안녕하세요, 스물두 번째 X-Review입니다. 이번 논문은 2020년도 CVPR에게재된 AANet: Adaptive Aggregation Network for Efficient Stereo Matching 논문입니다. 그럼 바로 리뷰 시작하겠습니다 !
1. Introduction
전통적인 stereo matching 알고리즘은 일반적으로 다음의 4가지 단계의 파이프라인을 따릅니다.
- matching cost computation
- cost aggregation
- disparity computation
- disparity refinement
matching cost를 계산한다는 것은 stereo 이미지가 있을 때 두 이미지들 간의 유사도를 pixel level로 측정하는 것을 의미하며, 이렇게 계산한 matching cost를 쌓으면 H x W x D(disparity) 크기의 cost volume이 생성됩니다. 이 cost volume을 가지고 좀 더 신뢰도 있는 cost를 계산해 내기 위한 과정이 cost aggregation 과정이며, 이렇게 aggregation한 cost를 바탕으로 disparity를 계산하고 정제하는 과정이 일련의 과정입니다.
이런 전통적인 방식의 stereo matcing알고리즘은 크게 global 방법론과 local 방법론으로 나눠볼 수 있습니다. global 방법론은 보통 cost data 부분과 주위 픽셀들간의 disparity 차이가 급격하게 차이나는 것을 막기 위한 smoothness 부분과 관련된 목적 함수를 설계하고, 이 목적 함수를 최소화하도록 하는 최적화 문제를 푸는 것으로 생각해볼 수 있습니다. 목적 함수는 아래와 같겠습니다.
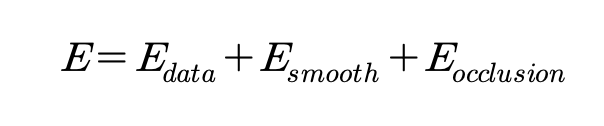
이 global 방법론 같은 경우 이미지 내의 모든 픽셀을 이용해 최적화하기 때문에 계산량이 많다는 단점이 있습니다. 반면, local 방법론같은 한 픽셀의 disparity를 계산할 때 오직 그 주위 이웃 픽셀의 정보만 이용한다는 점에서 global method보다 훨씬 빠르죠. 지금도 여전히 이런 전통적인 방식의 과정을 따르고 있지만, 이 전통적인 방법론은 여전히 텍스처가 없는 영역이나, 반복적인 패턴이 있는 영역, 얇은 물체 부분에서 어려움을 겪고 있습니다.
DNN을 도입하자, 더 좋은 표현력을 학습할 수 있었고 이는 앞에서 언급한 어려움을 겪는 상황들에서 좋은 결과를 얻는 결과를 이끌어 내었습니다. DispNetC는 dispairty estimation task에서 처음 등장한 end-to-end 학습 가능한 프레임워크이며, 이어서 나온 GC-Net 같은 경우는 왼쪽 이미지의 feature와 오른쪽 이미지의 feature를 concat함으로써 4D cost volume을 생성해 내었으며 이로 인해 3D convolution이 4D cost volume을 aggregate하는데 사용되어야 했습니다. 이후 등장한 PSMNet은 cost aggregation 과정에서 3D convolution을 더 많이 사용함으로써 GC-Net보다 더 좋은 성능을 보였습니다.
하지만, 3D convolution을 많이 사용함으로써 SOTA의 성능을 이끌어 냈지만, 이 3D conv는 계산량이 높으며, 메모리도 많이 소비됩니다. 지지난 주 리뷰했던 GA-Net같은 경우도 이런 3D convolution의 단점을 언급하며 2개의 guided aggregation layer라는 것을 제안하며 3D conv를 대체해 사용하겠다 라고 밝혔지만, 여전히 GA-Net 모델 안에는 15개의 3D convolution이 사용됩니다.
저자는 이 시점에서 이런 물음을 던집니다.
How to achieve state-of-the-art results without any 3D convolutions while being significantly faster?
본 논문에서 저자는, cost aggregation 과정에 사용되는 2가지의 효과적이고 효율적인 모듈을 설계합니다. 먼저 첫번째로 intra-scale cost aggregation을 위한 sparse point 기반 representation을 제안합니다.

Fig 1을 보면, 기존 regular convolution을 사용했을 때와, 저자가 제안한 sampling location 방식을 비교해볼 수 있습니다. (a)의 원본 이미지에서 노란색, 빨간 색 점이 aggregation한 point의 location이라고 해본다면 우리가 아는 convolution을 해당 location에 적용한다면 (b)와 같이 고정된 location이 sampling되겠죠. 이에 반하여 저자는 (c)와 같이 adaptive하게 location을 sampling하는 방식을 제안한 것입니다. 이렇게 adaptive하게 point를 sampoing한 이유는 비슷한 disparity를 갖는 영역을 sampling하고자 한 것으로 disparity 불연속으로 인해 발생하는 edge-fattening 문제를 완화할 수 있는 효과를 갖는다고 합니다.
endge-fattening 문제란, 아래 그림에서 보이는 것과 같이 disparity를 추정할 때 물체의 edge 부분이 뚱뚱하게 나오는 문제를 뜻합니다.

