안녕하세요. 이번에도 VQA 논문을 가져오게 되었습니다. 요즘 VQA 방법론에 대해서 흥미로운 부분이 많다고 느꼈는데, 이번에 초청 세미나 때 조재원 교수님께서 추천한 논문이 있는데 그 논문의 기반이 되는 논문이 이 GGE 논문이라 이번에 가져오게 되었습니다. 그럼 리뷰 시작하겠습니다.
<Introduction>
이번에도 다른 논문들처럼 VQA에 존재하는 bias에 대해서 언급하며 시작합니다. 제가 이전에 리뷰했던 CF-VQA에서도 언급했듯이, 단순히 모델에게 “what sports ..”로 시작하는 질문을 던졌을 때 아무런 정보도 보지 않고도 “tennis”라고만 대답했을 때도 높은 정확도를 얻을 수 있다는 것은 유명합니다. 그래서 단순히 이러한 데이터셋의 bias를 고려하지 않고 학습을 한다면 out-of-domain data에 대해서 일반화하는 능력이 저하될 것입니다.
현재 이러한 문제에 대해서 대응한 방법론은 크게 3가지 방법론으로 나눌 수 있습니다. ensemble-based 방법론, grounding-based 방법론, counterfactual-based 방법론 입니다. counterfactual based 방법론의 대표적인 예가 제가 이전에 리뷰한 CF-VQA라고 생각하시면 좋을 것 같습니다. 각 방법론에 대해서 간단히 설명드리고자 합니다. ensemble-based 방법론은 question-only branch에 따라 sample의 가중치를 조정하는 방식으로 bias를 줄이고자 합니다. grounding-based 방법론은 human-annotated visual explanation을 활용하여 이미지 정보를 더 잘 활용하도록 설계됩니다. counterfactual-based 방법론은 위의 두가지 방법론의 혼합으로 생각하시면 이해하시기 쉬울 것 같습니다.
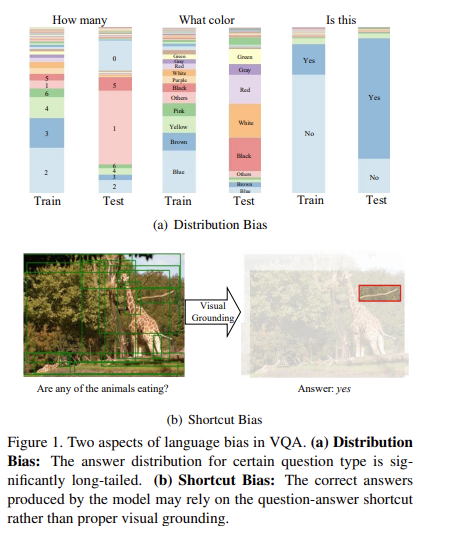
위의 방법론들을 통해서 bias를 완화함에도 불구하고 본 논문에서는 기존 방법들이 vision, language information을 충분히 활용하지 못함을 말하는데요. 이를 위해서 실험을 진행하였고, 그 결과 VQA에서 language bias는 Figure 1(a)에서 보이는 train과 test간의 통계적 분포 격차로 인한 distribution bias와 Figure1(b)에서 보이는 특정 QA 쌍 간의 의미적 상관관계, 즉 shortcut bias 이렇게 두가지로 나타났다는 것을 알게 되었습니다.
이러한 발견을 발판삼아 본 논문에서는 functional space에서 gradient descent와 같은 biased 모델과 기본 모델을 앙상블하는 model-agnoistic한 debias framework Greedy Gradient Ensemble(GGE)를 제안합니다. 이 방법의 핵심 아이디어는 딥러닝의 과적합 현상을 활용하는 것인데요. 데이터의 bias된 부분을 biased feature로 greedily하게 과적합하면, 결과적으로 bias된 모델로는 풀기 어려운 example에 집중하여 보다 이상적인 데이터 분포로 예상되는 기본 모델을 학습할 수 있습니다.
최종적으로 GGE의 contribution을 정리하면 이와 같습니다.
