이번 주차 X-Review 또한 Temporal Sentence Grounding in Videos(TSGV) 관련 논문입니다. 본 논문은 23년도 CVPR에 게재되었으며, 20, 21년도 근처의 초창기 방법론들을 익히던 와중 23년도 CVPR에 prompt learning 기법으로 TSGV에 접근한 논문이 있어 알아보게 되었습니다. 미시간 주립와 인텔에서 공동 연구된 논문입니다.

바로 리뷰 시작하겠습니다.
1. Introduction
저자가 기존 방법론들의 어떠한 문제를 지적하는지 알아보겠습니다. 이 문제점은 굉장히 쉽고 직관적으로 이해할 수 있습니다.
TSGV는 구체적인 text query가 주어졌을 때, 긴 untrimmed video에서 실제 text query가 설명하고 있는 사건이나 동작의 구간을 예측하는 task입니다. 즉 temporal 축 관점에서 현재 프레임과 주어진 text query와의 상응 여부를 판단해야 하는 것입니다. 이에 따라 TSGV에서는 spatial-temporal context를 파악하는 것이 중요하게 여겨졌고, 최신 방법론들은 대부분 C3D, I3D 등의 3D Convolutional Neural Network를 visual encoder로 활용하고 있습니다(위와 같은 방식을 3D model이라 칭하겠습니다). 2D Convolutional Neural Network로부터 추출한 visual feature에는 비디오의 spatiotemporal information이 담겨있다고 보기 어렵기 때문입니다.
일반적으로 어떠한 task를 수행하든 프레임 feature를 dense하게 추출할수록 좋은 성능을 기대할 수 있습니다. 기존 학계의 3D model들은 비디오에서 16개 프레임을 하나의 clip으로 묶되, 심지어 8개의 프레임씩은 겹치도록 두어 3D encoder로부터 feature를 추출하게 됩니다. 이는 굉장히 dense한 feature extraction 방식이라고 볼 수 있습니다. 그렇기 때문에 TVG를 실용적 관점으로 적용하고자 할 때엔 이렇게 feature extraction cost가 큰 것이 바람직하다고 볼 수는 없을 것입니다.
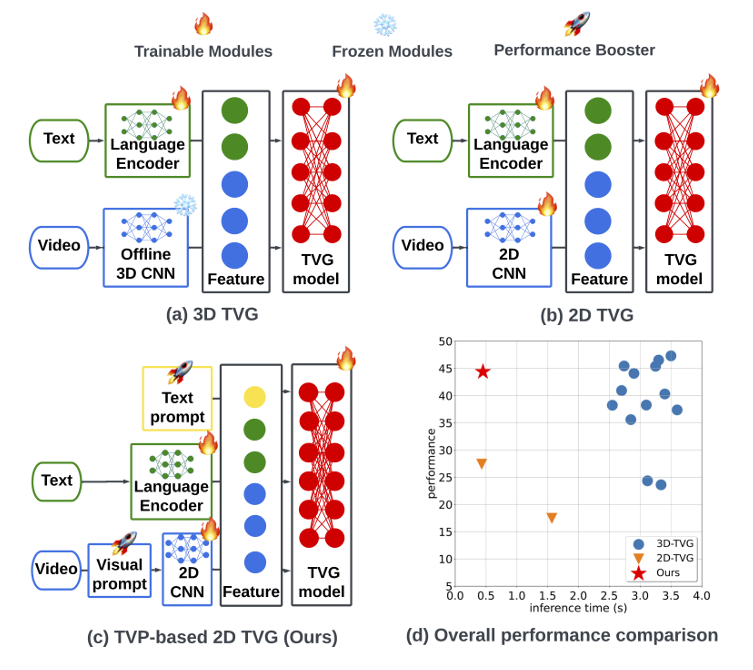
본격적인 설명을 드리기에 앞서 저자는 TSGV task를 Temporal Video Grounding(TVG)라고 부르고 있습니다. 그림 1에는 어떠한 visual encoder를 사용하는지에 따른 모식도와 이에 대한 성능-inference time 그래프가 나타나있습니다. 우선 그림 1-(a)와 그림 1-(b)를 함께 보았을 때, 3D model의 visual encoder는 같이 학습되기에는 cost가 너무 크기에 freeze되어 있는 모습입니다. 반면 2D model의 visual encoder는 computational cost가 훨씬 적기에 학습 중 파라미터가 함께 갱신됩니다. 이를 토대로 그림 1-(d)를 보았을 때, 2D model들은 inference time이 크게는 6~7배 가량 빠르지만 성능 측면에서는 크게 낮은 것을 볼 수 있습니다. 많은 연구 분야에서 고려되는 speed-accuracy trade-off 상황이라고 볼 수 있겠죠.
