안녕하세요. 이전에 쓴 논문 리뷰 몇 편을 다시 보았는데, 설명이 장황하여 길기만 한 느낌이였습니다. 이번 리뷰부터는, 제가 생각한 논문의 핵심 내용을 중점으로 다루고자 합니다. 이번 리뷰에서는 서베이 논문에 대해 언급하고자 합니다.
신년 세미나를 통해 Few-Shot + OD에 대한 연구 방향에 대해 말씀드렸는데, 이전 3-4편의 논문 리뷰를 보면 여전히 해당 분야에서의 성능은 좋은 모습을 보여주지 않습니다. 그러면서 Transfer-Learning, Meta-Learning 등의 다양한 접근법을 적용해보는 추세입니다. 현재까지 해당 추세가 이어져오는데, 예를 들어 Meta-Learning 방법이 Few-Shot OD의 일반적인 방법으로 받아들여질때쯤, Fine-Tuning만으로 이전의 성능을 모두 이기는 등, 다양한 관점에서 연구되며 성능이 엎치락 뒤치락 하는 모습을 보입니다. 그래서 이번에는 Survey 논문을 읽어 전체적인 흐름을 파악하고자 합니다.
이전에 ‘Survey 논문은 깊이없는 Related Work‘라는 고정 관념이 있었지만 이번 CSUR (ACM Computing Surveys), 무려 2023 IF 14.324의 저널에 기고된 서베이 논문을 읽다보니, 과거 연구로부터의 흐름을 파악하는데 도움이 되었습니다. 그럼 37장의 논문, 이번에는 Few-Shot과 관련된 부분에 대해 살펴봅니다.
Introduction
다들 아실 내용일테지만, 2-Stage로 대표되는 R-CNN, Fast R-CNN, Faster R-CNN은 Region Proposal (Selective Search: R-CNN / RoI Pooling Layer: Fast R-CNN / Regoin Proposal Network (RPN): Faster R-CNN)의 결과로 나온 RoI에 대한 Classification과 Regression을 진행합니다. 반면, 1-Stage로 대표되는 Yolo-style (Yolo, SSD, RetinaNet)은 사전에 정의한 Anchor를 토대로 Detection을 진행합니다. 이외에도 최근에는 transformer 기반의 DETR, Anchor-Free 기반의 검출 모델 등 다양한 모델이 등장하고 있습니다.
