안녕하세요, 이번에도 데이터셋 논문 리뷰입니다.
아마존에서 bin-picking 관련해서 챌린지 관련 논문으로 알고 봤는데 아닌 것 같네요. 다시 한 번 찾아봐야 할 것 같습니다. 이번 논문은 제목에서도 알 수 있듯이 bin-picking을 타겟으로 한 데이터셋이고 크게 어려운 부분은 없는 것 같습니다.
리뷰 시작하겠습니다.
Introduction
bin-picking의 어플리케이션 측면에서는 가득 찬 bin에서 물체를 파악하여 잡아 올리는 로봇과 밀접한 연관이 있습니다.

위 그림(1)과 같은 측면에서 생각하시면 되겠습니다. 빨간색 통과 같은 공간을 bin이라고 합니다. 산업이 발전함에 따라서 최근에는 로봇이 많이 사용이 되는데요. occlusion이 심하거나 clutter한 상황에서 pose estimation을 수행하는 것은 여전히 어려운 문제입니다. 이때 6D pose estimation을 수행하기 위해서는 single RGB 또는 RGB-D 기반의 데이터를 통해 수행을 할 수 있습니다.
최근 딥러닝이 발전하면서 object detection, segmentation, autonomus driving과 같은 테스크들은 실제 데이터를 기반으로 동작하게 됩니다. 데이터셋을 구성하려면 결국 annotation 과정이 필요한데 매우 시간이 오래걸리는 작업이라고 볼 수 있습니다. 6D pose estimation을 위한 기존의 데이터셋에서는 데이터의 양적인면에서도 적었으며 장면에 대한 다양성도 부족합니다. 저자는 이러한 측면을 봤을 때 bin-picking을 하기위한 시나리오에 적합하지 않다고 합니다. 이번 논문에서는 위와 같은 데이터 구성의 문제점들을 해결하는 데이터셋을 제안합니다. 해당 데이터셋은 학습으로 사용되는 합성 데이터 총 198,000장, 테스트로 사용되는 실제 데이터 8,000장으로 구성되어 있습니다.
Related work
최근에는 3D 데이터를 취득할 수 있는 저렴한 센서들이 여럿 등장한 이후 많은 데이터셋들이 나오고 있는 추세입니다.
Occlusion / clutter
LINEMOD는 6D pose estimation에서 자주 나오는 데이터셋입니다. 텍스처가 없는 15개의 물체로 구성되어 모든 클래스를 합쳐 18000개의 RGB-D 이미지들이 구성되어 있는 벤치마크 데이터셋입니다. 해당 데이터셋은 Occluded-LINEMOD으로 모든 물체에 대해 GT가 추가되어 occlusion과 같은 문제들을 해결하기 위한 데이터셋으로 확장되었습니다.
Rutgers APC 데이터셋은 24개의 물체와 1만 개중에 6000개를 테스트셋으로 사용하는 데이터셋입니다. 해당 데이터셋은 occlusion과 clutter에 대한 시나리오로 구성되어 있지만 해당 데이터셋에서 다루는 물체들은 모두 텍스처가 뚜렷한 물체들만 다루므로 산업에서 사용하는 bin-picking의 대상이 될 수 없습니다.
Similar properties
Desk3D, YCB-V, [6], [14]는 동일한 장면을 다른 시점에서 촬영을 했기 때문에 pose의 변화가 제한적이며 데이터의 중복성이 있습니다. 또한 bin-picking을 다루는 것은 [14]에서 말고는 없었다고 하네요.
T-LESS 데이터셋은 30개의 산업 현장에서 사용되는 물체들을 다룹니다. 모두 텍스처가 없는 물체들을 다루지만 이 또한 pose의 가변성과 데이터의 중복이 심하다고 지적합니다.
6D pose에 대한 annotation을 수행하는 것은 많은 시간을 필요로 하는 건 아실 것이라고 생각합니다. 이처럼 시간적으로 많이 소비되고 어려운 과정을 필요로 하기 때문에 대부분의 데이터셋들은 마커를 이용하여 자동으로 생성하는 과정을 사용합니다. 하지만 이 또한 동일한 장면을 여러 번 촬영한 경우 데이터가 중복되어 pose의 유연성이 떨어진다고 합니다. 하지만 해당 경우는 중복된 장면을 제거하면 데이터셋이 적어지므로 학습에 사용하기 위한 데이터가 줄어들게 되는 문제가 있습니다.
[6] A. Tejani, D. Tang, R. Kouskouridas, and T.-K. Kim, “Latent-class hough forests for 3d object detection and pose estimation,” in Euro- pean Conference on Computer Vision (ECCV), 2014.
