이번 리뷰 논문은 세그멘테이션과 언어 모델에서 핫한 두 개의 파운데이션 모델 SAM과 CLIP을 하나의 모델로 병합하는 방법(model merging)을 제시하는 방법론에 해당합니다. 두 모델의 특징을 살리면서 하나의 모델로 병합으로써, 두 모델의 지식을 망각 (catastrophic forgetting) 없이 계승 받기 때문에 SOTA에 준하는 open class에서의 segmentation; Zero-shot segmentation (instance or semantic)을 달성합니다. 또한, ViT 하나의 모델로 병합하기 때문에 매우 높은 계산 효율성을 보여줍니다.
최근 파운데이션 모델들을 활용한 연구들이 많이 보이고 있고, 큰 기업에서도 해당 모델들을 어떻게 하면 다운스트림에 잘 녹일 수 있는가에 대해서 연구를 진행하고 있습니다. 추후, 저희 연구들도 어떻게 하면 파운데이션 모델을 잘 활용하여 우리의 문제를 풀어 갈지 고민해봐야 할 것 같습니다.

Intro
최근 SAM과 CLIP과 같은 vision foundation models (VFM)이 개발됨으로써, 수 많은 연구에서 VFM을 사전 학습 모델로 사용하여 확장하고 있습니다. 특히, CLIP은 의미론적인 이해에 탁월하며, SAM은 공간적인 이해 능력이 뛰어나기 때문에 관련된 다운 스트림 연구에서 활발한 활용이 되고 있죠. 대부분의 다운 스트림 연구에서는 두 모델을 독립적인 연산을 수행하여 특징 정보를 활용하기 때문에 각 모델 별로 개별적인 모델을 설계하고 운용해야 하기 때문에 비효율적이며, 두 사이의 연관 정보를 활용하기가 어렵다는 문제가 있습니다.
이러한 문제를 해결하기 위해서 multi-task learning이 존재합니다. 하지만 multi-task learning은 개발하기 위해서는 수 많은 데이터와 리소스가 요구되며, 여러 태스크에 접근이 가능해야 하는 경우도 있습니다. 또한, 파운데이션 모델들은 unsupervised or semi-supervied approachs에 의존적인 경우가 대다수라 엄청 많은 리소스를 요구합니다. (e.g. SAM ~ 1.1B masks is computationally demanding) 특히, 단일 모달인 아닌 다중 모달을 요구하는 경우에는 더욱 많은 리소스를 요구합니다.
이러한 문제점을 해소하기 위해서 model merging라는 연구 분야가 부상하기 시작했다고 합니다. 대부분의 model merging은 추가적인 학습 데이터 없이 여러 태스크의 모델들을 다중 태스크를 수행 가능한 단일 모델로 병합하는 것이 목적입니다. 예를 들어 가중치 병합(e.g. weight interpolation, parameter importance analysis 등)과 같이 추가적인 training/finetuning 없이 병합을 진행하기 때문에 모델 측에 강한 스트레스를 부여하여 성능이 저하되거나, 다양한 태스크에서 일반화가 떨어지는 결과를 보여줍니다.
해당 논문에서는 근복적으로 다른 목적, 상이한 기능 그리고 다른 모달리티에서도 서로 상호 작용이 가능하도록 VFMs을 병하는 것을 목표로 합니다. 이러한 목표에서 weight interpolation과 같이 나이브한 병합 방식들은 forgetting을 야기시키는 원인이 됩니다.
저자는 위 문제를 해결하기 위해서 continual learning (CL)과 knowledge distillation (KD)를 활용하여 training-free 병합과 멀티 태스킹 학습 사이의 차이를 메우는 것을 목표합니다. 논문에서는 복잡한 말로 설명되어져 있는데 일부 학습 데이터를 가지고 fine-tunning을 한다는 것을 설명합니다. 이를 통해 각 파운데이션 모델의 사전 지식을 망각하지 않고 병합이 가능해진다고 밝힙니다.
+ 망각(=성능저하 및 낮은 일반화)를 해결하기위해서 적은 데이터 셋을 이용해서 continual learning라는 측면에서 사전 학습 모델 중 하나를 기반으로 또 다른 모델을 병합하고 knowledge distillation를 이용해서 기존 모델의 지식을 유지한다. 라고 보면 됩니다.
