이번 논문은 저번 세미나에서 발표했던 Open World Object Detection(OWOD) 방법론 중 Trainable Proposal Sampler 대신에 Random Boxes 사용해 class-agonistic detector 능력을 향상 시킨 방법론에 해당합니다. class-agonistic detector에 대해서 잘 모르시는 분들을 위해 부가 설명을 하자면, 알려진 객체 클래스 뿐만이 아니라 알려지지 않은 클래스를 가진 객체도 검출 가능한 클래스 무관한 검출기를 의미합니다.
해당 기법은 random region propsal을 통해 학습된 분류기를 통해 기존 방법론 대비 빠른 속도로 학습이 가능하며 알려진 객체에 대한 정확도를 유지하며 알려지지 앟은 객체에 대한 recall 향상에 큰 기여를 합니다.
Intro
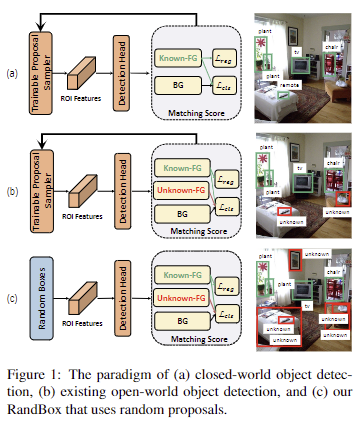
실제 세계에서 서로 다른 클래스를 가진 물체들은 공통된 시각적 특징을 통해 구분이 가능합니다. 예를 들어, ‘말’을 감지하면 ‘소’를 감지하는 데 도움이 될 수 있습니다. ‘말’과 ‘소’ 둘 다 ‘네발 달린’ 동물이기 때문입니다. 따라서 제한된 객체 클래스 포함된 학습 데이터에서 학습된 탐지기를 일반화하여 학습 데이터에 없는 클래스를 가진 시각적으로 유사한 객체를 탐지할 수 있습니다. fig 1의 오른쪽 열에서 볼 수 있듯이, 기존의 close-world에서의 객체 검출 외에도 OWOD에서는 학습 데이터 내 클래스에서 벗어난 객체를 감지하여 “unknown”으로 표시할 수 있습니다.
기존 OWOD에서 “known” 에서 “unknown”으로 feature transfer를 수행하기 위해서 다음과 같은 training loss를 사용합니다.
Knwon-FG (foreground). 기존 closed-world detection과 마찬가지로 예측된 Region Proposals (RP)의 라벨과 알려진 객체의 GT 간의 스코어를 계산합니다. 여기서 라벨은 클래스와 bbox 쌍 입니다. 특히, Faster R-CNN과 같은 2 stage detector들은 “proposal sampler”와 “matching score”는 RPN과 bbox IoU에 해당합니다. DETR과 같은 end-to-end detector들은 query transformer decoder와 bipartite matching socre에 해당합니다. 일치하는 proposals인 경우, loss는 class cross-entropy L_{cls} 와 bbox regression L_{reg} 에 해당합니다.
BG (background). 기존 탐지 기법에서는 일치하지 않는 모든 proposals은 BG로 간주되며, “BG” 레이블이 있는 L_{cls} 만 계산되어집니다. OWOD의 경우에는 아래에서 설명할 Unknown-FG을 제외하고 불일치된 proposals만 해당합니다.
Unknown-FG. 해당 부분이 기존 탐지기와 주된 차이점에 해당합니다. 해당 방법은 휴리스틱한 설계를 기반으로 합니다. 특정 임계값보다 높은 클래스 신뢰도를 가지는 일치하지 않는 proposals이 등장하는 경우에 loss는 bbox에 대한 regression 없이 “unknown”에 해당하는 특수 레이블에 할당 되어 L_{cls} 로 계산되어집니다. 해당 기법은앞서 설명한 feature transfer를 가정으로 둡니다. Unknwon-FG가 수집하는 알려지지 않은 객체가 많을 수록 OWOD 성능 향상에 영향을 줍니다.
