안녕하세요, 스물 세 번째 x-review 입니다. 이번 논문은 2023년도 CVPR에 게재된 PiMAE: Point Cloud and Image Interactive Masked Autoencoders for 3D Object Detection 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
현재 RGB 이미지와 포인트 클라우드 데이터를 융합하여 사용하고자 하는 연구가 계속 진행되고 있는데, 이러한 연구는 두 차원의 정보를 이용함으로써 더 나은 representation 결과를 얻고자 합니다. 직관적으로 쌍으로 주어지는 2D 픽셀과 3D 포인트는 같은 장면을 촬영했을지라도 서로 다른 관점에서 정보를 제공하고 있죠. 이런 정보를 함께 활용하여 성능 향상을 이룰 수 있겠지만, 이러한 멀티 모달리티 데이터를 무작정 모델의 입력으로 동시에 주게 되면 발생하는 한계점이 분명 존재하기에 모델을 설계하는 것은 어려운 task 입니다. 그래서 저자는 더 나은 representation 학습을 위해 두 도메인 사이의 상호작용을 통한 unsuprevised 멀티 모달 학습 프레임워크를 설계하고자 합니다. 설계를 위해 Masked Autoencoder (MAE)를 활용하고자 하는데 기존의 존재하는 MAE 사전 학습은 단일 모달리티로 제한되었다고 합니다. 멀티 모달리티에서 MAE의 필요성이 많이 언급되었지만 기존의 방법들은 3D와 2D 데이터를 연결하는데 있어 아직 유의미한 결과를 내지 못하고 있다고 합니다.
이를 해결하기 위해 본 논문에서는 두 도메인의 데이터 간의 상호 작용을 통해 2D, 3D의 feature을 훨씬 더 잘 학습할 수 있는 효과적인 파이프라인으로 PiMAE를 제안합니다. 특히 두 도메인에 대한 임베딩을 각각 진행하기 위해서 두 개의 독립적인 MAE 학습 프레임워크를 사용하여 포인트와 이미지 쌍을 사전학습 할 수 있습니다. 또한 이 과정에서 두 데이터의 alignment를 맞추기 위해서 세 가지 구조를 설계하였습니다.
먼저 입력으로 들어오는 이미지와 포인트를 토큰 형태로 바꾸고 두 입력 데이터의 토큰 간의 정보를 주고받기 위해 포인트 토큰을 이미지 패치에 projection하여 마스킹에 대한 alignment를 맞춥니다. 다음은 feautre fusion을 위해 새로운 대칭 구조의 autoencoder 구조를 설계합니다. 이러한 인코더는 각 모달에 대한 독립적인 인코더와 두 모달리티에서 공유되는 인코더, 두 인코더로 분리하여 구성됩니다. 그러나 정작 MAE의 마스킹 토큰은 디코더만 통과하기 때문에 모달리티 별로 디코더에서 재구성을 수행하기 위해서는 마스킹 토큰 간의 상호 작용이 존재해야 하기 때문에 공유 디코더 설계 역시 중요한 설계 구조라고 할 수 있습니다. 그렇기 때문에 마지막으로는 그런 멀티 모달에서의 재구성을 위한 모듈로, 이미지 level의 understanding을 인코딩하기 위해 포인트 클라우드 feature을 처리하는 기능을 재구성 모듈에서 수행하고 있습니다.
