안녕하세요, 스물 두 번째 x-review 입니다. 이번 논문은 2022년도 CVPR에 게재된 포인트 클라우드와 이미지 정보를 융합하여 3D Object Detection을 수행하는 논문 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
당시 3D detection은 입력으로 포인트 클라우드만을 사용한 방법론들이 등장하고 있었습니다. 불규칙한 포인트 클라우드를 입력 데이터로 사용하기 위해서는 메쉬나 복셀 그리드처럼 일정한 형태로 변형하거나 voting 기법 혹은 pointnet과 같은 백본 네트워크를 통해 symmetric한 함수를 통과하는 등의 방법이 존재합니다. 그 중에서도 트랜스포머는 permutation invariance한 특징을 가지고 큰 규모의 데이터 사이의 관계를 파악할 수 있기 때문에 3D detection에서 눈에 띄는 성능 향상을 가지고 왔다고 합니다. 트랜스포머는 또한 많은 분들이 익히 아시듯이 detection에서도 사용되고 있죠. 이런 두 도메인에서 각각의 단일 모달리티 detection task에서는 활발하게 사용되면서도, 트랜스포머를 통해 두 모달리티의 장점을 합쳐서 사용하려는 시도는 극히 드물었다고 합니다. 3차원 인지 분야에서 포인트 클라우드는 기하학적인 정보를 제공하는 어떤 필수적인 데이터라고 할 수 있지만 컬러나 텍스처 정보는 존재하지 않는데, 이미지는 이러한 누락된 정보를 제공하면서 포인트 클라우드의 노이즈를 보완할 수 있습니다. 결론적으로 저자는 2D 이미지를 3D detection에 사용해야 한다고 말하고 있네요. 이렇게 2D 이미지를 사용할 수 있는 가장 직관적인 방법은 이미지에서 3차원 RGB 벡터를 추출하여 포인트 feature로 확장하는 것 입니다. 이러한 직관적인 방법을 활용한 대표적인 방법론이 CNN 기반의 ImVoteNet인데, 2D/3D 사이의 도메인 차이로 인해 발생하는 차이를 해결하기 위해 RGB 벡터를 추출하는 것이 아니라 사전학습된 2D 검출기에서 추출한 이미지 feature를 사용하였습니다. 그러나 이미 GF3D라는 방법론에서 ImVoteNet처럼 이미지/포인트 클라우드 voting 결과를 동시에 반영하면 발생하는 그룹화의 정확도 하락을 문제로 제시하였습니다. 또한 ImVoteNet은 첫번째 레이어에서 두 도메인의 feature을 합쳤는데, 이는 두 모달리티의 의미론적인 관계를 완전히 사용하거나 .. 흠
본 논문에서는 위와 같은 CNN이 아닌 트랜스포머 기반의 새로운 3D detection 모델인 Bridged Transformer (BrT)를 제안하게 됩니다. BrT는 트랜스포머 내에서 패치 단위로 주어지는 이미지와 샘플링한 포인트 클라우드의 학습 과정을 연결하게 됩니다. 각 포인트 클라우드와 이미지 패치 간의 어텐션 연산은 차단하면서 트랜스포머 레이어 전체에 사용되는 object query를 통해 연결할 수 있습니다. 연결하는 과정에서 이미지와 포인트 클라우드의 각 장점을 더 잘 활용하기 위해서 두 가지를 제안하였는데, 첫번째로 이미지와 포인트 클라우드에 대한 조건부 object query를 사용합니다. 두번째는 포인트와 패치 사이의 projection을 통해 두 모달리티의 공간적인 관계를 활용하였습니다. 이에 대한 내용은 method에서 더 자세하게 다루도록 하겠습니다. 결국 BrT는 글로벌한 정보를 활용하여 기존 CNN 기반 방법론에서 발생하던 그룹화 성능 하락을 방지하고, 이미지 feature을 첫번째 레이어에서 포인트 클라우드 차원으로 이동시키는 대신 트랜스포머를 통해 전체 네트워크에서의 propagation이 가능하게 합니다. 또한 추가적으로 BrT는 단일 이미지 뿐만 아니라 포인트 클라우드가 멀티뷰 이미지와도 합쳐질 수 있도록 확장 가능하다고 합니다.
여기서 본 논문의 mian contribution을 정리하면 다음과 같습니다.
