안녕하세요, 스무번째 x-review 입니다. 이번 논문은 2022년도 WACV에 게재된 RGB 기반 3D Object Detection 논문 입니다. 정말 오랜만에 3D detection 논문을 읽어봤는데요, 이전과 다르게 오로지 RGB만을 입력으로 활용하는 방법론 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
RGB 영상 정보는 모두 아시다시피 가장 보편적으로 사용되는 데이터인데요, 3D 관점에서 보았을 때 물체나 scene에 대한 시각적인 정보를 제공할 순 있지만 물체의 정확한 크기와 같은 기하학적인 정보를 제공할 수 없습니다. 또한 단일 RGB 이미지에서는 촬영한 카메라의 위치에서 보이지 않는 영역이라면 그 영역에 대해서는 어떠한 정보도 얻을 수가 없죠. 그렇다면 동일한 scene에 대해서 여러 위치에서 촬영한 RGB 이미지를 사용한다면, 즉 멀티뷰로 촬영을 하게 되면 단일 이미지에 비해서 scene에 대한 정보를 확실히 더 많이 제공받게 됩니다. 그래서 몇몇 3D Object Detection 연구에서는 멀티뷰로 인퍼런스를 하고 있는데요, 단일 RGB 이미지를 독립적으로 예측한 다음에 각 예측을 합치게 됩니다. 본 논문에서는 여기서 더 나아가서 멀티뷰 이미지를 인퍼런스 뿐만 아니라 학습 입력 데이터로 사용하고자 합니다. 멀티뷰 입력으로 취급되지만 특이하게 하나의 이미지만 입력으로 들어가는 것까지 가능하며 이는 단안 벤치마크에서도 잘 작동함을 보여준다고 합니다.
이렇게 오로지 RGB만을 사용하는 3D Object Detection은 일반적으로 포인트 클라우드를 사용하는 3D Object Detection과 마찬가지로 indoor와 outdoor로 구분할 수 있습니다. indoor와 outdoor 환경에서 3D detection에 접근하는 기준은 아무래도 검출해야 하는 물체가 되는데요, 예를 들어 outdoor에서는 주로 검출되는 물체가 자동차이겠죠. outdoor 데이터셋에서 검출해야하는 자동차는 차종이 다르다고 하더라도 일반적으로 크기가 비슷하고 땅 위에 위치해 있기 때문에 이를 BEV로 사영시켰을 때 자동차끼리 겹쳐서 보이지 않는 경우가 없습니다. 그래서 자동차의 정확한 3차원 위치를 알기 위해서 BEV로 사영시키는 것이 훨씬 더 많은 정보를 제공받을 수 있습니다. 그렇기 때문에 많은 outdoor 3D detection에서는 포인트 클라우드가 아니라 BEV 평면에서의 2D detection이 진행되고 있습니다. 반면에 indoor 환경에서의 물체는 outdoor와는 조건이 꽤나 다른데요, 침대나 옷장과 같이 큰 물체부터 시작해서 화병이나 컵과 같은 작은 물체까지 크기가 매우 다양합니다. 또한 물체의 배치 테이블 위에 컵이 놓여있거나 물체들끼리 수직으로 겹쳐져 있는 경우에는 사영하였을 때 손실되는 정보가 많아 outdoor 환경처럼 BEV 평면에 사영하는 것이 적절하지 않습니다. 그래서 RGB 기반의 3D Object Detection은 보통 outdoor/indoor로 나누어진 도메인에 특정된 경향이 있습니다. 본 논문에서는 이러한 경향성에 따라 outdoor/indoor를 따로 처리할 수 있는 각각의 head를 만들어 두 도메인에서 모두 동작할 수 있는 구조를 설계하였습니다.
여기서 본 논문의 mian contribution을 정리하면 다음과 같습니다.
