안녕하세요, 스물세 번째 X-Review입니다. 이번 논문은 2022년도 CVPR에게재된 Practical Stereo Matching via Cascaded Recurrent Network with Adaptive Correlation 논문입니다. 그럼 바로 리뷰 시작하겠습니다. ?
1. Introduction
Stereo matching은 pixel-level로 두 영상 간의 disparity를 예측하는 task입니다. 최근 대용량의 합성 데이터셋이 증가하면서 CNN 기반의 stereo matching 방법론들이 좋은 성능을 달성하기 시작했지만, 저자는 이런 알고리즘을 일상에서 촬영한 사진에 적용하기에는 아직 3가지의 문제점이 존재한다고 합니다. 3가지 문제점은 다음과 같습니다.
- 현존하는 대부분의 알고리즘은 영상의 디테일한 부분이나, 그물과 같은 얇은 구조체에 대해서 정확하게 disparity를 추정해내지 못한다.
실제로 우리가 일상에서 촬영한 영상들은 모델이 학습하고 추론하는 영상보다 훨씬 더 큰 해상도를 갖고 있는데, 이런 고해상도의 영상으로 모델이 disparity를 예측할 경우 fine detail 주위의 disparity error가 생기게 되며, 이는 사람이 시각적으로 봤을 때 썩 유쾌하지 않게 보인다고 합니다. - 스테레오 이미지 쌍이 종종 다른 카메라 모듈로부터 취득될 수 있기 때문에, Real-world 스테레오 이미지 쌍에 대해서 완벽하게 정합하는 것은 어렵다.
구체적으로, focal length와 distortion 파라미터와는 무관한 경우인 스마트폰으로 스테레오 영상을 취득하게 된다면 이상적이지 않은 rectification 결과를 얻게 되겠습니다. 대부분의 방법론들이 스테레오 영상쌍은 완벽하게 rectified 되었을 것이라 가정한 방법론이기 때문에 앞서 언급한 스마트폰으로 취득된 영상 같은 경우 제대로 동작하지 않겠죠. 또, 이미지 쌍이 다른 카메라 모듈에 의해 취득된 경우 조명이나 이미지 퀄리티 등이 다르게 되겠고 이는 곧 disparity를 추정하는 것을 더 어렵게 만듭니다. - 대용량의 합성데이터셋에서 학습한 모델을 실제 scene으로 generalize할 수 있지만, 텍스처가 없는 상황이나 반복적인 패턴이 있는 영역 같은 경우 여전히 disparity를 추정하기 어렵기 때문에 학습 데이터셋에서 이런 scene에 대한 주의가 필요하다.
본 논문에서는 앞서 언급한 실용적인 스테레오 매칭에서의 3가지 문제를 해결하는 Cascaded REcurrent Stereo matching network(이하 CREStereo)를 제안합니다. 1번 문제를 해결하기 위해, 즉 영상에 디테일한 부분에 대한 dispairty 성능을 개선하기 위해서 저자는 coarse-to-fine 방식으로 disparity를 반복적으로 업데이트하는 hierarchical network를 디자인하였으며, 추가적으로 높은 해상도의 영상을 추론하기 위해 stacked cascaded 아키텍처를 도입하였습니다. 또한 2번 문제를 해결하기 위해서 (rectification 에러의 영향을 줄이기 위해) feature matching 단계에서 adaptive group local correlation layer를 고안해 사용하였습니다. 추가적으로 3번 문제를 해결하기 위해 조도와 텍스처, 모양이 다양한 새로운 합성 데이터셋을 소개합니다.
그래서 본 논문의 contribution을 요약하자면 다음과 같습니다.
- 실용적인 스테레오 매칭을 위한 cascaded recurrent 네트워크를 제안하며, 고해상도 영상을 추론하기 위한 stacked cascaded 아키텍처를 제안한다.
- 이상적이지 않은 rectification에 대한 상황을 다루기 위한 adaptive group correlation layer를 제안한다.
- real world scene으로 더 잘 generalize할 수 있는 새로운 합성 데이터셋을 제안한다.
- SOTA !

CREStereo에 대한 정성적 결과는 위와 같습니다. 각각 left 이미지와 모델이 예측한 disparity입니다.