- 트랜스포머 네트워크 내에서 이미지와 포인트 클라우드를 연결한 새로운 3D Object detection 프레임워크 제안
- 포인트 클라우드와 이미지 패치 projection과 조건부 object query를 활용한 이미지와 포인트 클라우드 연결 네트워크 설계
- SUN RGB-D와 ScanNetV2 데이터셋에서 SOTA 달성
2. Method
2.1. Overall architecture
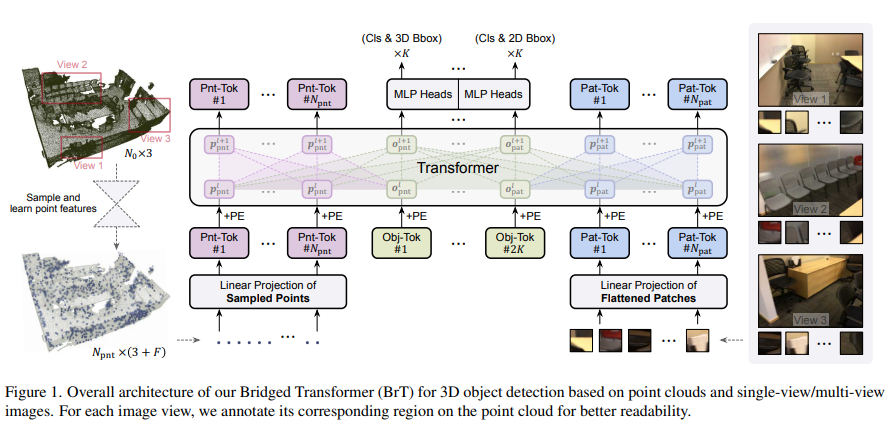
먼저 BrT의 전반적인 파이프라인을 살펴보면, N \times 3 포인트 클라우드와 H \times{} W \times 3의 이미지가 입력으로 주어집니다. 센서가 depth 포인트 클라우드 RGB 이미지를 동시에 취득한다는 시나리오를 기반으로 scene당 하나의 이미지를 이용하는데, 이는 scene당 여러 개의 이미지로의 확장이 가능함을 3.5절에서 다루고 있습니다.
먼저 포인트 클라우드 데이터를 트랜스포머 레이어에 태우기 전에 처음 입력으로 들어오는 N_0 \times 3개의 포인트를 N_{pnt} \times (3 + F) “시드 포인트”로 샘플링합니다. N_{pnt}는 샘플링한 포인트 클라우드의 개수를 의미하며 3과 F는 각각 3차원 유클리디언 좌표와 포인트 feature의 차원을 뜻합니다. 다음으로 이미지는 ViT의 과정을 따라 MLP로 임베딩되기 이전에 N_{pat}로 분할됩니다. 그러면 임베딩 된 이미지 패치와 함께 학습된 object query가 모델에 주어지면 바운딩 박스 좌표와 클래스를 예측하는데 사용되는 출력 임베딩을 생성합니다. 또한 2K개의 object query를 사용하는데 그 중 K는 포인트, 또 다른 K는 이미지 패치에 대한 query 입니다. 결국 N_{pnt} + N_{pat}개의 기본 토큰과 2K개의 object query 토큰을 사용하고 있습니다. hidden dimension이 D라고 가정하면, l번째 트랜스포머 레이어에 있는 토큰 feature는 포인트 토큰 p^l_{pnt} \in \mathbb{R}^{N_{pnt} \times D}과 이미지 패치 토큰 p^l_{pat} \in \mathbb{R}^{N_{pat} \times D}, 포인트에 대한 object query o^l_{pnt} \in \mathbb{R}^{K \times D} 그리고 이미지 패치에 대한 object query o^l_{pat} \in \mathbb{R}^{K \times D}로 이루어져 있습니다.
사용하는 카메라의 내,외부 파라미터가 주어지면 3차원 포인트 클라우드를 2차원 평면으로 사영할 수 있습니다. 앞으로 이러한 3차원 포인트 좌표 k = [x, y, z]^T에서 2차원 이미지 픽셀 좌표 k’ = [u, v]^T로의 사영을 proj : \mathbb{R}^3 → \mathbb{R}^2 식(2)로 정의하겠습니다.
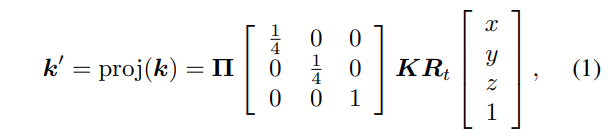
여기서 K와 R_t는 각각 내, 외부 파라미터이며 \Pi는 perspective mapping 입니다.
