안녕하세요. 오늘 제가 소개할 논문은 ICCV 2017에 개재된 Localizing Moments in Video with Natural Language입니다. 비디오 태스크 중 하나인 Moment Retrieval을 최초로 다룬 논문입니다. Moment Retrieval이 어떤 태스크인지, 이 논문이 이 태스크를 어떻게 해결했는지 리뷰하겠습니다.
Introduction

Moment Retrieval 즉, 텍스트 쿼리 기반 비디오 구간 검색은 Figure 1의 예시와 같이 “The little girl jumps back up after falling(작은 소녀가 넘어지고 나서 일어납니다)”과 같은 구체적인 행동, 혹은 상태를 나타내는 텍스트 쿼리가 주어졌을 때에 비디오에서 쿼리에 해당하는 구간을 찾는 태스크입니다. 구체적으로는, 비디오와 텍스트 설명이 주어졌을 때, 주어진 텍스트 설명에 해당하는 비디오 내의 시작점과 끝점을 식별합니다. 이는 언어와 비디오 이해를 모두 요구하는 도전적인 과제입니다.
기존의 자연어 기반 비디오 검색 방법들은 텍스트 문자열이 주어지면 전체 비디오를 검색(Action Classification)하지만 비디오 내에서 특정 순간이 언제 발생하는 지를 식별(Moment Retrieval)하지 않습니다. 저자는 비디오 내의 순간을 localizing하기 위해, 저자는 referring expressions과 해당 순간의 비디오 특징이 공유 임베딩 공간에서 가까워지는 합동 비디오-언어 모델을 학습하자고 제안합니다. 전체 비디오 검색과는 대조적으로 특정 순간의 비디오 특징뿐만 아니라 전체 비디오 컨텍스트와 긴 비디오 내에서 텍스트 쿼리에 해당하는 순간이 언제 발생하는 지를 아는 것이 순간 검색을 위한 중요한 단서입니다. 예를 들어, “무대 위의 남자가 관객에게 가장 가까워진다”는 텍스트 쿼리를 고려해 보세요. “가장 가까운”이라는 용어는 상대적이며 제대로 이해하기 위해서는 temporal context가 필요합니다. 추가로, 긴 비디오 내에서 순간의 시간적 위치는 그 순간을 localizing하는 데 도움이 될 수 있습니다. “자전거 타는 사람이 경주를 시작한다”는 텍스트 쿼리에 대해, 우리는 비디오의 끝 부분에서의 순간들보다 자전거 타는 사람이 경주하는 비디오 초반의 순간들이 텍스트 쿼리에 더 가까울 것으로 예상합니다. 따라서 우리는 temporal context를 제공하는 글로벌 비디오 특징과 비디오 내에서 순간이 발생하는 시점을 나타내는 시간적 endpoint 특징을 포함하는 Moment Context Network (MCN)을 제안합니다.
모델을 훈련시키는 주요 장애물 중 하나는 현재 비디오-언어 데이터셋이 특정 순간을 고유하게 지역화할 수 있는 자연어를 포함하지 않는다는 것입니다. 또한 기존의 데이터들은 짧은 클립 기반의 액션을 포함하는 영상인 반면 Moment Retrieval이 실제로 필요한 데이터는 긴 텍스트 쿼리에 해당하지 않는 영상들을 포함하고 있다는 것이 Moment Retrieval 태스크를 힘들게 만듭니다. Untrimmed Video(배경을 포함하는 가공되어지지 않은 영상)는 일반적으로 가공된 비디오(Trimmed Video)에서 포함되지 않는 배경을 포함하기 때문입니다. 따라서, 원활한 학습을 위해서는 편집되지 않은 비디오 촬영물에서 독특한 순간들과 각 순간을 고유하게 localizing할 수 있는 설명이 짝을 이룬 데이터셋이 필요하게 됩니다.
따라서, 저자는 local과 global한 비디오 특징을 모두 활용하는 Moment Context Network (MCN)를 제안하며 동시에 40,000개 이상의 referring descriptions와 편집되지 않은 비디오 내 localized된 순간의 쌍으로 구성된 Distinct Describable Moments (DiDeMo) 데이터셋을 제공합니다.
