안녕하세요, 허재연입니다. 이번에는 model calibration을 다룬 논문을 들고 왔습니다. Active Learning의 confidence 관련 논문을 읽다 calibration 관련 이해가 필요하겠다 싶어 읽어본 논문인데, 인용 수도 많고(약 5000) model calibration 분야에 있어 중요한 논문인 듯 하여 읽어 보았습니다. transformer 계열 모델에 대해서도 분석이 있으면 좋았겠지만 예전 논문인지라 다루지 않는 게 아쉽긴 했습니다.
관련 개념이 생소하신 분들을 위해 model calibration이 무엇인지부터 간단히 짚고 시작하겠습니다.
Model Calibration
날이 갈수록 딥러닝 모델이 여러 연구 분야에서 매우 높은 성능을 보여주고 있습니다. 그렇다면 우리는 이 성능 좋은 모델을 바로 산업에 가져다 써도 될까요? 모델 예측이 잘못되었다면 우리는 어떻게 대처해야 될까요? Autonomous driving이나 Medical AI와 같은 모델의 잘못된 예측이 인명 피해나 큰 경제적 손실을 야기할 수 있는 분야에서는 모델의 예측이 틀렸을 때에 대한 대비가 필요하며, 이는 모델의 성능 자체 만큼이나 중요합니다. 실제 산업 현장에는 다양한 외부 변수가 생길 수 있기 때문에 모델이 잘못된 예측을 할 수 있고, 따라서 모델의 예측이 불확실할 때에는 이에 대한 정보를 제공할 수 있어야 합니다. 좀 더 구체적으로 말하면 모델이 단순 예측 값 뿐만 아니라 예측 확신도에 대한 정보를 제공할 수 있다면 비교적 유연한 대처가 가능할 것입니다(자율 주행을 하다 운전자에게 운전을 위임한다던지).
그럼 신뢰할 수 있는 좋은 모델이란 무엇일까요? Classification model을 기준으로 한다면, 모델의 예측 확률 결과와 모델의 정확도가 유사하면 신뢰할 수 있을 것입니다. 실제 Accuracy와 모델의 prediction confidence가 유사하다면, 모델이 해당 클래스에 대해 얼마나 확신하고 있는지/어려워하는지 정보를 줄 수 있을 테니까요. 하지만 현대 딥러닝 모델의 예측 confidence는 실제 accuracy보다 상당히 높습니다. 틀린 답을 내놓으면서도 해당 예측 결과를 과신한다는 뜻입니다. 분류 모델이 이런 과도한 confidence를 내놓는 것을 overconfidence라고 하며, overconfidence를 방지하기 위해 실제 accuracy와 confidence값 사이 차이를 줄여 교정하는 것을 model calibration이라고 합니다. 100번의 예측을 시켰을 때 80번의 정답을 내놓고, 평균 confidence가 0.8이라면 해당 모델은 잘 calibrated되었다고 말할 수 있습니다. 논문에서는 완벽한 calibration을 다음과 같이 표현 할 수 있다고 합니다 :
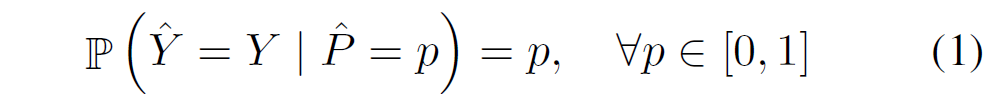
Y_hat은 class prediction이고, P_hat은 confidence입니다.
본 논문은 10년 전 간단한 신경망 모델과 달리 현대 딥러닝 모델들이 분류 성능은 좋아졌지만 calibration 성능은 떨어졌다는 것을 밝히고, Image/Text classification model들에 대해 calibration에 영향을 미치는 요소들을 연구한 논문입니다. 리뷰 시작하겠습니다.
