안녕하세요. 오늘은 moment retrieval (video temporal grounding) task를 다룬 논문입니다. 바로 리뷰 시작하겠습니다.
이 논문은 untrimmed video(편집되지 않은 영상)에서 자연어 쿼리를 통해 temporal segments를 retrieving하는 태스크(Moment Retrieval)를 다룹니다. 이 태스크는 자연어의 뉘앙스와 비디오 콘텐츠에 대한 이해를 필요로 합니다. 예시로 밑의 Figure 1에서 두 자연어 쿼리는 같은 물체에 대해 얘기하고 있지만, 동사로 인해 큰 차이가 생기고, 영상 프레임의 temporal ordering 또한 중요한 단서로 주어집니다.

현존하는 cross-modal retrieving 방법론은 다른 modalities를 같은 임베딩 공간에 투영하는 임베딩 함수를 통해 학습합니다. 가장 많이 사용되던 방법은 유클리드 거리를 이용하는 standard similarity metric이지만, 영상 클립과 자연어 전체를 사용하는 해당 방법은 fine-grained에서 적합하지 못합니다. 또한 임베딩은 일반적으로 서로 독립적이기 때문에 한 모달리티의 입력을 사용해서 다른 모달리티의 처리를 조정하는 것은 거의 불가능합니다. 두 모달리티의 정보를 더 잘 처리하기 위해 저자는 multilevel 접근 방식을 제안합니다.
첫번째 레벨에서 저자는 temporal segment proposal 단계에서 자연어 특징을 주입합니다. 구체적으로는 입력 쿼리의 인코딩과 유사성을 기준으로 temporal segments에 가중치를 다시 부여합니다. 이를 통해 모델은 쿼리와 더 관련이 있는 클립을 선정할 수 있습니다. 비디오 특징 가중치는 쿼리 세트에 풀링할 수 있으면, 이는 단일 영상에서 여러 쿼리가 들어왔을 때의 계산 비용을 줄여줍니다.
두번째 레벨은 쿼리와 클립의 유사성을 계산할 때를 다룹니다. LSTM 모델을 활용하여 후보 클립의 시각적 특징 임베딩을 조건으로 쿼리 문장을 단어별로 처리하고 비선형 유사성 점수를 생성합니다. 이는 기존의 vector 임베딩과는 달리 vision과 language의 early fusion으로 볼 수 있습니다. 또한 쿼리의 단어별로 비디오 특징과의 유사성을 구할 수 있습니다. 또한, multi-task loss를 구함으로써 두 모달리티의 공유된 representation을 학습하는 것으로 retireval의 성능을 올릴 수 있습니다.
저자가 제안하는 모델은 기존 연구와 다른 점이 크게 두 가지가 있습니다. 첫번째는 기존의 쿼리를 신경쓰지 않는 sliding window 혹은 hand-crafted 경험적 방법과는 달리 쿼리에 기반한 temporal segments를 propose합니다. 저자는 R-C3D를 일반화하여 query-specific proposals를 생성합니다. 두번째는 문장 임베딩을 얻기 위해 RNN의 hidden state를 pooling하는 벡터 임베딩 접근 방식을 개선합니다. 기존의 시각적 정보를 고려하지 않던 방식과 달리 문장 임베딩을 하는 과정에서 시각적 특징을 고려합니다.
저자는 contribution을 3가지로 요약합니다.
- 쿼리 임베딩을 segment proposal network포함시켜 query-guided proposals를 생성합니다.
- early fusion 방식을 채용하며 LSTM을 학습해 쿼리와 비디오 클립 간의 fine-grained 유사성을 모델링합니다.
- shared feature representations를 더 잘 학습하기 위해 추가적인 태스크로 captioning을 다룹니다.
Approach
저자의 핵심 아이디어는 early fusion, query-specific proposals, caption을 재생성하는 multi-task formulation를 사용하여 language와 vision을 서로를 matching하기 전에 통합하는 것입니다.
먼저, 저자가 해결하려는 태스크를 정의하면 untrimmed video(가공되지 않은 영상;real world video)를 V, 자연어 쿼리를 S라고 할때, 태스크의 목표는 S에 가장 매칭되는 temporal segment(clip) R을 반환하는 것입니다.
