안녕하세요. Video task에서 backbone으로 자주 활용되는 SlowFast 모델을 리뷰하겠습니다.
Motivation
Artificial Neural Network 즉, 인공신경망은 생물신경망에서 영감을 받아 고안되었습니다. 물론 인공신경망과 생물신경망이 실제로 작동하는 방식은 완전히 같지는 않지만, 정보를 받아 간단한 연산을 수행하고 정보를 다시 전달하는 Neuron(뉴런)들이 여러개 연결된 Network(망)으로 작동하는 생물신경망의 구조를 인공신경망이 모방했기 때문입니다. 이처럼 인공지능은 때때로 생명체가 작동하는 방식, 좀 더 구체적으로는 생명체가 정보를 처리하는 방식을 모방하는 것으로 발전합니다. Convolutional Neural Network(CNN: 합성곱 신경망) 또한 뉴런의 연결패턴이 동물 시각 피질의 조직과 유사하다는 점에서 영감을 받아 개별 피질 뉴런은 receptive field(수용장)으로 알려진 시야의 제한된 영역에서만 자극에 반응하고 상이한 뉴런의 receptive field는 전체 시야를 볼 수 있도록 부분적으로 중첩됩니다(https://ko.wikipedia.org/wiki/합성곱_신경망).
SlowFast 방법론 또한 동물의 시각정보처리방식에서 영감을 받아 고안되었습니다. 저자는 SlowFast가 영장류의 시각계에 있는 망막 신경절 세포(Retinal ganglion cells, RGCs)가 시각 정보를 처리하는 방식을 모방했다고 밝힙니다. 최신 연구에서 망막 신경적 세포는 약 80%의 Parvocellular Cells(이하 P-cells)와 20%의 Magnocellular Cells(이하 M-cells)로 이뤄져있다는 것을 발표합니다. 연구에 의하면 M-cells는 high temporal frequency작동하고 fast temporal changes에 반응하지만 spatial detail과 color에는 둔감하고, P-cells는 섬세하게 spatial detail과 color에 반응하지만, lower temporal frequency 즉, 자극(시각적 변화)에는 천천히 반응합니다.
SlowFast Network
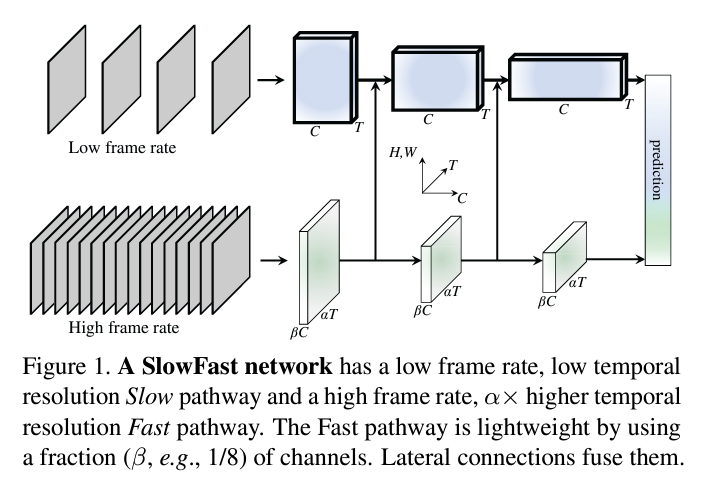
SlowFast 네트워크는 두개의 다른 framerates를 다루는 single stream architecture라고 할 수 있지만, 망막 신경절 세포에서 영감을 받았다는 것을 컨셉으로 했기에 2 pathway를 강조했다고 언급하고 있습니다.
Slow pathway
Slow pathway의 구조는 모든 convolutional model이 될 수 있습니다. 어느 모델을 사용해도 무관하다는 것을 의미함으로 해당 논문에서의 저자는 ResNet을 채용했습니다. Slow pathway의 중요한 컨셉은 large temporal stride τ를 갖는 것입니다. 다시 말하면 τ프레임 당 1개의 프레임을 사용한다. 저자가 연구한 τ의 일반적인 값은 16입니다. 이는 30fps 비디오의 경우 초당 약 2프레임 샘플링됩니다. 샘플링되는 프레임의 수를 T라고 할때 raw clip의 길이는 T*τ 프레임이 됩니다.
Fast pathway
Slow pathway와 병렬적으로 진행되는 다른 convolutional model입니다.
