제가 이번에 리뷰할 논문도 6D pose Estimation 연구입니다.
Abstract
해당 논문은 RGBD 기반의 6D Pose Estimation 논문으로, 색상 정보와 깊이 정보를 효과적으로 융합하여 자세 추정을 개선시키고자 DFTr(Deep Fusion Transformer) 블록을 제안합니다. 기존 융합 방식과 다르게 DFTr은 의미론적 유사도를 이용하여 두 모달리티의 관계를 잘 모델링할 수 있으므로 서로 다른 모달리티에서 global하게 feature를 개선시켜 정보를 추출할 수 있도록 합니다. 또한, 강인성과 효율을 높이기 위해 거의 real-time으로 추론을 수행하며 정밀한 3D keypoint의 위치를 추정하기 위해 non-iterative하게 global 최적화를 수행하는 새로운 vector-wise voting 알고리즘을 제안하였습니다. 본 논문에서 제안한 방법론의 효율성과 일반화 가능성을 실험적으로 보였으며, 4가지 벤치마크에서 SOTA 성능을 달성하였습니다.
Introduction
최근 RGB-D 센서를 이용하여 영상 정보에 기하학적 정보를 보완하는 6D Pose Estimation 연구가 활발히 진행되고 있습니다. 그러나 여전히 서로 다른 모달리티 정보인 RGB와 Depth 정보를 융합하는 것에는 어려움이 있습니다. 선행 연구들은 Depth 정보를 추가하여 최종 pose 정보를 refinement하거나 추출된 RGB와 Depth feature를 직접적으로 연결하여 pose 정보를 추정하는 데 활용하였습니다. 그러나 이러한 방식은 3D 정보를 최대한 활용하지 못하며, occlusion에 민감하게 반응하며, global한 특징을 고려하지 않는다는 문제가 있습니다. 최근 연구들도 단순한 point-wise 융합 인코더를 이용하거나 K-NN을 이용하여 주변 point를 찾아 이용하는 방식이며, 이러한 방식도 도메인의 global한 의미론적 관계를 고려하지 않습니다. 또한 이러한 융합 방식은 금속 물체와 같이 반사율이 높은 표면에서 다음과 같은 이유로 잘 작동하지 않습니다.
(1) 특정 모달리티의 정보 부족으로 CNN이나 PCN(point cloud network)을 이용한 특징 추출 실패
(2) 객체간의 occlusion으로 데이터 손실
(3) K-NN 기반 클러스터링 방식은 통합된 feature가 객체에 존재하지 않을 가능성이 있어 노이즈에 민감함
본 논문에서는 효과적으로 RGB-D 데이터를 융합하기 위해 Deep Fusion Transformer 네트워크를 제안합니다. 저자들은 기하학 정보와 형태 사이의 전체적인 의미론적 유사성을 추론하여 두 데이터의 구별되는 특징을 암시적으로 집계하도록 Deep Fusion Transformer(DFTr) 블록을 설계하였다고 합니다. 저자들은 global한 의미론적 유사성 모델링이 데이터 누락과 노이즈로 인한 feature 혼동 문제를 완화할 수 있다고 주장합니다. 또한, 학습된 RGB-D feature를 이용하여 occlusion에 대한 강인성을 높이기 위해 keypiont 기반의 6D Pose Estimation 방법론을 활용하였다고 합니다. 저자들은 3D point 별 단위 벡터를 학습하고 효과적이고 반복적이지 않은 weighted vector-wise voting 알고리즘을 제안하였으며, 단위 벡터를 이용하여 네트워크가 학습하기 쉽고 정확도를 유지하면서도 추론 속도를 크게 향상시킬 수 있었다고합니다.
본 논문의 contribution을 정리하면 다음과 같습니다.
- 강력한 representation을 학습하기 위해 새로운 딥 퓨전 트랜스포머(DFTr) 블록을 설계하고 여러 scale에서 사용할 수 있는 효과적인 cross-modality feature aggregation 네트워크 제안
- 3D keypoint의 위치를 추정하기 위해 global 최적화 방식을 적용한 weighted vector-wise voting 알고리즘 제안 (PVN3D와 FFB6D에서 기존 클러스터링 알고리즘 대신 해당 알고리즘을 적용하여 각각 약 1.7배, 2.7배 빠른 추론 속도를 YCB-Video 데이터에서 확인함)
- MP6D, YCB-Video, LineMOD, Occlusion LineMOD 데이터에서 다양한 실험 수행
Methodology
6D Pose Estimation은 대상 객체의 좌표계와 카메라 좌표계 사이의 rotatin과 translation 정보를 추정하는 것으로, 해당 논문은 RGB-D test 이미지가 주어졌을 때, 서로 다른 모달리티간의 정보를 충분히 통합할 수 있는 심층 모델을 설계하는 것을 목표로 합니다.