- We provide analysis for the language bias in VQA task and decompose the language bias into distribution bias and shortcut bias.
- We propose a new model-agnostic de-bias framework Greedy Gradient Ensemble (GGE), which sequentially ensembles biased models for robust VQA.
- On VQA-CP, our method makes better use of visual information and achieves state-of-the-art performance, with 17.34% gain against simple UpDn baseline without extra annotations.
<Revisiting Language Bias in VQA>
<Problem Definition>
VQA는 $\mathcal{D}=\{v_i, q_i, a_i\}^N_{i=1}$데이터셋이 주어지며, image $v_i \in \mathcal{V}$,question $q_i \in \mathcal{Q}$, 라벨링된 answer $a_i \in \mathcal{A}$ 로 구성되어 있습니다. 여기서 C answer 후보에 대한 분포를 생성하는 mapping $\mathcal{f}_{VQ}:V\times Q→\mathbb{R}^C$ 을 최적화해야합니다. 이를 식으로 보면 아래와 같이 볼 수 있습니다.
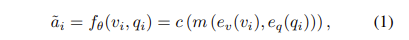
여기서 $e_v:V→\mathbb{R}^{n_v\times d_v}$는 이미지 인코더, $e_q:Q→\mathbb{R}^{n_Q\times d_Q}$는 question 인코더, $m(\cdot)$은 multi-modal fusion을, $c(\cdot)$는 multi-layer perception classifier를 의미합니다. 그리고 모델의 output vector $\tilde{a} \in \mathbb{R}^C$는 각 answer cadidate에 속할 확률을 나타냅니다.
<Experimental Analysis for Language Bias>
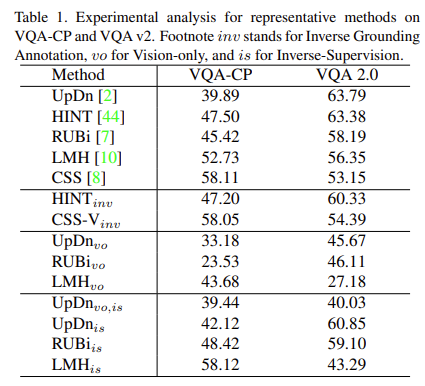
이 섹션에서는 위에서 언급한 두가지 bias에 대해서 설명하고자 합니다. 여기서는 여러가지 모델을 이용하여 실험을 진행하는데요. 간단히 설명드리면, 베이스라인 모델로 UpDn 모델로 가져가며, grounding-based 방법론으로는 HINT모델을, ensemble-based 방법으로는 RUBi, LHM을, counterfactual-based 방법론으로는 CSS 모델을 가져갑니다. 각 모델의 VQA-CP 데이터셋에서와 VQA 2.0 데이터셋에서의 성능 비교를 통해서 bias에 대해서 설명하고자 합니다.
<Inverse Grounding Annotation>
visual-grounding의 contribution을 먼저 분석하기 위해서 human annotation을 추가 정보로 사용하는 HINT와 CSS-V를 실험해보겠습니다. 먼저, human-annotated region 중요도 점수 $S_h$를 관련없는 grounding인 $S’h = 1 – S_h$로 바꿔보겠습니다. 그러면 성능을 한번 확인해볼까요? Table1읕 통해서 확인할 수 있습니다. $\text{HINT}{inv}, \text{CSS-V}_{inv}$의 성능이 기존의 성능과 크게 다르지 않는 것을 확인할 수 있습니다. 이 말은 성능 향상이 반드시 relevant region을 살펴보는 데서 오는 것이 아님을 나타냅니다. 모델이 일부 어려운 질문에 정답을 맞추기는 했지만, 여전히 이미지와 관련없이 language information에 기반하여 예측을 수행하는 것을 나타내죠. 본 논문에서는 이를 “inverse lanuage. bias”라고 부릅니다.
<Vision-only Model>
두 번째 실험은 RUBi와 LMH에서 앙상블 branch를 분석하는 것을 목표로 합니다. 기본 모델에서 multi-modal fusion 없이 vision feature만을 answer classifier에 입력합니다.
