안녕하세요, 스물 한 번째 x-review 입니다. 이번 논문은 2023년도 ICCV에 게재된 이미지 3D Object Detection 논문 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
indoor 기반 3D Object Detection은 현재까지 활발하게 진행되고 있는 연구 분야인데 최근까지의 연구는 보통 포인트 클라우드 기반의 방법론의 성능을 검증하는 방향이었습니다. 그러나 이러한 연구 방향을 실용성 관점에서 보았을 때 depth 카메라, 스테레오 센서, 혹은 레이저 스캐너와 같이 비싼 3D 센서로부터 취득할 수 있는 데이터 의존성이 높다는 한계가 존재합니다. 3D 센서에서 얻는 포인트 클라우드와 다르게 RGB 이미지는 가격이 보다 합리적일 뿐만 아니라 인간의 시각과 유사한 정보를 취득할 수 있습니다. 그렇기 때문에 이미지 기반의 indoor 3D Object Detection은 중요한 연구 방향 중 하나 입니다.
이미지 기반에서도 두 갈래로 나눌 수 있는데 먼저 단안 이미지로의 3D Object Detection 입니다. 이는 만족스러운 수준의 정확도를 보이곤 있지만 하나의 RGB 이미지만으로 3차원 물체를 검출하기 위해 직면해야하는 한계점들이 존재합니다. 이미지 내 물체들에 대한 스케일이 모호하거나 겹쳐져 있거나 혹은 제한된 FoV가 이에 해당합니다. 그래서 자연스럽게 scene의 더 많은 정보를 제공해주기 위해서 멀티 뷰 이미지를 입력으로 사용하기 시작했고 3차원 검출에서 더 강인한 성능을 보이기 시작했습니다. 멀티뷰 이미지가 입력으로 들어가게 되면 2D feature을 3차원 공간에서 활용하기 위해 볼륨을 사용해야하는데, 지금까지의 볼륨 생성은 실질적인 기하학적 특성을 무시한 채 단순 합쳐지는 형태를 이루었기에 이러한 점을 저자는 문제로 정의하게 되었습니다.
그래서 본 논문에서는 기하학적 특성을 고려하여 볼륨을 표현할 수 있는 ImGeoNet을 제안합니다. 3차원에서 free 공간, 2차원으로 따지면 background와 같은 영역에 대한 복셀의 영향력을 줄이고자 하였습니다. 그래서 각 복셀 그리드가 물체 표면 위에 존재할 가능성을 예측한 다음, 예측한 가능성을 바탕으로 볼륨에 가중치를 차등적으로 주게 됩니다. 이러한 구조는 모델이 물체와 free 공간 사이를 잘 구분짓게 해줌으로써 검출 성능 향상에 영향을 미칩니다.
ImGeoNet은 세 개의 indoor 데이터셋 ARKitScene, ScanNetV2 그리고 ScanNet200에서 평가를 진행하였고 제가 바로 이전에 리뷰한 ImVoxelNet과 비교하였을 때 큰 차이를 두고 SOTA를 달성하였습니다. 특히 흥미로웠던 점은 3차원 검출에서 영향력이 큰 포인트 클라우드 기반의 모델보다도 높은 성능을 보이면서 이미지 기반 3차원 검출의 가능성을 보였다는 것 입니다. 자세한 내용은 실험 파트에서 다루도록 하고 여기서 본 논문의 main contribution을 살펴보면 다음과 같습니다.
- 멀티뷰 입력 데이터로 기하학적 정보를 파악할 수 있는 새로운 3차원 물체 검출 프레임워크 제안
- 3개의 indoor 데이터셋에서 SOTA 달성
- 포인트 클라우드 기반 모델인 VoteNet과 2가지 시나리오에서 경쟁력 있는 성능 달성
2. Related Work
2.1. Image-based Object Detection
Monocular Object Detection
단안 이미지 3D 물체 검출은 실용성과 비용 측면에서 상당히 효율적인데요, 일부 방식에서는 depth map feature 추출을 위해서 추가적인 백본을 사용하거나 혹은 depth 이미지를 3차원 수도 포인트 클라우드에 역사영 하게 됩니다. 그 중에서 indoor 환경의 경우 예측해야 할 물체의 클래스 별로 3차원 shape을 활용하여 물체를 감지하는 연구가 존재합니다. 최근 들어서는 물체 검출을 scene understanding 분야의 downstream task로 간주하여 연구가 진행되고 있습니다. 그러나 단안 이미지 사용의 경우 introduction에서 이야기한 것처럼 scene의 스케일이 모호가고 occlusion 되거나 FoV가 제한적이라는 큰 한계점이 존재합니다.