1. Overview
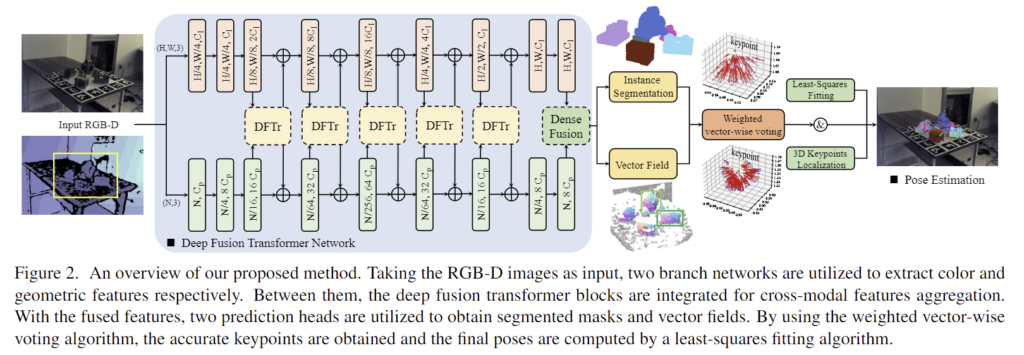
저자들이 제안한 DFTr 네트워크는 [Fig. 2]에서 확인할 수 있으며, 해당 네트워크는 먼저 CNN과 PCN을 이용하여 외관적 특징과 기하학적 특징을 각각 추출합니다. 또한 DenseFusion 모듈을 도입하여 각 도메인 내에서 point 별 local한 특징을 수집합니다. 최종 feature를 얻기 전에 두 모달리티의 정보를 교환하기 위해 각 레이어에 deep fusion transformer 블록을 이용합니다. 이는 외관과 기하학적 특징 사이의 의미론적 유사성을 모델링하고 상대 도메인에서 강조된 feature를 각 branch에 통합하여 representation을 학습합니다. 또한, 특징을 집계하기 위해 RGBD 대응관계를 명시적으로 이용하는 대신 전체 feature에 positional embedding을 추가하는 암시적인 방식을 이용하였다고 합니다. 추출된 point별로 융합된 특징을 이용하여 instance segmentation 보듈을 통해 각 객체의 mask를 예측하고 weighted vector-wise voting 모듈을 이용하여 장면 내의 객체의 3D keypoint 위치를 추정합니다.
2. Deep Cross-Modality Feature Embedding
RGB-D 이미지가 입력으로 주어졌을 때, 먼저 카메라 intrinsic 파라미터를 이용하여 depth 이미지를 point cloud P_o∈\mathbb{R}^{N⨉3} 로 변환합니다. 이후 RGB와 Depth branch는 각각 feature I_o와 P_o를 추출합니다. 이때 각 레이어마다 feature를 DFTr 블록으로 입력하여 cross-modality 정보를 집계합니다. (이러한 구조는 FFB6D 네트워크와 유사합니다.) 이를 통해 네트워크 초기 단계에서도 두 모달리티 데이터의 multi-scale의 local & globla 한 정보를 특징 추출 과정에 추가할 수 있다고 합니다.
Deep fusion transformer block
DFTr block은 두 모달리티의 feature 사이의 고유한 correspondence를 탐색하는 것을 목표로 합니다. [Densefusion/Pvn3d]과 같은 선행 연구는 RGB와 기하학적 특징을 픽셀단위로 연결하여 융합하고 global한 feature를 생성한 뒤 연결된 각 특징에 누적하여 global한 표현력을 확보하였으며, 또다른 융합 방식을 활용한 [FFB6D]는 대상 픽셀(point)에 대한 주변 픽셀(point)정보를 활용하여 non-local한 feature를 생성하고 생성된 feature를 해당 point(픽셀)의 feature에 연결합니다. 이러한 융합 방식은 global한 feature representation을 충분히 활용하지 못하고 입력 데이터의 품질에 크게 영향을 받는다는 문제가 있습니다. 이는 곧 두 데이터 중 하나라도 불확실한 정보가 포함될 경우 성능이 크게 저하되는 경향을 보인다는 것입니다. 게다가 센서 calibration 오류로 인해 RGB-D 데이터의 정합이 맞지 않을 경우에도 잠재적인 문제가 됩니다.(정리하자면 point 별 정보를 활용하여 global 한 정보를 취득하고, 이를 다시 local한 feature에 연결하여 사용하는 기존의 방식들은 대응되는 정보가 확실하게 일치해야하며, 그렇지 않을 경우 문제가 발생한다는 것입니다.)