추가적으로 저자는 content-adaptive weight를 학습하도록 하여 cost aggregation 과정에서 position-specific weighting을 도입하였습니다. 이는 일반적인 convolution이 커널이 가진 파라미터를 이미지의 모든 영역에서 공유한다는 단점을 극복하는데 목적을 둔 것입니다. 저자는 이런 아이디어를 deformable convolution을 이용해 구현하였습니다.
또한 저자는 cross-scale cost aggregation이라는 전통적인 cost aggregation 알고리즘을 뉴럴 네트워크 레이어를 사용해 근사화하였습니다. 이건 multi-scale의 cost volume을 병렬적으로 구축하고 adaptive하게 크기가 다른 cost volume끼리 상호작용 하도록 한 것입니다. 이로써 텍스처가 없는 영역이나, 적은 지역에서 정확한 disparity를 예측할 수 있게 되었습니다.
결과적으로 두 가지의 모듈을 제안함으로써 cost aggregation을 효율적으로 할 수 있게 되었으며, PSMNet보다 4배, GA-Net보다 38배 빠른 속도로 동작하는 모델을 제안합니다.
2. Method
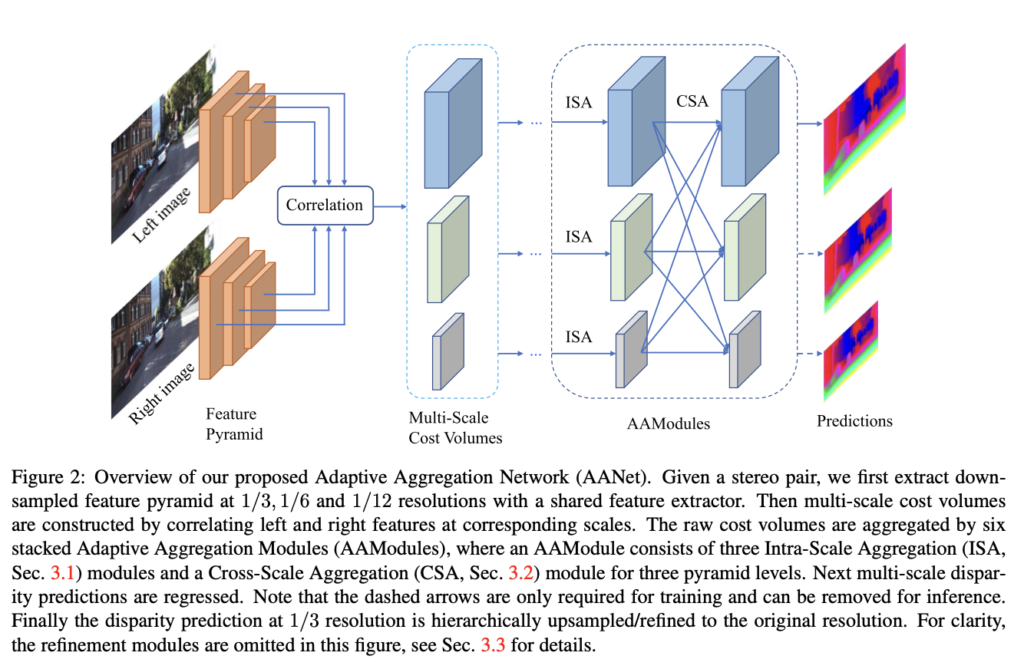
아키텍처 구조는 위 FIg2에서 살펴볼 수 있습니다.
Rectification 된 이미지 쌍 I_l와 I_r가 주어질 때 먼저 두 이미지는 공유된 feature extractor를 통과하여 downsample 된 feature pyramid \left\{ F^s_l \right\}^S_{s=1}와 \left\{ F^s_r \right\}^S_{s=1}를 추출해냅니다. 여기서 S는 scale의 수이며, s는 각 scale 인덱스입니다. s=1인 경우가 가장 큰 scale을 나타냅니다.
그 다음 크기가 같은 좌 우 이미지 feature들 간의 상관관계를 고려하여 multi-scale의 3D cost volume \left\{ C^s \right\}^S_{s=1}를 생성해 냅니다. 아래 식2에 이 과정이 적혀 있습니다.
