안녕하세요, 이번에도 데이터셋 논문입니다.
기존 6D pose estimation 테스크에서 사용되었던 YCB-V라는 데이터셋의 단일 센서가 아닌 여러 센서를 통해 취득한 데이터셋입니다. YCB는 Yale-CMU-Berkeley의 약어로 3개의 대학에서 공동으로 개발된 데이터셋이라고 하네요. YCB에 있는 물체들을 이용하여 촬영한 데이터셋을 PoseCNN의 논문에서 YCB-V를 제안하였고 6D pose estimation의 대표적인 데이터셋이라고 할 수 있습니다.
논문 리뷰 시작하겠습니다.
Introduction
Kinect v1, ASUS Xtion과 같은 1세대 RGB-D 카메라는 이제 사용할 수가 없습니다.
최근에는 이를 대체할 수 있는 다양한 3D 카메라가 출시되고 있는데요. 각 센서마다 depth를 만드는 기법들은 크게 3가지로 나눌 수 있습니다.
- Structured Light(SL)
- ToF(Time of Flight)
- active stereo
depth를 생성하는 기법에 대한 차이뿐만 아니라, range, FOV, 크기, 전력 소비 등 여러 측면에서 차이가 있습니다. 로봇이 사용되는 요구 사항이 서로 다르기 때문에 예를 들어 manipulator에는 깊이 해상도가 좋은 고해상도 RGB-D 카메라가 필요할 수 있지만, 소형 디바이스에 들어가려면 전력 소비가 적거나, 크기가 작은 센서를 필요합니다. 하지만 제조업체의 사양만으로는 적합한 카메라를 선택하기 어렵고, 여러 대의 카메라를 구입하고 설치하는 데는 많은 비용과 노동력이 소요됩니다.
이러한 이유로 7개의 서로 다른 3D 카메라에서 취득한 RGB와 depth 정보를 포함하는 YCB-Multicam(YCB-M)을 제안합니다. 해당 데이터셋은 각 49,294개의 프레임에 있는 각 물체에 대한 GT 6D pose에 대한 annotation 정보가 구성되어 있습니다.
YCB-M dataset
이제 본격적으로 YCB-M에서 데이터 취득과 GT annotation을 어떻게 하였으며 센서팩을 구성에 대해 알아보겠습니다.
1. Data Acquisition

이번 데이터셋의 경우, YCB[1] 논문의 그림을 가져와봤습니다. 위의 그림에 있는 물체들에 대해 32개의 scene들로 녹화하여 구성되어 있으며 기존의 YCB-V, FAT 데이터셋에서 사용된 물체들과 동일하게 구성하였다고 하네요. 녹화된 영상에는 다양한 occlusion 정도를 가진 물체가 나오도록 배치를 하였고, 또한 마커보드를 사용하므로 영상 내에는 모든 scene마다 구성되어 있습니다. 카메라 간의 변환을 일정하게 유지하면서 다양한 시점에 대한 데이터를 제공하기 위해 카메라를 end-effector에 장착을 하여 진행을 하였다고 하네요.

그림(1)의 왼쪽을 전체적인 셋업을 확이할 수 있습니다. 또한 end-effector에 카메라를 장착하였으므로 로봇팔이 움직이는 위치에 따라 촬영을 진행하게 됩니다. 따라서 카메라 간의 변환을 일정하게 유지한다는 의미는 사전에 정해진 궤적을 따라 로봇팔이 움직이는 것을 의미합니다.
이상적으로는 동기화를 통해 모든 카메라를 통한 데이터가 동시에 캡처/녹화가 되는 것을 목표로 합니다. 하지만, 저자는 동기화를 해버리면 결국 카메라 간의 간섭이 있기 때문에 depth 데이터의 퀄리티가 떨어질 수 있다고 하네요. 따라서, 궤적을 움직이는 것을 여러 번 수행하여 한 번에 한 대의 카메라만 촬영을 활성화하여 2가지로 나누어 취득을 진행하였다고 합니다.
- 로봇팔이 각 앵커포인트(특정 위치)에서 멈추고 각 카메라에서 한 프레임씩 차례로 녹화를 진행한다.(snapshot) – 1번 반복
- 로봇팔이 간섭을 피하기 위해 단일 카메라로 모든 앵커 포인트를 멈추지 않고 이동하면서 녹화를 진행한다.(trajectory) – 7번 반복
[1] 1. B. Çalli, A. Singh, A. Walsman, S. S. Srinivasa, P. Abbeel, and A. M. Dollar, “The YCB object and model set: Towards common benchmarks for manipulation research,” in International Conference on Advanced Robotics,ICAR2015,Istanbul,Turkey,July27-31,2015. IEEE,2015, pp. 510–517.