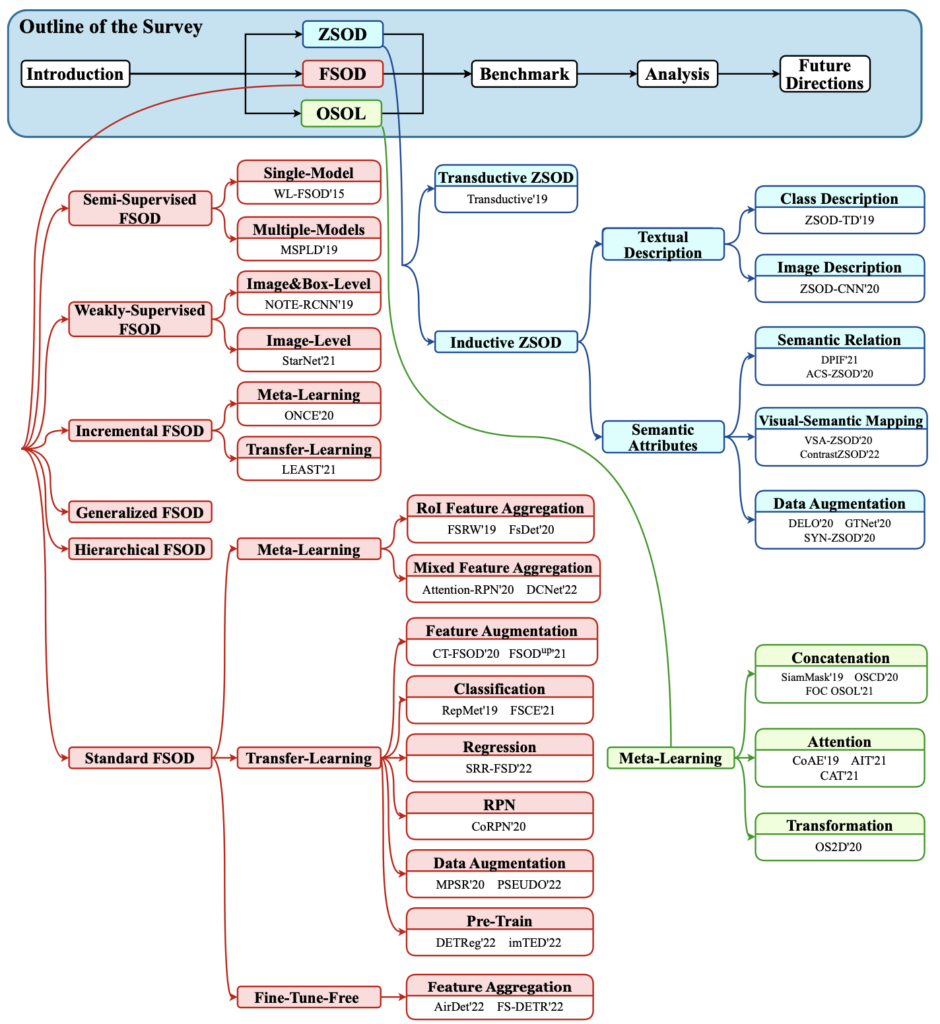
하지만, Object Detection (OD)는 학습 데이터가 부족한 상황에서 과적합 등의 이유로, 좋은 성능을 보이지 못합니다. 실제로 어노테이션된 데이터가 모델의 성능을 일정 측면 보장하지만, 비용 측면이 문제 될 수도, 해당 클래스가 희귀할 수도 있습니다. 신년 세미나 이전에도 몇 번 언급한 내용이죠. 일 년 넘게 OD의 논문을 읽은 저한테는, 이 태스크의 필요성은 너무나도 확실해 보입니다. 해당 문제를 풀고자 Low-Shot Object Detection (LSOD) 로 대표되는 세 방법들, One-Shot Object Localization (OSOL), Few-Shot Object Detection (FSOD), Zero-Shot Object Detection (ZSOD)이 등장합니다. 이 태스크들은 영상 외의 정보를 필요로 하는지에 따라 (ZSOD는 영상 외에 각 클래스의 의미론적인 정보 (e.g. CLIP)에 따라 클래스를 구별함) 다시 OSOL, FSOD / ZSOD로 나눌 수 있습니다.
따라서 이번 리뷰에서는 영상 정보로만 진행하는, OSOL과 FSOD에 대해 주로 알아봅니다. OSOL과 FSOD는 Few-Shot Learning (FSL)을 바탕으로 발달되어 왔으며, 그러므로 학습 방식 또한 FSL을 따릅니다. FSL은 전체 데이터에 대해 일차적으로 전체 클래스에 대해 많은 수의 어노테이션된 샘플 (Base Dataset)과 Base Dataset과 겹치지 않은 클래스에 대한 작은 수의 어노테이션된 샘플 (Novel Dataset)로 나눈 후, 다시 Novel Dataset을 one-, few-의 학습을 위한 데이터 (Support Sample)와 평가를 위한 데이터 (Query Sample)로 나누어 진행합니다.
