이번에 소개드릴 논문은 BinsFormer라는 논문입니다. 논문이 arxiv에만 공개되어 있는 것이 아쉽긴한데 그 당시에 KITTI depth estimation benchmark (Feb, 2022)에서 1등을 한 방법론으로 arxiv 논문 치고 인용수가 높은 논문입니다.
Intro
일반 해당 논문은 monocular depth estimation task를 수행하는 논문으로 지도학습 기반의 방법론이기 때문에 model architecture 쪽에 대한 contribution이 짙게 존재합니다. 보다 구체적으로는 깊이 추정 분야에서 이 bin이라고 하는 부분에 대해 어떻게 좋은 bin을 만들지에 대한 모델 설계 방식이 본 논문의 핵심 contribution 입니다.
bin에 대해 설명드리기 전에 앞서, 기본적인 논문의 도입 배경에 대해 설명드리면 원래 depth estimation 분야는 pixel level regression task에 해당합니다. 말 그대로 영상 내 픽셀 하나하나들이 의미하는 거리 값을 모델이 예측하는 것이죠.
하지만 이러한 regression 방식으로 모델을 학습하고 prediction하는 것은 학습 수렴이 느리고 정확도도 아쉽다고 합니다. 그래서 깊이 추정을 N개의 bin들을 통해 해당 거리에 해당하는 빈 값을 고르는 classification 문제로 풀고자 하는 방법론들이 등장했습니다.
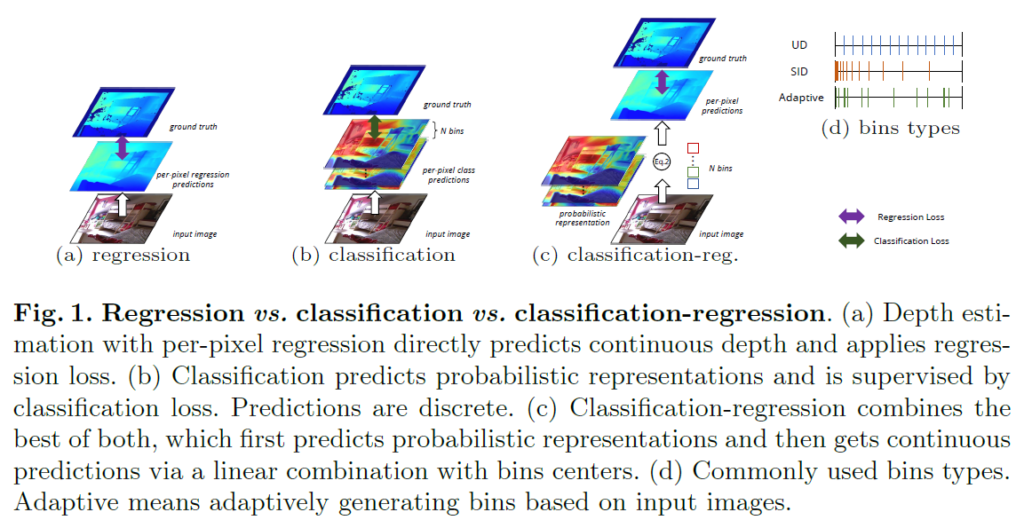
이러한 분류 기반 방식은 성능이 좋았지만 아무래도 classification 방식으로 수행하다보니 추정된 깊이 결과 값이 부드럽고 연속적이지 못하며 오히려 뚝뚝 끊기는 현상들이 발생했다고 합니다. 즉 시각적으로 보기 좋지 못하였고, 이러한 시각적 결과는 후에 3D reconstruction 등 depth를 활용하는 후처리 작업에서 문제가 될 수 있다고 합니다.
이러한 classification 기반 방식의 단점을 극복하고자, classification과 regression을 적절히 조합한 classification-regression 기반 방법론들이 제안됩니다. 이러한 방식들은 각 픽셀에 대하여 어떠한 (거리) 빈이 가장 확신도가 높은지에 대한 확률 분포를 계산한 다음에 실제 거리를 의미하는 빈들과의 가중합 방식을 적용하여 최종 거리를 계산하게 됩니다.
이러한 classification-regression 방법론들의 주요 관심사는, 초기 bin 값을 어떻게 설정하느냐였습니다. 가장 단순하게는 uniform한 간격을 띄도록 설정하는 방식이 존재할 수도 있으며, 앞부분에는 촘촘하게 하다가 거리가 멀어질수록 빈 값을 드문드문 놓는 방식도 있었으며, 또는 데이터 셋에 맞추어 모델이 bin 값을 학습하는 learnable 방식도 존재하곤 했습니다.
