안녕하세요. 오늘 제가 리뷰할 논문은 바로 CVPR2015에 개재된 Learning Spatiotemporal Features with 3D Convolutional Networks입니다. 이 논문은 비디오 task에서 3D convolution을 제시한 모델입니다.
Introduction
인터넷에서의 multimedia의 발전으로 비디오들이 늘어나고 있습니다. multimedia상에서의 수많은 정보들을 잘 이해하기 위해서는 비디오들을 이해하고 분석하는 것이 중요하지만, 비디오 task에서의 발전에도 불구하고 아직 부족한 것은 사실입니다. 실제로 이 논문이 개재될 때에는 비디오에 관련한 연구가 아직 활발하게 이뤄지기 전입니다. 저자는 특히 large-scale의 비디오 tasks를 homogeneous way로 해결하기 위해서는 generic한 video descriptor가 필요하다고 주장하며, 효과적인 video descriptor를 위해서는 크게 4가지의 특성들이 필요하다고 말합니다.
- generic(포괄적): discrimitive한 동시에 여러 타입의 비디오를 represent할 수 있어야한다.
- compact(한 descriptors): 수많은 정보들 속 많은 비디오들을 다뤄야하기에 compact한 descriptors들이 필요합니다.
- efficient(to compute): real world에서는 수 천의 비디오들을 분 단위로 처리해야합니다.
- simple(to implement): 좋은 descriptors는 linear classifier와 같은 쉬운 모델에서도 잘 작동해야합니다.
이미지 tasks에서는 IMAGENET을 활용한 image feature들을 잘 추출하는 많은 사전학습 ConvNets가 생겼습니다. 이러한 features들은 전이학습에 효과적이지만 motion modeling의 부족으로 비디오에는 적합하지 않습니다. 여기서 motion modeling은 temporal 정보를 의미합니다. 비디오는 시간이 흐름에 따라 같은 동작이어도 전 후의 동작에 따라 의미가 달라질 수 있기에 temporal 정보가 중요합니다. 따라서 저자는 spatio-temporal features를 3D ConvNet을 활용하여 학습한 모델을 제안합니다. 저자는 경험적으로 learned features에 간단한 linear classifier를 사용하는 것 만으로도 성능을 뜰어올릴 수 있고, 저자가 제안하는 C3D가 여러 비디오 task에서 적합하다고 소개합니다. 이를 3줄 요약하면
- 비디오에서는 3D convolution을 활용한 모델이 appearance, motion 모두 잘 학습합니다.
- 3x3x3 convolution kernel을 모든 layer에 적용하는 것이 가장 효율적이라는 것을 실험적으로 증명합니다.
- 위의 이유로 C3D에 단순한 linear classifier를 사용하는 것으로 당시의 SOTA를 달성했습니다.

Learning Features with 3D ConvNets
3D ConvNet은 2D ConvNet이 담을 수 없는 temporal 정보들을 담을 수 있습니다.
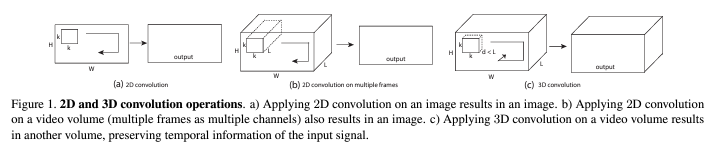
저자는 2D ConvNet에서의 3×3 convolutional kernels를 활용하여 깊게 쌓은 모델의 성능이 더 좋다는 것에 영감을 받아 3D에서도 3×3을 유지했다고 밝힙니다. 아마 2015년의 논문이니 VGG의 영향을 받은 것으로 보입니다.
일반적으로 비디오에서 video clip size는 c*l*h*w로 표현하고 c, l, w, h는 각각 채널의 수, frames의 길이, 넓이, 높이를 뜻합니다. kernel size는 d*k*k로 표현하고 d는 kernel temporal depth, k는 kernel spatial size를 의미합니다.
비디오의 데이터셋인 UCF101은 101개의 class를 갖는 비디오를 분류하는 데이터셋입니다. 모든 비디오들은 128×171로 resize가 되고 16-frame clip을 나누고 학습시에는 3x16x112x112로 random crop합니다. 구체적인 implementation으로는 5개의 convolution, 5개의 pooling, 2개의 fc layer로 구성되어있습니다. 확실히 2015년 논문인지라 간단한 구조로 구성되어있습니다.
