안녕하세요, 허재연입니다. 오랜만에 Representation Learning 논문을 들고 왔습니다. Representation Learning은 data 부족 및 학습 비용 절감을 해결하고자 하는 방법 중 하나로, self-supervised learning, unsupervised learning의 하위 분야로 볼 수 있습니다. 딥러닝 학습법이 발전하며 많은 성과를 보이고 있는데, 성공적인 딥러닝 개발의 핵심에는 항상 풍부한 데이터가 있었습니다. 일반적으로 모델 엔지니어링을 수행하는 것보다는 더 많은, 더 좋은 데이터를 학습에 사용하는 방법이 더 많은 성능 개선을 이루어 낼 수 있습니다. 하지만 우리에게는 항상 데이터가 부족합니다. 우리가 원하는 task에 알맞게 데이터를 수집하고 라벨링 하는 금전적/시간적 자원이 많이 소모되기 때문입니다. 특히 데이터를 단순히 수집하는 것보다는 라벨링하는 과정에서 많은 예산 및 시간이 소모됩니다. 기존에는 imagenet 등 큰 데이터셋으로 supervised learning된 파라미터들을 transfer learning하는 방법을 많이 사용하였지만, 이 방법에도 한계가 있습니다. 이에 따라 ML/AI 연구자들은 해당 문제를 극복하기 위해 다양한 연구를 수행하고 있습니다. Active Learning은 라벨링 예산이 한정되어 있을 때 최대한 모델 학습에 효과가 좋은 고가치 데이터를 선별하고자 하며, Semi-Supervised Learning은 수도라벨링 등의 방법을 통해 적은 수의 라벨만으로 학습하는 방법을 연구합니다. 그리고 Self-supervised learning이나 Unsupervised Learning은 주어진 GT label 없이 데이터의 정보를 최대한 모델이 확보하게 합니다. 이 또한 다양한 방법으로 수행됩니다.
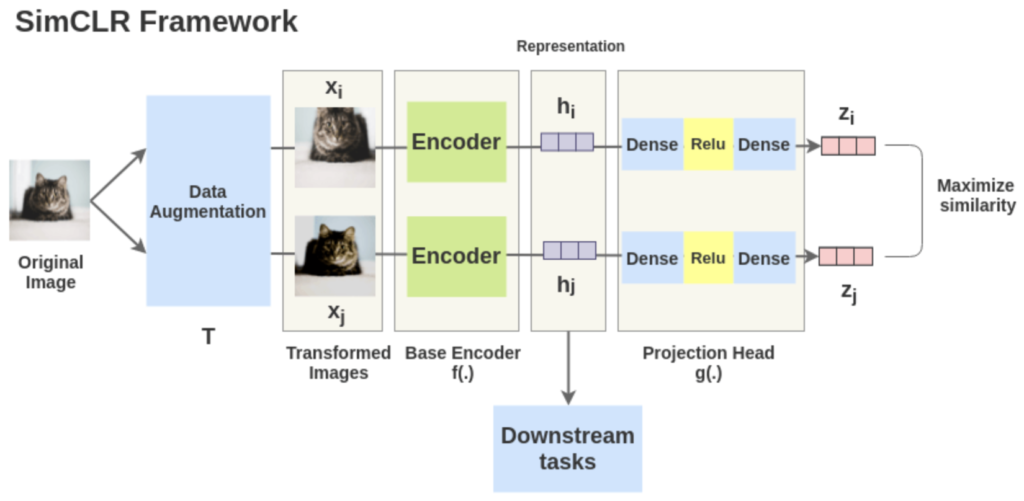
예를 들어, 이전에 리뷰한 SimCLR의 경우에는 contrastive learning을 이용해 Self-supervised learning을 진행합니다. 하나의 이미지를 서로 다르게 augmentation한 이미지 쌍인 positive pair는 벡터 간 거리가 가깝게, 그리고 서로 다른 이미지 쌍인 negative pair는 벡터 간 거리가 멀어지게 학습을 진행합니다. contrastive learning을 하는 과정에서 모델이 데이터에 대한 표현력(representation)을 확보하길 기대하고, 사전학습이 끝나 데이터에 대한 표현력을 확보한 모델을 downstream task에 fine-tuning하여 사용합니다.