Query-Guided Segment Proposal Network
handcrafted 경험적 방법, sliding window 방법을 사용하는 대신 저자는 learned segment proposal network(SPN)을 사용합니다. SPN은 먼저, C3D를 사용하여 모든 프레임들을 인코딩합니다. 그런 다음, 미리 정의된 앵커 세그먼트들의 세트에 대한 상대적 오프셋을 예측함으로써 가변-길이 세그먼트 제안들이 얻어집니다. 제안 특징들은 3D 관심 영역 풀링(Region of Interest Pooling)에 의해 생성됩니다.
SPN은 R-C3D에서 처음 사용되었습니다. 저자는 R-C3D의 SPN은 모든 관심 있는 구간을 제안하지만, text-to-clip에서는 특정 쿼리가 주어지기 때문에 모든 관심 있는 구간이 아닌 쿼리와 관련이 있는 구간만 필요로합니다. 따라서 저자는 query-guided SPN을 제안합니다. 쿼리의 feature representation을 사용하여 SPN을 조정하고 관련 시각 영역에 집중하는 방법입니다.
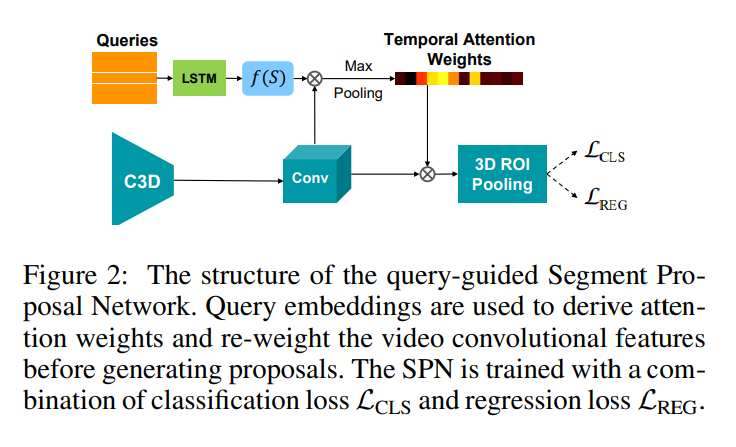
Figure 2는 query-guided SPN의 구조를 보여주는 그림입니다. 모든 쿼리 S는 sentence embedding LSTM의 hidden state를 풀링하는 것으로 feature vector f(S)에 임베딩됩니다.
Early Fusion Retrieval Model
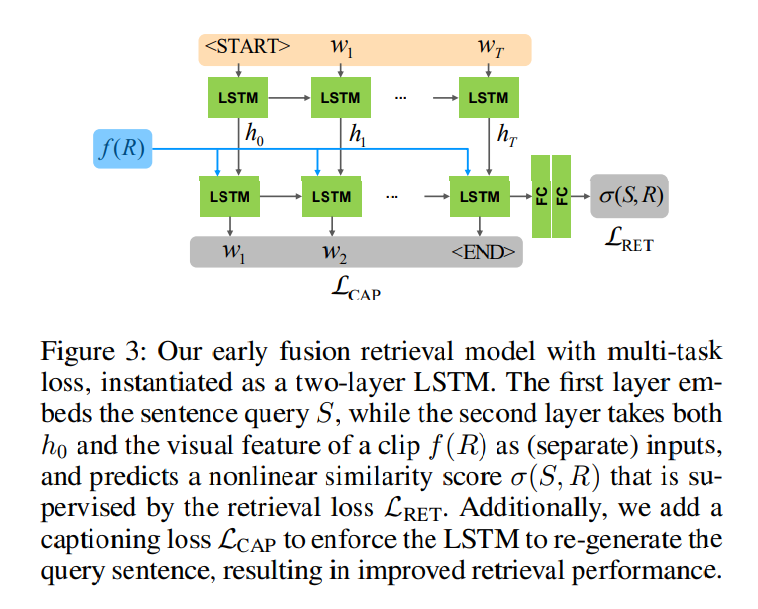
인풋으로 영상 클립의 풀링된 C3D의 특징과 쿼리 문장을 받아 첫 계측에서 LSTM을 통해 문장의 단어를 처리하고 두번째 계층에서는 문장의 임베딩을 시각적 특징 임베딩과 결합합니다. hidden state는 유사성 점수를 예측하기 위해 사용됩니다. early fusion으로 시각적 특징과 언어적 특징을 초기 단계에 함께 처리합니다. 이러한 early fusion 구조는 문장의 각 단어가 시각적 특징과 상호 작용하기에 잠재적으로 다른 연관성을 학습할 수 있습니다. 또한 retieval을 위한 더욱 효과적인 유사성 metric을 학습할 수 있습니다. 시작적 특징을 위한 모델로 C3D가 아닌 다른 모델을 사용해도 괜찮으며 LSTM 또한 다른 RNN 모델로 대체가 가능합니다.