그림 1에서 저자가 이야기하고자 하는 것은, 분명 3D model의 성능이 압도적으로 높은 것은 사실이되 실용적 관점에서 보았을 때는 2D model의 추론 속도가 필요한 상황이라는 점입니다. 이러한 상황에서 저자는 한 가지 고민을 하게 됩니다. “2D model의 실용성을 유지하며 이를 3D model의 성능과 준하도록 고도화할 수는 없을까?”인데요, 이를 다루기 위해 저자가 제안하는 프레임워크가 Text-Visual Prompting(TVP)이며 이에 대한 모식도는 그림 1-(c)를 통해 확인할 수 있습니다. 특징을 살펴보면 결국 2D model을 기반으로 하여 효율성을 유지하고, 성능을 끌어올리기 위한 Visual prompt와 노란 동그라미로 표시된 Text prompt가 추가되어 있네요.
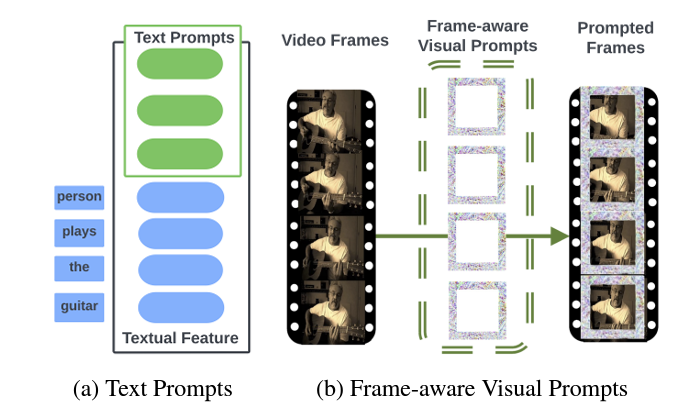
그림 2는 방금 말씀드린 visual-, text-prompt를 설명하고있습니다. 그림 2-(a)의 Text prompt는 저희 팀에서 계속 다뤘던 Vision-Language Pretraining 내지는 prompt learning 관련 리뷰에서 계속 볼 수 있었는데, 문맥을 스스로 학습할 수 있도록 text encoder로부터 추출한 text feature 앞에 learnable parameter를 붙여주고 있는 모습입니다. 반면 그림 2-(b)의 Frame-aware Visual Prompts는 조금 생소하실 수도 있지만, 결국은 프레임의 padding이 가해지는 위치에 learnable parameter를 끼워넣어주어 이를 추후 feature extraction의 입력으로 사용하는 것입니다. 목적이나 기대효과는 text prompt와 동일하다고 볼 수 있습니다.
저자는 3D model과 유사한 성능을 냄과 동시에 효율적인 2D model인 TVP model을 구축하기 위해 앞서 이야기한 prompt learning 기법 뿐만 아니라, Temporal-Distance IoU(TDIoU) loss도 함께 제안합니다. 자세한 내용들은 contribution을 정리한 뒤 다음 장에서 살펴보겠습니다.
Contribution
- We propose an effective and efficient framework to train 2D TVG models, in which we leverage TVP to improve the utility of sparse 2D visual features without resorting to costly 3D features.
- We integrate visual prompt with text prompt to co-improve the effectiveness of 2D visual features. On the top of that, we propose TDIoU-based prompt-model co-training method to obtain high-accuracy 2D TVG models.
- We show the empirical success of our proposal to boost the performance of 2D TVG, 9.79% improvement on Chrades-STA, and 30.77% in ActivityNet-Captions together with 5\times{} inference time acceleration over 3D TVG methods.
2. Methods
2.1 Problem Definition
먼저 notation을 정리하겠습니다.
하나의 비디오 \textbf{v} \in{} \mathbb{R}^{N_{\text{vid}}\times{} C \times{} H\times{}W}, 그와 짝을 이루는 sentence \textbf{s} \in{} \mathbb{R}^{N_{\text{tex}}}가 주어졌을 때, TVG의 최종 목적은 상응하는 구간 \hat{T} = (\hat{t}_{\text{sta}}, \hat{t}_{\text{end}})를 예측하는 것입니다. 각 encoder를 g_{\text{vid}}, g_{\text{tex}}, f를 TVG method라 했을 때 전체 과정은 아래 수식 (1)과 같습니다.
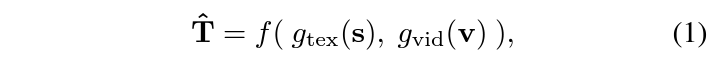
2.2 TDIoU Loss Function
이전 리뷰에서도 다루었지만, 기본적으로 TVG의 방법론들은 가지고 있는 ground truth 구간으로부터 학습하고자 아래 수식 (2)와 같은 tIoU loss를 최소화합니다.