2. Method
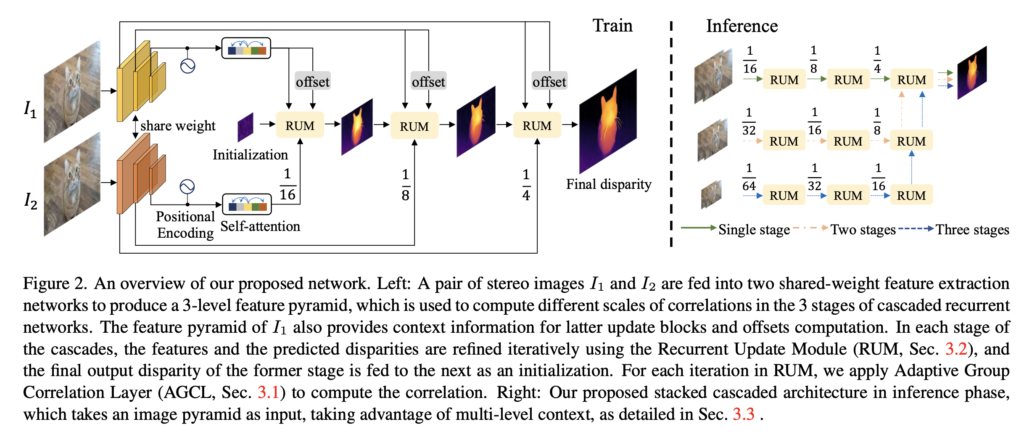
Fig 2는 네트워크 구조입니다. 보시면 두 영상이 입력으로 들어가면 가장 먼저 feature extraction을 통해 3-level의 feature pyramid가 생성되게 되며, 각각의 feature는 서로 다른 크기의 correlation을 계산하는데 사용됩니다. 각 feature map을 가지고 예측된 disparity는 RUM(Recurrent Update Module)이라고 하는 모듈을 통해 반복적으로 개선되게 됩니다. RUM 모듈안에는 Adaptive Group Correlation Layer가 들어있으며, 이를 통해 correlation을 계산하게 됩니다.
2.1. Adaptive Group Correlation Layer
먼저 rectification이 잘 되지 않았을 때의 상황을 고려하기 위해 설계한 Adaptive Group Correlation Layer(이하 AGCL)에 대해 살펴보도록 하겠습니다.
저자는 real-world 스테레오 카메라에 대한 완벽한 캘리브레이션은 어렵다고 합니다. 예를 들어 두 카메라가 정확히 수평 에피폴라 라인 선상에 위치하지 않을 수 있겠으며, 영상 보정 후에도 약간의 왜곡이 남아있을 수 있습니다. 그럼 결과적으로 스테레오 이미지 쌍에서 서로 일치하는 point가 같은 에피폴라 라인 위에 놓여있지 않을 수 있겠죠. 따라서 AGCL(Adaptive Group Correlation Layer)을 통해 이를 해결하고자 합니다.
Local Feature Attention.
우선, 스테레오 매칭 같은 경우 가장 먼저 두 영상 간의 matching cost를 계산하는 단계가 존재합니다. 이는 픽셀 레벨로 두 영상간의 correlation을 계산하는 것으로 이해하면 되겠습니다. 저자는 이 때 영상의 모든 픽셀에 대해 글로벌한 상관관계를 계산하는 방식 대신, local window 내의 point에 대해서만 계산하는 방식을 취합니다. 이는 메모리나 계산량을 줄이기 위함이겠죠. 저자는 LoFTR의 feature matching 방식에서 영감을 받아 correlation을 계산하기 전 attention 모듈을 거치도록 하였습니다. 이는 feature map에서 global context 정보를 얻기 위함입니다. 이때 계산 복잡도를 낮추기 위해 linear attention layer를 사용했다고 합니다. 이 역시 LoFTR의 아이디어를 차용한 것으로 보입니다. linear attention layer에 대한 보다 자세한 설명은 정민님의 LoFTR 리뷰를 참고하세욤. .
2D-1D Alternate Local Search.