Moment Context Network (MCN)
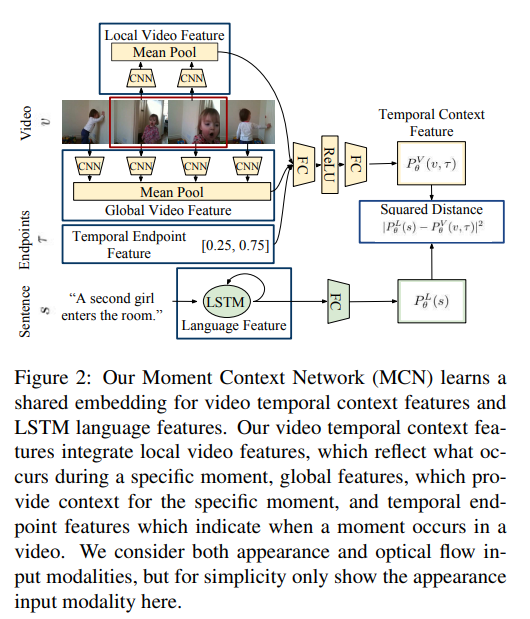
비디오 프레임들은 시작점t와 끝점t가 주어질때, local features와 global temporal context를 추출할 수 있고, language features는 LSTM 네트워크를 통해 추출할 수 있습니다. test때에는 다음의 수식을 통해 최적화됩니다.
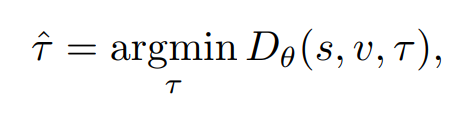
여기서 Dθ는 주어진 모델 매개변수 θ로 문장 s, 비디오 v, 그리고 시간 간격 τ에 대한 합동 모델입니다.
Video Temporal Context Features
비디오 순간들을 local features와 global video features을 통합하여 visual temporal context features로 인코딩합니다. 비디오 특징을 추출하기 위해 각 비디오 프레임에 대해 깊은 cnn을 사용하여 high level 비디오 특징들을 추출한 다음, 비디오 프레임을 average pooling을 통해 특정 시간 범위에 걸쳐 비디오 특징을 평균화합니다. local features는 비디오 프레임의 average pooling에 의해 구성되고 global features는 비디오의 모든 프레임을 average하여 구성됩니다.
Language Features
LSTM을 사용하여 언어 데이터의 특징을 추출하고, 이를 비디오 데이터와 결합합니다. 저자가 제안하는 DiDeMo 데이터셋은 40000개의 분장을 포함하고 있지만, 아직 작은 데이터셋이라 설명합니다. 그리고 이러한 작은 데이터셋을 사용할 때에도 Glove라는 단어 임베딩 방식이 원-핫 인코딩보다 더 좋은 결과를 보인다고 설명합니다. MCN은 언어와 비디오 데이터의 특징을 결합하여 embedded appearance, flow와 language features의 거리차이를 제곱하여 계산하는 공식을 사용합니다.
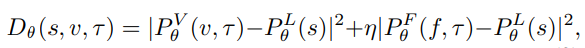
여기서의 η는 ‘late fusion’의 매개변수로 ablation study에 의해 2.33로 설정했습니다.
Loss
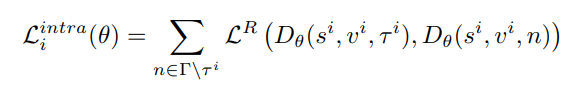
위 수식에서 LR은 max(0, x – y + b) 형태의 ranking loss로 구성되어 있으며, 여기서 타우는 모든 가능한 시간 간격 비디오 인터벌을 나타내고, b는 마진입니다. 이 손실 함수는 직관적으로 텍스트 쿼리가 비디오 내의 가능한 다른 모든 시간 간격보다 더 가까운 시간 간격에 대응되도록 장려합니다. 타우가 여러 인터벌을 나타내므로 anchor기반의 방법론이라고도 생각할 수 있겠네요.