Multi-view Object Detection
멀티뷰에서는 DETR을 확장하여 활용하거나 BEV 이미지에서 자율 주행 관점에서 3차원 물체를 검출하고자 하였습니다. 하지만 indoor 환경은 일반적인 자율 주행 환경과 달리 outdoor에 존재하지 않는 다양한 종류의 물체 클래스가 포함되기 때문에 위와 같은 방식은 indoor 환경에서 효과적으로 작동할 수 없습니다. 가장 주목할만한 방법론은 ImVoxelNet으로 3차원 복셀 기반의 feature 볼륨을 형성하여 indoor 3차원 물체 검출에서 눈에 띄는 성능 향상을 보였습니다. 그러나 ImVoxelNet의 feature 볼륨은 볼륨을 생성하는 과정에서 입력으로 들어오는 scene의 기하학적인 구조를 담지 못한다는 한계가 존재하여 본 논문에서는 이를 보완하기 위한 ImGeoNet을 제안하게 된 것입니다.
3. Approach
Problem Formulation
같은 장면을 여러 뷰로 촬영한 임의의 정해지지 않은 수의 이미지 \{I_t\} \subseteq \mathbb{R}^{H \times W \times 3}와 대응하는 내부 파라미터 \{K_t\} \subseteq \mathbb{R}^{3 \times 3} 그리고 카메라 포즈 정보 \{T_t\} \subseteq SE(3)가 입력으로 주어집니다. 예측 결과로는 3차원 물체 검출의 목적처럼 물체의 카테고리 정보와 3차원 바운딩 박스 \{b\} \subseteq \mathbb{R}^7가 나오게 됩니다. 바운딩 박스의 파라미터는 (x, y, z, w, h, l, \phi) 총 7개로 그 중 (x, y, z)는 박스의 중심 좌표를, (w, h, l)은 박스의 사이즈, 그리고 \phi은 yaw 앵글을 의미합니다.
Framework Overview
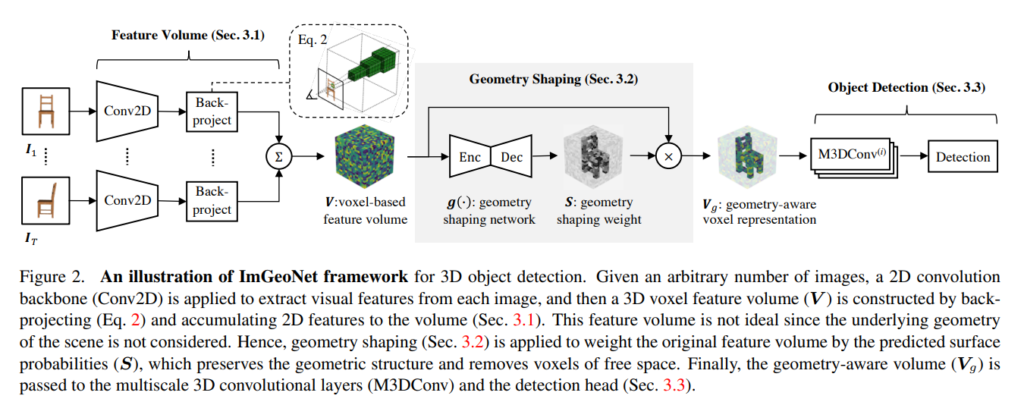
우선 간략하게 구조의 파이프라인을 살펴보도록 하겠습니다. ImGeoNet은 2D 백본 네트워크를 거친 feature을 3차원으로 역사영하여 복셀 볼륨을 형성합니다. 그러면 2D feature는 카메라 중앙으로부터 방출되는 ray를 따라 복셀에 복제됩니다. 그러나 이런 과정으로 얻은 3차원 복셀 볼륨은 free 공간의 복셀 그리드에 의미 없는 정보를 부여하게 될 수도 있어 검출 성능 저하를 일으킵니다. 그래서 1차적으로 위와 같이 형성한 복셀 볼륨에 기하학적인 정보를 포함시키기 위해서 **geometry shaping(gs)**을 수행합니다. gs는 복셀이 정말로 물체 표면에 위치하는, 즉 물체가 존재하는 영역인지에 대한 확률을 계산하여 확률에 따라 각 복셀 feature에 가중치를 부여합니다. 결국 background를 의미하는 free 공간에는 낮은 가중치가 할당되면서 물체 표면에 해당하는 복셀에는 높은 가중치가 부여되면서 다양한 시점에서의 2D feature 정보를 합칠 수 있게 됩니다. 학습 때는 GT 포인트 클라우드를 복셀로 변환하여 gs 네트워크를 학습하고 이전 3차원 물체 검출 태스크가 그러듯이 각 복셀의 바운딩 박스를 예측한 후 NMS를 수행하여 최종 예측 결과를 얻게 됩니다.