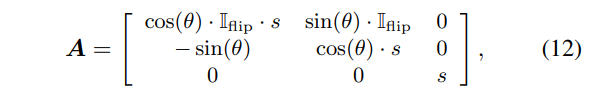
앞에서 object query가 주어지면 그에 대한 출력 임베딩을 생성한다고 했는데 이는 2K개의 object query에 대응하여 2K개의 출력값으로 이루어져 있습니다. 첫번째 K개 출력을 3차원 바운딩 박스 좌표와 클래스를 예측하기 위해 MLP를 통과시키고 나머지 K개 출력값의 경우 또 다른 MLP를 이용하여 2차원 바운딩 박스 좌표와 클래스를 예측하도록 합니다. 2차원 바운딩 박스는 식(12)에 따라 3차원 바운딩 박스 좌표를 2차원 카메라 평면에 사영한 다음 사영된 형태로 얻어지기 때문에 2차원 바운딩 박스 좌표에 대한 추가적인 작업이 필요하지 않음을 강조하고 있습니다.
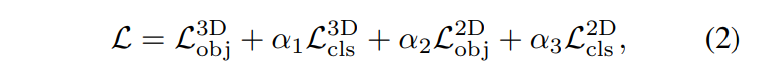
BrT의 Loss는 크게 두 파트로 나뉘는데 먼저 바운딩 박스의 위치를 예측하는 regression loss와 박스의 클래스를 예측하는 classification loss 입니다. regression loss는 또 L^{3D}_{obj}와 L^2D_{obj}두 개로 나누어지는데 각각 3차원, 2차원의 바운딩 박스에 관한 loss 입니다. 마찬가지로 classification loss 역시 L^{3D}_{obj}와 L^{2D}_{obj}로 구성됩니다. 이 두 개의 loss를 합친 전체 loss 계산 식을 위의 식(2)와
같이 정의합니다.
2.2. Transforemr building block of BrT
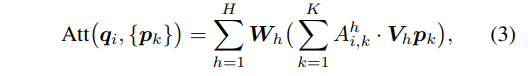
- h : H개의 어텐션 헤드 중 하나의 인덱스
- W_h, V_h : output과 value의 projection에 대한 가중치
- A^h_{i, k} : attention weight
본 논문의 트랜스포머 구조는 multi-head attention (MSA) 구조로 query, key, value 세 개의 집합을 입력으로 가지게 되죠. \{q_i\} query와 key와 value에 대한 \{p_k\}가 주어지면 식(3)처럼 MSA는 linear projection에 의한 가중합을 출력합니다.
Fig1에서 볼 수 있듯이 BrT 트랜스포머 모듈은 p^l_{pnt}과 p^l_{pat}, 즉 포인트 클라우드와 이미지 패치 사이의 attention 계산이 이루어지지 않도록 막고 있기 때문에 각 토큰의 attention은 식(5)와 같이 계산됩니다.
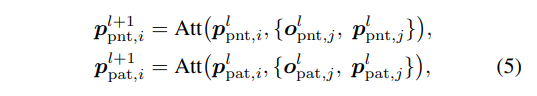
- i, j : 토큰 인덱스
비록 트랜스포머 모듈 안에서 두 모달리티 토큰 사이의 attention 계산을 못하게 하곤 있지만 포인트 클라우드와 이미지 패치 사이의 projection을 통해서 명시적으로 두 모달리티의 관계를 활용하였습니다. 즉 두 좌표계의 차이가 크기 때문에 트랜스포머에서 global attention은 하진 않는 대신 projection을 통해 두 데이터의 상관관계를 사용하고자 한 것 입니다.
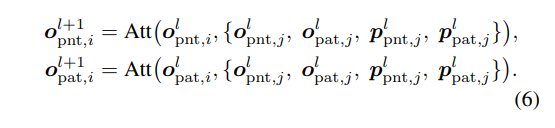
게다가 앞서 계속 object query를 사용한다고 이야기하였지만 이 object query에는 3D ↔ 2D 좌표계 사이의 차이를 줄이면서 두 정보를 더 잘 연결하기 위한 추가적인 기능을 하도록 설계되어 있고 각 object query는 식(6)과 같이 정의할 수 있는데 더 자세한 내용은 3.3절에서 이어서 다루도록 하겠습니다.