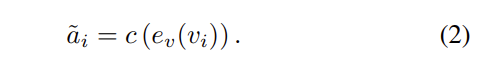
텍스트 정보를 사용하지 않으므로, 당연히 QA 쌍 간의 shortcut도 없습니다. Table 1을 통해서 볼 수 있듯이, $\text{RUBi}{vo}$의 성능은 크게 하락했지만 $\text{LMH}{vo}$는 여전히 $\text{UpDn}_{vo}$보다 정확도에서 큰 차이로 앞서 있는 것을 확인할 수 있습니다. LMH 모델은 학습 데이터셋에서 가장 흔한 답변을 제제(penealizing)함으로써, 모델이 단순히 가장 일반적인 답변을 반복하는 대신 더 다양한 균형 잡힌 답변을 생성하도록 하는데요. 이를 바탕으로 본 논문의 저자들은 LHM에서 향상된 정확도가 학습 데이터셋에서 가장 흔한 답변을 제재하여 inverse distribution에 따른 더 균형 잡힌 분류기를 이끌어내는 데에서 온다고 생각하였습니다. 이는 LMH에서 distribution bias가 RUBi의 question shortcut bias와 비교하여 다른 역할을 한다는 것을 의미합니다.
<Inverse Supervision for Balanced Classifier>
inverse distribution bias가 실제로 정확도를 향상시킬 수 있는지 직접 확인하기 위해서 본 논문의 저자들은 간단한 inverse supervision 전략을 설계했습니다. 각 iteration마다 매개변수는 다른 지도하에 두 라운드로 업데이트 됩니다. 첫 번쨰 라운드에서는 모델을 실제로 label $\mathcal{A}$로 지도하여 prediction P(a)를 얻습니다. 가장 높은 예측 확률을 가진 상위 N개의 답변이 $a^+$로 선택됩니다. 두번쨰 라운드 학습에서는 label이 $\hat{A}=\{a_i|a_i\in \mathcal{A},a_i \in∉a^+\}$로 정의됩니다. 이 방식으로 모델은 첫 번째 라운드 학습에서 가장 확신 있는 답변을 지속적으로 제재하며, inverse distibution bias에 따라 더 균형 잡힌 분류기를 형성합니다. $\text{UpDn}_{vo}$에서 정확도 향상은 distribution bias가 있음을 확인할 수 있는데요. RUBi의 결과는 더 나아가 distribution bias와 shorcut bias가 보완적임을 나타낸다고 합니다.
길었습니다. 정리해보겠습니다. 위의 실험에 따르면, 다음과 같은 통찰을 얻을 수 있습니다.
높은 정확도가 system이 답변 분류에 있어서 정말로 시각적으로 근거를 두고 있다는 것을 보장하지 않습니다. 실제로, 모델이 질문의 언어적인 특성만을 이용해 답변을 결정하는 경향이 있을 수 있습니다. 이는 모델이 실제로 이미지를 ‘이해’하는 대신, 단지 데이터셋의 언어적인 bias를 활용해 예측을 하는 경우가 될 수 있습니다.
distribution bias와 shortcut bias는 VQA에서 보완적인 특면을 가집니다. distribution bias는 모델이 특정 답변에 과도하게 의존하는 경향을 말하며, shortcut bias는 모델이 질문과 답변 사이의 직접적인 연결을 학습하는 경향을 말합니다.
자 그러면 본격적인 방법론으로 넘어가 보겠습니다.
<Method>
논문의 저자들은 위의 발견을 바탕으로, GGE라는 새로운 model-agnostic de-bias learning paradigm을 제안합니다. 이는 단계적으로 distribution bias와 shorcut bias를 제거하여 모델이 이미지에 집중하도록 강제합니다.
<Greedy Gradient Ensemble>
train set을 (X,Y)라고 표시해봅시다. X는 observation space를 나타내고 Y는 label space를 나타냅니다. 이전 VQA 방법론에 따라서, binary cross-entropy (BCE) loss를 이용한 분류 문제를 다룬다고 해봅시다.