2. Ground Truth Annotation
RGB-D로 제공되는 YCB-M 데이터셋은 모든 프레임에 대해 annotation된 데이터를 제공합니다. 각 물체의 6D pose와 segmentation, 2D/3D bounding box, 마커를 기준으로 하는 카메라의 pose로 구성되어있습니다. 또한 데이터셋에 사용된 3D 모델도 앞서 언급된 YCB-V와 FAT에서 가져온 모델을 그대로 사용하였다고 하네요. 제공되는 annotation 정보들을 통해 객체 reconstruction, semantic segmentation 또는 2D object detection과 같은 6D pose estimation 이외에도 다양한 테스크에도 적용할 수 범용성에 대한 어필을 하네요.
GT에 대한 annotation 정보는 scene당 한 번씩 기준이 되는 프레임에 대해서 모든 물체에 대해 6D pose를 수동으로 라벨링을 하고 각 이미지에 해당하는 카메라 프레임으로 pose를 변환하여 얻었다고 하네요. 그럼 수동으로 라벨링은 PoseCNN 모델을 사용하여 pose 추정의 예측 결과를 다듬는 식으로 진행을 했다고 하네요.
annotation 정보에 마커를 기준으로 하는 카메라의 pose도 구성되어 있다고 말을 했었는데, 해당 내용의 역할은 각 scene당 마커보드가 존재하므로 가능합니다. YCB-M에서 사용하는 마커보드는 ArUco라는 마커로 모양이 사전에 정의된 형태로 픽셀, 크기에 따라 여러 종류로 생성할 수 있습니다. 해당 데이터셋에서는 21개의 마커를 사용하여 기준(마커) 프레임으로부터 카메라에 대한 pose를 추정하여 모델로부터 물체에 대한 예측된 6D pose를 처음에 계산하여 다음 프레임부터는 각 프레임마다 카메라의 pose가 달라지는 만큼 물체의 pose 또한 변화하므로 이를 통해 전체적인 GT pose들을 구성하게 됩니다. 하지만 저자는 마커 기반의 카메라 pose 추정은 경우에 따라 부정확한 결과를 도출하는 경우가 있었다고 합니다. synthetic 포인트 클라우드와 카메라에 의해 취득된 scene 데이터 간의 일치를 통해 이루어진 작업을 설명하고 있습니다. synthetic 포인트 클라우드는 아마 각 RGB-D 센서에서 얻을 수 있는 걸 말하는 것 같습니다. RealSense 센서에서 녹화된 bag 파일을 풀면 나오는 포인트 클라우드로 이해하시면 될 것 같습니다.
그럼 segmentation과 2D bounding box는 어떻게 구성했을까요?
카메라 pose에 대한 물체의 6D pose와 물체의 크기로부터 3D bounding box를 통해 세 가지(visibility, segmentation, 2D bounding box)를 계산할 수 있는데요. 먼저 visibility는 카메라의 viewpoint에서 3D 모델의 synthetic으로 depth 를 GT pose로부터 렌더링하여 계산을 했다고 합니다. segmentation mask는 visiblitiy를 구하기 위해 얻은 depth 이미지에서 물체에 속하지 않은 영역을 의미합니다. GT pose가 조금이라도 align이 맞지 않는 경우, 배경이나 다른 물체의 일부가 segmentaion mask에 포함될 수 있으므로 오차에 대한 특정 threshold가 0.04이상 차이가 나는 경우 해당 이미지는 제외시키는 방식으로 진행을 했다고 합니다. 2D bounding box는 개별적으로 렌더링된 각 물체의 synthetic depth 이미지를 통해 얻을 수 있게 됩니다.
각 물체의 visibility는 결국 occlusion의 정도를 의미하게 되는데요. 수식으로 나타낸다면 아래와 같이 나타낼 수 있습니다.
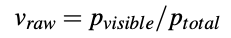
먼저 raw visibility를 구해야하는데, 이때 p_{total}은 각 물체에 대한 렌더링된 depth 이미지에서 물체가 차지하는 픽셀의 수를 의미하고 p_{visible}은 다른 물체와 생기는 occlusion이 생겼을 때에 대한 segmentation mask에서 물체가 차지하는 픽셀의 수를 나타냅니다. 하지만 v_{raw}는 카메라의 FOV에서 부분적으로 벗어난 경우에 대해 고려하지 않도록 하기위해 아래의 식으로 최종 visibility를 계산합니다.