Fast pathway는 small temporal stride: τ/α (α>1)을 갖는다. 이때 α는 Fast, Slow의 frame rate이다. Slow, Fast는 같은 raw clip을 input으로 받는다. Fast pathway는 αT프레임을 샘플링한다. Slow에 비해 α배만큼 dense하다. 저자가 연구한 α의 일반적인 값은 8입니다. 이 α값이 SlowFast 컨셉에서 key입니다. 두 pathway가 다른 temporal speeds를 갖는다는 것을 의미하기 때문입니다.
Fast pathway는 높은 input resolution을 갖는 것뿐만 아니라 네트워크 layer 전체에 걸쳐서 high resolution을 추구합니다. temporal pooling과 time-strided convolution도 없습니다. 즉, Fast pathway는 global average pooling layer에 이를 때까지, feature tensor가 항상 시간 차원을 따라 αT 프레임을 유지하며 temporal fidelity를 가능한 한 유지합니다.
Fast pathway는 훨씬 낮은 채널 용량을 사용하여 더 가벼운 모델이 됩니다. Slow pathway의 채널 수에 비해 β (β < 1)의 비율을 가집니다. 저자는 β = 1/8 값을 사용합니다. 연산의 수는 β의 제곱에 비례합니다. 이것이 바로 Fast pathway가 Slow pathway보다 계산 효율성이 더 높은 이유입니다. Fast pathway는 전체 계산의 대략 20%를 차지합니다. 실제로 망막 신경절 세포의 약 15-20%가 M-세포로 구성되어 있습니다. 저자가 제안하는 SlowFast 모델이 실제 동물이 motion을 인식하는 것과 굉장히 비슷하다는 것을 보여줍니다.
낮은 채널 용량은 spatial semantics를 나타내는 능력이 약하다는 것을 의미하기도 합니다. 기술적으로, Fast pathway는 spatial dimension에 채널이 적어 Slow pathway보다 spatial modeling capacity가 안 좋습니다. 하지만, 저자는 SlowFast 모델의 Fast pathway가 spatial modeling capacity가 안 좋은 것은 temporal modeling capacity가 올라가 있기 때문에 적절한 trade-off라고 주장합니다.
Lateral Connections
두 pathway의 정보는 두 pathway 사이에 lateral connections, 즉 옆으로 연결되는 통로를 사용하여 정보를 통합합니다. lateral connections는 서로 다른 spatial resolution과 semantics를 통합합니다.
저자는 “stage”마다 두 pathway 사이에 한 개의 lateral connection을 붙입니다. Slow pathway에서 ResNet을 채용했다고 언급을 했었는데 저자는 ResNet에서 pool1, res2, res3, 그리고 res4 뒤에서 lateral connection을 붙여 fuse합니다. 두 pathway는 서로 다른 temporal dimensions을 가지고 있기 때문에, lateral connections은 transformation을 수행하여 temporal dimensions를 맞춥니다. 마지막에는 각 pathway의 output에 대해 global average pooling을 수행한 다음, 두 개의 특징 벡터가 연결되어 fully-connected layer의 입력이 됩니다. 밑의 그림에 자세한 모델의 구조가 있습니다.
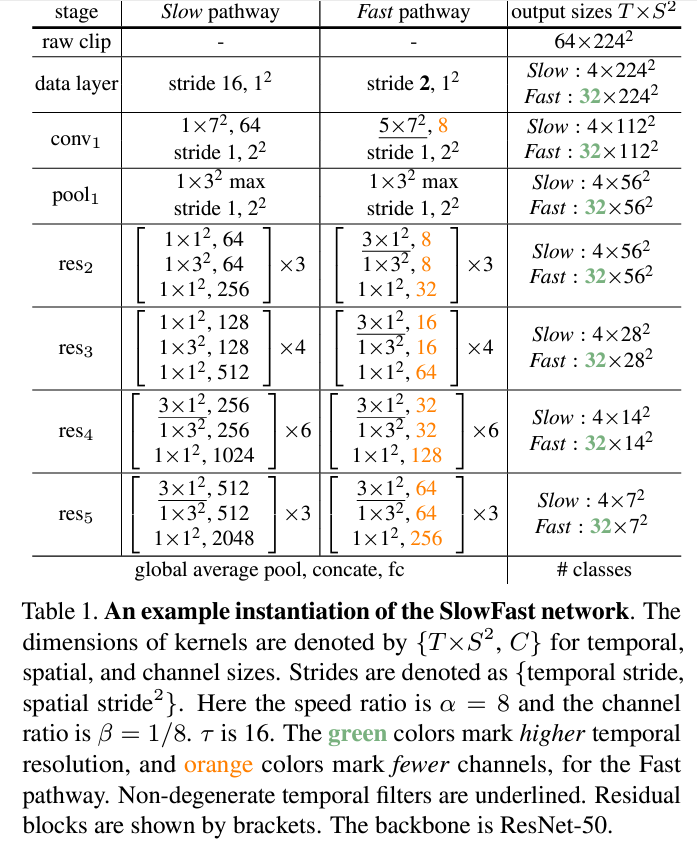
Lateral connection의 경우, 총 3개의 방법으로 fusion했으며 각각의 방법은 다음과 같습니다.
