Before Review
OTT 과제 제안서 작업 과정에서 Open-Vocabulary Object Detection에 대해서 서베이를 하고 있습니다.
마침 Open-Vocabulary Object Detection 문제를 Scene Graph와 접목 시켜서 푸는 연구가 나와있어 나중에 개인 연구에도 많은 귀감이 될 거 같아 논문 하나 리뷰 하게 되었습니다.
리뷰 시작하도록 하겠습니다.
Introduction
Object Detection은 예전부터 전통적으로 컴퓨터 비전 도메인에서 중요하게 다뤄진 문제 입니다. 대다수의 학생들도 딥러닝을 활용한 컴퓨터 비전을 배우면 가장 먼저 하는 것이 Object Detection 이죠.
전통적인 Object Detection은 고정된 category set을 가정하고 학습과 추론을 진행했습니다. 즉, 추론 과정에서는 학습 과정에서 배운 category만 대응할 수 있는 구조 였던 것이죠.
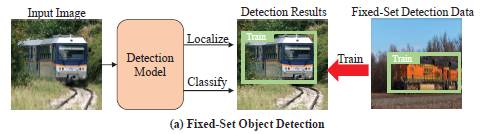
따라서 다양한 real-world system에서 Object Detection을 수행하기 위해서 내가 원하는 category를 포함하는 새로운 데이터 셋으로 re-train 시키는 과정이 필요 했습니다. 따라서 open-set을 가정하는 연구들이 많은 주목을 받게 되었습니다. open-set 연구란 모델이 학습 과정에서 볼 수 없었던 category에 대해서도 대응할 수 있는 방법들을 의미합니다. 학계에서 open-set을 가정하는 object detection은 크게 두 가지 흐름이 있는 거 같습니다.
먼저, Open-World Object Detection은

위의 그림과 같이 학습 과정에서 배우지 못한 category에 대해서는 unknown category라 예측하고 이를 다시 labeling을 수행하고 효과적으로 incremental learning 하는 과정을 의미합니다. 자율주행 상황에서 갑자기 등장하는 unknown object 들을 대응하기 위해서는 이러한 연구들이 필요하다고 볼 수 있습니다.
또한, Open-Vocabulary Object Detection은
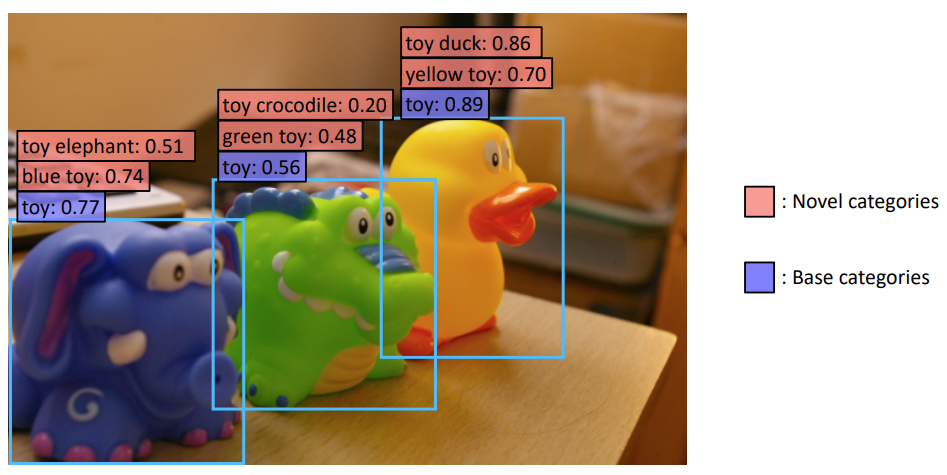
위의 그림과 같이 학습 과정에서 배우지 못한 Novel category에 대해서도 예측을 가능하게 만드는 연구라 볼 수 있습니다. 그림을 보면 학습 과정에서 사용한 base category는 toy 입니다. 하지만 그림을 보면 각각의 toy들은 blue toy, toy elephant, green toy 모두 가능합니다.
이렇게 새로운 category가 주어져도 일관성 있는, 일반성 있는 예측을 수행하도록 해주는 것이 open-vocabulary object detection이라 볼 수 있습니다. 이러한 것을 가능하게 해주는 것은 바로 Vision-Language Model(VLM)이죠. CLIP과 같은 대용량 Vision-Language Data로 학습한 모델은 fixed detection train dataset에 포함되는 object 뿐만 아니라 훨씬 더 다양한 object에 대해서 이미 text pair와 align을 맞추는 사전 학습을 했기 때문에 도움이 된다는 것 입니다.
제가 리뷰 하는 논문은 제목에서도 알 수 있듯, VLM을 활용하는 open-vocabulary object detection(이하 OV-detection) 연구 입니다.
