제목에서 확인할 수 있듯 이 논문은 video semantic segmentation task를 다루고 있는데요, 제가 해당 task에 자세히 알고 있는 것은 아닌지라… video segmentation관련 내용보다는 본문의 방법론이 최적화/경량화 관점에서 어떤 contribution이 있는지를 중점으로 리뷰 진행하도록 하겠습니다.
Introduction
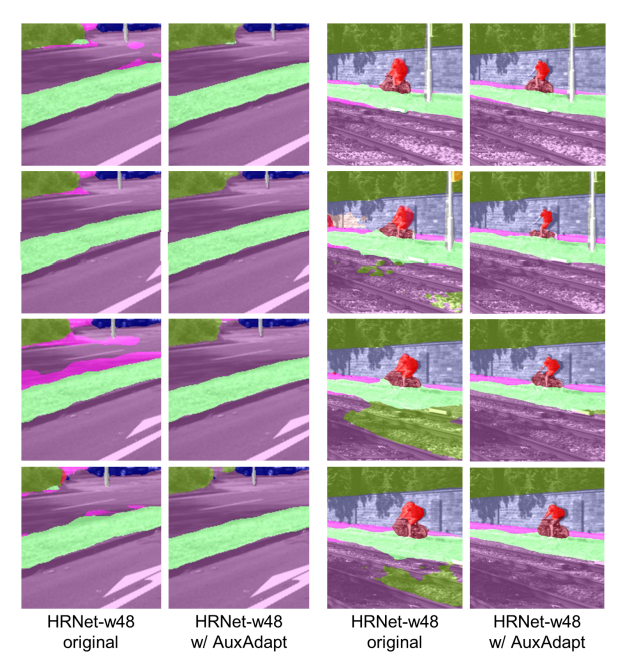
Video semantic segmentation에는 temporal consistency 문제가 발생한다고 합니다. Temporal consistency란 비디오 데이터를 처리할 때 연속적인 프레임에서 정보가 일관되게 유지되는 정도를 나타내며, video segmentation을 수행할 시 동일 object를 연속된 frame에서 서로 다르게 인식하는 것을 의미합니다. 이러한 문제의 원인은 Video segmentation을 수행할 때 각 frame에 단순히 image segmentation기법을 독립적으로 적용하는 방식을 사용하였기 때문입니다. [그림1]의 1열과 3열은 temporal consistency가 떨어지는 상황을 보여주고 있는데요, 연속된 프레임에서 비슷한 시각적 특징을 지니며, 같은 label을 가지고 있는 픽셀이 서로 다르게 labeling 되는 것을 확인할 수 있습니다.
이에 기존 연구들은 비디오 데이터에 추가적인 정보를 함께 사용하였는데요, 대부분 optical flow를 사용하여 이웃 프레임 간 픽셀의 대응 관계를 통해 temporal consistency를 확보하였습니다.
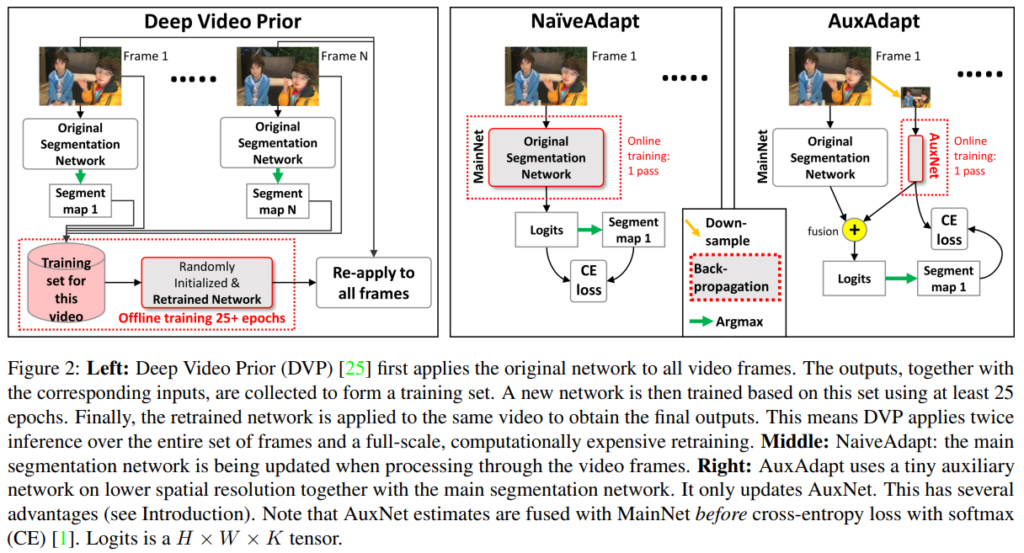
그러나 optical flow 기반의 방법론은 정확한 optical flow map은 추론하기 어려우며, segmentation을 수행하기 위해 video frame과 optical flow를 동시에 사용해야 하기 때문에 computational overhead가 발생한다는 단점이 있습니다. 이에 Deep Video Prior(DVP)와 같이 optical flow를 사용하지 않는 test-time adaptation 기반의 방법론이 사용되기도 하였으나, 이 또한 test video 당 20 epoch 이상의 추가적인 학습을 필요로 하기 때문에 상당한 computational cost가 발생한다는 문제가 있었습니다.