3.1. Feature Volume
3차원 물체 검출을 위해서는 2D 이미지로는 얻을 수 없는 주어진 scene에 대한 기하학적인 구조를 파악할 수 있어야 하겠죠. feature 볼륨은 스테레오 매칭이나 surface reconstruction과 같이 scene의 기하학 구조에 대한 태스크에서 이미 효과를 입증하고 사용되고 있습니다.
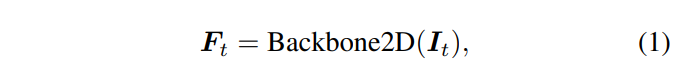
따라서 본 논문에서도 feature 볼륨 V \in \mathbb{R}^{H_v \times W_v \times D_v \times C}을 사용하고 있으며 그 이전에 입력으로 들어오는 데이터 중 I_t에서 식(1)과 같이 사전학습된 2D backbone을 통해 feature을 추출하고 있습니다. 참고로 복셀 V에서 H_v, W_v, D_v는 복셀의 크기 단위로 볼륨의 측면 길이를 나타내며 C는 featre의 차원을 의미합니다.
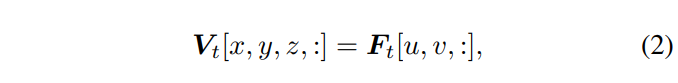
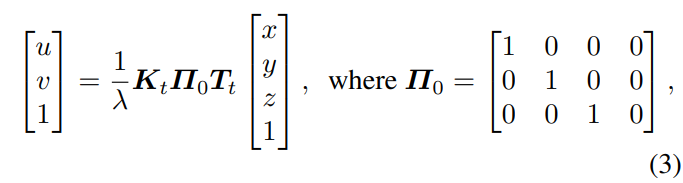
백본 네트워크를 거친 feature는 식(2)와 같이 3차원 볼륨으로 역사용되는데 픽셀 좌표 (u, v)는 복셀 중심 (x, y, z)로부터 계산되며 \lambda는 복셀 중심과 카메라 중심 사이의 광축 거리를 의미합니다. 실제로 복셀 중심에서 해당 역사영 2D feature을 찾게 됩니다. 만약 view 안에 포함되지 않고 외부에 위치한 복셀이 있다면 해당 복셀의 featur는 0으로 값을 채웁니다.
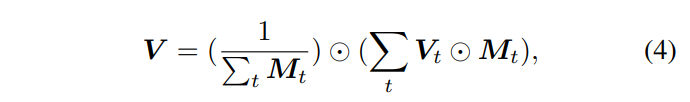
이렇게 계산된 V_t가 여러 뷰에서 계산이 될 것이며 역사영된 모든 V_t의 평균을 구하여 feature 볼륨 V를 식(4)처럼 구성하게 됩니다. M_t는 이진 마스크로 이전에 리뷰한 ImVoxelNet에서도 사용한 개념이네요. 복셀이 I_t의 뷰 범위에 있는지를 여부를 판단하기 위해 사용합니다.