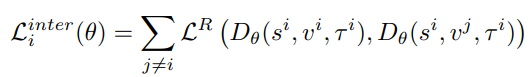
위 수식은 서로 다른 비디오 간의 거리를 기반으로 합니다. 이 손실은 텍스트 쿼리가 비디오 내의 해당 순간들에 더 가까워지도록 유도하고 비디오 외부의 순간들과 구별하도록 학습해야 하므로, broad semantic concepts를 구분하도록 합니다.
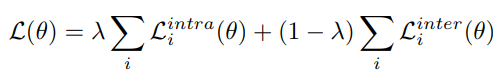
최종 inter-intra video ranking loss는 위와 같습니다. λ는 cross-validation을 통해 선정했다고 합니다. 구체적으로 몇으로 설정했는지는 여기에서 설명하지는 않네요
The DiDeMo Datast
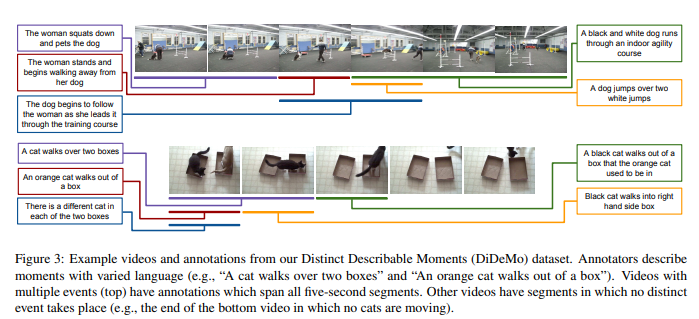
저자는 각 설명이 단일하고 독특한 순간과 짝을 이루도록 하기 위해 두 단계에 걸쳐 데이터셋을 수집했습니다. 먼저, annotators에게 비디오를 보고 순간을 선택하고 다른 사용자가 설명만 보고 같은 순간을 선택할 수 있도록 그 순간을 묘사하도록 요청했습니다. 그 후 첫 번째 단계에서 수집된 설명은 annotators가 비디오를 보고 수집된 설명에 해당하는 순간들을 표시하도록 요청함으로써 데이터셋을 수집했습니다.
영상을 선정하는 과정은 다음과 같습니다. YFCC100M에서 임의로 14,000개 이상의 비디오를 선택합니다. 선택한 비디오가 편집되지 않았다는 것을 보장하기 위해 각 비디오를 인접 프레임 간의 색상 히스토그램의 차이에 기반한 샷 감지기를 통해 검증한 후에 비디오를 수동으로 필터링합니다. DiDeMo에 있는 비디오는 real world 비디오의 다양한 집합을 대표하는데 독특한 순간들 뿐만 아니라 편집된 비디오에서 제외될 수 있는 배경들도 포함합니다.
위의 Figure 3에서 예시를 통해 보여주고 있으며, 편집되지 않은 비디오에 여러 텍스트와 텍스트에 해당하는 부분이 데이터셋에 포함되어있습니다.
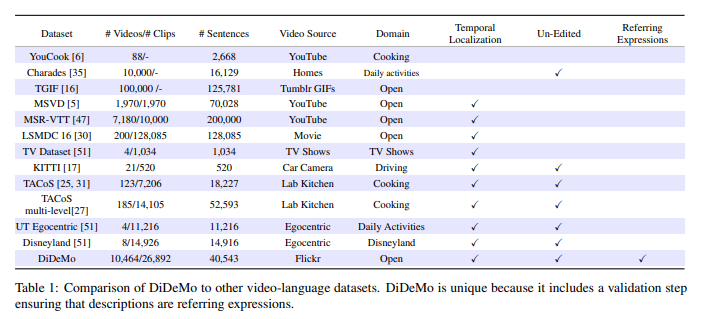
Table 1에서는 DiDeMo 데이터셋이 다른 데이터셋과 비교하여 DiDeMo 데이터셋이 Moment Retrieval에 적합하다는 것을 보여주고 있습니다.