따라서 본 논문의 저자들은 video 데이터만으로 segmentation을 진행하는 unsupervised test-time adaptation 방법론인 AuxAdapt를 제안하였습니다. 해당 방법론의 핵심은 기존 segmentation network(이하 MainNet)를 사용하되, 여기에 small auxiliary network(AuxNet)를 추가한 것으로, test-time adaptation을 수행 시 MainNet은 고정시킨 채 AuxNet만 학습시키는 것입니다. 구체적인 방법론은 아래의 method 부분에서 설명드리고, 저자들이 언급한 본 논문의 contribution을 정리하고 넘어가겠습니다.
- Video semantic segmentation의 temporal consistency 향상을 위한 unsupervised online adaptation 방법론인 AuxAdapt 제안. AuxAdapt는 optical flow와 같은 cross-frame feature를 필요로 하지 않으며, 기존 모델에 추가하는 방식으로 범용성이 넒음.
- Main segmentation network에 추가되는 small auxiliary network인 AuxNet 제안. adaptation 진행 시 main net의 업데이트를 진행하지 않아 효율적인 연산 가능
- 두 연속 프레임의 차이를 기반으로 momentum coefficient를 조절하는 change-detection-based-adaptive momentum 제안
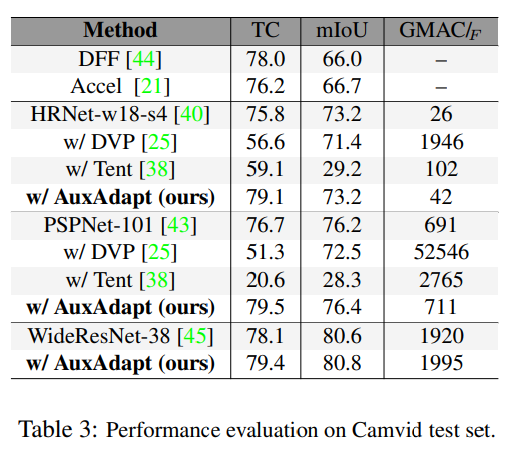
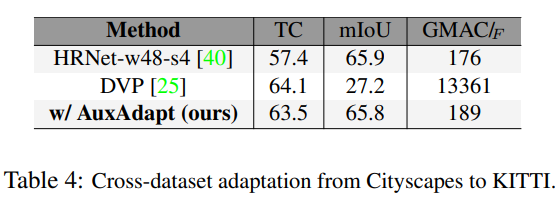
- Cityscapes, Camvid, KITTI 데이터셋으로 실험하여 기존 방법론에 비해 적은 computational cost로 더 높은 segmentation 성능을 달성함
Method
Learning from Network’s Own Decisions
어떤 이미지를 학습된 모델로 Segmentation 하는 경우 , 사전 학습된 모델 \mathcal{f}^{\text{main}} 은 RGB 이미지 {x} \in [0, 1]^{H \times W \times 3} 을 입력으로 받아, K -class의 prediction map인 y^{\text{main}} \in \mathbb{R}^{H \times W \times C} 을 생성합니다. 이미지 내의 spatial location (i, j) 에 대해, {y}{\text{main}}(i,j,k) 는 해당 픽셀이에서 class k 에 대한 confidence score를 나타냅니다. segmentation을 위해 {y}^{\text{main}} 의 마지막 차원에 대해 픽셀별로 argmax 연산이 적용되어, 각 픽셀에 대해 가장 score가 높은 class가 해당 pixel의 class로 예측됩니다. 한 이미지에 대한 segmentation 결과는 모든 픽셀의 예측 클래스를 포함하여 {y}^{\text{seg}} \in {1, 2, \ldots, K}^{H \times W} 라고 표기될 수 있는데요, video를 입력으로 하였을 때는 이러한 segmentation이 프레임에 걸쳐 진행되기 때문에 프레임의 순차적인 시퀀스 \mathbf{X} = \{\mathcal{x}_1, \ldots, \mathcal{x}T\} 에 대한 segmentation은 \mathcal{f}^{\text{main}} 은 {Y} = \{\mathcal{y}_1^{\text{seg}}, \ldots, \mathcal{y}_T^{\text{seg}}\} 로 표현되며, 이때 T 는 비디오의 프레임 수를 의미합니다.