- 처음으로 RGB 이미지 기반 멀티뷰 3D Object Detection을 위한 end-to-end 학습
- 단일과 멀티뷰 입력에서 모두 동작할 수 있는 새로운 3D Object Detector 제안
- indoor와 outdoor 도메인을 고려한 개별적인 head를 통해 두 도메인의 데이
- 터셋에서 모두 SOTA 달성
2. Related Works
3. Proposed Method
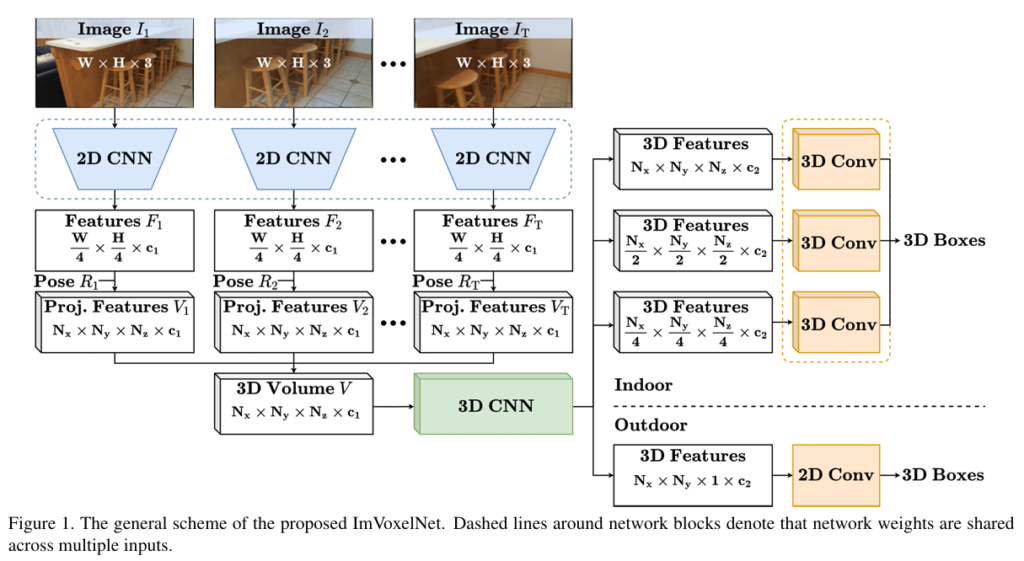
본 논문의 방법론은 카메라 포즈와 함께 임의의 뷰에서 촬영된 RGB 이미지를 입력으로 넣을 수 있습니다. 이미지가 입력으로 들어오면 우선 사전학습된 2D backbone으로 feature을 추출하게 됩니다. 얻은 feature을 앞서 introduction에서 언급하였듯이 3D 복에서 최종 예측을 하기 위해 pose를 사용해서 사영하게 됩니다. 사영된 feature들로 만들어진 각각의 복셀 볼륨을 단순 element-wise하여 합치게 되고 합쳐진 최종 볼륨을 3D convolution 네트워크로 구성된 neck으로 전달합니다. neck을 통과한 출력값은 head의 입력값으로 들어가서 각 anchor에 대한 바운딩 박스를 예측하게 되겠죠. 예측 결과인 바운딩 박스는 (x,y,z,w,h,l,\theta) 총 7개의 파라미터로 구성되는데, 그 중 (x,y,z)는 3차원 박스의 중심 좌표이며 (w,h,l)은 각각 width, height, length를 의미합니다. 마지막으로 \theta는 z축으로의 회전 각도를 뜻합니다. 여기까지가 Figure1에서 확인할 수 있듯이 논문이 제안하는 구조의 전체적인 파이프라인 입니다. 2D feature 추출과 3D neck 네트워크까지는 이전에 존재하는 방법론을 사용하였고 새롭게 제시하는 구조는 indoor에서의 detection을 위한 멀티 스케일 3D head 구조를 설계하였다고 합니다.
3.1. 3D Volume Construction
우선 3D 볼륨을 형성하는 과정에 대해 살펴보겠습니다. 전체 입력 이미지셋이 T일 때 t번째 이미지를 I_t \in \mathbb{R}^{W \times H \times 3}라고 정의하고(T가 1보다 크면 멀티뷰 입력, 1이면 싱글 뷰 입력 입니다) 사전학습된 2D 백본에 입력 이미지를 통과시키면 2D feature을 추출할 수 있죠. 출력값으로 나오는 4개의 feature map shape은 \frac{W}{4} \times \frac{H}{4} \times c_0, \frac{W}{8} \times \frac{H}{8} \times 2c_0, \frac{W}{16} \times \frac{H}{16} \times 4c_0, 그리고 \frac{W}{32} \times \frac{H}{32} \times 8c_0 입니다. 이렇게 추출한 4개의 feature map을 FPN을 통해 합치게 되는데 합친 feature map F_t의 shape은 \frac{W}{4} \times \frac{H}{4} \times c_1으로 표현할 수 있고 c_0과 c_1은 백본 네트워크에 따라 달라질 수 있다고 합니다.
