24년도를 맞이해서 처음 작성하는 x리뷰네요. 이번에 소개드릴 논문은 DistractFlow라는 방법론으로 mix-up 기반 data augmentation을 통해 optical flow의 성능을 향상시키는 방법론입니다.
Intro
optical flow는 두 연속되는 프레임 사이에 픽셀 별 offset을 계산해야하는 task입니다. 즉 이전 프레임과 현재 프레임의 픽셀 움직임이 얼만큼 차이나는지를 알아야 하는데 이때 모델 학습을 위한 GT를 구하는 것이 상당히 어렵습니다. 따라서 unlabeled data를 어떻게 잘 쓸 수는 없을까에 대한 연구가 꾸준히 진행되어오고 있습니다.
가장 기본적으로는 teacher-student distillation approach가 존재하는데, 이러한 방법론들은 teacher와 student network 사이에 전체 영상 속 loss를 계산하기 때문에 teacher model의 local uncertainty 부분을 잘 고려하지 못한다고 합니다.
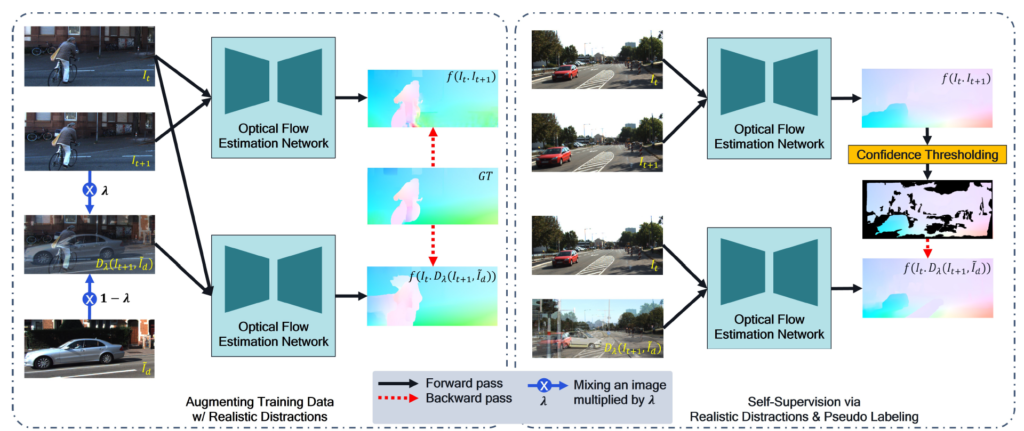
본 논문에서 저자들은 distracted image pair를 활용하여 모델이 semantic correspondence를 더 잘 학습할 수 있는 방법론을 제안합니다. 여기서 distracted image pair란 두 장의 서로 다른 영상을 mixup하여 만든 영상을 의미합니다.
이러한 distracted image와 원래의 영상 간에 쌍을 optical flow 모델에 입력으로 넣어 예측을 수행하고, 해당 예측값을 실제 GT와 비교하는 식의 data augmentation 관점에서 학습 방식이 하나 존재합니다.
또한 둘째로는 real GT를 활용할 수 없는 상황에서, mixup data augmentation을 취하지 않은 원본 영상으로 추론한 optical flow map을 pseudo GT로 삼아 (mixup을 취하여 만든) distracted image pair에 대한 optical flow 추론 학습에 사용한다는 점입니다.
결과적으로 mixup을 활용하면 supervised setting에서도 좋은 성능을 보일 수 있으며 동시에 unsupervised 상황에서도 학습을 수행할 수 있다는 것이 이 논문에 가장 큰 contribution으로 보입니다.
Method
그럼 방법론에 대해서 알아보도록 하겠습니다.