- Time-to-channel(TtoC): {αT*S*S, βC} -> {T*S*S, αβC}로 tranpose하는 방식으로 α개의 frame이 채널로 tranpose됩니다.
- Time-strided sampling(T-sample): α개의 frame중에 하나를 sampling해서 {αT*S*S, βC} -> {T*S*S, βC}로 바꿉니다.
- Time-strided convolution(T-conv): 5×1×1 kernel로 2βC의 output channel과 stride α로 3D convolution을 수행해 바꿉니다.
이후 Experiment에 의하면 T-conv의 방식이 제일 좋다고 합니다.
Instantiations
SlowFast의 개념은 일반적으로 사용될 수 있습니다. 저자는 ResNet을 활용했지만, ResNet이 아니더라도 다양한 backbone모델을 사용자의 입맛에 맞게 구체화될 수 있습니다. 위의 Table 1.은 저자가 구현한 SlowFast의 구조로 자세한 설명은 하지않지만, 위에서의 Slow pathway, Fast pathway의 철학에 맞게 ResNet을 활용하여 재구성했습니다.
Experiments
SlowFast가 3D features를 다른 모델이 비해 얼마나 잘 뽑을 수 있는 지를 실험을 통해보여줍니다.
Action Classification
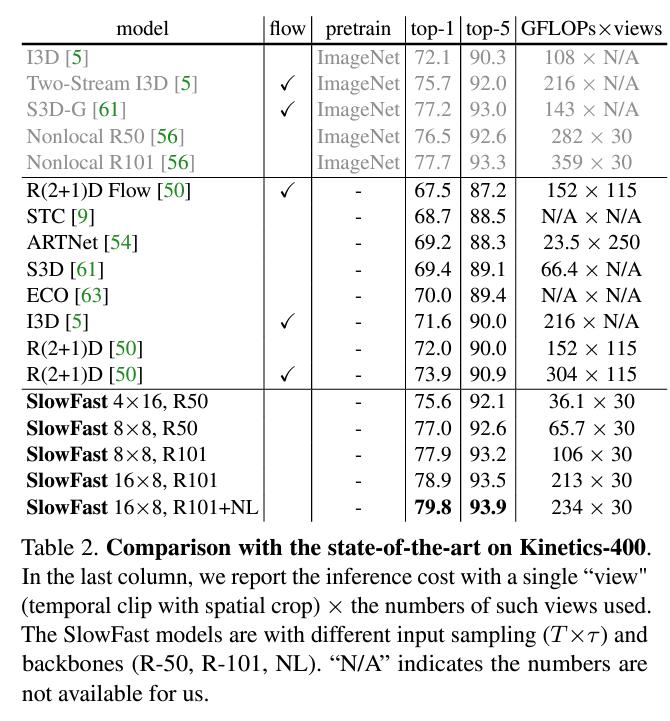
위의 표는 Kinetics 데이터셋에서의 SlowFast 모델이 얼마나 좋은 성능을 내는지를 보여줍니다. 여기서의 NL은 Non-local 모델의 non-local blocks를 의미합니다. ResNet101 모델과 NL block을 사용하는 것으로 제일 좋은 성능을 보여줍니다. 제가 NL block에 대해 잘 알지 못하는데 해당 논문에서는 NL block에 대한 추가설명을 논문에서 하고있지는 않아 어떤 역할을 하는지는 잘 모르겠네요. NL block없이 ResNet101만을 사용했을 때에도 기존 SOTA였던 I3D 모델보다 좋은 성능을 보여주는 것을 확인할 수 있습니다.