Multi-Task Loss
모델을 정의한 후에 저자는 다른 작업에서도 이득을 얻을 수 있도록 손실함수를 설계했습니다. 그래서 손실함수에 캡셔닝 손실함수를 추가하는데 이는 비디오 클립에서 얻은 문장을 재생성할 수 있는 검증 단계로 적용할 수 있습니다.
그림 3과 같이 LSTM의 두 번째 레이어는 인풋 쿼리 문장을 재생성하도록 요구합니다. 이때 시각적 특성 f(R)에 조건을 둬, 단어 w_t를 생성할때, 이전 단계에서의 hidden state를 사용합니다. 저자는 표준화된 log likelihood의 합이 최대화되는 문장 캡셔님 손실을 사용합니다.
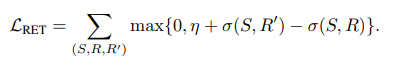
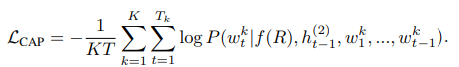
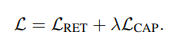
Implementation
저자는 교차검증을 통해 λ를 0,5로 설정했습니다. 마진 매개변수 η는 0.2로 설정되고 학습 미니배치는 32개의 일치하는 문장-클립 쌍을 포함합니다. Adam optimizer를 사용했고, learning rate는 0.001로 설정되며, validation 셋에서 조기 정지를 적용하여 총 30 에포크 동안 훈련합니다.
단어 임베딩(LSTM의 첫 번째 레이어)을 위해 저자는 300차원의 GloVe 벡터를 사용합니다. 모든 데이터셋에서 사전 훈련된 단어 임베딩은 300차원이며 LSTM의 hidden state 크기는 512로 설정됩니다. 공통 임베딩 공간의 크기는 후기 융합 검색 모델에서 1024입니다.
문장-클립 쌍의 유사성 점수는 LSTM의 두 번째 레이어가 생성하는데 이는 마지막 단어에 해당하는 상태를 이용하고, 두 개의 완전 연결(Fully-connected) 계층를 통과시킨 후 시그모이드 활성화 함수를 이용해 스칼라 값 a를 생성합니다. 두 FC 레이어는 차원 수를 512에서 64로, 그리고 1로 줄입니다.
Experiments
text-to-clip을 위한 데이터셋인 Charades-STA와 ActivityNet Captions를 사용했으며, 비교를 위해 세가지 버전의 모델과 두가지 baseline을 설정했습니다.
- Random: 후보 클립 중에서 무작위로 설정하는 baseline
- VE: 쿼리 문장과 비디오 클립을 벡터로 별도로 임베딩하는 방식
- LSTM: LSTM을 사용하여 유사성을 예측하는 early fusion 모델
- LSTM+QSPN: LSTM이 포함된 query-guided segment proposal network
- LSTM+QSPN+Caps: Captioning이 포함된 전체 모델
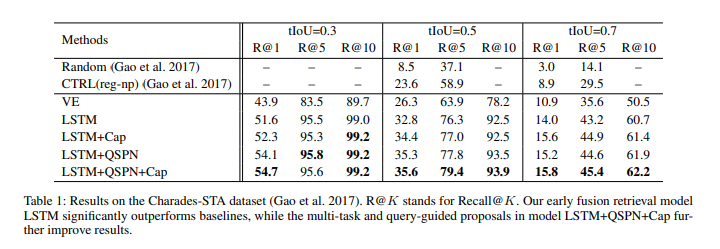

Charades 데이터셋은 자연어 쿼리를 통한 비디오 내 특정 이벤트의 시간적 위치를 평가하기 위해 제안된 데이터셋입니다. 학습용으로 라벨링된 12408개의 문장,클립 쌍과 7318개의 테스트용 쌍으로 구성되어 있습니다.
