
안녕하세요, 이번에도 6D pose estimation의 데이터셋 논문입니다.
KeyPose라는 모델을 사용하여 저자가 제안한 데이터셋에 적용한 것 까지가 해당 논문의 전체적인 흐름인데요. 특별한 점은 투명한 물체를 사용한 것 + 투명한 물체에 대한 depth 이 새로운 관점으로 볼 수 있겠습니다. 이전에 리뷰한 StereOBJ-1M과 동일한 저자로, 이번 논문이 선행 연구입니다. KeyPose를 확장하여 StereOBJ-1M을 구성한 것으로 보이네요.
논문 리뷰 시작하겠습니다.
Introduction
물체에 대한 3D 위치와 방향을 추정하는 것은 AR, 로봇 매니퓰레이터와 같은 인식을 포함하는 컴퓨터 비전 어플리케이션의 핵심 연구 중 하나 입니다. 그 중 3D keypoint를 사용하여 사람의 손이나 몸과 같이 관절이 있고 변형 가능한 물체를 처리하는 Landmark detection, human pose estimation의 연구도 있습니다. 이러한 방법 중 일부는 단일 RGB 이미지에서 3D keypoint를 예측하지만, 다른 방법은 깊이 센서로 취득한 RGB-D 데이터를 사용하여 더 나은 정확도를 달성합니다. 하지만, Projected light 또는 ToF 센서와 같은 기존의 상용 깊이 센서는 물체가 센서의 난반사를 지원할 수 있는 특정 표면에 대한 가정을 전제로 수행합니다. 이로써 투명하거나 반짝이는 금속 물체와 같은 경우 해당 조건을 만족하기 어려운 조건이라고 볼 수있습니다. 즉, 투명한 경우 depth를 구하는 것이 어렵습니다.
이번 논문에서는 스테레오 RGB 이미지에서 투명한 물체에 대한 keypoint 기반의 pose 추정 방법을 처음으로 제안합니다.
전체적인 contribution은 다음과 같습니다.
- depth 정보가 필요 없는 투명한 물체를 포함한 실제 물체에 대해 3D keypoint를 라벨링하는 파이프라인을 구성함
- 3D keypoint, 투명/불투명 depth 정보가 있는 스테레오 및 RGB-D 이미지로 구성된 6개 클래스로 총 15개 물체들로 구성함
