이번 리뷰 논문은 Open World Object Detection (OWOD or OWD) 태스크에 관한 논문입니다. 처음으로 OWOD 태스크를 정의하고 벤치마크와 해결안을 제시한 논문이기도 합니다. 해당 논문을 읽게 된 계기는 이번 자율 주행을 위한 비전에 관련된 제안서를 작업 중 교수님이 던져 주신 여러 키워드 중 하나이기도 하며, 할당된 ‘지속발전 가능한 인지’에 어떤 기술이 적합한지에 대해서 고민하다가 해당 태스크가 제안서 주제에 대해서 적절하다고 판단하여 선택하게 되었습니다.
Intro
해당 태스크가 왜 자율 주행 분야에 적합하다고 판단한 이유에 대해 설명하려면 기존 가능한 방법들에 대해 살펴보아야 합니다. 자율 주행이 level 4,5로 올라가기 위해서는 희소하게 등장하는 케이스에서 안정적으로 동작해야 하기에 인지 관점에서는 open world의 물체들을 인식하여 회피하거나 상호작용이 가능해야 합니다. 그러기 위해서는 open world를 포괄 가능한 데이터 셋을 만드는 것이 가장 베스트이지만 이는 현실적으로 불가능합니다. 차선책으로 지속적인 데이터 셋 업데이트와 이에 따른 모델 재학습을 수행하는 방법이 있습니다. 하지만 해당 방법도 어플리케이션 관점에서 비효율적이며, 업데이트 된 데이터 셋에 예외적인 케이스가 있어야 한다는 점에서 여전히 한계를 보인다고 볼 수 있습니다.
OWOD는 위와 같은 문제들을 해결하기 위해 제안된 태스크로 간략하게 설명하자면 close set으로 학습된 검출기를 ‘unknown’이라는 클래스를 예측하고 해당하는 물체를 기억하고 점진적으로 확장 가능한 검출기를 목적으로 하는 태스크에 해당합니다.
여기서 핵심은 close set에 ‘unknown’이라는 클래스를 추가하여 open world로 가까워지고 추가적인 ‘unknown’ 클래스를 추가하여 새로 재학습하는 것이 아닌 기존 검출기를 점진적으로 확장하는 것(Incremental Object Detection)이라고 볼 수 있습니다.
+ 한 사이클이 끝나면 ‘unknown’ 중 인식된 객체들만 oracle (수동 작업)을 수행하여 세부 클래스를 부여합니다.
+ 그 후, knowledge distillation (KD)나 continuous learning (CL), exemplar replay (ER) 등을 이용하여 이전 지식을 계승 받으면서 새로운 세부 클래스를 학습합니다.
+ 본 논문에서 밝히기로는 exemplar replay (ER)이 가장 좋은 성능을 보이다고 합니다. ER은 few-shot learning과 유사하다고 보시면 됩니다.
즉, 자율 주행 중 등장 가능한 예외적인 물체들을 검출기가 인식하고 예외적인 물체에 대해서 확장 가능한 검출기로 위에서 언급한 문제점들을 해결하는 방법론에 해당한다고 볼 수 있습니다.
말이 길었는데 간단하게 저자가 언급한 contribution에 대해서 정리하고 method로 넘어가도록 하겠습니다. contribution은 다음과 같습니다.
- 현실 세계를 더 가깝게 모델링하는 새로운 문제 설정인 Open World Object Detection을 소개
- OWD의 어려움을 해결하기 위해 contrastive clustering, unknown-aware proposal network, energy based unknown identification을 기반으로 하는 새로운 방법론인 ORE를 개발
- Object detection의 open world characteristics을 측정하는 데 도움이 되는 포괄적인 experimental setting을 소개하고, baseline methods과 비교하여 ORE를 벤치마킹
- 제안된 방법론은 Incremental Object Detection를 위해 설계된 것은 아니지만 Incremental Object Detection 태스크에서도 SOTA를 달성
Method
ORE에 대한 구체적인 방법을 언급하기 앞서서 OWD의 전반적인 파이프라인을 설명하고 ORE의 모듈인 contrastive clustering, unknown-aware proposal network, energy based unknown identification에 대해서 설명하도록 하겠습니다.