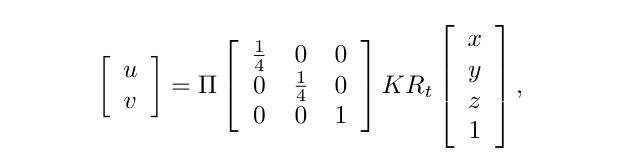
만약에 전체 이미지셋 중에서 t번째 입력에 대한 feature map F_t를 사영한 3D 복셀 볼륨을 V_t \in \mathbb{R}^{N_x \times N_y \times N_z \times c_1}이라고 정의해보겠습니다. 각 데이터에서 x,y,z축에 대한 공간 범위가 존재하게 되므로 이러한 범위를 x_{min}, x_{max}, y_{min}, y_{max}, z_{min}, z_{max}로 표시하겠습니다. 고정된 복셀 사이즈(s)의 경우 공간적 범위를 N_xs = x_{max} - x_{min}, N_ys = y_{max} - y_{min} 그리고 N_zs = z_{max} - z_{min}으로 표현할 수 있습니다. 핀홀 카메라 모델을 사용해서 feature map F_t의 2D 좌표 (u, v)와 볼륨 V_t의 3D 좌표 사이의 대응 관계를 위의 식과 같이 형성할 수 있습니다. K와 R_t는 많은 분들이 아시다시피 카메라의 내,외부 파라미터를 의미하고 \Pi는 perspective mapping을 의미합니다. 이렇게 좌표를 사영하고 나면 일단은 모든 복셀 그리드에 동일한 feature가 채워져 있습니다.
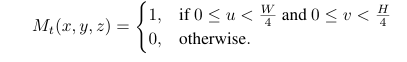
여기서 V_t와 동일한 shape의 이진 마스크 M_t를 정의해서 각 복셀 그리드가 카메라 frustum 내에 위치하는지를 판단할 수 있습니다.
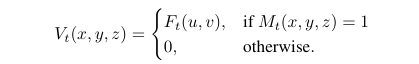
카메라 frustum 내의 위치에 대해서만 볼륨 V_t에 대응되는 F_t의 유효한 값을 채워넣습니다.
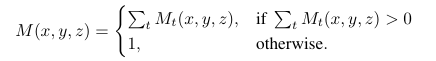
그럼 모든 이미지에서의 이진 마스크 M (M_1, . . . , M_t의 합)을 구할 수 있습니다.
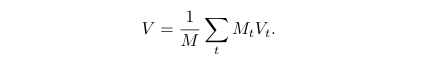
마지막으로 사영된 feature들로 채워넣어진 모든 이미지에서 각각의 볼륨 V_1, . . . , V_t을 만들 수 있고 이를 평균낸 것이 바로 최종 3D 볼륨인 V가 됩니다.