따라서 저자들은 RGB와 기하학적 feature를 긴 sequence token으로 처리하고 이를 global하게 암시적으로 특징에 융합하는 새로운 양방향 cross-modality fusion block(DFTr)을 설계하였습니다. DFTr block은 transformer 기반의 구조로, computer vision 분야에서 transformer가 long-range dependencies를 잘 포착한다는 것이 입증되었기 때문에 transformer 기반의 블록을 설계하여 모델의 global한 표현력을 향상시키고자 하였다고 합니다.
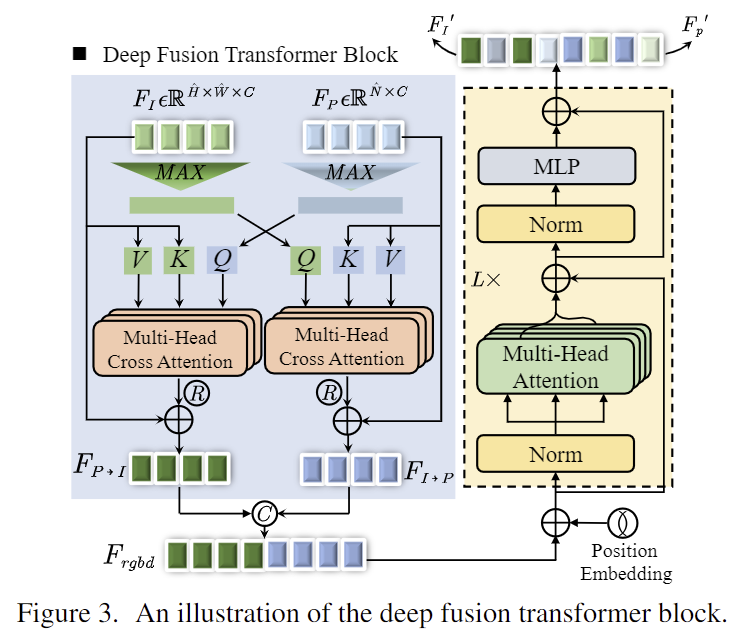
DFTr block은 [Fig. 3]에서 확인할 수 있듯 i번째 레이어에서 RGB feature map F_I∈\mathbb{R}^{\hat{H}⨉\hat{W}⨉C}과 기하학적 feature F_P∈\mathbb{R}^{\hat{N}⨉C}가 주어졌을 때, 두 branch 사이에 cross-attention 모듈 연산을 적용한 다음, transformer 기반 모듈을 이용하여 두 모달리티 정보의 전체 요소의 sequence를 모델링합니다. 저자들은 이미지 패치 사이의 상호간의 정보를 수집하는 Cross-ViT 연구에서 영감을 받아 네트워크를 설계하였으며, feature map F_I와 F_P를 flatten하여 sequence를 형성한 뒤 max pooling을 이용하여 global한 feature F_I^{max}∈\mathbb{1⨉C}와 F_P^{max}∈\mathbb{1⨉C}를 생성합니다. 이후 Transformer 연산을 수행합니다.
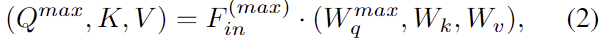
- W_q^{max}, W_k, W_v: Query, Key Value의 학습 가능한 projection 행렬
- F_{in}∈\mathbb{R}^{N_{in}⨉C} : flatten된 feature ( N_{in}=\hat{H}\hat{W}(\hat{N}))
- F_{in}^{max}∈\mathbb{R}^{1⨉C} : pooling된 feature
그 다음 mulit-head cross-attention연산을 통해 정제된 feature F_{out}을 추정하며 아래의 식으로 구할 수 있습니다.
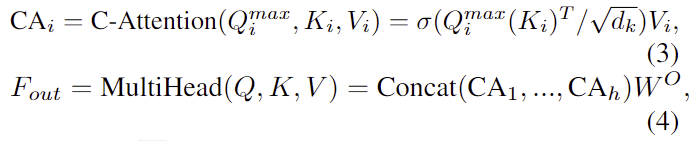
이후 F_{out}를 각 input featuer F_{I}와 F_P에 더하여 feature F_{P↦I}와 F_{I↦P}를 구하고 두 feature를 concate하여 F_{rgbd}를 구합니다.