위에 설명드린 바와 같이 \mathcal{N}^{\text{main}} 을 X 에 적용하여 video semantic segmentation은 가능하지만, 그 결과로 나온 Y 는 일반적으로 temporal consistency가 떨어지게 됩니다. 저자들은 이러한 문제의 원인을 output의 uncerteny로 보았는데요, 이에 network로부터 생성된 hard label로 학습함으로써 이를 해결하고자 하였습니다. 이는 network가 이전에 본 것과 시각적으로 유사한 이미지 영역에 대해 더 confidence가 높은 prediction을 수행할 수 있도록 하여 uncertainty 문제를 해결하였다고 합니다. 이때, 학습은 one-pass 방식으로 동작하여 test video가 모델을 한 번만 통과하게 됩니다.
위의 알고리즘을 간단히 구현하면 [그림2]의 중앙 그림과 같이 t 번째 프레임에서 y_t^{\text{main}} 과 y_t^{\text{seg}} 사이의 loss를 계산하고 이 loss에 대해 네트워크를 업데이트 하는 방식으로 나타낼 수 있습니다. 논문에서는 이러한 adaptation method를 NaiveAdapt라고 하였습니다. 그러나 이 NaiveAdapt는 전체 network를 학습하기에 computational cost가 높고, 긴 비디오에 대해서는 오히려 segmentation acc가 떨어지는 경우가 있었으며, 이전 프레임의 정보를 필요로 하는 architecture나 recurrent module을 가진 모델 경우 학습이 어려웠다고 합니다.
Adaptation Using Auxiliary Network
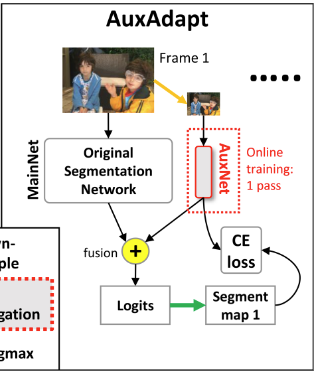
위의 단점을 해결하기 위해 저자들은 간단한 해결책을 제시하였는데, 위 그림과 같이 기존 segmentation network(MainNet)에 small auxiliary network(AuxNet)을 추가하였습니다. 비디오를 스트리밍할 때, 시간 t 에서 MainNet과 AuxNet은 각각 현재 프레임에 대한 자신의 예측 맵, y_t^{\text{main}} 과 y_t^{\text{aux}} 를 생성합니다. 그런 다음 두 모델의 prediction map을 더한 뒤 argmax 연산을 적용하여 이산적인 semantic segmentation decision, y_t^{\text{seg}} ,를 얻습니다. NaiveAdapt와 달리, AuxAdapt에서는 MainNet을 고정된 상태로 유지하면서 y_t^{\text{seg}} 를 기반으로 오직 AuxNet만 update를 진행하며, 아래의 [수식 1]과 같이 gradient descent를 사용합니다.
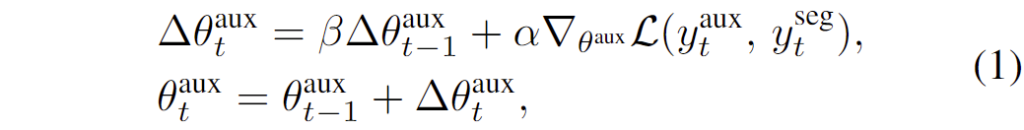
[수식 1]에서 \theta^{\text{aux}} 는 AuxNet의 파라미터를 나타내고, \alpha 는 learning rate, \beta 는 past gradients를 제어하는 momentum coefficient를 의미합니다. Loss function은 아래의 [수식 2]와 같이 CE를 사용하였습니다.
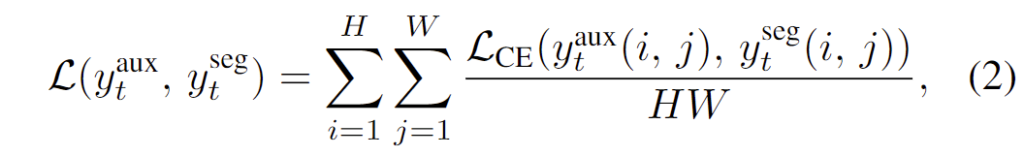
비디오의 각 프레임을 네트워크가 처리하면서 업데이트가 수행되므로, 배치 크기는 1로 고정되며, 이로 인해 batch normalization 레이어의 평균과 표준 편차가 고정됩니다.