이 때, OV-detection에서 VLM을 활용하는 방법은 크게 세 가지로 분류 됩니다.
- Pretraining-based methods : CLIP과 같은 사전 학습된 feature를 사용하는 것 입니다. 물론 CLIP의 표현력이 너무나도 일반적이기 때문에 효과가 어느 정도 있지만 adapter 없이 pretrain feature를 그대로 사용하는 것은 sub-optiaml 할 수 있습니다.
- Weakly supervised methods : Image classification 용 데이터 셋은 보통 class나 데이터가 훨씬 많고 사전 학습된 CLIP의 CAM이나 RPN(Region Proposal Network)를 활용해 pseudo bounding box를 학습에 사용하는 구조 입니다. 하지만 근본적으로 생성되는 pseudo box가 noisy 하기 때문에 sub-optimal 할 수 있습니다.
- Reformulation as grounding problem : Grounding data는 보통 text caption과 object에 대한 bounding box도 제공이 된다고 합니다. 이를 활용해서 학습을 추가적으로 진행하면 pretraining-based method 보다 더 유연하고 weakly supervised 방식 보다 덜 noisy 합니다.
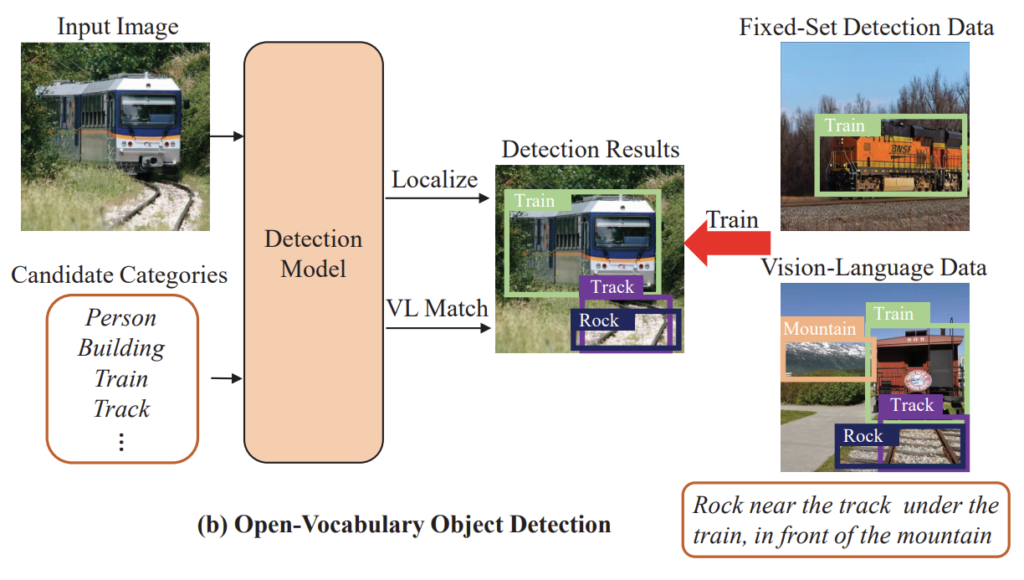
본 논문의 저자는 grounding box에서 좀 더 나아가 relation 정보를 활용하고자 합니다. 무슨 말이냐면 위의 그림에서 Vision-Language Data로 제공되는 caption을 살펴보도록 하겠습니다.
“Rock near the track under the train, in front of the mountain”
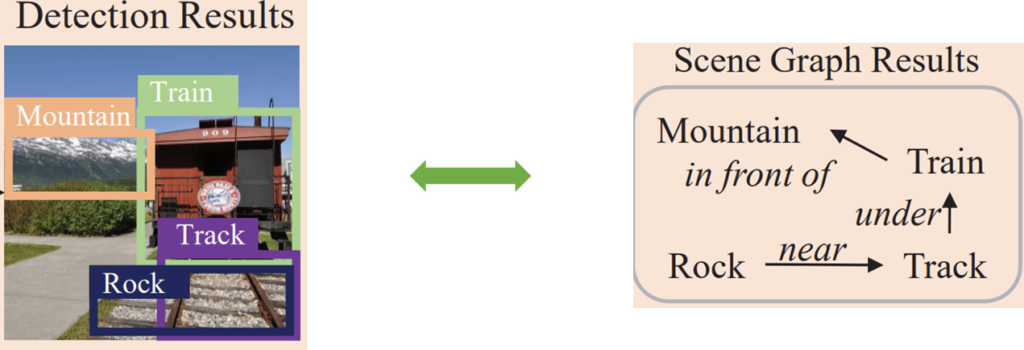
저 caption에서 제공되는 relation을 통해 model은 unseen object를 찾을 수도 있습니다. 무슨 의미냐면 “under train“이라는 말이 있다면 train 아래에 무엇이 있다는 말을 의미합니다. 설령 model이 train 아래에 있는 객체를 놓쳤다고 해도 이러한 관계 정보를 활용하면 다시 검출을 할 수 있다는 것이죠. 저렇게 “near”, “under”, “in front of” 처럼 관계를 나타내는 단어를 통해 model은 더욱 localization을 잘 수행할 수 있다는 것 입니다.