픽셀 레벨로 두 영상간의 correlation을 계산하게 되면 correlation volume이 생성됩니다. 이 correlation volume이란 두 영상 사이의 대응관계를 나타내는 것이라고 보면 되겠으며 단순히 두 영상의 feature map간의 내적을 통해 계산할 수 있습니다. Optical flow 방법론인 RAFT 같은 경우 두 feature 간의 correlation을 계산할 때 channel축으로 내적해서 (HxWxHxW) 크기의 correlation volume을 생성하게 되며, RAFT의 스테레오 버전인 RAFT Stereo같은 경우도 (안읽어봐서 잘은 모르지만) (HxWxW)크기의 cost volume이 생성된다고 합니다.
하지만, 본 논문에서 저자는 local search window 내에서 correlation을 계산하기 때문에 RAFT, RAFT Stereo보다 훨씬 작은 크기인 H x W x D 크기의 correlation volume이 생성된다고 합니다. 여기서 H, W는 feature map의 height, width에 해당하며 D는 W보다 훨씬 작은 correlation pair의 수입니다. correlation pair 수란 예를 들어 좌측 영상의 feature map의 한 픽셀에 대해 우측 영상의 feature map에서 correlation을 계산한다고 할 때 그 한 픽셀과 대응관계가 계산되는 픽셀의 수를 말합니다. 본 논문의 경우 모든 픽셀에 대해 global 한 correlation을 계산하는 것 대신 local window내의 point에 대해서만 계산한다고 했으니 D는 W보다 훨씬 작은 수에 해당하겠죠 !
PSMNet이나 AANet과 같이 기존의 cost volume 기반의 스테레오 네트워크는 대게 (H x W x D_max) 크기의 cost volume을 구축해 사용하곤 했습니다. D_max는 disparity의 최대값에 해당하는데 즉, 가장 큰 displacement 값을 search 범위로 설정한 것이죠. 이렇게 local correlation pair보다 훨씬 더 큰 수를 고정된 search 범위로 고정해버리면 추론 시에 노이즈가 많이 생긴다고 합니다. 게다가 다른 카메라 베이스라인을 가지는 스테레오 영상을 generalize하기에는 미리 사전에 범위를 설정하는 것이 굳이? 싶다는 것이죠.
무튼 (x, y) 좌표에서 feature map F_1와 F_2에 대한 local correlation은 다음과 같이 계산됩니다.
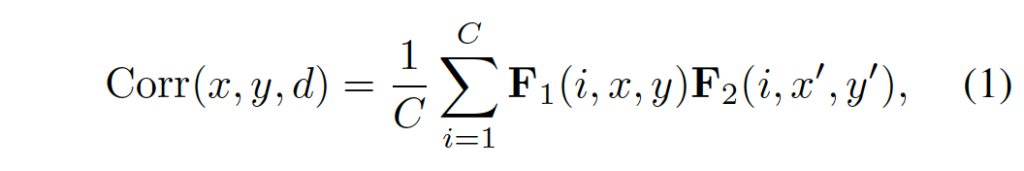
- C : 채널
- x’ = x + f(d), y’ = y + g(d)
d는 [0,D-1]의 범위 내의 수로 d번째 correlation pair에 해당하며, f(d)와 g(d)는 현재 픽셀(x,y)에 대해 correlation을 계산하는 d번째 pair의 수평 수직으로의 offset입니다.
전통적으로는, rectified된 두 이미지들 사이에서 matching point를 찾을 때 오직 epipolar line 상의 point에 대해서만 searching을 수행했습니다. 그러나 저자들은 비이상적인 stereo rectification 경우를 고려함으로써 matching 정확도를 향상하기 위해 2D-1D alternate local search 방식을 도입합니다. 이는 기존에 1D로만 matching을 수행했는데, 2D도 고려한 matching을 수행한다고 보면 되겠습니다.