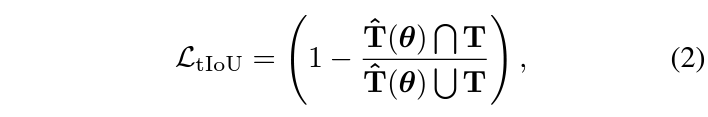
수식 (2)는 결국 특정 (비디오-text) 쌍의 GT 구간과 모델의 예측 구간 간 temporal IoU가 최대화되도록 만들어주는데, 만약 겹치는 구간이 아예 없다면 학습 중 gradient vanishing 문제를 일으키게 됩니다. 아예 어긋난 예측을 내뱉어 본 loss로 열심히 학습을 해도 모자라는 상황에서, 교집합 구간이 0이 되기 때문에 직접적인 학습이 어려워진다는 것으로 해석해볼 수 있습니다.
이를 해결하고자 저자는 GT 구간과 예측 구간 간 normalized central time point distance와 duration difference를 학습 중 최적화하는 TDIoU loss를 제안합니다.
\mathcal{L}_{\text{dis}}: Distance Loss
결국 교집합 구간이 존재하지 않더라도 학습이 이루어지도록 하는 추가 장치들이 등장할텐데, \mathcal{L}_{\text{dis}}는 GT 구간의 중간 지점과 예측 구간의 중간 지점의 차이를 정규화 후 최소화합니다. 이는 아래 수식 (3)과 같습니다.
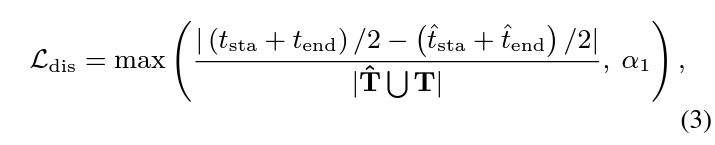
분모는 합집합 구간의 길이로 들어가며, 분자의 수식은 각 구간 중간 지점의 거리 차이라고 해석할 수 있습니다. 이렇게 되면 교집합 구간이 존재하지 않더라도 직접 두 구간을 가깝도록 만들 수 있을 것입니다. 수식 (3)에서 \alpha_{1}은 0.2이며, 학습 후반 \mathcal{L}_{\text{dis}}의 진동을 방지하고자 설정되었다고합니다. 학습 후반에는 어느정도 overlap이 생겼을 것으로 기대하고 \mathcal{L}_{\text{dis}}의 영향을 줄여주는 것으로 해석하였습니다.
\mathcal{L}_{\text{dur}}: Duration Loss
앞선 \mathcal{L}_{\text{dis}}만으로 최적화한다면 GT와의 중간 지점이 동일해지며 꽤 겹치는 방향으로 학습될 수 있지만, 구간의 중심 뿐만 아니라 길이까지 동일해야 최적의 학습이 이루어진다고 볼 수 있을것입니다. 이에 따라 아래 수식 (4)와 같은 \mathcal{L}_{\text{dur}}이 적용됩니다. 여기서 \alpha_{2}는 0.4이며 수식 그대로 두 구간의 길이를 동일하게 맞춰주는 역할을 수행합니다.
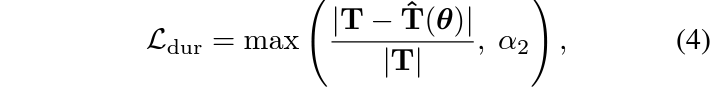
이에 따라 최종적으로 적용되는 loss \mathcal{L}은 아래 수식 (5)와 같습니다.
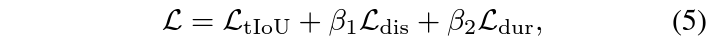
2.3 Text-Visual Prompt Design
저자의 main contribution인 prompt learning 부분입니다.
앞서 수식 (1)에서의 방식은 비디오와 text query가 각각의 encoder를 타고나와 여러 논문에서 제안하는 방법론 f에 의해 구간을 예측한다면, 저자가 제안하는 TVP 프레임워크는 크게 보았을 때 우선 아래 수식 (6)과 같이 정리할 수 있습니다.
