이 논문의 주요 키워드
- Temporal Grounding
- Moment Retrieval
- Long-form video
이 논문을 깊게 이해하려면 다음 지식이 필요합니다.
- Temporal Grounding에 대한 이해 (Moment-DETR 리뷰)
안녕하세요. 백지오입니다.
스물 일곱 번째 X-REVIEW는 이전에 리뷰한 Moment-DETR에 이어, moment retrieval 분야의 논문입니다. 다만 Moment-DETR이 150초 길이의 짧은 영상(QVHIGHLIGHTS 데이터셋)에서의 moment retrieval을 수행하였다면, 1시간 이상의 영화와 같은 긴 영상에서의 moment retrieval을 수행하는 것에 집중한 논문입니다.
2022년, 영화들로 구성된 MAD 데이터셋과 길이가 긴 1인칭 영상들로 구성된 Ego4D 데이터셋이 등장함에 따라, 기존의 video grounding 연구를 길이가 긴 영상에 확장할 수 있게 되었습니다. 그 결과, 길이가 짧은 영상에서는 잘 동작하던 방법론들이 길이가 긴 영상에서는 대체로 잘 동작하지 않는다는 것을 발견하게 되었는데요. 본 논문에서는 non-describable windows를 identifying 하고 pruning 하는 과정을 통해 긴 영상에서의 video grounding 성능을 향상하였다고 합니다. 제안된 프레임워크는 base grounding model과 Guidance Model로 구성되는 guided grounding framework인데, base grounding model은 영상을 짧은 temporal window 단위로 분석하며 어떤 segment가 주어진 자연어 쿼리를 잘 나타내는지 판단하고, Guidance Model은 describable windows를 강조(emphasize)하는 역할을 한다고 합니다. 뭔가 2-stage detector가 생각나는 구조네요. Guidance Model은 두 종류가 존재하는데, Query-Agnostic한 모델과 Query-Dependent 한 모델이 존재하며 각각 효율과 정확도와 관계가 있다고 합니다. 제안한 모델은 MAD와 Ego4D에서 각각 $4.1%, 4.52%$의 성능 향상으로 SOTA를 달성했다고 하네요.
Moment retrieval은 주어진 자연어 형태의 쿼리와 관련이 있는 영상 속의 영역을 찾아내는 task입니다. 이때, 검색 대상이 되는 영상의 길이가 길어지게 되면, 찾아내고자 하는 영역이 아닌 영역(negative)의 수가 늘어남에 따라 자연히 task의 난이도가 높아지게 됩니다. 이러한 search space의 증가에 따라, 검색 대상인 영상을 빠르게 스캔하고, 검색 가능한(query-able) 영역을 찾는 것이 중요하다고 합니다. 검색 가능한 영역이라는 개념이 흥미로운데요, 아래 예시를 보겠습니다.

그림 1을 보면, 주어진 영상 속에서 쿼리와 연관된 긴 영상 속에 존재하는 두 가지 영역이 예시로 나와있는데요. 첫번째 영역은 “두 사람이 테이블에 앉아있는 장면” 정도로 설명할 수 있는 반면 두 번째 영역은 “여자아이가 물에 빠진다.”, “강아지가 문을 연다.”, “강아지가 여자아이를 구하기 위해 물에 뛰어든다.”와 같이 다양한 문장으로 설명할 수 있습니다. 두 영역이 3분 30초 정도의 비슷한 길이임에도 불구하고, 두 번째 영역이 검색의 결과가 될 만한, notable moment를 더 많이 가지고 있음을 알 수 있습니다. 저자들은 이러한 관측을 기반으로 검색 대상인 영상 속 작은 영역 중, 시각적으로 자연어 쿼리와 유사하거나, 주목할만한(remarkable) 영역을 포함할 확률이 높은 영역을 의미하는 describable windows라는 개념을 도입합니다. 반대로 시각적으로 풍부하지 않은 영역들은 non-describable windows로 정의합니다.
이러한 접근은 짧은 영상에서는 꽤나 높은 성능을 보여주는 VLG-Net과 같은 SOTA moment retrieval 방법론들이 긴 영상에서는 CLIP 기반의 zero-shot 방법과 큰 차이를 보이지 않는 것으로 보아, 긴 영상에 존재하는 자연어로 설명하기 애매한 영역(non-describable)들이 noise로 작용하여 모델이 영상 속 중요한 부분들을 놓치는 것이 아닌가 하는 직관에 기반한다고 합니다.