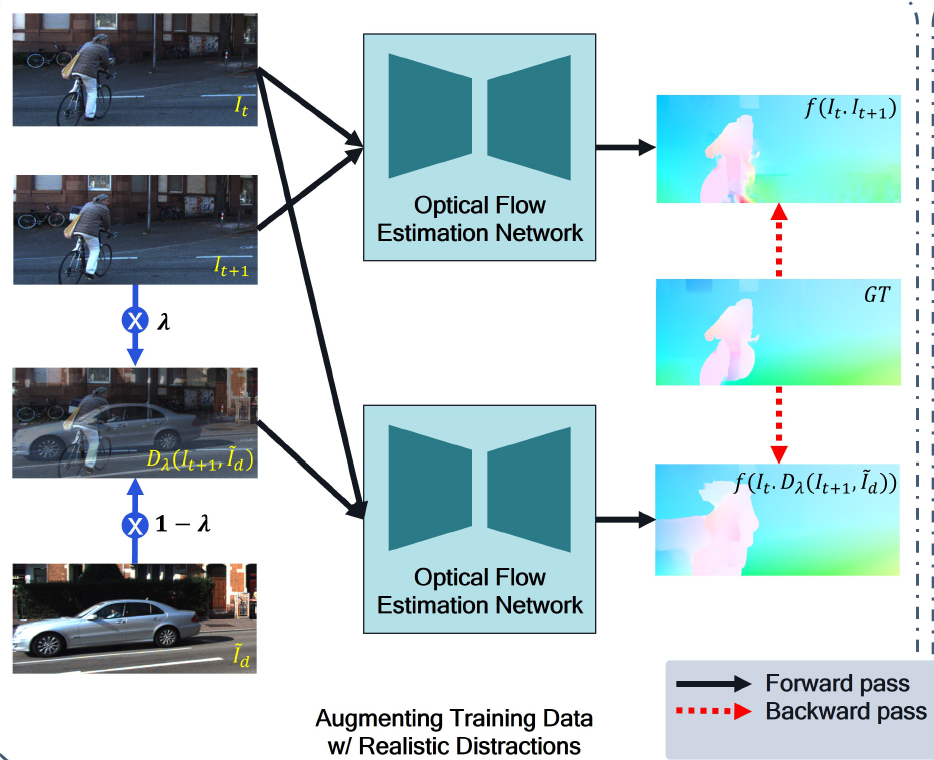
그림2를 잘 살펴보시면 좌측에 람다값을 이용하여 distracted image를 생성하는 것을 확인하실 수 있습니다. 여기서 이 distracted image와 원래의 image 사이에 관계는 실제 환경에서 발생할 수 있는 어려운 상황들을 묘사할 수 있다고 합니다. 보다 구체적으로, 한쪽 frame에서는 보이지만 시간의 흐름에 따라 다른쪽 프레임에서는 대상이 보이지 않는 occlusion 현상이나, 모션 블러 등 대상이 분명하게 보이지 않는 상황들을 묘사할 수 있다는 것이죠.
그리고 이러한 distracted image와의 관계를 계산하기 위해서는 모델이 두 영상 간에 대응관계를 계산하기 위해서 더 많은 semantic 정보를 고려할 수 있도록 학습이 된다고 합니다.
mixup기반의 데이터 합성 방식에 대하여 장점을 말씀드리면 다음과 같습니다. 먼저 인위적으로 어려운 상황들을 합성하는 다른 방법론들과 달리, 서로 다른 장면을 일정 비율(람다)만큼 섞어서 만들기 때문에 만드는 과정이 매우 간편합니다. 또한 동일한 모달리티의 데이터를 활용하기 때문에 물리적 특성들( 가령 도로나 하늘, 빌딩 등의 위치 및 class 정보들)이 매우 유사하여 너무 터무니 없는 상황들이 연출되지 않으며 자연스러운 합성 영상을 생성할 수 있다고 합니다.
아무튼 이렇게 mixup을 기반으로 distracted image pair 쌍을 만들면 해당 쌍을 모델의 입력으로 넣어 값을 추론합니다. 그리고 추론한 값은 실제 GT와 아래 수식을 이용해 loss를 계산합니다.
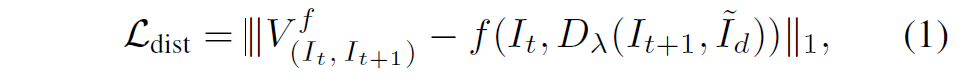
여기서 I_{t}, I_{t+1} 는 각각 t, t+1 frame 영상을 의미하며, f는 optical flow model을 의미합니다. 또한 V, D_{\lambda}, \tilde{I}_{d} 는 각각 ground-truth forward flow map, mixup function, mixup을 수행하기 위한 다른 frame image를 의미합니다.
결국 mixup을 통해 만든 distracted image pair를 optical flow 네트워크에 태워서 생성한 추론값과 실제 GT와 supervision을 하는구나 라고 이해하시면 편할 것 같습니다.