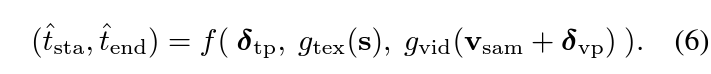
출력은 동일하게 시작, 끝 지점이며 입력값이 조금 다른 것을 볼 수 있는데요, 수식 (6)에서 \delta{}_{\text{tp}}는 text prompt, \delta{}_{\text{vp}}는 visual prompt를 각각 의미합니다. 우선 비디오로부터 uniform-sampling을 수행하여 얻은 프레임들을 \textbf{v}_{\text{sam}}이라 칭합니다. 이후 그림 2에서 보았던 것처럼 visual prompt를 적용한 뒤 visual feature를 추출합니다. 이는 text prompt, text feature와 함께 f에 입력되고 있는 것을 볼 수 있습니다.
2.4 Framework
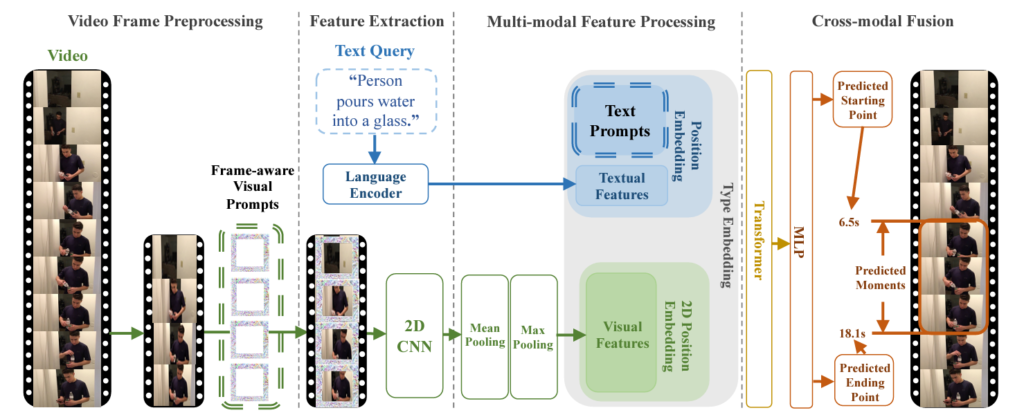
전반적인 프레임워크는 위 그림 3을 통해 확인할 수 있습니다. 크게 4단계로 구성되어있네요.
저자는 2D TVG 베이스라인으로 ClipBERT를 선택하였습니다. 기본적인 파이프라인을 ClipBERT로 두고 이에 저자가 제안하는 prompt 기법을 추가하는 것입니다. 그림에서 볼 수 있는 4가지 단계는 아래와 같습니다. 이들이 본 방법론에 특화된 4가지 구분이라기보단, TVG의 일반적인 파이프라인이라고 생각하시면 됩니다.
- Video Frame Preprocessing
- Feature Extraction
- Multi-modal Feature Processing
- Cross-modal Fusion
각 단계가 어떠한 역할을 하는지, 어떤 연산을 수행하는지는 아래 알고리즘 1의 pseudo code와 함께 설명드리겠습니다.

매우 길고 복잡해보이지만 저자가 절차 하나마다 notation을 붙이면서 길어보이는 것 뿐이라, 차근차근 설명 드리겠습니다. 그림 3과 함께 보시면 빠르게 이해하실 수 있을 것입니다.
1. Video frame preprocessing
L1에선 입력받은 비디오 \textbf{v}로부터 일부 프레임만을 uniform-sampling 합니다. 이렇게 얻은 프레임을 \textbf{v}_{\text{sam}}이라 하고, L2는 여기에 \delta{}_{\text{vp}}를 그림 2-(b)와 같이 붙여 \textbf{v}'_{\text{sam}}을 얻는 과정을 의미합니다. 본 단계에서 sparse sampling을 하는 이유는 ClipBERT의 컨셉 또한 적은 양의 프레임을 샘플링하고 2D encoder로 feature를 추출한 뒤 BERT의 기법을 빌려 text와의 multimodal embedding을 잘해보자는 것이기 때문에, 효율성을 중시하는 본 방법론에서도 이를 베이스라인으로 삼았다고 생각됩니다.
2. Feature extraction
L3, L4는 각 모달 feature를 추출하는 과정을 의미하며 이 때 g_{\text{vid}}는 R-50의 앞 5개 block, g_{\text{tex}}는 사전학습된 BERT에 해당합니다. 추출한 feature를 각각 \textbf{Q}_{\text{vid}}, \textbf{Q}_\text{{tex}}라 칭하고 있습니다. 단순히 각 모달의 feature를 추출하는 것이 전부입니다. 이 feature들을 어떻게 각각 enhance하고 서로 interaction 시킬지가 중요할 것입니다.