3.2. Geometry Shaping
이렇게 구성한 featue 볼륨은 앞서 계속 이야기 하였듯이 scene의 기하학적인 구조는 고려하지 않은 채 단순 역사영하여 얻게 됩니다. 특히나 각 복셀은 해당 복셀이 카메라 광선을 따라 가까운 표면에 존재하는지 여부와 관계없이 모두 동일한 feature 값이 할당됩니다. 가장 큰 문제는 물체 표면에 존재하지 않는 복셀에 값이 할당되어 검출 모듈이 잘못된 예측을 할 가능성이 높은 것이겠죠. 이를 위해 멀티 뷰 이미지를 통해 기하학적인 정보를 얻고 물체가 존재하지 않아 비어있어야 할 복셀에는 가중치를 낮춤으로써 노이즈를 제거할 수 있는 gs를 제안하고 있습니다.
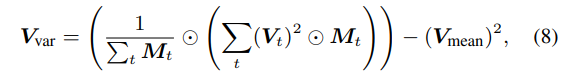
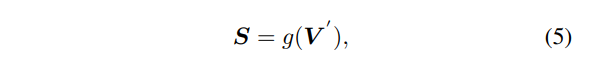
eature 분산을 고려하여 식(8)을 feature 볼륨 V과 연결하여 V’을 계산합니다. V’을 gs 네트워크 g를 통해 geometry shaping 볼륨 S를 생성합니다. 식(8)에 대해 더 설명하자면 V_{mean}이 식(4)를 통해 계산된 V와 동일하며 Var(X) = E[X^2] - E[X]^2 분산 식을 활용한 것 입니다. 결국 gs 네트워크는 표면 복셀을 예측하기 위한 입력으로 V_{mean}과 V_{var}가 합쳐진 값을 활용하는 것이죠.
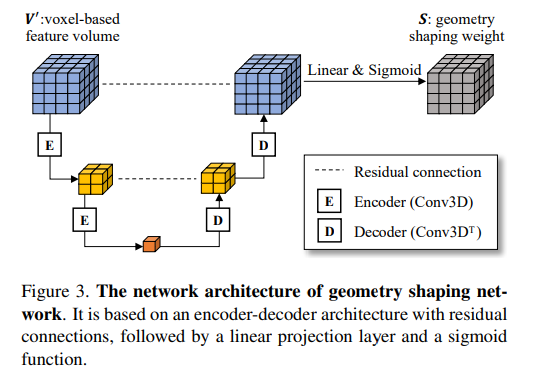
S는 합쳐진 feature 볼륨 V’와 동일한 그리드 크기를 가지며 복셀이 물체 표면에 존재할 가능성을 나타냅니다. 구체적으로 Figure 3과 같이 residual connection의 인코더 디코더 구조로, 인코더는 3개의 3D 컨볼루션 레이어와 디코더는 하나의 transpose 3D 컨볼루션 레이어와 하나의 3D 컨볼루션 레이어로 구성되어 있습니다.
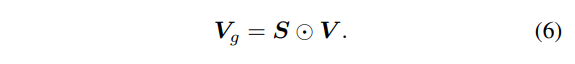
이제 각 복셀이 물체 표면에 존재할 가능성이 얼마나 되는지를 알았으니 기존 feature 볼륨에 가중치로 활용해주면 되겠죠. 가중치는 free 공간에서 더 작은 값을 가지기 때문에 V_g는 주로 물체 표면에 대한 값으로 남아 기하학 정보를 더 잘 설명하여 최종 예측의 정확도를 더욱 향상시킬 수 있습니다.
실제로 구현에 있어서 RGB-D 프레임을 포인트 클라우드로 변환한 후, 적어도 하나의 포인트를 포함하고 있다면 해당 복셀은 표면 복셀이라고 간주합니다. 또한 각 카메라 광선에 대해 특정 마진을 설정하여 설정한 마진 내에서 표면 복셀에 인접한 위치 역시 positive로 간주합니다. 그 후에 focal loss를 이용한 표면 복셀 여부를 예측함으로써 gs 네트워크를 end-to-end로 학습합니다. 학습 단계에서는 depth 센서 데이터만 gs 네트워크를 학습하는데 사용되며 inference 단계에서 멀티뷰 이미지만을 활용하게 됩니다.