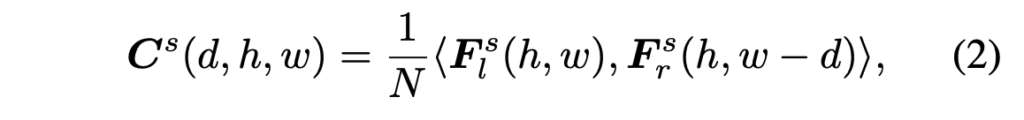
- <.,.> : 두 feature vector간의 내적
- N : 추출된 feature의 채널 수
- C^s(d, h, w) : disparity d에 대해 (h, w) 위치에서의 matching cost
이후 이렇게 생성된 Cost volume은 몇개의 Adaptive Aggregation 모듈(AAModules)을 통과하면서 aggregation 과정을 거칩니다. 이 AAModule은 intro에서 짧게 언급했던 adaptive Intra-Scale Aggregation(ISA) 모듈과 adaptive Cross-Scale Aggregation(CSA) 모듈로 구성됩니다. 마지막으로 예측된 낮은 해상도의 disparity map은 계층적으로 upsample되면서 원본 해상도를 갖게 됩니다.
이제 AAModule을 구성하고 있는 ISA 모듈과 CAS 모듈에 대해 살펴보도록 하겠습니다.
2.1. Adaptive Intra-Scale Aggregation
ISA 모듈은 edge와 같이 disparity 불연속 상황에서 edge-fattening 문제를 완화하기 위한 목적으로 설계되었습니다. 저자는 flexible하고 효과적으로 cost를 aggregation하기 위해 sparse한 point 기반의 표현을 제안하였습니다. 이를 구현하는데 deformable conv를 사용하였죠.
특정 scale에 대해 D x H x W 크기를 갖는 cost volume C에 대한 cost aggregation 전략은 아래 식3과 같이 정의됩니다.
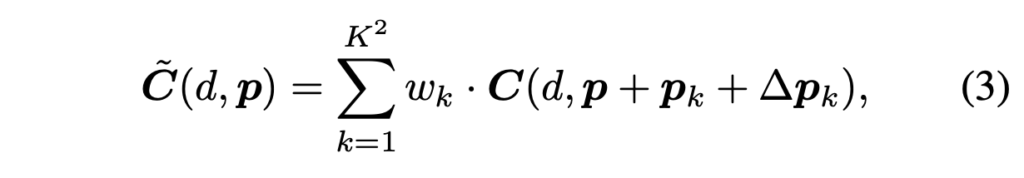
- \tilde{C}(d, P) : disparity d에 대해 pixel p위치에서 cost aggregation 결과
- K^2 : sampling된 point 수
- w_k : k번째 point에 대한 aggregation weight
- p_k : window 기반 cost aggregation에서의 픽셀 p에 대한 fixed offset
이전 stereo 연구와의 차이점은 sampling 위치 p + p_k에 대한 추가적인 offset Δp_k를 학습한다는 것입니다. 이로써 adaptive한 sampling이 가능해지면서 물체의 경계선이나, 얇은 구조체에 대해 좋은 결과를 얻을 수 있게 됩니다.
하지만,,, context를 학습하는 과정에서 일반적인 convolution weights \left\{ w_k \right\}^{K^2}_{k=1}는 spatial sharing 특성을 갖고 있기 때문에 content-agnostic하게 만듭니다. 이는 일반적인 convolution이 전체 영상에 대해 같은 filter를 사용하기 때문에 하나의 kernel weight가 optimal solution이 될 수 없다는 것을 의미합니다. 그래서 저자는 추가로 position-specific weights \left\{ m_k \right\}^{K^2}_{k=1}
를 학습하도록 하여 content-adaptive cost aggregation을 수행하도록 하였습니다. 해당 식은 아래 식4와 같습니다.
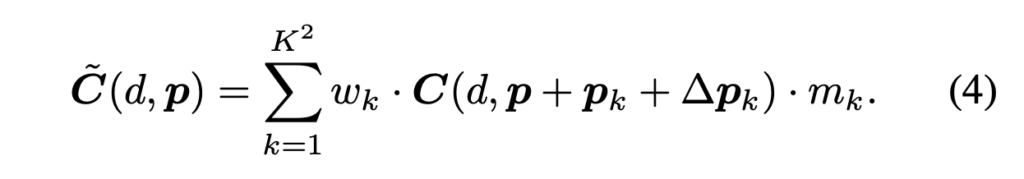
저자는 deformable convolution으로 위 식을 구현했는데, deformable conv에서는 Δp_k와 weights m_k가 같은 채널에 있을 것을 가정합니다. 본 논문에 경우에서는 같은 채널이라 함은 같은 dispairty d가 되겠죠.
저자는 이 Intra-Scale Aggregation(ISA) 모듈을 3개의 layer(1×1, 3×3, 1×1)와 resnet의 residual connection을 쌓아서 구성했습니다. 이때 3×3 conv가 deformable conv에 해당합니다. 이 구조는 resnet의 bottleneck과 유사해보이지만, 계속 같은 채널을 유지한다는 점에서 차이점이 있습니다. 이는 채널이 dispairty 후보에 해당하는 것이기 때문에 수를 유지하는 것입니다.