3. Multimodal feature processing
3, 4단계에서 두 모달의 feature enhancement가 이루어지기 때문에 사실상 TVG에서 가장 중요한 부분입니다. L5에서는 Pixel-BERT에서의 방식을 따라 앞서 얻은 \textbf{Q}_{\text{vid}}에 2\times{}2 max-pooling과 시간 축에 대한 average-pooling을 적용해 \textbf{Q}'_\text{{vid}}를 얻습니다. L6에서는 앞서 얻은 text feature Q_{tex}에 text prompt \delta{}_{\text{tp}}를 붙여 \textbf{Q}'_{\text{tex}}를 얻어줍니다. 이후 L7, L8에서는 각 모달 feature에 positional embedding을 더해 \textbf{Q}''_{\text{vid}}, \textbf{Q}''_{\text{tex}}를 얻습니다.
다음으로 L9에서는 앞서 얻은 2D 형태의 \textbf{Q}''_{\text{vid}}가 flatten된 후 \textbf{Q}''_{\text{tex}}와 concat됩니다. 이를 \textbf{Q}_{\text{all}}이라 부르고 여기에 type embedding \textbf{M}_{\text{type}}을 더해준다고 하는데, 아마 concat된 index를 기준으로 vid 부분과 tex 부분에 다른 값을 더해주는 것 같습니다. 정확한 것은 추후 코드를 살펴보고 말씀드리겠습니다.
4. Crossmodal fusion
마지막 단계로, 앞 단계까지 각 모달의 feature를 잘 만들어내고 합쳤다면 이제 최종 단계를 만들어내기 직전 두 모달 간 관계를 modeling해주는 부분입니다. L11에 나타나있는 f는 BERT와 동일하게 12-layer transformer를 사용하였으며 이에 대한 출력값을 \textbf{Q}_{\text{CM}}이라고 부릅니다. 이후에는 이를 MLP, sigmoid의 입력으로 주어 정규화된 시작, 끝 지점을 예측하게 됩니다.
저자가 단계별로 친절히 설명해주다보니 notation이 많아 좀 복잡해보였을 수도 있다고 생각합니다. 결국은 ClipBERT의 multi-modal interaction 방식을 따르되 visual-, text-prompt를 붙였다는 것이 가장 큰 차이점이네요. 우선 실험 성능을 알아보기 전 Implementation detail을 바탕으로 구조 전반 및 학습 방식에 대한 세부사항을 설명드리겠습니다.
2.5 Crossmodal pretraining setup
TVP에서 사용되는 visual encoder R-50은 grid-feat 방식으로 사전학습된 weight를 가져왔는데, 자세한 내용은 본래의 논문을 참고하시면 좋을 것 같습니다. 또한 text encoder와 12-layer transformer는 모두 English Wikipedia와 BookCorpus로 사전학습한 BERT-based 모델을 가져왔다고 합니다. 이렇게 사전학습한 모델을 가지고 와서, 다시 한 번 cross-modal pretraining의 장점을 누리기 위해 TVP 프레임워크를 Visual Genome Caption 데이터셋과 COCO Captions 데이터셋으로 사전학습하였다고 합니다. 해당 데이터셋들로 사전학습 할 때엔 BERT의 Next Sentence Prediction task와 유사하지만 image-text 단위로 수행되는 image-text matching과, 마찬가지로 BERT의 masked language modeling 기법이 적용되었다고 합니다.
2.6 Implementation setup
Contribution에서 언급했듯 TVP는 두 가지 데이터셋 Charades-STA(C)와 ActivityNet Captions(A)에서 벤치마킹을 진행합니다. 우선 비디오마다 uniform-sampling할 프레임의 개수 N_{\text{vid}}는 C에서는 48, A에서는 64를 사용하였습니다. 모든 프레임은 긴 쪽을 기준으로 448에 맞게 resize되었으며 448\times{}448로 zero-padding 되었습니다. 두 데이터셋 모두에서 visual prompt의 크기는 96인데, 448\times{}448 크기의 프레임의 가장자리 부분부터 가운데만 남기가 96픽셀씩을 prompt로 대체한다고 생각하시면 됩니다. 아래 실험에서 말씀드릴 표 4를 참고하시면 형태를 이해하시기 편하실겁니다. Text prompt는 C에서는 10, A에서는 20개로, 해당 개수만큼의 추출된 text feature 앞에 붙어서 함께 임베딩된다고 생각하시면 됩니다.
방법론 측면에서 추가적으로 궁금하신 내용은 질문 주시면 답변드리도록 하겠습니다.
이제 실험 부분으로 넘어가겠습니다.
3. Experiments
3.1 Experiment Setup
Datasets
앞서도 잠깐 언급했지만, 우선 최근 TVG 벤치마킹에 가장 흔히 사용되는 두 가지 데이터셋 Charades-STA와 ActivityNet Captions에 대하여 통계량을 살펴보겠습니다.
