이 논문의 주요 키워드
- Weakly Supervised Vision-Language Pre-training (UVLP, WVLP)
- Non-parallel Image-Text Data
- Relative Representation
이 논문을 깊게 이해하려면 다음 지식이 필요합니다.
- Multi-modal contrastive learning에 대한 이해 (CLIP 리뷰 파트 1, 파트 2)
- Unsupervised Vision-Language Pre-training 이전 연구 (μ-VLA 리뷰)
안녕하세요. 백지오입니다.
스물 네 번째 X-REVIEW는 이전 리뷰에 이은 Weakly Supervised Vision-Language Pretraining (WVLP) 논문 리뷰입니다. 칭화대에서 작성된 논문이며 코드는 공개할 예정인지 논문에 링크만 달려있네요. 본 논문에서는 기존 WVLP 방법이 Object Detector를 이용해 추출한 object tag들과 unaligned text 간의 유사도를 통해 weakly-align을 수행한 것과 달리, 조금의 aligned data를 바로 취하여 사용하는 방법을 사용했다고 하는데요, object tag를 사용하는 것이 이미지와 텍스트의 매우 국소적 맥락밖에 고려하지 못하기 때문에, 라벨을 조금은 사용하여 weakly supervised 방식으로 VLP를 수행하는 것이 맞다고 주장합니다만, 이러한 주장을 위해 앞선 unsupervised 방법들이 사실은 weakly supervised라고 주장하며, 라벨을 일부 사용한 자신들의 방법과 비교함에도 그다지 큰 성능 향상을 보지는 못한 논문이라 아쉬운 것 같습니다.
과제와 약간의 흥미로 서베이하고 있는 UVLP 분야의 가장 최신 논문이다보니 읽기는 읽었는데, 썩 좋은 논문은 아니었던 것 같습니다. Relative Representation이라는 개념이 흥미롭기는 한데, 제가 이 분야로 연구를 계속하게 된다면 이 논문을 baseline 삼지는 않을 것 같네요.
아무튼, 리뷰 시작해보겠습니다.
WVLP의 핵심적인 문제는 대규모의 정렬된 이미지-텍스트 쌍을 사용하지 않고 모달리티 간의 연관 정보를 학습하는 것 입니다. 기존 방법들은 일반적으로 이미지로부터 Object Detector를 통해 텍스트 형태의 object tag들을 추출하고, 이를 anchor로 활용하여 이미지와 텍스트 모달리티의 연관을 학습하였는데요. 이미지에 대한 정보를 담고 있으면서도 텍스트 형태인 이 tag들을 이용해 이미지와 텍스트 데이터를 약하게나마 정렬시킴으로써 supervised VLP 방법들과도 견줄만한 성능을 보일 수 있음을 보였습니다.
그럼에도 불구하고 이러한 object tag 방식에는 두 가지 한계가 존재합니다. 먼저 object tag는 이미지의 일부 영역과 텍스트의 일부 명사에 해당하는 아주 국소적인 영역만을 제한적으로 나타낼 수 있는 한계가 있으며, 이러한 tag들의 vocabulary (종류)가 매우 한정적이고 중복된 개념을 담고 있어 복잡한 맥락을 표현하기 어렵다는 점 입니다.
저자들은 이러한 한계로 인하여 object tag를 이용한 VLP에는 근본적인 한계가 있으며, 모달리티 간의 라벨을 전혀 사용하지 않는 것이 올바른 접근인지에 대한 재고가 필요하다고 합니다.
저자들은 최근 representation learning과 zero-shot classification 분야에서 활용된 바 있는 상대적 표현 (relative representation)을 WVLP에 적용하고자 합니다. Relative representation이란, 어떤 데이터를 몇 개의 기준(anchor) 데이터와의 유사도로 나타내는 기법입니다. 저자들은 이러한 방법이 사람이 디자인한 tag가 아닌 잘 학습된 신경망 기반의 표현이며, 데이터 간의 관계를 이용하므로 modality-invariant 하게 적용할 수 있다는 점에서 WVLP에 적용하기 좋다고 주장하며, 이를 적용한 VLP 프레임워크인 Relative rEpresentation-based Language-Image pre-Training, RELIT을 제안합니다.
RELIT은 아주 극소량의 이미지-텍스트 쌍을 앵커로 선정하고, 이들과의 relative representation을 활용해 각 데이터를 나타냄으로써 common relative representation space를 형성합니다. 또한, align 되지 않은 단일 모달 corpora에서 weakly-aligned 이미지-텍스트 쌍을 구성할 수 있는 relative representation 기반 데이터 수집 방법론을 제안합니다. 저자들은 4가지 downstream task에서의 실험을 통해 이러한 방법의 효과를 입증하였다고 합니다.