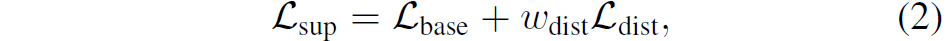
그리고 원본 영상 쌍( I_{t}, I_{t+1} )에 대해서도 flow를 추론하고 실제 GT와 비교하는 loss term인 \mathcal_{base} 도 함께 존재합니다.
Semi-supervised Learning via Realistic Distraction and Pseudo-Labeling
다음은 실제 GT가 없는 unlabeled 상황에서 어떻게 mixup 기반으로 모델을 학습시킬 수 있는지에 대한 내용입니다. 이 부분도 상당히 간단한데, 가장 간단한 컨셉은 mixup이 적용되지 않은 image pair로 추론한 optical flow map을 pseudo GT로 활용하여, mixup이 적용된 distracted image pair를 입력으로 추론한 flow map을 추론 및 학습시키는 것입니다.
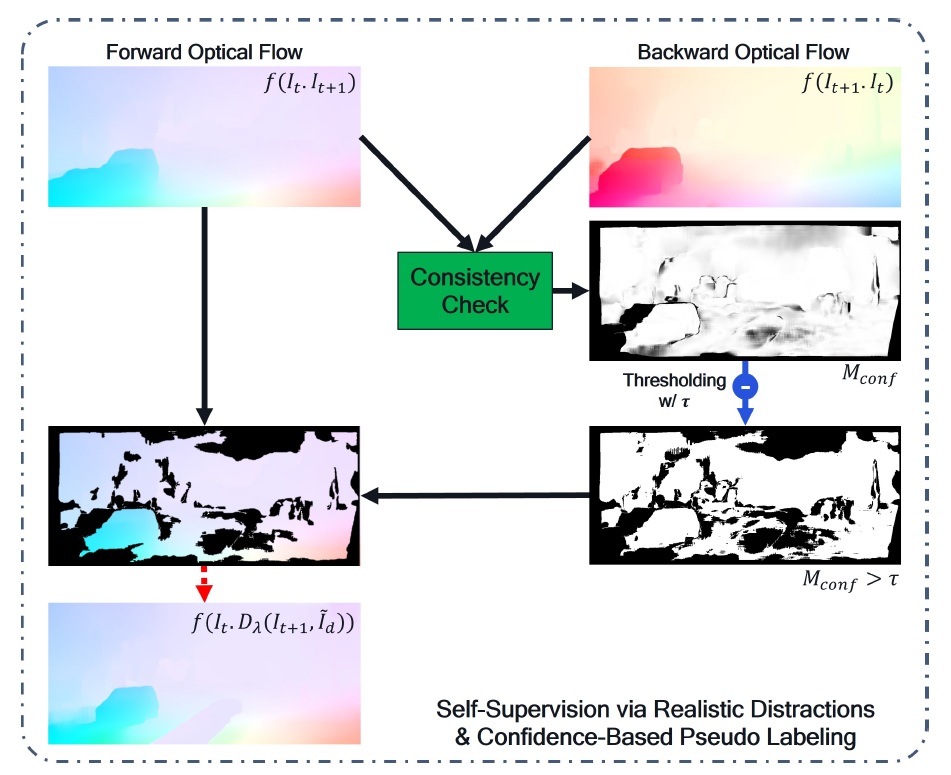
아무래도 mixup을 적용하지 않은 원본 영상 쌍이 입력으로 들어간 경우 mixup이 적용된 distracted image pair보다 훨씬 쉬운 케이스이기 떄문에 모델이 더 정확한 flow map을 추론할 수 있겠죠. 그래서 이를 pseudo GT로 활용하는 것으로 보입니다.
다만 아무리 쉬운 케이스라고 할지라도 한번도 보지 못한 unseen domain에 대하여 모델이 영상 내 모든 픽셀에 대해 정확한 추론을 수행하는 것은 상당히 어려운 일입니다. 따라서 저자들은 forward/backward flow map을 추론한 다음, 이들이 일정 threshold 보다 더 큰 경우 uncertainty로 놓고 이를 제거하는 confidence-aware pseudo-labeling을 수행하였습니다.

forward/backward consistency check에 대해서 이 논문이 새롭게 제안한 것은 아니고, 기존의 optical flow 방법론들이 많이들 활용하는 regularization term으로 이해해주시면 좋을 것 같습니다. 개념에 대해서 간단하게만 다시 설명드리면 (t, t+1) 프레임 순으로 넣은 forward flow map과 (t+1, t) 순서로 넣어서 추론한 backward flow map에 대하여 어떤 픽셀 위치 x가 있다고 할 때 forward(x)와 backward(x+foward(x))가 서로 동일한 대상을 지칭하는 것이기 때문에 크기 값이 동일해야한다는 개념입니다.