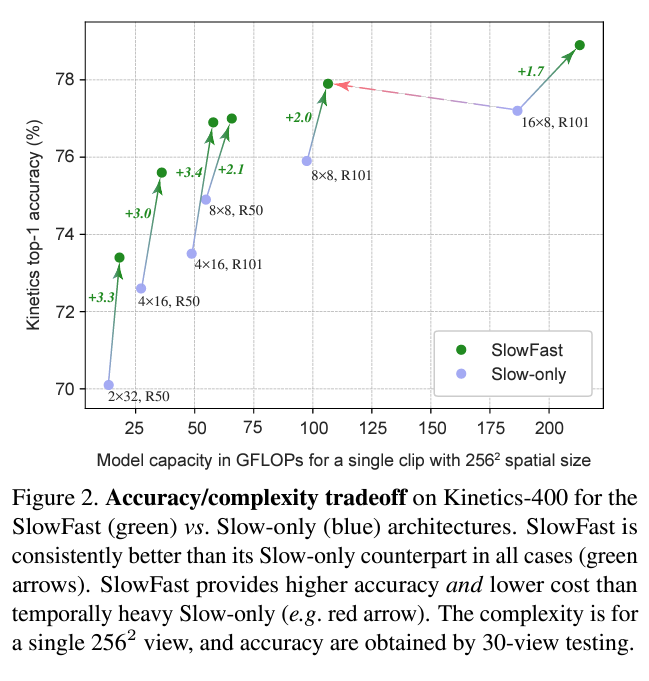
Figure 2.는 SlowFast에서 Slow pathway와 Fast pathway를 같이 사용하여 Fast pathway의 temporal 정보를 활용하는 것이 얼마나 효율이 좋은 지를 또 Slow와 Fast의 비율을 어떻게 조정하는 것이 더 좋은 효율을 내는 지를 확인할 수 있습니다.
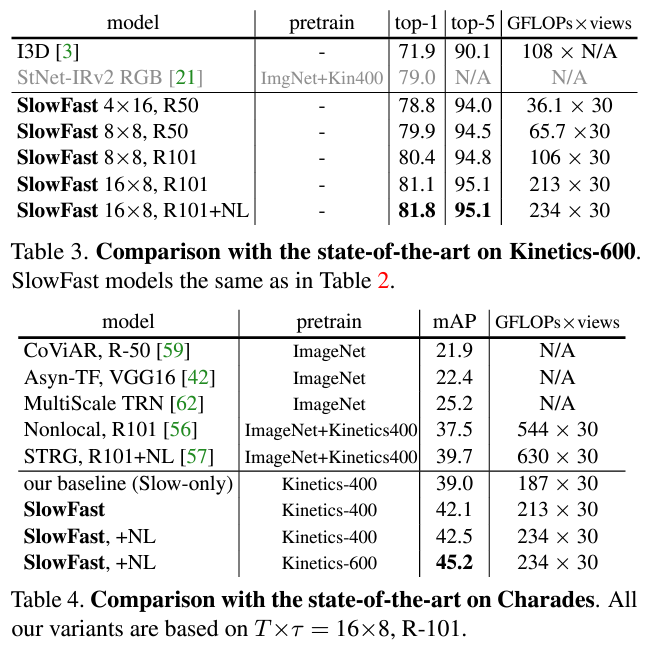
위의 표는 Charades 데이터셋에 대한 성능표입니다.