Introduction
최근 딥러닝 기술의 발전으로 신경망의 정확도는 크게 향상되었으며 객체 검출, 음성 인식, 의료 진단과 같은 응용 분야에서 빼놓을 수 없는 도구가 되었습니다. 하지만 실제 의사 결정 시스템에서 분류 모델은 단순히 정확도가 높아야 할 뿐만 아니라 언제 잘못된 예측을 할 가능성이 있는지에 대한 정보를 제공해야 합니다. Autonomous driving system에서 만약 object detection network가 즉각적으로 장애물/보행자 여부를 확실히 예측할 수 없는 상황이면 자동차는 제동을 걸기 위해 다른 센서의 출력에 더 의존해야 합니다. 혹은 자동화된 의료 서비스에서 질병 진단 모델의 신뢰도가 낮을 때는 숙련된 전문의에게 제어권을 넘겨야 합니다. 구체적으로 말해서, 신경망 모델은 단순히 예측값(prediction)과 더불어 보정된 신뢰도(calibrated confidence) 측정값을 제공해야 합니다. 즉 해당 class label에 대해 모델이 얼마나 확실하게/불확실하게 예측하는지에 대한 정보를 제공해야 합니다. 만일 잘 calibrated된 모델을 활용한다면 모델 해석 관점에서도 좋은 정보를 제공할 수 있을 것이고, 모델을 거친 (calibrated되었으므로 신뢰할 수 있는)확률 값을 다른 task와 잘 결합해서 사용할 수도 있을 것입니다. 논문에서는 네트워크 출력을 음성 인식 언어 모델과 결합하거나, 객체 탐지를 위한 카메라 정보와 결합시켜 성능을 향상시킬 수 있을 것이라는 예시를 드네요.
그럼 우리가 사용하는 딥러닝 모델들은 calibration 관점에서 신뢰할 수 있을까요? LeNet과 같은 초기의 간단한 신경망들은 잘 calibrated된 확률 값을 제공되었다고 합니다. 이후 딥러닝 모델이 점점 발전하면서 분류 정확도는 상당한 발전을 이루었지만, 역설적으로 현대 딥러닝 모델들의 calibration 성능은 예전 만큼 좋지 못하다고 합니다.
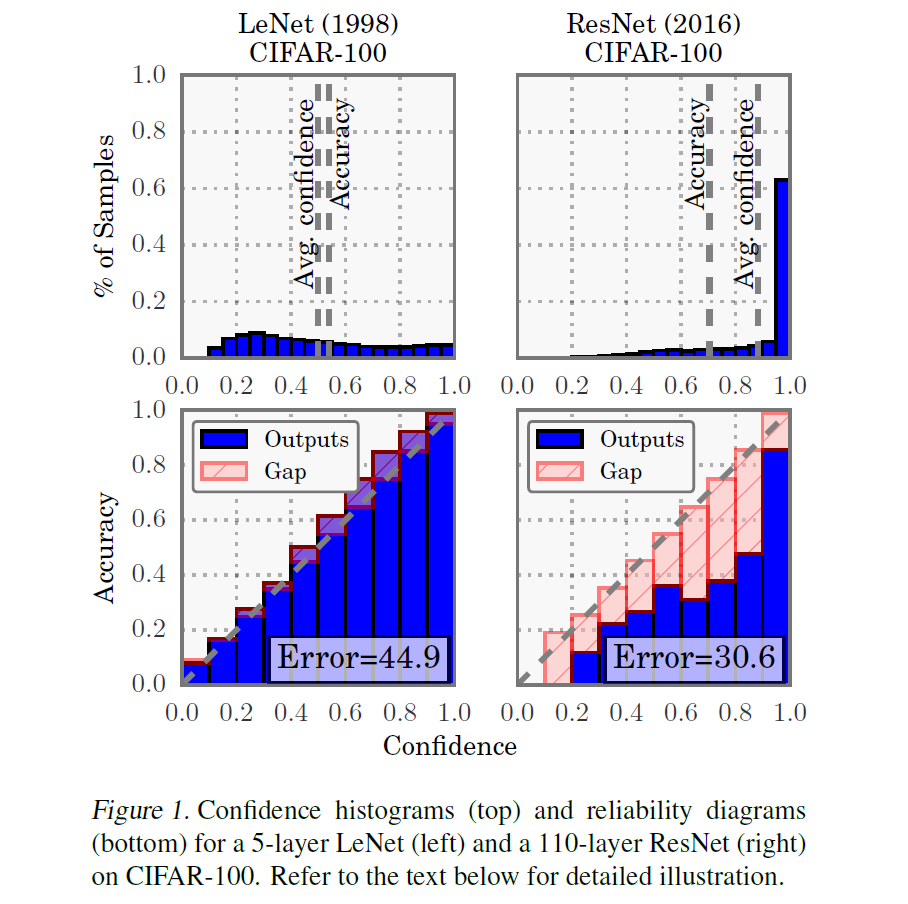
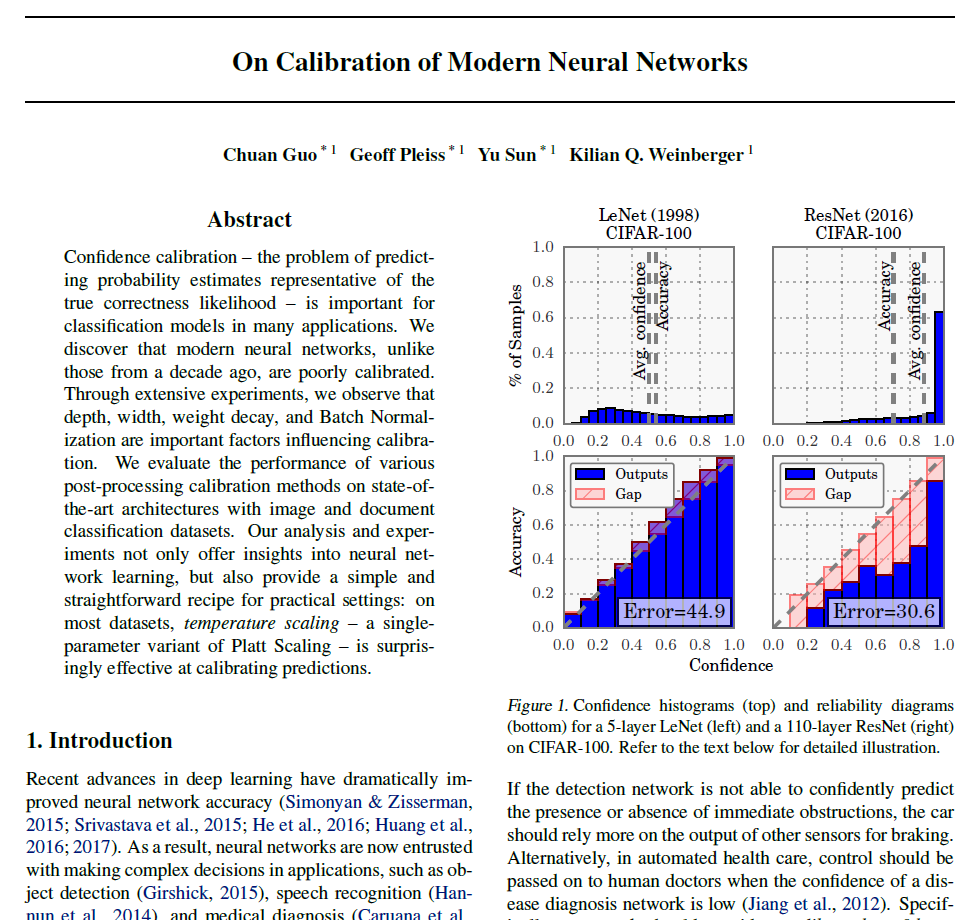