[14] A. Doumanoglou, R. Kouskouridas, S. Malassiotis, and T.-K. Kim, “Recovering 6d object pose and predicting next-best-view in the crowd,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
Fraunhofer IPA bin-picking Dataset
Sensor Setup
해당 데이터셋은 실제 데이터와 합성 데이터로 나뉘어지는데요.
실제 데이터는 Ensenso N20- 1202-16-BL라는 스테레오 카메라를 사용했다고 합니다. 카메라에 대한 간단한 스펙을 알아보면 범위는 1m ~ 2.4m이며 적정 거리는 1.4m정도라고 합니다. 이미지의 해상도는 1280×1024의 크기로 취득되고, bin 촬영을 진행했다고 합니다.
합성 데이터는 Sile ́ane 데이터셋 에서 사용한 동일한 파라미터를 사용하여 physics simulation(시뮬레이터?)을 사용하였으며 디테일한 요소들을 다룬다고 하네요.
Dataset Description
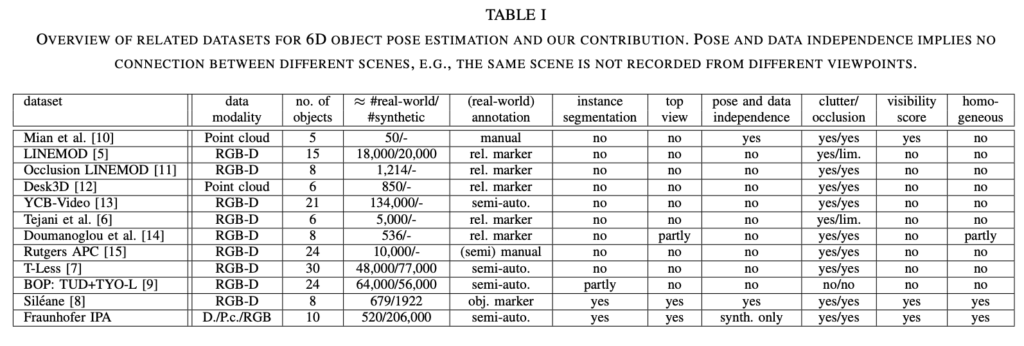
이번 데이터셋은 [8]의 데이터셋과 다른 8개의 대칭 물체들을 다루었고 [7] 데이터셋에서 사용한 물체를 그대로 사용했다고 합니다. 해당 데이터셋에서 새롭게 추가된 산업용 물체는 2가지인 것 같습니다. 해당 물체들은 revolution에 대한 대칭을 가지는 gear shaft와 cyclic에 대한 대칭을 가지는 ring screw를 의미합니다.
해당 데이터셋은 학습셋과 테스트셋이 분리되어있으며 테스트셋 같은 경우 처음에 비워져있던 bin에 반복적으로 채우는 방식으로 연속적인 데이터가 구성되어 있다고 합니다. 해당 절차는 10번의 주기로 구성되어 있으며 특정 한도에 도달되면 종료되는 방식으로 진행됩니다. 학습을 위한 데이터셋은 테스트 셋에 비해 많은 250번의 주기로 구성되지만 이렇게 되면 시간이 많이 걸리면서 annotation이 오래걸리는 이유로 실제 데이터는 사용하지 않는다고 하네요. 즉 학습 데이터에는 모두 합성데이터를 사용하여 구성한 것 같습니다. 합성 데이터를 사용하여 학습한 모델은 오히려 두 도메인의 갭 차이가 발생하는 문제가 발생하여 좋은 결과를 초래하지 못 할 것이라고 생각했지만 이러한 sim2real을 사용한 학습 방법이 오히려 높은 성능을 달성할 수 있다는 증명을 하는 논문을 레퍼런스로 두었네요. 합성 데이터로 사용하는 학습 데이터 같은 경우 이미지 간의 독립적이며 테스트 데이터 같은 경우 종속적이라고 할 수 있습니다. 다시 설명하면 합성 데이터 같은 경우 한 장면에 bin을 채우는 방식으로 구성할 수 있지만 테스트 셋은 record를 할 때 장면이 계속 바뀌게 되므로 이전 장면에 의존적이므로 종속적이라고 할 수 있습니다.
GT pose 라벨링 구성은 다들 아시듯이, Rotation, translation은 기본으로 구성되어있고, visibility score, object ID, segmentation 정보가 들어가 있다고 하네요.
Data Collection Procedure
이전에 언급했던 특정 한도라는 단어를 말했었는데 그 내용을 다루는 섹션입니다.
합성데이터의 경우,
bin-picking이라는 일반적인 장면을 만들기 위해 시뮬레이터를 사용하는 사용하는데 이름은 V-REP라고하네요. 검색해보니 로봇을 사용할 수 있는 시뮬레이터 툴 같은데 이를 이용하여 로봇팔을 생성하여 시뮬레이션을 할 수 있는 유용한 툴 같네요.