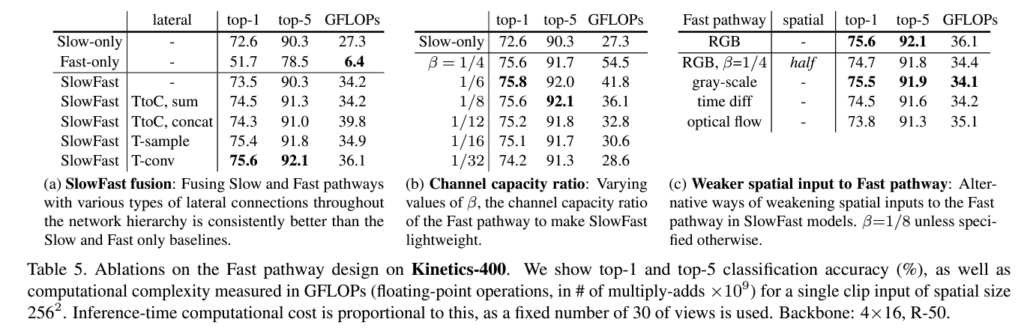
위의 표는 Fast pathway에 대한 실험으로 (a)에 의하면 Slow pathway와 Fast pathway를 같이 사용하는 것이 가장 좋은 성능을 보입니다. Fast pathway에서 Slow pathway에서 T-conv를 사용한 lateral connection이 가장 좋은 성능을 보이는 것을 설명합니다. (b)는 fusion을 위해 각 pathway의 feature의 크기를 나타낼 때 사용하는 β 값에 대한 실험 결과로 1/6, 1/8이 제일 좋은 성능을 보입니다. (c)는 Fast pathway에서 spatial semantics와 color가 효율이 좋지 않은 것을 보여주는 것으로 Fast pathway는 spatial 정보보다는 temporal 정보에 집중한다는 것을 보여줍니다.
Conclusion
SlowFast는 실제 동물의 망막 신경절 세포의 작동방식에서 영감을 받아 작동방식을 모방하는 것으로 temporal 정보를 잘 다룰 수 있는 모델을 구상했습니다. 실제로도 좋은 성능을 보여주며 현재 연구에서도 backbone으로 자주 활용되는 모델입니다. SlowFast 모델과 같이 spatial정보와 temporal 정보를 다루는 두개의 pathway의 architecture는 저로써는 굉장히 신기하고 동시에 좋은 성능을 낸다는 것이 인상적이네요.
안녕하세요 박성준 연구원님 좋은 리뷰 감사합니다.
결국 두 pathway에서 sampling rate를 다르게 함으로써 temporal 정보와 영상의 detail을 둘다 확보하는 방법론으로 이해하였습니다.
질문이 있는데요, 각 stage마다 lateral connection으로 두 feature를 fusion하는 것으로 이해하였는데 그렇다면 이 backbone의 최종 output은 어떤 형태로 나오는 지 궁금합니다. 각 pathway의 output으로 두 개의 feature가 나올텐데 본 논문처럼 단순히 gap 후에 concat하는 방식을 사용하나요?
혜원님 답변 달아주셔서 감사합니다.
sampling rate를 다르게 함으로 temporal 정보와 영상의 detail을 둘다 확보하는 방법 맞습니다. backbone의 최종 output은 혜원님이 언급해주신대로 각 pathway의 output 두개의 feature를 gap한 후에 concat하는 방식으로 구현했습니다.
안녕하세요 좋은 리뷰 감사합니다.
3가지 lateral connection 방식 중 T-conv 이외 두 가지는 각각 transpose, sampling 방식이기에 학습 기반인 T-Conv가 성능이 가장 좋을 것으로 간단하게 생각해볼 수 있습니다. 이에 대해 저자가 직접 언급한 논리적인 이유가 있나요?
그리고 벤치마크 표에서 view가 무엇을 의미하는지도 같이 적어주시면 좋을 것 같습니다.
현우님 좋은 답변 감사합니다.
논문에서는 Ablation Experiments를 통해 T-conv의 성능이 제일 좋은 것을 실험적으로 증명했다고 언급하지만 T-conv가 다른 두 방식에 비해 왜 좋은 지에 대한 고찰은 없습니다. 이에 대한 제 의견을 붙이자면 현우님이 언급해주신 것처럼 convolution 방식이 transpose, sampling과 달리 학습을 통해 가중치를 조정하기에 성능이 가장 좋은 것으로 생각됩니다.
벤치마크에서의 view는 표의 맨 오른쪽 연산량을 계산하는 데에 있어 방법론마다 cropping, clipping등을 inference하는 방식이 다르기에 방법론마다 사용하는 input image의 spatial size와 프레임 수를 나타냅니다. 예를 들어, 10 temporal clips each with 3 spatial crops 즉, 각각 3가지 다른 위치에서 시작한 10개의 영상 클립을 사용한 경우 30views가 됩니다. 본문에서는 view에 대한 설명이 부족했네요. Experiments관련 이해를 위해 설명이 필요한 부분은 빠짐없이 작성하도록 하겠습니다. 피드백 주셔서 감사합니다.