저자들의 contribution은 다음과 같습니다.
- WVLP에 relative representation을 적용하고 object tag 방법론 대비 우수성을 보임.
- Relative representation 기반의 WVLP 프레임워크를 제안함.
- 4가지 downstream task에서 기존 WVLP 베이스라인보다 좋은 성능을 보이며 VLP와 WVLP의 갭을 줄임.
그러나 저자가 weakly-supervised라 주장하는 기존 방법론들은 라벨을 하나도 사용하지 않은 것이고, RELIT은 극소량이나마 라벨을 사용한 것인데 이를 비교하는 것이 fair한가 의문이 강하게 들기는 합니다. 다만 relative representation이 흥미로우니 계속 읽어보겠습니다.
Related Work
Relative Representation. 어떤 데이터를 기준 데이터들과의 유사도로 나타내는 relative representation은 2022년 제안되어 zero-shot classification 등의 분야에 활용되었는데요, 본 논문은 이를 WVLP에 적용한 첫 시도라고 합니다.
Weakly Supervised Vision and Language Pre-training. 멀티모달 데이터의 매칭 관계 라벨 없이 사전학습을 진행하는 연구는 Unsupervised VLP, VLP without parallel image-text data라는 이름으로 U-VisualBERT (2021)에서 처음 제안되었습니다. U-VisualBERT는 object detector를 이용해 이미지에서 object tag를 추출하여 pseudo caption으로 활용하여 이미지와 텍스트의 cross-modal alignment를 학습했습니다. 이어서 μ-VLA (2022)에서는 object tag와 유사한 caption을 retrieval 하여 이미지 데이터와 텍스트 데이터를 weakly-align 한 후 학습에 활용하여 VLP를 수행했습니다. VLMixer (2022)에서는 CutMix 기법을 통해 VLP를 수행하였고, E2E-UVLP (2022)는 UVLP를 위한 end to end 프레임워크를 제안했습니다. 앞선 연구에서는 task를 unsupervised VLP로 칭하고 있는데 저자들은 이들을 weakly supervised VLP로 칭하며, 제안하는 RELIT은 tag를 anchor로 사용한 앞선 방법들과 달리 relative representation을 사용한다고 합니다.
여기서 앞선 방법들이 label을 전혀 사용하지 않았다는 점은 어물쩍 넘어가는 게 괘씸하네요. 앞서 소개한 논문 중 E2E-UVLP는 동일한 1 저자가 작성한 논문이라 이전 연구 방향을 모르던 것도 아닐 텐데, 너무 편의주의적으로 기존 연구들을 묶는 느낌입니다.
Data Augmentation. 데이터 증강은 딥러닝에서 매우 좋은 성과를 보인 바 있는데요. VLP에서도 매우 방대한 양의 웹-크롤링 데이터에서 저품질의 이미지-텍스트 쌍을 찾아내어 이미지 캡션 모델을 이용해 pseudo-caption을 만들어주는 방식으로 데이터 증강을 적용한 연구가 있었습니다. 저자들은 RELIT에서도 text-only 데이터셋에서 학습된 캡션 모델을 활용해 이를 수행해 줬다고 합니다.
Method
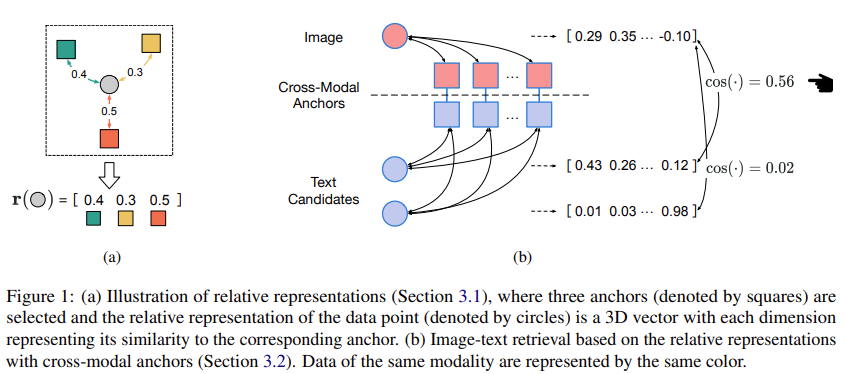
Relative Representations
Relative representation의 아이디어는 어떤 데이터를 기준 데이터들과의 유사도 벡터로 나타내는 것입니다. 이 논문에서는, zero-shot classification task에서 좋은 잠재력을 보인 cross-modal anchor들을 선정하고 데이터들을 이 anchor들과의 유사도로 나타내고자 합니다.