저자는 이러한 relation 정보를 잘 모델링 하기 위해 Scene-Graph Based Discovery Network(SGDN)을 제안합니다. 자세한 방법론적 얘기는 바로 뒤에서 하도록 하고 컨셉만 얘기하자면 Detection을 잘 하고 싶으니 Scene Graph를 함께 만들어보겠다는 의미입니다.
본 논문의 contribution 정리하고 이제 제안하는 방법론에 대해서 살펴보도록 하겠습니다.
- 저자는 처음으로 scene graph cue를 활용하는 OV-detection framework를 제안하였습니다. + 방법론에 대한 완성도
- 저자가 제안하는 SGDN은 많은 이전 sota를 능가했습니다. 또한 SGDN은 open-vocabulary scene graph로 생성할 수 있는데 이 과정에서 다른 open-vocabulary scene graph에서 하지 못하는 결과도 만들어낸다고 합니다.
그럼 이제 본격적으로 제안하는 방법론에 대해서 살펴보도록 하겠습니다.
Proposed Method
Overview
아래의 그림은 제안하는 방법론을 전반적으로 보여주는 구조도 입니다. 크게 세가지 모듈로 구성되어 있다고 볼 수 있습니다.
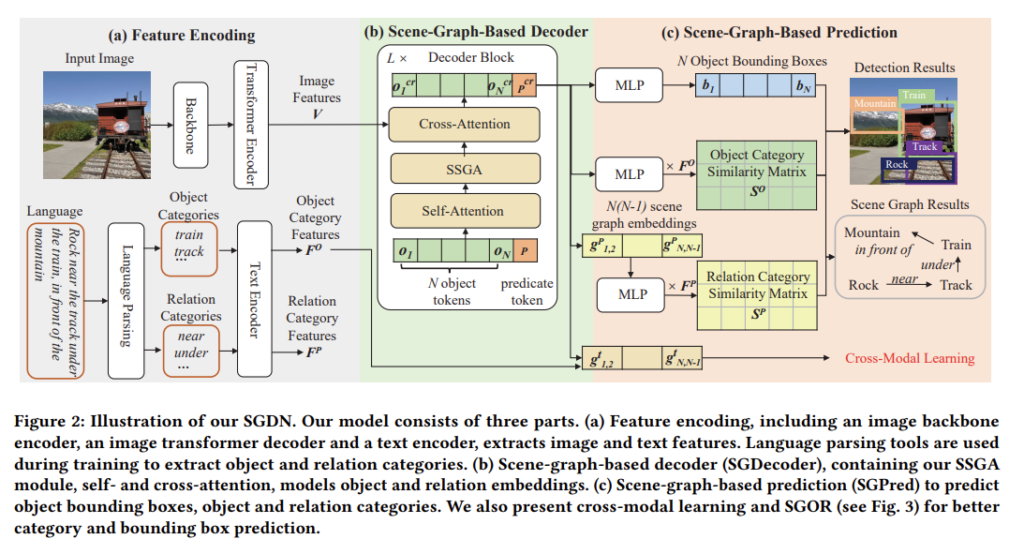
먼저 Feature Encoding, 입력으로 들어오는 Image와 몇 개의 Text를 처리합니다. Inference 과정에서 text는 보통 C개의 candidate object category가 들어옵니다.
다음으로 Scene-Graph-Based Decoder(SGDecoder), object와 relation에 대한 embedding을 생성하는 모듈 입니다. SGDecoder의 경우 OV-detection을 좀 더 잘 수행하기 위해 scene-graph 정보로부터 object embedding을 풍부하게 만들어주는 Scene-Graph-Guided-Attention(SSGA)이 제안되었습니다.
마지막으로 Scene-Graph-Based-Prediction(SGPred), object에 대한 bounding box, category, relation 정보에 대해 예측을 수행하는 모듈 입니다. 여기서 Dection Results와 Scene Graph Results를 바탕으로 서로 상호 보완적인 작업을 수행하기 위해 Scene-Graph-Based Offset Regression(SGOR) 이 제안되었습니다.
Feature Encoding
Image Encoder
Image Encoder는 Deformable DETR with ResNet50이라고 합니다. 한 장의 이미지가 들어와서 Image Encoder를 거치고 나오면 \mathbf{V}\in \mathbb{R}^{N_{v}\times D_{v}}를 얻을 수 있습니다. 이 때 N_{v}는 이미지 patch의 갯수이며 D_{v}는 embedding 차원입니다.