그림 (3)과 같이 해당 데이터셋에서 사용하는 ring screw에 대해서 해당 시뮬레이터를 사용한 모습을 보여줍니다. 각 물체들의 3D 모델을 넣어 다양한 위치에서 임의의 방향으로 bin에 넣는식으로 진행했다고 합니다. 자동제어나 동역학을 수강하신 분들은 아시겠지만, 로봇팔과 같은 메니퓰레이터를 사용하는 것은 소프트웨어로만 움직이는 것이 아니라 동역학과 같은 물리적으로 생길 수 있는 영향에 대해 고민을 해야하는데요. 대표적으로 충돌에 대한 고려를 해야합니다. 외부 물체로부터의 충돌도 있겠지만 로봇팔이 움직이면서 self-collision과 같은 문제가 발생할 수 있기 때문에 참고하시면 좋을 것 같습니다. 저자는 이러한 충돌 문제를 다루기 위해 내장된 Bullet이라는 물리엔진을 사용했다고 합니다. 논문에 불릿이라는 물리 엔진을 설명하면서 링크를 Pybullet을 걸어줬는데요. 메인에 보이는 KUBRIC이라는 데이터셋 generator가 눈에 띄네요. 보니 구글에서 만든 툴 같은데 참고하면 좋을 것 같습니다.

그림 (4)는 한 페이지를 차지할 정도로 되게 크네요.. 해당 그림은 저자가 새롭게 추가한 물체에 대한 현실성을 높이기 위해 기존의 사용하던 물체에 대한 파라미터는 바꾸지 않고 않았으며 bin의 pose만 조금씩 바꿔가면서 데이터를 취득했다고 합니다. 빈 bin에서부터 시작해서 물체의 개수를 조금씩 늘려주는 식으로 반복적인 과정을 진행하는데요. 정리하자면 첫 번째 물체 1개를 넣고 비우고 두 번째에는 물체 2개를 넣는식으로 진행하는 식으로 반복적인 과정을 진행하면서 모든 물체들의 pose와 RGB, depth, segmentation에 대해 모두 취득하고 해당 과정은 사전에 정의된 한도 사이클을 도달할 때까지 진행합니다. 그림 (4)는 모든 사이클을 다 돌았을 때에 대한 그림이라고 이해해주시면 되겠습니다. visibility score는 어떻게 계산되는 건지 궁금했는데, 이는 segmentation에 의존적으로 계산되는 것 같습니다. 대상이 되는 물체가 전체 중 어느정도로 보이는지에 대해 계산하는 것 같은데 논문에는 해당 내용에 대해 자세한 설명이 없네요.
실제 데이터의 경우,
합성 데이터와 다르게 가득 찬 bin에서부터 시작하게 되는데요. 물체를 하나씩 제거하면서 진행합니다. 이때 합성 데이터의 경우 bin의 pose를 조금씩 바꾸어가면서 취득을 했지만 실제 데이터에는 고정을 했다고 합니다. 사이클이 도는 동안 bin이 비워질때까지 데이터를 계속 record하며, annotation을 하기 위해 record한 데이터의 순서를 바꾸었다고 합니다. 되게 참신한 방법인 것 같네요. 3D-3D에 대한 align을 맞춰주는 ICP(Iterative Closet Point) 알고리즘을 적용하여 새롭게 추가된 물체의 3D 모델에 대응되는 point cloud를 이용하여 정합을 맞춰주어 6D pose를 얻는다고 합니다.

그림(5)와 같이 gear shaft와 ring screw에 대해 각각 (a)colorized point cloud, (b)real depth (c) synthetic depth (d) segmentation 순으로 구성되어 있는 것을 확인할 수 있습니다. 이처럼 얻어진 6D pose를 바탕으로 시뮬레이터를 이용하여 물체에 대한 visibility score까지 결정할 수 있다고 합니다. 또한 각각의 물체에 대한 실제 depth와 합성 depth를 통하여 annotation 과정에 대한 결과를 입증할 수 있다고 합니다.
Evaluation
해당 데이터셋과 제공하는 3D 모델을 이용하여 point cloud와 함께 depth와 GT를 생성하는 python 기반의 툴을 제공하여 데이터셋을 만드는 것을 편리하게 진행할 수 있었다고 합니다. 해당 데이터셋의 경우 실제 데이터와 합성 데이터를 같이 사용하므로 domain randomization을 함께 사용하면 실제 데이터에서 보다 강인하고 정확한 6D pose를 얻을 수 있다고 합니다. 학습 데이터에 사용되는 합성 이미지에 다양한 augmentation을 적용하여 합성 데이터를 이용하지만 실제 데이터에도 강인하게 작동하는 일반화 된 모델을 만들 수 있다고 합니다.