본 논문에서 제안한 PiMAE 사전 학습 구조의 성능을 확인하기 위해 SUN RGBD와 ScanNetV2 데이터셋에서 다양한 fintuning 구조와 3D, 2D object detection 그리고 few shot 이미지 classification와 같은 task에서의 실험을 수행하였습니다. 실험 결과를 통해 모든 downstream task에서 최신 방법론들 대비 개선된 성능을 보여주었다고 하네요. 여기서 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 처음으로 3개의 새로운 기능을 통해 포인트 클라우드와 RGB 모달리티에서 사전학습 MAE 구조를 제공
- 멀티 모달리티 학습을 향상시키기 위해 cross modal 마스킹 방식, 공유 디코더, cross modal 재구성 모듈을 제안
- 2D, 3D 검출기에 대해서 큰 차이를 두고 좋은 성능을 보이며 PiMAE의 효과를 증명
2. Methods
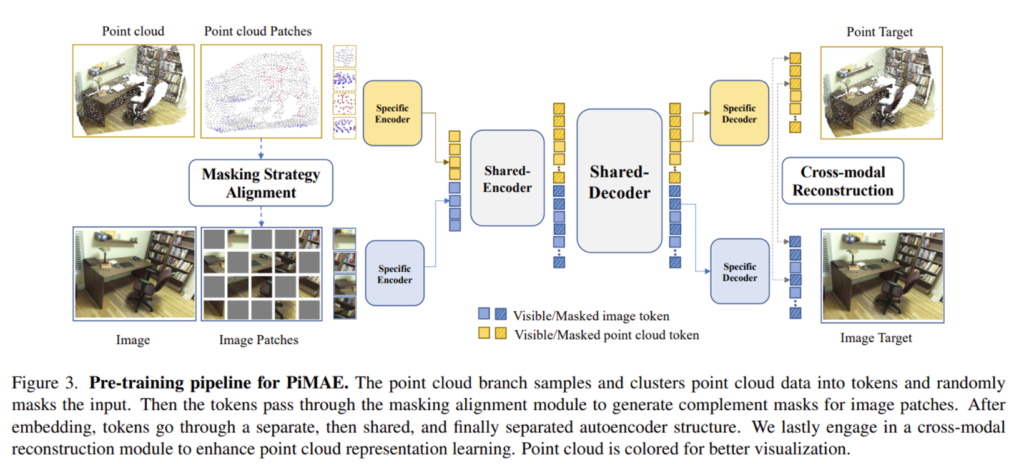
2.1. Pipeline Overview
Fig 3이 PiMAE의 전반적인 구조로, 가장 먼저 포인트 클라우드에 대한 샘플링과 clustering을 통해 데이터를 토큰에 임베딩한 후 포인트 토큰에 대한 랜덤 마스킹을 수행합니다. 이 마스킹 패턴은 2D로 변환되어 이미지 패치는 포인트 토큰이 마스킹 되지 않은 영역에 대해서 마스킹되는데, 저자는 이를 상호 보완적으로 마스킹한다고 표현하며 이런 마스킹 이후에 이미지 패치를 토큰에 임베딩 합니다. 이러한 토큰을 대칭적인 인코더-디코더 구조의 입력으로 사용하는데, PiMAE의 인코더-디코더 구조는 개별적인 / 공유하는 모듈이 각각 구성되어 있으며 개별 모듈은 모달리티 별로 feature을 학습할 수 있도록 하며 공유 모듈은 두 모달리티 간의 상호작용을 강화하기 위해 설계하였습니다. 이런 인코더-디코더 구조를 통과한 후에 사전학습 모델에서 cross modal 재구성 모듈을 통해 이미지 level의 understanding을 표현하기 위해서 포인트 클라우드 feature을 활용하게 됩니다.
2.2. Token Projection and Alignment
앞서 언급한 이미지와 포인트 클라우드에 대한 토큰을 생성하기 위해서 먼저 이미지는 픽셀 범위가 겹치지 않도록 패치로 분할한 후에 position embedding(PE)와 modality embedding(ME)가 포함된 linear projection layer을 통해 임베딩 됩니다. 포인트 클라우드는 Farthest Point Sampling (FPS)와 KNN을 통해 샘플링 및 클러스터링 처리한 후에 각 클러스터링한 그룹을 마치 이미지에서 패치와 같은 개념으로 활용하여 이미지와 마찬가지로 lienar projection layer을 활용하여 토큰으로 임베딩합니다.
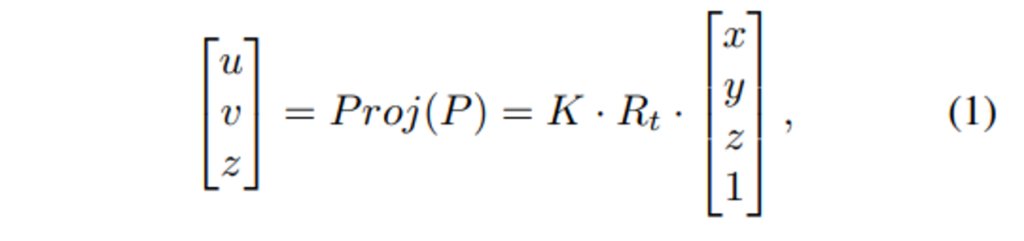
두 차원의 토큰에 대한 alignment을 맞추기 위해서 3차원 포인트 클라우드를 카메라 이미지 평면으로 projection 합니다. 그러한 projection 관계식이 위의 식(1)로 정의할 수 있으며 K와 R_t는 각각 카메라 내부, 외부 파라미터를 의미합니다. (x, y, z), (u, v)는 원래 3차원 좌표와 포인트가 projection된 2차원 좌표로 정의됩니다.