Experiments
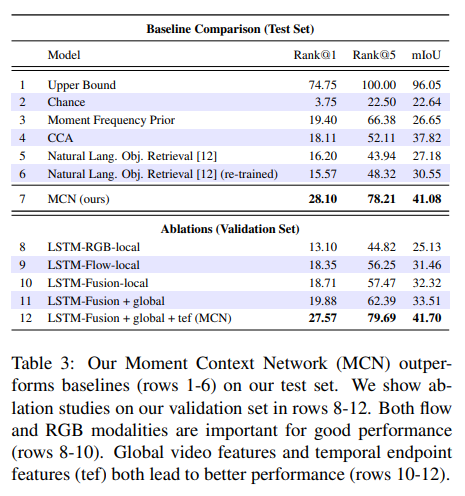
Moment Retireval의 평가 지표로 Rank@1은 모델이 검색하고자 하는 대상 순간을 첫 번째로 정확히 검색해낸 비율을 의미합니다. 예를 들어, Rank@1이 30라면 30%로 모델이 가장 관련성 높은 순간을 첫 번째 순위로 찾았다는 것을 의미합니다. Rank@5는 상위 5개 중에서 하나라도 정확한 순간을 포함하는 지를 나타내는 지표로 Rank@5가 80이라면 80%로 모델이 관련성 높은 순간을 상위 5개 결과 안에 성공적으로 찾았다는 것을 의미합니다. mIoU는 각 클래스별 IoU값의 평균으로 예측 boundaries가 얼마나 정확한 지를 나타내는 지표로 볼 수 있습니다.
표 3에서 Moment Context Network(MCN) 모델을 저자가 설정한 baseline 모델들과 비교합니다. 사실 Moment Retrieval에 대해 처음 소개하는 논문인 만큼 다른 baseline들에 비해 월등히 좋은 성능을 보여줍니다만 다른 baseline에 대한 이해가 부족하여 정확하게 이해하지는 못했습니다. 아무래도 다른 baseline과 달리 비디오의 특징과 자연어를 통합하여 학습하고 활용하는 MCN의 성능이 다른 baseline들에 비해 성능이 좋은 것은 당연하다고도 생각됩니다.

Figure 4 는 실제 DiDeMo 데이터셋의 GT와 MCN의 예측을 정성적으로 비교한 것으로 실제로도 덱스트 쿼리에 해당하는 순간을 잘 찾아내는 것을 볼 수 있습니다.
Conclusion
저자는 real world 비디오에서 비디오 내의 순간들을 자연어로 localizing하는 태스크:Moment Retrieval을 소개합니다. 저자가 제안하는 Moment Context Network(MCN)는 local, global video features 및 temporal endpoint features를 활용하여 비디오 순간들을 포착합니다. 평가를 위해 40,000쌍 이상의 localizing된 순간들과 관련 표현들로 구성된 DiDeMo를 제안했습니다. MCN은 많은 자연어 쿼리를 비디오에서 적절히 지역화하지만, 여전히 많은 도전과제들이 남아있습니다. 예를 들어, 복잡한 (시간적) 문장 구조를 모델링하는 것은 여전히 매우 도전적이라고 합니다 (예로 MCN은 “개가 멈춘 후에 다시 구르기 시작한다”를 지역화를 하지 못합니다). 또한, DiDeMo는 드문 활동, 명사, 형용사로 이루어진 long-tail distribution을 가지고 있습니다. 저자는 더 발전된 (시간적) 언어 추론과 이전에 보지 못한 어휘에 대한 일반화 능력 향상은 두 가지 잠재적인 미래 연구 방향이라고 밝힙니다.
처음으로 Moment Retrieval 과제를 제안한 논문이라 아직은 해결해야할 과제들이 많은 것이 눈에 보입니다. 다음 x-review는 Moment Retrieval의 후속 연구로 MCN의 단점을 보완하고 발전시킨 방법을 리뷰할 예정입니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다!
본문의 Video Temporal Context Features에서 local features를 설명해주신 부분에서 질문이 있습니다.
local features의 경우 global features와는 다르게 특정 구간, 예를 들면 2초에서 4초까지의 순간 내에서 각 프레임의 특성을 추출하고 추출한 특성들을 평균 풀링하여 해당 시간 범위 동안의 평균 특성을 얻는 것 같습니다. 하지만 주어진 테스크가 비디오에서 쿼리에 해당하는 구간을 찾는 것이기 때문에 구간에 대한 정보도 필요로 할 것 같은데 이는 어떻게 표현되는지 궁금합니다.