- 입력을 RGB 스테레오만을 사용하여 물체의 3D keypoint를 높은 정확도로 예측하는 모델인 KeyPose는depth를 입력을 사용하는 방법보다 성능이 뛰어난 것을 입증함
Transparent Object Dataset(TOD)
본격적으로 이번 논문에서 제안하는 Depth 센서없이도 샘플에 대해 3D keypoint에 대한 라벨링을 할 수 있는 전체적인 파이프라인에 대해 알아보겠습니다.
Data Collection with a Robot
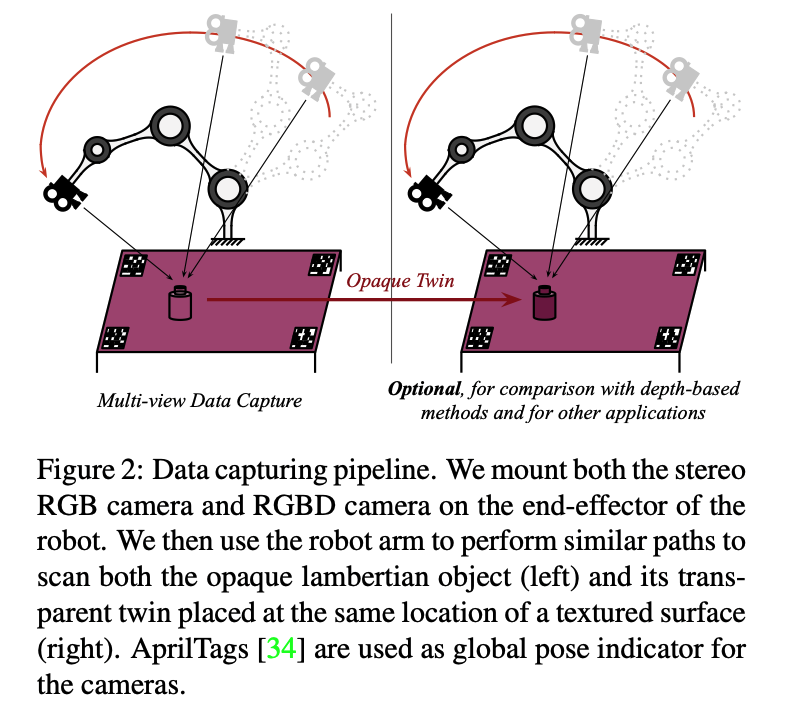

수 많은 RGB 이미지에 3D keypoint에 손으로 직접 라벨링을 하는 것은 depth에 대한 불확실성으로 인해 어렵거나 불가능하다고 합니다. 이렇기 때문에 저자는 위 그림(2)와 같이 multi-view geometry를 이용하여 적은 수의 이미지에서 2D keypoint를 물체가 움직이지 않은 이미지 셋에 대한 3D keypoint로 차원을 올려주는 식으로 할 수 있는데요. 스테레오 카메라를 사용하여 로봇 팔에 부착된 카메라를 움직여 시퀀스 형태로 이미지를 캡처하는 방식으로 진행됩니다. 물론 로봇 팔이 아니라 사람이 직접 손으로도 움직일 수 있습니다. 사람손으로 직접 움직인건 StereOBJ-1M 에서 한 것을 확인할 수 있습니다. 해당 리뷰에 있는 파이프라인을 그대로 따라가므로 참고하시면 되겠습니다. 배경에 대한 다양성을 높이기 위해 물체의 그림 (17)과 같이 아래 밑면에 다양한 텍스처의 배경을 배치합니다.
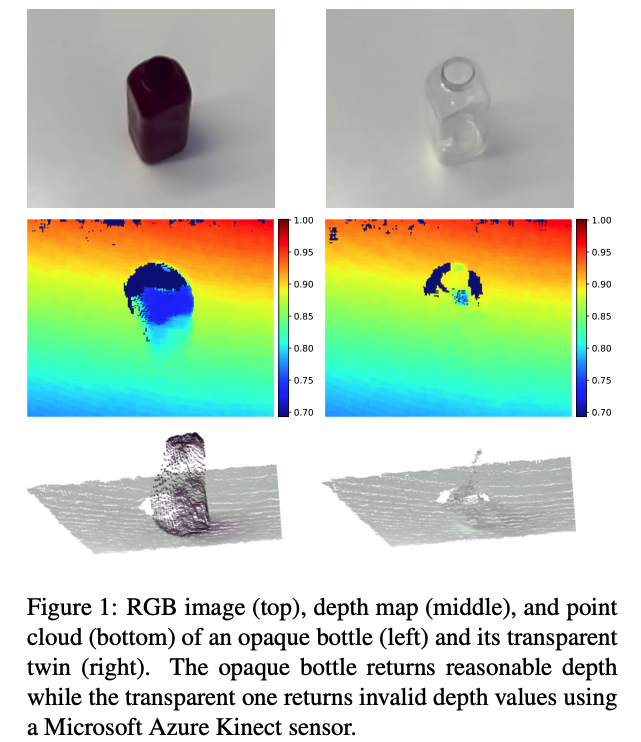
이렇게 총 생성된 이미지 수는 64000장이며 이는 KeyPose 모델을 학습하고 평가하기에 충분했다고 합니다. 저자는 스테레오 카메라를 이용한 데이터 외에도 Kinect Azure를 이용하여 depth 데이터를 같이 사용했다고 합니다. 해당 데이터는 부수적인 데이터이긴 하지만 depth 데이터가 필요한 방법론과 KeyPose 모델을 비교하기 위해 설계를 했다고 하네요.