표 1의 구성은 Charades-STA 데이터셋에서의 결과를 보여주고 있습니다. VE이 CTRL 모델을 앞서는 결과를 보여주었고 그에 대한 2개의 의견을 제시합니다. 하나는 R-C3D 모델에서의 segment proposal이 더 정밀한 결과를 보여주며 두번째로는 CTRL에서 사용하는 binary classification loss보다 triplet-based loss가 더 좋은 손실함수이기 때문입니다. LSTM모델은 VE보다도 좋은 모습을 보여줍니다. 이는 VE는 ‘문을 여는’, ‘문을 다는’과 같은 문장을 헷갈려하지만 LSTM과 LSTM+QSPN+Caps 모델은 이 두가지 행동을 구분할 수 있다고 설명합니다.
ActivityNet Captions는 밀집 비디오 캡셔닝 작업을 위해 제안되었습니다. 시간적 세그먼트 주석과 쌍을 이루는 캡션들이 포함되어 있고 text-to-clip 에도 사용될 수 있습니다. 여기서의 Caption 문장들은 각 비디오에 대한 입력 쿼리 문장으로 사용됩니다. 20k개의 비디오가 포함되어있으며 저자는 이를 50/25/25의 비율로 학습/검증/테스트 셋으로 분류했습니다. 검증 셋을 테스트로 진행했고, 테스트 셋은 캡션을 위해 사용했다고 밝힙니다.

위 사진은 각각 Charades-STA 데이터셋과 ActivityNet Captions 데이터셋에 대한 정성적 결과를 보여줍니다.
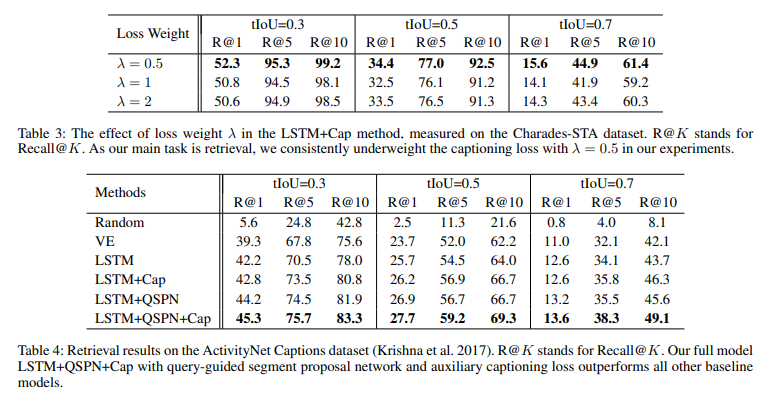
표 3은 λ값 설정을 위한 ablation study 결과를 보여주며 0.5에서 제일 좋은 성능을 보여줍니다. 표 4는 ActicityNet Captions에서의 성능을 보여줍니다. Charades-STA 데이터셋에서의 결과와 비슷한 결과를 보여줍니다.
Conclusion
저자는 기존의 클립과 텍스트를 따로 임베딩 한 후에 유사성을 구하는 것이 아닌 early fusion을 이용하고 LSTM의 두 계층을 활용하여 문장 쿼리와 비디오 클립 간의 유사성 점수를 직접 예측함으로 성능 개선을 이뤄냈습니다.
early fusion 방식을 활용하여 문장 내에 있는 단어의 이미와 클립의 시작적 특징에 직접 결합하는 방식이 효과를 보인 것이 인상적이네요. 오디오와 같은 다른 모달리티가 추가되었을때에도 활용할 수 있을지도 궁금해지는 방법론입니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다~
본문의 Multi-Task Loss 부분에서 질문이 있습니다.L(RET)의 수식에서 S, R , R’이 나와있던데 여기서 R’는 무엇을 의미하는 것인가요?? L(RET)의 수식이 σ(S, R’)을 포함시켰을 때 무엇을 MAX하려는 것인지 설명해주시면 감사하겠습니다!
안녕하세요 의철님 좋은 답변 감사합니다.