Text Encoder
Text Encoder는 RoBERTa를 사용했다고 합니다. 우리는 object category와 relation을 처리해야 하기 때문에 input text는 두 가지로 분류할 수 있습니다.
학습 단계(Training)에서는 language parsing tool을 사용하여 명사와 관계를 분리하는 작업을 먼저 진행했다고 합니다.
“Rock near the track under the train, in front of the mountain”
- 명사(noun) : Rock, track, train, mountain + “no object”
- 관계(relation) : near, under, in front of + “no relation”
각각의 명사와 관계마다 예외 처리를 위한 “no object” 혹은 “no relation”도 추가적으로 들어가게 됩니다.
추론 단계(Inference)에서는 우리가 target으로 하려는 application에 맞춰 후보군을 미리 생성해야 합니다. 여기서는 category의 경우 C개의 후보가 있다 가정하고 relation의 경우 M개의 후보가 있다 가정하겠습니다. 그렇게 되면 Text encoder는
- \mathbf{F}^{o}\in \mathbb{R}^{(C+1)\times D} : category를 담당해줄 text embedding 입니다.
- \mathbf{F}^{p}\in \mathbb{R}^{(M+1)\times D} : relation을 담당해줄 text embedding 입니다.
이렇게 출력을 반환할 것 입니다.
Scene Graph Based Decoder
다음으로 디코더 부분 입니다. DETR 구조와 유사하기 때문에 DETR 구조에 대해 잘 모르신다면 저의 지난 리뷰를 한번 읽어보시길 바랍니다.
우선 디코더의 입력으로는 N개의 학습 가능한 object token이 들어옵니다. 그리고 여기서 subject와 object 간의 관계를 담당해줄 수 있는 predicate(서술어) token을 하나 사용합니다. 즉, predicate token을 하나 사용해서 여러개 object 끼리의 관계를 모델링하겠다는 의미 입니다. 서술어를 담당하는 predicate token을 하나만 사용하는 이유는 간단 합니다.
Object 간 관계를 정의할 때 Scene Graph Generation 분야에서는 i번째 object token \mathbf{o}_{i}와 j번째 object token \mathbf{o}_{i}를 predicate token \mathbf{p} \in \mathbb{R}^{D}를 가운데에 두고 concat 하여 정의합니다.
- \text{relation} : [\mathbf{o}_{i},\mathbf{p},\mathbf{o}_{j}] \in \mathbb{R}^{3D}
따라서 predicate token은 정말 일반적인 서술어의 역할만 한다는 관점에서 하나만 사용해주고 구체적은 object 간 관계를 모델링할 때는 object token끼리 같이 사용해서 모델링 해주게 됩니다.
Self-Attention
당연히 decoder block 마다 self-attention을 수행하게 되는데 이 때 query, key, value가 모두 동일하게 object token과 predicate token 입니다. 일단 token 간 dependency를 잘 모델링 하기를 기대한다고 보시면 됩니다.

The SSGA Module
다음으로는 Scene Graph 정보를 이용하여 object token을 좀 더 풍부하기 encoding하게 해주는 sparse scene guided attention(SSGA) 모듈에 대해서 설명하겠습니다.
기본적으로 scene graph를 구성하는 embedding은 아래와 같이 정의 됩니다.
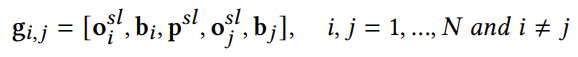
여기서 \mathbf{o}^{sl}_{i}와 \mathbf{o}^{sl}_{j}는 self attention 처리된 객체 token이며, \mathbf{p}^{sl}는 self attention 처리된 서술어 token 입니다.
다음으로 \mathbf{b}_{i}와 \mathbf{b}_{j}는 각각 i번째 객체의 box 좌표와 j번째 객체의 box 좌표입니다.
그런데 여기서 갑자기 box 좌표가 등장했습니다..?
저자가 말하기로 detail은 Scene Graph Based Prediction에서 설명할테니 여기서는 그냥 넘어가자라고 하네요.
무튼 위에서 정의한 graph embedding \mathbf{g}_{i,j}\in \mathbb{R}^{3D+8}는 2개의 object pair가 있을때 하나 정의 됩니다. 그렇다면 N개의 object가 있을 때는 몇 개의 pair를 생성할 수 있을까요? 여기서는 방향도 중요합니다. 누가 subject이고 누가 object인지에 따라 embedding이 달라지기에 결국 N\times (N-1)개의 pair가 생성 됩니다.