Figure 1은 CIFAR-100에 대해 LeNet과 ResNet에 대해 Confidence histogram, reliability diagram으로 비교한 것입니다. 위쪽 그림(confidence histogram)에서 LeNet은 Avg confidence와 Accuracy가 비슷하지만, ResNet같은 경우에는 그 값의 차이가 커진 것을 확인할 수 있습니다. 추가적으로 ResNet의 경우 output이 1.0에 가깝게 쏠려있는 것을 보니 prediction confidence가 항상 매우 크게 나오는 overconfidence가 발생하는 것을 확인할 수 있습니다. 아래쪽 그림(reliability diagram)에서도 accuracy와 confidence값의 차이를 나타내는 분홍색 영역이 LeNet보다 ResNet이 훨씬 큽니다. 종합적으로 ResNet이 분류 성능은 훨씬 뛰어나지만, Calibration 성능은 LeNet보다 한참 뒤떨어진다는 것을 알 수 있습니다.
저자들은 신경망이 miscalibration 되는 이유를 이해하고, 어떻게 해야 miscalibration 문제를 완화할 수 있을 것인지 탐구하고자 합니다. 본 논문에서 저자들은 여러 Computer Vision과 NLP task에서 신경망이 overconfidence로 실제 확률을 나타내지 못한다는 것을 밝히고, miscalibration 문제를 유발하는 model 구조 / 학습 요소들을 살펴봅니다. 이후에는 miscalibration을 해소할 수 있는 몇몇 방법들을 살펴보고 (당시)SOTA 방법론에 적용해 봅니다.
Definitions
여기서는 calibration 성능을 측정하는 평가 지표 몇 가지를 짚고 넘어갑니다. 살펴보겠습니다.
Reliability Diagrams
Reliability Diagram은 0~1까지의 confidence값을 N개의 균등한 bin으로 나눈 후 해당 bin의 accuracy와 confidence 평균의 차이를 비교해 그림으로 나타낸 것으로, Introduction에서 살펴 본 Figure1의 아래 그림입니다. 모델 calibration이 완벽하다면 y=x 그래프 형태의 항등 함수처럼 나타납니다. 유한한 sample에 대해 예측 accuracy를 얻기 위해서 prediction값들을 M개의 interval bins로 나누면(각 사이즈는 1/M) 구간 별 Bm개의 sample에 대해 accuracy를 다음과 같이 표현할 수 있습니다.