3.3. Object Detection
식(6)에서 얻은 V_g에 대해서 저자는 아직까지 다양한 스케일의 물체를 구분하는데는 여전히 한계가 존재한다고 합니다. 따라서 멀티 스케일의 dense 3D 컨볼루션 레이어로 한 번 더 변환합니다.
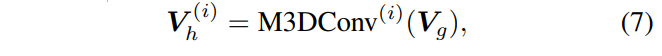
여기서 i \in \{0, 1, . . . , L - 1\}은 스케일 인덱스이며 서로 다른 스케일의 볼륨은 다른 그리드 크기로 이루어져 있습니다. detection 헤드는 ImVoxelNet에서 2D detector인 FCOS를 변형하여 구성한 head와 마찬가지로 2D detector을 3D 볼륨으로 확장하고 있습니다. L개 스케일의 모든 위치를 고려하여 각 위치에 대한 분류 확률, centerness, 그리고 3차원 바운딩 박스를 예측합니다.
4. Experiment
본 논문에서는 ARKitScenes, ScanNetV2, 그리고 ScanNet200 데이터셋 3가지로 실험을 진행하는데 ARKitScenes와 ScanNet200 같은 경우에는 저도 익숙하지 않은 데이터셋이라서 한번 살펴보고 넘어가려고 합니다.
ARKitScenes
아이패드로 촬영한 RGB-D 비디오 데이터셋으로 사용하는 세 가지 중 가장 현실적인 scene들로 구성되어 있다고 합니다. 1,661개의 독립적인 scene에 대한 캡처로 구성되어 있으며 이미지 해상도는 192×256 입니다. 프레임의 인덱스에 따라 각 scene의 뷰를 균등하게 샘플링하였으며 학습을 위해 샘플링된 뷰의 수는 이미지 기반과 포인트 클라우드 기반으로 나누어 각각 50개, 200개 입니다. 포인트 클라우드를 얻기 위해서 제공된 낮은 resolution의 depth map을 기반으로 3차원 공간으로 역투영하였다고 합니다. 기억해야 할 점은 ARKitScene의 depth map은 저해상도로 제공되는 반면 ScanNetV2의 포인트 클라우드는 고해상도로 3차원으로 reconstruction된 mesh 형태에서 나오기 때문에 포인트 클라우드의 퀄리티가 ScanNet이 더 우수하다는 것 입니다.
ScanNet200
ScanNet200은 ScanNetV2에서 물체 클래스가 200개로 확장된 데이터셋으로 카테고리는 라벨링된 표면 포인트 클라우드의 수에 따라서 66개 / 68개 / 66개의 클래스를 head / common / tail 그룹으로 나눕니다. 보통 작은 물체는 큰 물체보다 표면 포인트 수가 적기 때문에 각 그룹에 속해있는 물체의 평균 크기는 head에서 tail로 갈수록 작아집니다.
실험의 베이스라인은 동일하게 멀티뷰 이미지 기반에서 SOTA 모델인ImVoxelNet으로 선정하였습니다. 또한 대표적인 포인트 클라우드 기반 모델인 VoteNet과도 비교를 진행하였습니다.