스테레오와 RGB-D를 같이 장착한 로봇팔을 이용하여 초기 스캐닝 단계에서 두 개의 depth 정보를 얻고, 두 번째 스닝에서 투명한 물체를 opaque twin(같은 물체인데, 페인트를 칠한 물체)으로 바꾼 상태에서 두 개의 depth 이미지를 수집합니다(그림 (2)의 오른쪽 참고). 이때 RGB-D 이미지는 궤적과 카메라 캡처의 시간의 차이로 인해 스테레오와 약간 다른 pose로 캡처되지만, RGB 이미지에서 RGB-D 카메라의 계산된 pose와 RGB 센서에서 depth 센서의 알려진 오프셋을 활용하여 depth 이미지를 왼쪽 스테레오 이미지와 정확하게 정렬하도록 warpping 할 수 있다고 하네요.
Keypoint Labeling and Automatic Propagation
데이터셋을 정확하게 구성하는 방법은 어떻게 해야될까요?
저자는 다양한 오류 원인에 대한 해결을 하는 방식으로 진행을 했다고 하는데요.
첫 번째로, AprilTag(마커)의 위치를 찾는 것이 완전하지는 않다고 합니다. 이러한 문제는 카메라의 pose를 측정하는 것에 부정확한 정보를 주게 됩니다. 해당 문제를 해결하기 위해 타겟이 되는 물체에 대해 마커를 넓게 배치하였다고 합니다. 즉 물체와 가깝게 배치를 하면 오히려 부정확한 정보가 나오나봅니다.
두 번째로, 2D 이미지의 keypoint에 사람이 직접 라벨링을 하면 depth를 사용하지 않으므로 불확실성으로 인해 error가 커지는 것을 방지하기 위해 FPS(Farthest Points Sampling)을 베이스라인으로 활용하여 효율적으로 수행했다고 합니다.
저자는 manual annotation의 정확도를 알고싶어 3D keypoint의 절대적인 GT는 알 수 없지만, AprilTag와 2D annotation의 reprojection error를 고려할 때 라벨링의 오차 정도를 추정할 수 있습니다. 라벨링된 3D Keypoint의 랜덤 오차가 약 3.4mm RMSE로 계산되었다고 합니다. 해당 오차를 측정하는 방법은 몬테카를로 시뮬레이션을 사용했다고 하는데 불확실한 사건의 가능한 결과를 추정하는 데 사용되는 수학적 기법이라고 합니다. 이를 어떻게 사용했는지 알고 싶어 찾아보았는데 잘 안 나오네요..
Predicting 3D Keypoints from RGB Stereo
이제 3D keypoint의 지도학습을 사용하여 스테레오 입력에서 물체에 대한 pose를 추정하는 KeyPose에 대해 알아보도록 하겠습니다.
Data Input to the Training Process
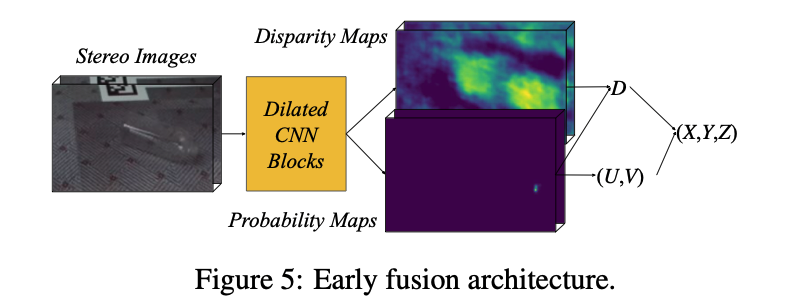
이번 KeyPose는 2-stage로 진행되는 모델로 bounding box를 먼저 찾고 이후에 추가적인 파이프라인으로 구성되어 있습니다. 먼저, 물체의 위치를 대략적으로 결정하는 detection 단계가 있어야겠죠. 그림(5)의 UV-heatmap을 사용하여 투명한 물체를 detection 하게 됩니다.

