안녕하세요 정의철 연구원입니다. 제가 이번에 리뷰할 논문은 ‘Diverse mini-batch Active Learning’입니다. 기존의 Active Learning은 데이터를 하나씩 선별하였기에 딥 러닝 모델에서는 효율적이지 않습니다. 따라서 이 논문에서는 미니 배치 Active Learning 환경을 고려하여 여러 데이터를 한 번에 선택하게 됩니다. 또한 미니 배치로 선별된 데이터들의 정보성과 다양성을 고려하는 방식을 제안합니다. 이 접근 방식은 K-means 클러스터링 알고리즘을 사용하여 이전에 제안된 방법보다 더 효과적으로 확장되며, 비교적 더 나은 성능을 달성합니다.
1. Introduction
AL(Active Learning)의 핵심 구성 요소는 쿼리 전략입니다. 쿼리 전략은 오라클이 주석을 달아야 할 unlabeled dataset의 샘플을 결정합니다. AL에서 자주 사용되는 두 가지 유형의 쿼리 선택 기준은 정보성(Informativeness)과 대표성(representativeness)입니다. 정보성을 사용하는 쿼리 전략은 대표적으로 다음과 같습니다.
- 최소 신뢰 (Least Confidence):
- 모델이 출력 클래스에 대해 매우 불확실한 경우의 데이터 포인트 선택.
- 계산: 각 입력 샘플 x에 대해 최고 확률을 가진 클래스 y*를 선택하여 신뢰 점수 LC(x) 계산.
- 해석: 낮은 클래스 확률 P(y*|x)은 높은 신뢰 점수 LC(x)로 이어지며, 이는 샘플 x의 정보성이 높다는 것을 의미.
- 최대 엔트로피 (Maximum Entropy):
- 모델의 불확실성이 높은 데이터 포인트 선택.
- 계산: 각 입력 샘플 x에 대해 클래스에 따라 엔트로피를 계산하여 정보 엔트로피 H(x)를 얻음.
- 해석: 높은 정보 엔트로피 H(x)는 모델이 여러 클래스에 대해 동등하게 불확실한 경우로 해석되며, 이는 샘플 x의 정보성이 높다는 것을 의미.
- 마진 기반 불확실성 (Margin-Based Uncertainty):