$M$개의 앵커 $\mathcal A = \{ a_1, a_2, \cdots, a_N \}, a_i = \{ \hat x_i, \hat y_j \}$가 주어질 때, $x_i, y_i$는 각각 이미지와 텍스트의 쌍이고, 사전학습된 인코더 $E_I$에 $x_1$을 통과시키면 앵커 $o$와의 유사도는 다음과 같습니다.
$$sim(x, a_i) = \cos(\mathbf E_I(x), \mathbf E_I(\hat x_i))$$
$\cos(\cdot, \cdot)$이 코사인 유사도를 나타낼 때, $x$의 relative representation은 아래와 같이 나타내집니다.
$$\mathbf r_{\mathcal A}(x) = (sim(x, a_1), \cdots, sim(x, a_M))$$
유사하게 텍스트 $y$의 relative representation $\mathbf r_{\mathcal A}(y)$도 사전학습된 텍스트 인코더 $E_T$에 의해 정의됩니다. 데이터 포인트 간의 relationship이 객관적이기 때문에 모델마다 다른 representation space를 가지고 있더라도 relative representation은 유사한 형태를 갖게 됩니다. 따라서, 동일한 쌍의 이미지와 텍스트의 relative representation은 비슷한 형태를 갖게 됩니다.
Weakly-Aligned Image-Text Pairs Retrieval
이미지와 텍스트가 정렬되어 있지 않더라도 모델에 여러 모달의 데이터를 한 번에 입력해 주는 것이 중요한데요. 저자들은 μ-VLP가 retrieval을 통해 정렬되지 않은 단일 모달 데이터셋들로부터 weakly-aligned data pairs를 만드는 것으로부터 영감을 받아 이미지들의 relative representation을 기반으로 연관이 있는 문장들을 retrieval 합니다. 그림 1b에 이 과정이 나와있는데, 먼저 아주 소량의 이미지-텍스트 페어를 얻어 cross-model anchor 삼습니다. 이때 저자들은 이렇게 사용하는 anchor의 수가 일반적인 VLP 모델에서 사용하는 pair의 양보다 현저히 적어 weakly supervised라 할 수 있다고 강조합니다. 이어서, 모든 이미지와 텍스트들의 relative representation을 구해줍니다. 마지막으로 각 이미지와 문장들의 유사도를 비교해 이미지와 가장 유사도가 높은 문장을 매칭하여 weakly aligned 이미지-텍스트 쌍을 구성해 줍니다.
수식으로 표현하면 $M$ 개의 이미지-텍스트 페어를 aligned 이미지-텍스트 데이터셋 $\mathcal D_{align}$에서 추출하여 앵커 $\mathcal A$로 삼고, unaligned 이미지, 텍스트 데이터셋 $\mathcal D_I, \mathcal D_T$의 데이터들의 relative representation을 구하여 weakly-aligned 이미지-텍스트 데이터셋 $\mathcal D_{wa} = \{ (x_1, \hat y_1), \cdots , (x_N, \hat y_N) \}, N=|D_I|$을 구성해 줍니다. 이때 $\mathcal D_I$의 이미지 $x_i$와 매칭되는 $\mathcal D_T$에서 추출한 캡션은 아래와 같이 선정됩니다.
$$ \hat y_i = \arg\max_{y\in\mathcal D_T}\cos(\mathbf r_{\mathcal A}(x_i), \mathbf r_{\mathcal A}(y))$$
이미지와 텍스트의 인코딩에는 각각 사전학습된 ViT와 Sentence-BERT를 사용했다고 합니다.
저자들은 relative representation은 object tag와 다르게 이미지와 텍스트의 전체 맥락을 포착할 수 있기 때문에, relative representation에 기반한 retrieval이 object tag 기반 retrieval에 비해 고품질의 weakly-aligned 데이터셋을 얻을 수 있다고 주장합니다.
Pseudo Caption Generation
아무리 relative representation 기반 retrieval이 좋은 weakly-aligned 데이터셋을 구성할 수 있다고 하더라도, 여전히 이미지에 적절하지 않은 caption이 매칭되는 경우가 있을 수 있는데요. (특히 이미지와 텍스트 데이터가 따로 수집된 경우) 이러한 문제를 해결하기 위해, 저자들은 추가로 pseudo caption generation을 수행합니다.
