Introduction
Sentimental analysis란 텍스트의 어조가 긍정적인지, 부정적인지 혹은 중립적인지를 분석하는 task입니다. 최근에는 sns등에 image, audio, video 등 여러 모달리티를 통한 expression이 증가하였고, 이에 따라 Multimodal Sentiment Analysis(MSA)가 등장하였습니다.
MSA는 여러 모달리티로부터 획득한 feature를 fusion하여 최종적인 감정을 예측하는 방식으로 동작합니다. 이때, 각 모딜리티 별 특징값과 긍정/부정 감정 사이에는 correlation이 존재하게 됩니다. 예를 들자면, video 데이터의 찡그린 얼굴 표정은 부정 감정, audio 데이터의 웃음 소리는 긍정 감정과 correlation이 존재하게 되겠죠.
그러나 논문의 저자들은 MSA의 기존 연구들이 텍스트 모달리티에서 잘못된 correlation을 학습하는 문제를 겪고 있다고 지적하였습니다. 즉, MSA 모델에서 text와 감정의 correlation에서 특정 단어와 감정 간의 연관성이 높게 나타나는데 그 결과를 신뢰 할 수 없다는 것입니다.
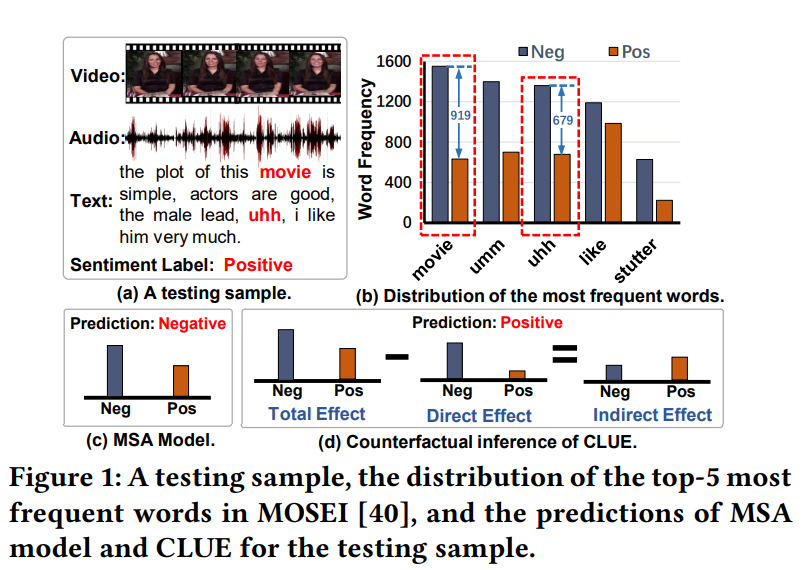
위의 [ 그림 1(b) ]는 CMU-MOSEI 데이터셋의 text 데이터 중 등장 빈도 수가 가장 높은 5개의 단어와 감정 별 분포를 나타낸 것으로, 이때 “movie”, “uhh”와 같이 특정 감정을 나타내는 단어가 아님에도 데이터셋 자체에서 부정 감정의 sample에서 더 많이 등장하는 것을 확인할 수 있는데, 이러한 경우 학습된 모델은 해당 단어를 높은 확률로 부정 감정으로 예측하게 됩니다.
위와 같이 데이터의 감정 분포에 따라 편향적으로 학습된 모델은 평가 시 text와 label간의 correlation이 달라지는 Out-of-distribution(OOD) 환경에서는 성능이 떨어지게 됩니다. 따라서 MSA모델의 일반화 성능을 향상시키기 위해 저자들은 OOD 환경에서 text 모달리티의 bad effect를 줄일 수 있는 OOD MSA task를 제안하였습니다.