그래서 우리의 Scene Graph Matrix \mathbf{G} \in \mathbb{R}^{N(N-1)\times (3D+8)}가 하나의 이미지마다 정의 됩니다.
앞서 정의한 Self-attention은 object, predicate token 끼리 attention 이고 여기서 정의하려는 attetnion은 object와 Graph간의 attention 입니다.

이 때 computational cost를 줄이기 위해 object는 해당 object와 연관된 graph embedding끼리만 attention을 수행하는 sparse attention을 수행합니다.
이렇게 Graph Information을 활용하여 object token을 좀 더 풍성하게 encoding 하는 것이 제안하는 SSGA의 핵심 입니다.
Cross Attention
Cross Attention은 Image Encoder와 SSGA를 거치고 나온 token 간의 attention 입니다. 기존 DETR에서 사용했던 attention 구조와 동일합니다.

정리하면 하나의 Decoder block은 총 3개의 attention 연산을 거치고 나오게 됩니다.
Scene Graph Based Prediction
다음으로 Prediction 모듈입니다. Prediction을 수행하는 부분은 그렇게 어렵지 않습니다. 결국 우리가 예측해야 하는 데이터는 총 세가지 입니다. 1) object bounding boxes, 2) categories, 3) relation categories 이렇게 말이죠.
Object bounding box prediction
Decoder block을 거치고 나온 Object Token을 MLP에 태워서 각각 입력 token에 대한 예측 bounding box를 반환 합니다. 이 부분은 DETR과 동일하여 어렵지 않습니다.
Scene Graph based offset Regression(SGOR)
그런데 사실 bounding box 예측을 가장 마지막 디코더 block에서 진행하지 않습니다. Box의 offset을 모델링하는 것이 fixed-set object detection 쪽에서 이미 좋은 성능을 보여주어서 저자도 비슷하게 진행했다고 합니다.
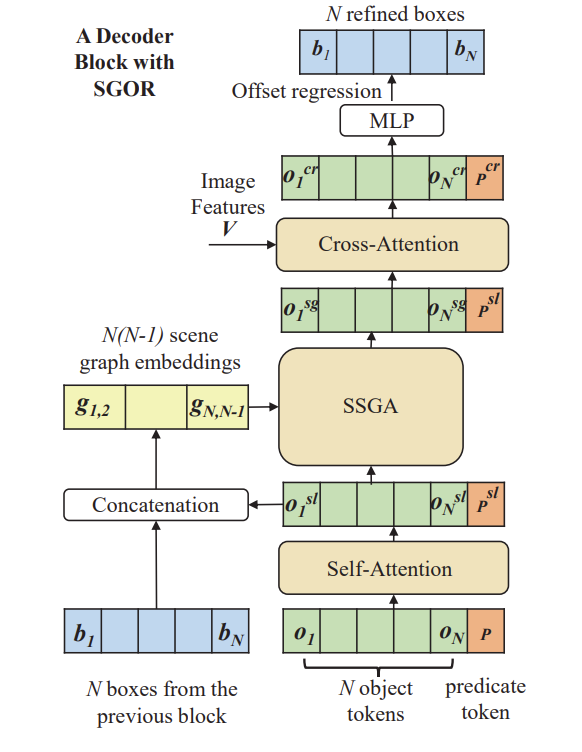
위의 그림에서 “N boxes from the previous block”이란 말이 있습니다. 일단 처음에는 랜덤하게 N개의 object에 대해 box 좌표를 초기화 합니다. 이렇게 랜덤하게 초기화 했기 때문에 아까 위에서 box가 갑자기 등장했을 때 사용할 수 있었던 이유이기도 합니다.
다음으로 우리는 decoder block 내의 모든 attention 연산을 거치고 나온 object token을 이용하여 box의 offset을 모델링 합니다.
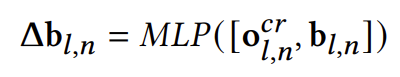
이렇게 말이죠. 그리고 나면 다시 bounding box를 수정하고 다음 decoder block으로 전달해줍니다.
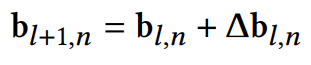
모든 decoder block을 거치고 나온 refined box \mathbf{b}_{L+1,n}=\mathbf{b}_{L,n}+\Delta\mathbf{b}_{L,n}를 우리는 final box prediction으로 사용하게 됩니다.
Object category prediction
Category prediction은 간단합니다. 가장 마지막 decoder block을 타고 나온 최종 object token과 category embedding 간의 내적을 진행하면 되기 때문입니다. 물론 object token을 바로 사용하는 것은 아니고 two-layers MLP를 거치고 나온 embedding과 category embedding 간의 코사인 유사도를 나타내는 행렬을 생성합니다.