4.1. Results
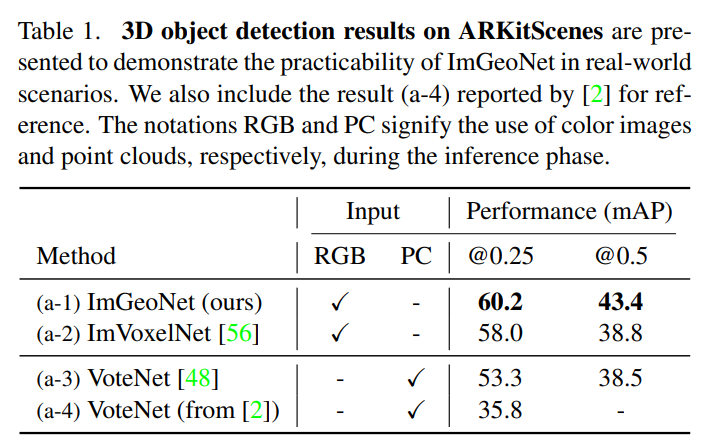
먼저 ARKitScenes에서의 실험 결과 입니다. ImGeoNet이 비교 모델 대비 가장 높은 성능을 보이며 SOTA를 달성하였습니다. ImVoxelNet과의 비교를 통해 기하학 정보를 포함하는 복셀 표현이 모바일 환경이 제공하는 낮은 퀄리티의 depth map에서도 gs 네트워크가 효과적임을 보여주고 있습니다. 또한 VoteNet 대비 이미지 기반의 ImGeoNet과 ImVoxelNet이 더 높은 성능을 보여주면서 3차원 물체 검출에서 이미지 사용에 대한 가능성을 강조하고 있습니다.
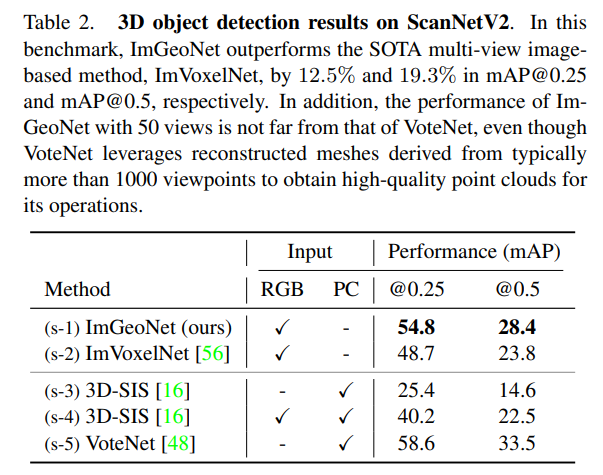
다음은 ScanNetV2에서의 실험으로 마찬가지로 ImGeoNet이 가장 우수한 성능을 달성하였습니다. 포인트 클라우드만을 사용하는 (s-3)보다는 거의 2배 이상의 성능 향상을 보였으며 특히 포인트 클라우드에 이미지 정보를 융합한 (s-4)보다도 높은 성능을 보이고 있습니다. 제가 읽었던 보통의 3D Object Detection 논문은 포인트 클라우드를 단독으로 사용하고 싶지만 scene의 semantic한 정보를 얻기 위해서 RGB 이미지를 보조로 활용하곤 했는데 이렇게 오로지 이미지만을 사용하여 비등한 성능을 보이니 꽤나 인상깊었습니다.
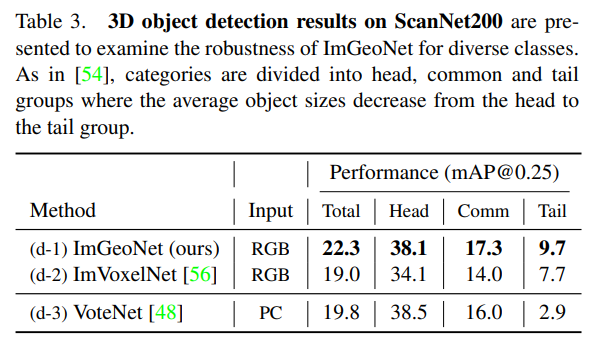
다음은 ScanNet200 실험 결과로 ScanNetV2 대비 클래스 수가 증가한 데이터셋에서의 변화를 보여주고 있습니다. ScanNet200에서 구분한 모든 클래스 그룹에서 ImGeoNet이 ImVoxelNet보다 좋은 성능을 보임으로써 다양한 클래스의 물체가 포함된 scene에 대해서 기하학적인 볼륨 표현이 효과적이라고 저자는 분석하고 있습니다. 특히 포함된 물체의 평균 크기가 더 작은 common부터 tail 클래스 그룹에서 (d-3)보다 (d-1)이 높은 성능을 보이는 것을 꽤나 강조하고 있는데요, 그 이유는 VoteNet이 1000개 이상의 뷰에서 취득한 3D reconstruction 메쉬를 이용하는 반면, ImGeoNet은 50개의 뷰에서 얻은 이미지만을 입력으로 사용한다는 것 입니다. 이러한 결과가 나올 수 있는 이유는 이미지를 기반으로 다양한 크기의 물체가 포함된 데이터셋에 대해 사전학습된 2D backbone을 통해 추출한 시각적 정보를 잘 활용하였기에 보다 작은 물체에 강인하게 반응할 수 있다고 합니다.