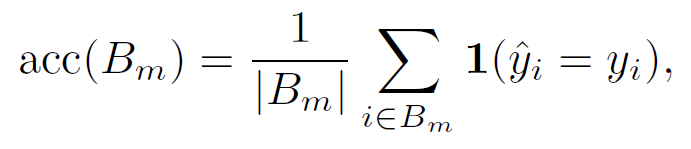
index i 에 대해 y_i는 true class label을, y_i hat은 prediction label을 의미합니다.
Bm에 대한 평균 confidence는 유사하게 다음과 같이 나타낼 수 있습니다.
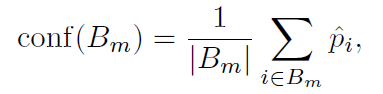
p_i hat은 sample i에 대한 confidence 값입니다. 완벽히 calibration된 모델은 모든 m에 대해 acc(Bm) = conf(Bm)일 것입니다.
acc와 conf를 위 그림과 같이 그래프로 나타내고, 두 수치의 차이를 살펴보면 얼마나 잘 calibration됐는지 시각적으로 확인할 수 있습니다.
Expected Calibration Error (ECE)
ECE는 calibration 성능 측정에 자주 사용되는 지표로, Reliability Diagram을 정량적 수치로써 나타낸 것입니다. 이름이 error이므로 ECE값이 낮을수록 calibration 성능이 좋다고 생각하시면 됩니다.
신뢰도 관점에서 모델 성능을 어떻게 평가 할 수 있을까요? 모델의 예측 확률 결과와 정확도의 차이가 얼마인지 확인하면 될 것입니다. confidence와 accuracy값이 얼마나 차이나고 있는지를 절댓값으로 계산해 평균을 내면 calibration 지표를 계산할 수 있습니다.
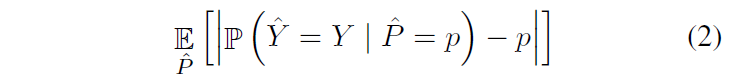
(2)번 수식은 무한개의 sample을 가정한 표기이기 때문에 ECE는 데이터들을 M개의 bins로 나누어 위 (2)번 수식을 다음과 같이 나타낸다고 합니다.
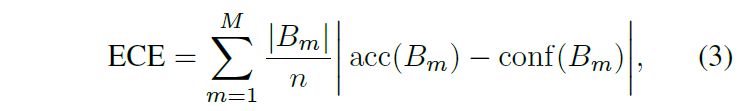
데이터 1000개에 대해서 200개씩 5개의 집단으로 나눈다고 하면 M=5이고, (200개 m번째 집단 Bm에 대한 평균 accuracy – m번째 집단의 평균적인 예측 confidence)를 계산한 다음 평균을 구한다고 생각하시면 됩니다. M은 데이터를 나눈 집단 개수, n은 전체 데이터 개수, Bm의 나눈 집단의 크기(샘플 수)를 나타냅니다. acc(Bm)은 집단 Bm에 대한 예측 모델 정확도를, conf(Bm)은 집단 Bm에 대한 모델 확률값들(confidence)의 평균을 의미합니다.
자주 사용되는 지표이기도 하고, 이 논문에서도 calibration 성능을 측정하는 주요 지표로 ECE를 사용합니다.
Maximum Calibration Error (MCE)
ECE와 함께 제안된 지표이며, 식도 비슷합니다. high-risk application 상황처럼 신뢰 할 수 있는 confidence 평가 지표가 필요한 상황을 고려한 지표로, confidence와 accuracy 차이 중 가장 큰 값을 취합니다(ECE는 가장 큰 값을 취하는게 아니라 평균을 내서 사용했었죠). ECE에서 평균을 사용하던 것을 max값을 취하는 것으로 바꾼 지표라고 생각하시면 됩니다.
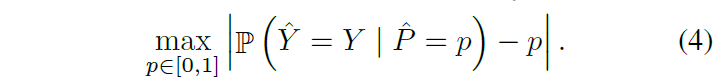
ECE에서 (2)번 수식을 (3)번 수식으로 표기한 것처럼 (4)번 수식을 다음과 같이 근사시킬 수 있습니다.