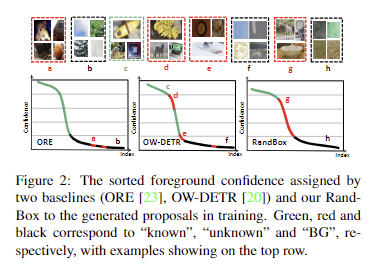
그러나 실제로 Unknown-FG는 일반적으로 알 수 없는 객체에 대한 recall이 낮은 문제가 있습니다. fig 2에서 보이는 바와 같이, 기존 방법에서는 신뢰도가 높은 대부분의 proposals이 known-FG로 매칭됩니다. 알 수 없는 객체와 BG가 혼합된 불일치 proposals은 모두 낮은 신뢰도를 가지며, Unknown-FG를 BG와 구별하기 위해 필요한 신뢰도는 점진적으로 감소하는 경향을 보여줍니다. (known: green, unkown: red, BG: black. red와 black을 구분하기 어려운 결과를 보여줌)
GT가 존재한다면 이러한 경향은 쉽게 해결할 수 있지만, 알려지지 않은 객체에 대한 근거 레이블이 없기 때문에 알려진 객체에 대해 훈련된 RPN은 필연적으로 편향될 수밖에 없습니다.
해당 논문에서는 알려진 객체로 제한된 훈련 데이터로 인해 잘못된 feature transfer로 confounding effect가 발생해 편향이 생긴다는 점을 지적합니다. 위 현상에 대해 좀 더 설명하자면, fig 1-b에서 보이는 것처럼 훈련 데이터로만 RPN을 학습하게 된다면 알려진 물체만 감지하는 경향을 피할 수 없게 됩니다. 이러한 문제를 해결하기 위해 저자는 학습 데이터와 독립된 무작위 도구 변수인 RandBox를 제안합니다. 해당 기법은 독립적인 RP를 사용하여 알 수 없는 객체가 등장 가능한 위치를 더 많이 탐색하게 하여 능동적인 학습이 가능하도록 합니다. fig 2-RandBox에서 볼 수 있듯이, 알려진 객체에서 알려지지 않은 객체로의 신뢰도 점수의 구분이 명확해지는 결과를 토대로 RandBox를 통해 알 수 없는 객체의 recall이 크게 향상된 결과를 보여줍니다.
무작위성이 가져다주는 이점은 다음과 같습니다. 첫째, 무작위화는 제한된 알려진 객체의 분포와 무관하므로, 무작위 제안은 알려진 대상에 의해 훈련이 혼동되는 것을 방지하는 도구 변수가 됩니다. 둘째, 편향되지 않은 훈련은 제안된 매칭 점수를 사용하여 더 많은 제안을 탐색하도록 장려합니다. 이러한 장점을 토대로 해당 기법은 Pascal-VOC/MS-COCO와 LVIS의 두 가지 벤치마크에서 SOTA를 달성하는 결과를 보여줍니다.
Method
OWOD은 점차 확장되는 알려진 클래스 K 집합을 감지하는 동시에 클래스가 알려지지 않은 클래스 집합 U를 “unknown”으로 검출하는 것입니다. 학습 데이터에는 알려진 물체가 n개 포함된 훈련 이미지 집합 \{(b_i, y_i) \}^{n}_{i=1} 으로 레이블이 지정되며, 여기서 b_i 는 i번째 물체의 bbox, y_i \in K는 해당 클래스에 해당합니다. OWOD의 목표는 입력은 이미지이고 출력은 m개의 예측 집합 P = \{(\hat{b_i}, \hat{y_i})\}^{m}_{i} =1 을 추론 가능하도록 검출기를 훈련하는 것이며, 여기서 예측 라벨은 \hat{y_i} \in R^{K+2} 는 K+2 ∪ {“unknown”, “BG”}에 해당하게 됩니다.