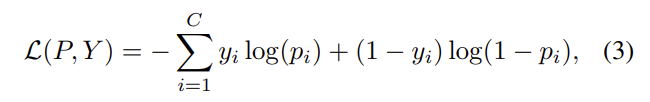
여기서 C는 class의 수를 의미합니다. $p_i=\sigma(z_i)$이고 $z_i$는 class i의 예측된 logit 값을 의미합니다. $\sigma(\cdot)$는 sigmoid 함수를 의미합니다. 기본적으로 prediction $f(X;θ)$와 label Y 사이의 loss를 직접적을 최소화합니다.
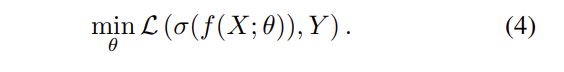
$f(\cdot)$이 과도하게 매개변수화된 DNN인 경우에 모델은 데이터셋의 bias에 과적합되기 쉬우며 일반화 능력이 떨어지는 문제를 겪을 수 있습니다.
본 논문에서는 이러한 과적합을 활용하는데요. $B=\{B_1,B_2,…,B_M\}$을 사전 지식을 바탕으로 추출할 수 있는 bias feature들의 집합이라고 가정합니다. 이번에는 bias된 모델들과 기본 모델의 앙상블을 label Y에 맞춰 학습합니다.
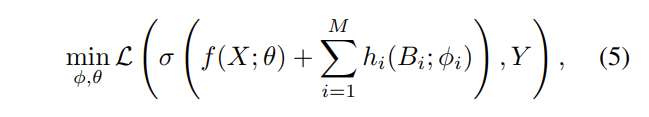
여기서 $h_i(\cdot)$은 특정 bias feature에 대한 bias된 모델입니다. 이상적으로는, 데이터의 bias된 부분이 bias된 모델들에 의해서만 과적합되어, 기본 모델이 bias되지 않은 데이터 분포로부터 학습될 수 있기를 바랍니다. 이를 달성하기 위해서 bias 모델들이 greedy 전략으로 데이터셋을 과적합할 수 있는 더 높은 우선순위를 가지도록 하는 GGE를 제안합니다.
futional space에서 봤을 때, $H_m=\sum^m_{i=1}h_i(B_i)$라고 가정하고 $H_m에 h_{m+1}(B_{m+1})$를 추가하여 loss $\matcahl{L}(σ(\mathcal{H}_{m}+h_{m+1}(B_{m+1})),Y)$이 감소하는 것을 원한다고 가정해봅시다. 이론적으로 $h_{m+1}$의 바람직한 방향은 $H_m$에서 $\mathcal{L}$의 음의 미분입니다.
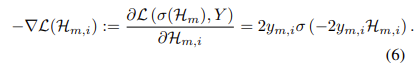
분류 문제의 경우 class i: $\sigma(f_i(x)) \in \{0,1\}$에 대한 확률만 고려합니다. 따라서 음의 기울기를 분류를 위한 “가짜 label”로 처리하고 BCE loss로 새로운 모델 $h_{m+1}(B_{m+1)$을 최적화 합니다.
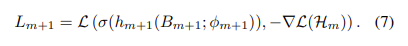
모든 bias된 모델들을 통합한 뒤, 기본 모델 f는 다음과 같이 최적화 합니다.
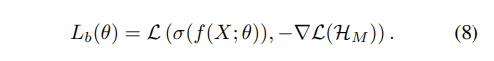
테스트 단계에서는, 기본 모델만을 예측에 사용합니다.
조금 더 직관적으로 설명해보고자 합니다. bias된 모델들에 의해 쉽게 fit될 수 있는 sample에 대해, 그 loss의 음의 기울기(즉, 기본 모델을 위한 가짜 레이블)은 상대적으로 작아집니다. f(X;θ)는 이전 앙상블 bias된 classifier $\mathcal{H}_M$에 의해 해결하기 어려운 sample들에 더 많은 주의를 기울일 것입니다.