- 모델의 불확실성이 높은 경우를 계산하는 것.
- 계산: 최대 클래스 확률 y*와 두 번째로 높은 클래스 확률 y**을 비교하여 마진 M(x) 계산.
- 해석: 높은 마진 M(x)은 모델이 불확실한 경우를 나타내며, 이는 샘플 x의 정보성이 높다는 것을 의미.
대표성을 사용하는 쿼리 전략은 전체 훈련 데이터 풀을 대표하는 샘플을 선택하는 것입니다. 이는 서로 너무 유사한 샘플을 선택하고 싶지 않다는 것을 의미합니다.
유사성은 특성 공간에서 샘플 간의 거리로 측정할 수 있습니다. 여기에도 여러 옵션이 있으므로 그 중 두 가지를 살펴보겠습니다.
1. K-means Clustering
- 데이터를 k개의 클러스터로 그룹화하는 알고리즘
- 쿼리 전략: 각 클러스터에서 특정 수의 샘플을 선택하여 전체 데이터를 대표하는 샘플을 얻습니다.
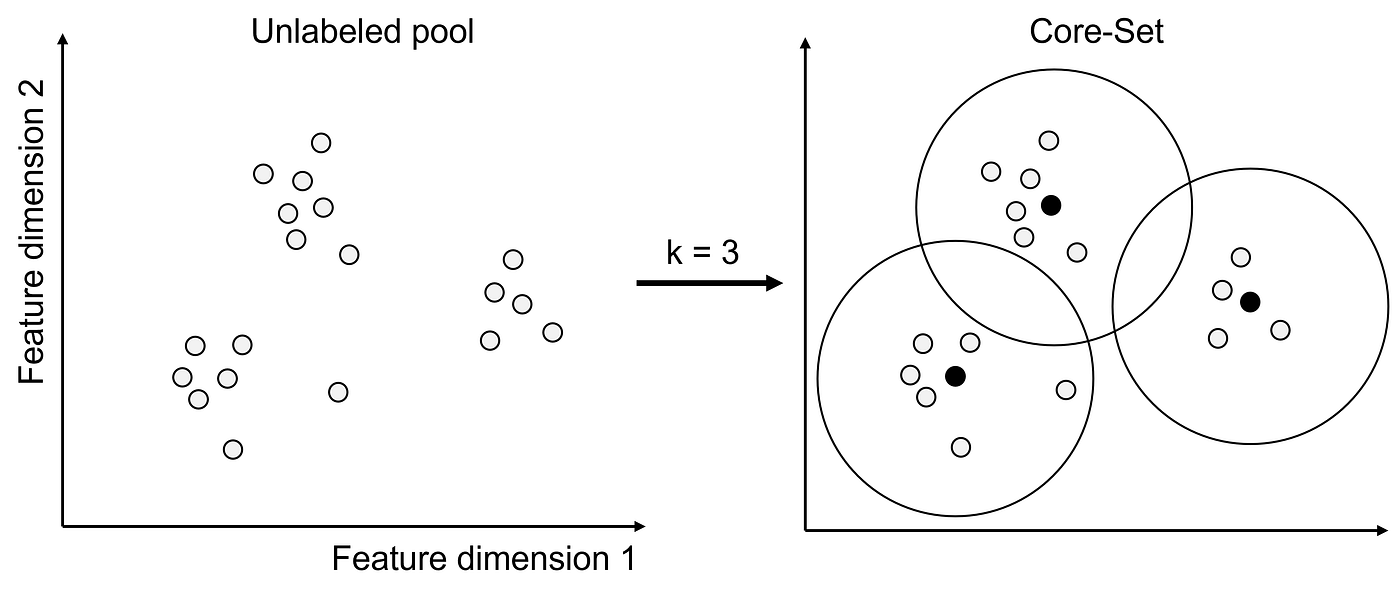
2. Core-Set Selection
- 전체 데이터 세트를 가장 잘 대표하는 핵심 샘플을 선택하려는 방법
- 쿼리 전략: Core-Set은 k-Center 문제를 기반으로 합니다. k-Center 알고리즘은 데이터 포인트와 그에 가장 가까운 중심 간의 최대 거리가 최소화되도록 k개의 중심을 선택합니다. 아래 그림에서 시각적으로 확인할 수 있습니다.
그리고 세 번째 쿼리 전략은 정보성과 대표성을 혼합합 하이브리드 쿼리 전략입니다. 이를 수행하는 방법은 다양합니다.
그 중에서 가장 직관적인 알고리즘 중 하나가 제가 이번에 리뷰할 “Diverse mini-batch Active Learning” (DBAL)입니다.
Hybrid (하이브리드):
- 정보성과 대표성을 조합하여 모델 성능을 향상시키기 위한 전략입니다.
- 예를 들어, DBAL 알고리즘은 불확실성에 기반하여 샘플을 걸러내고, 그런 다음 가중치 K-평균을 사용하여 클러스터링하고 클러스터에서 대표적인 샘플을 선택합니다.
2. Problem Setup