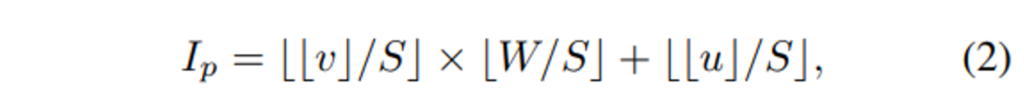
- u, v : x, y축 좌표 값
- S : 이미지 패치 사이즈
포인트 클라우드에서 토큰은 클러스터링 된 포인트 그룹을 패치로 삼아서 만들어진다고 했는데, 그 기준이 바로 클러스터링 그룹의 중심이 되기 때문에 그룹에 해당하는 토큰 뿐만 아니라 중심 포인트 역시 랜덤하게 선택하여 visible 토큰으로 삼고 나머지는 마스킹 토큰으로 처리합니다. visible 포인트 토큰 P \in \mathbb{R}^3에 대해서 그에 대응하는 그룹 중심점 포인트를 P \in \mathbb{R}^3을 대응하는 2차원 카메라 좌표로 projection하여 p \in \mathbb{R}^2를 얻게 되는 것이죠. 그래서 각각의 2차원 이미지 좌표 I_p를 정의한 것이 식(2) 입니다.
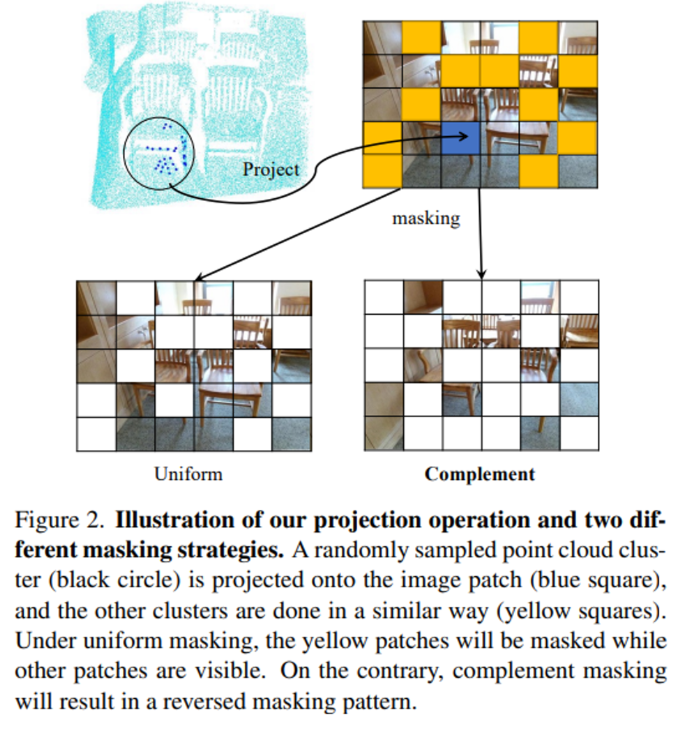
visible 포인트 클라우드를 이렇게 projection한 후 I_p와 같이 인덱싱을 하고 나면 포인트 토큰과 대응하는 이미지 패치를 얻을 수 있죠. 그러면 이러한 이미지 패치를 상호보완적인 마스킹 방식을 적용하게 되는데요, 포인트 토큰에서는 visible이었던 토큰이 이미지 토큰에서는 masking 토큰이 되는 것이죠. 이는 Fig2를 통해 확인할 수 있으며 uniform한 세팅보다 visible 토큰에서 더 풍부한 semantic 정보와 cross model feature 추출에 있어서도 더 다양한 정보를 얻을 수 있게 된다고 합니다.
2.3. Encoding Phase
인코더는 크게 각 모달리티의 특성을 고려한 model-specific 인코더(MS)와 cross-modal(CM) 인코더, 두 가지로 나눌 수 있습니다. 전자는 각 모달리티에서 얻을 수 있는 특화된 feature을 추출하기 위해서, 후자는 두 모달리티 사이의 상호보완적인 feature을 얻 위함이겠죠. 먼저 MS 인코더는 ViT 백본의 두 브랜치로 구성되어 있습니다. MS 인코더가 feature 공간에 입력 토큰을 매핑하여 모달리티의 차이를 학습할 수 있도록 align된 visible 토큰에 각각의 position과 modality를 임베딩하여 CM 인코더로 전달합니다. 그럼 CM 인코더는 visible 패치의 feature을 fusion하고 모달리티 간의 상호 작용을 진행합니다.