3.2. 3D Feature Extraction
이제부터 indoor, outdoor 관점으로 나뉘어서 방법론이 서술되는데 아무래도 저는 indoor에서의 3D Object Detection을 진행할 예정이기 때문에 indoor에 초점을 맞추어 적어보도록 하겠습니다. 앞서 간략한 파이프라인 설명에서 이야기하였듯이 형성된 복셀 볼륨 V는 feature을 refine하기 위해서 인코더-디코더 구조의 3D convolution 네트워크인 neck의 입력으로 들어가게 됩니다. 이는 이전에 존재하던 구조를 사용하고 있는데 기존의 구조는 48개의 3D convolution 레이어로 구성되어 높은 계산 비용과 inference 속도가 느리다는 단점이 존재합니다. 본 논문에서는 3D convolution 레이어의 수를 줄임으로써 기존의 단점을 보완하고자 하였습니다. 인코더는 딱 3개의 다운샘플링 잔차 블럭과 각각의 3D 컨볼루션 레이어로 구성하였으며 디코더 역시 3개의 업샘플링 블럭으로 구성되어 있는데 이는 transposed 3D 컨볼루션 레이어와 또 다른 3D 컨볼루션 레이어로 구성되어 있습니다. 이러한 neck 네트워크는 각각 \frac{N_x}{4} \times \frac{N_x}{4} \times \frac{N_z}{4} \times c_2, \frac{N_x}{2} \times \frac{N_x}{2} \times \frac{N_z}{2} \times c_2, 그리고 N_x \times N_y \times N_z \times c_2 shape을 가진 3개의 feature map을 출력합니다.
3.3. Detection Heads
ImVoxelNet은 입력을 RGB 이미지로 받지만 이를 3D 복셀 공간으로 표현하면서 결국에는 포인트 클라우드 기반의 3D Object Detection 방법론과 동일한 head를 사용할 수 있는 조건을 만족하게 됩니다. 따라서 저자는 해당 방법론에 특화된 어떠한 구조를 새롭게 만들어야 되는 것이 아닌 기존의 SOTA 방법론에서의 모듈을 그대로 사용할 수 있다고 이야기하네요.
3.3.1 Indoor Head
당시 모든 indoor 기반 3D Object Detection 방법론은 sparse하게 제공되는 포인트 클라우드를 사용하기 위해서 deep Hough voting을 활용하였습니다. 하지만 이는 raw한 포인트 클라우드 자체를 입력으로 사용할 때의 이야기이고, 본 논문에서는 앞에서 다루었다 싶이 복셀 기반의 표현 방법을 선택하였습니다. dense한 3D 멀티 스케일의 head를 설계한 것이 3D Object Detection task에서는 ImVoxelNet이 최초였다고 하네요. 설계한 head는 2D detection에서 FCOS라는 방법론에 영감을 받았는데, 기존의 FCOS head는 FPN을 거쳐 feature를 추출해서 2D 컨볼루션 레이어를 통해 바운딩 박스를 예측할텐데 이를 3D detection에 적용하기 위해서 컨볼루션 레이어를 3D로 변경하였습니다. 또한 물체가 있을법한 위치에 대해 후보를 선정하기 위해서 center 샘플링을 적용하였습니다. 이 과정에서 기존 2D에서는 총 9개의 후보(3 \times 3)가 선택이 되는데, 3차원으로 넘어오면서 물체당 총 27개의 후보가 만들어집니다. head는 이러한 centerness를 포함해서 classification, location을 예측하기 위한 총 3개의 3D 컨볼루션 레이어로 구성되어 있습니다.
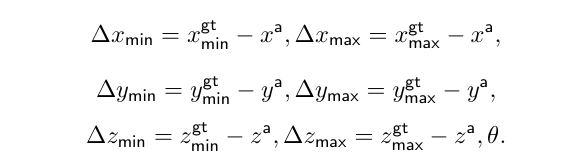
결국 입력으로는 앞선 neck의 출력으로 나온 \frac{N_x}{4} \times \frac{N_x}{4} \times \frac{N_z}{4} \times c_2, \frac{N_x}{2} \times \frac{N_x}{2} \times \frac{N_z}{2} \times c_2, 그리고 N_x \times N_y \times N_z \times c_2이 들어오고 출력으로 각 3차원 위치((x^a, y^a, z^a)에 대해서 classification 확률 p와 centerness c, 그리고 예측한 3차원 바운딩 박스까지 head에서 예측하게 됩니다.
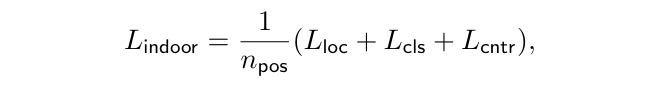
Loss 역시 기존 FCOS의 loss 함수를 적용하는데, classification에 대한 L_{cls}는 focal loss를 사용합니다. 그리고 centerness L_{cntr}은 cross entropy loss를, L_{loc}는 IoU loss로 계산합니다. 3D detection task에 이용하기 위해서 2D IoU 대신 3D IoU loss를 사용하였다고 합니다. 또한 GT의 중심점을 3차원으로 업데이트 하였고 마지막 n_{pos}는 3차원 positive에 속하는 location의 개수를 의미합니다.