먼저 데이터의 다양성을 증가시키기 위한 목적함수는 식(1)번과 같습니다. 이는 k-means를 활용한 방법으로 절차는 아래와 같이 정리할 수 있습니다.
- 입력:
- 레이블되지 않은 데이터 집합 (XU)
- 클러스터링할 클러스터 수 (K)
2. K-means 클러스터링:
- XU의 데이터를 K개의 클러스터로 그룹화
- 클러스터링은 Euclidean 거리 측정을 사용하여 수행
- 알고리즘은 클러스터에 속한 각 데이터 포인트를 해당 클러스터의 중심으로 할당
3. 반복:
- 새로운 대표 데이터 포인트를 사용하여 클러스터링을 수행
- 이를 반복하여 수렴할 때까지 진행
위의 식은 정보성을 고려한 식으로 다시 변형이 될 수 있습니다. 변형된 식은 (3)과 같이 나타낼 수 있습니다.

위의 식에서 Si 는 i 번째 데이터의 정보량에 대한 것이고 Si 는 0과 1 사이의 값을 갖게됩니다. 정보성을 구하는 방법에는 다양한 방법들이 적용될 수 있는데 대표적으로 uncertainty sampling 이나 Mutual Information 기법이 사용됩니다. Zi,k 는 거리를 계산할 때, 데이터들을 해당 클러스터에 속하는 데이터의 거리만 계산할 수 있게끔 하는 [0,1] 두 개의 값을 가지는 값입니다.
3. Experimental
다음은 실험부분입니다. 저자는 다중 클래스 분류 문제에 대해 선형 모델, 다층 퍼셉트론, CNN 모델을 사용하여 평가하였습니다. . 정보성 측정에는 마진 기반 불확실성(margin-based uncertainty) 방법론을 사용하였습니다. 식은 아래와 같습니다.

여기서 Py(1,i)은 가장 확신 있는 클래스의 예측 확률이고, Py(2,i)는 두 번째로 확신 있는 클래스의 확률입니다. 이 불확실성 측정은 모든 실험에서 가장 성능이 좋았으며 엔트로피 기반 측정이나 least-confident measure과 같은 측정 방법들은 random selector보다 성능이 떨어졌습니다.
AL의 학습 과정 중 데이터를 선별하는 loop에서는 각 단계마다 모델 훈련을 위해 k개의 예제를 선택합니다. CIFAR-10를 제외한 모든 데이터셋에 대해 k = 100을 사용했으며, CIFAR-10에 대해서는 k = 1000을 사용합니다. 하지만 공정한 비교를 위해 모든 unlabeled 데이터를 클러스터링하는게 아니라 먼저 βk개의 가장 정보성이 데이터만 클러스터링합니다. β의 선택이 어느 정도의 범위 내에서는 결과에 큰 영향을 미치지 않지만 데이터셋과 배치 크기(k)에 대해서는 β의 크기가 달라져야 한다고 합니다. 예를 들어 데이터셋이 k와 비교했을때 매우 큰 경우 β값을 키워야하고 데이터셋이 k와 비교했을때 작은 경우 작은 β값을 선택해야 더 나은 결과로 이어진다고 합니다.
또한 β의 선택과 독립적인 방법을 탐색하기 위해 클러스터에서 데이터를 선택하는 방법을 다양하게 시도합니다.
각 클러스터에서 클러스터 중심에 가장 가까운 예제를 선택하는 대신, 각 클러스터에서 가장 정보성이 높은 예제를 선택하는 방법을 사용했습니다. 이 방법은 가중 클러스터링을 수행하는 것과 유사한 결과를 나타내어 클러스터링이 가중되지 않았을 때에도 같은 결과가 나타났다는 것을 의미합니다. 또 다른 시도한 방법은 클러스터 중심에 가장 가까운 것이 아니라 각 클러스터에 대해 유사성 점수와 정보성 합이 가장 큰 k개의 예제를 선택하는 것입니다. 유사성의 경우 1 – ˜d(xi, xc)로 표현이 되며 ˜d는 클러스터 중심까지의 거리이고 이는 0-1로 정규화되었습니다.
하지만 이 방법의 결과는 다른 방법보다 나쁘게 나타났다고 하는데 이는 전체 데이터셋을 사용하여 클러스터링하는게 아닌 βk만 사용하여 클러스터링을 진행하기 때문인 것 같습니다.
4. Results
4.1 Browse Node UK Appliances
이 데이터셋은 2015년에 Amazon UK 마켓에서 판매된 9천 개 제품의 제품 제목 및 설명을 포함하고 있습니다. 총 24개 범주의 제품이 있으며, 제품 범주별로 클래스가 불균형하게 분포되어 있습니다. 데이터셋을 무작위로 훈련 세트와 테스트 세트로 분할하고 70/30의 비율을 사용했습니다. 매개변수 값인 β = 10에 대해 다양성 기반 방법은 서로 유사한 성능을 보이며 baseline 우수한 결과를 보입니다. 그러나 성능이 비슷하더라도 Clustered 방법은 Submodular 기반 방법보다 빠르게 학습되는 모습을 보였습니다.(FASS(10)은 약 4700초, Clustered(10)은 단 10초에 완료되었습니다).

4.2 20 Newsgroups
20 Newsgroups 데이터셋은 20개의 다른 뉴스 그룹으로부터 수집된 기사를 포함하며, 각 기사를 해당 뉴스 그룹으로 분류하는 것이 목표입니다. Figure 2의 결과에 따르면 다양성을 고려한 쿼리 전략 방법들이 불확실성 샘플링에 비해 더 나은 성능을 보이는 것을 확인할 수 있습니다.