특히 21년도 CVPR에 게재된 논문인 Adabins라는 논문에서는 입력되는 장면에 따라서 실제 GT depth의 분포가 다르다는 점에서, 모델이 깊이 추정에 사용하는 bin 역시 입력에 맞게 적응적으로 추론해야 할 필요성을 다시 한번 확인했으며, bin center를 적응적으로 추론하는 transformer 기반 bin generation 모듈을 제안했다고 합니다.
하지만 이러한 Adabin의 노력에도 불구하고 여전히 성능의 개선에 한계가 있다고 저자는 주장하는데, 가장 큰 문제는 decoder의 제일 마지막 레이어의 출력값인 최고해상도 특징 맵에 의존하여 bin 값을 예측한다는 점으로 이 때문에 빈 값과 확률 표현 값이 모두 하나의 레이어 특징으로 추론이 되어 충분한 상호작용이 부족하며, 글로벌 및 세부적인 정보의 표현력이 부족해진다고 합니다. 대충 저자의 문제 제기를 요약해보면 single layer에서 bin을 생성하는 것에 무언가 문제가 있다고 생각을 하는 것 같네요.
또 새로 지적하는 문제는 adabin에서 제안된 분포에 적용하는 chamfer loss는 헛된 inductive bias를 불러일으켜 정확한 bin을 생성하는데 한계가 있다고 합니다.
결과적으로 저자들은 이러한 문제를 해결하기 위해 2가지 방안을 제안합니다. 첫째로 트랜스포머 디코더를 활용하여 bin의 길이와 bin 임베딩 벡터 자체를 구분 두어 생성하였다는 점, 그리고 이때 multi-scale feature map을 적절히 활용하여 구조적 기하학 정보를 포괄적으로 이해하고, coarse-to-fine 방식으로 깊이 영상을 추론할 수 있었다고 합니다.
마지막으로 추가적인 장면 이해 query를 트랜스포머 디코더에 추가하여, 입력된 환경이 무엇인지 분류를 수행하도록 하였으며 이러한 scene classification token과 query token간에 self-attention을 통하여 입력 장면에 맞춤 bin을 생성할 수 있었다고 합니다.
보다 구체적인 내용은 아래 method에서 더 다뤄보도록 하겠습니다.
Framework Overview
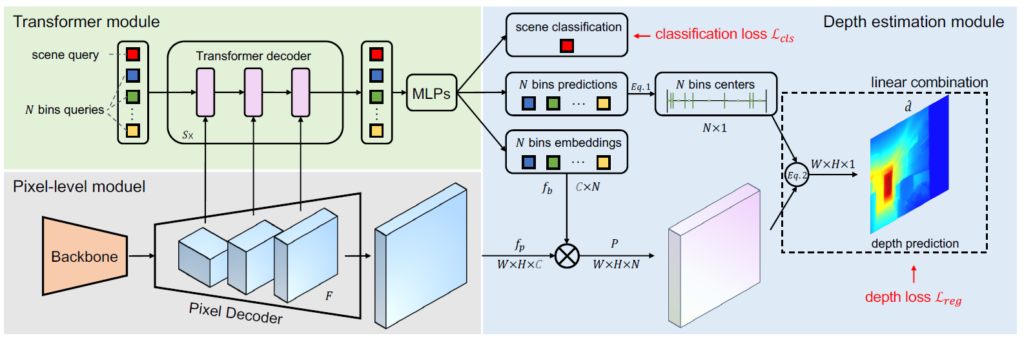
그림2는 Binsformer의 전체 framework을 나타내는 그림입니다. 먼저 크게 특징을 추출하는 Encoder backbone, pixel Decoder, Transformer Module, Depth estimation Module로 구성되어 있는 모습입니다.
Encoder backbone 같은 경우에는 Resnet과 같은 CNN을 활용할 수도 있으며, Swin transformer같은 Transformer 기반 네트워크를 사용해도 무방하다고 합니다. 말 그대로 입력 영상에서 좋은 feature map을 생성하기만 하면 된다는 것이죠.
그 다음에 중요한 부분은 그림2 좌측 상단 녹색 배경의 Transformer module입니다. 해당 transformer module에서 깊이 추론에 필수적인 bin을 생성하게 됩니다. 여기서 N개의 bin query가 존재한다고 표기되어 있는데, 초기 bin query를 pixel decoder의 feature map과 적절히 Transformer의 attention 연산을 거치며 해당 입력 영상에 맞춤형 bin을 생성하는 것이 Transformer module의 핵심입니다.