3.4. Extra 2D Head
일부 indoor 벤치마크에서 3D Object Detection은 scene undersatnding의 하위 task로 구분됩니다. 이에 따라 평가 프로토콜이 3차원 바운딩 박스만 예측하는 것이 아니라 scene understanding task와 관련된 카메라의 회전과 공간 배치(room layout)까지 예측해야 합니다. 그래서 추가적으로 R_t와 3D 레이아웃 추정을 위한 헤드를 추가하게 되는데요, 이러한 헤드는 두 개의 병렬적인 브랜치로 구성되어 fc layer 두개는 room 레이아웃을 출력하고 또 다른 두개의 fc layer는 카메라 회전을 추정합니다. 해당 헤드의 입력으로는 백본 네트워크 출력 결과의 글로벌 average 풀링을 통한 8c_0 shape의 단일 텐서가 주어집니다.
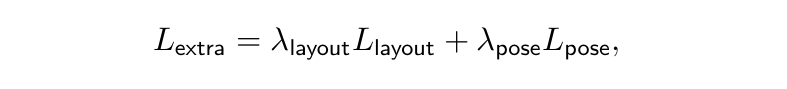
헤드는 카메라 포즈를 pitch, roll로 출력하고 3차원 레이아웃 박스를 7개의 바운딩 박스 파라미터로 출력합니다. 해당 부분의 loss 역시 이전부터 사용하는 loss로 수정하여 이전에 detection head에서 학습하기 위해 사용하던 loss와 일치시키도록 합니다.
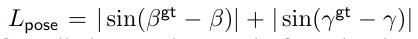
따라서 레이아웃 L_{layout}는 예측된 레이아웃 박스와 GT 레이아웃 박스 사이의 회전된 3D IoU loss로 정의하며 이는 2.3.2에서 사용하는것도 동일합니다.
4. Experiments

indoor 기반 데이터셋은 SUN RGB-D와 ScanNet을 사용하였는데, 그 중 Table 4는 SUN RGB-D에 대한 실험 결과 입니다. NYU-37이라는 데이터셋의 물체를 포함하는 T3DU라는 당시 가장 최근의 단안 벤치마크와 본 논문이 제안하는 ImVoxelNet을 비교하고 있습니다. 선정한 벤치마크가 카메라 포즈와 레이아웃을 추정하기 때문에 훈련 과정에서 extra head인 L_{indoor}+L_{extra}를 최적화 해야 합니다. Table 4는 mAP가 이전의 방법론들 대비 18% 이상의 차이를 보이고 레이아웃과 카메라 포즈 추정에서 역시 T3DU보다 높은 성능을 보이는 것을 확인할 수 있습니다.


다음으로 Table 5는 또 다른 데이터셋인 ScanNet에서의 실험 결과 입니다. 학습 과정에서는 한 scene당 T = 50개로 구성된 이미지를 사용하며 scene당 최적의 테스트 이미지 수를 찾기 위해서 ablation study까지 Table 6과 같이 진행하였습니다. 각 테스트 이미지 개수를 5번에 나누어 설정하였을 때 테스트 이미지ㅇ가 많을 수록 더 나은 결과를 보이고 있습니다. 모델 파이프라인에서 가장 시간이 많이 걸리는 부분이 3D 컨볼루션으로 복셀 볼륨을 처리하는 부분이고 2D feature을 추출하는 부분은 약간의 overhead가 발생하고 있습니다. 따라서 scene당 테스트 이미지의 수가 증가함에 따라 시간이 비선형적으로 증가하게 됩니다. Table 5에서 볼 수 있듯이 ImVoxelNet은 포인트 클라우드를 사용하지 않음에도 불구하고 높은 성능을 보여줍니다. 특히나 RGB 이미지를 추가적인 모달리티로 사용하여 복셀 볼륨을 표현하는 포인트 클라우드 기반의 모델인 3D-SIS보다 좋은 결과를 보여주고 있습니다.