저자들은 이러한 문제를 해결하기 위해, 영상 속 describable windows를 강조하는데 특화된 Guidance Model과 짧은 영역에서 moment retrieval을 수행하는 base grounding model로 구성된 Guided Grounding Framework를 제안합니다.
또한 저자들은 멀티 모달 정보들을 모두 활용하기 위해, Guidance Model이 비디오와 오디오 정보를 트랜스포머 인코더를 활용하여 함께 활용하도록 설계하였습니다. 마지막으로 Query Agnostic과 Query Dependent한 두 종류의 Guidance Model을 제안하는데, 전자는 영상 속 describable windows를 사전에 찾아놓을 수 있어 효율적인 반면, 후자는 쿼리를 고려하여 매 예측 시 windows를 탐색하기 때문에 속도는 느리지만 정확도가 높다고 합니다.
저자들이 제안한 2-stage 구조는 기존의 moment retrieval 방법에 쉽게 적용할 수 있으며, 본 논문에서는 Moment-DETR을 기반으로 실험을 진행하였습니다. 저자들의 contribution은 다음과 같습니다.
- 기존 SOTA moment retrieval 방법론들을 긴 영상에서도 잘 활용할 수 있도록 해주는 two-stage guided grounding framework 제안
- 검색 대상이 있을 확률이 높은 중요한 describable window들을 찾아주는 Guidance Model 제안
- MAD와 Ego4D에서 SOTA 달성
Related Work
Video Grounding Methods. Video grounding은 크게 proposal 기반 방법과 proposal-free 방법으로 나눌 수 있습니다. Proposal 기반 방법은 $M$개의 후보 영역 $\{ (\mathcal T_\text{start}, \mathcal T_\text{end}) \}_1^M$을 생성하고 각 영역의 confidence score 혹은 alignment score를 기반으로 예측을 수행하는 반면, proposal-free 방법은 주어진 영상과 쿼리에 대하여 바로 boundary를 생성하는 방법입니다. Mun et al. (2020)은 temporal 어텐션 기반 방법을 통해 비디오 세그먼트와 쿼리의 semantic phrase들의 bimodal interactions 속 local, global 정보를 활용하는 proposal 기반 방식(어렵네요…)으로 문제를 해결하였고, Li et al. (2021)은 피라미드 네트워크 구조를 통해 query-enhanced video feature의 multi-scale temporal correlation maps를 활용하여 proposal-free 방식으로 문제를 풀었다고 합니다. 이 정도 설명만으로는 뭔가 감이 안 잡혀서, grounding을 본격적으로 파게 되면 위의 두 논문도 읽어봐야겠네요.
Proposal-free 방식은 여러 후보에 대한 연산을 수행할 필요가 없으므로 추론이 더 빠른 장점이 있는 반면, proposal 기반의 방법들은 속도는 느려도 정확도가 높은 장점이 있습니다. Proposal 기반 방법은 대량의 후보 예측을 만들고, 연산량이 많은 NMS를 적용하여 후처리 하는 방식이기에 정확도는 높더라도 속도가 매우 느릴 수밖에 없죠.
한편, 길이가 긴 영상에서는 기존의 video grounding 방법들이 대체로 좋지 못한 성능을 보임을 이전 연구에서 알 수 있었는데, 저자들은 two-stage cascade 방식을 통해 긴 영상에서도 video grounding이 잘 동작하도록 하는 pipeline을 설계하고자 하였습니다. 저자들이 제안한 방식을 활용하면, proposal 기반과 proposal-free 방식 모두 긴 영상에서도 한층 더 잘 동작하게 할 수 있다고 합니다.
Long-from Video Grounding. 영상의 길이가 길어짐에 따라, 기존의 video grounding 모델들과 현대의 하드웨어로는 영상 전체를 한번에 처리하는 것이 불가능해집니다. 따라서 영상을 짧은 window로 나누어 처리하는 방식이 제안되었는데요, 긴 영상을 어느 정도 overlap이 있는 temporal windows로 분할하고, grounding을 수행한 다음 그 결과를 모두 모아 confidence score 순으로 정렬하는 방식이 제안되었습니다. 그러나 이러한 방법은 영상의 길이에 비례하여 false positive의 수를 크게 증가시키기 때문에, 저자들은 이러한 문제를 극복할 수 있는 guide 기반의 two-stage grounding 방법을 제안합니다.