SimCLR가 contrastive learning을 이용한 사전학습으로 representation learning을 진행했다면, 사람이 설계한 다른 handcraft 방법으로 사전학습을 진행할수도 있습니다.
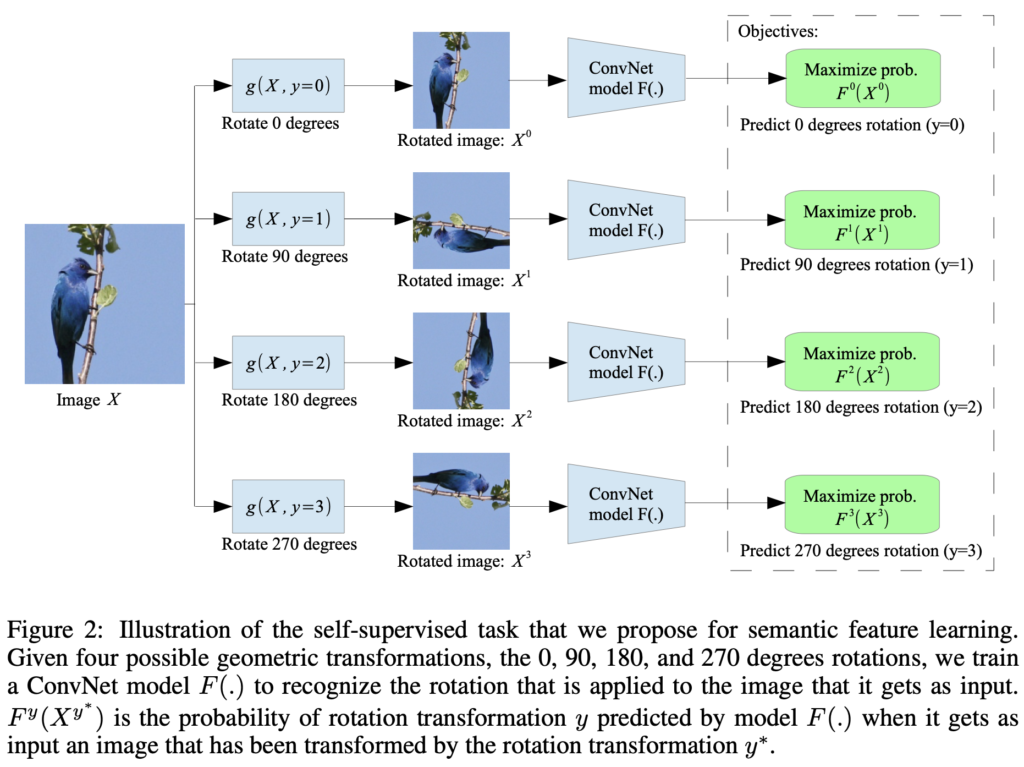
위 그림은 ICLR 2018에서 제안된 self-supervised learning 방법으로, 이미지 데이터에 대해 무작위로 0, 90, 180, 270도의 rotation을 수행한 후, 이미지 rotation이 얼마나 되었는지 각도 맞추기 학습을 진행합니다. 회전 각도를 맞추는 사전학습 과정에서 모델은 이미지 데이터의 표현력을 어느 정도 확보할 수 있습니다. 여기에는 GT label이 주어질 필요 없이 사전학습 모델이 스스로 라벨(이미지가 회전한 각도)을 생성해 학습을 진행합니다. 오늘 리뷰할 논문은 이렇게 사람이 직접 설계한 pretext task로 사전학습을 하는 방법을 제안합니다. 이 방법들 이외의 대표적인 pretext task로는 이미지의 원래 색상을 추론하는 colorization, 이미지를 패치 단위로 잘라 서로 간의 관계를 맞추는 context prediction, 이미지 중간을 drop하고 해당 부분을 채우게 하는 image inpainting 등이 있습니다. 오늘 리뷰에서는 퍼즐을 푸는 pretext task를 이용한 unsupervised learning을 살펴보겠습니다.