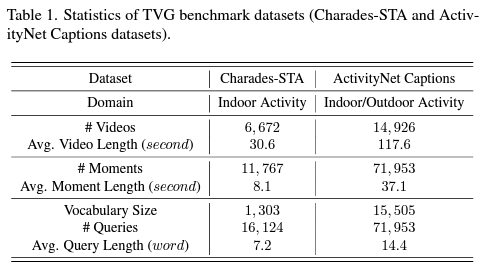
표 1을 통해 두 데이터셋의 일반적 통계량을 살펴볼 수 있는데, Charades-STA보다는 ActivityNet Captions의 비디오 개수, 각 비디오 당 길이, text query에 상응하는 moment의 개수 및 길이, 주어지는 query의 개수와 각 query의 길이 모두가 많거나 긴 것을 볼 수 있습니다. 저자도 다른 방법론들과의 비교를 위해 두 데이터셋으로 벤치마킹을 수행하고 있습니다.
참고로 평가지표는 Accuracy를 사용합니다. 본 방법론이 Regression-based method이기 때문에 하나의 text query에 대한 하나의 구간만을 예측하게 되는데요, 그렇기 때문에 Recall@5, Recall@10 등의 평가지표를 사용하는 것이 불가능합니다. 이에 따라 기존 방법론들의 평가지표와 마찬가지로 Accuracy(=Recall@1, IoU=0.3, 0.5, 0.7)을 사용합니다. R@1, IoU=0.3인 경우 0.3 이상의 tIoU를 가지는 예측을 TP로 두고 정확도를 계산한다는 의미로, IoU 기준이 높아질수록 깐깐해지니 측정되는 정확도는 낮아지겠죠.
나머지 세부사항은 방법론 마지막 부분에 정리하였으니 넘어가도록 하겠습니다.
3.2 Experiment Results
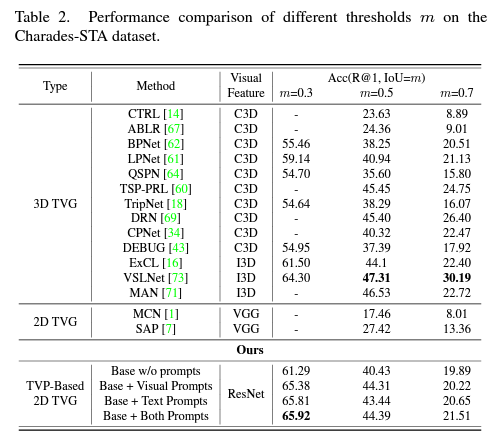
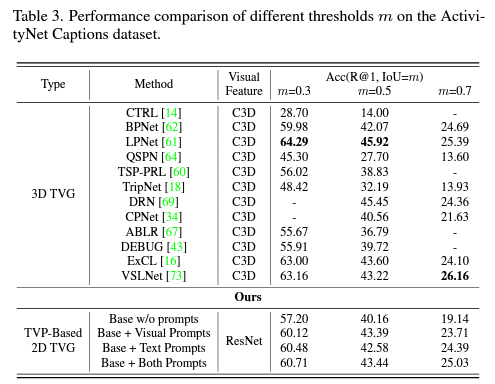
표 2, 3은 각각 Charades-STA, ActivityNet Captions 데이터셋 벤치마크 성능입니다.
Introduction에서 보여드렸던 그림 1-(d)에서의 정량적 성능을 알아볼 수 있는데요, 저자가 정의한 문제점이 어느정도 해결되었는지를 보기 위해서는 3D model과의 성능 차이를 살펴보아야할 것입니다. ActivityNet Captions 데이터셋에 대해 2D model의 성능이 reporting된 것이 없기에 Charades-STA 데이터셋 기준으로 본다면, 무려 IoU=0.3 기준으로 저자의 TVP가 SOTA 성능을 달성하고 있습니다. 나머지 IoU 기준에서는 3D model보단 낮지만 기존 2D model들보다는 압도적으로 높은 성능을 보여주고 있습니다. 이 정도면 성능 측면에서 두 방법론의 간극을 메워가고 있다고 볼 수 있을 것 같습니다.