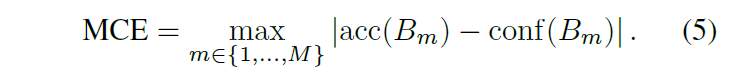
Observing Miscalibration
저자들은 최근 신경망 구조와 학습 기법이 크게 발전함을 언급하며, Figure1에서 관찰된 miscalibration의 원인이 될 수 있는 몇몇 요소들을 확인합니다. 직접적으로 인과 관계를 추론할 수는 없지만, model capacity 증가, 규제화(regularization)의 부재가 miscalibration과 밀접한 관련이 있어 보인다고 합니다.
model capacity
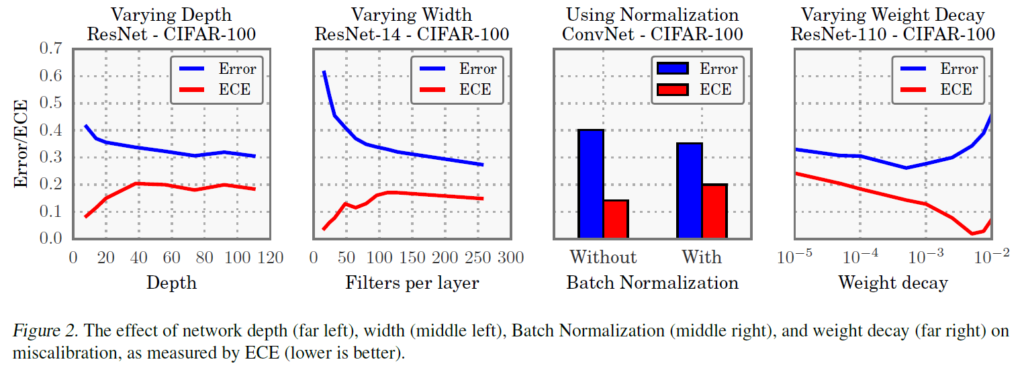
신경망 모델은 최근 발전을 거듭하며 모델 용량이 극도로 증가했습니다. CNN 모델 같은 경우, 이제는 수백 개의 layer와 layer 당 수십~수백의 convolution filter를 가지는 모델이 등장했습니다(ResNet/DenseNet). 모델의 depth, width가 증가하며 classification error가 감소했지만, 저자들은 이런 모델 용량 증가가 model calibration 관점에서는 오히려 악영향을 끼친 것을 발견했습니다. Figure 2를 보면 CIFAR100에 대해 훈련된 ResNet의 경우, Depth와 layer당 filter 수를 증가시킬 경우 classification Error는 감소하지만 ECE는 오히려 증가하는 것을 확인할 수 있습니다. 가장 왼쪽 Depth같은 경우 layer 당 filter 수를 64개로 고정했고, 두 번째 Filter per layer의 경우 depth를 14로 고정한 것입니다. 공통적으로 모델 용량이 커짐에 따라 ECE가 증가하는 것을 확인할 수 있습니다.
학습 도중 모델이 예측 class를 어느 정도 정확하게 맞출 수 있을 정도로 훈련이 되었을 때, 모델이 이후에는 예측의 confidence를 높임으로써 Cross-Entropy를 더욱 최소화할 수 있습니다. 저자들은 모델 용량이 증가함에 따라 cross-entropy를 더욱 낮출 수 있는 능력을 갖추게 되므로 모델이 더욱 과신하는 경향이 생긴다고 설명합니다.
Batch Normalization
Batch normalization은 계층을 통과하는 데이터 분포를 조절할 수 있게 하여 신경망이 더욱 잘 최적화 되도록 돕습니다. 이 정규화 기법으로 ResNet, DenseNet과 같은 매우 깊은 신경망을 설계할 수 있게 되었습니다. Batch norm을 통해 훈련 시간을 단축시키고, 추가적인 regularization의 필요성을 줄이고, 신경망의 정확도를 높일 수 있었습니다.
저자들은 배치 정규화가 구제척으로 모델의 최종 예측 과정에 어떻게 영향을 미치는지 지적하기는 어렵지만, 배치 정규화를 적용시킨 모델이 miscalibration되는 경향을 발견했다고 합니다. Figure 2에서 보면 6-layers ConvNet에서 배치 정규화가 적용되었을 때 분류 오답률은 감소했지만 ECE는 증가합니다. 이러한 경향은 모델의 하이퍼파라미터를 어떻게 설정하던 관계 없이 일관적으로 관찰되었다고 합니다.