Varying network architectures
저자는 temporal information을 가장 집합하는 최적의 kernel size가 몇 인지를 실험을 통해 제시했습니다. 위의 implementation 설정을 유지하고 3×3으로 크기를 고정한 채 kernel의 temporal depth만 바꿔가며 실험을 진행했고 두 가지의 architecture로 실험했습니다.
- homogeneous temporal depth: 모든 convolution layers가 같은 kernel temporal depth를 가집니다.
- varying temporal depth: kernel temporal depth가 convolution layers마다 바뀝니다.
1번의 경우에는 kernel temporal depth를 1, 3, 5, 7로 설정하여 실험하였고, 2번의 경우에는 kernel temporal depth가 점점 커지는 increasing과 점점 작아지는 decreasing으로 각각 3-3-5-5-7, 7-5-5-3-3으로 두가지로 나누어 실험하였습니다.
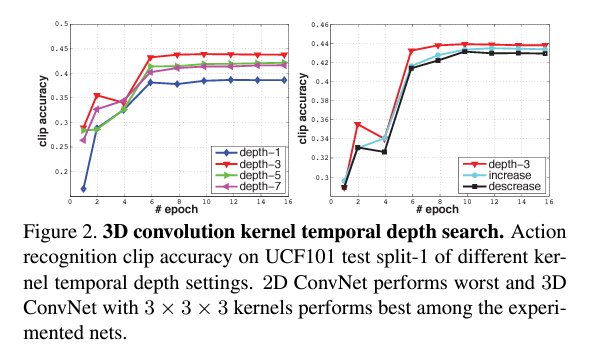
위의 그래프가 실험결과를 나타냅니다.
depth-1 즉 kernel temporal depth를 1로 고정한 경우에느 temporal depth정보를 온전히 담지 못하여 다른 architecture에 비해 낮은 accuracy를 보여줍니다. 실험결과에 따르면 기존의 2D convolution에서 좋은 성능을 보여준 3×3 kernel size와 마찬가지로 3x3x3의 3D kernel size가 가장 좋은 결과를 보이는 것을 확인할 수 있습니다.

kernel size가 3x3x3이 3D ConvNet에 있어 최선의 옵션이었다는 것을 저자가 실험을 통해 알아낸 후에 모델의 구조를 위의 사진과 같이 구성합니다. 총 8개의 convolution, 5개의 max-pooling, 2개의 fully connected layers로 구성하고 softmax를 취하는 기본적인 convolution 구조를 3D로 구성했습니다. 이때의 C3D는 3x3x3 filters, 1x1x1 stride로 convolution, 2x2x2, 2x2x2stride로 pooling(첫 pooling layer는 1x2x2, 1x2x2)으로 구성했습니다.
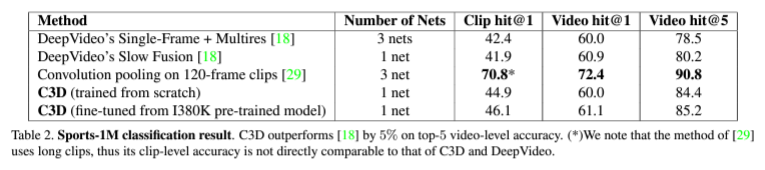
데이터셋은 2015년 당시 가장 큰 분류 데이터셋이었던 Sport-1M 데이터셋을 사용하였고 이 데이터셋은 스포츠 모션을 분류하는 비디오 클립들로 구성되어있습니다. 학습할 때에는 랜덤하게 5개의 2초 길이의 영상을 추출하여 사용했고, 128×171를 16x112x112의 size로 random crop하여 16개의 frame으로 구성한 클립으로 학습했습니다. 데이터증강으로는 horizontal flip를 사용했고 결과는 다음과 같습니다.
밑은 실제 C3D모델을 이용하여 학습한 피쳐맵을 시각화한 결과입니다.
Experiments
Action Recognition
Action Recognition은 동작을 담고있는 비디오가 주어졌을때 그 비디오의 동작을 분류하는 task로 accuracy를 evaluation metric으로 활용하는 task입니다. image classification과 비슷하지만 이어지는 동작이 있는 영상을 분류한다는 점이 다릅니다.