MS 인코더는 E_I : T_I \mapsto L^1_I와 E_P : T_P \mapsto L^1_P로 나타낼 수 있는데 E_I, E_P는 각각 이미지, 포인트 클라우드 데이터를 처리하는 인코더를 의미합니다. T_I, T_P가 visible 이미지, 포인트 토큰을 나타내며 L^1_I, L^1_P는 이미지와 포인트 latent space로 정의합니다. 즉 CM 인코더는 서로 다른 latent space의 L^1_I, L^1_P를 융합하는 역할을 하기 때문에 E_S : L^1_I, L^1_P \mapsto L^2_S로 정의할 수 있습니다.
2.4. Decoding Phase
두 모달리티의 차이 때문에 디코더에서도 역시 high level latent를 디코딩 하기 위해 특화된 디코더 구조가 필요합니다. 인코더에서는 마스킹 토큰을 통과시키지 않기 때문에 공유 디코더에 visible 토큰과 더불어 마스킹 토큰을 통과시킴으로써 두 모달리티의 마스킹 토큰에 대해서도 상호 작용이 가능하도록 설계하였습니다. 이러한 설계 구조가 아닌 각 모달리티에 특화된 독립적인 두 개의 브랜치로 디코더가 구성된다면 서로 다른 형태의 마스킹 토큰들을 feature fusion에 전혀 사용할 수 없게 되겠죠. 그 다음에는 추후 재구성에 각각의 모달리티 정보를 더 활용하기 위해 MS 디코더를 통과하게 됩니다.
공유 디코더의 입력으로는 인코딩된 visible 토큰에 대한 feature와 두 도메인의 마스킹 토큰을 포함한 전체 토큰인 L^{2’}_S이며 공유 디코더는 D_S : L^{2’}_S \mapsto L^3_I, L^3_I latent representation에 대해 모달리티 간의 상호 작용을 수행하는 것이죠. 그러면 그 다음 MS 디코더에서 이미지와 포인트 클라우드 공간으로 다시 매핑하게 되는데 이를 D_I : L^3_I \mapsto T’_I와 D_P : L^3_P \mapsto T’_P로 표현합니다. 여기서 D_I와 D_P가 이미지와 포인트 MS 디코더를 의미하며 T’_I, T’_P는 visible 이미지와 포인트 패치, L^3_I, L^3_P 가 MS 디코더 출력으로 나오는 이미지와 포인트 클라우드 latent space를 의미하게 됩니다.
2.5. Cross-model Reconstruction
두 모달리티에 대한 재구성이 수행되기 때문에 이에 대한 개별적인 Loss 계산이 이루어지며 PiMAE에는 총 3개의 로스가 사용됩니다. 포인트 클라우드는 ℓ2 chamfer distance를 사용한 L_{pc}가 계산되며 이미지는 MSE loss인 L_{img}로 계산되고 마지막으로 cross modal reconstruction loss인 L_{cross}가 사용됩니다.
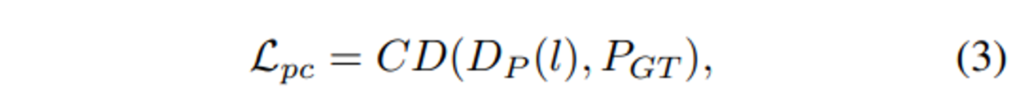
- CD : l2 chamfer Distance function
- D_P : 포인트 MS 디코더
- P_{GT} : GT 포인트 클라우
최종 reconstruction에는 앞서 맞춘 align 관계를 활용하여 마스킹된 포인트 클라우드의 대응하는 2차원 좌표를 얻습니다. 그 다음 재구성된 이미지 feature을 업샘플링하여 대응되는 2차원 좌표를 알고 있는 각 마스킹된 포인트 클라우드가 재구성된 이미지 feature와 매칭될 수 있도록 합니다. 마스킹 포인트 토큰은 대응하는 visible 이미지 feature을 recover 하기 위해서 하나의 Linear projection layer의 cross model prediction 헤드를 거칩니다. 해당 모듈에서는 visible 포인트 토큰은 사용하지 않는데, 그 이유는 상호 보완 마스킹 방식을 사용했기 때문에 visible 포인트 토큰은 마스킹 이미지 feature와 대응되어 representation 학습을 방해할 수 있기 때문이라고 합니다.