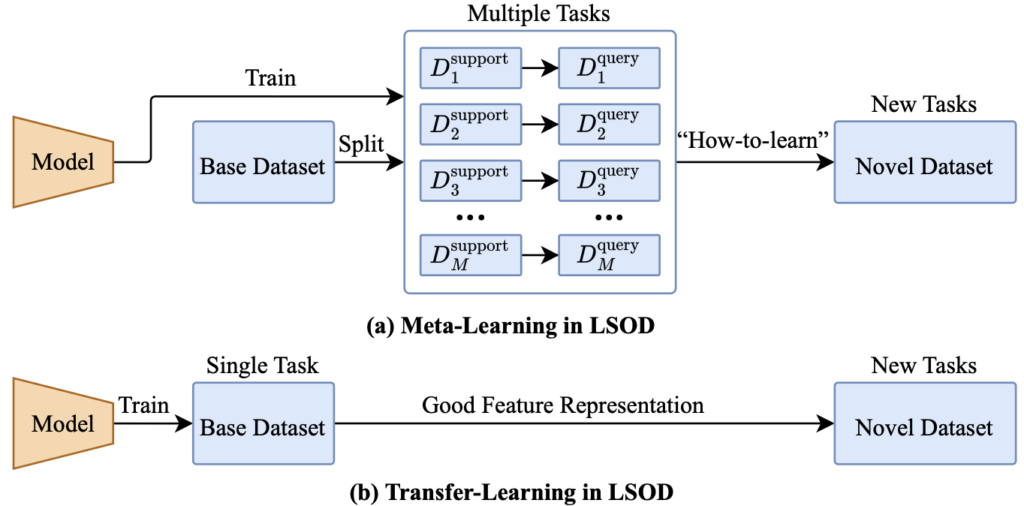
현대의 FSL은, Meta-Learning (META)과 Transfer-Learning (TL)을 접목하는 방법으로 나뉩니다. 그렇다면, META와 TL에 대해서도 알면 좋습니다. 이전 리뷰들에서 설명하였으니 이번에는 간략히 설명하자면: META는 학습하는 방법을 학습하는 메커니즘으로, 주로 전체 Base Dataset을 나누어 다수의 FSL 데이터 셋을 정의하여 모델을 학습하여 실제 FSL 태스크에 빠르게 적용할 수 있도록 하기를 목표합니다. 반면, TL은 Novel Dataset을 위해 Base Dataset을 학습 시 좋은 Representation을 획득하기를 목표로 합니다. 맨 처음 언급한 바와 같이 META는 FSL을 위해 더욱 근본적인 접근법으로 연구되고 있었으나, 2020 ECCV “Rethinking few-shot image classification: a good embedding is all you need?” 에서 TL을 활용한 접근법이 특히 Cross-Domain FSL에서 META의 성능을 앞도하는 모습을 보이며 아직 FSL을 위한 정설은 없습니다. 하지만, FSL은 이미지 분류 연구의 흐름에 따라 발달되어가는 반면, OSOL과 FSOD는 객체의 위치를 찾아야하는 문제를 포함하므로 아직 주류로 연구되고 있지는 않습니다.
그렇다면 OSOL과 FSOD를 볼까요? 우선 OSOL은, 현실적인 태스크로 보기는 어렵습니다. 2019년 즈음, FSOD에 대해 이제 막 연구되고 있을 때 워낙 처참한 성능을 보이다보니 ‘우선 얘부터 풀어보자’는 측면에서 약 2년가량 연구되다, 2022년 이후에는 FSOD가 확실히 대체한 모습을 보입니다. 왜냐하면 OSOL은 “영상 내 주어진 객체의 위치를 찾는 태스크”입니다. 예를 들어 “이 영상에서 고양이는 어디에 위치해있을까? BBOX를 잘 쳐봐”와 같죠. One-에서 알 수 있듯 One-Shot에 국한되어 있는데, Support Sample 하나 만으로 Query Sample에서 위치를 잘 예측해야합니다. 이는 과적합.. 보다도 Support Sample이 어떤 Sample이냐에 따라서도 성능 차이가 날 수 있을 것으로 보입니다. 벤치마킹 데이터 셋이 Pascal VOC, COCO인 것을 보아 다행히도 한 영상 내 하나의 객체만 존재하는 영상은 아니겠지만, 자율주행 관점에서 사용되기엔 힘들 것 같습니다.