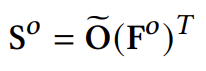
이 때, \mathbf{S} \in \mathbb{R}^{N\times (C+1)}로 각각의 object가 각각의 category에 해당할 확률을 나타내는 행렬이라 보시면 됩니다.
그렇다면 우리는 저 행렬을 바탕으로 object마다 score가 가장 높은 category를 바탕으로 예측을 수행하면 됩니다.
Relation category prediction and joint learning
마찬가지로 relation에 대한 예측도 비슷하게 진행됩니다. 여기서는 Scene Graph Matrix \mathbf{G} \in \mathbb{R}^{N(N-1)\times (3D+8)}를 바탕으로 진행합니다. 먼저 여기서도 two-layers MLP를 활용하여 3D+8에 대한 차원축을 D로 변환시켜 줍니다.
다음으로는 똑같이 relation embedding과 내적을 수행하여 유사도 행렬을 정의해줍니다.
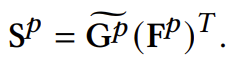
마찬가지로 우리는 정의한 유사도 행렬을 바탕으로 object pair마다 score가 가장 높은 relation을 바탕으로 예측을 수행하면 됩니다.
Cross-modal learning
여기서는 말이 cross-modal learning이지 그냥 relation에 대한 supervision까지 활용하는 방법이라 생각하시면 됩니다. 우리가 학습 과정에서는 어떤 object와 object가 어떤 relation인지 정보를 알고 있으니 그 정도를 토대로 Scene Graph를 구축해서 guide를 줘보자라는 것이죠.
여기서는 Scene Graph Matrix \mathbf{G} \in \mathbb{R}^{N(N-1)\times (3D+8)}를 구축하는 과정에서 ground-truth를 참조하여 object와 relation에 대한 embedding을 대체합니다. 정확히는 object token들을 object category embedding으로 대체한다고 하네요.
그 다음에 동일한 two-layers MLP를 통과하여 유사도 행렬을 만들어냅니다.
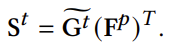
위에서 relation을 예측하는 과정에서 정의한 \mathbf{S}^{p}와 방금 G.T를 참조하여 생성한 \mathbf{S}^{t}가 유사해질 수 있는 loss를 하나 붙이면 더욱 일관성 있는 학습을 할 수 있다고 합니다.
Training
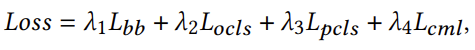
제안하는 방법론의 학습을 담당하는 Loss는 4개 입니다.
- L_{bb} : bounding box에 대한 손실로 smooth L1-Loss를 사용했다고 합니다.
- L_{ocls} : object category에 대한 손실로 BCE Loss를 사용했다고 합니다. 결국 우리가 유사도 행렬을 바탕으로 예측을 진행하니 임의의 object가 임의의 category 인지 아닌지를 예측하는 과정과 동일하기 때문에 BCE Loss를 사용하고 있습니다.
- L_{pcls} : object pair의 relation에 대한 손실로 동일하게 BCE Loss를 사용했다고 합니다
- L_{cml} : cross modal learning에 대한 손실로 BCE Loss를 사용했다고 합니다. 결국 \mathbf{S}^{p}와 \mathbf{S}^{t}가 유사하게 만드는 것이 목표이므로 BCE Loss를 사용해도 무방합니다.
Experiments
Experiment Settings
처음 보는 분야의 논문이기 때문에 실험 세팅도 한번 정리하고 넘어가도록 하겠습니다.
VL data
OV-detection 시나리오에서는 어떠한 VL data도 활용이 가능합니다. 저자는 이전 다른 연구 처럼 grounding data를 활용했다고 합니다. Flickr30K Entities는 31K개의 이미지 데이터와 관련된 annotation이 존재합니다. Visual Genome의 경우 108K개의 이미지 데이터와 관련된 annotation이 존재합니다.
저자는 이를 합쳐 대략 140K개의 이미지 데이터를 학습 데이터로 활용하였습니다.
VL data의 경우 많으면 수백만의 데이터를 가지는 경우도 있는데 저자는 그렇게 까지는 활용하지 않았다고 합니다.
또한 Visual Genome의 경우 scene graph annotation도 제공하지만 그것은 활용하지 않았다고 하네요.
COCO
COCO 2017 데이터는 120K개의 학습 이미지와 5K개의 검증 데이터가 존재합니다. 일반적인 zero-shot 세팅을 가정하기 위해 COCO 48개의 base category와 17개의 novel class를 사전에 정의했다고 합니다.
이 때 COCO의 120K개 학습 이미지와 위에서 Flickr30K Entities와 Visual Genome을 합친 데이터가 겹치는 부분이 있어 중복되는 부분은 제거를 했다고 합니다.