결과적으로 이러한 confidence mask를 생성하여 loss 계산 시 confidence가 일정 threshold 이상일 경우에만 학습이 되도록 학습이 진행됩니다.
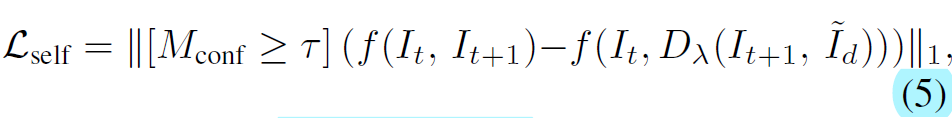
Experiments
그럼 실험 결과에 대해서 소개드리겠습니다.
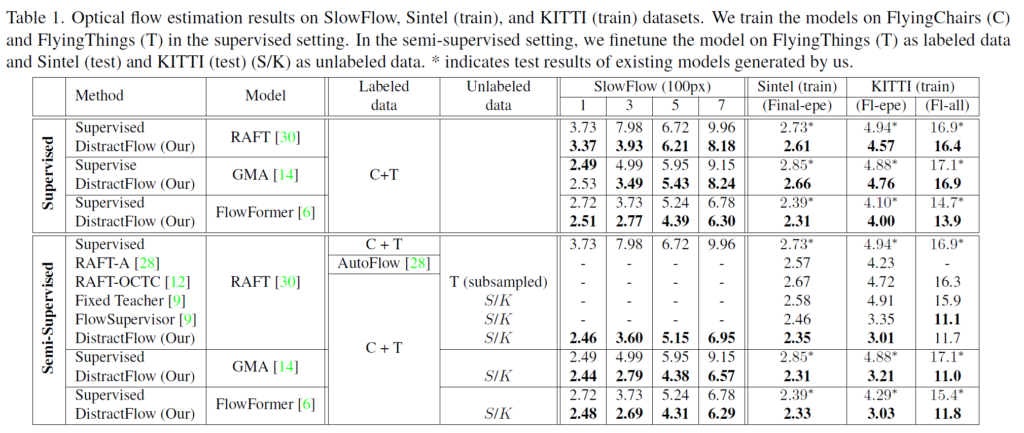
먼저 첫번째 테이블은 supervised와 semi-supervised learning 상황에서 방법론을 나타낸 것입니다. 제안하는 DistractFlow는 결국 mixup data augmentation을 기반으로 하고 있기 때문에 RAFT, GMA, FlowFormer와 같은 다양한 architecture에서 사용이 가능하며 또한 supervised learning만 수행하더라도 해당 방법론을 활용할 수 있습니다. 이러한 관점에서 각 architecture에서 모두 유의미한 성능 향상을 보였다라고 저자는 주장합니다.
그리고 Semi-Supervised learning은 labeled data로 학습하면서 동시에 unlabeled data에 대해서는 실제 GT 없이 수식 5를 통해 학습하는 방식을 의미합니다. 여기서는 다른 learning method(Fixed teacher, flow supervisor) 등과 비교하는 결과가 나오게 되는데, 결과적으로 KITTI train(F1-all)에서 FlowSupervisor를 제외하고는 가장 좋은 성능을 보여주고 있습니다.
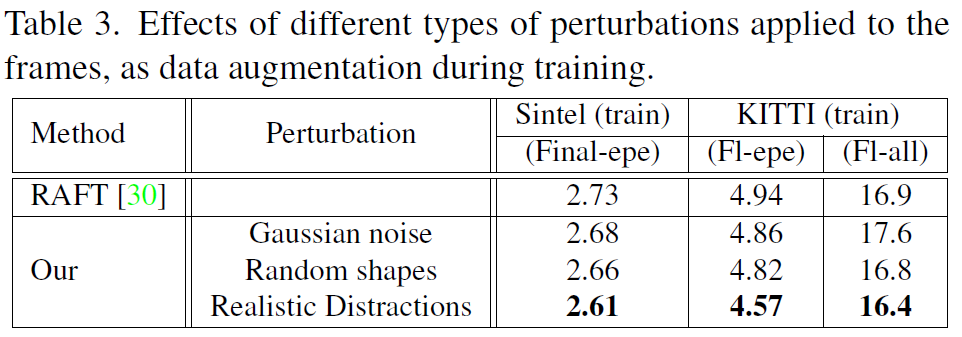
다음은 ablation study에 대한 결과입니다. 가장 먼저 RAFT라는 방법론을 baseline으로 삼은 후, 영상에 data augmentation을 어떻게 적용하는 것이 좋은가에 대한 결과였는데, 결과적으로 Realistic Distractions 즉 mixup 기반의 영상 distraction이 가장 모델 성능 향상에 효과적이라고 합니다.