Multimodal Transformers. 트랜스포머 구조를 활용해 멀티모달 데이터를 처리하고자 하는 연구는 이미 많이 진행되었습니다. 저자들은 이러한 방법에서 중요한 것이, 각 모달리티의 각 요소를 shared embedding space로 projection 하는 것을 잘 학습하는 것이라고 보는데요. 따라서 저자들은 이러한 점을 세밀하게 고려하여 Guidance Model을 설계하였다고 합니다.
Temporal Proposals. Temporal proposal은 untrimmed video에서 어떤 행동(action)이나 사건(event)이 있을법한 구간을 포함해야 합니다.초기에는 action classifier를 통해 어떤 행동이 존재하는 영역을 proposal로 삼는 방법이 제안되었으나, 이러한 방법은 classifier가 학습된 action class에 dependent 하므로 바람직하지 않고, 최근에는 visual 정보 상에서의 어텐션 기반의 방법이 제안되었으나, 긴 영상에서 중요한 영역을 찾기 위해서는 다양한 multimodal 정보도 고려하여야 최대한 많은 후보 영역을 생성할 수 있으므로 이상적이지 않다고 합니다. 결국 저자들이 제안한 descriable window와 같은 방식이 좋다고 하네요.
Method
저자들의 목표는 긴 영상 속에서 찾고자 하는 영역(moment)이 있을 확률이 높은 describable window를 찾는 guidance model $\mathcal g$를 학습시키는 것입니다. 이를 통해, 기존의 grounding model $\mathcal V_g$로 하여금 제안된 후보 영역 안에서 grounding을 잘 수행하게 되는 것이죠. $\mathcal V_g$의 temporal moment prediction이 예측의 시작과 끝 지점 $(\mathcal T_s, \mathcal T_e)$, confidence score $s$로 $\{ (\mathcal T_s, \mathcal T_e, s) \}^M_1$와 같이 정의될 때, 영상에서 샘플링된 temporal window $W$와 fusion 연산 $\mathcal M$을 통해 temporal moment prediction은 아래와 같이 정의됩니다.
$$ \mathcal M(\mathcal V_g, \mathcal g, W) \rightarrow \{ (\mathcal T_s, \mathcal T_e, s^*) \}^M_1$$
Grounding model $\mathcal V_g$. Grounding Model은 temporal window $W$에서 샘플링된 video observation $V$와, 자연어 쿼리 $Q$를 입력받고, $M$개의 temporal moement를 출력합니다.
$$\mathcal V_g(V, Q) \rightarrow \{ (\mathcal T_s, \mathcal T_e, s) \}^M_1$$
본 논문에서는 기존의 사전 학습된 grounding model을 활용하였는데요. 기존 방법들은 길이가 짧은 영상에서는 잘 동작하였으나 길이가 긴 영상에서는 false positive의 수가 늘어남에 따라 성능이 심각하게 낮아졌다고 합니다. 그러나 저자들이 제안한 Guidance Model을 도입함으로써 기존 방법들의 정확도를 향상할 수 있었다고 하네요.
Guidance model $\mathcal g$. Guidance model의 목표는 빈 window에서 생성된 예측들에는 낮은 점수를 부여하고, moments를 포함한 영역 (describable windows)에서 생성된 예측에는 높은 점수를 부여하는 것입니다. $\mathcal g$ 역시 $V, Q$를 입력받고 각 window에 대한 타당성(plausibility) confidence score $p^*$를 출력합니다.
$$\mathcal g(V, Q) \rightarrow p^*$$
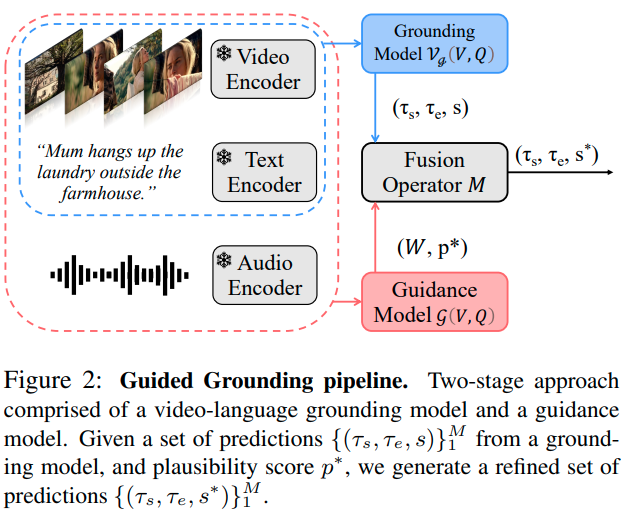
Guided grounding output $\mathcal M$. 예측 $\{ (\mathcal T_s, \mathcal T_e, s) \}^M_1$과 각 window $W$에 대한 plausibility score $p^*$를 얻은 후, fusion 연산 $M$을 통해 각 예측 moment에 대한 refined confidence score를 얻게 됩니다. 단순히 각 confidence score $\{s\}^M_1$에 대응되는 plausibility score $p^*$를 곱해주면 됩니다. 그 결과 최종 예측은 아래와 같습니다.