이렇게 bin query들을 잘 생성하였다면 이제 depth module에서 깊이 추론 과정을 수행하게 됩니다. bin query들 중 특정 브랜치에 따라서 bin embedding과 bin prediction으로 빠지게 되는데, 여기서 bin embedding은 pixel decoder에서 나온 최고해상도 feature map과의 내적 연산을 통해 어떤 bin과 가장 연관성이 높은지를 결정하는 key 생성을 목적으로 하며, bin prediction은 특정 후처리를 통해 깊이 추정을 위한 최종 bin으로 변환이 됩니다.
대략적인 흐름을 설명드렸는데, 보다 구체적인 내용은 아래에서 하나하나 다뤄보도록 하겠습니다.
Per-pixel module
먼저 Backbone 다음에 이어서 나오는 Per-pixel module은 사실상 인코딩 과정을 통해 줄어들었던 해상도를 원본 해상도로 복원해주는 디코더의 역할을 수행하는 네트워크입니다. 따라서 해당 모듈에서 나온 결과값 f_{p} 는 H x W x C의 shape을 지니게 되며 여기서 HW는 feature map의 해상도를, C는 채널을 의미하게 됩니다.
그리고 이러한 f_{p}는 multi-scale로 구성이 되어 있다라는 점을 참고해주시면 좋을 것 같습니다.(즉 1/4, 1/8, 1/16 등 다층 해상도를 지님)
저자가 제안하는 binsformer는 단순히 transformer를 CNN의 대체연산으로 사용하던 기존 연구들과 달리 Transformer를 통해 bin을 생성하고자 하는 것이기 때문에 해당 per-pixel module의 결과값인 f_{p}는 바로 밑에서 소개드릴 Transformer module의 입력으로 어떻게 활용되는지를 잘 보셔야 합니다.
Transformer module
단순히 image feature map을 Transformer에 태워 attention 연산을 수행하는 것이 아니라, BinsFormer에서는 Transformer가 좋은 bin을 생성하기 위해 활용된다고 말씀드렸습니다.
구체적으로 이야기하면, 먼저 초기 N개의 입력 토큰들은 bins query의 역할을 수행하며, 이들은 per-pixel module의 output인 f_{p}와의 상호작용을 통해 output embedding Q \in \mathcal^{C_{q} \times N} 를 생성하게 됩니다. 그 다음에 Q에 FC layer 연산 및 softmax 연산을 취하여 N개의 길이를 가지는 빈들을 생성하게 되는 것이죠.
또한 3개의 Fc layer + RELU 연산을 통해 N개의 bins embedding f_{b} \in \mathcal{R}^{C\times N}를 생성하게 되며 이러한 bins embedding은 per-pixel module의 output인 f_{p}와의 내적을 통한 유사도 계산에 활용됩니다.
Multi-scale prediction refinement
저자들은 깊이 추정을 수행하는데 있어 고해상도의 특징맵에서 세세한 디테일을 학습하는 것이 매우 중요하며, 이를 위해 multi-scale prediction refinement 전략을 적용했다고 합니다.
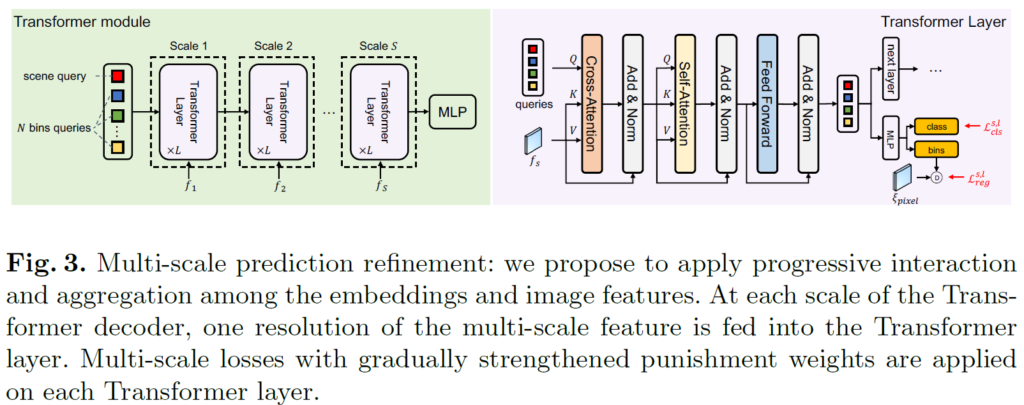
그림3을 보시면 multi-scale refinement 과정을 확인하실 수 있는데, 먼저 하나의 scale에 대해 Transformer 연산이 수행하는 과정을 보다 자세히 살펴보면, Query는 bin query, K와 Value는 per-pixel module에서 생성된 multi-scale feature map 중 하나로 cross-attention 한번 진행하고, 그 이후에 self-attention을 통해 정보 통합을 한번 더 수행합니다.