Preliminaries: Existing OWOD Methods
해당 기법에서는 2-stage detector인 Faster R-CNN와 end-to-end detector인 DETR을 기반으로 설명이 진행됩니다. 학습에는 검출기에 의해 예측된 P는 세가지 subset으로 Known-FG, Unknown-FG, BG로 분할되어져 분류 손실과 bbox 손실을 계산됩니다.
Detector. 영상이 입력되면 검출기는 m 개의 proposal을 생성하고 RoI 특징 x를 추출한 다음 분류기를 사용하여 bbox와 logit인 \hat{b}, \hat{y}로 구성된 P를 생성합니다. 서로 다른 방식을 가진 두 검출기는 첫번째 단계에서 큰 차이를 가집니다. 1) Faster R-CNN은 라벨이 지정된 데이터에 대해 사전 훈련된 RPN을 활용합니다. 여기서 objectness (알려진 객체를 포함하고 있을 확률)이 가장 큰 상위 m 개의 proposal을 예측합니다. 2) DETR은 먼저 CNN 백본과 transformer decoder 조합을 사용하여 이미지를 토큰으로 변환합니다. 그럼 transformer decoder는 토큰을 통해 prposal을 생성합니다.
Knwon-FG. 해당 기법에서는 앞에서 설명드린 바와 같이 GT를 활용하여 알려진 객체의 bbox와 클래스를 학습합니다. 자세한 내용은 생략하겠습니다.
+ 여기서 Known-FG에 해당하는 subset은 P^{K} 로 표시합니다.
Unknown-FG & BG. 는 일치하지 않는 예측에서 선택됩니다. 구체적으로 해당 방법에서는 각 예측에 대해 Unknown-FG 점수를 계산하고 가장 큰 점수를 가진 top-5를 Unknown-FG로 선택합니다. 점수는 Faster R-CNN 기반 방법들은 objectness를 이용하고 DETR 기반은 RoI feature의 평균값을 이용하여 계산합니다. 여기서 Unknown-FG의 subset은 P^{U} 로 표시합니다. 이외 나머지 subset은 P^{B} 로 표시됩니다.
Training Loss. 위에서 정의한 세가지 subset에 대한 손실을 각각 계산합니다. Known-FG에 대한 손실 L^{K} 는 아래와 같이 기존 close-set detector와 동일한 방식을 사용합니다.
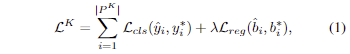
여기서 분류에는 CE Loss나 focal loss를 사용하며, bbox은 각 기법에 따른 방식과 동일한 방법을 사용합니다.
Unknown-FG and BG은 GT 정보가 없기 때문에 아래와 같이 L_{cls} 만 계산합니다.

최종적인 loss는 다음과 같습니다.
OWOD Pipeline. 먼저, 검출기의 파라미터를 무작위로 초기화하고 K 개의 레이블이 지정된 데이터로 훈련을 진행한 다음 K와 U을 포함한 데이터로 평가(Task 1)를 진행합니다. 그 다음에 추가로 레이블링된 K′ ⊂ U를 확장하여 학습 데이터로 제공됩니다. 즉, K ← K ∪ K′로 확장되고 U ← U \ K′로 축소된다고 보시면 됩니다. Task 1에서 훈련된 검출기는 업데이트된 K로 finetuning 후에 U로 다시 평가(Task 2)를 진행합니다. 이는 다음 Task에서도 반복 수행됩니다.