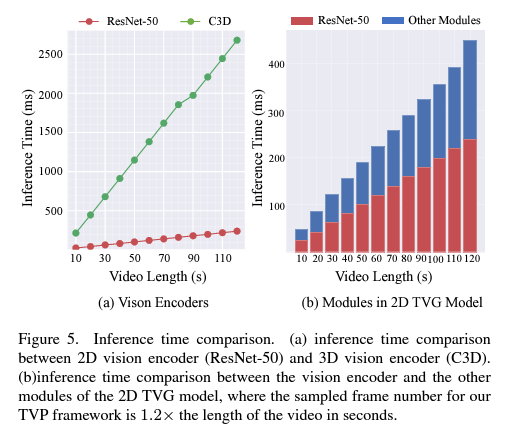
사실 성능-inference time 간 trade-off 관계에서의 간극을 메웠는지 봐야하기 때문에, 위 그림 5에 나타난 각 model의 inference time도 함께 비교해보아야 할 것입니다. Inference time은 비디오에 대한 feature extraction 시간 + 예측을 수행하기 위한 TVG module 시간으로 나눠볼 수 있습니다. 저자에 따르면 2D model이든 3D model이든 feature extraction 시간이 전체 inference time의 절반 이상을 차지한다고 합니다. 이 와중에 3D model의 feature extraction 시간이 2D model의 feature extraction 시간보다 5배 이상 길며, 3D model의 feature extraction만 수행해도 2D model의 모든 inference를 마칠 수 있을만큼 긴 시간이 수반된다고 합니다.
그림 5와 같은 inference time 차이를 보여주며 표 2, 3에서의 성능 차이면, 저자들이 제안한 방법론이 충분히 효율적이면서 효과적이라 이야기할 수 있을 것으로 보입니다.
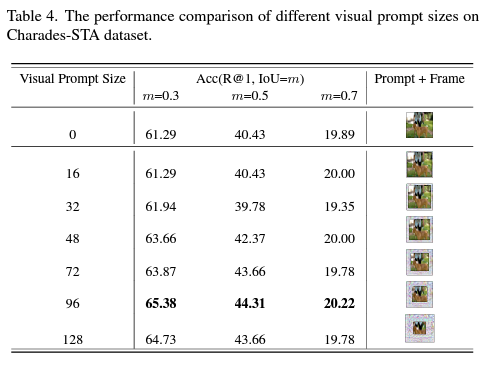
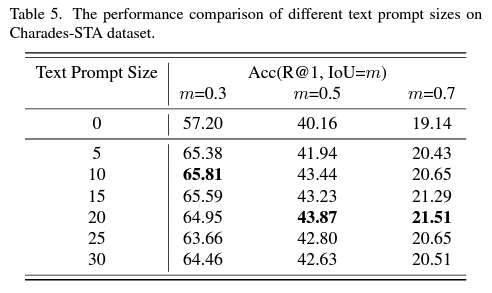
다음으로 표 4, 5는 각각 Visual Prompt의 크기와 Text Prompt의 크기에 대한 ablation 실험입니다. 앞서 detail을 설명드릴 때 visual prompt가 프레임의 가장 자리에 어떻게 들어가는지 쉽게 그려지지지 않는 분들이 계실 것이라 생각했는데, 이에 대해서는 그림 4를 보시면 될 것 같습니다.
Visual prompt는 어느 정도 크기를 계속 키워갈수록 성능이 오르다가 96에서 수렴하는 것을 볼 수 있습니다. 반면 text prompt는 visual prompt보다 상대적으로 크기가 작은 것을 볼 수 있습니다. Text prompt의 크기가 작은 scale에서도 잘 동작하는 이유는, text feature는 각 768차원, visual feature는 각 2048차원이기에 더 적은 개수만으로도 text를 잘 표현하는 prompt를 최적화시킬 수 있음과 동시에 visual prompt는 feature 추출 이전에 붙지만 text prompt는 추출된 feature 이후에 붙어 상대적으로 직접적인 최적화가 진행되기 때문이라고 예측해볼 수 있습니다.
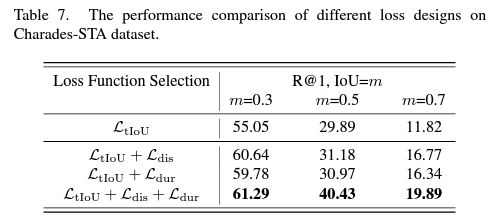
마지막으로 loss ablation 성능만 살펴보고 마무리하겠습니다. TDIoU loss보다는 prompting 부분이 핵심 contribution이라 생각했기에 큰 성능 향상을 기대하지 않았는데, 위 표 7을 보니 두 loss \mathcal{L}_{\text{dis}}, \mathcal{L}_{\text{dur}}이 베이스라인 대비 굉장히 큰 성능 향상을 불러왔음을 알 수 있습니다.