$$P=\{(\mathcal T_s, \mathcal T_e, s^*)\}^M_1$$
Grounding in long-form videos. 저자들은 긴 영상을 $K$개의 짧은 sliding window로 나누어 grounding을 수행하였습니다. 각 window 별로 $M$개의 예측 moment가 생성되어 전체 예측은 $K\times M$개가 되며, 최종적으로 confidence score $s^*$로 결과를 정렬하여 예측 결과를 생성했습니다.
Guidance Model Design and Training Details
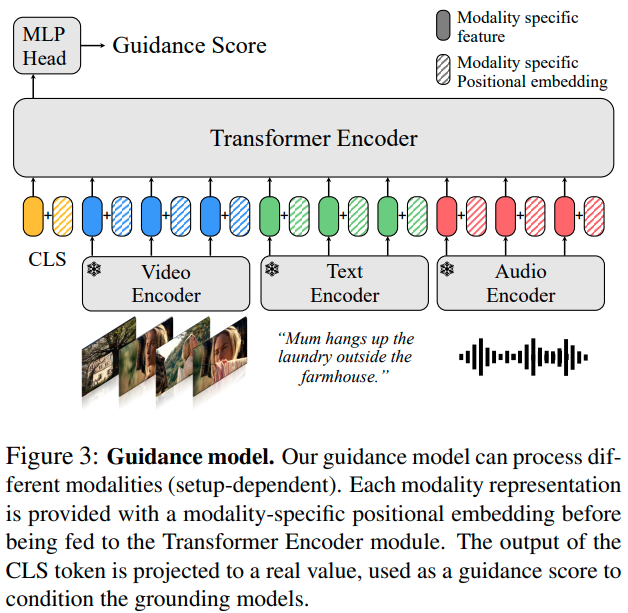
Window Representation. 먼저 입력 window $W$에서 observation $V$를 샘플링합니다. $V$에는 비디오, 오디오, 텍스트와 같은 입력들이 포함되어 있으며, 각 모달리티들에서 사전학습된 frozen encoder를 통해 embedding을 추출해 줍니다. 비디오 임베딩, 오디오 임베딩, 텍스트 임베딩을 각각 $E_v\in \mathbb R^{L_{vg}\times D_v}, E_a\in\mathbb R^{L_{ag}\times D_a}, E_t\in\mathbb R^{L_{tg}\times D_t}$와 같이 나타냅니다. $D$는 각 임베딩의 차원을 나타냅니다. 각 임베딩은 MLP를 통해 동일한 $d_g$ 차원의 공통 임베딩 공간으로 투영되며, layer normalization과 dropout을 거칩니다.
Guidance Model은 query-dependent와 query-agnostic 두 가지 버전이 존재하는데, Query-dependent는 쿼리 텍스트를 포함하여 $E_{in}=|E_{cls}, E_v, E_a, E_t|\in\mathbb R^{(L+1)\times d_g}, L=L_{vg}+L_{ag}+L_{tg}를 입력으로 받고, Query-agnostic은 $E_{in}=|E_{cls}, E_v, E_a|$를 입력으로 받습니다. $E_{cls}$는 학습가능한 cls 토큰입니다.
각 입력에는 modality-specific positional embedding이 더해지며, 비디오 모달리티에는 sinusoidal positional embedding(기본 트랜스포머에서 사용한 삼각함수 기반 임베딩)을 적용하고, 나머지 모달리티에는 학습가능한 positional embeding을 적용했다고 합니다.
Architecture. 구조는 전체적으로 원본 트랜스포머를 따라갔습니다. $E_{in}$를 $L_t$개의 트랜스포머 인코더 계층에 입력하고, 마지막 계층 출력에서 CLS 토큰 위치에 대응하는 임베딩 $E_{out}$을 MLP에 입력하여 plausibility score를 얻었다고 합니다.