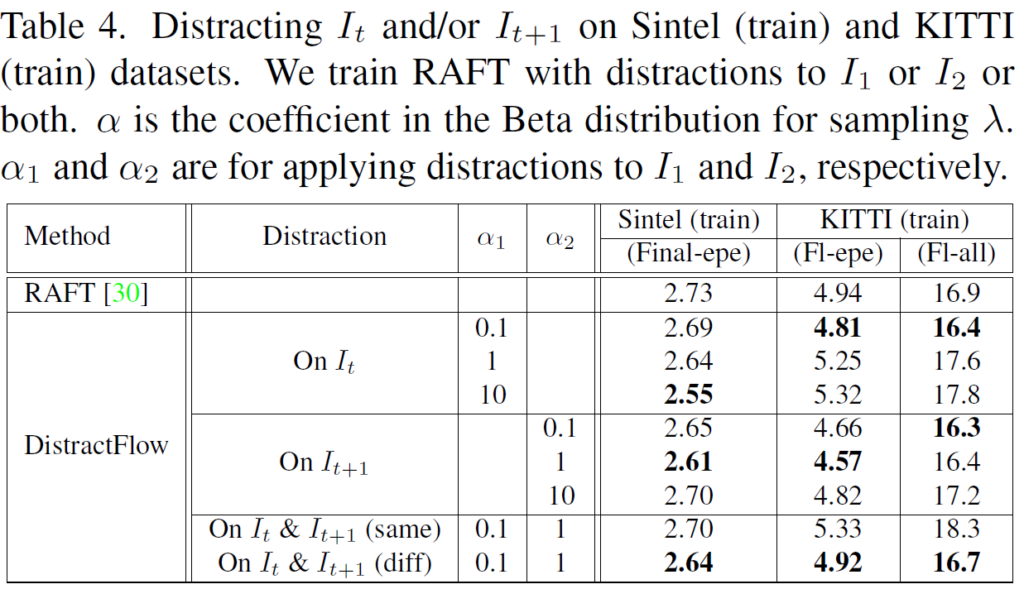
다음으로 위에 실험은 mixup distraction을 t frame 영상에 적용할지, t+1 frame 영상에 적용할지와 적용한다면 어느 수준으로 lambda 값을 설정할지 등을 정하는 비교 실험입니다. 결과적으로만 놓고 보면, t+1 frame에서 distraction을 주는 것이 가장 최적의 성능을 달성할 수 있었다고 합니다.
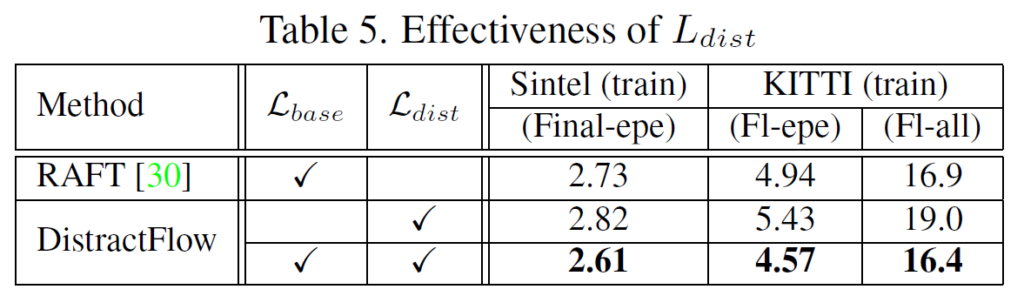
위에 실험은 RAFT 베이스라인에 대하여 loss term을 기존 supervised learning( L_{base})만 할지 아니면 mixup 기반으로 distracted image pair에 대해서만 학습을 할지, 또는 둘다 할지에 대한 ablation study인데 당연하게도? 두 loss term을 같이 쓰는 것이 가장 좋은 성능에 달성하였습니다.