양방향으로 cross-attention 모듈을 통과하여 얻은 feature F_{rgbd}∈\mathbb{R}^{L⨉C} ( L= \hat{H} \hat{W} \hat{N} )는 transformer 기반의 모듈인 TrM(.)에 입력됩니다. 이때 두 feature 사이의 공간적 정보를 암시적으로 인코딩하기 위해 학습 가능한 positional embedding을 DFTr block에 삽입합니다. 각 레이어는 TrM(.) block을 통과하여 \mathcal{F_l} = TrM_{\mathcal{l}}(F_{rgbd}) 를 구합니다.
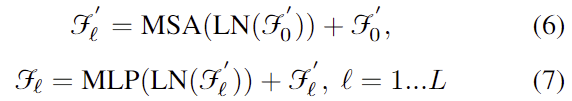
- \mathcal{F}_0’ = F_{rgbd} + \sigma_{pose} 이며 \sigma_{pose} 는 position embedding, \mathcal{F}_0은 이미지 feature나 기하학적 feature의 초기값을 의미합니다.
- MSA, LN, MLP는 각각 multihead self-attention, layernorm, Multi-Layer Perceptrons를 의미합니다.
이렇게 두 개의 최종 feature를 얻은 뒤, RGBD feature쌍을 얻은 다음 Densefusion 모듈에 입력하여 dense한 fused feature를 생성합니다. 이후 생성된 feature는 pose 추정을 위해 instance mask와 keypoint의 vector field를 예측하는 데 활용됩니다.
3. Weighted Vector-Wise Voting for 3D keypoints Localization and Pose Estimation
정확도를 위해 6D Pose Estimation에서 바로 pose를 추정하지 않고 대부분 keypoint를 먼저 예측하는 방식을 활용합니다. 저자들도 이러한 방식을 따랐으며, 모델의 정확도와 효율을 높이기 위해 새로운 keypoint 위치 추정 알고리즘을 제안하였습니다. 예측된 mask와 keypoint vector field를 활용하여 3D keypoint를 추정하고 이후 대응관계를 이용하여 object의 pose를 추정합니다.
Instance-level 3D keypoint localization
앞서 구한 fused feature가 주어졌을 때, instance segmentation과 keypoint vector field 예측을 위해 2가지 head를 이용합니다. 학습 과정에 명확한 경계나 제약이 주어질 경우 학습에 도움이 되므로 저자들은 미리 정의된 keypoint에 대한 point 별 offset을 직접 regression으로 구하는 대신 point p_i에서 3D keypoint k_j로의 방향을 나타내는 단위벡터를 예측하는 방식을 제안합니다.
segmented object의 3D points P = \{ p_i|i=1, ..., M \}와 각 point에 대응되는 vector field V_o = \{ v_j | j= 1, ..., K\}가 주어졌을 때 keypoint는 아래의 식으로 정의됩니다.
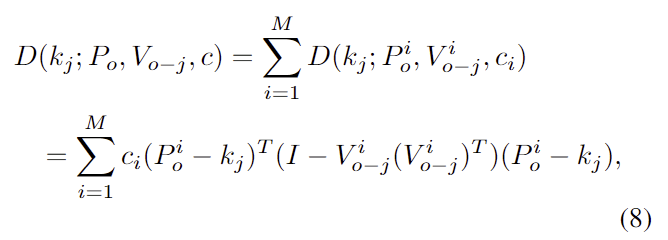
- V_{o-j}: j번째 keypoint 예측값의 vector field
- c_i: 학습 가능한 각 vector의 가중치
위의 식(8)에서 distance D(.)를 최소화하도록 최적화를 수행합니다.
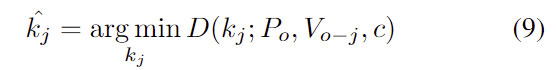
Keypoint-based object pose estimation
예측된 3D keypoints \{ k_j \}^K_{j=1}와 이에 대응되는 3D keypoints\{ k_j ^*\}^K_{j=1}가 주어졌을 때, Least-squares estimation 방식을 이용하여 pose를 추정합니다.
Overall multi-task loss function
또한 학습을 위한 최종 loss는 segmentation loss와 vector field loss를 가중합하여 구하며,
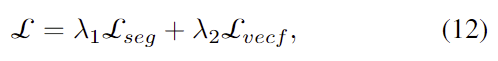
- \mathcal{L}_{seg}: Local loss
이때 vector field의 loss는 아래의 식으로 정의됩니다.
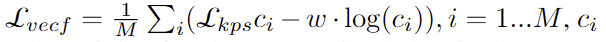
- \mathcal{L}_{kps}: L1 loss
저자들은 \lambda_1 = \lambda_2 = 1로 설정하였다고합니다.