Introduction

본 논문에서는 self-supervised learning의 한 종류로 jigsaw puzzle을 푸는 pretext task를 통해 Visual Representation Learning을 수행하는 방법을 제안합니다. 해당 방법은 GT label 없이 수행할 수 있으며 사전학습이 끝난 backbone model은 image classification이나 object detection같은 다양한 downstream task에 finetuning하여 사용될 수 있습니다. 저자들은 Jigsaw puzzle을 푸는 사전학습 방식은 이미지 데이터 전체의 맥락과 로컬 특징을 함께 고려해야 하기 때문에 상당히 좋은 표현력을 얻을 수 있다고 주장합니다. 그리고 사전학습의 목적이 jigsaw puzzle을 푸는 모델을 만드는것이 아닌 좋은 feature를 학습하는 것임을 강조하며, 모델(backbone으로 Alexnet을 바탕으로 사용합니다)이 풍부한 feature를 고루 학습할 수 있게 하기 위해 단순히 퍼즐을 푸는데 shortcut이 될만한 low-level 단서들(인접 픽셀 간의 맥락이라던지)을 최대한 배제하도록 설계하였습니다. 퍼즐을 풀면서 학습한 특징들을 transfer learning하여 classification, detection task에서 성능을 측정했으며, ImageNet 데이터로 supervision 방식으로 사전학습된 모델보다 성능은 뒤떨어지지만 퍼즐을 풀면서 학습된 특징들이 classification과 object detection 문제에서 유의미한 정보를 갖고 있다는 것을 보여줍니다(성능이 떨어지기는 하지만 imagenet과 달리 GT label 없이 사전학습 했다는 점에서 의의가 있습나다)
Solving Jigsaw Puzzles
The Context-Free Architecture
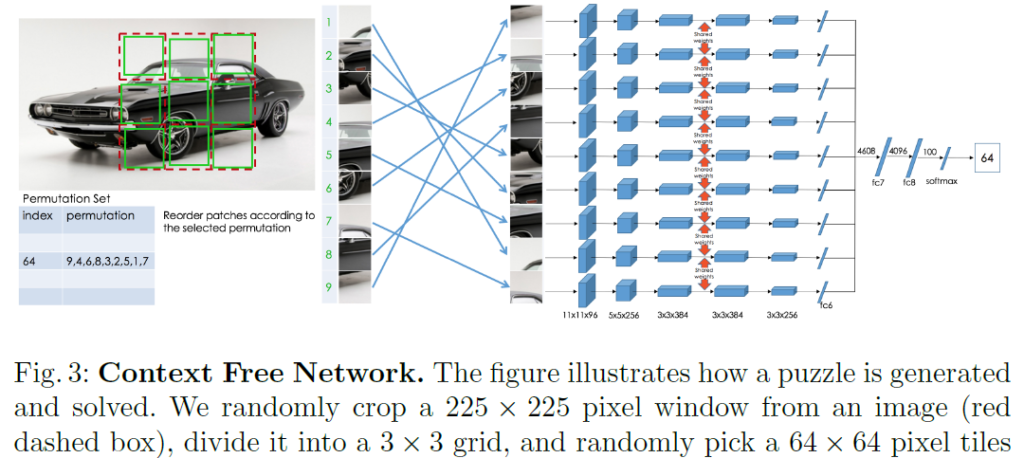
저자들은 첫번째 fc layer(Fig3에서 fc6)까지 가중치를 공유하는 Siamese-ennead convolutional network를 사용합니다. 샴 네트워크는 샴 쌍둥이를 연상하면 되는데요, 신체의 일부를 공유하는 샴 쌍둥이처럼 샴 네트워크는 가중치를 공유하는 네트워크입니다. 이렇게 설계한 이유는 convolution layer에서는 물체의 맥락을 고려하지 않게 image feature만 학습시키고(shortcut 방지) 연산량을 줄이기 위해서라고 합니다. 샴 네트워크는 처음 보는 개념이었는데, 이 블로그 글을 보고 감을 잡았으니 관심있으신 분들은 한 번 보셔도 좋을 것 같습니다. 