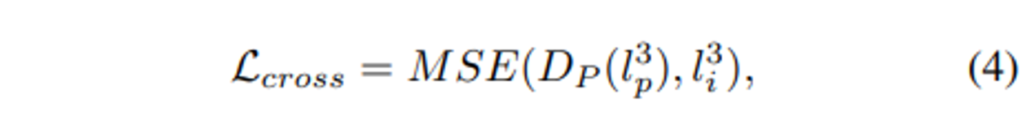
- l^3_p : l^3_p \in L^3_p, 포인트 클라우드 representation
- l^3_i : l^3_i \in L^3_i, 이미지 representation
수식적으로 cross modal reconstruction loss는 식(4)와 같이 정의할 수 있습니다.
3. Experiments
실험에서는 SUN RGBD로 사전학습한 PiMAE를 다양한 downstream task에서 평가하였습니다.
3.1. Results on Downstream Tasks
Indoor 3D Object Detection
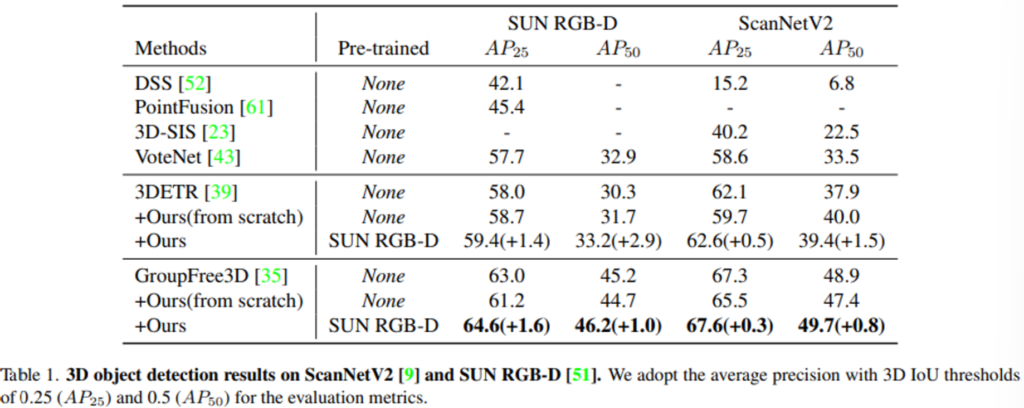

Indoor 3D Object Detection에서 SOTA 방법론인 3DETR와 GroupFree3D에서 백본 네트워크를 PiMAE로 변경한 성능 결과를 보여주고 있습니다. PiMAE로 변경하였을 때 두 모델에서 모두 기존 성능보다 개선된 결과를 보여주고 있습니다.
Outdoor monocular 3D Object Detection

다음은 indoor 사전학습 데이터와 비교하여 데이터가 비교적 어려운 outdoor 데이터셋에서의 3D Object Detection 결과를 보여주고 있습니다. 이를 통해 indoor/outdoor 환경에서 모두 강인한 성능을 보이며 일반화가 가능함을 검증하고 있습니다.
2D Object Detection

다음으로는 2D 이미지 branch의 feature 추출기를 DETR에 적용한 결과 입니다. ScanNetV2 데이터를 기반으로 사전학습된 백본과 스크래치 레벨의 백본 모두에서 실험을 수행하였습니다. Table2에서 확인할 수 있듯이 2D detector인 DETR에서도 큰 폭을 가지고 성능이 향상하면서 2D detection task에서 본 논문의 이미지 데이터 branch의 사용 가능성을 확인하였습니다.
3.2. Ablation Study
Ablation Study에서는 다른 사전학습 방식을 사용하였을 때 PiMAE 성능을 확인하고자 하였습니다.