2.3. Bridge by conditional object queries
포인트 클라우드가 존재하는 3차원 좌표계와 이미지 픽셀의 2차원 좌표계는 당연하게도 매우 다를 수 밖에 없는데 이러한 차이가 트랜스포머 기반의 모델에서 두 데이터의 관계를 학습하기 어렵게 만듭니다. 이 부분에 대해서 본 논문은 object query를 이용하였고 특히 3D와 2D 좌표를 모두 인식할 수 있는 조건부 object query를 활용하고자 하였습니다. 트랜스포머 기반의 object detection 모델의 경우 object query는 학습 과정에서 특정 영역과 박스 크기에 fitting되어 나타나는데 이는 심지어 random 초기화에 의해 생성됩니다. 저자는 이러한 사실을 기반으로 포인트 클라우드와 이미지 패치에 대한 object query의 feature가 트랜스포머 모듈 내에서 align 맞춰질 수 있다고 가정을 하게 됩니다. 그래서 random하게 생성되는 object query 대신에 포인트와 이미지 사이의 align이 맞춰진 조건부 object query를 사용하고자 하였습니다.
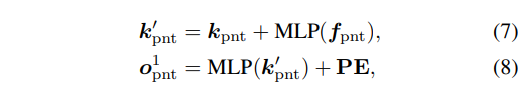
두 object query의 align을 맞추기 전 먼저 입력으로 들어오는 N_{pn}개의 포인트를 KNN을 통해 K개로 샘플링하면 k_{pnt} \in \mathbb{R}^{K \times 3} 포인트 좌표와 f_{pnt} \in \mathbb{R}^{K \times F} feature을 포함하고 있겠죠. 그러면 f_{pnt}를 기반으로 추가 학습되어 bias를 가지는 k_{pnt}을 더하여 k’_{pnt} \in \mathbb{R}^{K \times 3}을 학습합니다. 트랜스포머 모듈에서 사용되는 포인트의 object query o^1_{pnt}는 바로 k’_{pnt}의 조건부 object query인 것 입니다.
다음으로 이미지 패치의 object query o^1_{pat}는 대응하는 이미지에 대한 k’_{pnt}를 projection한 픽셀의 좌표인 proj(k’_{pnt}) \in \mathbb{R}^{K \times 2}를 찾습니다. 이후엔 포인트 클라우드 object query와 마찬가지로 식(9)와 같이 이미지 패치의 조건부 object query인 o^1_{pat}을 계산할 수 있는 것이죠.
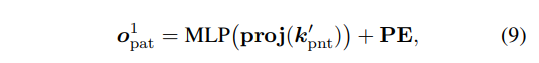
식(8)과 (9)에서 사용하는 PE는 동일한 position 임베딩으로 이렇게 position 임베딩 공유를 통해 직관적으로 두 object query가 트랜스포머 내에서 align이 맞추어져 있다고 말할 수 있다고 합니다. 이러한 공유된 PE를 사용함으로써 align이 맞추어지고 두 도메인 object query을 연결하여 사용함으로써 나타나는 효과에 대해서는 ablation study에서 증명하고 있습니다.
2.4. Bridge by point-to-patch projection
트랜스포머 내에서 두 입력 데이터 사이의 직접적인 attention 계산을 하지 않는 대신 object query로 연결해주긴 하나, 더욱 두 모달리티의 장점을 극대화하여 사용하고자 point-to-patch projection을 수행합니다. N_{pnt}의 3차원 좌표를 n_{pnt} \in \mathbb{R}^{N_{pnt} \times 3}라고 한다면, n_{pnt}에 대응하는 카메라 좌표의 2차원 픽셀인 proj(n_{pnt}) \in \mathbb{R}^{N_{pnt} \times 3}을 찾을 수 있겠죠.
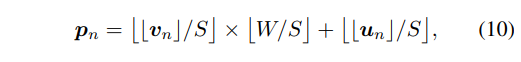
- \lfloor . \rfloor : 반올림 연산
- p_n \in \{ 1, 2, . . . . , N_{pat}\} : n번째 포인트에 대응하는 이미지 패치 인덱스
- S : 이미지 패치 사이즈
전체 포인트 개수에서 n번째 포인트에 대해 (n = 1, 2, . . ., N_{pnt}) 2차원 평면으로 projection한 픽셀 좌표의 x축과 y축은 v_n(1 \le v_n \le W), u_n(1 \le u_n \le H)로 정의합니다. 이 u_n과 v_n은 반올림하여 가장 가까운 정수 좌표계로 이동함으로써 이미지 픽셀 좌표계에서 합리적인 값으로 할당될 수 있습니다.