네트워크 이름도 shortcut이 되는 context를 최대한 덜 고려하게 학습하겠다는 의미로 Context-Free Network(CFN)라고 이름 지었습니다(퍼즐 위치 관계는 fc6의 output들을 concat한 fc7부터 고려되기 때문에 그 이전까지는 context가 완전히 분리되어 학습됩니다). imagenet 데이터를 활용하여 Alextnet으로 학습 시킬 때는 1. 이미지에서 225×225 크기로 이미지를 random drop 한 뒤 2. 3×3 grid로 분할하고(각 grid는 75×75 pixel cell) 3. 인접 픽셀간의 관계가 shortcut이 되는것을 방지하는 gap을 만들기 위해 9개의 75×75 cell에서 64×64 pixel tile을 추출하고 4. 이 9개의 tile들을 무작위로 순서를 바꿔 CFN으로 전달합니다. CFN은 가중치를 공유하는 9개의 CNN으로 이루어져 있으며 각 CNN은 1개의 tile을 입력 받은 것입니다. 5. fc6을 거친 feature vector는 concat되어 fc7로 전달되며, 최종적으로 CFN은 9개 tile의 순서를 반환합니다. 이 이외에도 shortcut이 될만한 요소들을 없애기 위해 추가적인 augmentation이 들어갑니다(인접 색상 정보를 완화하기 위해 tile별로 따로 normalize를 하거나, RGB채널의 chromatic aberration을 이용하는 것을 방지하기 위해 grayscale image로 만들기도 합니다).
Experiment
저자들은 퍼즐풀기로 학습된 특징들에 대한 성능을 측정하기 위해 PASCAL VOC로 classification, detection, semantic segmentation에 적용해봅니다. CFN에서 AlexNet으로 중간 구조가 다르지 않은 부분들에 대해 transfer learning을 하여 fine-tuning합니다.

결과적으로 기존의 방법들과 비교해 classification, detection, segmentation 모든 task에서 상당히 개선된 결과를 얻을 수 있었습니다.
일반적으로 백본 모델에서 중간까지는 data의 general한 feature를 학습하고, 말단에서 task를 수행하게 학습된다고 알려져있다고 합니다. 저자들은 어디서부터 task와 관련된 학습을 하기 시작하는지 알기 위해 각 layer에 lock을 걸어보며 실험했다고 합니다. 학습은 imagenet classification으로 진행되었고, lock이 걸렸다고 표시된 레이어까지는 freeze되었으며 그 뒤 layer는 랜덤 초기화되어 학습했다고 보시면 됩니다.
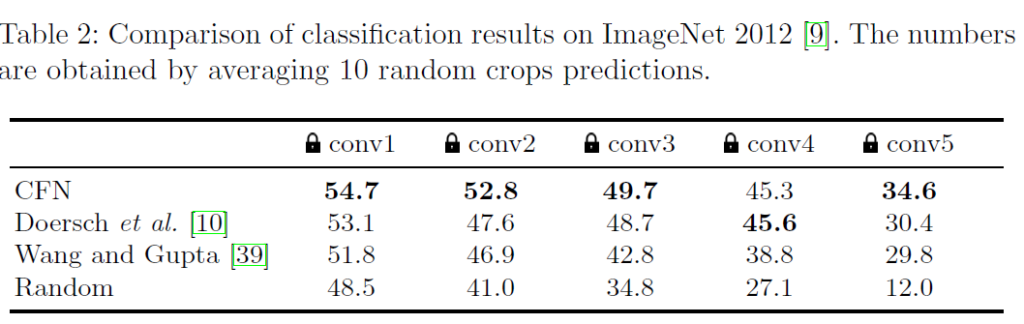
conv4->conv5로 넘어갈 때 classification accuracy가 낮아지는것을 확인할 수 있습니다. 저자들은 이것을 바탕으로 conv5 layer부터 퍼즐 풀기 작업에 특화되기 시작했다고 해석합니다.