Cross-modal masking
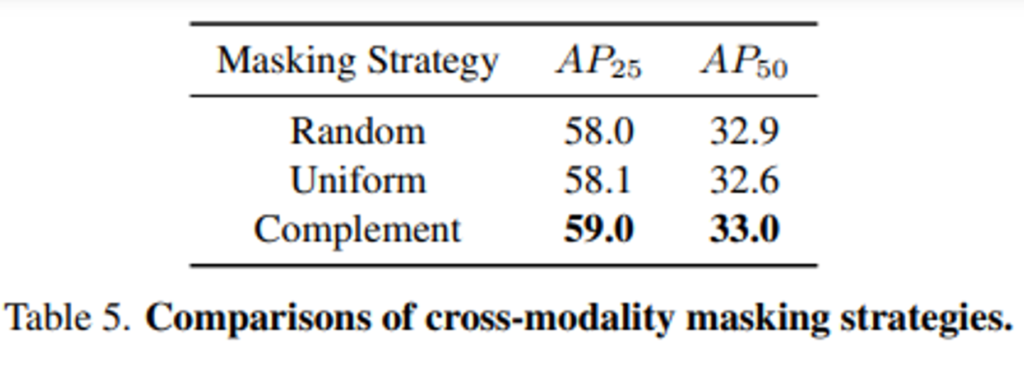
마스킹 방식에서 상호보완적인 마스킹을 사용하고 있는데 두 모달리티 사이의 마스킹 관계가 성능에 미치는 영향을 확인하기 위해 Uniform 마스킹을 도입하여 비교합니다. Uniform 마스킹은 두 모달리티에서 동일한 영역의 토큰을 마스킹하며 Complement 마스킹은 method에서 설명하였듯이 겹치지 않는 영역의 토큰이 서로 다른 모달리티에서 마스킹 되는 방식을 의미합니다. 기존 MAE에서 많이 사용하는 Random 마스킹까지 세 가지 방식으로 사전학습하였을 때 3D detection 성능을 Table5를 통해 확인할 수 있습니다. 랜덤 마스킹과 비교하여 complement 마스킹은 다양한 semantic 정보를 가진 서로 다른 모달리티 패치 간에 상호 작용을 가능하게 하였습니다. 그러나 Uniform 마스킹에서는 추출된 포인트 클라우드 feautre와 이미지 feature가 동일한 align으로 제공되기 때문에 상호작용을 하는 것이 2차원 정보를 활용하는데 도움이 되지 않는다고 분석하고 있습니다. 추가적으로 Table5의 실험은 의도적으로 cross modal reconstruction 모듈 없이 사전학습한 결과로 이는 Uniform 마스킹 방식이 마스킹된 이미지 feature에 projection되어 semantic한 정보가 적고 ablation study에서 추가적으로 성능 변화에 영향을 미칠 수 있기 때문이라고 합니다.
Effect of Cross-modal Reconstruction
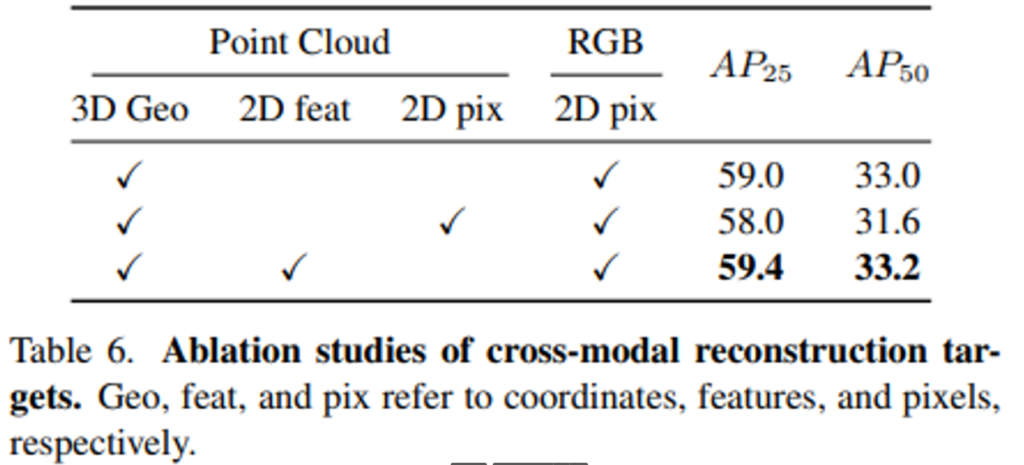
2D feature 뿐만 아니라 픽셀을 재구성하는 cross modal reconstruction 역시 가능합니다. 이 중에서 본 논문이 제안하는 포인트 클라우드와 2D feature을 통한 재구성의 우수성을 입증하기 위한 ablation study 결과를 Table 6을 통해 제공하고 있습니다. feature level에서 재구성을 하였을 때 가장 높은 성능을 보이는 것을 확인할 수 있으며 이는 cross modal reconsturction이 모달리티 간의 추가적인 상호 작용이 가능하며 2D feature을 인코딩하여 다운스트림 task에서 모델의 성능을 향상시키는데 기여할 수 있다고 합니다.