2.2. Adaptive Cross-Scale Aggregation
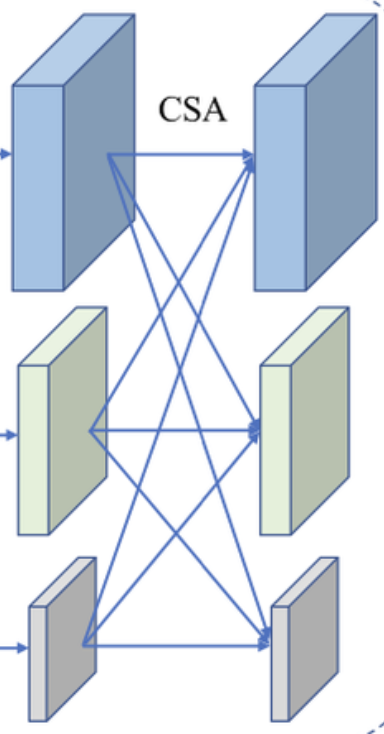
이제 CSA 모듈에 대해 살펴보도록 하겠습니다. Texture가 없거나 적은 영역에서는 coarse scale에서 상관관계를 찾는 것이 더 결과가 좋습니다. 이는, 같은 크기의 patch를 사용한다면 이미지가 downsample되어 있을 때가 더 texture 정보를 잘 식별할 수 있기 때문입니다. 그러므로 전통적인 cross-scale cost aggregation 알고리즘에서 multi-scale interaction이 제안된 것입니다. 이 알고리즘에서 최종 cost volume은 서로 다른 크기에서 수행된 cost aggregation 결과를 adative하게 결합함으로써 생성됩니다. 저자는 이를 식5를 통해 근사화하도록 하였습니다.
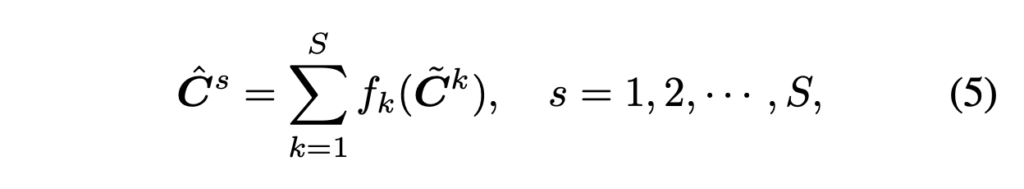
- \hat{C}^s : cross-sclae cost aggregation을 마친 cost volume 결과
- \tilde{C}^k : intra-scale aggregation을 마친 scale k에 대한 cost volume 결과
f_k는 서로 크기가 다른 cost volume을 adaptive하게 combination하기 위해 사용되는 함수로 아래 식 6에서 확인할 수 있습니다.
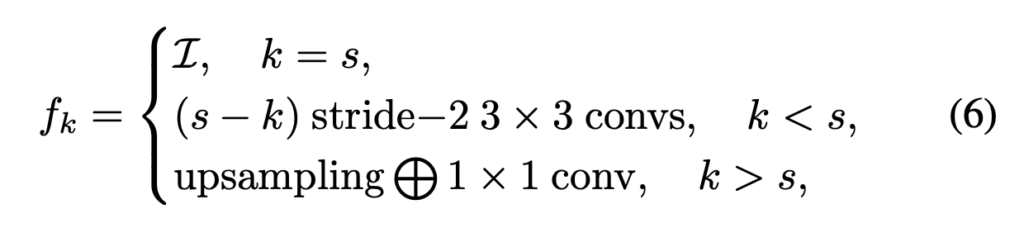
이 함수의 정의는 HRNet으로부터 채택된 것으로 각 scale k, s가 같다면 identity 함수가 되며, k가 s보다 작은 경우에는 k의 scale이 더 큰것을 의미하기 때문에(s=1이 가장 큰 크기이기 때문) conv를 통해 downsampling 해줍니다. 마지막으로 k가 s보다 큰 경우에는 upsampling하여 해상도를 맞추고 1×1 conv를 통해 채널 수를 맞추는 것을 확인할 수 있습니다.
2.3. Adaptive Aggregation Network
제안된 ISA, CSA 모듈을 합쳐 AAModule을 완성하였으며 이 AAModule을 6번 stack해 cost aggregation 과정에 사용하였습니다.
2.4. Disparity Regression
각 픽셀에 대해 soft argmin 방식을 도입하여 disparity를 예측하도록 하였습니다.