이러한 cross-attention 과정을 통해 feature map에 맞춤형 bin을 생성하도록 하며, self-attention으로 bin들 간에 대한 정보 통합 과정도 수행하게 되는 것이죠. 그리고 이러한 attention 연산이 마무리 되었다면, 다음 transformer layer로 넘어가게 되는데, 이때 또 다른 해상도의 deocoder feature map이 입력으로 들어오면서 multi-sclae refinement를 수행한다는 것입니다.
또 한가지 눈여겨 볼 점은, 각 scale module에서부터 depth prediction을 통한 loss와 뒤에서 소개드릴 scene classification loss를 계산한다는 점입니다. 즉 multi-sclae로 loss도 계산하더라 라고 이해하시면 되겠습니다.
Depth Prediction Module
그럼 깊이 추정 모듈에 대해서 다시 알아보도록 하죠. Transformer module을 통해 올바른 bin query들이 생성되었다면, 이들은 각각 bin embedding과 final bin prediction 과정을 거쳐 최종 bin을 생성하게 됩니다.
이때 bin embedding f_{b}는 per-pixel decoder의 최고해상도 feature map f_{p}와의 내적 연산을 통해여 H x W x C –> H x W x N으로 변환시키게 됩니다. 이는 깊이 추론에 활용되는 최종 bin c(b)의 shape이 N x 1이며 해당 c(b)와의 가중합을 통해 최종적인 깊이 값(H x W x 1)을 생성하기 위함입니다.
그럼 이때 c(b)는 어떻게 생성이 되느냐면, 이는 그냥 Adabin의 방식과 동일하게 수행하였다고 합니다.
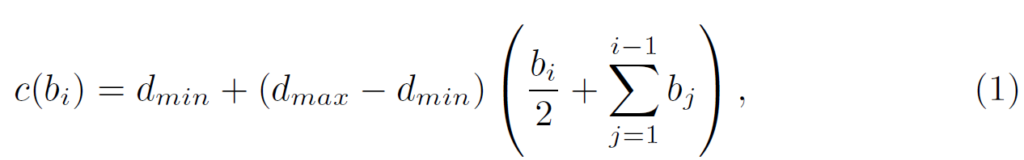
여기서 d_{min}, d_{max} 는 각각 해당 데이터 셋의 최소 거리와 최대 거리를 의미합니다. 그리고 c(b_{i}는 i번째 빈의 중심 빈이라고 합니다.
그 다음에는 아까 위에서 설명드린대로 f_{p}, f_{b} 간의 내적 후 softmax를 취한 p와의 가중합을 통해 최종적인 깊이값을 생성하는 것이죠.

그리고 본 논문은 지도학습이기 때문에 아래 loss를 통해 GT depth와의 loss를 계산 방식으로 모델을 학습합니다.
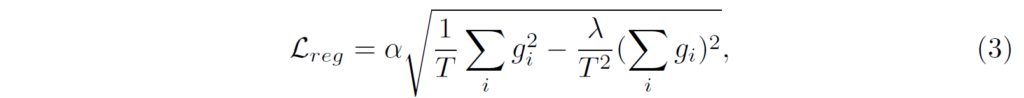
Auxiliary scene classification
Transformer module에서 bin query과 달리 scene classification을 위한 token이 하나 따로 있는 것을 위에 그림에서 확인하실 수 있었을 겁니다. 단순히 입력 이미지에 맞게끔 adaptive bin을 생성하는 것 보다는 이렇게 scene classification을 수행하는 token을 따로 두어 해당 token으로는 따로 Auxiliary scene classification을 수행함으로써 입력 영상이 지금 어떠한 장면인지를 모델이 더 의미론적으로 파악하기 쉽다고 합니다.
즉 scene classification을 수행하는 token과 bin query들 간에 self-attention을 통해 장면에 대한 global semantic information을 bin query들이 잘 학습할 수 있었다고 저자는 주장하고 있죠. 이 부분은 컨셉이 직관적이어서 요정도만 설명하고 넘어가겠습니다.