Loss function and supervision definition. 이진 크로스 엔트로피 함수를 통해 $\mathcal g$를 학습시켰습니다. Query-agnostic 모델은 각 window가 어떤 moment를 하나 이상 포함하고 있는지에 대한 binary label만을 가진 데이터셋 $\mathcal D_\text{agnostic}$에서 학습되었고, query-dependent 모델은 각 window가 moment를 포함하는지 여부와 해당 moment와 관련된 query까지 주어지는 $\mathcal D_\text{dependent}$에서 학습되었습니다.
Moment Retrieval은 기존 모델로 수행하고 guidance model만 제안해서인지 method는 상당히 간단하네요. 다만 이어지는 실험의 양이 꽤 되어서 ICCV에도 붙을 수 있지 않았나 싶습니다. 한번 계속 보시죠.
Experiments
Metric. Video grounding에서는 흔히 $IoU=\theta$에서의 Recall@K ($R@K-IoU=\theta$)를 지표로 활용합니다. 저자들은 여기에 더하여 Mean Recall@K 지표를 도입했다고 하는데요, IoU 임계값에 대한 성능의 평균을 통해 더 작은 표로 성능을 볼 수 있다고 합니다.
Datasets. MAD는 384K개의 자연어 쿼리와 1200시간에 달하는 650개의 영화로 구성되어 있습니다. 저자들은 대부분의 실험을 MAD에서 진행하였습니다. 한편, Ego4D는 931명의 촬영자에 의한 1인칭 시점의 영상으로 구성된 데이터셋으로, 그중에도 NLQ subtask는 13개 타입의 질문에 따라 moment나 정보를 찾아내야 한다고 합니다. 비디오는 3.5분에서 20분으로, MAD에 비하면 그렇게 길지는 않네요.
Baselines. MAD 데이터셋에서는 VLG-Net과 zero-shot CLIP, Moment-DETR을 사용하였는데, 앞선 두개는 proposal-based 방법이고 Moment-DETR은 proposal-free 방식입니다. Ego4D에서는 Moment-DETR과 멀티모달 span-based 방법인 VSL-NET을 사용했습니다. 모든 방법론들이 저자들이 제안한 Guidance Model을 적용 시 성능 향상이 일어났다고 합니다.
Implementation Details
Feature Extraction. Visual, Text 임베딩은 MAD와 동일하게 CLIP 기반의 방법으로 추출하였습니다. Visual feature는 초당 5장의 프레임을 $D_v=512$차원으로 추출하였고, text도 $D_t=512$ 차원으로 추출됐습니다. 오디오 임베딩은 OpenL3을 통해 추출하였다고 하는데, 저도 오디오 모달리티는 처음 접해봐서 다음에 살펴봐야겠습니다. 저자들은 OpenL3 모델 중에서도 environmental audiovisual data를 포함한 영상에서 사전학습된 체크포인트를 이용하였고, 128 bands를 가진 spectrogram time-frequency representation을 사용했답니다. 오디오 임베딩도 $D_a=512$로 임베딩 되었습니다. 또한, 오디오 임베딩을 추출할 때 stride size를 0.2초에 해당하게 주었다는데, 이는 추출 frame rate가 5 Hz, 즉 visual feature와 동일하다는 의미라고 합니다. 다만 Ego4D 데이터셋에서는 Ego4D 논문에서 제안된 조금 다른 방식으로 오디오 feature를 추출했다고 합니다.
Guidance Model. 저자들은 Guidance Model 중 query-dependent 모델은 비디오, 오디오, 텍스트의 세 가지 모달리티로, query-agnostic은 비디오, 오디오 두 가지 모달리티로 학습시켰으며, 트랜스포머 인코더 계층은 $L_t=6$, hidden size $d_g=256$으로 설계했습니다. 학습은 sliding window 방식으로 window size $L_{vg}=64$ 프레임으로, MAD에서 12.8초, Ego4D에서는 34.13초의 span에 해당한다고 합니다. 모델은 AdamW, learning rate $10^{-4}$, weight decay $10^{-4}$로 batch size 512에서 100 에포크 학습하였습니다. 학습 시간은 따로 나와있지 않은데, Guidance Model만은 모델 크기가 작아서 오래 걸리지는 않지 싶습니다.