이렇게 찾은 물체에 대한 bounding box를 통해 그림(4)와 같이 왼쪽 이미지에서 고정된 크기로 crop 후 오른쪽 이미지에서 같은 height를 가지도록 crop을 하면서 epipolar geometry를 유지하도록 합니다. 이때 직사각형의 형태는 어디에 표시되든 오른쪽 이미지의 물체를 포함할 수 있을만큼 충분히 확장되어야 하는데요. 이렇게 확장에 대한 제한을 두기 위해 특정 픽셀 만큼의 오차가 발생하였고 이에 입력으로 주는 crop에 대한 크기를 180×120으로 고정하였다고 합니다.
입력으로 들어가는 이미지는 모델에 의해 각 keypoint에 대한 위치와 depth를 의미하는 UV(2D)와 keypoint의 오프셋인 D(disparity)를 생성합니다. 이러한 UVD triplet은 3차원 XYZ 좌표를 인코딩 할 수 있습니다. 이러한 XYZ 위치를 라벨로 사용하여 이미지 영역에 reprojection하여 UVD에 대한 차이를 비교하여 학습에 대한 오차를 계산할 수 있습니다. 해당 reprojection error는 multi-view geometry에서 가장 널리 사용되는 안정적이고 물리적으로도 실현가능한 오류 방법이라고 하네요.
Architecture for 3D Pose Estimation
KeyPose 모델은 다음과 같은 방식으로 동작하게 됩니다.
Stereo for Implicit Depth
스테레오 이미지를 사용하여 모델에 depth 정보를 같이 사용
Early Fusion
두 이미지(좌, 우)의 crop 정보를 가능한 한 빠르게 결합
Broad Context
각 keypoint의 공간적인 context를 최대한 넓게 확장하여 물체의 관련 모양 정보 활용
다시 한 번 그림(5)를 보면 모델의 기본 구조를 확인할 수 있습니다. 스테레오 이미지를 스택시켜 diated 3 x 3 conv. 를 입력시켜 해상도를 일정하게 유지하면서 keypoint를 예측하기 위한 context를 확장하는 방식입니다. 두 가지 branch는 각 keypoint에 대한 context가 완전히 혼합되도록 설계를 했으며 keypoint 당 하나씩 projection head를 통해 UVD 좌표를 추출합니다. 이때 2가지 projection 메소드가 있는데요.
Direct Regression
3개의 1 x 1 conv. layer가 N x 3의 UVD 좌표를 생성합니다. 이때 N은 keypoint의 수를 의미합니다.
Heatmaps
각 keypoint i에 대해 CNN의 layer가 heatmap을 생성한 다음 spatial softmax를 사용하여 probability map을 생성한 다음 UV 좌표를 얻습니다. 또한, disparity에 대한 heatmap을 계산하고 probability map과 convolution을 통해 최종 disparity D를 얻습니다.
Losses
KeyPose는 Keypoint UVD loss, Projection loss, Locality loss 이렇게 3가지의 loss function을 사용합니다.
Keypoint UVD Loss
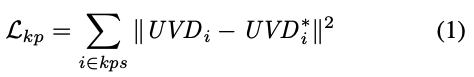
예측된 UVD에 대한 픽셀값과 GT UVD*에 대한 픽셀 값의 squared error를 계산하는 식(1)과 같이 연산을 합니다.
Projection Loss
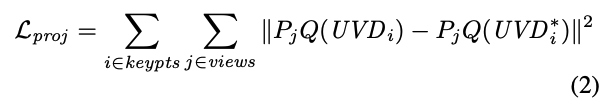
예측된 UVD 값은 3D 포인트로 변환된 다음, 3D 포인트를 생성하는 데에 사용된 view에 대해 reprojection을 합니다. 예측된 reprojection과 GT reprojection에 대한 loss 또한 squared error를 통해 계산됩니다. 이때 P_{j}는 projection function을 의미하며, Q는 UVD를 XYZ 좌표로 변환하는 reprojection matrix를 의미합니다.