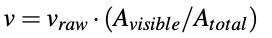
이미지 내에 있는 투영된 3D bounding box의 area(A_{visible})에 투영된 3D bounding box의 전체 area(A_{total})를 나누어 최종 visibility v를 구합니다. visibility==0인 물체는 해당 프레임에 대한 annotation에서 제외됩니다.
3. 3D Cameras in the Dataset
이번에는 각 카메라 센서에 대한 내용을 설명하는데요.

그림(2)는 각 센서에서 취득한 데이터셋의 구성 중 예시를 나타낸 그림입니다. 각 프레임이 촬영되는 동안 로봇팔은 정지 상태에서 진행되고, 각 센서마다 원근감에 대한 차이가 있는 것을 확인할 수 있는데 이는 카메라의 장착 위치가 모두 상이하고 내부적으로는 optics(RGB)가 다르기 때문입니다.
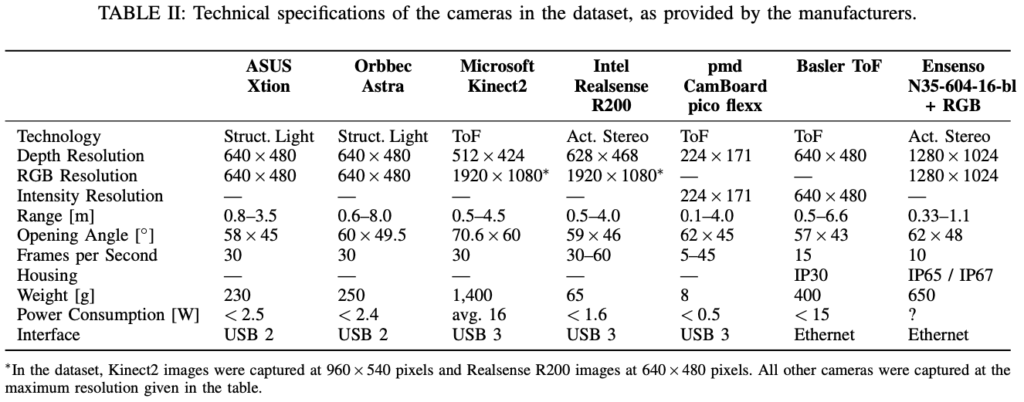
표(2)는 각 센서들의 스펙(?)을 나타내고 있습니다. 감사하게도 논문에서 센서에 대한 설명을 해놔서 정리하면 좋을 것 같아 작성해두겠습니다.
1) ASUS Xtion Pro Live(단종)
- SL 기반
- 다른 많은 센서에 비해 depth의 노이즈와 결측값이 적음.
2) Orbbec Astra
- SL 기반
- 사양, 소프트웨어 API 및 카메라 데이터가 Xtion과 거의 동일
- depth 또한 Xtion과 거의 비슷한 성능
- 특정 depth의 범위, depth의 불연속성, depth 이미지 테두리에서 artifact(홀을 의미하는 것 같음)가 생김
- 필터링을 통한 후처리 과정을 통해 해결 가능
3) Microsoft Kinect2
- ToF 기반
- 비교한 센서들 중에 가장 FOV가 넓음
- depth 퀄리티는 SL보다 떨어짐
- but, 2m 이상의 범위에서는 좀 더 정확함
4) Intel Realsense R200
- active stereo IR 기반
- 비교한 센서들 중에 가장 RGB 해상도가 가장 높음(Kinect2와 동일)
- depth 퀄리티는 SL보다 떨어짐
- 그림 2의 point cloud(detail)에 보면 울퉁불퉁함(평면성이 떨어짐)
- stereo matching에 실패하면 많은 양의 artifact발생
5) pmd CamBoard pico flexx
- ToF 기반
- RGB 센서 없음
- 해상도가 낮음
- depth 퀄리티는 Kinect2와 유사함
6) Basler ToF ES
- ToF 기반
- RGB 센서 없음
- 비교한 센서들 중에 depth 퀄리티 제일 낮음(노이즈, 결측값 많음)
7) Ensenso N35(N35-604- 16-bl)
- 근거리 active stereo (IR / visible blue light, 둘 중 하나의 projector 선택하여 사용) 기반
- uEye(RGB) +blue light projector를 사용했을 때 2번째로 depth 퀄리티가 좋았다고 함
Evaluation
해당 데이터셋의 유효성을 검증하기 위해 다양한 센서로부터 취득된 데이터를 가지고 DOPE[2] 모델을 통해 평가를 진행합니다.