저자들은 text 모달리티에서 잘못된 correlation을 줄이면서도 텍스트 자체가 가지는 semantic한 정보는 유지하는 것을 목표로 CounterfactuaL mUltimodal sEntiment (CLUE)라는 framework를 제안하였습니다. 간단히 설명드리자면 [ 그림 1(c) ]가 기존 MSA 모델의 예측값일 때 이를 Total Effect(TE)라 하고, cross-modal modeling을 통해 text 모달리티가 감정 예측에 직접적인 영향을 끼치는 정도(Direct Effect)를 계산한 뒤 [ 그림 1(d) ]와 같이 Indirect Effect를 계산하는 것입니다.
자세한 설명은 method에서 이어서 진행하도록 하고, 저자들의 contribution을 요약하자면 다음과 같습니다.
contribution
- textual modality와 sentiment label 간의 spurious correlation을 완화하고, MSA 모델의 일반화 능력 측정을 위한 OOD MSA task 정의
- model-agnostic counterfactual multimodal sentiment analysis framework 제안
Preliminary
Causal graph
Causal 그래프는 변수 간의 인과 관계를 나타내는 방향성 비순환 그래프로, 노드는 변수를, 노드 간의 선은 각 변수 간의 인과 관계를 의미합니다.
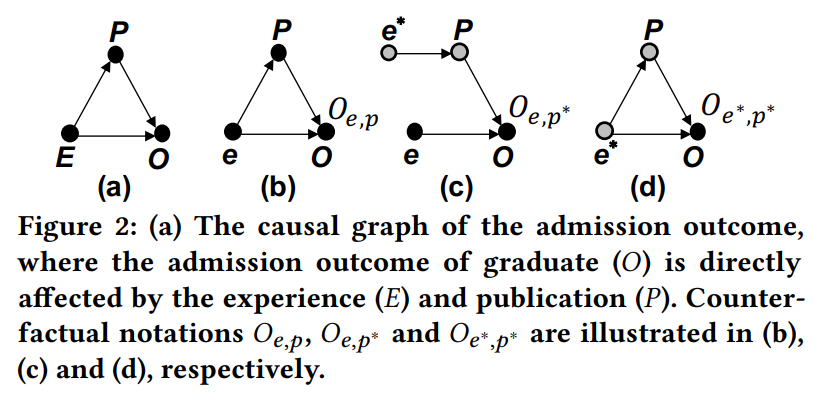
위의 [ 그림 2 ]는 experience, publication, outcome에 대한 causal 그래프를 나타낸 예시로, outcome O는 experience E에 의해 직접적으로 영향을 받고, experience E를 매개로 하는 publication P에 의해 간접적으로 영향을 받는 관계를 나타내고 있습니다.
Counterfactual Inference
이 부분에 관한 설명은 김주연 연구원님의 Counterfactual VQA 논문 리뷰의 intro에도 언급되어 있는데요, Counterfactual Inference factual observation에 기반하여 counterfactual question에 답하는 것, 즉, “만약 실제 일어난 사건과 다른 사건이 발생했다면 그 결과가 어떻게 될 것인가?”를 나타냅니다. 본 논문에서는 실제 발생하지 않은 경우, 즉 counterfactual한 상황을 random variable로 설정하였습니다.
먼저 어떠한 상황이 발생하였음을 수식으로 표현하자면, E = e와 P = p의 조건 하에서 P와 Q의 값은 아래의 [ 수식 1 ]과 같습니다,
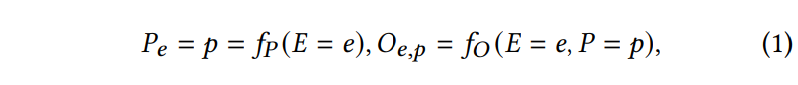
[ 수식 1 ]은 [ 그림 2(b) ]를 식으로 표현한 것으로, 여기서 P_e는 만약 experience e를 가졌다면 그에 따른 publication이 어떻게 될 것인지를 나타내고, O_{e,p}는 만약 experience e와 publication p를 가졌다면 그의 outcome이 어떻게 될 것인지를 나타냅니다.