preventing shortcuts

저자들은 직소퍼즐을 푸는데 도움이 될 수 있는 shortcut 요소들을 ablation study하며 관계를 살펴보았습니다. shortcut이 될 수 있는 요소들을 방지하면 detection performance가 올라가는것을 통해 pretext task가 어려워질수록 사전학습 단계에서 좋은 representation을 얻을 수 있음을 확인했습니다. edge continuity를 방지하기 위해 tile간 gap을 두었고, chromatic aberration(색수차)를 이용하는것을 방지하기 위해 grascale image를 학습에 포함시켰습니다(grayscale과 color 데이터 비율 3:7). 추가적으로 각 타일의 색상 채널에 random color jittering도 적용시켰습니다.
image retrieval
저자들은 간단한 image ranking으로 image retrieval을 이용하여 feature의 품질을 평가했습니다. PASCAL 데이터셋에서 test set의 bounding box를 쿼리로 사용하고 pool5의 feature에서 최근접 이웃법을 사용했습니다.

Fig5는 정성적으로 top-4 retrieval을 확인한 것이고, Fig6은 정량적으로 비교를 수행한 것입니다. Fig5에서 (a)는 쿼리 이미지, (b)는 AlexNet, (c)는 색수차를 block하지 않고 학습한 CFN의 결과이며 그 뒤에는 다른 논문이 비교군입니다.
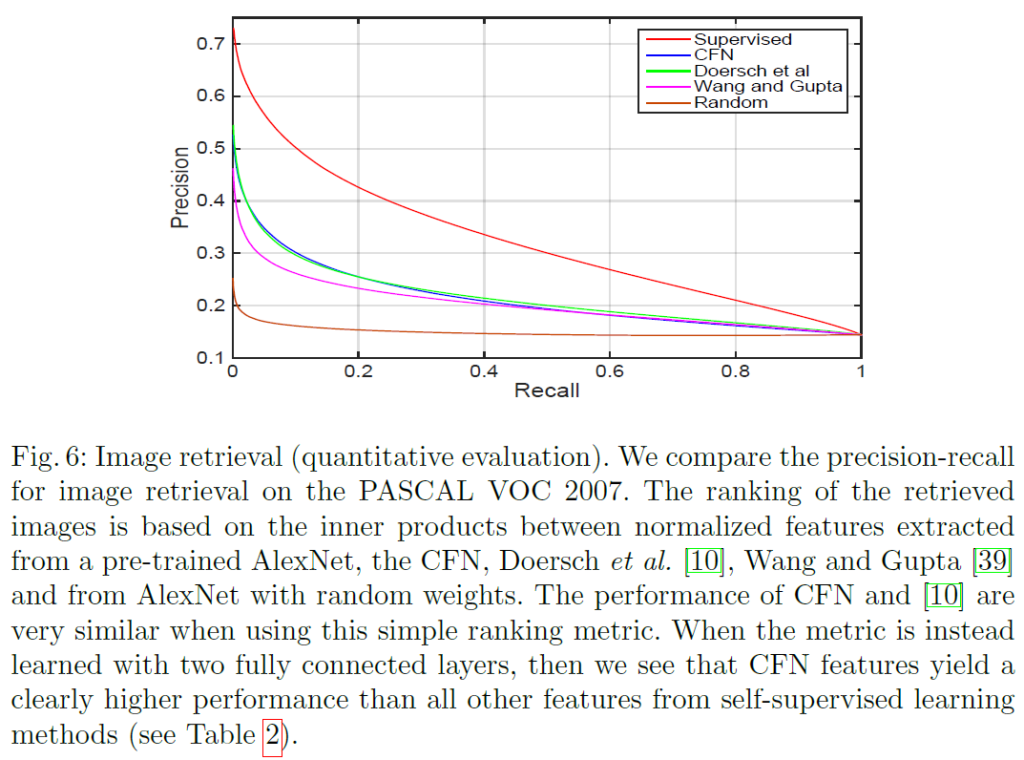
Fig 6을 보면 CFN이 self-supervised learning 방법들 중 상당히 좋은 성능을 보여주는것을 확인할 수 있습니다.