Experiments and Results
- 저자들은 MP6D, YCB-Video, LineMOD, Occlusion LineMOD로 실험을 진행하였으며, ADD(S)와 VSD를 평가지표로 사용하였습니다. (데이터 및 평가지표는 이전 6D Pose Estimation 리뷰를 참고해주세요)
1. Comparision with SOTA
Evaluation on the MP6D dataset
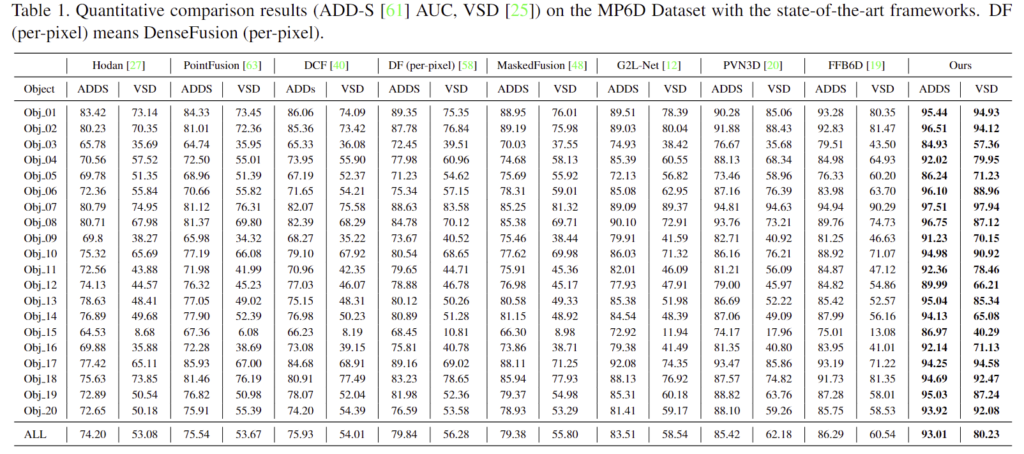
- 위의 Table 1가 MP6D 데이터 셋에 대한 정량적 평가 결과로 반복적인 refinement 없이 PVN3D와 FFB6D에서 ADDS에 대하여 7.59%, 6.72% 개선된 성능을 보였으며, VSD에서는 19.69%와 18.05% 개선된 성능을 보였습니다.
- 이를 통해 제안한 방법론을 통해 성능 개선이 이루어 졌음을 보였습니다.
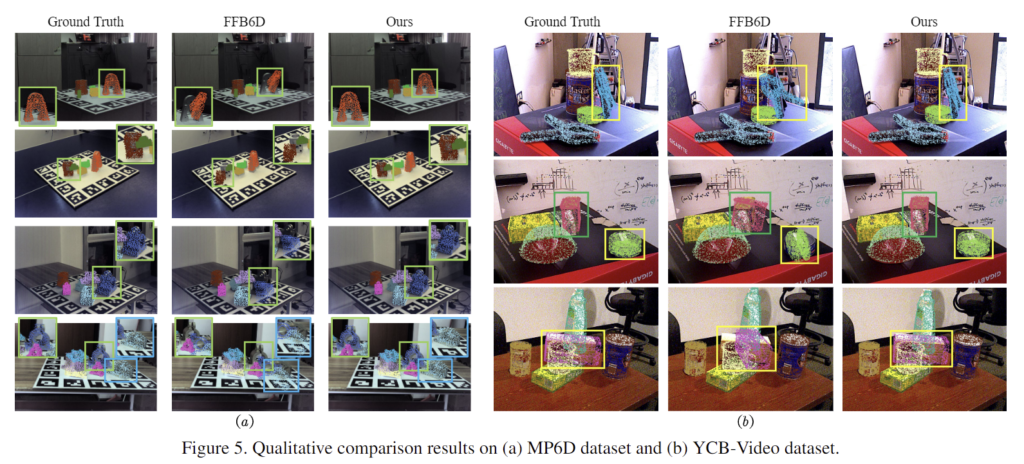
- [Fig. 5]를 통해 정성적 결과를 확인할 수 있습니다.