먼저, 1D search같은 경우 g(d)를 0으로 두고 f(d) ∈ [-r, r]로 두었습니다.(r=4) 2D search같은 경우 dilated convolution과 유사하게 dilation l을 갖는 kxk크기의 그리드를 사용하여 correlation을 계산하였습니다. (k=3)
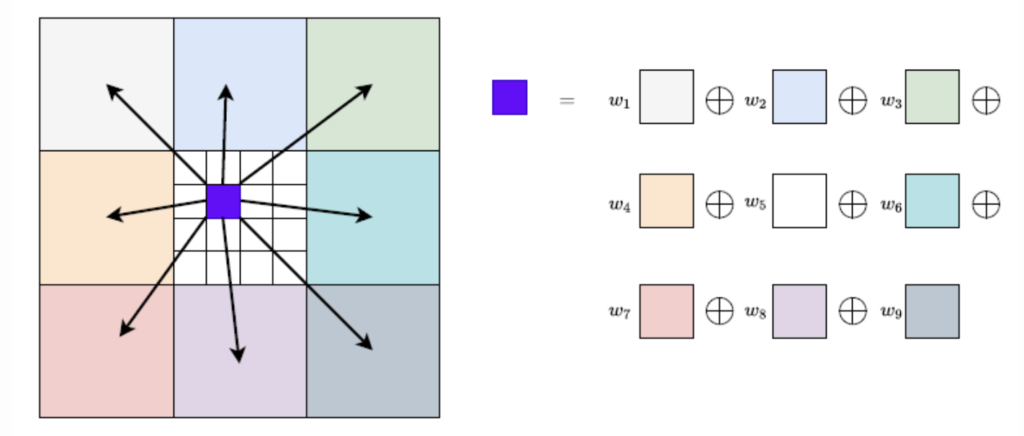
Deformable search window.
스테레오 매칭은 종종 occlusion이나 텍스처가 없는 영역에 대해서 disparity를 예측하는 것을 어려워하는데, 저자는 이를 해결하기 위해 단순히 고정된 크기의 윈도우를 사용해서 local search를 수행함으로써 correlation을 계산하는 것이 아닌, deformable convolution을 사용하여 adaptive한 window를 설계하였고, 이 adaptive한 serch window가 생성해낸 correlation pair들에 대해서만 correlation을 수행하게 하였습니다. 이 방식은 지난 번 리뷰한 AANet에서 아이디어를 따온 것으로 보이는데, AANet같은 경우 cost aggregation과정에서만 해당 방식을 사용했다면 본 논문에서는 matching cost를 계산할 때도 사용한다는 점이 차이점입니다.
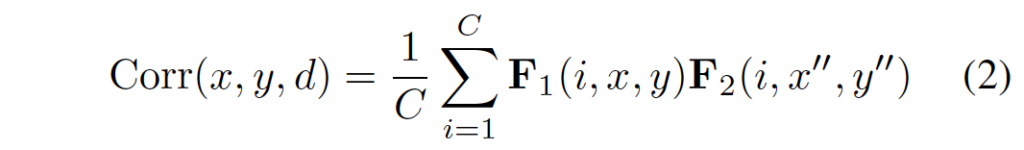
아무튼 offset dx, dy가 추가적으로 학습되도록 하였으며, 이를 추가한 새 correlation은 위 식 2와 같이 계산됩니다. 이제 x’’ = x + f(d) + dx가 되고 y’’ = g(d) + dy가 되겠네요.