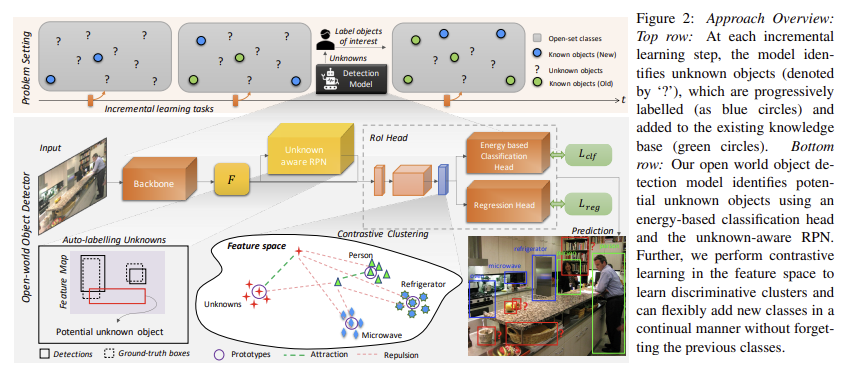
Open World Object Detection 과정
- 먼저, known class 집합 K = {1, 2, …, C}이 있고 이를 예측 가능한 검출기 M^c가 있다고 가정
- 또한 해당 모델은 unknown class 집합 U = {C+1, …}을 ‘unknown’ 클래스에 해당하는 라벨 0으로 예측 가능하다고 가정
- U가 예측되면 unknown class ‘unknown’을 탐지하면 ‘unknown’에 대해 분류 가능한 human user (=oracle)가 ‘{new class}’로 분류를 진행하고
- 모델은 다시 학습하지 않고 예측한 ‘unknown’ 을 ‘{new class}’로 새로운 지식을 적응적으로 업데이트를 수행
- 3-4 과정을 반복하며 지식을 늘림
전반적인 파이프라인은 fig 2의 상단에서도 확인 가능합니다.
Contrastive Clustering
저자는 해당 문제를 해결하기 위해 검출기의 latent space에서 클래스 간 명확한 구분을 학습하면 두 가지 효과를 얻을 수 있다는 가설을 세웁니다. 먼저, 이를 사용하면 모델이 unknown instance의 특징 표현이 known instance와 “어떻게 다른지” 식별하여 unknown instance를 novel instance로 식별하는 데 도움이 됩니다. 두번째로 latent space에서 이전 클래스와 겹치지 않고 new class instances에 대한 특징 표현을 학습할 수 있어 잊어버리지 않고(without forgetting) 점진적으로 학습(incrementally learning)하는 데 도움이 됩니다. 해당 가설을 대응하는 모듈이 contrastive clustering에 해당합니다.
contrastive clustering의 핵심 컨셉은 클래스 간 간격을 최대화하는 contrastive clustering problem으로 OWOD를 해석하는 것입니다. 실제로 구현한 방법은 매우 심플합니다. 클래스 C에 대한 중간 feature f_c 와 known class i에 대응되는 prototype p_i 가 있을 때 이에 대응되는 contrastive loss는 다음과 같이 정의 됩니다.
+ 중간 feature f_c 는 RPN을 통해 RoI pooling 나온 feature에 해당합니다.
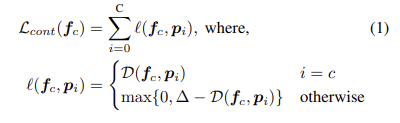
여기서 D는 distance function으로 cos-sim을 사용했다고 합니다. \delta 는 밀어내는 정도에 대한 하이퍼 파라미터로 저자는 10을 사용했다고 합니다.
해당 모듈에서 핵심적인 부분은 prototype vector P = \{ p_0 ··· p_C \} 로 각 클래스 별 특징들을 대표하는 값들로 아래의 Alg 1과 같은 방법으로 점진적으로 클래스 별로 수집된 값들의 클래스 별 특징들의 평균 값으로 구성됩니다.

특정 burn-in iteration I_b 마다 fixed-length queue q_i, F_{store} = \{ q_0, ..., q_C}에 저장되어져 특정 iteration I_p 마다 신규 클래스 정보들을 업데이트하고, Alg 1-9의 모멘텀 n으로 업데이트를 수행합니다. 저자는 queue의 크기는 20, I_b = 1k, I_p = 3k, 모멘텀=0.99로 설정했다고 합니다.