저자는 이번 논문에서 진행한 평가 결과에 대해 먼저 카메라에 따른 편차(이미지나 depth 퀄리티)에 대한 주장을 하는 것에 적합하지 않다고 말을 합니다. 여기서 평가한 DOPE라는 특정 pose estimation 알고리즘이 다른 카메라에서 어떻게 작동하는지만을 보여주는 것이라고 합니다. DOPE에 대한 부연 설명을 하자면 단일 RGB기반의 detection을 수행하고 pose estimation을 수행하는 2-stage 기반의 방법론입니다. 이때 detection을 수행할 때는 depth를 고려하지 않는 점과 20개의 물체 클래스 중에 6개만 학습된 pretrain 모델이 존재하는 점과 pico flexx 및 Basler TOF 카메라는 RGB 이미지를 제공하지 않고 depth만 제공하므로 DOPE 모델을 적용할 수 없습니다.
위와 같은 문제가 있었기 때문에 저자는 fair comparison을 하기 위해 6개의 물체만 pretrained weight를 가져와서 평가를 진행하였고 fine-tuning은 따로 진행하지 않았다고 하네요.

그림(3)은 데이터셋에 해당하는 6개의 물체에 해당하는 샘플 프레임에 대해 DOPE를 적용하여 추정된 결과를 나타내는 그림입니다. FP가 생기는 원인은 주로 실제 물체의 스케일과 일치하지 않았다고합니다. 이러한 문제는 depth 정보를 이용한다면 물체의 절대적인 스케일과 비교하여 이러한 FP의 대부분을 처리할 수 있을 것 같습니다.
[2]
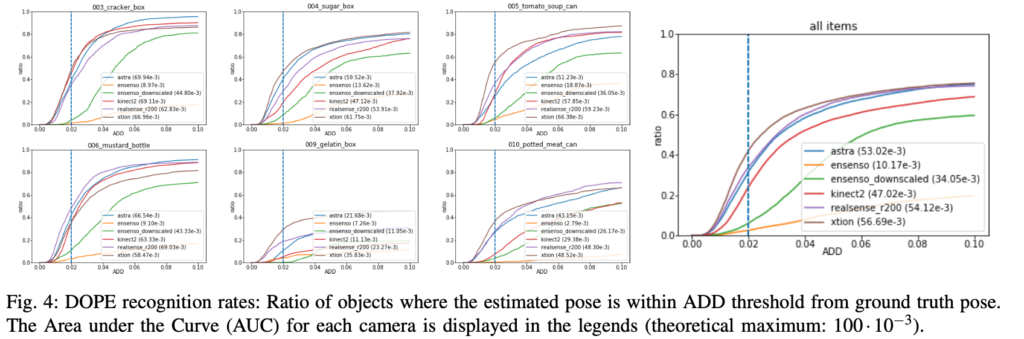
평가지표는 ADD를 사용하였으며 Basler ToF 및 pico flexx 센서는 평가에서 제외되었습니다. 그림(4)는 ADD를 계산하고 각 카메라에 대한 Area Under the Curve(AUC)을 계산한 것을 나타냅니다. 점선은 DOPE 논문과 같이 분석에 필요한 정확도를 나타내는 threshold(2cm)을 의미한다고 하네요.
ADD(Average Distance) : GT pose와 예측 pose에서 각 3D 모델에 대한 점 사이의 평균 거리
Conclusion
이번에는 6D pose estimation 뿐만 아니라 범용성을 위한 벤치마크 데이터셋인 YCB-M을 살펴보았습니다. 세 가지 주요 depth 추출 기법(SL, ToF, Active stereo)를 다루는 총 7가지의 3D 카메라로부터 취득된 데이터들이 구성되어 있습니다. 제안한 데이터셋을 이용하여 DOPE를 적용하여 여러 센서들에 대한 평가 결과까지 보여주었습니다.
이상으로 논문 리뷰 마치도록 하겠습니다.
감사합니다.
안녕하세요 희진님 좋은 리뷰 감사합니다!
본문의 Data Acquisition에서 ‘동기화를 해버리면 결국 카메라 간의 간섭이 있기 때문에 depth 데이터의 퀄리티가 떨어진다’고 하셨는데 카메라를 동기화시키면 동시에 작동하므로 다수의 카메라로 원하는 시점에서 데이터를 취득할 수 있는거 아닌가요? 여기서 말하는 카메라 간의 간섭이 무슨 의미인지 궁금합니다.
감사합니다!
안녕하세요, 리뷰 읽어주셔서 감사합니다.
동기화는 센서간의 신호를 주고 받으면서 같은 시간에 정보를 얻는 것이 목적이라고 볼 수 있습니다. 하지만 각 센서 간의 신호의 Hz가 다르다면, 이때 데이터의 손실이 발생할 수 있습니다. 이를 카메라 간의 간섭이라고 볼 수 있습니다.
감사합니다.