AuxAdapt는 small AuxNet을 도입함으로써, 전체 MainNet을 업데이트하는 것보다 훨씬 적은 연산량을 확보하였으며, MainNet의 복잡한 학습 절차에 관여하지 않고 forward 연산만 실행하므로 AuxAdapt를 어떤 semantic segmentation 네트워크에도 쉽게 적용할 수 있다는 장점이 있습니다.
또한 AuxNet은 general data에 대한 segmentation 성능을 확보할 수 있었는데요, 구체저으로는 main net이 고정되어 있기 때문에 adaptation으로 인한 catastrophic forgetting 을 방지하고 여러 데이터에서 최소한의 성능을 확보할 수 있었다고 합니다.
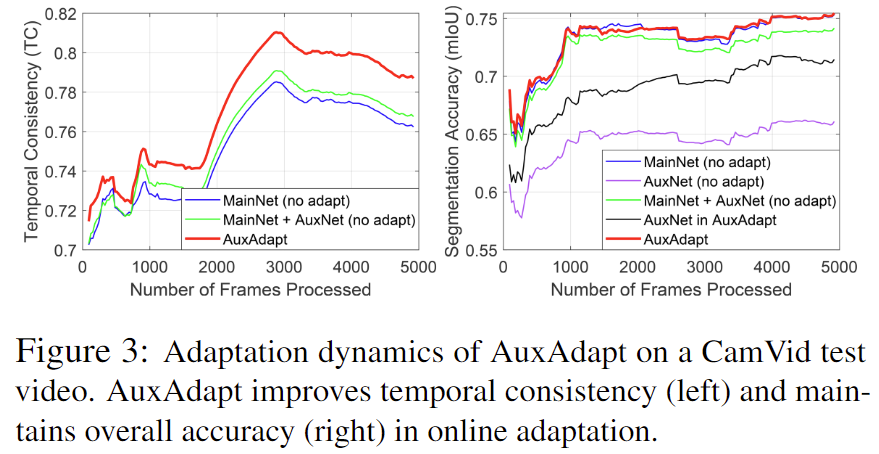
[그림 3]은 sample test video에 대한 adaptation
AuxAdapt의 동작 과정은 아래의 [알고리즘 1]과 같이 정리할 수 있습니다.

Experiments
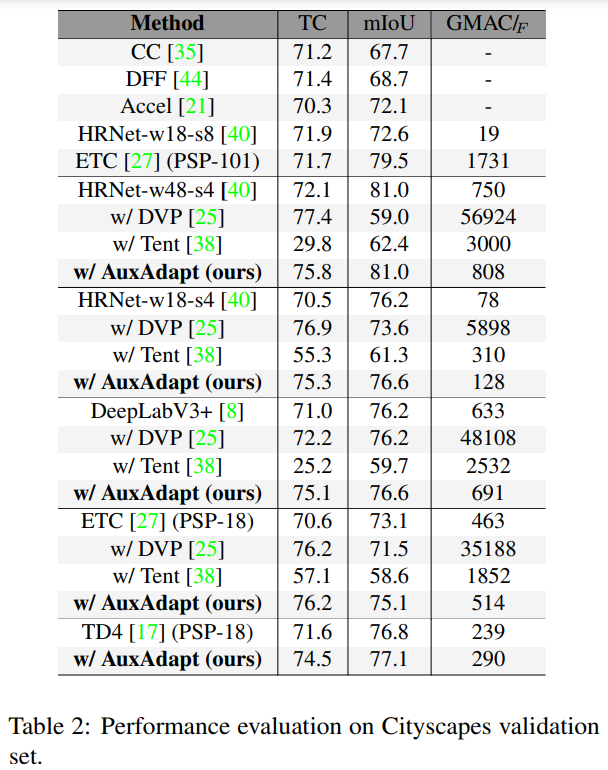
안녕하세요. 천혜원 연구원님 좋은 리뷰감사합니다.
Figure3에서 MainNet + AuxNet (no adapt)와 AuxAdapt 에서의 성능차이가 꽤 나는 것으로 확인되는데 여기서 adapt가 단순히 AuxNet을 붙이는 것외에 adaptation을 적용해 adaptation으로 인한 catastrophic forgetting 을 방지한다고 언급해주셨는데 adaptation이 무엇인지 catastrophic forgetting이 왜 방지되는지 궁금합니다.