밑의 표는 Sports-1M 데이터셋을 통해 사전학습된 C3D모델을 불러와서 UCF-101에 대해 fine-tuning한 결과입니다. baseline으로 imagenet에 대해 사전학습된 모델과 iDT가 있는데 여기서 iDT는 improved dense trajectories라는 이름의 당시 sota였던 hand-crafted features라고 논문에서 알려줍니다. linearSVM을 활용한 방법론을 baseline으로 잡은 것이 신기하네요. 추가로 imagenet에도 linearSVM이 baseline으로 설정되어있는데 논문에서도 hand-crafted features라고 표현한 것으로 보아 비디오 task에서의 연구가 활발하기 전이라 처음으로 전통적인 기계학습의 정확도를 넘긴 딥러닝 기반 방법론이 C3D이기에 비교군이 기계학습의 방법론이었던 것 같습니다.
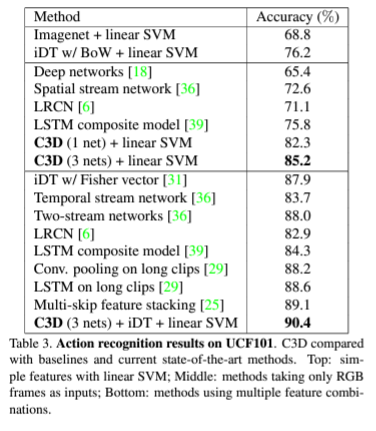
C3D의 fully-connected layer에서 4096차원의 linear layer를 활용하여 저자는 82.3%의 성능을 이뤄냈고, linear layer의 수를 3개로 늘려 12288차원으로 늘린 후 85.2%의 정확도를, 3개의 linear layers와 iDT를 같이 사용하여 90.4%의 성능을 달성하여 당시 sota를 달성했습니다.
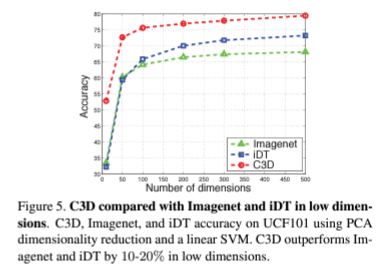
iDT와 imagenet에서 사전학습된 모델과 C3D의 성능을 비교하는 그래프입니다. 확실히 temporal 정보가 없는 imagenet에서 사전학습된 모델의 성능이 가장 낮고 3D convolution을 활용한 C3D의 성능이 월등히 좋은 것을 확인할 수 있습니다.

위의 사진은 imagenet로 얻은 feature와 C3D의 feature를 임베딩한 embedding space를 시각화한 사진으로 imagenet에서의 사전학습보다 C3D가 feature들이 잘 모여 군집화되어있는 것을 정성적으로도 확인할 수 있습니다.
Action Similarity
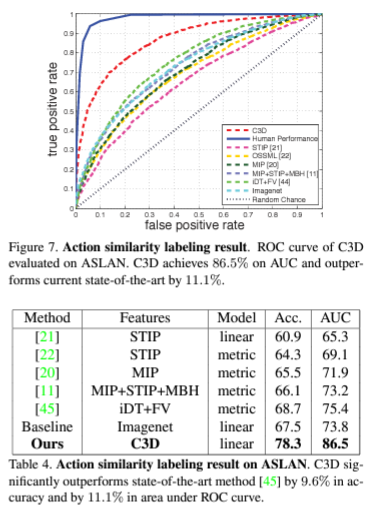
action similarity라는 task는 비디오 쌍이 주어지고 주어진 비디오 쌍이 같은 행동인지 다른 행동인지를 예측하는 task입니다. 위의 action recognition과는 다르게 행동의 유사성을 예측하는 것에 초점을 맞추고 있습니다.
ASLAN 데이터셋을 사용했으며 ASLAN 데이터셋은 432개의 동작 클래스에서 나온 3631개의 비디오로 구성되어있습니다. ASLAN 데이터셋의 구성상 훈련셋에서 본적이 없는 동작이 나오기 때문에 꽤 난이도가 있다고 언급하고 있습니다.
action recognition에서의 결과와 마찬가지로 Action Similarity task에서도 C3D의 성능이 제일 좋은 것을 확인 할 수 있습니다.
위의 두 task이외에도 scene and object recognition task에서도 C3D가 SOTA를 달성했음을 논문에서 밝히고 있습니다.