Proposed RandBox
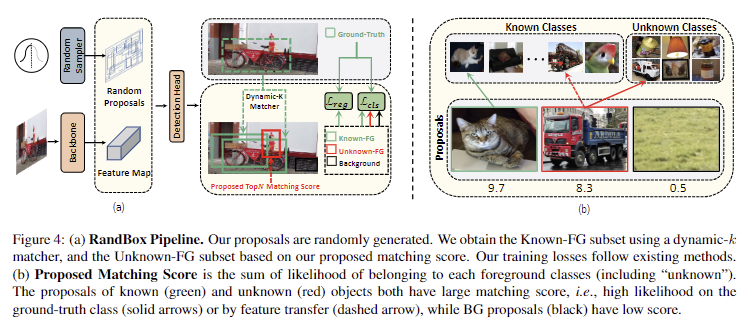
앞서 언급한 바와 같이 기존 방법들은 Unknown-Fg에서 알려지지 않은 객체 대한 낮은 recall로 인한 문제를 가지고 있습니다. 이를 해결하기 위해서 RandBox는 두 가지 개선 방법을 제안합니다. 1) 알려진 객체에 대해 훈련된 region sampler를 사용하는 대신 가능한 한 많은 알려지지 않은 객체 위치를 탐색하는 무작위로 영역 제안을 생성할 것을 제안합니다. 2) 알려진 객체와 일치하지 않는 제안에 패널티를 주지 않고 가능한 한 많은 알려지지 않은 객체 제안을 탐색 할 수 있는 matching score를 제안합니다.
Detector with Random Proposals. 훈련에서는 각 영상에 대한 영역 제안으로 500개의 bbox를 무작위로 생성합니다(fig 4-a). 각 bbox에 대해 [0, 1]의 임의 실수 4개를 샘플링되며, 각 값들은 standard Gaussian distribution을 [-2, 2]로 자른 다음 [0, 1]로 선형적으로 스케일되어져 샘플링됩니다. 4개의 값들은 각각 bbox 중앙의 가로 및 세로 좌표와 bbox의 너비 및 높이에 해당합니다. 경계를 벗어난 bbox의 너비와 높이는 이미지 크기에 맞게 조정됩니다. 테스트에서는 예측의 무작위성을 제거하기 위해 각 이미지에 대해 10,000개의 사전 정의된 bbox를 제안으로 사용하며, 이는 10개의 scales, 10개의 aspect ratios, 100개의 spatial locations을 포함합니다. 그 다음 예측된 bbox들은 NMS를 수행합니다.
Known-FG.은 fig 4-a와 같이 Dynamic-k Matcher를 사용합니다. 이는 GT와 예측 bbox의 bipartite matching score를 기반으로 k 개의 propsal과 매칭됩니다. 여기서 k 는 각 propsal과 GT bbox b 사이의 IoU의 합으로 동적으로 선택됩니다.
+ Dynamic-k Matcher은 최신 close-set detector에서 사용하는 최신 기법입니다.
Unknown-FG를 구하기 위한 새로운 matching score 기법을 제안합니다. 먼저, 가장 큰 matching score를 가진 상위 N개의 proposal를 선택합니다. 선택된 proposal 중에서 이미 Known-FG에 있는 proposal은 제거된 상태로 선택됩니다. classification logit \hat{y} 를 matching score로 활용하기 위해 아래 수식을 이용합니다.
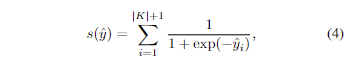
여기서 알려진 객체 K와 “+1″인 unknown class를 추가하여 sigmoid를 수행합니다. 이로써, logit은 unknown class에 대해서도 추가로 예측할 수 있게 됩니다. Unknwon-FG에 대한 logit을 학습 시키기 위해서 Known-FG에 없는 상위 N개의 proposal을 pseudo-lable로 사용하여 학습을 진행합니다. 해당 설계는 feature transfer를 가정(Unknown-FG와 Known-FG 사이의 유사성은 BG와 known-FG 사이의 유사성 보다 크다)을 기반으로 합니다. fig 4-b에서 보이는 바와 같이 알려지지 않은 객체에 대한 proposal은 shared feature로 인해 알려진 클래스에 속할 가능성이 있는 반면에 BG는 알려진 기능과 거의 공유되지 않는 것을 볼 수 있습니다. 따라서 알려지지 않은 객체는 “unknown”에 속할 가능성이 높아지며 이에 대한 recall이 증가 할 수 있습니다.
Other Details. 훈련 목표는 수식 (3)과 동일합니다. ResNet-50을 백본으로 사용했으며, Fast R-CNN [18] 기반 아키텍처이며, detection head는 Sparse R-CNN을 활용했다고 합니다.