그 다음, counterfactual은 (*)로 표현하였는데요, [ 그림 2(c) ]는 experience 없이 publication을 가졌다면 outcome이 어떻게 도출될 것인지를 나타낸 것으로, 여기서 O는 E \rightarrow O를 통해 E=e를 받고, P는 E \rightarrow P를 통해 E = e^*를 받습니다. E =e^*는 아무런 experience도 없음을 나타내며, 그 외의 경우는 E = e를 나타냅니다.
Causal effect
Causal affect란 reference 변수 값이 특정 값으로 변경될 때 outcome 변수에서의 차이를 나타내며, 이는 Total Effect (TE)로도 표현될 수 있습니다. 예를 들어, outcome O에 대한 experience E = e의 TE는 아래의 [ 수식 2 ]와 같습니다.
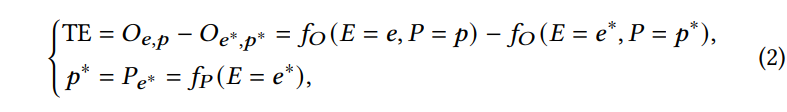
여기서 O_{e^*, p^*}는 reference를 나타내고, E와 P는 각각 e^*와 p^*로 설정되는데, 구체적으로, O_{e^*, p^*}는 만약 experience 없다면 그에 따른 outcome이 어떻게 될 것인지를 나타냅니다. 따라서, TE는 experience가 없는 상태에서 experience 있는 상태로 변할 때의 변화를 나타내는 것이죠.
이러한 TE는 Natural Direct Effect(NDE)와 Total Indirect Effect(TIE)의 합으로 구성되어 있는데, 구체적으로, NDE는 E에서 O로 direct path를 따라 E = e의 효과를 나타내며, E \rightarrow P \rightarrow O에 따른 indirect effect는 고려하지 않습니다. 반면 TIE는 TE와 NDE 사이의 차이를 측정하며, indirect effect path E \rightarrow P \rightarrow O를 따라 E = e^*)에서 E = e)로 변할 때 O의 변화를 나타냅니다. 결론적으로 E = e에 대한 O의 NDE는 다음과 같이 계산할 수 있습니다.
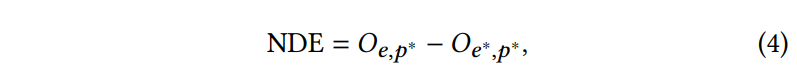
여기서 O_{e,p^*}는 counterfactual situation을 나타내며, E는 e로, P는 p^*로 설정됩니다, 즉, E = e^* 일 때 P의 값입니다. [ 수식 2 ]과 [ 수식 4 ]를 기반으로, [ 수식 5 ]와 같이 TE에서 NDE를 빼서 E = e에 대한 O의 TIE를 얻을 수 있습니다.
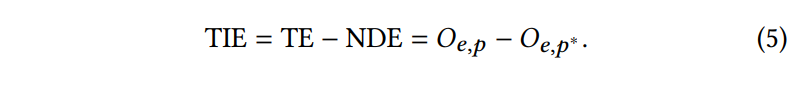
Method
MSA task를 수식으로 정의해보겠습니다. N개의 샘플을 가진 데이터셋은 \mathcal{D} = { ( t_1, a_1, v_1, y_1 ) , \cdots , ( t_N, a_N, v_N, y_N) }로 표현될 수 있습니다. 여기서 t_i, a_i, v_i 및 y_i는 각각 i번째 sample의 text, audio, video 데이터와 감정 label을 나타내는데, MSA의 목적은 t_i, a_i, v_i를 입력하여 y_i를 예측하는 multimodal model \mathcal{F}_{\theta}를 학습하는 것이며, 이때, \hat{y}_i는 i번째 sample에 대한 감정 별 예측 확률, \theta는 model의 learnable parameter입니다.