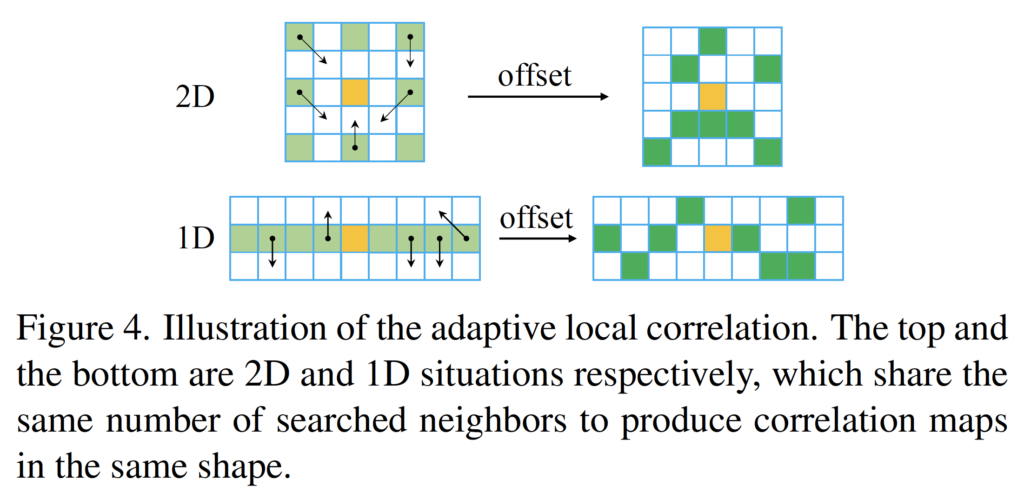
Fig4가 방금 설명드린 deformable search window를 도식화한 것입니다. 좌측이 adaptive window를 도입하기 전 window에 해당하는데, 앞서 1D에서의 search 범위는 기준 픽셀 기준으로 (-4, 4) 범위이며, 2D같은 경우 dilation l을 둔 3×3 window를 사용한다고 했던 부분을 그림으로 확인해볼 수 있습니다. 여기에 adaptive하게 correlation을 계산하도록 추가적으로 dx, dy offset을 학습하도록 하였고 이는 최종적으로 우측 그림과 같게 되겠죠. 좌측 영상을 기준 영상으로 삼았다면 현재 좌측 영상 feature의 픽셀인 주황색 픽셀에 대해 우측 영상의 feature에서 초록색 영역에 해당하는 pixel에 대해 correlation을 계산하게 된다는 의미입니다.
Group-wise correlation.
추가로 저자는 GwcNet의 group-wise 방식을 차용해왔습니다. 기존 stereo matching에서 cost volume을 생성해 낼때는 좌우 feature에 대해 matching cost를 계산한 후 단순히 concat하는 방식을 사용했었습니다. GwcNet은 이렇게 concat하게 되면 feature간의 similarity 정보를 잃게 되는 것이라고 하며 feature map을 채널축으로 g개의 그룹으로 나눈 후 각각의 그룹에 대해서 matching cost를 계산해 낸 후 나중에 결합함으로써 4D cost volume을 생성해내어 사용하는 방식을 제안합니다. 본 논문에서 저자도 feature map을 g개의 그룹으로 나눈 후 각각의 group feature map에 대해 local correlation을 개별적으로 계산한 후 최종적으로 D x H x W 크기의 correlation volume g개를 concat하여 gD x H x W 크기의 볼륨을 구축하였습니다.
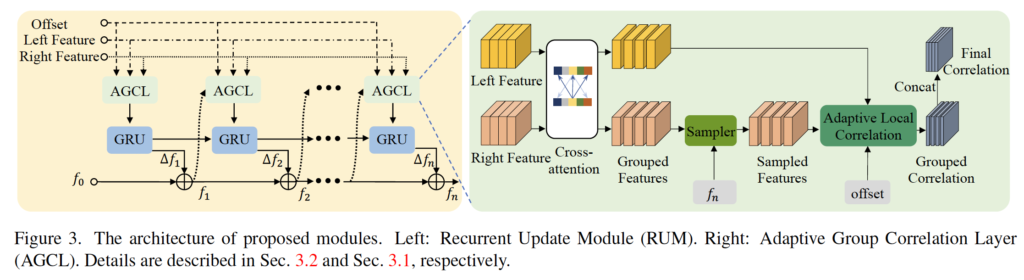
방금 설명드린 내용은 Fig 3의 우측 초록색 부분에 나타나 있는데, 보시면 grouped feature들 갈각에 대해 correlation volume이 생성되고, 최종적으로 concat함으로써 final correlation 볼륨이 생성되는 것을 확인할 수 있습니다.
2.2. Cascaded Recurrent Network
스테레오 매칭에서 high-level 특징맵의 경우 큰 수용영역과 함께 의미론적 정보도 충분히 담고 있어 matching이 용이할 수 있지만, 이런 특징맵에서 fine structure에 대한 디테일한 정보들은 사라지게 됩니다. 본 논문에서는 고해상도의 영상이 입력으로 들어왔을 때에도 디테일을 보존하고 robust하게 동작할 수 있도록 하기 위해 correlation을 계산할 때와 disparity를 업데이트 하는 과정에서 반복적으로 추론하고 재보정하는 cascaded recurrent refinement 방식을 제안합니다.
Recurrent Update Module.