Auto-labelling Unknowns with RPN
contrastive clustering을 통해 latent space에서 클래스 간 명확한 구분이 가능하도록 하였으나, unknown class를 구분하려면 해당 클래스에 대한 정보가 있어야 합니다. 단순한 접근으로는 unknown instance를 ‘unknown’로 라벨링을 진행하면 되나, 무한한 정보들을 라벨링하는 것은 불가능에 가깝습니다.
저자는 이를 해결하기 위해서 pseudo-label unknown instances하기 위한 RPN 기반 auto-labeling mechanism인 Unknown-aware proposal network을 제안합니다.
해당 모듈에서는 RPN은 class agnostic하다고 가정합니다. 클래스에 상관 없이 물체와 같은 현상을 보이는 경우를 박스를 치는 RPN의 특성을 이용하여 background 중 높은 objectness scores를 가지지만 GT와 겹치는 부분이 없는 물체를 ‘unkown’이라고 라벨링합니다. 간단히 말해, objectness scores에 따라 정렬된 top-k개의 background region proposals을 unknown objects로 선택합니다.
+ 저자는 k=1로 설정
Energy Based Unknown Identifier
위의 모듈을 통해 latent space에서 auto-labelled unknown instances된 정보들은 known과 unknown instances를 수치적으로 판별이 이뤄져야 합니다. energy based classification head에서는 known과 unknown instances를 명시적인 구분하는 방법을 제안합니다.
Energy Based Unknown Identifier은 latent feature space F와 이에 대응되는 labels l \in L을 기반하는 energy function E(F, L)을 학습하는 것이 목표 합니다. energy function은 Helmholtz free energy을 기반으로 하며 수식으로 정의하면 다음과 같습니다.
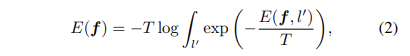
T는 Temperature parameter이며, 위 수식을 검출기와 soft-max layer로 풀어내면 다음과 같습니다.
(이전 연구에서 밝힌 관계입니다.)
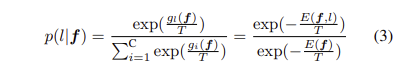
g()는 classification head. logits측면에서 분류 모델의 free energy를 다음과 같이 정의합니다.
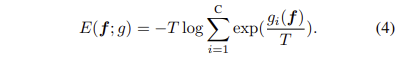
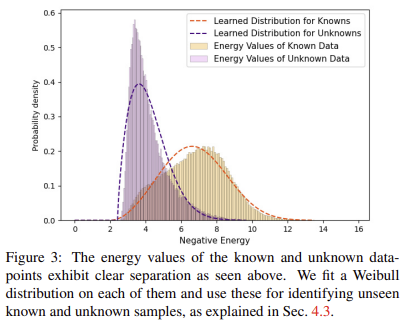
위 energy function을 이용하여 contrastive clustering를 통해 분리된 클래스를 스칼라 형태로 명확하게 구분 가능해집니다.
+ energy function은 F과 L 사이의 공간을 따라갈 수 있도록 학습하여 f와 l이 얼마나 유사함을 나타내는 것으로 이해하셔도 무방. 효과는 fig 3에서도 확인 가능
Alleviating Forgetting
해당 모델은 미지의 클래스를 인식하고 새로운 클래스로 학습하는 것이 주된 목표로 합니다. 허나, 처음부터 재학습을 진행하는 것은 실현 가능한 솔루션이 아닐 뿐더러, 해당 단계에서는 해당하는 training data가 존재하지 않습니다. 만약에 재학습이 가능하더라도 이는 기존 클래스에 대한 catastrophic forgetting를 발생시킬 수 있습니다. 저자는 catastrophic forgetting를 완화하기 위해 incremental learning에서 높은 성능을 보인 example replay를 적용클래스 측면에서 균형적인 샘플 셋을 저장해두고 각 incremental step이 끝난 후, finetunning을 진행합니다. 여기서 저자는 N_{ex} = 50장 씩 클래스 별 균형을 맞춰 샘플 셋을 구축하여 사용했다고 합니다.