CLUE Framework
Causal Graph in the MSA Task
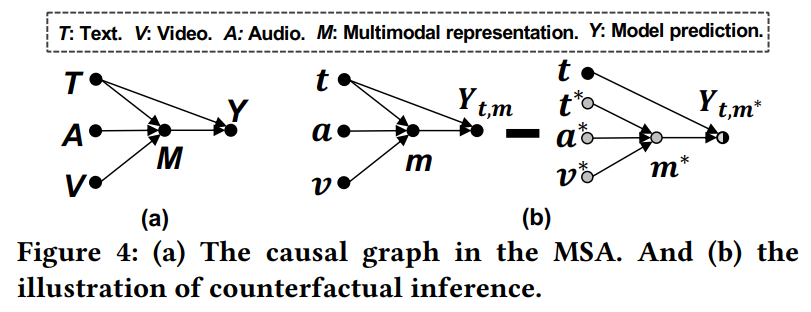
CLUE의 framework 자체는 [그림 4 ]와 같이 간단히 나타낼 수 있습니다. 사실상 [ 그림 2 ]의 experience를 text 모달리티, publication을 v, a, t의 multiomodal representation, outcome을 예측 감정이라고 생각하시면 됩니다. 세 모달리티 T, A, V와 multimodal representation M, 그리고 예측값 Y 사이의 관계는 아래의 두 가지 갈래로 나눌 수 있습니다.
• T \rightarrow Y: 텍스트와 모델 예측값 사이의 shortcut으로, text데이터가 output에 직접적인 영향을 상황이며, 이는 text 모달리티가 label과의 잘못된 correlation을 가져 모델에 bad effect를 끼치는 상황을 나타냅니다.
• (T, A, V) \rightarrow M \rightarrow Y: T, A, V가 mediator M을 통해 모델 예측값에 영향을 미치는 상황으로 text의 간접적 영향을 나타냅니다. M은 multimodal representation으로, 다양한 모달리티 간의 alignment를 기반으로 보다 신뢰도가 높은 정보를 추출합니다. 예를 들어, 기쁜 어조의 목소리와 웃는 얼굴의 비디오가 주어진 경우, 해당 데이터의 의미론적 정보를 통해 모델은 텍스트에서 “great”이라는 단어에 집중하고 “movie”에 의해 발생한 잘못된 상관관계를 filtering하게 됩니다. 즉, T \rightarrow M \rightarrow Y는 text 모달리티의 good effect를 나타내게 됩니다.
Counterfactual MSA Framework
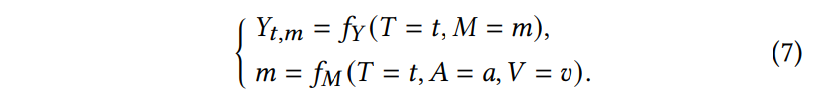
논문에서 제안하는 causal relationships은 [ 수식 7 ]과 같이 나타낼 수 있습니다.
여기서 Y_{t,m}은 M = m과 T = t 상황에서의 모델 예측값입니다. 이때, Y_{t, m}은 여전히 text 모달리티 T = t의 직접적인 영향(bad effect)를 받는다고 할 수 있는데. 이를 분리하기 위해, 저자들은 text 모달리티에 대한 NDE와 TIE를 모델 예측에서 별도로 예측하고자 하였고, 우선 text의 TE와 NDE를 계산한 다음, TE에서 NDE를 빼서 TIE를 계산하였습니다.
T를 기준으로 TE와 NDE를 측정하면 아래의 [수식 8, 9]와 같이 나타낼 수 있습니다.