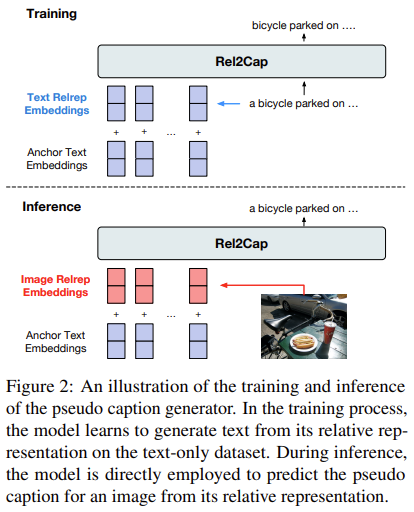
먼저 잘 학습된 text generator를 이용해 relative representation이 주어지면 해당하는 텍스트를 생성하도록 학습시킵니다. 이렇게 파인튜닝된 모델을 이용하면, 이미지의 relative representation이 주어졌을 때 이를 잘 나타내는 캡션을 생성하도록 할 수 있는 것이죠.
구체적으로 텍스트 데이터 $y\in \mathcal D_T$에 대한 relative representation $\mathbb r_{\mathcal A}(y)$로부터 prefix $\mathbf P\in \mathbb R^{M\times d}$를 아래와 같이 유도합니다.
$$ \mathbf P = [\mathbf r_{\mathcal A}(y)]^\top\mathbf W_r + [E_T(\tilde y_1), \cdots, E_T(\tilde y_M)]\mathbf W_e $$
$E_T(\tilde y_i)\in \mathbb R^{d_T}$는 $i$번째 앵커의 텍스트 인코더 출력을 의미하며, $\mathbf W_r \in \mathbb R^{1\times d}, \mathbf W_e \in \mathbb R^{d_T\times d}$는 2개의 학습 가능한 투영 행렬입니다. 이렇게 구해진 $\mathbf P$가 입력되었을 때, $y$를 예측하는 모델을 사전학습된 GPT-2를 파인튜닝하여 만들었고, Rel2Cap이라 이름붙였습니다. 연산량을 줄이기 위해, $\mathbf P$에서 가장 유사도가 높았던 $K$개의 anchor만을 모델 입력으로 주었다고 합니다.
이렇게 학습된 Rel2Cap 모델을 이용해, 저품질의 캡션을 가지고 있는 이미지 $x$의 relative representation으로 구성된 $\mathbf P’$로부터 pseudo caption을 생성할 수 있습니다. 저품질 캡션을 판별하기 위한 quality score는 $s(x, \hat y) = \cos(\mathbf r_{\mathcal A}(x), \mathbf r_{\mathcal A}(\hat y))$와 같이 정의됩니다. 만약 retrieval 된 캡션과의 점수보다 생성된 캡션과의 점수가 높을 경우, 캡션을 생성된 캡션으로 대체한다고 합니다.
지금까지, RELIT이 어떻게 weakly-aligned 이미지-텍스트 데이터셋 $\mathcal D_{wa}$를 구성하는지 살펴보았습니다.
Pre-training
모델 구조는 vision 인코더와 멀티모달 인코더로 구성된 E2E-UVLP와 같은 구조를 사용하였습니다. weakly-aligned 이미지-텍스트 쌍에서 이미지는 vision 인코더에 먼저 입력되고 그 출력을 다시 텍스트와 함께 멀티모달 인코더에 입력하게 됩니다. 이러한 end-to-end 프레임워크는 외부 object detector와 region feature를 사용하는 방법들보다 우수함이 밝혀진 바 있다고 하는데, 다음에 읽어봐야겠습니다.
저자들은 Masked Tag Prediction (MTP), Masked Language Modeling (MLM), Image Text Matching (ITM)의 세 가지 사전학습 objective를 통해 멀티모달 representation을 학습합니다.
Masked Tag Prediction. 이미지 데이터와 데이터에서 검출된 object tag의 object-level cross modal alignment를 수행합니다. 15%의 확률로 tag의 일부를 마스킹하고, 이미지와 다른 tag들을 이용해 복원하도록 합니다. 이미지 $x$와 object tag $t$에 대해 MTP 목적함수는 아래와 같이 정의됩니다.
$$\mathcal L_{MTP} = -\mathbb E_{x\in \mathcal D_I}\log P(t_m|t_{\backslash m}, x)$$
$t_m, t_{\backslash m}$은 각각 masked unmasked tag를 의미합니다.