위의 패러다임을 Batch Stochastic Gradient Decent (Batch SGD)에 적용시키기 위해, Algorithm 1과 Algorithm 2에 따라 GGE-iteration, GGE-together라는 두가지 최적화 schedule을 구현합니다. GGE-together는 다음과 같이 bias된 모델들과 기본 모델을 함께 최적화합니다.
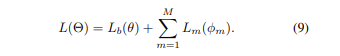
GGE-iter에 대해서는, 각 모델이 특정 데이터 배치 반복 내에서 반복적으로 업데이트하게 됩니다.
<GGE Implementation for Robust VQA>
다시 돌아와서, 저희는 위에서 두가지 bias, distribution bias, shorcut bias가 있음을 말했습니다.
<Distribution bias>
본 논문에서는 ditribution bias를 question type에 조건을 두고 train set에서의 answer distribution으로 정의합니다. 이를 식으로 표현하면 아래와 같이 표현할 수 있겠군요.
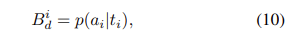
여기서 $t_i$는 question $q_i$의 type이라고 말할 수 있습니다. question type에 조건을 두고 sample을 계산하는 이유는 distribution bias를 줄일 때 type information을 유지하기 위함입니다. question type information은 이미지가 아닌 question에서만 얻을 수 있으며, 줄어야 할 language bias에는 속하지 않습니다.
<Shortcut Bias>
shortcut bias는 특정 QA 쌍 간의 의미론적 연관성을 의미합니다. 본 논문에서는 question-only branch를 사용하여 question shortcut bias를 구성합니다. 식으로 표현하면 아래와 같이 표현할 수 있습니다.
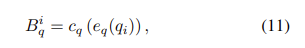
여기서 $c_p:Q->\mathbb{R}^C$ 입니다.
본 논문에서는 distribution bias와 shortcut bias가 보완적이라는 주장을 검증하기 위해서, 다양한 language bias를 가진 앙상블에 대해 GGE 3가지 버전을 설계하여 실험하였습니다.
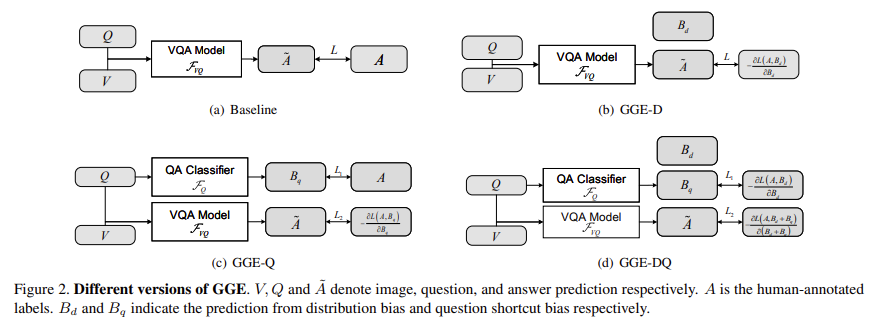
<GGE-D>
GGE-D는 Figure2(b)와 같이 앙상블에 대한 distribution bias만 모델링 합니다.
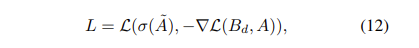
$\tilde{A}$는 prediction, A는 labelled answer를 의미합니다.
<GGE-Q>
GGE-Q는 shorcut bias에 대해서 question-only branch만 사용한 버전입니다. Figure2(c)를 보시면, labelled answer이 있는 question-only branch를 최적화합니다.
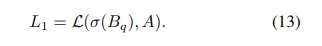
기본 모델의 loss는 아래와 같습니다.
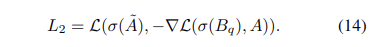
GGE-DQ는 distribution bias와 shortcut bias를 동시에 사용한 버전을 의미합니다. Figure2(d)를 보시면, $B_q$에 대한 loss는 아래와 같습니다.
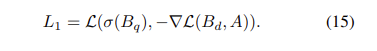
기본 모델에 대한 loss는 아래와 같습니다.
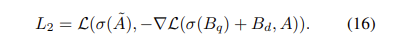
$L_1, L_2$에 대해 GGE-iter, GGE-tog를 모두 테스트를 수행합니다.