저자는 GRU 블록과 앞서 제안했던 Adaptive Group Correlation Layer(AGCL)을 기반으로 이 Recurrent Update Module(이하 RUM)을 구성하였습니다. Fig3에서 좌측의 노란색 블록이 RUM에 해당합니다.
optical flow 방법론인 RAFT같은 경우에도 flow map을 반복적으로 추론하고 보정하는 방식을 사용하는데, RAFT같은 경우 한 correlation volume에 대해 average pooling을 취함으로써 multi-scale의 correlation volume을 구성하는 형식입니다. (RAFT에 대한 보다 자세한 설명은 정민님의 리뷰를 참고하세욤..) 이 RAFT의 영향을 저자가 좀 받은 것 같은데, 본 논문에서는 모든 feature map 각각에 대해 반복적으로 correlation을 계산하고 이후 예측해낸 disparity를 refinement하는 것이 한 개의 correlation volume만을 사용하는 RAFT와의 차이점이라고 볼 수 있겠습니다.
Cascaded Refinement.
cascade방식으로 refinement할 때 이전에 예측된 disparity map이 upsampling되어 feature와 크기를 맞춰준 후 RUM의 입력으로 들어가게 됩니다. 이때 저자는 RAFT에서 제안된 convex upsampling을 사용했습니다. convex upsampling에 대한 설명은 정민님의 RAFT 리뷰 원문을 훔쳐왔습니다.
컨볼루션 2개 태워서 H/8×W/8×(8×8×9)H/8×W/8×(8×8×9) 크기의 마스크를 만든 뒤 9에 해당하는 차원에 softmax를 취해서 가중치 필터를 만든 뒤 계산된 flow map에게 weighted combination을 해주면 된다고 하네요.
2.3. Stacked Cascades for Inference
학습 단계에서는 3-level의 feature pyramid에 대해 계층적으로 refinement를 수행한다고 하였습니다. 하지만, 고해상도의 영상이 입력으로 들어오게 되면 feature를 추출하고 correlation을 계산할 때 수용 영역을 키우기 위해 더 많은 downsampling을 수행하게 될 것입니다. 하지만, 고해상도 영상에서 큰 displacement를 갖는 작은 물체의 경우,,,,, 바로 다운샘플링하게 되면 이 영역에 대한 feature가 손실된다고 합니다. 저자는 이러한 점을 고려하여 추론시에는 stacked cascaded 구조를 통해 inference하는 방식을 제안합니다.
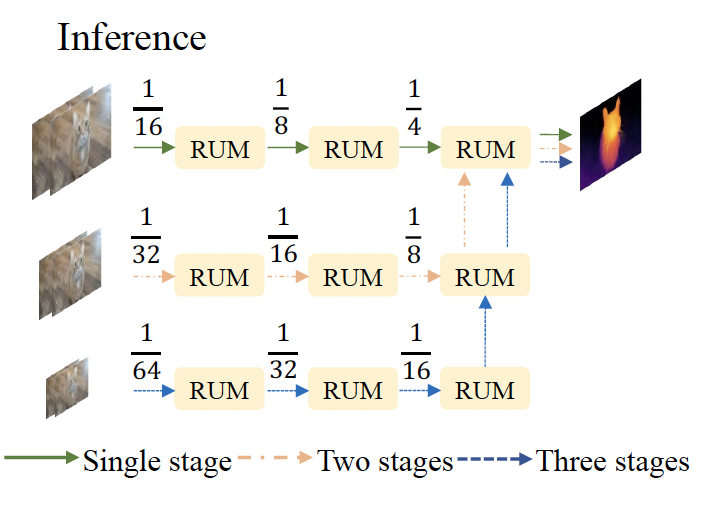
추론시 입력으로 들어온 영상을 downsample하여 image pyramid를 생성해놓고 위 그림과 같이 각각의 image에 대해 RUM을 태우고 나온 결과를 upsampling하고 또 반복적으로 RUM을 태우고… 하는 형식으로 동작합니다. image pyramid 별로 각 stage를 거치고 나온 최종 disparity map은 최종적으로 가장 큰 해상도를 갖는 영상의 stage에서 마지막 RUM의 입력으로 들어가 disparity map을 예측해내게 됩니다.