저자도 정확히 “Not realistic enough since the object classes in the test images are not pre-known in real life”의 표현을 하며 해당 지점을 언급하여 OSOL의 한계를 드러냅니다. 반면 FSOD는 다음의 차이 (1) 객체의 클래스를 예측해야하는 문제 (2) OSOL은 Test (Query) Image마다 Support Image를 샘플링하는 반면, FSOD는 Support Image Set을 한 번 샘플링하여, 전체 Test (Query) Image에 적용합니다. (3) FSOD는 One-일수도, Two-일수도, Ten-Shot일수도 있습니다. 보통, One-, Five-, Ten-, (때로는 30-) 에 대해 벤치마킹 합니다. (4) OSOL은 META의 방법만을 따르는 반면, FSOD는 META 외에도 TL의 방법도 존재합니다. META FSOD의 핵심은 “몇몇의 어노테이션된 샘플 (Support)의 Feature를 추출한 이후, 그들을 Query 영상의 Feature와 통합하여 Query 영상의 클래스와 위치를 예측하도록 돕습니다. 이 때 통합한다 (Aggregation)는 의미는 모델이 Support로부터 적절한 표현력을 가질 수 있도록 촉진하는 작동입니다. 반면, TL FSOD는 Base Dataset에 대해 미리 학습한 이후, Novel Dataset에 Fine-Tuning합니다. 학습하는 Detector, Fine-Tuning 시 과적합되지 않도록 하기 위한 방법 등에 대해 연구되고 있겠네요. 이외에도 Semi-Supervised FSOD, Weakly-Supervised FSOD, Incremental FSOD 등 FSOD는 정말 다양한 방법과 접근법으로 연구되고 있습니다. 아래의 사진을 통해 OSOL, FSOD, ZSOD의 전체적인 흐름을 살펴본 후 우선 OSOL에 대해 간단히 살펴보겠습니다.
One-Shot Object Localization (OSOL)
Task Setting & Framework of OSOL
본 논문의 형식입니다. 각 Task의 Setting (Pipeline)을 소개한 후, 해당 Task 내 Approaches들에 대해 구분합니다. OSOL의 Setting은 앞서 언급하였으니, 한 지점만 짚고 넘어가겠습니다. OSOL은 Base Dataset으로부터 학습한 이후, Query Sample에 대해 예측하기 위한 하나의 Support Image를, 랜덤하게 샘플링하여 고릅니다. 즉, 앞서 언급한 바와 같이 Query에 대응하는 하나의 Support Image가 메 반복마다 변동합니다. 그럼.. 음? Iteration이 많으면 내재적으로 다양한 Support Image를 학습할 수 있는 것 아닌가? 싶네요. OSOL이 FSOD와 크게 다른 점은 OSOL은 사전에 객체의 클래스에 대한 정보를 가지고 있기 때문에 Support Image에서 Potential Object (모델이 전경으로 보는 객체)에 대해, 정말 전경인지 아니면 배경인지에 대한 Binary Classification만을 수행합니다.