<Connecting to Boosting>
부스팅은 분류 문제를 해결하기 위해 널리 사용되는 앙상블 전략을 말하는데요. 부스팅은 많은 약한 분류기들(즉, 정확도가 완벽하지 않은 모델들)을 결합하여서 하나의 강한 분류기를 만드는 방법을 의미합니다. 각 약한 분류기는 데이터의 특정 부분에 초점을 맞춰 학습하며, 이들을 결합함으로써 전체적으로 강력한 예측 성능을 가진 모델을 만들게 됩니다. 신경망은 아주 강력한 모델이기 때문에 전통적인 부스팅 방식에서 요구하는 ‘약한 학습자’로서의 역할을 하기 힘듭니다. 신경망은 쉽게 과적합이 될 수 있고, 이는 부스팅의 기본 전제와 상충되기 때문입니다. 이 논문에서는 신경망의 이러한 과적합 경향을 활용하여, 의도적으로 bias된 feature에 대해 과적합되게 함으로써, 이를 제어하는 새로운 방식의 부스팅을 제안하는데요. 테스트 단계에서는 bias된 모델들의 영향을 제거한 기본 모델만을 사용하여 prediction을 수행하게 됩니다.
이러한 방식을 Batch SGD에 적용하기 위해서 두가지 전략이 설계되었는데, GGE-iteration과 GGE-together입니다. 위에서 언급한 그 둘이 맞습니다. 이 전략들을 이용해 bias된 모델과 기본 모델을 동시에 최적화하며, 학습 과정에서 모델이 데이터의 다양한 측면을 효과적으로 학습하도록 합니다.
<Experiments>
실험은 language-bias에 민감한 VQA-CP v2와 표준 데이터셋인 VQA v2에서 이뤄졌습니다.
<Evaluation Metrics>
각 모델에 대해서, 정확도를 비교하여 성능을 확인할 것인데요. 이는 표준 VQA 평가 지표라고 말할 수 있습니다. 그러나 앞에서 분석한 바에 따르면, 좋은 정확도만으로 모델이 시각적으로 잘 근거를 두고 있다는 것을 나타내기에는 충분하지 않았었죠. 이를 위해서 본 논문의 저자들은 다른 평가 지표가 있어야 할 필요성을 느끼고 정확도 말고도 다른 평가지표를 사용하는데요.
[45]에서는 VQA에서 시각적 근거를 정량적으로 평가하기 위한 새로운 지표인 정확하게 예측되었지만 부적절하게 근거된 (CPIG)가 제안되었습니다. 어떤 인스턴스가 정답을 위한 ground-truth 영역(예: HAT [22])이 모델의 상위 N개 가장 민감한 시각적 영역 안에 있는 경우, 올바르게 근거된 것으로 간주됩니다. 편의상, 우리는 1 − CPIG를 CGR(올바른 예측을 위한 정확한 근거)로 정의합니다:
[45] 논문에서는, Correctly Predicted but Improperly Grounded (CPIG)가 VQA에서 시각적 근거를 정량적으로 평가하기 위한 metric으로 제안되었습니다. 어떤 인스턴스가 정답을 위한 ground-truth 영역이 모델의 상위 N개 가장 민감한 시각적 영역 안에 있는 경우, 올바르게 근거된 것으로 간주됩니다. 편의상, 1-CPIG를 CGR(Correct Grounding for Right prediction)로 정의합니다.
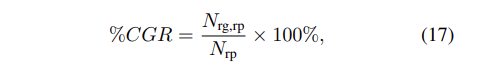
여기서 $N_{rp}$는 정답 예측의 총 개수이고, $N_{rg,rp}$는 올바른 시각적 근거와 함께 정확하게 대답된 인스턴스의 수를 의미합니다.
하지만 뒤에 성능을 보시게 되면, CGR 만으로는 모델간의 차이를 충분히 구별하기 어려울 수 있습니다. 즉, 모든 모델이 비슷한 CGR을 가질 수 있기 때문에, 그 모델이 분류에 시각적 정보를 충분히 사용하고 있는지 정량적으로 평가하기 위해 CGW(Correct Grounding but Wrong prediction)를 사용합니다.