Experiment
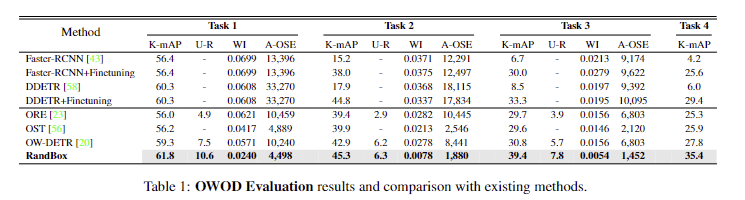
Tab 1에서는 벤치마크에서 SOTA를 달성한 결과를 보여주며, U-R(Unknown-Recall)이 크게 향상된 결과를 보입니다.
Ablation Experiments
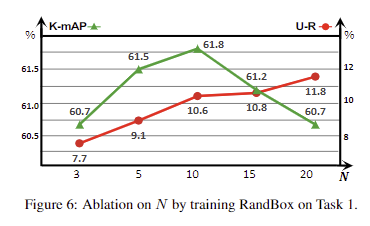
Choice of N (Fig 6). Unknown-FG를 형성하기 위해 mathcing score에서 Top-“N”에 따른 성능 변화. N이 증가하면 recall 성능이 향상하나, 과해지는 경우에는 Known에 영향을 줘 mAP 성능이 하락되는 결과를 보임. 저자는 N=10이 가장 균형이 있다고 판단하여 10을 사용
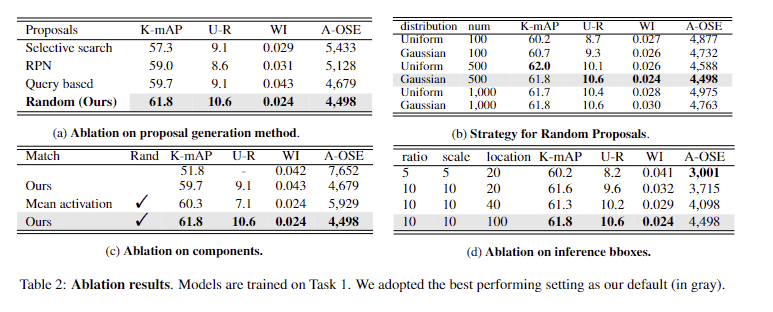
Proposal generation methods. (Tab 2-a) 기존 검출기에서 사용하는 proposal sampler에 따른 성능 결과. random이 가장 좋은 성을 보임
Strategy for Random Proposals. (Tab 2-b) 난수 값 생성 방법과 갯수에 따른 성능.
Components. (Tab 2-c) 제안한 모듈 제거에 따른 성능 변화
Inference Bboxes. (Tab 2-d) 추론 시, 박스 구성에 따른 성능 변화
+ 추론에서는 SSD의 default box와 동일하게 생성함. 앵커 튜닝에 따른 성능 변화라고 보시면 됩니다.
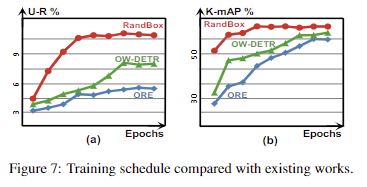
학습 수렴 빠르다는 실험 결과 (fig 7)
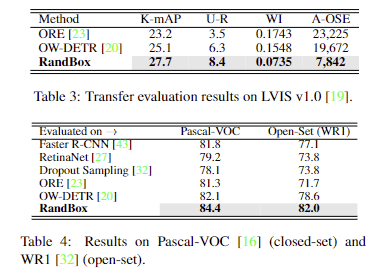
이외 벤치마크에서의 성능. SOTA 달성

정성적인 결과. (fig 8)
좋은 리뷰 감사합니다.