Evaluation on the YCB-Video dataset
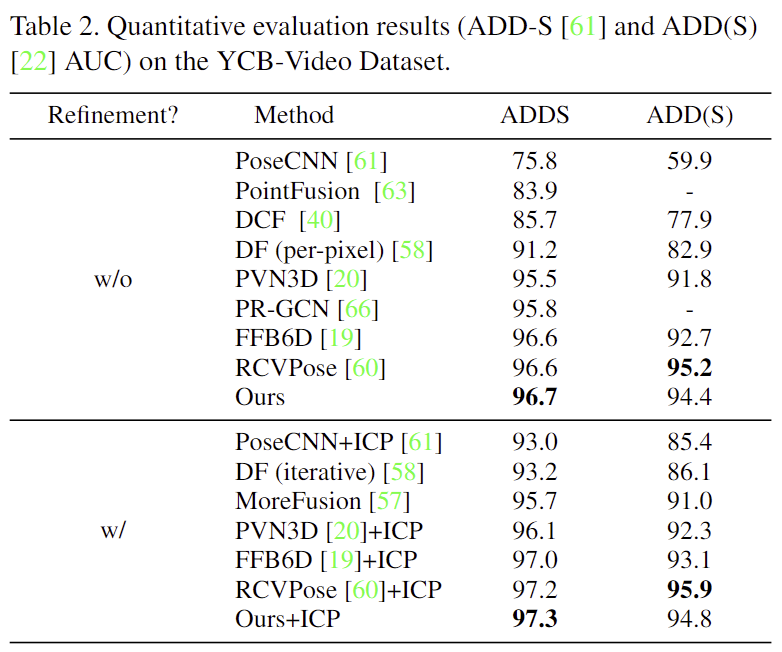
- 위의 Table 2에 YCB-Video에 대한 성능을 리포팅하였으며, 해당 논문의 모델이 FFB6D보다 ADD와 ADD(S)에 대해 0.1%와 1.7% 향상된 성능을 보였습니다.
- 추가적으로 refinement를 수행할 경우 ADDS에 대하여 RCVPose보다 좋은 성능을 보이는 것을 확인할 수 있습니다.
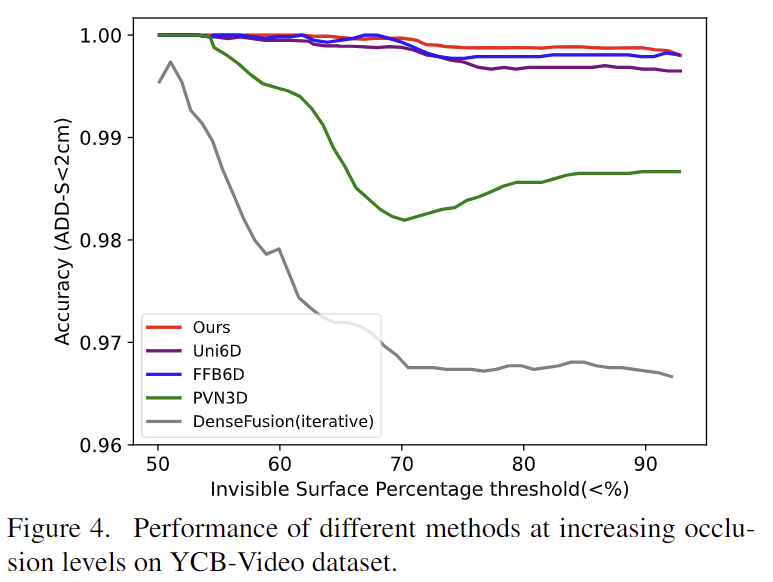
- 또한, [Fig. 4]를 통해 occlusion이 발생하였을 때 강인하게 작동함을 확인할 수 있습니다.
- 이에 대해 저자들은 두 모달리티 사이의 의미론적 유사성에 대하여 global하게 모델링하여 보이는 영역의 단서를 최대한 활용할 수 있었기 때문이라고 주장합니다.
- [Fig. 5]를 통해 정성적 결과를 확인할 수 있습니다.