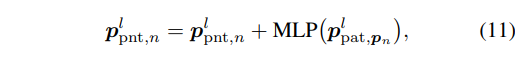
- n : p^l_{pnt}의 토큰 feature
- p_n : p^l_{pat}의 토큰 feature
이렇게 구한 point-to-patch projection은 식(11)을 통해 포인트와 이미지 패치에 대한 feature을 합치게 됩니다.
3. Experiments
실험은 indoor 데이터셋인 SUN RGB-D와 ScanNetV2에서 수행하였습니다.
3.1. Comparison with state-of-the-art methods
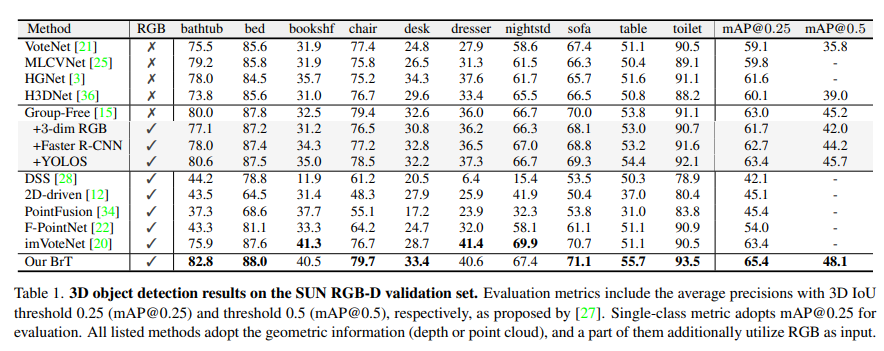
Results on SUN RGB-D
먼저 Table1은 SUN RGB-D에서의 실험 결과로 BrT가 기존 SOTA 방법론과 비교하였을 때 새롭게 SOTA를 달성한 것을 확인할 수 있습니다. 특히 계속 비교 대상으로 삼았던 GF3D (Group-Free) (포인트 클라우드를 입력으로 하는 트랜스포머 기반 모델)대비 mAP 0.25, mAP 0.5에서 각각 2.3%, 2.9%의 차이를, ImVoteNet (RGB 이미지만을 입력으로 하는 CNN 기반 모델)과 비교하였을 때 역시 mAP 0.25에서 1.9% 더 높은 성능을 달성하였습니다.
특히 오로지 포인트 클라우드만을 이용하여 높은 성능을 달성한 GF3D에 추가적인 모듈을 덧붙혀 실험을 진행하였는데요, (1) 3차원 RGB 벡터를 포인트 클라우드 feature에 추가, (2) 이미지 feature을 사용하기 위해 CNN 기반 2D 사전학습 모델인 Faster R-CNN을 사용, 그리고 (3) 트랜스포머 기반 2D 사전학습 모델인 YOLOS를 사용하여 입력 형태를 BrT와 동일하게 멀티 모달리티로 변경하였습니다. 3가지 케이스에 대한 실험 결과 기존 GF3D 대비 (3)만이 조금의 성능 향상이 존재하였습니다. 이러한 결과는 3D detection에서 RGB 정보가 포인트 클라우드에 추가적인 semantic한 정보를 제공할 수 있는 것은 맞지만 이렇게 RGB 정보를 직관적으로 합치는 것만으로는 좋은 결과를 얻기 어려움을 보여주고 있습니다. 특히 3차원 RGB 벡터를 직접적으로 사용하는 것은 2D↔3D 공간의 차이를 해결하지 못하고 성능 하락을 일으키게 되는 것을 실험적으로도 확인할 수 있습니다.