Experiemnts
실험 섹션에 대해서 설명드린 후 마무리 짓도록 하겠습니다.

위에 표는 NYU dataset에서의 ablations study를 나타내는 표입니다. 우선 baseline이라고 명시된 행은 transformer module과 depth prediction module이 전부 제거된 말 그대로 backbone과 per-pixel module만으로 곧바로 깊이를 regression하는 방법론이라고 합니다.
그리고 baseline+의 경우 Transformer module을 통해 bin embedding과 per-pixel decoder 간에 내적을 수행 후 regression하여 depth를 추론하는 것으로, bin center를 활용한 depth prediction 단계가 생략된 것으로 보시면 됩니다.
저자들은 우선 고정된 bin을 활용하는 UD와 SID 그리고 이전 SOTA인 adabin의 bin방식과 비교하여 자신들이 제안하는 Transformer decoder 기반의 bin 활용 방식이 가장 좋은 성능을 보여준다라는 것을 주장합니다.
또한 단순 regression 방식보다 classification & regression을 활용하게 될 경우, auxiliary classification을 통한 distribution에 추가 정보 제공 및 multi-scale refinement 각각이 모두 모델 성능에 점진적인 성능 향상을 보여주고 있습니다.
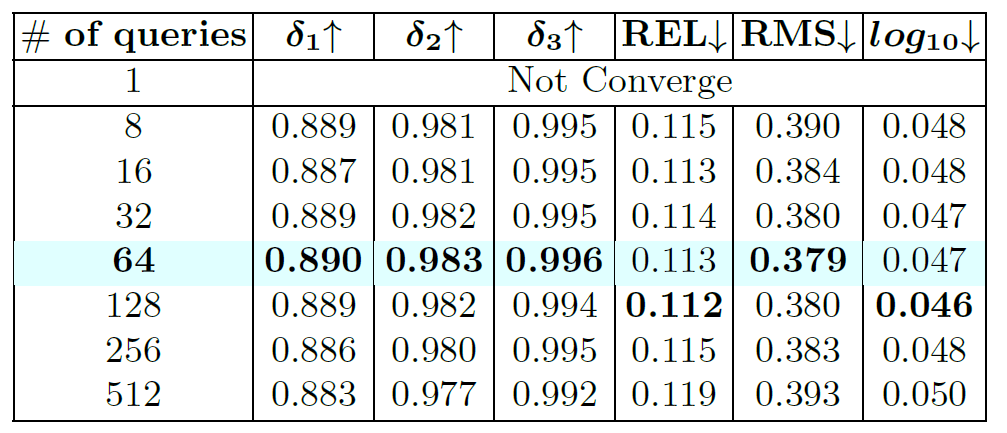
위에 표는 query의 길이에 대한 ablation study로 query의 개수가 너무 커지는 것은 오히려 성능에 감소를 불러일으키며 32~128 사이에 가장 적당했다고 합니다. 성능과 연산량 측면에서 64를 저자는 가져갔다고 하네요.
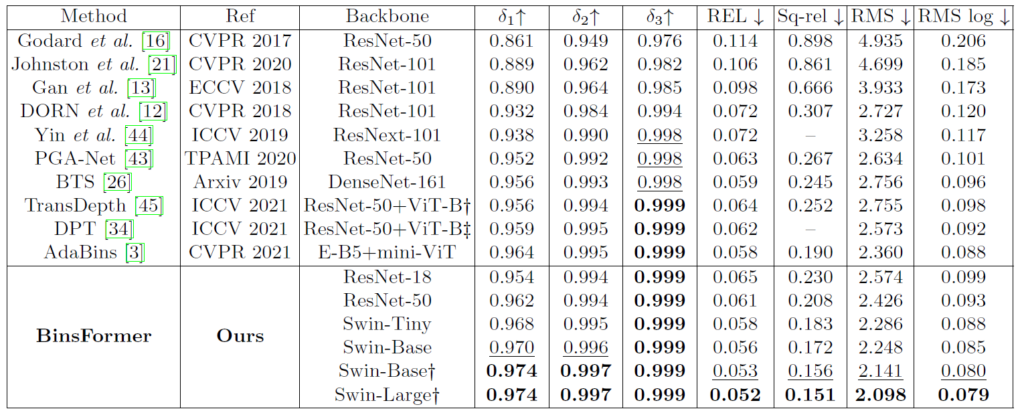
위에는 KITTI dataset에 대한 결과로, 해당 논문에서 모델의 크기 등의 비교를 안해주기에 정확한 비교는 조금 어려워보입니다. 특히 서로 다른 백본을 지니고 있는터라 모델의 크기 대비 누가 더 좋은 성능을 보여준다라고 말하기에는 어려운 상황인데, 일단 Swin의 Base 이상 모델을 활용할 경우 모든 메트릭에서 가장 큰 성능을 보여주고는 있습니다. 근데 저 십자 표시는 imagenet22K 사전학습을 의미하는지라 사전학습된 데이터의 양에서도 아마 차이가 존재할 것으로 여겨집니다.