Experiments
Open World Evaluation Protocol
- Data split: group classes into a set of tasks T = {T1, · · · Tt, · · · }. 각 태스크는 time t에 투입
- all the classes of {T_{\tau} : \tau <t} will be treated as known and {T_{\tau} : \tau >t} would be treated as unknown.
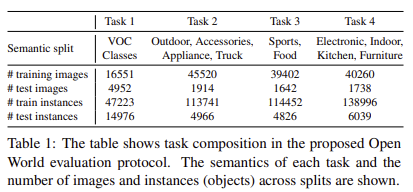
- Pascal VOC, MS-COCO 사용
- Task 1: VOC 모든 클래스
- 이외의 task는 MS-COCO의 클래스 60개를 의미론적으로 구분하여 20개 씩 나눔
- 주어진 val split, test split를 이용하여 평가 진행함
- 구체적인 구성은 Tab 1을 확인
+ 최근 방법론들은 해당 구성이 아닌 다른 구성을 사용함. 태스크 별 불균형적인 구성이 태스크 평 공평한 비교가 어려워서 그렇다고 하는데 기회가 되면 다루겠습니다.
Evaluation metrics
- Wilderness Impact (WI) metric
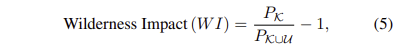
P_k는 알려진 클래스의 precision, P_{k \union U}는 알려지지 않은 클래스에 대한 precision에 해당합니다. 모든 실험은 Recall 0.8을 기준으로 진행합니다.
- Open-Set Error (A-OSE)
- 잘못 분류된 알려지지 않은 클래스의 객체 수
- mAP for incremental object detection
- new class에 대한 incremental object detection 성능을 평가하기 위해 mIoU 0.5를 기준으로 mAP를 측정
Implementation Details
- ResNet50→Faster R-CNN을 기반
- classification head는 incremental classification methods를 따름
- unseen classes to a large negative value
- hus making their contribution to softmax negligible (ev → 0)
- T_i에 대해 학습하는 동안에는 일부 클래스에만 라벨이 지정됨. 테스트 중에는 이전에 클래스를 제외하고 이후 태스크에서도 ‘unknown’이라는 라벨로 평가를 진행
- exemplar replay을 위해 N_{ex} = 50으로 지정 (경험적으로 지정)
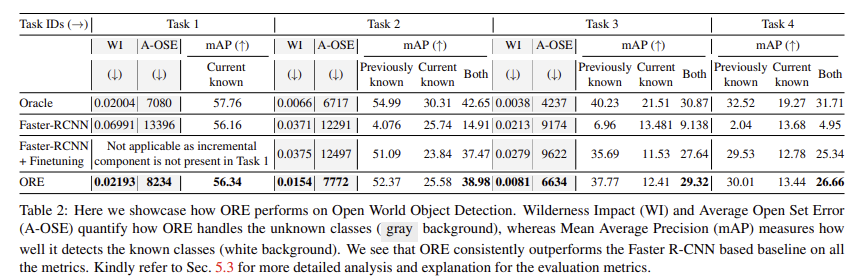
OWOD에서의 정량 평가
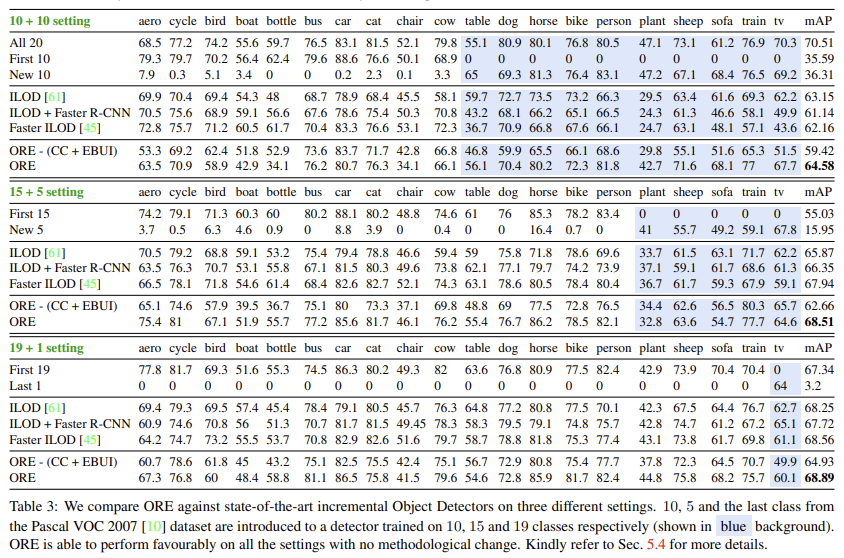
Incremental object detection에서의 정량 평가
Ablation study
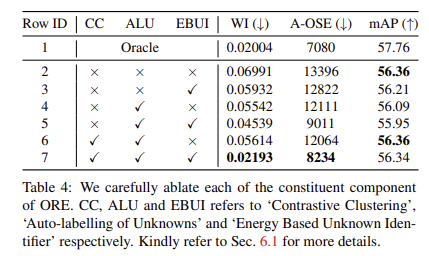
여기서 tab 4의 oracle은 unknown에 대해 GT를 부여하는 방식으로 upper로 보시면 됩니다.