마지막으로 각각의 데이터셋에서의 예측 바운딩 박스를 시각화한 정성적 결과를 보여주며 리뷰 마치도록 하겠습니다.
안녕하세요, 좋은 리뷰 감사합니다.
멀티뷰에서의 3D detection을 수행하는 연구를 이번 리뷰를 통해 알게되었네요.
간단한 질문 2가지만 드립니다.
1. 멀티뷰 관점에서 3D detection을 수행하는 것은 결국 depth를 사용하지 않게 되는데 해당 논문에서는 RGB-D 기반으로 다루어진 데이터셋에 대한 문제점을 제기한다는 그런 내용이 있는지 궁금하네요.
2. indoor와 outdoor에 대해 다른 아키텍처를 사용하는 이유가 어떤 건지 궁금합니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. 아니요 RGB-D 기반으로 다루어진 데이터셋에 대한 문제점을 제기한건 아니고 기존에 RGB로만 진행하던 3D detection의 한계점을 해결하기 위해서 본 논문의 방법론을 제안한 것 입니다.
2. introduction에서도 언급하였듯이 indoor와 outdoor 환경에서 검출해야하는 물체의 특성이 매우 다르기 때문에 이를 고려하여 각 환경에서 특화된 head를 설계하고자 하였습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
물체가 있을법한 위치에 대해 후보를 선정하기 위해서 center 샘플링을 적용한다고 하셨는데, 이러한 방식이 기존 3D Obejct Detection 방법론에서 deep hough voting과 어떤 점이 다른가요?? raw한 데이터를 사용하는지 혹은 복셀 형태로 바꾸는지가 다르다는 것은 이해를 했는데 데이터 형태와 달리 물체가 존재할 법한 위치나 center을 추리는 과정은 비슷하다고 생각해서 이 부분에 대해 추가적인 설명 부탁드립니다 ㅎ ㅅ ㅎ
또 하나 궁금한 점은,,, head에서 예측으로 나온다는 x_min, x_max와 같은 예측 결과는 박스 파라미터와 다른 파라미터인가요 ?!?
감사합니다 !
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
사실 deep hough voting 역시 포인트 중에서 물체의 중심이 될 가능성이 높은 포인트들을 추리는 역할을 하기 때문에 centerness sampling과 크게 다르지 않습니다. 코드까지 확인을 해보아야 정확히 알 수 있습니다만 . . 포인트 자체에서가 아니라 복셀로 나뉘어진 그리드 형태에서 중심점을 샘플링하기 위한 작업이라고 이해하였습니다.
그리고 head에서 나오는 결과값인 x_min, x_max 등은 박스 파라미터인 x,y,z,w,h,l과는 다른 파라미터이며 각 복셀이 가지고 있는 축의 크기가 다른데, 그런 축의 크기를 의미하는 파라미터 입니다.
안녕하세요. 좋은 리뷰 감사합니다.
멀티뷰 이미지를 학습 데이터로 사용하는 것에서 처음에는 아무런 의문없이 읽었다가 나중에 가서 의문점이 생겼는데요. 멀티뷰 이미지라는 것은 어떻게 만들어지는 것인가요? 한 object를 정해서 그 object를 기준으로 몇도 이동, 몇도 이동 이런식으로 찍어서 생기는 것이 멀티뷰 이미지인지, 아니면 한 object에 대해서 어떤 기준 없이 여러 장면을 찍은 것을 멀티뷰 이미지라고 말하는 것인지 궁금합니다. 이 task를 이해하기에 앞서서 먼저 데이터를 이해해야 더 와닿을거 같아 질문드립니다ㅎㅎ
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
우선 멀티뷰 이미지를 찍기에 앞서 이동하는 각도까지 미리 지정을 하고 촬영을 하진 않고, 한 scene 기준으로 여러 위치에 카메라를 놓고 촬영을 한 다음 reconstruction이나 다른 작업을 수행하여 각 위치에 대한 카메라 포즈를 계산할 수 있어서 계산한 카메라 포즈로 멀티뷰 이미지를 얻을 수 있습니다.