4.3 MNIST
Figure 3에서는 다양성을 고려한 다양한 방법들이 불확실성 샘플링 방법보다 우수한 성능을 보이는 것을 확인할 수 있습니다.
특히, pre-filtering의 값으로 β = 50을 사용한 Weighted Clustering 방법 및 unweighted Clustering 방법이 pre-filtering의 값으로 β = 10을 사용한 다양성 기반 방법보다 더 높은 성능을 보여주었습니다. 또한 제안된 방법은 Submodular과 비교했을 때 동등하거나 더 나은 성능을 보여주었습니다.

4.4 CIFAR-10
CIFAR-10 데이터셋에서는 단순한 모델로는 효과적인 학습이 어렵다고 판단하여 ResNet을 사용했습니다.
Fig5의 결과를 보시면 다양성 기반 선택이 불확실성 샘플링의 기준을 약간 능가하는 결과를 보여주고 있습니다. 또한, Weighted Clustering 방법이 unweighted Clustering보다 우수한 성능을 보여주고 있습니다.
종합하면, CIFAR-10 데이터셋에서는 ResNet과 같은 복잡한 모델과 데이터 특징 추출을 통해 다양성 기반 활동 학습이 효과적으로 작동함을 보여주고 있습니다

정의철 연구원님, 좋은 리뷰 감사합니다. 리뷰에서 Diverse mini-batch Active Learning(DBAL)는 불확실성에 기반해 샘플을 걸러내고, K-means를 이용해 클러스터링해서 대표적인 샘플을 선택하는 hybrid method라고 말씀해 주셨습니다. (1)번 수식이 k-means를 활용한 diversity 방법이고, (3)번이 uncertainty를 이용한 식 같은데, 주어진 설명만으로는 이해가 힘드네요. 단순히 margin sampling을 적용한 후 다시 clustering을 통해 데이터를 추리는 것인가요? margin sampling을 어떻게 이용한 다음 클러스터링을 진행하는건지 더 자세히 설명 부탁드립니다.
여담으로, 일반적으로 DBAL이라고 하면 Deep Bayesian Active Learning방법을 지칭하는 것으로 아는데, 여기서도 DBAL이라고 하는 것이 흥미롭네요.
감사합니다.
안녕하세요 재연님 질문 감사합니다.
margin sampling은 데이터의 uncertainty를 측정하기 위해 사용이됩니다. 즉 마진 기반 불확실성(margin-based uncertainty) 방법은 정보성 측정에 사용이 됩니다. 식(3)을 보시면 Si가 곱해져있는 것을 확인할 수 있는데 이는 i 번째 데이터의 정보량에 대한 것입니다. 마진 기반 불확실성(margin-based uncertainty) 을 사용하면가장 확신 있는 클래스의 예측 확률과 두 번째로 확신 있는 클래스의 확률의 차이가 작을수록 불확실한 데이터임을 의미하므로 이를 반영하여 수식(3)이 도출됨을 확인할 수 있습니다.
감사합니다.
안녕하세요 의철님 좋은 리뷰 감사합니다.
실험부분에서 정보성 측성에는 마진 기반 불확실성 방법론을 설명해주시며 가장 확신 있는 클래스의 예측 확률과 두번째로 확신 있는 클래스의 예측 확률의 차이를 총해 마진을 구한다고 언급해주셨는데 마진을 크게하여 모델의 불확실성을 줄이는 방법인가요? 마진을 측정하면 다른 방법론에 비해 어떤 점이 좋은 지가 궁금합니다.
안녕하세요 성준님 질문 감사합니다.
마진 기반 불확실성(margin-based uncertainty)의 방법론은 모델이 가장 확신 있는 클래스의 예측 확률과 두 번째로 확신 있는 클래스의 확률의 차이로 구하게 됩니다. 만약 모델이 어떤 데이터 x에 대해 확신이 없는 예측을 하게된다면 첫 번째 예측 확률과 두 번째 예측 확률의 차이가 작을 것입니다. 반대로 모델이 데이터 x에 대해 확신 한다면 첫 번째 예측 확률과 두 번째 예측 확률의 차이 클것입니다. 따라서 마진 기반 불확실성은 마진을 이용하여 불확실한 데이터를 선별하는 방법론이라고 이해하시면 될 것 같습니다.
감사합니다.