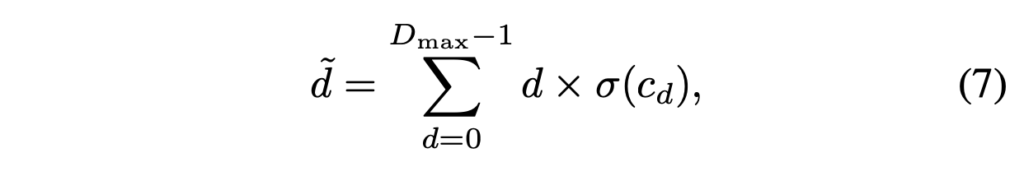
- D_{max} : maximum disparity range
- σ : softmax 함수
- c_d : disparity 후보 d에 대해 aggregated된 matching cost 결과
σ(c_d)는 disparity가 d일 확률이 되겠습니다.
2.5. Loss Function
제안된 AANet같은 경우 gt disparity를 가지고 end-to-end로 지도학습됩니다. 하지만, KITTI 데이터셋은 매우 sparse한 gt disparity를 갖고 있기 때문에 AANet의 학습에는 효과적이지 않았다고 합니다. 그래서 저자는 knowledge distillation에서 영감을 받아서 사전학습된 스테레오 모델이 예측한 disparity를 pseudo gt로 사용하였습니다. 이 때 사전학습 모델로는 GA-Net을 사용하였다고 합니다.
i = 1, 2, … N(각 scale)에 대한 Disparity 예측 D^i_{pred}은 가장 먼저 원본 입력 이미지 해상도로 bilinearly upsampling됩니다. 각 scale에 대한 loss함수는 아래와 같습니다.
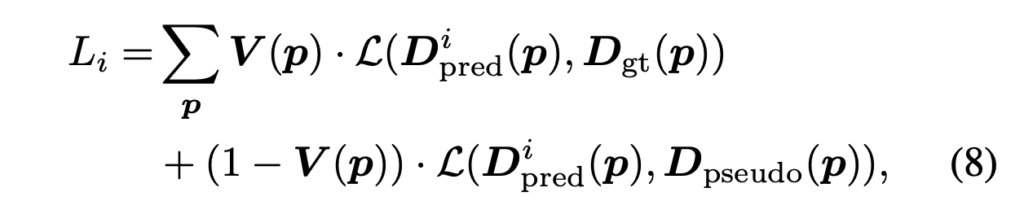
- V(p) : pixel p에 대한 gt disparity가 있는지 여부에 대한 이진 마스크
- L : smooth L1 loss
- D_{gt} : gt disparity
- D_{pseudo} : pseudo gt disparity
단순하게 pixel p에 대해 gt가 있는 경우에는 gt disparity와 예측한 disparity간의 smooth l1 loss, gt가 없는 경우에는 사전학습 된 GA-Net의 예측 결과를 pseudo gt로 사용하여 이 pseudo gt와 예측한 disparity간의 smooth l1 loss로 계산된다고 보면 되겠습니다.
마지막 loss함수는 모든 scale의 disparity 예측에 대한 loss를 가중합함으로써 계산됩니다.
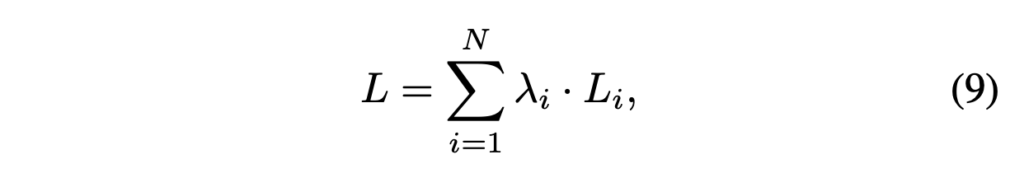
3. Experiments
본 논문에서는 Scene Flow, KITTI 2012, KITTI 2015 데이터셋에 대해 실험을 진행하였습니다. Scene Flow 데이터셋에 대해서는 EPE(end-point error)와 1-pixel error 평가 지표를 사용하였습니다. EPE는 픽셀 단위로 disparity error를 측정한 것을 의미하며, 1-pixel error은 EPE가 1pixel보다 큰 경우의 평균 비율입니다. 둘 다 낮을수록 좋은 성능입니다.