LVIS(Large Vocabulary Instance Segmentation)
LVIS 데이터는 100K개의 학습 이미지와 20K개의 검증 이미지가 존재합니다. LVIS에 존재하는 category의 경우 long-tail 분포를 따르고 있어 405개의 frequent, 461개의 common, 337개의 rare category로 분류 됩니다.
저자는 866개의 common + frequent를 학습용으로 쓰고 337개의 rare를 평가용으로 활용 합니다.
Main Results
먼저 COCO에서의 Zero-shot 결과 입니다. 여기서 without novel class는 학습 과정에서 novel class를 보지 못한 경우를 의미하고 with novel class는 학습 과정에서 novel class를 본 경우를 의미합니다.
저자가 제안하는 SGDN은 without novel class 상황임에도 불구하고 with novel class 의 sota 보다 더 높은 정량적 성능을 보여주고 있으며 다른 without novel class sota들에 비해서도 large margin의 perfomance gap을 보여주고 있습니다.
역시 Scene Graph의 위력이 상당합니다.
Training을 보면 학습에 사용한 데이터가 방법론마다 제각각 다른데 저자가 제안하는 방법은 비교적 적은 데이터를 가지고도 높은 성능을 보여주고 있어 높은 일반화 성능을 보여주고 있습니다
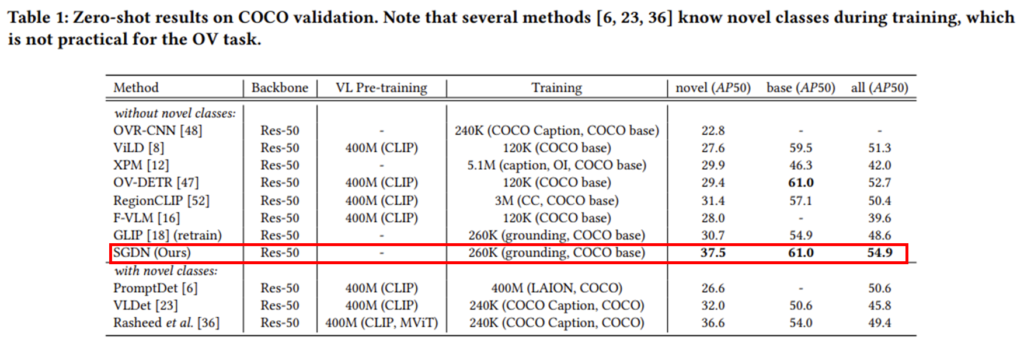
다음으로 LVIS에서의 Zero-shot 결과 입니다. 비슷한 경향성을 보여주고 있습니다. 여기서는 without novel class 상황의 VLDet에 대해서 common에 대한 mAP가 조금 밀리고 있지만 어차피 fair한 비교는 아니기에 크게 신경쓰지 않아도 됩니다.
그것을 제외하고는 모든 평가 상황에서 가장 좋은 성능을 보여주면서 LVIS data에서도 좋은 정량적 성능을 보여주고 있습니다.
타 방법론들 중 학습 데이터를 굉장히 많이 가져감에도 불구하고 저자가 제안하는 SGDN에 비해 훨씬 낮은 성능을 보여주는 것을 보면 Scene Graph의 효과가 상당했음을 알 수 있을 거 같습니다.
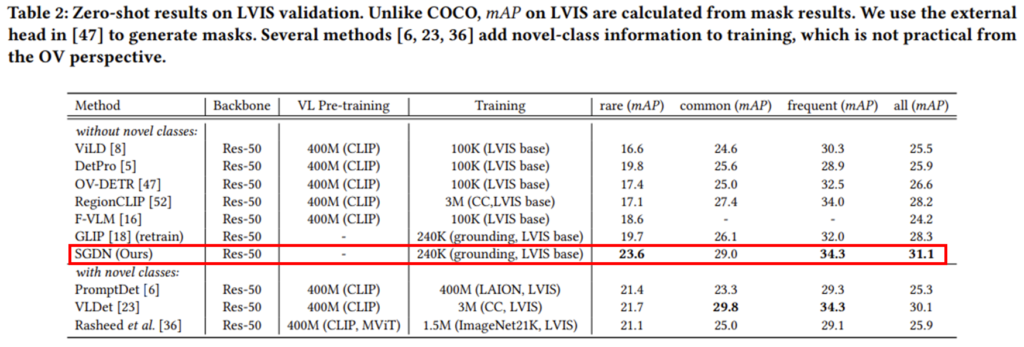
다음으로는 cross dataset result 입니다. 사실 원래 GLIP의 경우 27M개의 대용량 데이터와 Swin-L이라는 대용량 백본을 가지고 진행했던터라 성능이 꽤 높긴 했나 봅니다.
이 때 저자의 학습세팅과 동일하게 했을 때는 49.8->36.9로 떨어진다고 하네요.