Evaluation on the LineMOD dataset & Occlusion LineMOD dataset
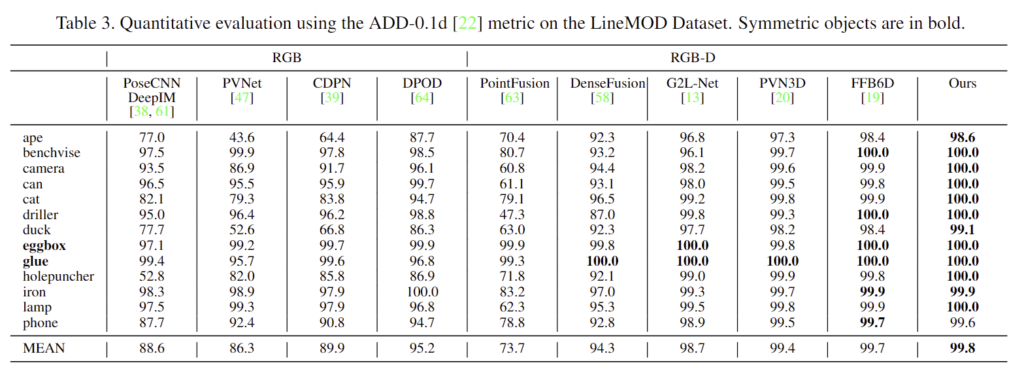
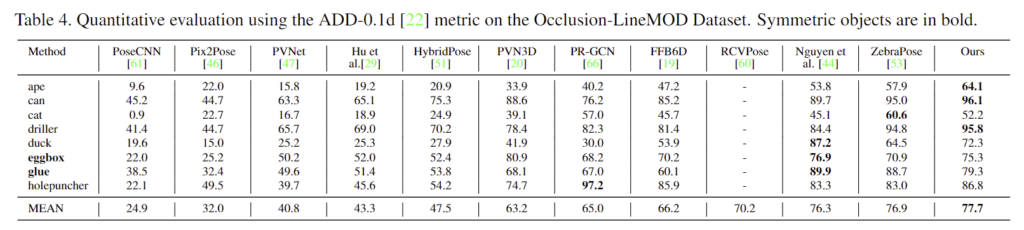
- 위의 Table 3과 Table 4는 LineMOD와 Occlusion LineMOD에 대한 정량적 결과를 나타내며저자들이 제안한 방식이 SOTA를 달성하였다고 합니다.
- 특히 Occlusion LineMOD에서의 성능을 통해 occlusion에 강인함을 입증하였습니다.
2. Ablation Study
Effect of the weighted vector-wise voting algorithm

- Table 7은 Weighted Vector-Wise Voting 알고리즘(WVWV)의 효용을 판단하기 위한 실험으로 YCB-Video에서 성능을 평가한 결과입니다.
- 왼쪽 표를 통해 다른 모델에 적용하였을 때 효과를 확인하였으며, 속도도 PVN3D는 1.7배, FFB6D는 2.7배 속도가 향상된 것을 확인할 수 있습니다.
- 오른쪽 표를 통해 MP6D에서 WVWV의 성능ㅇ과 MeanShift 알고리즘의 성능을 비교하였고, 저자들이 제안한 WVWV가 좋은 성능을 보이는 것을 확인하였습니다.
Time Efficiency
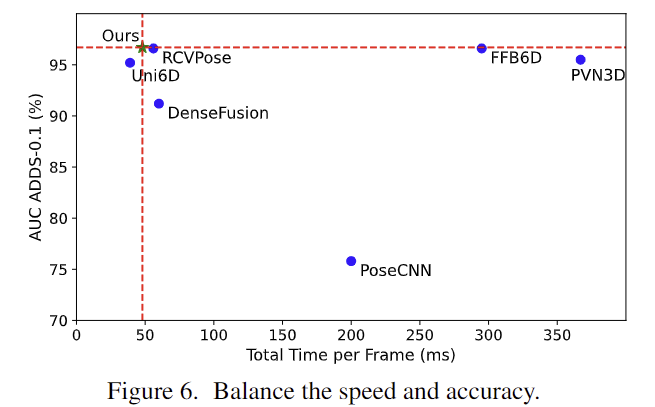
- 위의 [Fig. 6]은 YCB-Video에서 추론 시간과 성능을 그래프로 나타낸 것으로 Uni6D와 유사한 효율성을 보이며 더 낳은 성능을 달성하였다고 합니다.(48ms/frame)
안녕하세요 ! 좋은 리뷰 감사합니다.
본 논문의 트랜스포머 블럭에서 postiion embedding은 두 모달리티에서 공유되는 것인가요 ?? 해당 논문 이전 방법론들의 두 모달리티 사이의 고유한 대응 관계를 찾을 때 발생하는 문제점들 중 하나로 RGB-D 데이터의 alignment가 맞지 않을 경우를 말씀해주셨는데, 본 논문의 트랜스포머 블럭은 이러한 alignment가 맞지 않는 상황에서도 강인하게 동작을 할 수 있는 이유가 이러한 공유 임베딩을 사용했기 때문인지가 궁금합니다.
감사합니다.
질문 감사합니다.
1) 본 논문의 트랜스포머 블럭에서 postiion embedding은 두 모달리티에서 공유되는 것인가요 ??