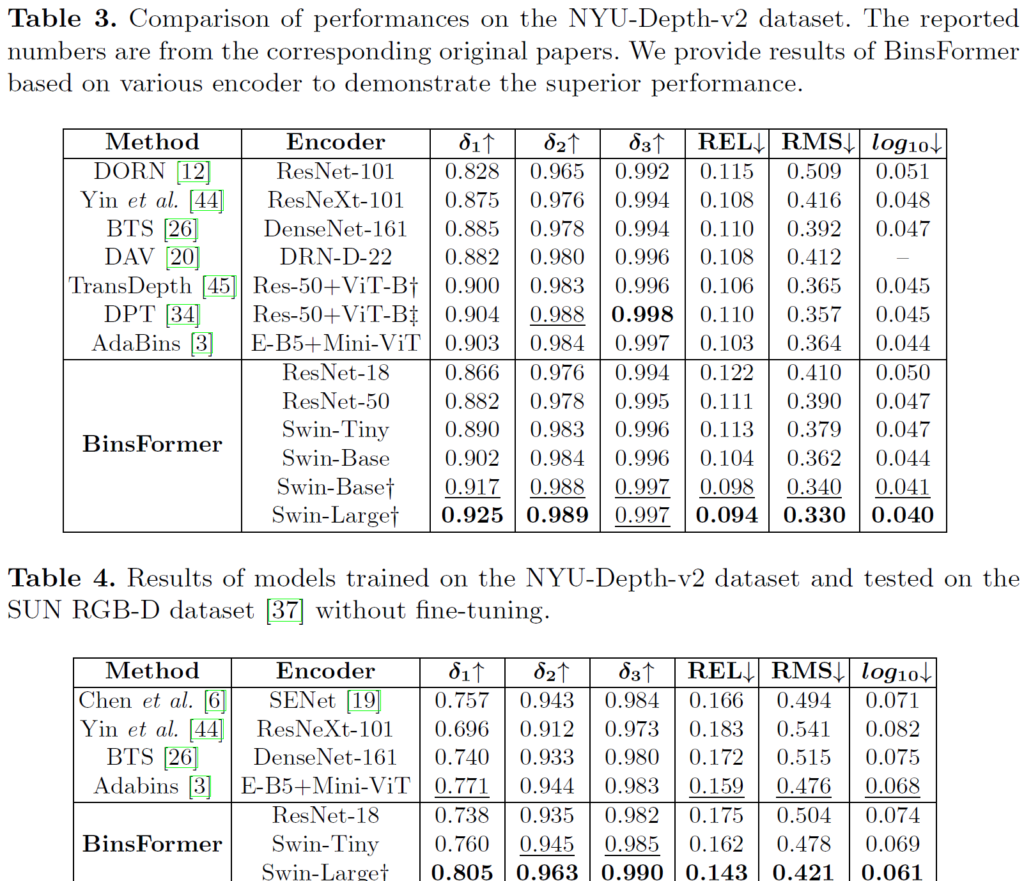
위에 표 3,4는 각각 NYU 데이터셋에 대한 학습 및 평가 그리고 NYU 데이터셋으로 학습 및 SUN RGB-D 데이터셋으로 평가한 결과입니다. KITTI와 마찬가지로 방법론들이 서로 다른 백본을 활용하는 바람에 직접적인 비교가 어렵다는 점에서 타 방법론들 대비 우수하다라고 말하기가 조금 모호한 상황입니다.
결론
트랜스포머를 활용해 영상의 특징 자체를 CNN에서 대체하는 방법론이 아닌 깊이 추정에 핵심인 bin 값을 잘 만들어보자라는 측면에서 컨셉 자체는 재밌게 여겨졌던 논문입니다만, 실험단에서 타 방법론과의 직접적인 성능 비교가 어렵다는 점에서 아쉽게 느껴진 논문입니다. 그래서 다른 학회를 붙지 못한 것인가? 싶기도 하구요.