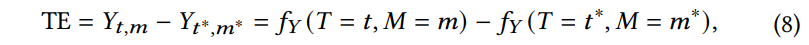
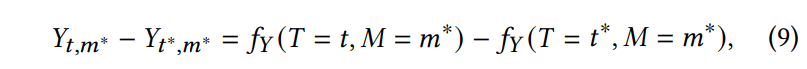
Experiments
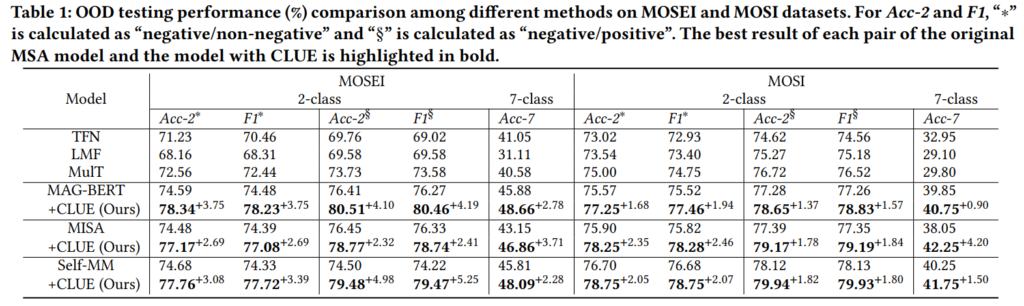
저자들은 실험을 통해 아래의 research question에 대한 결론을 도출하고자 하였습니다.
- RQ1. CLUE가 OOD test 환경에서 MSA 모델의 성능을 향상시킬 수 있는가?
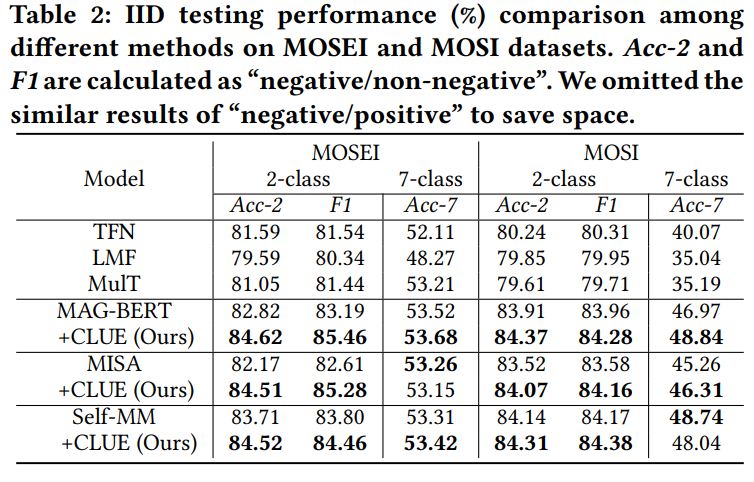
- RQ2. Independent Identically Distributed(IID) 같이 biased 평가 환경에서 CLUE는 어떻게 동작하는가?
- RQ3. CLUE의 각 요소는 결과에 어떤 영향을 미치는가?
Experimental Settings
데이터셋으로는 CMU의 MOSI와 MOSEI 데이터셋 두 가지를 사용하였는데, MOSI는 youtube에서 수집한 독백 영상으로 [-3, 3]범위의 연속 감정으로 labeling되어 있습니다. 이때 label은 -3에 가까울수록 부정적인 감정을, 3에 가까운 값일수록 긍정적인 감정을 나타냅니다. MOSEI의 경우 MOSI 데이터셋의 확장된 버전입니다.
Evaluation Tasks and Metrics
Evaluation metric으로는 MSA task에서 널리 사용되는 metric: 7-class / 2-class classification을 사용하였습니다. 7-class는 GT인 연속 감정을 가장 가까운 정수 값에 매핑하여 [-3, -2, -1, 0, 1, 2, 3]의 7 class를 가지는 것으로 취급한 뒤, 일반적인 분류 문제와 같이 분류 정확도를 구하는 것을 의미합니다. 2-class는 negative/non-negative의 class로 mapping하여 binary classification 하는 것으로, 본 논문에서는 성능 리포팅에 Acc와 함께 F1 score를 사용하였습니다.
안녕하세요 리뷰 감사합니다
실험 파트에서 저자들이 3가지 질문에 대해서 도출하고자 했는데 키워드 단어가 OOD와 IID 같습니다. 궁금한점이 있는데 Table1과 Table2는 동일한 데이터셋으로 실험을 한 것인데 어떻게 OOD상황과 IID 상황을 연출할 수 있었나요? 이 부분에 대해서 따로 어떻게 설정하였는지 궁금합니다
감사합니다