Conclusion
저자들은 Context-Free Network를 이용해 직소퍼즐을 푸는 pretext task를 사용하면 unsupervised representation learning 방법을 제안했습니다. 사전학습된 feature는 detection, segmentation, classification에서의 실험 결과 (상당히 예쩐이긴 하지만) 기존 방법론들을 뛰어넘는것을 보였습니다. 당시에는 unsupervised learning이 supervised pretraining 성능을 따라잡기 전이기 때문에 이 둘 사이 간극을 좁히는 것을 의의로 둔다고 합니다.
안녕하세요. 허재연 연구원님. 좋은 리뷰 감사합니다.
Representation learning 초기 연구에는 정말 특이한 방법도 있었군요… 신기합니다.
최근에는 이러한 방법을 전혀 보지 못한 걸로 미루어보건데, 결국 이 방법보다 더 좋은 다른 방법이 등장하였기에 최근에는 사용되지 않는 것이겠지 싶은데, 그러면 이 논문에서 비교한 이전 논문 2개는 각각 어떤 방법인지(저희가 알만한 방법인지), 이후에 연구는 어떤 흐름으로 진행되었는지 간단히 여쭤보고 싶습니다!
감사합니다.
self-supervised learning을 크게 분류하면 1.본 리뷰에서 다룬 pretext task계열, 2. Moco,SimCLR같은 contrastive learning계열 3.GAN 등 생성 모델을 이용한 방법론들, 4.최근 SOTA인 Masked Autoencoder 정도로 나눌 수 있을 것 같습니다. 저도 2010년대 후반에는 pretext task 논문이 거의 나오지 않아서 찾아봤었는데 contrastive learning 계열 방법론들이 워낙 좋기 때문에 주도적인 연구 흐름이 이쪽으로 넘어오게 된 것 같습니다. 최근에는 ViT기반 MAE가 좋은 성능을 보이기 때문에 주목받고 있습니다.
experiment에서 비교한 2가지 방법론들도 pretext task를 활용한 사전학습 방법으로 보입니다. 각각 [ICCV2015]Unsupervised visual representation learning by context prediction, [ICCV2015]Unsupervised learning of visual representations using videos이라는 논문인데 첫번째 논문은 이미지 패치 간의 위치 관계를 예측하는 context prediction을 이용한 pretext task를 이용하는 것으로 보이고, 두번째 방법은 저도 처음 보는 논문이어서 잘 모르겠습니다.
감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
self-supervised 관련 연구에는 너무 다양한 테스크들이 많은 것 같습니다. 이렇게 여러 방면으로 활용이 되니 꾸준히 연구가 발전하는 것이 느껴지네요.
간단한 질문 2가지만 드리자면,
1. 2016논문인데 AlexNet을 기반으로 사용된 이유가 궁금하네요. VGG, ResNet이 그 전년도에 나온 것으로 알고 있는데 이는 좋은 백본을 사용하지 않음에도 불구하고 이정도를 보여준다는 의미로 봐야하는지 궁금합니다.
2. intro를 들어가기 전, “Self-supervised learning이나 Unsupervised Learning은 주어진 GT label 없이 데이터의 정보를 최대한 모델이 확보하게 합니다.” 라고 되어 있는데 데이터가 좀 많이 있어야 모델이 feature를 학습하는 것에 용이해보입니다. 해당 논문에서 사용되는 데이터셋은 어느정도 규모로 데이터가 주어지는 건지 궁금합니다. 성능이 매우 뛰어난 걸 보아 충분히 feature를 골고루 학습할 만큼 주어지나요??
감사합니다.