Ablation Study
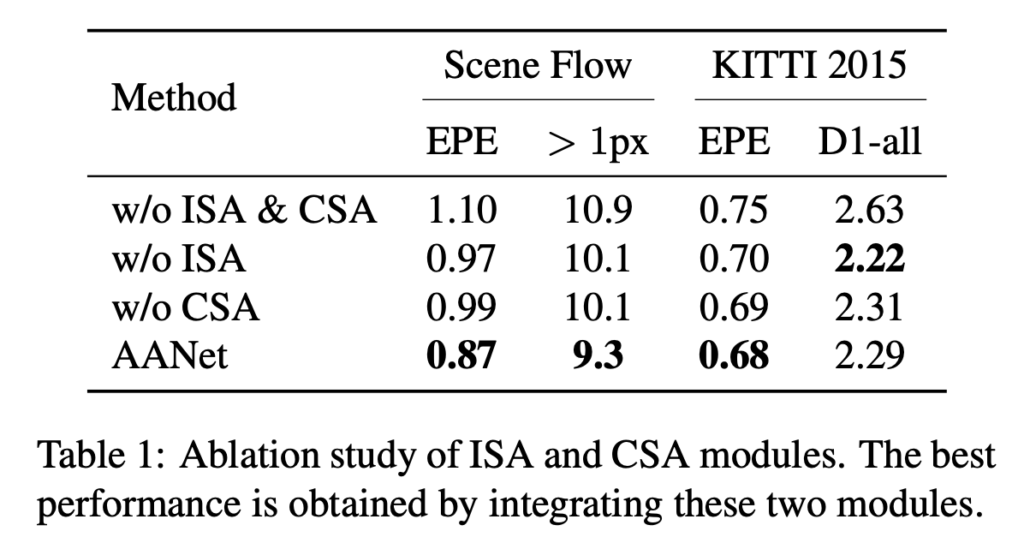
표 1은 ablation study 결과입니다. 저자는 제안된 ISA, CSA모듈을 제거할 경우 성능이 많이 떨어진다고 하며, 이 두 모듈이 상호 보완적으로 설계되었기 때문에 같이 사용했을 때 가장 높은 성능을 얻을 수 있다고 하며,, CSA 모듈만 적용했을 경우에 KITTI 2015 데이터셋에서 더 높은 성능이 나온 점에는 별 다른 언급을 하지 않고 있습니다… ㅋㅅㅋ

FIg3은 scene flow set에 대한 ablation study를 시각화한 결과입니다. 조금 안보이긴 하지만, 점선으로 된 texture가 없는 challenge한 영역을 보면, ISA, CSA 모듈을 적용하지 않은 baselin에 비해 AANet이 disparity를 더 잘 예측하고 있음을 보입니다.
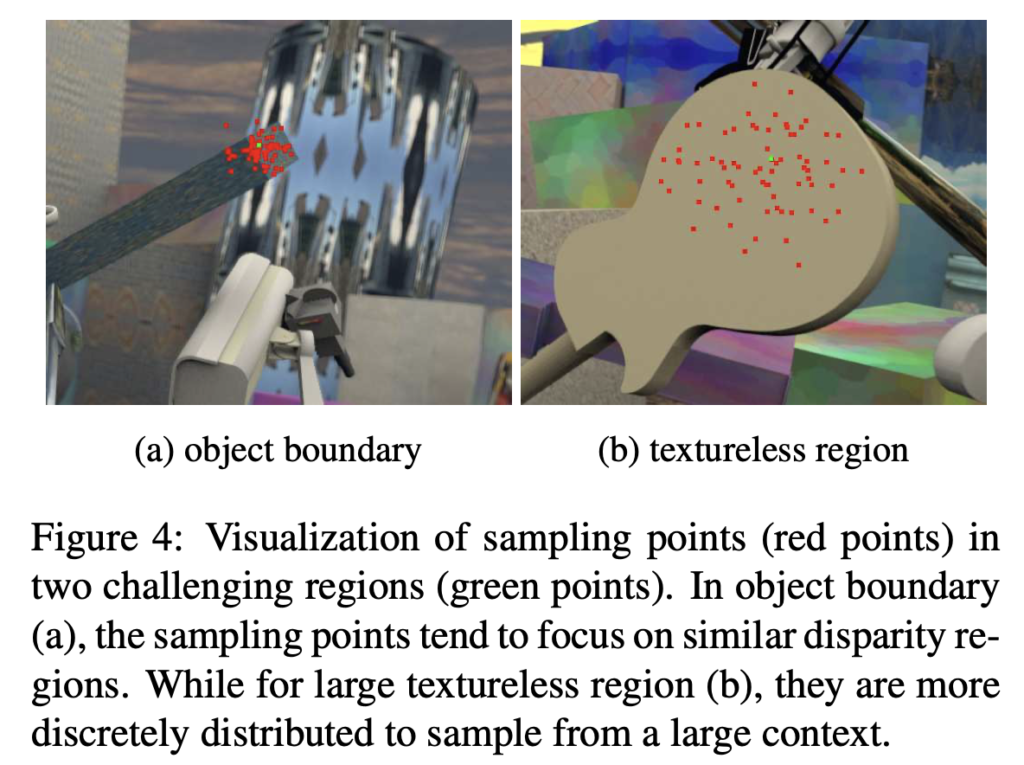
Fig4는 ISA 모듈을 통해 sampling한 포인트를 시각화한 결과입니다. (a)는 물체의 경계선, (b)는 texture가 없는 두 챌린징한 영역에 대한 결과로 point가 비슷한 disparity를 갖는 영역에 잘 sampling된 것을 확인할 수 있습니다.