Locality Loss
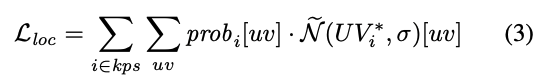
keypoint의 위치는 UV probability map에서 추정되지만, 해당 map은 단일 모달리티가 아니며 실제 위치에서 멀리 떨어져 있을 확률도 있습니다. 저자가 제안한 해당 식(3)을 설계하여 probability map이 keypoint 주변에 위치하도록 설계하였다고 합니다. \mathcal N은 keypoint i에 대한 GT UV_{i}^* 좌표를 중심으로한 circular normal distribution이며 \sigma는 표준편차입니다.
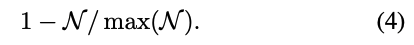
최종적으로 \tilde {\mathcal N}는 normalized inverse를 의미합니다.
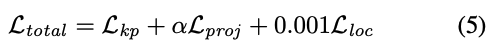
마지막으로 최종적인 Loss function은 식(5)와 같습니다. 이때 \alpha는 학습 과정에서 0~2.5까지 증가하면서 예측된 UVD 값이 안정화되도록 설계하였다고 합니다.
Experiments
TOD 데이터셋에서 KeyPose 모델과 DenseFusion을 통해 성능을 평가하는 실험을 진행합니다. 물체의 불투명/반투명에 대한 depth를 사용하여 DenseFusion의 두 가지 입력에 대한 결과를 비교했으며 이때, 불투명한 depth의 경우에도 투명한 물체의 RGB 이미지를 사용합니다.
평가지표로는 AUC와 3D keypoint error가 있습니다. 하지만 저자는 AUC는 정확도가 낮은 방법론들을 위해 개발이 되었으므로 3D keypoint의 MAE(Mean Absolute Error)를 사용하여 더욱 정확한 측정값을 선호한다고 하네요.
Pose Estimation
15개의 물체를 각각 개별적으로 학습하고 약 3000장 정도의 학습 데이터와 320장의 테스트 데이터가 사용되었다고 합니다. 해당 실험은 instance-level의 모델이 새로운 환경에서 얼마나 잘 일반화가 가능한지를 보여주는 실험으로 볼 수 있다고 합니다.
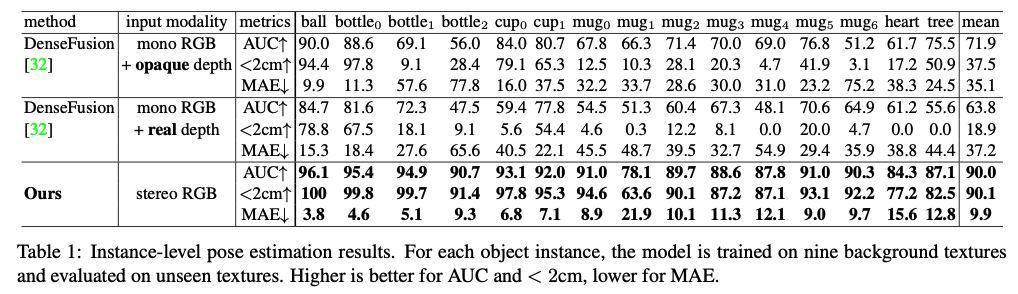
pose 추정 결과는 표(1)에 정리가 되어 있는데요 mug1과 mug6을 제외한 거의 모든 경우에서 불투명(opaque)이 반투명(real)보다 더 나은 성능을 보였습니다. 이는 불투명한 경우에도 상당한 오차가 발생할 수 있는 depth 센서에서 발생하는 depth error일 수 있다고 합니다. DenseFusion을 사용한 두 경우 모두 MAE가 35mm이상으로 큰 것을 확인 할 수 있습니다.
하지만 KeyPose는 전반적으로 DenseFusion 보다 앞서는 모습을 볼 수 있습니다. depth의 좋은 정보를 제공함에도 불구하고 좀 더 좋은 성능을 보이네요. 모든 물체에 대해 평균 9.9mm의 MAE를 보이며 이는 DenseFusion에 비해 3.5배 이상 높은 수치를 의미합니다. 이러한 결과는 스테레오 입력을 사용하는 KeyPose가 투명한 물체에 대해서도 잘 작동하는 것을 볼 수 있습니다.