Unknown-FG에서 ‘특정 임계값보다 높은 클래스 신뢰도를 가지는 일치하지 않는 proposals이 등장하는 경우’ unknown이라는 특수 레이블이 할당된다고 하셨는데, 기존의 close world의 객체검출 네트워크를 활용할 때도 바로 적용이 가능한 것인지 궁금합니다. 또한, 높은 신뢰도를 가지며 일치하지 않는다는 것이 어떤것과 비교해야하는 것인지 조금 더 설명 부탁드립니다!
또한, task와 평가지표에 대하여 한가지 궁금한 것이 있습니다. 해당 테스크는 유의미한 unknown을 얼마나 잘 구분하는지가 중요할 것 같은데, 증가시킨 클래스의 수에 대한 평가는 없는 지 궁금합니다.
Q1. Unknown-FG에서 ‘특정 임계값보다 높은 클래스 신뢰도를 가지는 일치하지 않는 proposals이 등장하는 경우’ unknown이라는 특수 레이블이 할당된다고 하셨는데, 기존의 close world의 객체검출 네트워크를 활용할 때도 바로 적용이 가능한 것인지 궁금합니다. 또한, 높은 신뢰도를 가지며 일치하지 않는다는 것이 어떤것과 비교해야하는 것인지 조금 더 설명 부탁드립니다!
A1. Objectness와 Proposed RandBox의 Unknown-FG에 있는 matching score을 활용하여 구분합니다.
그리고 OWOD 전제 자체가 이미 모델이 모르는 물체를 찾는다는 것이 전제이기에 모르는 물체를 찾는 것을 어떻게 학습할 것인지에 대해서는 주 관점을 가지진 않습니다.
Q2. 또한, task와 평가지표에 대하여 한가지 궁금한 것이 있습니다. 해당 테스크는 유의미한 unknown을 얼마나 잘 구분하는지가 중요할 것 같은데, 증가시킨 클래스의 수에 대한 평가는 없는 지 궁금합니다.
A2. 증가시키는 클래스 수는 고정되어 있습니다. unknown에 대한 평가는 K-mAP를 제외하고는 관련 평가 방법입니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
Unknown-FG를 BG와 구별하기 위해 필요한 신뢰도가 점진적으로 감소하는 경향을 보여주는 이유가 정의되지 않은 객체와 BG는 모두 낮은 신뢰도를 가지기에 유의미한 비교를 할 수 없기 때문이라고 이해하면 될까요??
또한 이런 OWOD의 실험 표를 많이 본 적이 없어서 드리는 질문인데, Task가 U와 K를 업데이트하면서 반복되는 횟수를 의미한다고 설명해주셨는데 이러한 파이프라인의 반복을 얼마나 할지에 대해서는 임의로 설정할 수 있는 것인가요 ? 만약 그렇다면 본 논문에서 Task4까지 진행한 이유나 혹은 추가적으로 Task를 진행했을 때 성능 변화에 대한 리포팅은 없었는지 궁금합니다.
Q1. Unknown-FG를 BG와 구별하기 위해 필요한 신뢰도가 점진적으로 감소하는 경향을 보여주는 이유가 정의되지 않은 객체와 BG는 모두 낮은 신뢰도를 가지기에 유의미한 비교를 할 수 없기 때문이라고 이해하면 될까요??
A1. 넵 맞긴 합니다. 기존 기법들은 Unknown-FG와 BG의 구분이 어렵다는 점을 지적하며 이를 구분 짓는 방법을 제시한 방법론 입니다.
Q2. 또한 이런 OWOD의 실험 표를 많이 본 적이 없어서 드리는 질문인데, Task가 U와 K를 업데이트하면서 반복되는 횟수를 의미한다고 설명해주셨는데 이러한 파이프라인의 반복을 얼마나 할지에 대해서는 임의로 설정할 수 있는 것인가요 ?
A2. 넵 task #이 # 번째 파이프라인입니다.
Q3. 만약 그렇다면 본 논문에서 Task4까지 진행한 이유나 혹은 추가적으로 Task를 진행했을 때 성능 변화에 대한 리포팅은 없었는지 궁금합니다.
A2. Tab 1이 해당 질문에 대한 실험 결과입니다.