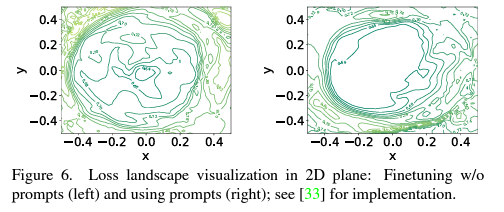
저자는 이러한 성능 향상과 관련해, 그림 6에서 볼 수 있듯 두 loss가 안정적인 loss landscape을 형성하며 학습 중 local minima에 빠지는 현상을 계속 방지해주었기 때문이라고 이야기하고 있습니다.
추가적인 hyperparameter 실험은 논문에 또 담겨있으니 질문 주시거나 논문을 참고해주시기 바랍니다.
이상으로 리뷰 마치겠습니다.
감사합니다.
좋은 리뷰 감사합니다.
베이스라인이 CLIPBERT라는 것은 사전학습된 CLIP을 사용했다고 보면 되나요? 해당 논문 뿐만 아니라 다른 논문에서도 CLIP을 기본적으로 많이 사용하는지 궁금합니다.
그리고 loss landscape 실험은 시각화를 어떻게 햇는지 나와있나요?? 그림을 어떻게 봐야하는건지 모르겠습니다
ClipBERT의 Clip은 저희가 이야기하는 CLIP이 아닌 비디오의 Clip을 의미합니다. Visual encoder는 R-50, Text encoder는 BERT와 동일한 12층 transformer를 사용합니다. 뭔가 CLIP을 활용하면 적당한 task로 보이는데, 신기하게도 최근 연구들은 모달 각각의 인코더를 태운 뒤 intereaction을 잘 수행하는 방향으로만 진행되고 있습니다.
Loss landscape의 시각화는, 저자들에 따르면 아래 논문을 참고하였다고 합니다.
– Visualizing the Loss Landscape of Neural Nets
그림을 확대하여 보시면 선에 작은 글씨들이 함께 적혀있는데, 결국은 상대적으로 평평한 loss landscape이 형성되며 local minima 굴곡 자체가 landscape 자체에서 사라지고, 이를 바탕으로 안정적 학습이 가능해진다는 의미입니다.
안녕하세요. 김현우 연구원님.
좋은 리뷰 감사합니다.
Visual prompt라는 건 처음봐서 굉장히 흥미롭네요. 다른 task이도 적용할만한 아이디어 같습니다.
궁굼한 점이 2가지 있는데요.
1. 방법론 소개 중 pixel-BERT라는 것이 등장하는데 앞선 clipBERT와는 어떻게 다른 건가요?
2. 기존 textual prompt learning 방법들을 보면 텍스트 앞뒤로 프롬프트를 넣는 방식인데, 본 논문에서는 이미지의 외곽 부분을 prompt로 대체한 모습입니다. 이는 결국 가장자리 정보의 손실을 의미하는데, 혹시 padding 방식으로 실험도 진행되었는지, 이렇게 정보 손실을 동반한 방법이 데이터셋의 특성(중요 정보가 화면 중심에 위치하는 경향 등)과 연관이 있지 않을지 현우님의 생각이 궁굼합니다!
감사합니다.
1. Pixel-BERT는 ClipBERT와 거의 동일하게 Visual feature와 text feature를 embedding한 후 하나의 Trasnformer로 넣어주게 됩니다. 이후 본문에서 설명드린 Image-Text Matching, Masked Language Modeling task로 사전학습을 진행합니다. 하지만 visual input이 비디오가 아닌 영상이고, 이를 바탕으로 VQA, Image-Text Retrieval 등의 downstream task를 수행합니다.
Pixel-BERT는 visual 부분 여러 입력 토큰이 한 영상으로부터 나오고, ClipBERT는 비디오에서 일부 프레임들이 sparse하게 sampling된 뒤 이러한 프레임들이 embedding되어 들어간다고 생각하시면 됩니다.
2. 우선 논문에 visual prompt 관련 실험이 있었습니다. 가장자리 픽셀값들에 visual prompt를 (더할지, 대체할지)에 대한 성능 비교였는데요. 일단 현재 방법론처럼 대체하는 것이 가장 높은 성능을 보였습니다.
질문해주신 것이 이렇게 영상 픽셀을 prompt가 대체하는 것이 아니라, 원본은 그대로 두되 해상도 자체를 늘리는 방식은 왜 사용하지 않았는지라고 이해하였습니다. 이러한 이유에 대해 저자가 논문에서 언급한 바는 없습니다.
Visual prompt를 처음으로 제안한 논문은 아래와 같습니다.
– Exploring Visual Prompts for Adapting Large-Scale Models
아래 논문에서 6.2절에 design과 관련된 이야기가 나오는데 이 실험 결과에 따라 저자도 prompt의 형태를 따라간것으로 보입니다.
감사합니다.