2.4. Loss Function
모델 학습은 gt값과 모델이 예측한 값을 통한 지도학습으로 수행됩니다.
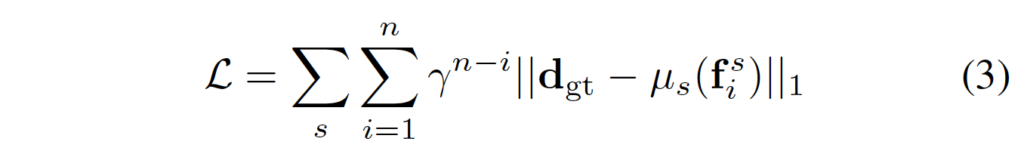
- μ_i : upsampling operator
- γ : 0.9
loss 식은 위와 같이 weighted l_1 loss입니다.
2.5. Synthetic Training Data
추가로 저자는 real-world에서 disparity 예측이 어려운 경우의 scene을 중점으로 하는 새로운 데이터셋을 제작했습니다. 3D 모델링, 렌더링 팩키지인 Blender를 사용해 합성 데이터셋을 생성하였습니다. 이때 모양, 조도, 텍스처의 다양성을 갖는 데이터셋을 구축하는데 집중했다고 합니다. 생성한 합성 데이터셋은 아래 Fig5에서 살펴볼 수 있습니다.

3. Experiments
실험은 Middlebury 2014, ETH3D, KITTI 2012/2015 데이터셋에서 수행되었으며 평가지표로는 AvgErr(평균에러), Bad2.0(disparity 에러가 2 픽셀보다 큰 경우의 퍼센트 비율), D1-all (왼쪽 영상에서 disparity outlier의 퍼센트 비율)
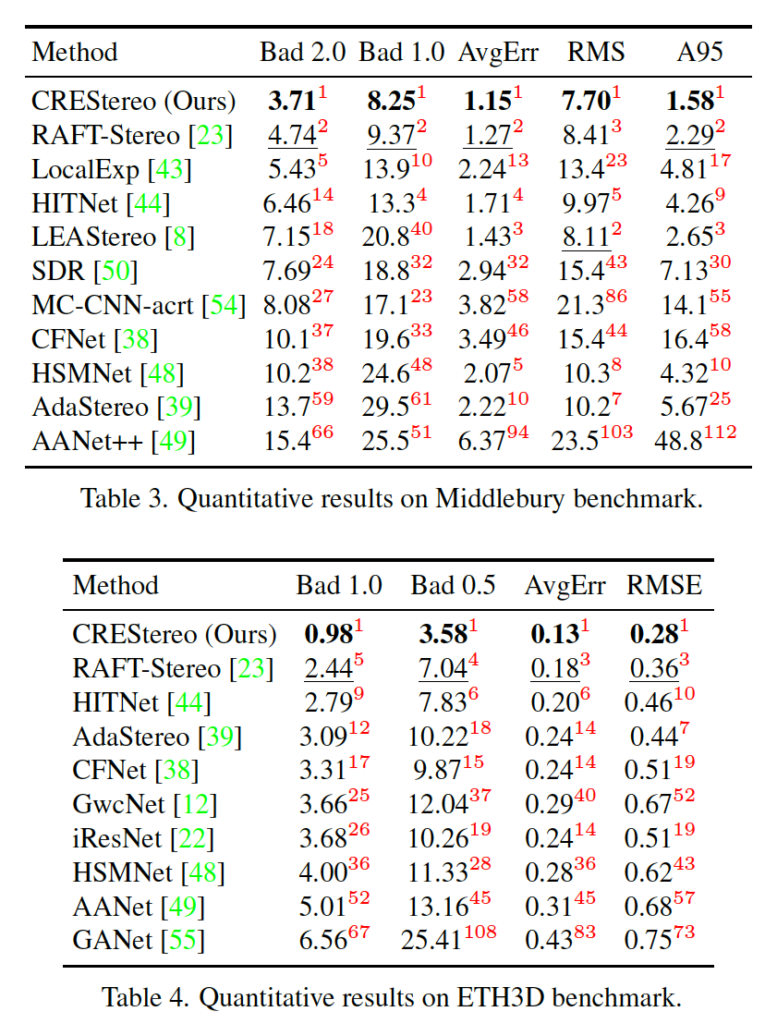
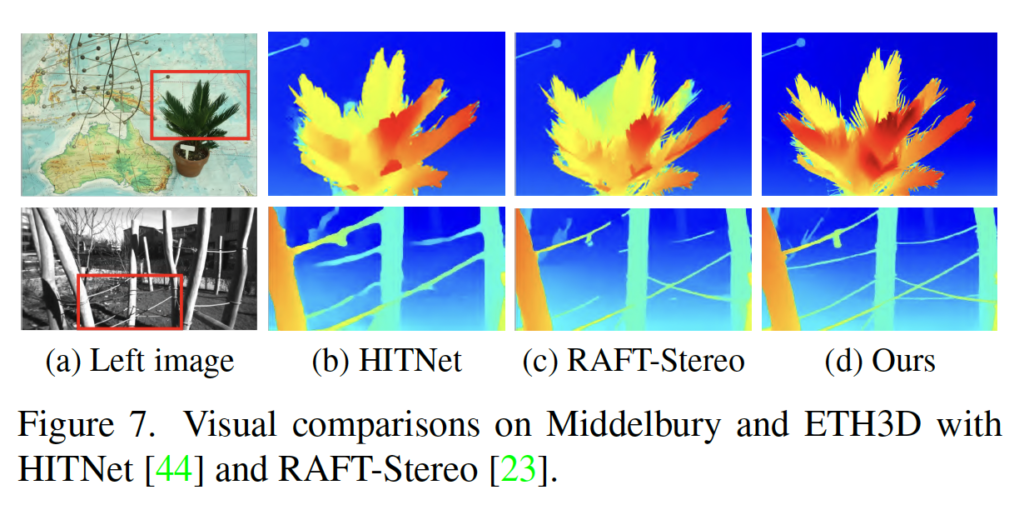
우선 Middlebury 데이터셋과 ETH3D 데이터셋에 대한 성능은 위와 같이 SOTA를 달성하였습니다. 특히 ETH3D 데이터셋에 대해서는 기존 sota인 RAFT-Stereo와 비교했을 때도 성능 차이를 많이 보입니다. 이에 대한 정성적 결과는 Fig7에서 보이고 있습니다. HITNet과 RAFT-Stereo와 비교해보았을 때 challenging한 영상에 대해서 disparity 예측을 잘 수행하네요 . . .