Weight decay
신경망의 주요 규제화(regularization) 기법이었던 weight decay는 점점 덜 활용되고 있습니다. 신경망 학습 시 용량이 증가하면 overfitting을 방지하기 위해 regularizatoin을 사용됩니다. 하지만 batch normalization의 강력한 regularzation 효과로 L2 regularization이 적을수록 일반화가 잘 되는 경향이 관찰되어 점점 weight decay를 거의 적용시키지 않고 모델 훈련을 진행한다고 합니다.
저자들은 weight decay가 작을수록 calibration에 부정적인 영향을 미치는 것을 확인했습니다. Figure 2에서 ResNet110에 대해 다양한 weight decay에 대한 실험 결과를 확인할 수 있습니다. regularzation이 추가될수록 model calibration은 더욱 좋아진다고 합니다.
Cross entropy overfitting(Negative Log-Likelihood. NLL)
저자들은 NLL을 통해 간접적으로 model calibration을 측정할 수 있다고 합니다.
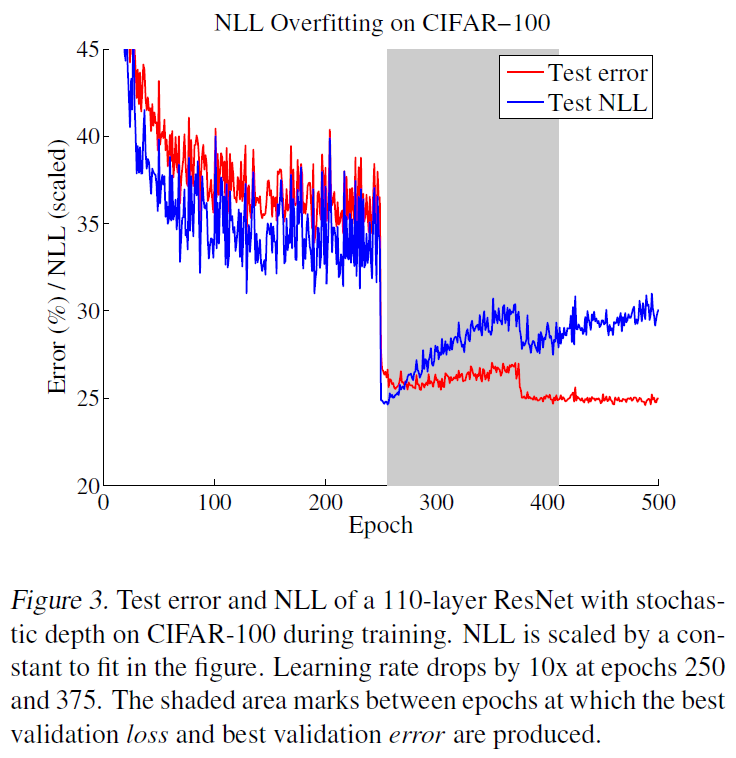
그림을 보시면 250Epoch에서 learning rate drop이 일어나자마자 낮은 error와 loss값을 보여주었지만, 이후 overfitting이 일어나면서 test CE는 오히려 높아지는것을 볼 수 있습니다. 하지만 이런 fitting이 오히려 모델 분류 정확도는 높게 만들어주는 결과를 보여주었습니다(test error 29%->27%). 위에서 언급한것과 같이 모델이 어느정도의 정확도를 갖추었지만 confidence를 더욱 과신해야 모델이 정답을 맞췄을 때 label(one-hot vector)와 차이가 줄어들기 때문임으로 이해했습니다.
Calibration Methods
calibration 성능을 좋게 만드는 몇몇 기법들이 있는데, 대부분 모델 예측 부분에 적용하는 기법들입니다
Histogram binning

Histogram Binning은 1. validation set의 confidence score에 따라 [0,1]까지의 범위를 N개로 분할하고(1부터 N까지의 {Bm}), 2. 각 구간에 해당하는 confidence를 갖는 sample들의 calibrated confidence를 bm의 실제 accuracy로 대체하는 것입니다. 분위를 분할하는 기준은 confidence score에 따른 균등 분할법과 validation set의 mass에 따른 균등 분할 등의 방법이 있다고 합니다. 모든 sample이 총 N개의 confidence를 갖도록 하기 때문에 굉장히 sparse한 confidence score가 산출된다는 것이 단점이라고 하네요.
Matrix and vector scaling
softmax layer를 거치기 이전의 logit vector z에 대해, 다음과 같은 선형 변환을 적용하는 방법입니다. 확률값으로 바꾸기 전에 적절한 변환을 가하는 방법이라고 생각하시면 됩니다.