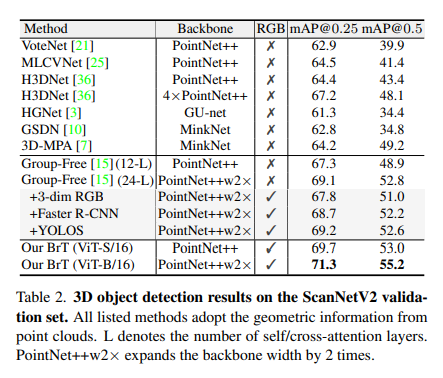
Results on ScanNetV2
다음은 ScanNetV2 데이터셋에서 결과로 여기서도 마찬가지로 GF3D에서는 3가지 추가 모듈을 통해 RGB 입력까지 사용할 수 있는 형태로 변형하였습니다. ScanNetV2에서도 (3)에서 0.1%의 성능 향상이 있었지만 모두 오히려 단순 RGB 정보를 활용하는 것이 성능 하락의 원인이 됨을 알 수 있습니다. 반면 BrT는 서로 다른 차원의 차이를 완화하고 두 모달리티 정보를 트랜스포머 내에서 연결하여 RGB 정보를 활용함으로써 71.3%의 높은 성능을 달성할 수 있었습니다.
3.2. Ablation analysis
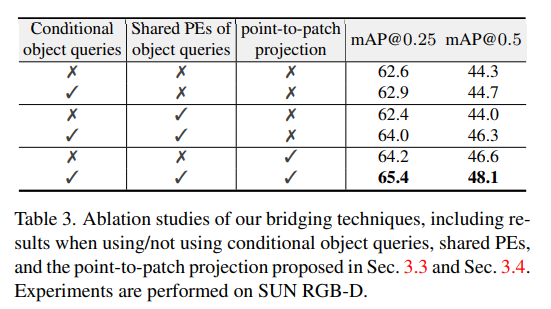
3.3절과 3.4절에서 조건부 object query를 사용하며 사용하는 과정에서 공유된 PE를 사용하고 추가적으로 point-to-patch projection까지 제안하였습니다. 해당 ablation study에서는 이 세가지가 성능에 미치는 영향을 확인하기 위해 수행되었습니다. 결과를 통해서 조건부 object query와 공유 PE를 단독으로 사용할 때는 눈에 띄는 성능 향상을 얻지 못하기 때문에 필수적으로 함께 사용해야 하는 반면 point-to-patch projection의 경우 단일로 적용하였을 때도 성능 향상에 긍적적인 영향을 미치는 효과를 확인하였습니다.

3.2절에서 두 토큰 사이의 직접적인 attention 계산을 수행하지 않는다고 하지 않는 반면 object query 간에 attention을 계산한다고 하였기에 object query를 통한 두 모달리티 정보를 활용하는 구조에 대한 강점을 입증하기 위해 ablation study를 수행하였습니다. 비교를 위해 토큰 간의 연결 구조를 설계하였고 ( 3번째 열) 실험 결과 default 세팅(마지막 행)에서 토큰과의 연결을 추가하였을 때 더 낮은 성능을 보이며 트랜스포머 내에서 직접적으로 두 모달리티의 토큰에 대한 attention 계산이 성능 하락에 영향을 미친다는 것을 증명하였습니다. 이를 통해 BrT에서 제안하는 object query를 통한 포인트 클라우드와 이미지를 연결하여 정보를 활용하는 구조가 합리적임을 확인하면서 리뷰 마치도록 하겠습니다.
안녕하세요. 손건화 연구원님.
포인트 클라우드와 rgb의 융합… 어질어질하면서도 재밌네요.
초반부에 ImVoteNet은 두 모달리티의 feature를 합쳐 의미론적인 정보를 모두 활용하다가… 라고 하다가 말을 줄이셨는데 무슨 내용인지 상당히 궁굼합니다.
그리고 제가 잘못 이해한 것인지 잘 모르겠지만 object query가 2k개 있다는 것이 트랜스포머 입력으로 2천개의 object token이 들어간다는 것인가요..?? 만약 그렇다면 모델 크기가 상당히 큰 것 같아서요.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
ImVoteNet이 RGB 벡터를 추출하는 것이 아닌, 사전학습된 2D 검출기에서 추출한 feature를 사용함으로써 2D/3D 사이의 도메인 차이로 인해 발생하는 문제를 해결하였다고 했는데, , , 왜 RGB 벡터가 아니라 feature를 사용하면 이런 문제를 해결할 수 있는 것인가요 ?
또, 식(1)에서 perspective mapping은 어떻게 구해지는 것인가요 ? 옆에 곱해지는 행렬인 [1/4 0 0 | 0 1/4 0 | 0 0 1]은 무엇인지 궁금합니다. ㅎㅎ
감사합니다 !