Grounding Models. Moment-DETR을 기준으로 hidden dimension 256, 2 encoder layer and 2 decoder layer, window length $L_v=128$ (MAD에서 5FPS로 25.6초에 해당), 10 moment queries를 사용했습니다. 모델은 AdamW에서 learning rate $10^{-4}$, batch size 256으로 학습했습니다. VLG-NET은 MAD에서 설명한 방법에 따라 학습했고, CLIP 역시 MAD에서 소개한 방법대로 zero-shot prediction을 수행했습니다. VSL-NET은 Ego4D와 같은 방법으로 적용했습니다. 추론 시, MAD에는 0.3, Ego4D에는 0.5의 임계를 적용한 NMS를 적용해 중복 예측은 제거했으며, 실험은 V100 GPU에서 진행했다고 합니다.
Results

먼저 MAD에서의 실험 결과입니다. 첫 3줄에 베이스라인 성능이 나와있고, 나머지 줄에 guidance model을 적용한 성능이 나와있습니다. 저자들이 제안한 Guidance Model을 도입함에 따라, 모든 베이스라인 모델의 성능이 증가하는 것을 확인할 수 있습니다. 주목할 점은 베이스라인에서는 proposal 기반 방법론들이 proposal-free인 Moment-DETR보다 우수한 성능을 보였으나, Guidance Model을 도입하자 proposal-free 방법인 Moment-DETR의 성능이 크게 증가하여, proposal 기반 방법을 앞서기도 했다는 점입니다. 이는 Guidance Model이 긴 영상에서의 moment retrieval 성능을 향상하는 것뿐 아니라, proposal 기반 방법과 proposal free 방법의 차이를 메꾸는 역할도 한다는 것을 의미합니다. 사실 guidance model의 동작 자체가 proposal 생성과 어느 정도 유사성이 있어서, Guidance Model을 적용한 Moment-DETR이 완전한 proposal-free라고 볼 수 있을까 하는 의문이 있기는 하네요.
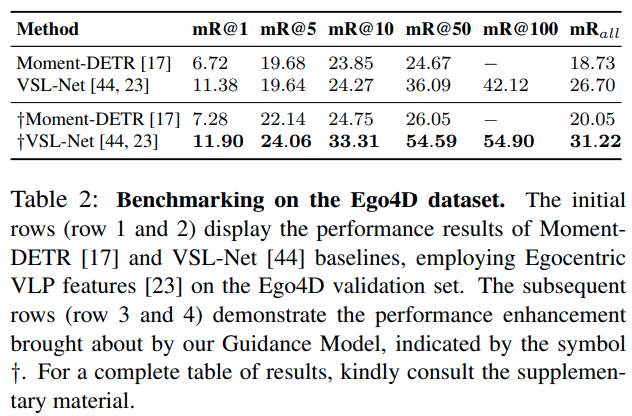
다음은 Ego4D에서의 실험 결과입니다. Ego4D는 MAD에 비해 오디오 정보가 부족한 특징이 있는데, 정확한 비교를 위해 Guidance Model에도 visual과 text feature만 활용했다고 합니다. 이번에도 역시 Guidance Model을 적용하자 성능이 향상되는 결과를 얻었습니다. 다만 영상 길이가 MAD만큼 길지는 않아서인지, 향상폭이 MAD에서처럼 크지는 않네요.
Ablation Study
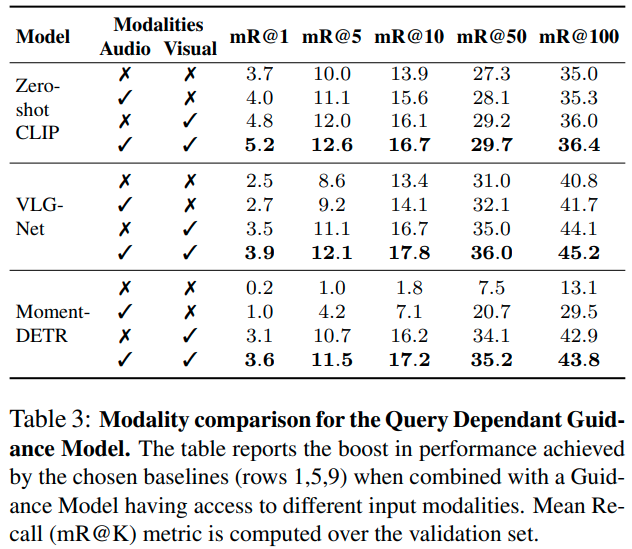
Guidance through multimodality fusion. 표 3에서는 각 베이스라인 별로 Guidance Model에 사용한 modality 별 성능이 비교되어 있습니다. 의외로 오디오 정보만을 사용해도 성능이 조금은 향상되며, 비디오 정보를 사용한 Guidance Model 적용 시 성능이 눈에 띄게 증가하고, 특히 두 모달을 함께 사용했을 때 가장 성능이 좋아지는 모습입니다.