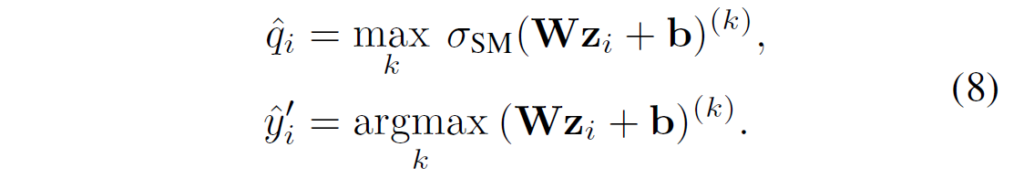
Temperature scaling
바로 위 Matrix/vector scaling의 가장 간단한 버전이라고 생각하면 됩니다. softmax를 거치기 이전 logit vector에 단순히 상수값 T를 나누는 방법입니다.

엄청 간단한 방법인데.. 이게 가장 성능이 좋다고 저자들이 강조합니다.
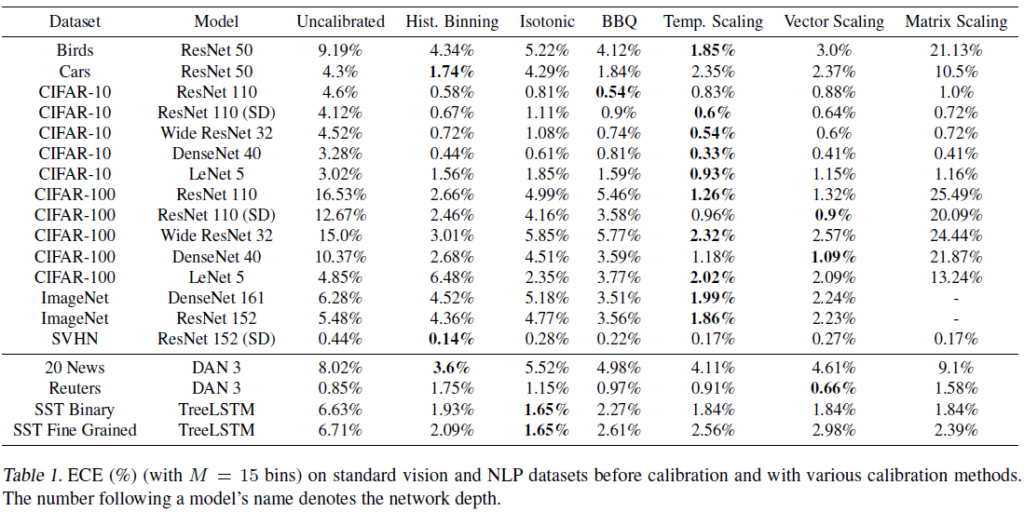
실험은 다양한 Image/Text classification으로 수행되었습니다. 평가 지표는 ECE입니다. text 분류가 있는데 17년 논문이라 transformer가 없는게 아쉽긴 합니다. Isotonic은 Isotonic regression을 이용한 calibration이고, BBQ는 Bayesian Binning into Quantiles라는, 베이지안 model averaging을 이용해서 histogram binning을 확장한 방법입니다.
놀라운 것이, 가장 적용이 간단한 temperature scaling이 vision task에서 가장 성능이 좋다는 것을 발견했다며 저자들이 강조합니다. NLP에서도 다른 방법론들에 크게 뒤지지 않습니다. (temperature scaling을 일반화시킨게 vector/matrix scaling입니다)
Binning 계열 방법론도 대부분 데이터셋에서 calibration 효과가 있지만 temperature scaling만큼은 아닙니다. 또한, binning 방법은 accuracy 성능을 손상시키기도 한다고 합니다.
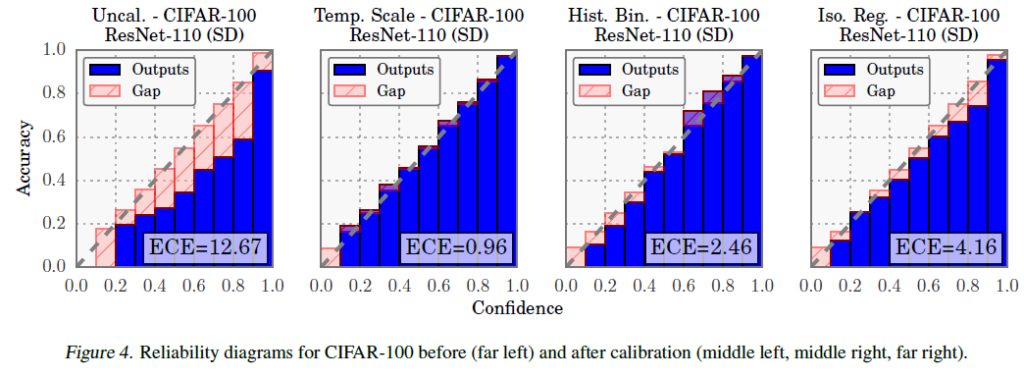
Figure 4는 calibration 전후 reliability diagram을 보여줍니다. 맨 왼쪽 uncalibrated된 ResNet은 overconfidence한 경향을 보입니다. 2번째는 Temperature scaling, 3번째는 Histogram Binning, 3번째는 Isotonic regression으로 calibration을 진행했습니다. 세 방법 모두 훨씬 나은 calibration을 보이며, temperature scaling이 가장 잘 calibration 되는 것을 그래프로 확인할 수 있습니다.