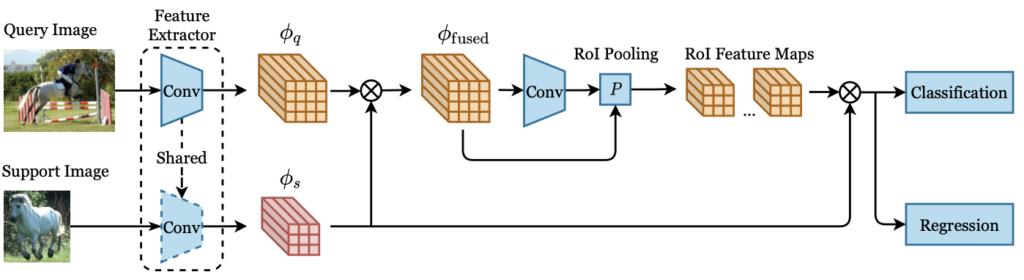
OSOL에 대한 연구가 많지는 않은편이지만, 최근의 OSOL (2021년) 연구들은 모두 META 기반의 Faster R-CNN을 활용합니다. Faster R-CNN을 활용하는 이유는 바로 위의 Potential Object에 대한 Binary Classification, 즉 RPN에서 Binary Classification을 하는 부분에 해당하기 때문이겠죠. OSOL은 보통 다음의 파이프라인으로 행해집니다. 1) 동일한 백본 네트워크로부터 Support와 Query의 Feature를 추출 2) 두 Feature map을 융합하기 위한, 연구들만의 “Feature Aggregation” 작업 수행 3) 융합된 Feature map은 RPN과 RoI Layer를 통과하여 카테고리 별 Region Proposal과 그에 해당하는 RoI Feature map 생성 4) 마지막으로, RoI Feature map은 Classification과 Regression 수행. 이 때 (Binary) Classification에서 True로 명명된 BBOX에 대한 Regression 결과 확인. 방법들도 매우 간단합니다. OSOL에 대한 정의, FSOD와의 차이점, 파이프라인 등을 알아보고자 작성하였으므로, 여태의 연구들은 아주 간단히 짚고 넘어가겠습니다.
Concatenation-Based Methods
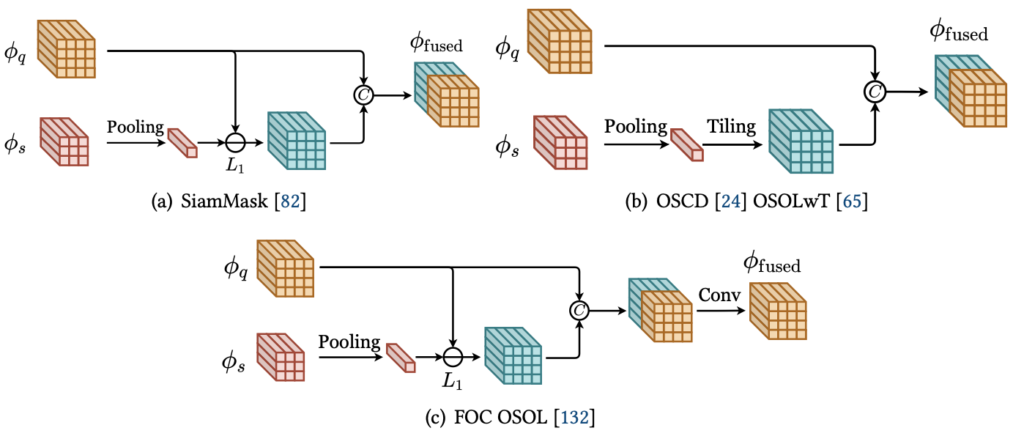
정말 우리가 아는 Feature map을 채널 축으로 Concat하는 연산입니다. 음, 이 점은 우리가 잘 아는 KAIST Pedestrian Detection 태스크와 결부지으면 이해가 잘 되겠네요. RGB와 Thermal의 Feature를 어떻게 융합할지에 대한 관점에서 채널 축으로 Concat하는 Halfway Fusion과 그 이후의 후속 논문들과 동일하다고 보면 좋습니다. 우선 처음 나온 SiamMask는 단순히 Support Feature map: \phi_{s} 을 채널 축에 대해 Pooling한 Embedding Vector v_s 를, Query Feature map: \phi_{q} 과의 차이에 대한 Feature map을 다시 \phi_{q} 와 채널 축 Concat한 Feature map을 활용합니다.