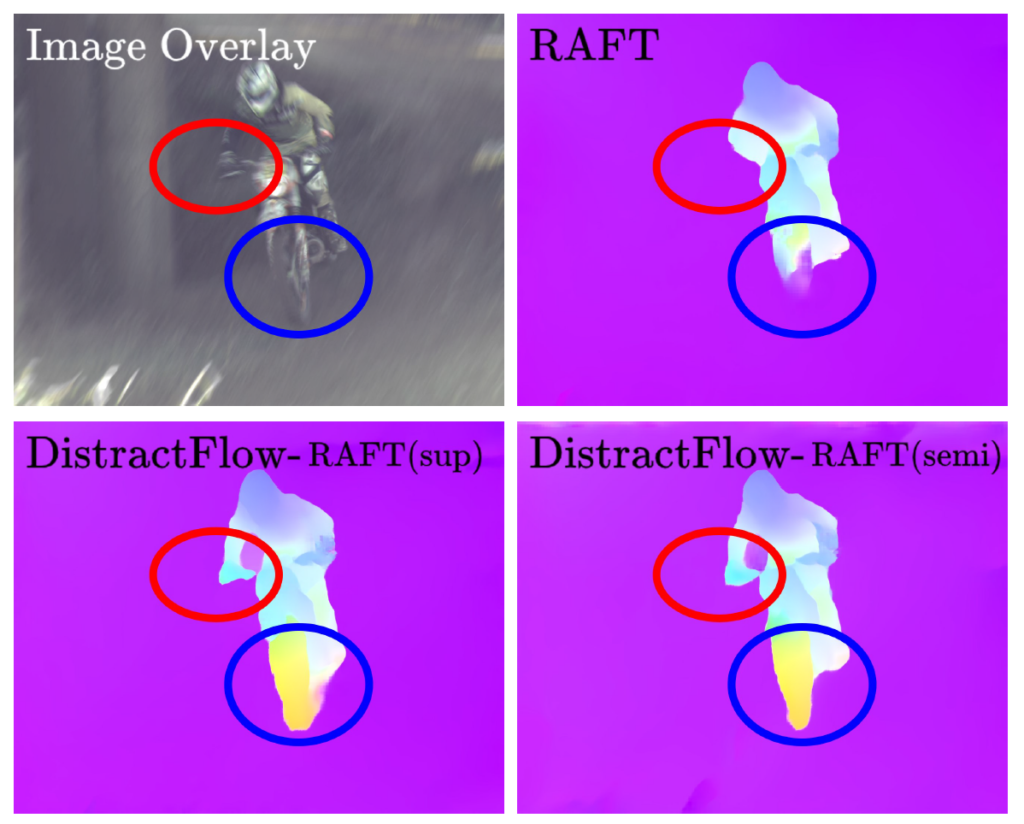
마지막으로, 이러한 mixup 기반의 학습 방식을 통해 영상이 noise/blur한 상황에 대해서도 기존 baseline(RAFT)와 달리 자신들이 제안하는 방법론은 더 강건한 flow map 추론이 가능함을 보여주고 있습니다.
결론
사실 mixup은 영상 분류쪽에서 처음 제안이 되어 많은 task에서 적용이 되었기 때문에 novelty 측면에서 아쉬움이 조금 있지는 않은가 합니다. 다만 optical flow에서는 mixup을 어떻게 활용할지에 대한 연구가 전혀 이루어지지 않았으며, 저자가 처음으로 mixup의 다양한 활용 가능성을? 보여주었기 때문에 CVPR에 accept 된 것이 아닐까 생각이 듭니다.
안녕하세요 정민님 좋은 리뷰 감사합니다~~
본문에서 supervised learning에 적용된 method 부분에서 질문이 있습니다. occlusion 현상이나, 모션 블러 등을 묘사하기 위해서 Id 이미지를 mixup 해줄때 Id 이미지가 선택되는 기준이 따로 있나요?
supervised learning에서 GT는 어떻게 표현되는지도 궁금합니다.
감사합니다.
댓글 감사합니다.
먼저 첫번째 질문에 대한 답으로는 id를 선택하는 기준은 랜덤으로 알고 있습니다.
그리고 supervised learning을 할 때 GT는 mixup이 전혀 없는 원본 GT를 그대로 활용합니다.