Example replay에 사용되는 데이터 갯수에 따른 영향력 분석
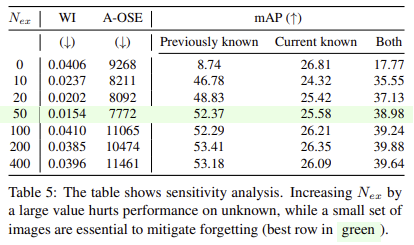
50개가 가장 적절하며, 더 적게 사용하는 경우에는 이전 지식들을 망각하는 문제가 발생함. 너무 많이 사용하는 경우에는 WI, A-OSE가 하락하는 것을 통해 unknow에 대한 영향력이 줄어드는 것을 볼 수 있음
OWOD 최근 기법들을 살펴보니 CLIP을 활용하는 방향으로 흘러가고 있으며, 더 나아가 LLM을 통해 주어진 클래스에 대한 attribute를 GPT와 같은 LLM을 통해 text로 추론시켜 이를 open vocabulary detection으로 풀어간 연구도 존재하며 이전 대비 높은 성능 향상을 보여주고 있습니다. 이러한 연구 동향에 따라 추후 연구들은 OVD와 OWOD가 결합된 방향으로 흘러 갈 것 같습니다. 저도… 그쪽으로 구상해야… 하나… 고민이네요…
안녕하세요 ! 좋은 리뷰 감사합니다.
예측한 unknown 물체는 다시 학습하지 않고 new class로 정의되어 업데이트가 수행된다고 하셨는데 그럼 다음 예측부터는 new class가 known class 집합인 K에 포함되어 진행되는건간요 ?? 그렇다면 known class로 K에 포함이 되더라도 GT가 없으니 다음 예측의 auto labelling knowns에서도 백그라운드 중에서 GT와 겹치지 않는 경우에 unknown으로 동일한 class가 선택될 수도 있다고 생각하는데 .. 이런 경우는 처리가 어떻게 되는건지 궁금합니다. Energy Based Unkown Identifie가 이러한 역할을 해주는 것 같은데 . . 명확하게 이해를 하지 못하여 질문 드립니다 ㅎ ㅎ ..
Q. 예측한 unknown 물체는 다시 학습하지 않고 new class로 정의되어 업데이트가 수행된다고 하셨는데 그럼 다음 예측부터는 new class가 known class 집합인 K에 포함되어 진행되는건간요??
A. 넵 맞습니다.
Q. 그렇다면 known class로 K에 포함이 되더라도 GT가 없으니 다음 예측의 auto labelling knowns에서도 백그라운드 중에서 GT와 겹치지 않는 경우에 unknown으로 동일한 class가 선택될 수도 있다고 생각하는데 .. 이런 경우는 처리가 어떻게 되는건지 궁금합니다. Energy Based Unkown Identifie가 이러한 역할을 해주는 것 같은데 . . 명확하게 이해를 하지 못하여 질문 드립니다 ㅎ ㅎ ..
A1. auto labelling은 작업자가 수동으로 라벨링을 수행하는 과정이라고 보시면 됩니다. 해당 과정에서 오탐지된 unknown도 처리되겠죠.
A2. Energy Based Unkown Identifie는 검출기의 classifier가 unknown에 대해 학습이 어렵기 때문에 proposal로부터 known, unknown, BG를 구분하기 위한 툴이라고 보시면 됩니다.