Runtime Analysis
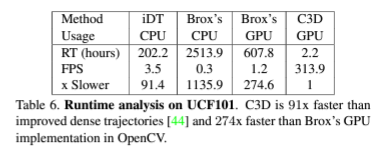
3D convolution은 메커니즘 상 연산량이 많을 수 밖에 없습니다. 2D convolution에서 한 차원이 추가되어 temporal 정보도 다루기 때문입니다. 저자는 이에 실행시간을 비교하여 C3D가 실행속도면에서도 강점을 지닌다는 것을 실험을 통해 보여주고 있습니다. 확실히 딥러닝기반의 방법론이기에 기계학습보다 훨씬 더 빠른 연산속도를 보여줍니다.
Conclusion
C3D는 3d convolution을 활용한 딥러닝 기반의 방법론으로 3d convolution을 비디오 task에 활용한 첫 논문입니다. 단순히 3d convolution을 적용하는 것이 아니라 최적의 kernel size를 찾기 위한 연구도 보여주며 2D보다 좋은 성능을 보여준다는 것을 증명하여 비디오에서 3D convolution의 가능성을 제시했고 이후 연구들이 temporal 정보를 담기 위해 3d convolution이 자주 활용되고 이후 연구들의 baseline이 되는 모델입니다.
비디오를 공부하면 빠트릴 수 없는 근본논문(?)으로 정적인 이미지가 아닌 이어지는 동작이 있는 비디오에서 3d convolution의 강력함을 알려주는 논문인 것 같습니다. 다음 리뷰에서는 C3D 이후에 발전한 모델을 다뤄보겠습니다. 리뷰 읽어주셔서 감사합니다.
안녕하세요, 박성준 연구원님. 좋은 리뷰 감사합니다.
video backbone에 대한 follow-up 차원으로 정리해주신 듯 한데, 마침 저도 video backbone 이해에 대한 필요성을 느끼고 있어서 재밌게 읽었습니다. 확실히 9년 전 논문이라 그런지 기계학습 기법들이 baseline으로 비교된 게 눈에 띄네요. 이후에 R(2+1)D, I3D, S3D 등 굵직한 방법론에 대해서도 자세한 리뷰 기대하겠습니다. 질문 몇 가지 남기겠습니다.
1. UCF101에 대해 설명하실 때 모든 video를 128×181로 resize한다고 하셨는데 H와 W를 의미하는것인가요? 그리고 Sport-1M에서는 128×171를 16x112x112로 random crop한다고 하셨는데 16x112x112은 l,w,h를 나타내는 것인가요? frame radom crop은 구체적으로 어떻게 하는 건가요?
2. Figure 5에 대한 설명에서 ImageNet 사전학습 모델과 비교하는데, image data인 imagenet을 이용해 어떻게 video model을 사전학습 하는 것인가요?
3. Figure 7에서 Action similarity labeling 실험에 대해서는 AUC로 성능을 나타내는데, 그럼 2개의 C3D 모델에 각각 이미지를 넣어서 같은/다른 label로 분류되는지를 측정하는 것인가요?
4. scene and object recognition task는 어떤 task인가요?
감사합니다.
재연님 좋은 답변 감사합니다.
1. 네 맞습니다. 128×171로 resize는 height와 weight를 의미합니다. 논문에서 UCF101의 resolution인 320×240의 거의 절반이라는 언급이 있는데 구체적으로 왜 128과 171이라는 숫자인지에 대한 설명은 없어 이유는 파악하지 못했습니다. Sport-1M의 데이터셋에서의 16x112x112로 random crop은 l, w, h가 맞습니다. 이때 l은 영상 클립의 길이로 16프레임 길이의 영상으로 전처리하는 것을 의미합니다. C3D의 경우 영상을 겹치는 부분없이 순서대로 16프레임 단위로 나누어서 모델의 인풋으로 활용합니다. Random crop은 프레임 단위로는 진행하지 않고 h,w에 대해서만 진행합니다. 본문에서 이에 대한 설명이 부족했네요.