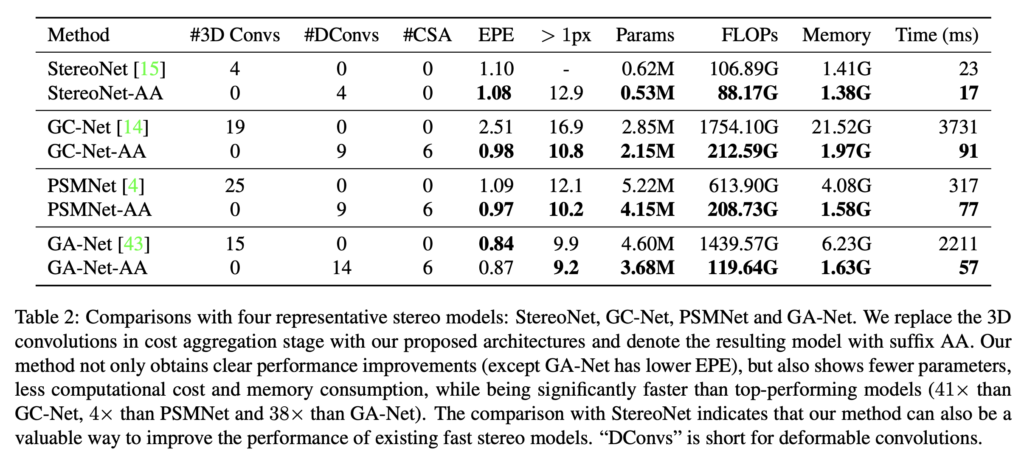
Table2는 네 개의 타 stereo 모델간의 비교를 보여줍니다. 저자의 목적이 3D convolution을 사용하지 않도록 하여 계산량이 적고 빠르게 동작하는 모델을 만들고자 한 것을 상기해보며 결과를 본다면, AA 모듈을 적용하였을 때가 더 적은 파라미터 수, 더 적은 계산 비용을 갖는다는 볼 수 있습니다. 또한, GC-Net에 비해 41배 빠르며, PSMNet보다 4배, GA-Net보다 38배 빠르게 동작하네요. 물론 기존 GA-Net이 AAModule을 적용했을 때보다 EPE가 더 낮긴 하지만, 일반적으로 더 좋은 성능을 보입니다.
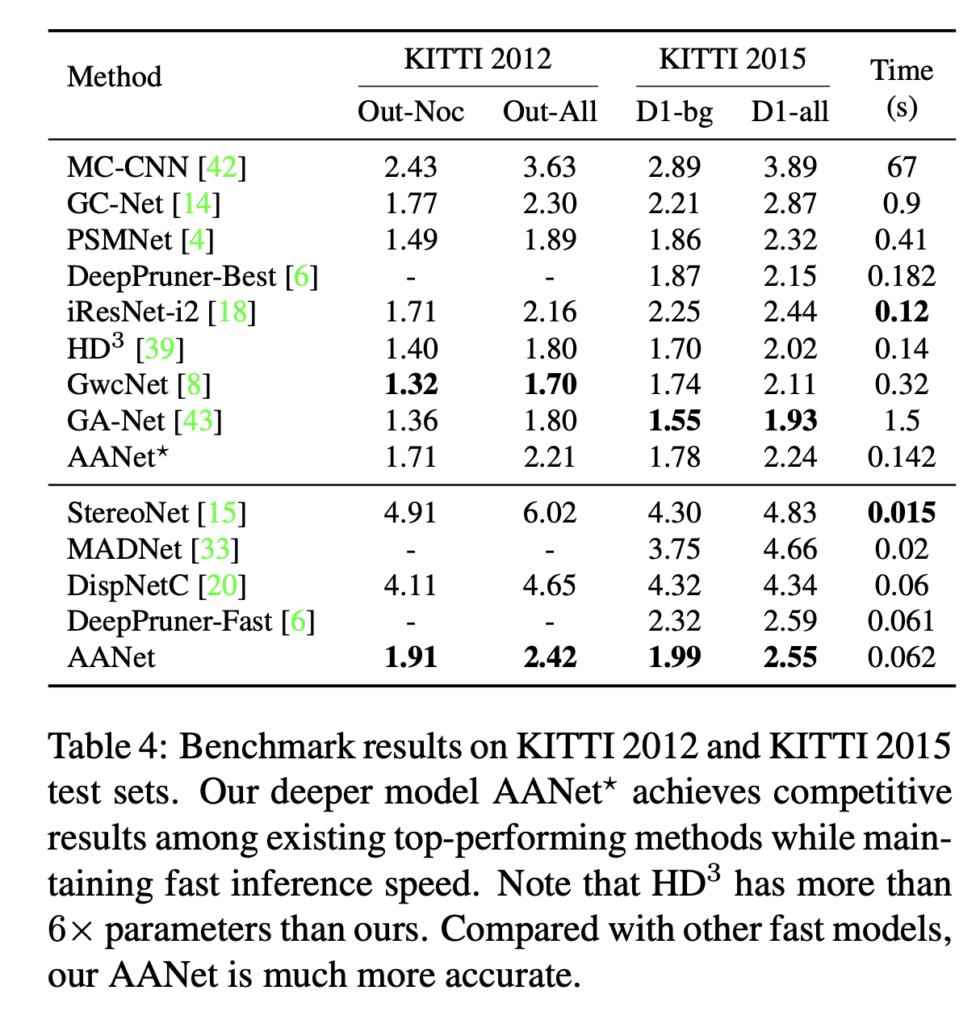
Table 4는 KITTI 2012, KITTI 2015 데이터셋에 대한 벤치마크 결과입니다. 구분선 아래는 비교적 빠르게 동작하는 모델과 비교한 것이며, 위는 타 모델과 비교하기 위해 더 높은 해상도(원본 이미지의 1/2)를 갖는 cost volume과 더 깊은 feature extractor를 사용하도록 변형한 모델인 AANet*을 사용하였습니다. 구분선 아래의 타 빠르게 동작하는 모델과 비교했을 때는 AANet이 훨씬 정확한 결과를 보이지만, 구분선 위의 타 방법론들과 비교했을 때는 ,, 그닥 좋은 성능은 보이지 않는 것으로 보입니다.