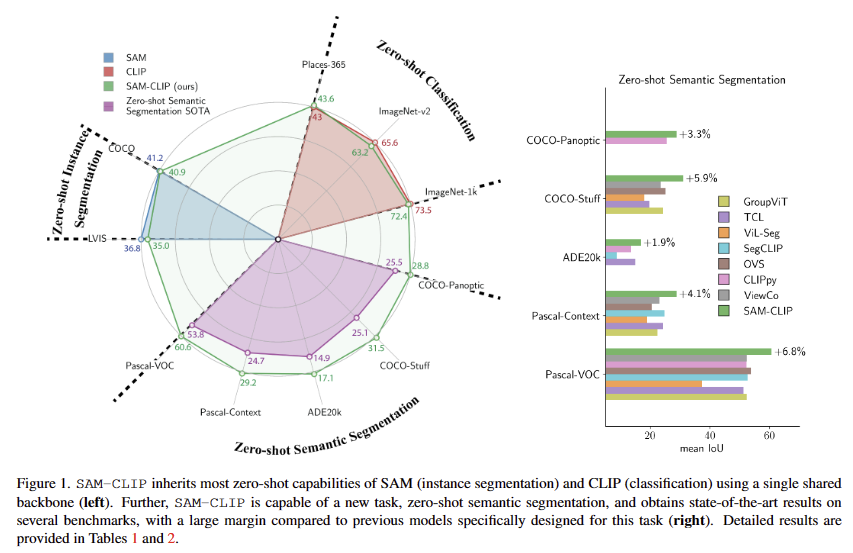
이를 통해 저자가 주장하길 제안한 프레임워크를 통해 SAM과 CLIP을 병합한 single multi-task model SAM-CLIP을 제시하며, 적은 연산량으로 엣지 디바이스에서도 활용이 가능하다고 합니다. 또한, fig 1을 통해 두 파운데이션 모델의 zero-shot capabilities (e.i. zero-shot classification and image-text retrieval from CLIP, and zero-shot instance segmentation from SAM.)을 최소한의 망각으로 계승 받았다고 합니다.
fig 1의 오른쪽과 같이 새로운 태스크인 zero-shot semantic segmentation에서 SOTA를 달성한 성능을 통해 SAM의 공간적 분석 능력과 CLIP의 의미론적 분석 능력을 적절히 병합됨을 보여줍니다.
+ 정리하면 베이스 혹은 teacher 모델인 SAM과 CLIP의 성능을 upper로 두되, 낮은 성능 하락을 보여주고 있음. 두 기능이 합쳐진 task라 볼 수 있는 zero-shot semantic segmentation에서는 SOTA를 달성함.
++ zero-shot semantic segmentation은 class까지 인지하여 같은 맥락으로 묶어야 하기 때문에 모델이 공간적, 의미론적 분석이 가능해야 합니다.
Method
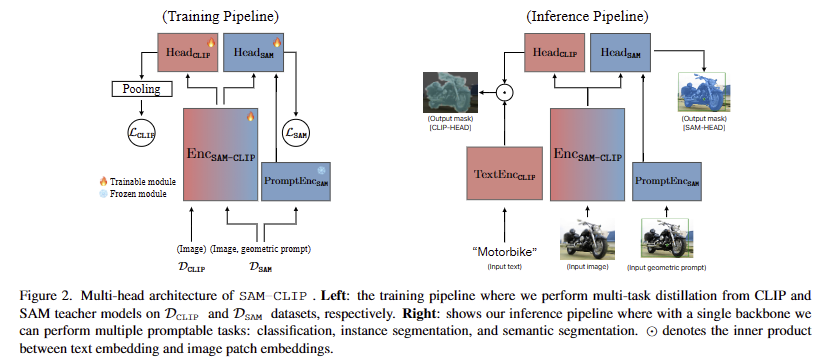
저자는 설명에 앞서서 제안하는 병합에 대해서 정의와 몇 가지 제약을 겁니다. 해당 기법에서 병합이 가능한 모델들은 영상 백본과 각 모달리티 별 백본과 다중 태스크를 수행하는 헤드/디코더를 가진 VFM이라는 전제를 둡니다. 여기서 병합의 목표는 서로 다른 모델의 영상 백본을 하나의 백본 모델로 만드는 것을 목표로 합니다.