감사합니다.
안녕하세요 의철님 좋은 답변 감사합니다.
MCN 모델은 CNN모델을 통해 모든 프레임의 high level video features를 추출합니다. 그 후 average pooling을 거치는 것으로 특정 시간의 비디오 descriptors를 생성합니다. 이때 특정 시간을 조절하는 것으로 비디오에서의 구간에 대한 특징을 얻을 수 있고 이를 구간에 대한 정보로 활용합니다.
감사합니다.
안녕하세요, 박성준 연구원님. 좋은 리뷰 감사합니다.
흥미로운 주제네요. 예전에 CLIP을 봤을때는 vision과 text domian 각각을 그냥 contrastive learning 때려서 직관적이었는데, 그 이전 논문이라 좀 더 복잡한 느낌입니다(task가 약간 다르기도 하구요).
제가 알기로 localization task에서는 일반적으로 후보가 되는 region을 제안하는 region proposal이 있는걸로 아는데, 여기에서는 보이지 않는 것 같아서 쓰이지 않는 것인지 궁금합니다. 아니면 moment retrieval은 localization이 아니니 애초에 필요가 없는 것인가요?
그리고 local/global 정보를 비디오의 feature vector가 모두 갖고 있어야 할 것 같은데, 어떻게 기술하는지 더 자세한 설명 주시면 감사하겠습니다.
감사합니다.
안녕하세요 재연님 좋은 답변 감사합니다.
MCN 모델은 비디오의 특징과 쿼리의 특징을 활용해 쿼리에 해당하는 구간들의 후보군을 구하고 순위를 매겨 쿼리와 가장 유사한 비디오의 구간을 추출하는 방법으로 구간을 구합니다. region proposal이라는 언급이 논문에 있지는 않지만 후보 구간을 제안하고 이들의 순위를 매겨 구간을 반환하는 region proposal과 비슷한 방법이라고 볼 수도 있을 것 같습니다. moment retrieval 또한 구간을 localizing하는 task로 region proposal을 활용하는 방법론 또한 존재합니다. MCN 이후 후속 연구에서 region proposal을 활용하여 후보 구간을 선정하는 방법론들이 제안되었습니다.
local/global 정보의 경우, MCN은 CNN을 거치며 얻은 각각의 프레임 특징들을 average pooling하여 활용하게되는데 이때 풀링하는 프레임의 수를 조절하는 것으로 local/global 정보를 다루고 있습니다. 논문에 언급된 바로는 8,16 프레임과 같은 적은 수의 프레임을 활용하는 것을 local 정보로, 전체 프레임을 풀링하여 활용하는 것으로 global 정보를 얻습니다.
감사합니다.
리뷰 잘 읽었습니다.
local feature를 구성하는 부분에서 특정 시간 범위에 걸쳐 average pooling 을 수행한다고 되어 있는데, 이 ‘특정 시간’ 이라고 하는 것이 저자가 임의로 지정한 N개의 frame 단위에 대해 수행되는 것인가요? 그렇다면 이 N이라는 파라미터가 작은지, 큰지가 꽤나 중요해질 거 같은데,, 통상적으로 어떻게 세팅되는지, 혹은 실험적으로 비교가 있는지 궁금합니다.
또한 리뷰 작성 도중에 ‘우리는’ 이라는 표현이 있는데 이 부분은 성준님이 리뷰를 작성하시면서 조금 다듬으시는게 좋을 듯 합니다.
감사합니다.
안녕하세요 석준님 좋은 답변 감사합니다.
‘특정시간’은 저자가 임의로 지정한 N개의 frame 단위 맞습니다. 논문에는 저자가 N을 몇으로 설정했는 지에 대한 직접적인 언급은 없지만, 10frame 마다 동작을 구분한다는 것으로 보아 10으로 설정한 것으로 추정됩니다. 추가로 fine-tuning하는 경우 ~3frames를 사용한다고 합니다. 통상적으로는 sliding window라 불리는 이 방법에서의 N은 8,16으로 설정되는 것으로 알고 있습니다.
잘 다듬어서 리뷰 작성하도록 하겠습니다. 좋은 피드백 감사합니다!