마지막으로 Fig 7은 KITTI 2015 데이터셋의 disparity 에측 결과에 대한 시각화 결과입니다. 빨간색과 노란색은 error가 큰 부분을 의미합니다.
안녕하세요. 좋은 리뷰 감사합니다.
전통적인 방식의 stereo matching 알고리즘은 크게 global과 local로 나눌 수 있고, 이 중 global 방법론은 목적 함수를 설계해 이 함수를 최소화하도록 하는 문제를 푸는 것으로 생각해 볼 수 있다고 하셨습니다. 이때 이 목적 함수는 고정되어 있는 것인가요 ? 아니면 유동적으로 설계할 수 있는 함수인건가요 ?
또 edge fattening 문제가 disparity를 추정할 때 물체의 edge 부분이 두껍게 나오는 것으로 이해했는데, 이와 같은 문제가 왜 발생하는지도 궁금합니다. 마지막으로 좌 우 이미지 feature 를 내적한 값을 사용함으로써 cost volume을 생성하는 것은 본 논문이 최초인건지 궁금합니다.
감사합니다 !
안녕하세요. 댓글 감사합니다.
1. global 방법론에서 설계하는 목적 함수 같은 경우 고정되어 있는 것은 아닙니다.
2. foreground 근처의 background를 foreground로 잘못 판단하여 더 fat하게 보이는 것인데, 이에대한 원인은 한 이미지에서는 배경이 pixel이 보이지만, 다른 이미지에서는 occlusion되어 있는 것 때문입니다.
3. 좌 우 이미지 feature간의 관계를 고려해 cost volume을 생성하는 방식은 DispNetC 방법론의 방식을 따른 것입니다.
안녕하세요 정윤서 연구원님 좋은 리뷰 감사합니다.
intro에서 기존 방법론인 DispNetC, PSMNet, GA-Net이 3D conv에 의해 높은 cost를 가진다고 언급해 주셨는데요, 그렇다면 [표2]에서 기존 방법론에 AA 모듈을 어떻게 적용한 것인지 궁금합니다. 기존 모델 구조를 가져가고 추가로 ISA, CSA를 붙이는 것으로 보이는데 오히려 연산량이 감소하는 이유가 궁금하네요.
그리고 본 논문의 main 실험은 [표4]인 것으로 보이는데요, 동일 데이터셋으로 실험한 결과임에도 성능 차이가 크게 발생하는 이유가 궁금합니다. 구분선 위의 AANet*과 비교되는 모델과 구분선 아래의 AANet모델과 비교되는 모델 간의 input shape이 다른 것으로 이해하면 될까요?
안녕하세요. 댓글 감사합니다.
1. 기존 방법론에서 cost aggregation 단계에서 사용되던 3D convolution을 본 논문에서 제안한 AA 모듈로 대체한 것입니다. 기본 모델 구조를 그대로 가져간 다음 추가로 ISA, CSA를 붙이는 것이 아니며, AA 모듈이 3D convolution의 연산량이 많이 든다는 점을 지적하며 제안한 모듈이기 때문에 연산량이 감소한 결과를 볼 수 있습니다.
2. 동일 데이터셋으로 실험했지만 성능 차이가 크게 발생하는 이유는 잘 모르겠지만,,, 구분선 아래의 방법론들이 inference 속도를 높이고자 하였고 이로써 성능이 떨어진 것으로 해석했습니다 . . 모델간의 input shape은 동일합니다.