Siammask가 단순히 Pooling, 차이, Concat만으로 이루어진 단순한 구조로, 좋은 성능을 보이지 못했으며 다음으로 나온 OSCD는 SiamMask의 Pooling한 벡터를 Tiling한 이후 \phi_{q} 와 Concat합니다. 더 단순한 구조죠. OSOLwT, FOC OSOL와 같은 논문들도 나왔지만, 그들 또한 OSCD의 구조 뒤 Convolution Block을 쌓아 올린 것에 지나지 않습니다. 말로만 단순히 설명하여 헷갈린다고 생각 들 수 있으나, 아래의 그림을 보면 아. 정말 끝이구나 생각이 들 것 입니다.
Attention-Based Methods
Concatenation-Based Method는 구현이 쉽다는 장점이 있지만, 단순히 채널 축 간의 연관성을 고려하므로 Query와 Support의 Feature 간 지역적 연관성을 활용하기엔 한계가 있습니다. 단순한 예로 객체가 회전되어 있으면, 두 Feature map 상 Spatial Information이 달라지는 문제가 발생하겠죠. 따라서 등장한 Attention을 활용한 방법이 등장하였습니다.
대표적으로 CoAE는 Non-Local Attention 연산 (Non-Local Neural Network: Long-Range Dependencies를 고려하고자 등장한 Attention 방법, ViT의 시초격)인 Co-Attention 연산과, 연산 이후 Pooling Embedding Vector v_s 와의 채널 축 곱 연산인 Co-Excitation 을 통해 Query와 Support 간 Spatial Relationship을 고려하고자 등장하였습니다. 다음의 수식을 보아도 이해가 어렵다해도, 그림을 보면 바로 이해될 것입니다. (1) \phi^{ca}_{fused} = \phi_q \oplus \psi(\phi_q, \phi_s) : Query와 Support 간 Non-Local Attention 연산 ( \psi ) 이후의 Feature에 대해 Query Feature와 더함. (2) \phi^{ce}_{fused} = \phi_q \otimes Pool(\phi_s) : Pooling Embedding Vector와 Query를 채널 축으로 곱함.
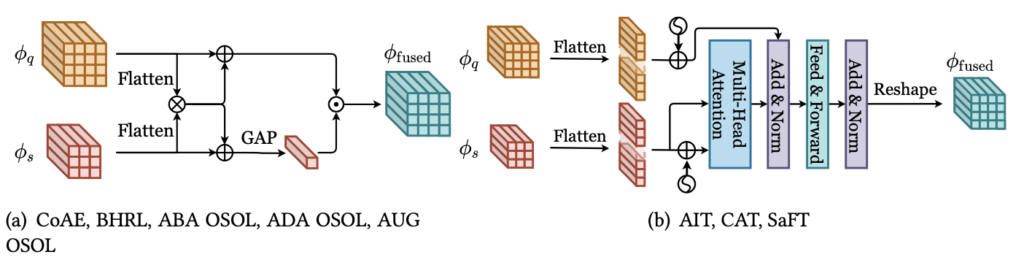
CoAE 이후의 논문 (BHRL, ABAOSOL, ADA OSOL, AUG OSOL)은 모두 Co-Attention과 Co-Excitation을 기반으로 하고 있습니다. 해당 연산이 Spatial 간 연관성 및 Long-Range Dependencies도 고려한다는 점에서, 그러면서 구현이 어렵지 않다는 점에서 높은 이점을 가지고 있습니다. 해당 Attention 외, 우리가 Attention이라고하면 가장 일반적으로 떠올리는 Transformer 기반의 Attention 연산을 활용한 OSOL 방법들도 나왔습니다 (위 Figure-(b): AIT, CAT, SaFT). 다만, 일반적인 Transformer-Based Attention 외 특이점은 없는 듯 보이네요. Attention 기반의 연산은 성능 향상에 큰 기여를 하지만, 더 좋은 Attention 연산을 위한 Transformer 기반의 방법은 많은 양의 연산량을 필요로 하는 단점이 존재합니다.