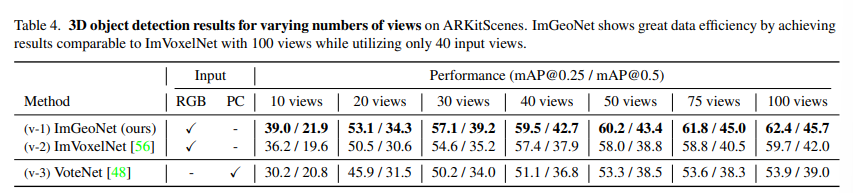
마지막은 ablation study로 먼저 입력으로 들어오는 뷰의 수가 결과에 얼마나 영향을 미치는지에 대한 실험 입니다. 이를 비교하기 위해서 이미지 기반에서는 feature 볼륨을 구성하는 이미지 뷰의 수를, 포인트 클라우드 기반에서는 reconstruction할 때 사용하는 뷰의 수를 조정하였습니다. 100개 뷰를 사용하는 VoteNet보다도 이미지 뷰 30개의 ImGeoNet의 성능이 더 좋네요 . . 또한 40개의 뷰의 ImGeoNet이 100개의 ImVoxelNet과 비슷한 성능을 달성하였습니다. 동일한 멀티뷰 이미지라는 조건 하에서 적은 뷰로도 이러한 결과를 얻을 수 있었던 이유로는 역시 gs 네트워크의 역할이 크다고 분석하면서 리뷰 마치도록 하겠습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
이진 마스크 M_t가 최종 feature 볼륨인 V를 형성할 때 뷰 범위 내에 복셀이 존재하는 여부를 판단하기 위해 사용한다고 말씀하셨는데, 정확히 어떻게 동작하는지 잘 와닿지 않아 ,,, 추가적인 설명 부탁드립니다.
또한 해당 논문의 contribution이 물체의 표면 복셀 / 배경인 free 공간을 나누어 가중치를 주면서 물체 검출 성능을 높이고자 한다고 이해하였는데 제시한것처럼 복셀 내에 포인트가 하나만 존재하더라도 표면 복셀이라고 간주한다면 존재하는 포인트가 표면 복셀인지 free 공간의 포인트인지도 나누지 않고 무조건 표면 복셀의 가중치를 주게 되나요 . . ? 배경 / 표면 복셀을 나누는 기준을 달리하였을 때 성능 변화가 많이 발생할 것이라고 생각하는데 혹시 ablation study가 없었는지 궁금하네요 . . ㅎ ㅅ ㅎ
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
이진 마스크는 각각의 볼륨과 동일한 shape을 가지고 각 복셀 그리드가 카메라 frustum 내에 위치하는지를 판단하여 frustum 내의 위치해 있을 경우에만 볼륨에 대응되는 유효한 feature 값을 채워넣을 수 있습니다.
제가 free 공간이라고 정의한 영역에 대해서 반대되는 용어가 물체 표면이기에 background라고 이해했었는데요, 지금 생각해보니 저자는 아무런 포인트, 특징이 포함되지 않은 영역을 free 공간으로 정의한 것이 아닐까 생각이 듭니다 . . 애초에 어떤 정보도 존재하지 않기에 물체 표면이 될 가능성이 전혀 없는 공간을 의미한다고 생각이 드네요. 그러면 어떤 포인트도 존재하지 않는 free 공간 / 포인트가 얼마나 포함되어 있는지에 따른 차등적인 가중치 부여가 자연스러운 흐름인 것 같습니다. 이런 맥락으로 생각해보면 기준을 달리한 ablation study가 없어도 이해가 가네요 . . ㅎ ㅎ