R은 untrimmed video를 V, 자연어 쿼리를 S라고 할때, S에 가장 매칭되는 temporal segment(clip)을 뜻하고 R’은 S에 매칭되지 않는 negative clip을 뜻합니다. max함수는 마진 η을 설정하여 positive clip와 negative clip의 차가 마진보다 큰 경우 0으로 나타내는 것으로 올바른 예측을 했다고 여기는 것을 뜻합니다. 반대로 positive clip과 negative clip의 차가 마진보다 작은 경우 학습을 통해 둘을 구분할 수 있도록 학습합니다. 수식에 대한 설명이 부족하여 이해가 어려우셨을 것 같네요. 수식과 포함되는 인자들에 대한 설명도 자세하게 하겠습니다.
감사합니다.
안녀하세요. 좋은 리뷰 감사합니다.
리뷰를 읽고 이 방법론은 LSTM을 학습해 쿼리와 비디오 클립 간의 fine-grained 유사성을 모델링하고 캡셔닝을 통해서 더욱 성능 향상을 이루었다고 이해하였습니다.
여기서 궁금한것이 어떻게 captioning을 추가하는 것이 성능 향상에 도움이 되는 것인가요? 추가적인 text 데이터를 주입하기 때문인가요? 그렇다면 만약에 captioning 성능이 좋지 않다면 오히려 비디오에 도움이 되지 않는 text를 생성하기 때문에 모델이 헷갈려해서 성능 하락으로 이뤄질 것 같은데 논문에 저자들은 이를 어떻게 해결하였나요?
감사합니다.
안녕하세요 주연님 좋은 답변 감사합니다.
저자는 related work에서 최근 연구에서 captioning 또한 retireval task로 해결할 수 있으며 이에 영감을 받아 구상했다고 언급했습니다. captioning의 경우 비디오의 한 장면을 text로 설명하는 task로 비디오와 자연어의 연관성을 학습합니다. 저자는 쿼리를 통해 얻은 구간에 대해 captioning을 진행해 captioning의 결과를 자연어 쿼리와 비교하는 것으로 모델의 결과를 검증하는 단계로 추가했습니다. 저는 손실함수에 captioning loss를 추가하는 것으로 모델이 결과를 검증하는 것이 성능 향상에 도움이 된 것이라 이해했습니다. captioning 성능이 좋지 않을때 성능하락으로 이뤄지는 것에 대해서는 논문에 언급이 되어있아 확실하게는 모르겠습니다만, 제 생각으로는 related work에서 언급된 것처럼 captioning과 retrieval의 관계가 비슷하여 captioning의 성능이 떨어져 성능하락으로 이뤄지는 일은 없을 것이라 생각됩니다.
감사합니다.
안녕하세요. 박성준 연구원님.
캡셔닝 task를 함께 수행하여 학습에 더 이득을 보고자 한 부분이 흥미롭네요.
표2의 우측에 유사도맵 비교도 눈에 띄는데, 이 그림에 대해 조금 더 설명해주실 수 있을까요?
감사합니다.
안녕하세요 지오님
표 2 우측의 유사도맵은 N개의 인풋 쿼리와 N개의 GT 세그먼트의 유사성점수를 나타내는 confusion matrix를 시각화한 그림으로 이상적인 상황은 Expected와 같은 대각선 형태의 이미지가 나오는 것입니다. 저자는 LSTM과 VE를 비교하며 VE의 경우에는 문이 열리고 닫히는 것과 같은 반대의 액션도 헷갈려하는 모습을 보인다는 점을 지적하며 LSTM을 사용한 이유를 강조하고 있고, 추가로 캡셔닝을 넣음으로 오차를 줄이는 것을 보여줍니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다!
모델이 학습한 표현이 의미 기반 매칭인지, 아니면 표현적 유사성(style similarity) 기반인지에 대해서 궁금합니다.
예를 들어 training set에서 “the man opens the door”라는 표현이 자주 등장하면, 비슷한 영상에서 “the person enters the room”이라고 해도 비슷하게 매칭할지 궁금합니다.
단어 선택이나 문장 구조는 다르지만 의미는 유사한 쿼리에 대해서도 높은 matching score를 유지할 수 있는지에 대한 의문점이 들어 답글 남깁니다!
query-guided segment proposal network에 대한 내용(쿼리 내용을 반영해 의미적으로 관련 있는 구간만 제안)을 보았을 때는 저자는 의미를 기반으로 한 구간 탐색을 하는 것 처럼 이해를 하였는데,
실험 부분에서 이 모델이 의미 기반인지 단순히 유사성 기반 인지를 나타내는지를 뒷받침하는 실험이 있는지 궁금합니다!
감사합니다.