1. 사실 저도 읽으면서 그 부분이 궁금하였는데 논문에 딱히 다른 언급이 없었습니다. 아무래도 16년 논문이면 논문 작성 및 실험은 14,15년도에 진행하였을텐데 그때 시점에서 새롭게 나온 모델들보다는 잘 알려져있던 Alexnet을 사용한것이 아닐까 합니다. 또한, 기존 방법론들과 실험 비교를 통해 성능이 개선되었다는것을 밝혀야 했을 텐데, 비교하게 되는 논문들이 백본을 최신 백본을 쓰지 않았기 때문인것으로 보입니다.
2. 데이터셋으로는 PASCAL과 ImageNet(1.3M)을 사용합니다. 보통 self-supervised learning의 경우 데이터에 라벨이 필요하지 않다보니 실제로 큰 규모의 데이터를 활용할 수 있는 경우가 많습니다.
감사합니다.
안녕하세요 재연님 좋은 리뷰 감사합니다.
저는 논문을 읽으면서 Context-Free Network(CFN) 부분에서 이해가 안되는 부분이 있었습니다. 모델의 task가 직소 퍼즐을 푸는 일이기 때문에 9개의 타일에 대한 순서가 최종 output으로 되어야할 것 같은데 모델 구조도 그림을 보시면 최종 output이 64로 되어있습니다. 여기서 모델은 최종적으로 어떠한 값을 출력하는건가요??
감사합니다.
해당 네트워크의 task는 사전 정의된 permutation의 index를 예측하는 것입니다. 타일을 어떻게 섞냐에 따라 다양한 permutation이 나올 수 있는데, 저자들은 기술적 한계로 모든 permutation을 다 사용하지 않고 일부만 사용했습니다. output의 64는 사전 정의된 permutation 중 하나를 인덱싱하는 출력이라고 생각하시면 될 것 같습니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
본 논문에서 물체의 맥락을 고려하지 않게 image feature만 학습시키기 위해 샴 네트워크를 사용했다고 하셨는데, 이후 직소 퍼즐을 푸는 pretext task관련 논문들도 샴 네트워크를 사용하는것이 일반적인가요 ? 이외에 어떤 경우에 샴 네트워크를 사용하는지 궁금합니다.
또, chromatic aberration이 뭔가요 ? chromatic aberration를 block했다는 의미가 무엇인지 궁금합니다. chromatic aberration를 이용하는 것을 방지하기 위해 grayscale 이미지를 학습에 포함시켰다 했는데, 이 grayscale 영상을 포함하지 않았을 때의 ablation study 결과는 없나요 ?
감사합니다.
일단 직소퍼즐 관련 연구가 그리 활발하지 않기 때문에 이렇다 할 후속 논문이 많지는 않습니다만, 이후에도 샴 네트워크를 사용하지는 않는 것 같습니다. 아예 ViT를 사용하는 등 완전히 다르게 문제를 해결하는 듯 합니다(논문 게재 텀도 깁니다). 샴 네트워크에 대해 제가 자세히는 알지 못하지만, 원래는 one-shot learning을 위해 개발되었으며( [ICML2015]Siamese neural networks for one-shot image recognition ) 소량의 데이터로도 학습이 가능하다는 장점이 있다고 합니다.
chromatic aberration(색수차)는 영상을 취득할 때 렌즈의 왜곡으로 인해 발생하는 색상 왜곡의 일종입니다. 가시광선(전자기파)는 색상(파장 대역)마다 굴절률이 다르므로, 영상 데이터를 취득할 때 렌즈에 의해 굴절된 빛들이 색상 불일치를 만들게 됩니다. 사진의 중앙부와 가장자리는 색수차의 정도가 다르므로, 모델이 이런 색수차 컬러 정보를 cue 삼아서 퍼즐을 해결하는것을 막고자 augmentation을 수행했다고 생각하시면 됩니다. 이를 방지하는 기법 중 하나인 color jittering의 ablation study 결과는 리포팅되어있는데, grayscale 포함 여부에 관련해서는 따로 언급이 없습니다.
감사합니다.