여기서는 SAM을 base VFM, CLIP을 auxiliary VFM으로 가정하고 설명을 진행합니다. SAM을 고해상도 영상에서의 segmentation에서 탁월한 성능을 보이지만 의미론적인 이해에는 제한이 있습니다. 반대로 CLIP은 의미론적인 이해를 위한 강력한 백본의 가지고 있습니다. 그렇기에 base VFM과 auxiliary VFM를 서로 반대로 수행해도 상관 없으나, CLIP은 상대적으로 저해상도의 영상을 이용하여 사전 학습되었기 때문에 고해상도 영상에서는 비효율적인 문제가 있습니다. 그렇기에 SAM을 base VFM을 선정하여 ViT-Det 구조에 CLIP이 상속될 수 있도록 구성합니다.
저자는 모델의 memory replay로 CP를 수행하기 위해서 base VFM과 auxiliary VFM을 학습하기 위한 subset [latext] D_{SAM}, D_{CLIP} [/latex]를 구성하여 사용 가능하다는 전제를 깝니다.
fig 2에서 보이바와 같이 저자가 제안한 프레임워크에서는 base VFM인 SAM은 image encoder ( Enc_{SAM}), prompt encoder ( PromptEnc_{SAM}), light mask decoder ( MaskDec{SAM})를 가지고 있으며, auxiliary VFM인 CLIP은 image encoder ( Enc{CLIP}), a text encoder ( TextEnc{CLIP})를 가지고 있습니다. 저자의 목표는 두 image encoders Enc_{SAM}와 Enc{CLIP}를 병합하여 Enc_{SAM}로 초기화된 하나의 백본인 Enc{SAM-CLIP}을 만드는 것입니다. 또한, 각 VFM에 대응되는 lightweight heads인 MaskDec{SAM}로 초기화된 Head{SAM}, 랜덤 웨이트로 초기화된 Head{CLIP}을 이용하여 결과를 생성합니다. 추가적인 다른 모달리티 인코더 (i.e. PromptEnc_{SAM} and TextEnc_{CLIP} )은 frozen한 상태에서 사용합니다.
+ appendix에 따르면 실제로 Head{CLIP}은 SAM의 transformer head의 마지막 weight로 초기화하였다고 합니다.
베이스 병합 방법은 D_{CLIP} 을 이용하여 consine KD loss를 이용하여 아래와 같이 병합을 수행합니다.
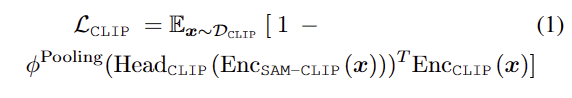
여기서 \phi^{Pooling} 로 영상 패치 레벨의 임베딩들을 Enc{CLIP}에 맞추는 역할을 수행합니다. 위 수식을 통해 teacher model인 CLIP의 encoder Enc{CLIP}을 교사로 하여 Enc{SAM-CLIP}과 Head{CLIP}을 학습이 가능합니다. 이를 통해 SAM에 CLIP의 의미론적 기능이 주입되지만 이는 큰 망각이 발생하여 치명적인 성능 하락을 보이게 됩니다.
저자는 해당 문제를 해결하기 위해서 rehearsal based multi-task distillation을 제안합니다. 이는 두가지 목표 “1) base model에서 auxiliary VFM로 지식을 효율적으로 증류하고 2) base model의 원래 기능을 보존하는 것.” 을 달성하기 위해서 2 단계의 학습 기법, head-probing과 multi-task distillation로 구성됩니다.
Head probing. 해당 스테이지에서는 수식 1을 수행하되, image backbone Enc{SAM-CLIP}을 얼리고 Head_{CLIP}만 학습 시키는 방식을 가집니다. 직관적으로 학습을 적용할 경우, 망각이 발생하는 Enc{SAM-CLIP}에 손상이 가기 전에 랜덤 초기화된 Head_{CLIP}의 초기화를 유의미하게 바꾸는 것을 목표로 합니다.
Multi-task distillation. 그 다음 스테이지에서는 muti-task training L_{CLIP} + \alpha L_{SAM} 을 수행하기 위해 두 헤드 Head_{SAM}과 Head_{CLIP}, image backbone Enc{SAM-CLIP}을 학습하는 것을 목표합니다.