Evaluation Metric
6D pose estimation 테스크에서 많이 사용되는 ADD/ADD-S를 사용한다고 합니다. 평가메트릭을 또 정리하자면 예측된 pose와 GT pose를 계산하여 3D 모델의 점에 대해 각각 적용했을 때 점과 점 사이에 생기는 거리를 구하고 이를 평균을 내는 과정입니다.
하지만 ADD만으로는 대칭인 물체에 대해 고려를 할 수 없으므로 ADD-S라는 새로운 평가지표를 도입해서 대칭인 물체를 고려하기 위해 거리를 구하는 목표는 같지만 거리가 최소가 되는 점만 사용하여 평균을 내는 것에 차이가 있습니다.
이러한 해당 평가지표를 이용하여 정확도(accuracy)를 측정하는 방법은 ADD(-S)로 표현을 하게 되는데요. 정확도를 측정하기 위해서는 옳은 pose인지 틀린 pose인지를 측정해야 합니다. 이를 위해서 특정 threshold를 걸어놓습니다. 보통 0.1을 걸어놓는데요. GT와의 최소 거리가 3D 물체의 diameter*0.1의 내에 있으면 해당 pose를 TP로 간주하여 정확도를 측정하는 방식입니다.
Object Pose Estimation Challenge for Bin-Picking
이번 데이터셋 같은 경우 실제 EvalAI와 비슷하게 challenge를 개최했었던 데이터셋인 걸로 알고 있습니다. 지금도 진행 중인지는 모르겠네요. BOP challenge에 해당 데이터셋은 없는 걸로 보니 독립적인 challenge인 것 같습니다. 해당 데이터셋을 이용하여 리더보드에 랭킹을 측정하는 식으로 진행하는 것 같은데 가입을 해도 어떻게 보는지 잘 모르겠네요…
Conclusion
이번 데이터셋은 최초로 bin-picking을 위한 벤치마크 데이터셋으로 실제 데이터와 합성 데이터로 구성되어 있으며 기존의 제안된 데이터셋에 물체를 2개 추가하고 보완해서 데이터셋을 publication한 것으로 보입니다. 저자는 더 많은 물체에 대해 다루어 공개하는 것을 향후 연구로 할 것이라고 합니다.
이번 논문을 읽고 사실 기존의 데이터셋을 좀 더 보완하는 것은 합성 데이터를 사용한 것이고, 추가적인 물체를 다루는 것 말고는 어떤 게 크게 달라졌는지 모르겠지만 당시에는 제안된 데이터셋을 보완하고 추가적인 데이터를 만들어내는 것 또한 큰 가치로 여겨진 것 같습니다.
이상으로 리뷰 마치도록 하겠습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
데이터셋을 구성하는데 있어서 250번, 10번의 주기라는 단어를 사용하셨는데 여기서 주기는 정확히 어떤 과정을 뜻하나요 ? 학습 데이터에서는 한 개의 물체에서 시작해서 여러개의 물체가 모두 bin에 담겨진 데이터가 취득되는 동안을 의미하며 테스트 데이터에서는 반대로 물체가 가득 찬 bin에서 아무것도 담겨있지 않을 때까지 recoding되는 과정이라고 이해하면 될까요?
그런데 왜 학습 데이터에서는 독립적으로 bin의 구성을 바꾸며 채워나가는 방식으로 구성하고 테스트 데이터는 리코딩을 통해 서로의 장면을 종속적으로 구성하나요 ?? 두 구성의 차이가 학습/테스트를 나누는 기준이 된 이유가 궁금합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 네, 물체가 모두 채워졌을 때를 기준으로 주기가 하나씩 증가하는 것으로 이해하시면 되겠습니다. 하지만, bin안에 몇개가 채워져야 모두 채워진 것으로 한도를 정하건지 명시가 되어있지 않네요.
2. 먼저 합성 데이터 같은 경우 시뮬레이터를 이용하여 얻기 때문에 연속적으로 얻을 수도 있지만 연속적이지 않은 프레임으로도 얻을 수 있습니다. 연속적인 장면을 구성해서 촬영하는 것이 아니라 한 프레임씩 채워서 하는 게 가능하므로 연속적이지 않다고 말할 수 있으며 이전 장면에 대해 독립적이라고 할 수 있습니다. 종속/독립을 이야기하는 것은 실제 데이터와 합성 데이터를 얻을 때에 대한 특징이라고 볼 수 있습니다. 하지만 이런 내용 때문에 train/test의 구성에 대한 기준이 나뉘게 되는 것은 아니고 합성데이터로만 구성한 학습셋과 실제 데이터로만 구성된 테스트셋으로 구성하였고 해당 합성 데이터를 사용한 학습으로도 domain gap이 크게 발생하지 않는다는 어떤 레퍼런스로 논문을 입증하고 있습니다