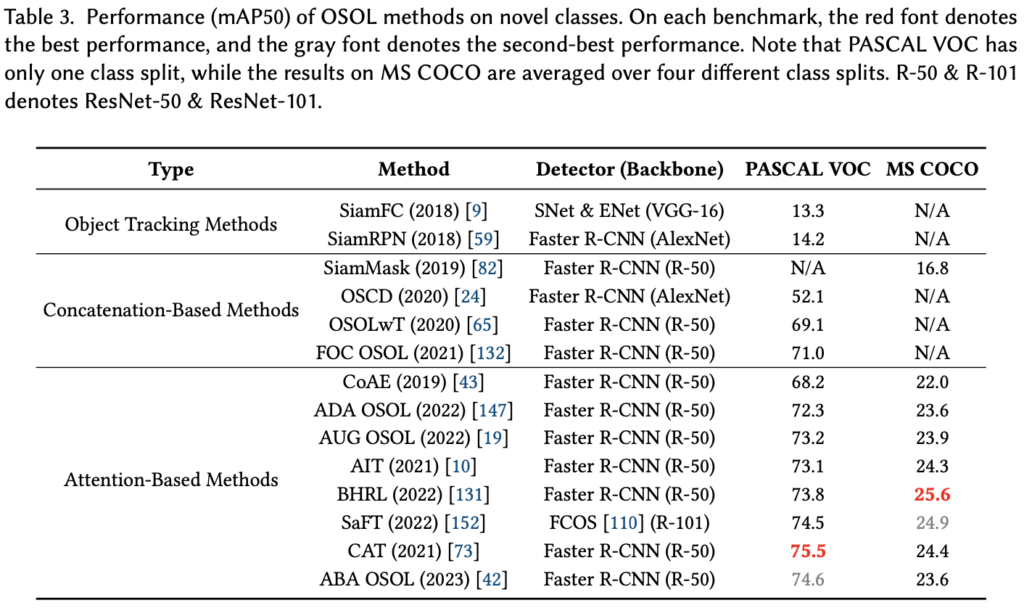
이외에도 사전학습한 TransformNet을 통해 Query와 Support 간 Spatial Align을 위한 Transformation Matrix를 구한 후, 해당 Matrix를 토대로 Query와 Support 간 4D Correlation (Query Feature map 사이즈, Support Feature map 사이즈)을 연산하는 방법도 존재합니다. 이제 OSOL을 전체적으로 요약하자면, Concatentation-Based는 구현이 쉽고, 연산량이 작은 장점이 있지만 성능이 좋지 못합니다. 반면, Attention-Based는 Query의 전경과 Support 이미지에 상응하는 연관성을 계산할 수 있다는 점에서, 좋은 성능을 보이지만 많은 연산량을 필요로하는 단점이 있죠. 바로 직전에 언급한 Transformation 기반의 방법은, 해석력이 좋아 왜 그런 결과가 나오는지에 대해 설명하기 좋지만, 큰 사전학습 모델이 필요하단 단점이 있습니다. 어느 접근법이 절대적으로 좋다고 말할 수는 없지만, 한 가지 확실한 점은 해당 태스크 자체가 현실상에서 쓸모있게 사용되긴 어려워 보입니다. 그러므로 우린 아래 Figure를 통해 성능만 간단히 살펴본 후, 다음 번에는 FSOD를 살펴보도록 하겠습니다. (기차에서 글 편집하려니 힘드네요. FSOD에 관해서는 2탄에서 찾아뵙겠습니다.)
안녕하세요 ! 좋은 리뷰 감사합니다.
읽어본바에 따르면 OSOL은 객체에 대한 클래스를 알고 있다고 하는데 그럼 Unknown object는 입력으로 들어올 수 없다는 의미인가요 !??!?!
또, 벤치마킹에서 Pascal VOC와 COCO는 클래스가 중복되지 않나요? 이런 태스크들은 랜덤 등의 세팅이 매우 중요할 것 같은데, 현재 어떻게 다루고 있는지 궁금합니다!
감사합니다.