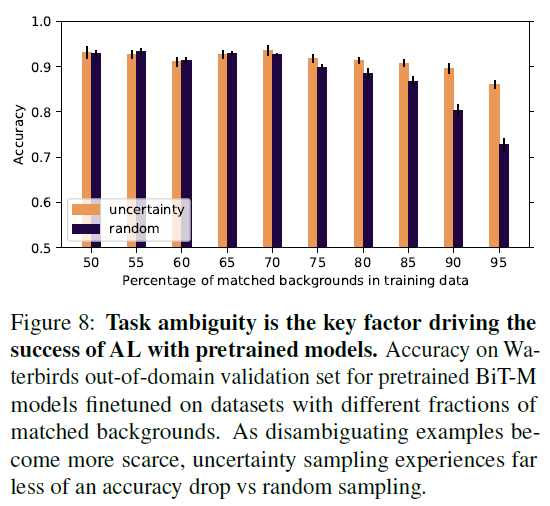
Figure 8은 task ambiguity가 AL에 얼마나 영향을 주는지 보여줍니다. waterbird dataset에서 mismatch 비율을 50%~95%로 변화시키며 실험을 진행하였는데, pretrained AL이 random sampling보다 acc 하락이 훨씬 적은 것을 확인할 수 있습니다. 이에 저자들은 task ambiguity가 해당 세팅에서 AL이 baseline보다 잘 작동하게 하는 핵심 요소 중 하나라고 주장합니다.
Conclusion
저자들은 사전학습된 모델에 사람이 task ambiguity를 예측할 필요를 완화시킬 수 있게 Active Learning이 이를 해결해 줄 수 있음을 보였습니다. 실험을 통해 데이터셋에 supuriously correlated되거나 domain shift가 있을 때 Active Learning이 해당 문제를 어느정도 완화시켜 줄 수 있음을 보였습니다. 저자들은 이러한 강점에도 불구하고 Active Learning에는 human-in-the-loop pipeline으로 사람이 지속적으로 라벨링을 해줘야 하거나, 라벨링에 노이즈가 없어야 하는 등의 AL 자체의 한계가 있음을 지적하며 향후 발전되길 바란다고 합니다.
안녕하세요 재연님 좋은 리뷰 감사합니다~
제가 아직 AL 분야의 코드를 자세히 살펴보지 못해서 이해가되지 않는 부분이 있는데 보통 AL의 학습과정에서 unlabeled dataset에서 데이터를 선별하여 라벨링하고 이를 labeled dataset에 추가시켜 모델을 다시 훈련시키는 것으로 알고 있습니다. 그리고 이 과정을 반복할때마다 모델의 가중치는 초기화 되는것으로 알고 있습니다. 그렇다면 사전 학습된 모델의 가중치도 초기화가 될 것 같은데 어떻게 사전학습이 AL에 미치는 영향을 분석하는 것일까요?
감사합니다.
Active Learning에서 사이클을 돌 때마다 모델을 초기화시켜서 재학습시키기도 하고, 이전 사이클 상태에서 그대로 업데이트를 하기도 합니다. 초기화시킨다는 것은 Active Learning이 시작하던 시점의 상태로 초기화시킨다는 것이겠죠. 사전학습된 모델을 fine-tuning 한다음에 초기화시킨다면 사전학습된 파라미터로 초기화시키게 될 것입니다.
감사합니다.
안녕하세요 재연님 좋은 리뷰 감사합니다.
Active Learning의 단점 중에 하나인 적은 라벨링으로 인해 모델이 편향되는 문제에 사전학습이 얼마나 효과적인지를 확인할 수 있는 논문인 것 같습니다. 간단한 궁금한 점이 하나 있는데 uncertainty기반이 아닌 diversity기반 방법론의 경우에는 전체 데이터셋의 분포를 잘 반영하는 subset을 활용하는만큼 사전학습의 유무에 상관없이 비슷한 성능이 나올 것이라 생각되는데 논문에서 사전학습이 diversity기반 방법론에서도 효과적인지에 대한 언급이 있었는지와 재연님의 생각이 궁금합니다.
감사합니다.
일단 논문에서는 diversity 기반 방법에 대한 언급은 없었습니다. 반약 diversity 기반 방법을 사용했다면 데이터 전체의 분포를 반영할테니 sampling ratio는 random sampling과 비슷하게 보일 수 있겠죠(하지만 무작위로 뽑는것보다는 비교적 informative한 데이터가 뽑힐 가능성이 높습니다).
만약 uncertainty 기반 방법과 다르게 모델의 prediction을 전혀 고려하지 않는 diversity AL 방법이라면 성준님 말씀대로 사전학습 유무과 크게 상관이 없을 것 같습니다. 하지만 모델의 prediction을 고려하는 방법론이라면 영향이 있겠죠. 제가 아직 diversity쪽을 제대로 follow-up하지 않아서 확실한 답변이 아닐 수 있지만, diversity 기반 방법은 일반적으로 데이터 분포만을 고려하기에 model prediction을 크게 염두하지 않는 것으로 알고 있습니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
Task ambiguity라는 개념이 굉장히 신선하게 다가왔습니다. 제가 요즘 읽고 있는 de-bias 방법론의 문제점과 비슷하다고 느껴져서 더욱 재밌게 읽었네요. 궁금한 점이 있는데 저자들은 모델에게 Task ambiguity가 있음을 어떻게 확인하였나요? 단순히 성능을 통해서 확인한 것일까요? 아니면 데이터 분포? 이러한 것들을 통해서 Task ambiguity가 있음을 확인하였나요?
감사합니다.
리뷰의 Figure 2,4를 참고하면 될 것 같습니다. 저자들은 mismatched accuracy, minority class accuracy 등으로 이를 간접적으로 확인하며, Figure 4에서 sampling 비율이 다른 것에서도 간접적으로 확인할 수 있습니다.
감사합니다.
안녕하세요. 허재연 연구원님
그림 1에서 가로축이 학습에 사용된 데이터의 양인데, 우측 끝이 학습 데이터 전체를 사용한 것이 맞나요?
데이터를 전부 사용하였을 때는 random과 AL 성능이 같아야 할 것 같은데, 성능 차이가 크게 나서 왜 그런지 궁굼합니다.
감사합니다
전체 데이터를 사용한것이 많습니다.
incremental learning에서는 데이터 학습의 순서를 어떻게 feeding하는지에 따라 최종 성능이 달라집니다. 일반적으로 AL 논문에서도 SOTA 모델의 그래프는 학습 초기에도 우수하지만 마지막 cycle에서 모든 데이터를 다 사용했을때도 다른 방법론들보다 최종적으로 개선된 성능을 보입니다.