이외에 KITTI 데이터셋에서는 Middlebury나 ETH3D 데이터셋과는 다르게 합성 데이터셋으로 사전학습한 모델을 KITTI 데이터셋에서 fine-tuning한 후 평가하였습니다. KITTI에서도 다른 방법론들과 비교할만한 성능을 달성하혔다고 하는데, 벤치마크 표는 없고 그냥 9.47%(out-noc under 2 pix)의 성능을 달성했다고만 적혀져있네요 .. 정성적 결과는 Fig8에서 보이고 있습니다.

안녕하세요. 리뷰 잘 읽었습니다.
search window같은 경우 AANet에서 deformable convolution을 사용한 아이디어를 그대로 가져온 것으로 보이며, AANet의 경우 cost aggregation과정에만 해당 방식을 사용하고 본 논문은 matching cost를 계산할 때도 사용한 점이 차이점이라 하셨는데 이렇게 matching cost에서도 deformable search window를 사용했을 때의 이점이 있나요?
또, deformbale한 searching window로 correlation을 계산하게 되면 왜 occlusion이나 textureless상황에서 좀 더 robust해지는지 추가 설명 부탁드립니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
방법론이 기존의 문제점을 잘 짚고 그것을 잘 해결하고자 한 것 같아 좋은 논문이라 생각이 듭니다. 그런데 introduction에서 고해상도 이미지에서도 잘 disparity를 잘 추정하고자 함을 밝혔는데 이에 관해서 추가 실험이 들어있지는 않았나요? 따로 고해상도 이미지를 정성적 혹은 가능하다면 정량적으로 평가를 진행했다면 좀더 설득력이 다가왔을 것 같은데 아쉬운 부분이 있어 질문합니다. (물론 이미 SOTA를 달성한 것에서 대단한 논문이라 생각이 듭니다)
감사합니다.