좋은 논문 리뷰 감사합니다.
2.5에서 “그 이유는 상호 보완 마스킹 방식을 사용했기 때문에 visible 포인트 토큰은 마스킹 이미지 feature와 대응되어 representation 학습을 방해할 수 있기 때문이라고 합니다.”라고 하셨는데 해당 부분에 대해서 이해가 안갑니다. 그리고 수식 4에서 이미지 representation의 아웃풋이 3 채널로 나오는 건가요???
cross modal reconstruction loss에 대해 추가 설명 부탁드립니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
먼저 상호보완 마스킹 방식을 사용했기 때문에 visible 포인트 토큰은 마스킹 이미지 feature와 대응되어 representation 학습을 방해할 수 있다는 말에 의미는 cross modal reconstruction 모듈이 2D feature을 이용해서 3D 포인트 클라우드의 reconstruction을 보완하기 위한 refinement 모듈인데, visible 포인트 토큰은 매칭되어 있는 이미지 패치가 마스킹되어 있기 때문에 2D feature을 사용해도 유의미한 표현을 하는데 도움이 되지 않는다고 판단한 것 같습니다.
수식4의 이미지 represenatation의 아우풋은 저도 3채널로 나온다고 이해하였습니다.
cross modal reconstruction은 결국 수식4에서 표시된것처럼 specific point decoder을 거친 포인트 토큰과 이미지 latent representation 사이의 MSE loss 계산을 통해 진행됩니다.
안녕하세요. 좋은 리뷰 감사합니다.
MAE의 구조에 대해 자세하게 몰라서 드는 질문인데 , , ,디코더의 출력으로 나오는 결과가 어떤 형태인가요 ?? !? 디코더의 결과가 마스킹된 토큰에 대한 예측 결과가 아니기 때문에 재구성이라는 과정이 추가적으로 필요한 것인지 궁금합니다.
그리고 재구성 ablation study에서 2D featur와 pixel을 사용하는 것이 저는 유의미한 차이를 발생시킬지 의문이 들었는데 성능 차이가 1% 이상 나는데 혹시 이에 대한 저자의 분석이나 건화님의 생각이 궁금합니다.
감사합니다 !
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
디코더의 출력 결과는 latent representation이었던 encoder의 결과값을 입력으로 받아 다시 패치 토큰으로 되돌려 놓은 형태 입니다. 디코더에서 포인트 클라우드와 이미지에 대한 각각의 reconstruction이 진행이 되고 포인트 reconstruction을 보완하기 위해서 cross modal reconstruction을 추가적으로 사용했다고 봐주시면 될 것 가습니다.
음 재구성 ablation study에 대한 질문에 저자의 분석은 따로 있지는 않았고, 제 생각에는 직관적으로 단순 2D pixel 값 만을 사용하는 것보다 해당 픽셀에서 얻을 수 있는 유의미한 feature을 reconstruction에 활용했기 때문에 아무래도 더 좋은 성능을 보이지 않았을까 생각합니다.
안녕하세요. 리뷰 잘 읽었습니다.
제가 찾던 연구와 조금 비슷해보여 읽었는데, 원본적인 궁금증이 아직 남아 있어 질문드립니다.
2D이미지와 3D PC를 함께 학습하기 위한 MAE이라면, 당연하게도 2D의 특정 위치와 3D의 특정 위치가 동일한 위치를 지정하고 있어야할텐데요, 그렇다면 2D카메라와 3D카메라 간 Resolution도 동일해야하며, 촬영한 위치도 동일해야할듯보입니다. (물론 Calibration을 통해 보정할 수는 있겠지만 현실 시나리오 상에서는 흠)
그렇다면 SUN RGB-D는 그러한 데이터 셋인가요? 그 다음 현재는 2D 이미지에서 마스킹을 씌우는 듯 하는데, 예전에 읽은 다른 분의 리뷰에서는 3D PC에 마스킹을 씌우는 방법도 있었는데, 해당 방법과 비교는 없을지 궁금합니다.