여기서, x는 원본 영상, g는 geometric prompt, , frozen SAM teahcer의 segmentation mask score z = MaskDec_{SAM}(Enc_{SAM}(x)) 에 해당합니다. L_{FD} 는 SAM에서 사용되는 loss로 linear combination of Focal and Dice로 구성됩니다. 학습 중 D_{CLIP} 과 D_{SAM} 은 각 loss L_{CLIP} 과 L_{SAM} 에 영향을 주며 서로에게 관여하지 않습니다. 추가로 망각을 줄이기 위해서 SAM 쪽 loss에 적은 영향을 가도록 설정합니다.
Experiment
Model Architecture. 12 transformer layers로 구성된 ViT-B/16 version of the Segment Anything Model (SAM)을 base model로 사용합니다. CLIP head는 따로 없기 때문에 3 transformer layers를 추가로 구성하여 생성합니다. 그리고 CLIP head에서는 Max pooling을 통해 segmentation을 생성하도록 구성하였다고 합니다.
Dataset Preparation. D_{CLIP} 은 CLIP에서 학습한 데이터셋 중에서 일부를 샘플링하여 40.6M unlabeled images로 구성, D_{SAM} 은 11M images and 1.1B masks로 구성했다고 합니다. 구성된 데이터 셋 중 1%는 validation을 위해 사용했고 구성된 40.8M images은 Merged-41M라고 칭함.
Training. 1) Head probing. CLIP-head probing takes 20 epochs ~ the teacher model은 DataComp-1B datase에서 학습된 OpenCLIP의 ViT-L/14 사용. 2) Multi-task distillation. 16 epoch, CLIP and SAM distillation losses은 비율 1:10로 설정. SAM의 teahcer model은 SAM ViT-B로 구성. batch는 CLIP은 2048 images, SAM은 32 images로 구성.
Zero-Shot Evaluations.
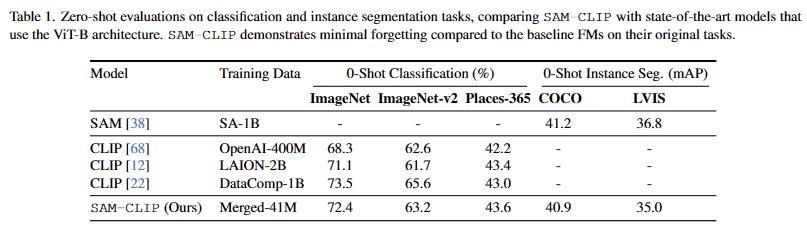
- CLIP Task: Zero-Shot Image Classification. Tab 1에서 보이는 바와 같이 최소한의 성능 저하를 보이는 것을 통해 최소한의 망각을 유지한 결과를 보여줌
- SAM Task: Zero-Shot Instance Segmentation. Tab 1에서 보이는 바와 같이 최소한의 성능 저하를 보이는 것을 통해 최소한의 망각을 유지한 결과를 보여줌
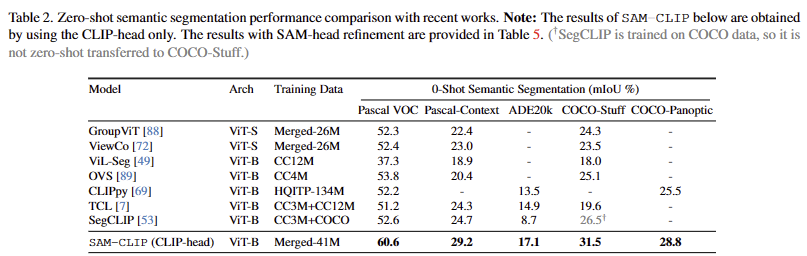
- Zero-Shot Transfer to Semantic Segmentation. Tab 2에서 보이는 바와 같이 zero-shot Semantic Segmentation task에서 SOTA를 달성함으로써, 두 모델의 특성들을 잘 융한한 것을 보임
Head-Probing Evaluations on Learned Representations.