Conclusion and Discussion
이번 논문에서는 스테레오 이미지에서 3D keypoint 위치로 표현되는 3D 물체의 pose를 추정하는 방법을 다루었습니다. 효율적으로 다루기 쉬운 3D keypoint 라벨링 하는 방법을 제공함으로써 keypoint pose를 추정하는 방법을 학습하고 depth와 함께 사용하는 모델과의 비교를 위해 depth를 취득하였으며, 반투명/불투명한 물체에 대한 대규모의 라벨링한 TOD 데이터셋을 만들었습니다. 스테레오 이미지의 early fusion을 활용하는 KeyPose 모델은 불투명 depth를 사용하는 경우를 포함하여 benchmark에서 모두 SOTA를 달성하였습니다.
이상으로 논문 리뷰 마치겠습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
RGB 이미지에서 3D keypoint를 직접 라벨링 하는 것이 depth에 대한 불확실성으로 인해 어렵다는 점은 이해하였으나, 멀티뷰 지오메트리로 넘어가게 되면 여러 장의 RGB 이미지를 통해 depth를 얻을 수 있지 않나요 ?? 2D keypoint를 3D keypoint 차원으로 올려준다는 것이 멀티뷰 이미지를 통해 얻은 depth 값을 사용한다는 것과 동일한 의미인지 궁금합니다.
그리고 스테레오 RGB와 RGB-D 카메라로 촬영을 하는 부분에서 RGB 이미지에서 RGB-D 카메라의 계산된 pose와 RGB 센서에서 depth 센서의 알려진 오프셋을 활용하여 depth 이미지를 왼쪽 스테레오 이미지와 정확하게 정렬하도록 warpping 할 수 있다는 것이 정확히 어떤 과정인가요 ?? depth 센서의 알려진 오프셋이 무엇을 의미하는지 등이 잘 이해가 되지 않아 조금만 더 추가적으로 설명해주시면 감사할 것 같습니다.
감사합니다 !
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. multi-view에 대한 기하학적인 관계를 통해 depth를 구할 수 있는 것은 맞지만, depth를 사용하여 3D으로 올리는 것은 아닙니다. feature matching으로 통해 얻은 2D keypoint를 이용하여 PnP 알고리즘을 통해 3D 포인트를 구할 수 있지만, 이러한 3D 포인트를 triangulation과 같은 과정을 통해 좀 더 정밀한 3D 포인트를 구할 수 있게 됩니다.
2. RGB 센서와 RGB-D 센서 간의 pose정보를 통해 두 센서간의 상대적인 거리를 알려진 오프셋이라고 하며, 이러한 pose 정보를 안다면 depth도 그만큼 회전과 이동을 해주면 warping을 할 수 있을 것이라고 이해했습니다.
감사합니다.
좋은 리뷰 감사합니다.
해당 논문은 투명한 객체에 대한 스테레오 RGB 영상을 이용하여 해결한다는 것이 신기하네요. 육안으로 보았을 때 투명한 객체에 대하여 인지하기도 어려워보이는 때, Table 1을 보면 상당히 좋은 성능을 보이는 것 같아서 stereo를 쓰는 것 외의 다른 스킬은 없었는 지 궁금합니다.
keypose는 정해진 크기로 crop을 한다고 되어있는 데, 전체 데이터 중 가장 가까이서 촬영된(객체가 크게 촬영된) 경우를 기준으로 180×120으로 설정한 것일 지궁금합니다. 만일 객체의 일부가 잘리기도 하는 것인지 그렇다면 이를 어떻게 고려하는지 추가적인 설명이 있었나요??
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 해당 논문의 핵심은 stereo vision을 이용하여 제안한 데이터셋에 어떻게 잘 동작하는지를 보여주므로, 다른 내용은 없었습니다.
2. 물체의 거리가 0.5m~1m라고 가정할 때, 물체를 충분히 포함할 수 있을만큼의 여유를 주었다고 합니다. 그래서 잘린 경우는 없을 것으로 보입니다.
감사합니다.