Describable windows. 앞선 실험에서 비디오와 오디오가 모두 강력한 정보를 제공한다는 것을 알았는데요. 앞선 실험에서 사용한 Guidance Model들은 query-dependent 모델로, query가 달라지면 영상 전체에서 describable window를 다시 찾아야 하여 효율적이지 못했습니다. 저자들은 query-agnostic한 Guidance Model을 통해 영상에서 한 번만 describable window를 찾을 수 있을지 시험해 보았습니다.
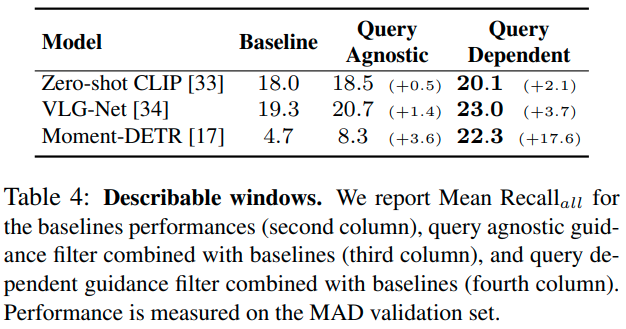
실험 결과, text(쿼리) 정보 없이 Guidance Model을 적용해도 약간의 성능 향상은 얻을 수 있었지만, query가 있는 편이 향상 폭이 더욱 확실했습니다. 결국 정확도와 추론 속도의 trade off에 따라 적절한 방법을 선택하는 수밖에 없겠네요.
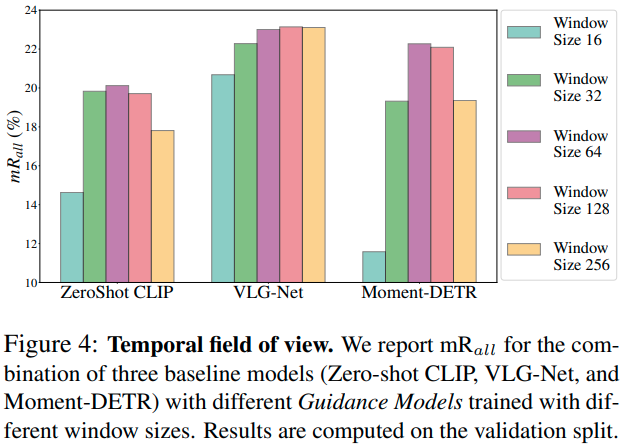
Temporal field of view. Guidance Model을 위한 적절한 window size를 탐색해보았습니다. MAD 데이터셋에서 프레임을 초당 5장 추출했으므로, size는 1당 0.2초에 해당하며, 16~256의 window size는 3.2~51.2초에 해당합니다. 대체로 window 크기가 너무 작거나 크지 않을 때, 64 정도에서 가장 좋은 성능을 보이는데, VLG-Net은 window size의 변화에 상대적으로 성능이 조금 변하는 반면 다른 방법론들은 차이가 큰 모습입니다만 이에 대한 별도의 분석은 없군요. 저자들은 window size가 작아지면 그만큼 fine-grained한 분석을 하게 되는데, 그것이 꼭 성능 향상을 보장하지 않으며, 오히려 맥락 정보를 충분히 얻을 수 있는 적절한 크기의 window size가 필요하다는 정도의 분석을 내놓고 있습니다.
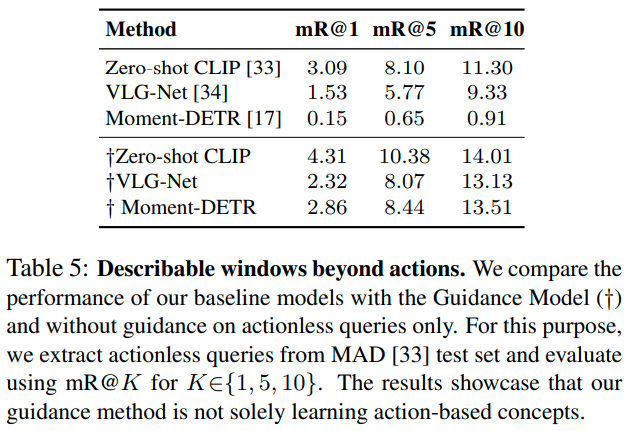
Describable windows beyond actions. 저자들은 MAD 데이터셋에 포함된 쿼리 중 적지 않은 쿼리가 동사가 없거나(10%) 대상의 상태만을 나타내고 있음(18%)을 발견했습니다. 예를 들어, “늦은 시간, 누군가의 빌딩”이나, “잠시 후, 원형 계단에서”와 같은 식으로 말이죠. 따라서 action classifier 등을 활용해 proposal을 생성하는 것이 적절하지 않을 수 있다는 것을 직감한 저자들은 본 연구를 수행하게 된 것인데요. 이 가설을 검증하기 위해, 위 표 5. 에 나타난 것처럼, action이 없는 쿼리들에 대하여 Guidance Model 유무에 따른 성능 차이를 비교해 보았을 때, action이 없는 영역에 대한 성능이 확실히 증가함을 알 수 있었습니다.