Conclusion
발전된 신경망은 분류 정확도가 확연히 개선되었지만 확률 예측 및 calibration 측면에서는 오히려 부정확해졌습니다. 본 논문에서는 calibration에 악영향을 미치는 요소들을 확인하고, calibration 방법들을 검토해서 효과가 있음을 밝혔습니다. 해당 방법들이 accuracy/calibration에 영향을 미치는 정확한 이유는 추후 연구되길 바란다고 밝힙니다. 그리고 구현이 쉽고 효과가 좋은 temperature scaling calibration을 추천한다며 논문이 마무리됩니다.
본 논문에는 나와있지 않지만, 추가적으로 알아보니 label을 smoothing하는 방법(prediction이 one-hot vector인 label값에 fitting되어 overconfidence한 경향 완화)이나 mix-up 증강(0~1사이로 convex combination 된 label을 학습)을 통해 overconfidence를 완화하는 방법도 있다고 합니다. 해당 방법론들도 결국 예측값 / 라벨값에 집중하기 때문에 모델 후반부 예측단에 치우치지 않고 model 자체의 calibration에 대해 고찰하는 논문이 있으면 읽어보고 싶네요. 논문에는 나와있지 않지만, softmax 함수 자체가 분자가 지수 함수이기 때문에 약간만 input값이 틀어져도 output이 크게 영향을 받기 때문에 overconfidence가 쉽게 유발되는 것이 아닌가? 하는 개인적인 생각도 듭니다.
또 본 논문이 너무 예전 논문인듯 싶어 추가적인 조사를 해 보니 non-convolutional(ViT, MLP-Mixer ..) 모델들이 convolutional model보다 calibration 성능이 더 좋다는 정보도 있습니다. 기회가 된다면 다음에 또 다루겠습니다. 혹시 추가적으로 논문을 읽어보고 싶으신 분이 계시다면 다음 논문을 살펴보시는것도 좋을 것 같습니다: [NeurIPS 2021] Revisiting the Calibration of Modern Neural Networks
감사합니다.
안녕하세요. 허재연 연구원님.
좋은 리뷰 감사합니다. 굉장히 흥미로운 주제네요.
리뷰를 읽으며 모델이 overconfidence를 보이는 이유를 저 나름대로도 생각해보았는데, 학습 시 사용하는 목표 함수가 결국은 True Positive의 경우 최대한 높은 confidence score를 줘야 하도록 되어 있다보니, A클래스가 맞으면 맞다, 아니면 아니다 확실히 출력하도록 학습되는것이 아닐까.. 하는 생각도 듭니다. 아마 이런 것 때문에 label smoothing이 도움이 되는 것 같기도 하네요.
다만 결국 모델이 헷갈리는 데이터(hard example)에 대해 낮은 값을 출력하게 되면, 이로 인해 accuracy의 감소도 크게 나타날 것 같은데, 논문에서 binning 방법이 accuracy를 손상시킨 다는 것 외에, calibration과 성능의 관계에 대하여 더 자세히 분석한 내용은 없었는가 궁굼합니다.
감사합니다!
안녕하세요, 백지오 연구원님. 좋은 의견 감사합니다. 본문에도 적혀있다시피, 결국 GT값이 [0,0,0,0,0,1,0,0] 형태의 one-hot vector이다 보니, prediction 또한 예측 confidence값이 높아야 loss함수가 낮아지기에 overconfidence가 나타나는 것으로 이해됩니다. 따라서 prediction의 scale을 조정해주거나, 정답 label을 1에서 낮춰주는 label smoothing이 효과를 보입니다.
또한, Figure 2처럼 모델고 학습에 있어 Error와 ECE를 비교한 것 이외에 calibration-accuracy 간 관계에 대해 추가적인 언급은 없습니다. 직접적으로 어떤 관계가 있는지 밝혀주었다면 좋을텐데, 아쉬운 부분입니다.