2. 3D convolution을 처음 제안하는 논문이다보니 ImageNet에 사전학습된 모델을 비교군으로 삼은 것으로 생각됩니다. ImageNet에 사전학습 된 모델은 Table 3에서의 baseline으로 설정된 모델과 같은 모델로 temporal information을 담고 있지 않고 당시에 사용되는 프레임워크인 Caffe에서 제공하는 ImageNet 사전학습 모델의 fc6 feature를 각 프레임별로 추출하고 평균화하여 비디오 서술자를 만들고 다중 클래스 SVM을 사용하여 분류한 성능입니다.
3. Action Similarity Labeling은 하나의 모델에 비디오쌍을 입력으로 받아서 두 비디오에의 행동이 같은 행동인지 다른 행동인지를 분류하는 이진분류 task입니다.
4. Scene and Object Recognition은 논문에서 Scene Recognition과 Object Recognition을 합쳐서 부른 말로 두개의 태스크입니다. Scene Recognition은 장면의 전반적인 내용에 대한 설명(beach, bedroom 등)을 제공하는 태스크이고 Object Recognition은 장면의 물체를 식별하는 과제(cat, dog 등)로 장면 내에 무엇이 있는지를 제공하는 태스크입니다.
안녕하세요. 박성준 연구원님.
좋은 리뷰 감사합니다.
C3D 논문은 저도 읽어보지 않아서 자세한 내용은 몰랐는데, 정리를 잘 해주셔서 이 기회에 잘 들여다본 것 같습니다. 궁굼한 점과 질문드리고 싶은 점이 있습니다.
논문에서 영상 하나에서 2초 길이의 영상 5개를 추출하여 학습했다고 하셨는데, 그렇다면 영상 하나가 적어도 10초 이상의 길이를 가질 것으로 생각되는데 그렇다면 10초 이상 중 2초의 영상만을 가지고 action recognition을 진행하는 건가요?
그리고 만약 보고자 하는 영상의 길이가 2초가 아니라 30초 이상으로 길어진다면, 프레임 추출과 모델 구조를 어떤 방식으로 수정하는 것이 좋을까요?
감사합니다.
지오님 좋은 답변 감사합니다.
제가 본문에서 사전학습을 통해 얻은 descriptors를 어떻게 Action Recognition에 활용하는 지에 대한 설명이 부족했던 것 같습니다.
Sports-1M 데이터셋에 대해 사전학습을 진행할 때에는 2초 길이의 영상을 5개 추출하여 학습하고, 사전학습 이후에 inference시에는 8프레임이 중첩되게 16프레임 단위로 나누어 C3D 네트워크를 거치며 fc6 activation값을 추출합니다. Fc6 계층은 4096차원의 벡터로 동영상의 특징을 나타내며 L2정규화하여 클립을 표현하는 효율적인 특징 벡터를 만듭니다. 이렇게 생성된 여러 descriptors를 multi-class linear SVM을 통하여 분류합니다.
따라서, 영상의 길이가 30초 이상으로 길어진다면 영상을 나타내는 descriptors의 수가 많아지는 차이가 생기지만, 모델 구조에 변화를 줄 필요는 없을 것이라 생각됩니다.
안녕하세요 성준님 좋은 리뷰 감사합니다~
본문에서 video descriptor가 가져야할 특성을 설명해 주신 부분에서 질문이 있는데 decriptor가 compact 해야하는 이유와 compact 하다는 것은 어떤 의미인지가 궁금합니다. 제 생각으로는 정보들이 많기 때문에 적은 메모리를 사용해서 데이터를 저장하고 전송하기 위함이거나, 빠른 처리 속도를 가지기 위해서 compact한 decriptor를 사용하는 것 같은데 혹시 다른 이유가 있나요??
또한 decriptor가 compact하면 보통의 decriptor와 어떤 차이가 있을까요? dimension의 수가 그저 감소한 형태인가요?
감사합니다!
의철님 좋은 답변 감사합니다.
첫 질문은 의철님이 언급해주신대로 논문에서 compact한 descriptor는 비디오의 처리, 저장, 검색을 하는데에 있어 도움을 준다고 언급합니다. compact하다는 것은 논문에서의 특별한 언급은 없지만 모델의 descriptor가 쓸데없는 정보 없이 중요한 정보만을 담는 것으로 이해하면 될 것 같습니다.
두번째 질문에 대해서는 Dimension의 수가 감소한 형태 맞습니다. 실제로 논문에서 dimension은 10으로 낮춰도 나쁘지 않은 성능을 보여준다는 것을 언급하고 있습니다.