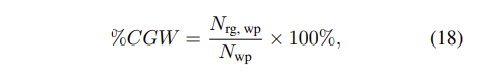
여기서 $N_{wp}$는 잘못된 예측의 수이고, $N_{rg,wp}$는 모델이 올바른 시작적 증거를 제공하지만 잘못된 예측을 한 인스턴스의 수 입니다. 논문의 저자는 CGR과 CGW의 차이를 이용하여 CGD(Correct Grounding Difference)를 최종적으로 사용합니다.
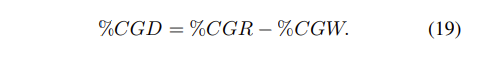
<Comparison with SOTA methods>
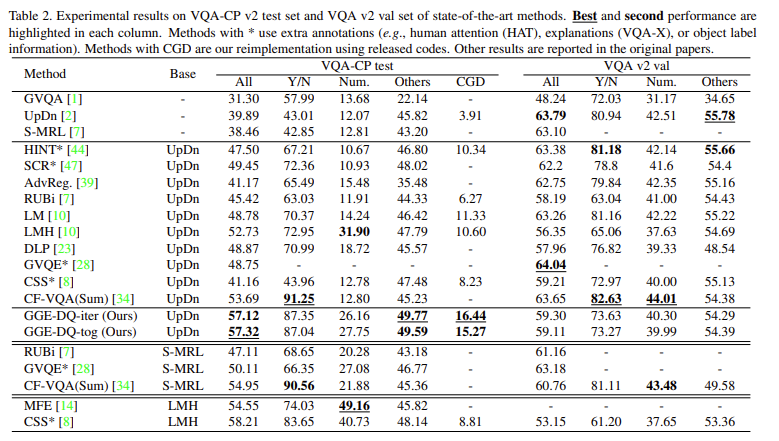
자 길었습니다. 그러면 직접적으로 성능 비교를 해보겠습니다. Table2를 통해서 그 성능을 확인할 수 있습니다. VQA-CP test set에 대한 실험은 VQA 모델이 language bias를 효과적으로 줄이는지 평가하는 것을 보여주는데요. Table 2에서 볼 수 있듯이 GGE-DQ가 추가 annotation 없이도 SOTA를 달성한 것을 확인할 수 있습니다. baseline 모델인 UpDn보다 정확도에서는 17%, CGD에서는 13% 더 높은 성능을 보이며, 이는 답변 분류와 시각적 근거 능력 모두에서 GGE가 효과적임을 입증합니다.
이렇게 논문 리뷰를 마쳐봤습니다. 이 논문을 읽으면서 분석 논문이 아닌가 싶을 정도로 논문의 저자들이 기존 문제점을 확실히 분석하였고 정확히 파악하였구나 느꼈습니다. 읽으면서 나는 이렇게 실험할 수 있을까 싶을정도로 꼼꼼해서 대단하다는 말이 저절로 나왔네요. 그럼 이만 마무리하겠습니다. 읽어주셔서 감사합니다.
[45] Robik Shrestha, Kushal Kafle, and Christopher Kanan. A negative case analysis of visual grounding methods for VQA. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8172–8181, Online, July 2020. Association for Computational Linguistics. 2, 3, 5
안녕하세요, 좋은 리뷰 감사합니다.
전반적으로 VQA의 문제점인 bias를 다루기 위해 최적화 부분을 다루는 내용이라 되게 어렵게 느껴지네요.
간단한 질문을 하나 드리자면,
부스팅을 사용하는 부분은 어떻게 사용이 되는 건가요? 정확도가 떨어지는 분류기를 대상으로 부스팅을 통한 앙상블을 사용한다고 되어있는데, 분포를 기반으로 동작하는 건가요?
약한 분류기는 어느정도의 정확도를 말씀하시는 건지 궁금합니다. 해당 VQA task를 수행하기 힘든 정도를 의미하는 건가요?
감사합니다.