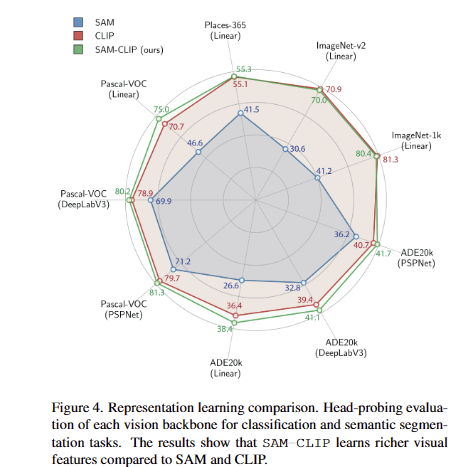
Tab 3과 Fig 4를 통해 두 파운데이션 모델의 특성을 잘 상속 받았음을 의미론적인 정보와 공간적인 정보 특생을 나타내는 두 데이터셋에서 평가를 진행함. 더 나아가 특정 head (ViT-Det의 transformer layer) 뿐만이 아니라 다양한 모델에서도 성능 향상을 보임으로써, 제시한 병합 방법에 대한 일반화 가능성을 보
추후 팀 연구 방향을 파운데이션 모델을 활용하는 방향으로 가져가야한다고 생각만 하고 논문을 안 찾아보고 있었는데… 좋은 논문들이 엄청 많이 나왔더라구요. 자주 읽을 수 있도록 노력해야겠습니다. 하하…
안녕하세요, 좋은 리뷰 감사합니다.
작년에 SAM과 CLIP을 합친 모델이 나왔었네요.실험의 결과를 보니 성능이 매우 개선된 것 같네요. 성능에 대한 figure 그래프도 저렇게 표현하는 것은 처음보네요.
간단한 질문이 하나 있습니다.
foundation model을 사용하면 파라미터 수가 많아지게되므로 바로 디바이스에 적용할 수 없어 distillation 같은 방법을 통해 파라미터 수를 줄이는 방법을 적용하여 student 모델을 사용했을 때 파라미터에 대한 정량적인 수치와 속도(FPS)에 대한 리포팅은 따로 없었는지 궁금합니다.
감사합니다.
Q. foundation model을 사용하면 파라미터 수가 많아지게 되므로 바로 디바이스에 적용할 수 없어 distillation 같은 방법을 통해 파라미터 수를 줄이는 방법을 적용하여 student 모델을 사용했을 때 파라미터에 대한 정량적인 수치와 속도(FPS)에 대한 리포팅은 따로 없었는지 궁금합니다.
A. LLM이랑 foundation model을 같은 것이라고 보신 것 같습니다. foundation model이 반드시 크지는 않습니다. 여기서 사용한 모델은 ViT-B보다 조금 더 큰 모델입니다.
흥미로운 분야의 리뷰 감사합니다 태주님.
코드적인 부분에서의 개인적인 궁금증이 있는데요,,,,
SAM, CLIP과 같은 foundation을 잘 가져와서 활용하고 싶은 저희 입장에서도 어쨌든 그들이 학습시켜 놓은 모델의 parameter를 불러와서 gpu위에다가 올려놔야 하지 않나요? 그렇게 되면 엄청나게 많은 resource가 들게 될텐데,,, 제가 이런 foundation 모델을 직접 사용해본 적이 없어서 생기는 의문점일수도 있습니다.
감사합니다.
Q. SAM, CLIP과 같은 foundation을 잘 가져와서 활용하고 싶은 저희 입장에서도 어쨌든 그들이 학습시켜 놓은 모델의 parameter를 불러와서 gpu위에다가 올려놔야 하지 않나요? 그렇게 되면 엄청나게 많은 resource가 들게 될텐데,,, 제가 이런 foundation 모델을 직접 사용해본 적이 없어서 생기는 의문점일수도 있습니다.
A. 해당 논문 방법론은 저희 연구실에서 원복 가능합니다.
좋은 리뷰 감사합니다 !
Head probing이라는 개념이 잘 이해가 되지 않습니다. Head probing은 본 논문에서 처음 제안된 개념인지 궁금합니다. Encoder_{SAM}으로 초기화된 Encoder_{SAM-CLIP}을 frozen 시키는 것이라면 결국 해당 과정에서 Encoder_{SAM-CLIP}은 Encoder_{SAM}과 동일한 것으로 이해하면 될까요??
Q. Head probing이라는 개념이 잘 이해가 되지 않습니다. Head probing은 본 논문에서 처음 제안된 개념인지 궁금합니다. Encoder_{SAM}으로 초기화된 Encoder_{SAM-CLIP}을 frozen 시키는 것이라면 결국 해당 과정에서 Encoder_{SAM-CLIP}은 Encoder_{SAM}과 동일한 것으로 이해하면 될까요??
A. Head probing을 쉽게 설명 드리면 head만 fine-tunning하는 것이라고 보시면 됩니다.