: 해당 논문에서는 두 feature를 concat한 값에 대하여 positional embedding을 수행하므로 공유한다기보다도 두 feature를 합친 새로운 feature에 대하여 하나의 positional embdding이 수행된다고 이해하는 것이 좋을 것 같습니다.
2)본 논문의 트랜스포머 블럭은 이러한 alignment가 맞지 않는 상황에서도 강인하게 동작을 할 수 있는 이유가 이러한 공유 임베딩을 사용했기 때문인지가 궁금합니다.
: 본 논문에서 alignment가 맞지 않아도 잘 작동할 수 있었던 이유는 ViT의 장점으로 연결할 수 있을 것 같습니다. 추출한 feature를 squence형태로 변환할 때 기존의 point-to-point 대응관계보다 더 넓은 영역을 볼 수 있기 때문이라고 생각합니다.
안녕하세요 승현님 좋은 리뷰 감사합니다!
본문의 Deep fusion transformer block에서 ‘ RGB와 기하학적 특징을 픽셀단위로 연결’ 한다고 하셨는데 이는 이미지에서 각 픽셀의 RGB 값을 추출하고 기하학적인 특징을 추출할때는 픽셀의 깊이 또는 3D 위치와 관련된 정보를 추출하는 것을 의미하나요?? 그리고 이를 연결하는 방법은 어떻게 이루어지는가 궁금합니다.
그리고 또다른 융합 방식으로 설명해주신[FFB6D]는 대상 픽셀(point)에 대한 주변 픽셀(point)정보를 활용하여 non-local한 feature를 생성하고 생성된 feature를 해당 point(픽셀)의 feature에 연결한다고 하셨습니다. 하지만 이는 global한 feature representation을 활용하지 못한다고 하셨는데 이는 non-local한 feature를 이용하기 때문인가요?? 그렇다면 non-local한 feature는 어떤 이점이 있길래 이전에는 사용이 된건가요?
감사합니다.
질문 감사합니다!!
1) 본문의 Deep fusion transformer block에서 ‘ RGB와 기하학적 특징을 픽셀단위로 연결’ 한다고 하셨는데 이는 이미지에서 각 픽셀의 RGB 값을 추출하고 기하학적인 특징을 추출할때는 픽셀의 깊이 또는 3D 위치와 관련된 정보를 추출하는 것을 의미하나요?? 그리고 이를 연결하는 방법은 어떻게 이루어지는가 궁금합니다.
:우선 ‘ RGB와 기하학적 특징을 픽셀단위로 연결’ 하는 것은 해당 논문이 아니라 DeepFusion과 PVN3D 입니다.
‘ RGB와 기하학적 특징을 픽셀단위로 연결’ 하는 방식에 대해 설명을 드리자면, rgb와 depth를 각각 feature를 추출한 뒤, 두 feature에 대응되는 값들을 concate등의 방식으로 열결하는 것을 의미합니다. 말그대로 모든 픽셀에 대하여 feature를 대응 시키는 것 입니다.
2) 또다른 융합 방식으로 설명해주신[FFB6D]는 대상 픽셀(point)에 대한 주변 픽셀(point)정보를 활용하여 non-local한 feature를 생성하고 생성된 feature를 해당 point(픽셀)의 feature에 연결한다고 하셨습니다. 하지만 이는 global한 feature representation을 활용하지 못한다고 하셨는데 이는 non-local한 feature를 이용하기 때문인가요?? 그렇다면 non-local한 feature는 어떤 이점이 있길래 이전에는 사용이 된건가요?
:용어가 헷갈리게 작성이 되어있었네요.. 우선 해당 논문에서 non-local한 feature와 global한 feature representation는 서로 다른 의미를 가집니다.
먼저 non-local한 feature를 이용하였다는 것은, RGB와 Depth 두 데이터를 서로 다른 브랜치로 특징을 추출하며, 이 과정에 RGB의 특정 픽셀에 대해서는 Depth로 추출한 특징의 global한 정보를, 반대로 Depth의 특정 point에 대해서는 RGB에서 추출한 특징의 global한 정보를 연결시켜주게 됩니다. 이러한 점에서 non-local한 feature를 사용하였다는 것입니다,
또한, global한 feature representation을 활용하지 못하는 것은 앞의 픽셀 수준의 특징을 뽑는 방식과 다르게 FFB6D는 RGB 영상에 SIFT를 먼저 적용하여 특징점을 추출한 뒤, 극 특징점들에 대응되는 3d point들을 FPS(farthest point sampling)방식으로 샘플링하여 사용하기 때문에 모든 픽셀/포인트에 대한 representation을 활용하지 못한다고 표현한 것으로 이해하시면 될 것 같습니다.