물론 대용량의 데이터와 대용량의 백본을 최적화 시키는 것 역시 어려운 작업이기 때문에 분명한 contribution이 있지만 이렇게 또 학습 세팅을 동일하게 했을 때는 저자가 제안하는 방식이 더 우수하다고 하네요.
Ablation Study
다음으로는 ablation study 입니다.
Scene Graph for OV detection
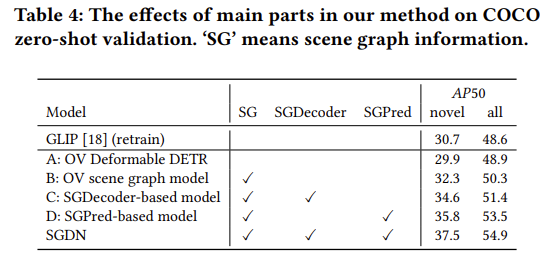
제안하는 모듈에 대한 ablation 입니다. Baseline 자체가 꽤 높은거 같기는 하네요. GLIP을 저자 본인이 retrain 시킨 성능이 30.7/48.6인데 베이스라인 실험 세팅이 29.9/48.9 입니다.
물론 그럼에도 제안하는 모듈을 모두 붙였을 때는 꽤나 많은 performance gain이 있긴 합니다.
버릴거 하나 없이 모두 다 사용했을 때 best performance를 보여준다고 합니다.
OV Scene Graph Generation
SVRP라고 해서 Open-vocabulary Scene Graph Generation에서 사용하는 베이스라인이 있는거 같습니다. 그런데 그 방법보다 더 OV Scene Graph Genearation을 잘한다고 하네요.
Detection을 잘 수행하기 위해 추가한 Graph 정보이지만 막상 Open-vocabulary Scene Graph Generation에서도 좋은 성능을 보여주고 있습니다.
역시 multi-task learning 관점에서 두 가지 task가 모두 잘되어야 좋은 효과가 있는 거 같습니다.
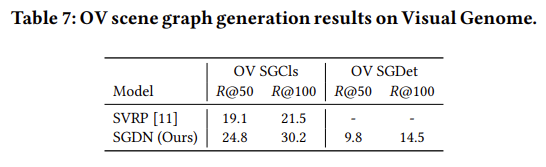
OV scene graph Detection
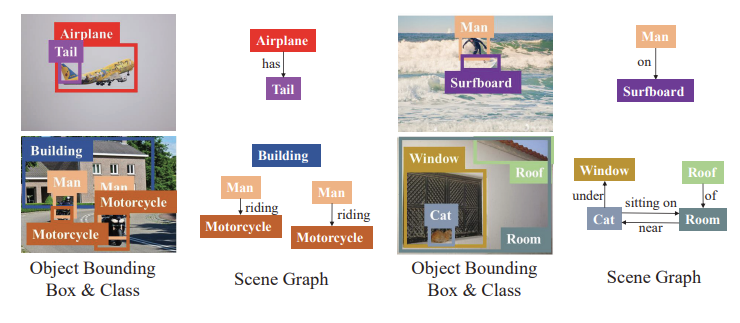
제안하는 방법이 relation도 예측을 하다 보니 이렇게 graph를 예측하기도 하는데 꽤나 정교한 Graph까지 생성이 가능한 것을 볼 수 있습니다.
Conclusion
비록 제안서 작업을 위해 서베이를 하다가 알게된 논문이지만 나름 재밌게 읽었습니다.
코드가 공개 되었다면 너무 좋았을텐데 저자한테 한번 연락 해봐야겠습니다.
저도 Scene Segmentation을 Scene Graph를 이용하여 해결하려고 했었는데, 비슷한 컨셉의 논문이 OV-detection에서 제안이 되었네요.
빠르게 연구하지 않으면 다른 이들에게 넘겨주게 될 거 같습니다. 제안서 작업 빠르게 마무리하고 개인 연구 다시 집중해서 진행해야겠습니다.
리뷰 읽어주셔서 감사합니다.
좋은 리뷰 감사합니다.
grounding data로부터 물체 간의 관계성을 scene graph와 detection+laungage model을 접목하여 OVD 태슼에 접근한 방식이 신선했습니다.
설명이 친절하게 잘되어 있어서 이해가 잘되네요 ㅋㅋ
근데 리뷰에서 novle class의 object localization을 어떻게 알아내는지에 대해서는 다루지 않아서 모델
이 어떤 식으로 알아내는지 설명 부탁드려도 될까요?
Training의 L_{bb}이 학습하는 GT가 known class에 대한 localization 정보만 가지고 있다면 novel class에 대한 localization은 더 더뎌질 것 같은데… 어떤 추가적인 장치가 있는 걸까요?