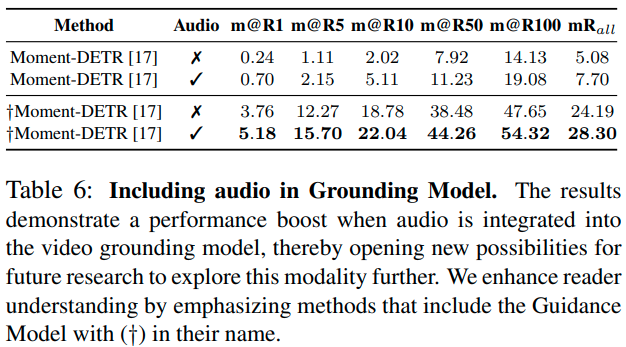
Enhancing Video Grounding by Using Audio. 저자들은 Moment-DETR에 오디오 feature를 함께 활용하여 큰 성능 향상을 얻을 수 있었습니다. 오디오 feature를 활용하는 것이 저자들의 주된 목적이 아닌 만큼, 표1과 2에서는 오디오 feature를 사용하지 않은 성능을 보고하였으나, 이러한 발견이 추후 연구에 도움이 될 수 있는 만큼 한 문단 정리하였다고 하네요.

Qualitative Results. MAD 테스트 셋에서의 정성적 결과입니다. a-c는 모델이 성공적으로 동작한 경우이며, d는 실패 사례인데요. a-c에서는 True Positive의 경우 기존 모델보다 높은 순위를 부여하고, False Positive에는 낮은 순위를 부여하는 데 성공하였지만, d에서는 True Positive에 기존 모델보다 낮은 순위를 부여한 모습입니다. 이는 제안한 Guidance Model이 non-describable window에 속한 예측에 페널티를 부여하기 때문에, 낮은 확률로 이러한 window에 속한 moment에는 좋지 않다고 하네요. 정확도가 매우 높아야 하는 task에서는 큰 단점으로 작용할 것 같습니다.
Limitations
제안한 방법이 긴 영상에서의 moment retrieval 성능을 크게 향상하기는 하였지만, 한계도 존재한다고 하는데요. 일단 쿼리와 모든 세그먼트를 비교해야 하다보니 결국 많은 연산 시간이 요구되며, 그렇다고 컴퓨팅 요구량이 적은 query-agnostic 방법을 쓰기에는 성능 하락이 존재한다는 단점이 있다고 합니다.
Conclusion
저자들은 길이가 긴 영상에서의 video grounding을 수행하기 위한 Guidance Model 기반의 two-stage 프레임워크를 제안했습니다. 이 방법은 Guidance Model을 기존 grounding model에 접목하는 방식으로 유연하게 적용할 수 있는 장점이 있지만 연산량이 많이 요구되고, 연산량 증가가 적은 query-agnostic 방법은 정확도가 떨어지는 한계가 있었습니다.
긴 영상에서 search space 증가에 따른 False Positive 증가 문제를 찾고자 하는 영역이 존재할 확률이 높은 describable windows로 search space를 제한하여 해결하고자 한 접근이 직관적이면서도, 다른 방법이 있지 않을까 생각해 보게 되는 논문이었습니다. 문제의 규모가 커지면 분할 정복을 하는 것이 일반적인 접근이기는 한데, 애초에 하나의 주제로 이어진 영화와 같은 영상을 특정 window로 분할하는 것이 최선일까 하는 의문이 조금 드네요.
다른 방법을 찾으면 논문을 쓸 수 있는 거겠죠. ?
재밌고 좋은 논문이었습니다.
새해 복 많이 받으세요!