Masked Language Modeling. 두 모달리티의 융합을 수행하기 위해 MLM을 진행합니다. weakly-aligned 데이터셋에 존재할 수도 있는 노이즈에 대비해 텍스트에서 명사구만을 마스킹하고, 이를 복원하도록 합니다.
$$ \mathcal L_{MLM} = -\mathbb E_{(x, \hat y)\in \mathcal D_{wa}} \log P(\hat y_m | \hat y_{\backslash m}, x)$$
이번에도 역시 $\hat y_m, \hat y_{\backslash m}$은 각각 masked, unmasked text에 해당합니다.
Image Text Matching. ITM은 VLP에서 instance-level cross-modal alignment를 학습하는데 흔히 사용되는 task로, 주어진 이미지-텍스트 쌍이 서로 연관되어 있는지 맞추는 문제입니다. 이미지-텍스트 데이터셋에서 절반의 텍스트를 다른 텍스트로 바꾸고, 주어진 쌍이 바뀐 쌍인지 아닌지를 나타내는 라벨 $l$로 학습을 진행합니다.
$$ \mathcal L_{ITM} = -\mathbb E_{(x, \hat y)\in \mathcal D’_{wa}}\log P(l|x, \hat y)$$
$D’_{wa}$는 랜덤 하게 수정된 데이터셋입니다.
Relative Representation-Guided Training. Weakly-aligned 데이터셋의 노이즈를 최소화하기 위해, 저자들은 앞서 정의한 quality score $s(x, \hat y)$를 통해 학습이 고품질 데이터 위주로 진행되도록 유도(guide)합니다.
$$ \mathcal L_{MLM} = -\mathbb E_{(x, \hat y)\in \mathcal D_{wa}}s(x, \hat y) \log P(\hat y_m | \hat y_{\backslash m}, x) $$
$$ \mathcal L_{ITM} = -\mathbb E_{(x, \hat y)\in \mathcal D’_{wa}}s(x, \hat y) \log P(l|x, \hat y) $$
Experiments
실험에는 기존 WVLP 연구들을 따라 Conceptual Captions (CC) 데이터셋의 이미지-텍스트를 활용한 실험과, CC 데이터셋의 이미지와 BookCorpus (BC) 데이터셋의 텍스트를 활용한 실험을 진행했습니다.
저자들은 CC 데이터셋에서 8,192개의 정렬된 데이터쌍을 추출하여 anchor로 사용하였고, 따라서 relative representation은 8192차원의 벡터가 되었습니다. 연산량을 줄이기 위해, 각 데이터와 가장 유사도가 높은 50개 앵커와의 유사도를 제외하고 나머지는 0으로 바꿔줬다고 합니다. 근데 8000개면 원래 데이터셋 크기가 어떻든 간에 너무 큰 거 아닌가 싶네요.
Retrieval은 faiss 라이브러리를 이용해 구축하였으며, 각 이미지에 대하여 가장 유사도가 높은 텍스트를 찾아 매칭을 수행하였고, Rel-Cap은 GPT-2를 learning rate 5e-5와 batch size 1024로 5 에포크 text-only 데이터셋에서 파인튜닝하여 얻었습니다. Synthetic caption generation 연구에서 좋은 결과를 보인 방식을 차용하여 $p=0.9$의 nucleus sampling을 통해 이미지 당 5개의 pseudo-caption을 생성하고, 이들 중 quality score가 가장 높은 것을 취했습니다. (nucleus sampling은 텍스트 생성 시 다음에 올 토큰을 샘플링하는 방식 중 하나입니다.) 추가로 μ-VLA에서 사용한 tag 기반의 retrieval도 사전학습 과정에 사용했다고 하는데… 여러모로 좋다는 건 다 가져다 쓴 것 같습니다.
E2E-UVLP과 같은 구조의 12 계층 SwinTransformer (Swin-B-384/32)를 vision 인코더로, BERT-base로 초기화한 12계층 Transformer를 멀티모달 인코더로 사용하였고, object tag 추출에는 VinVL을 사용했습니다. 모델은 15만 step을 batch size 512로 사전학습하였고, AdamW optimizer에 초기 learning rate는 3e-5, warm-up ratio는 10%로 하여 3일간 4장의 A100에서 학습하였습니다.
사전학습된 모델은 Visual Question Answering (VQA), Natural Language for Visual Reasoning (NLVR2), Visual Entailment (VE), image retrieval (Flickr30k)에서 파인튜닝 및 테스트하였습니다.
Main Results
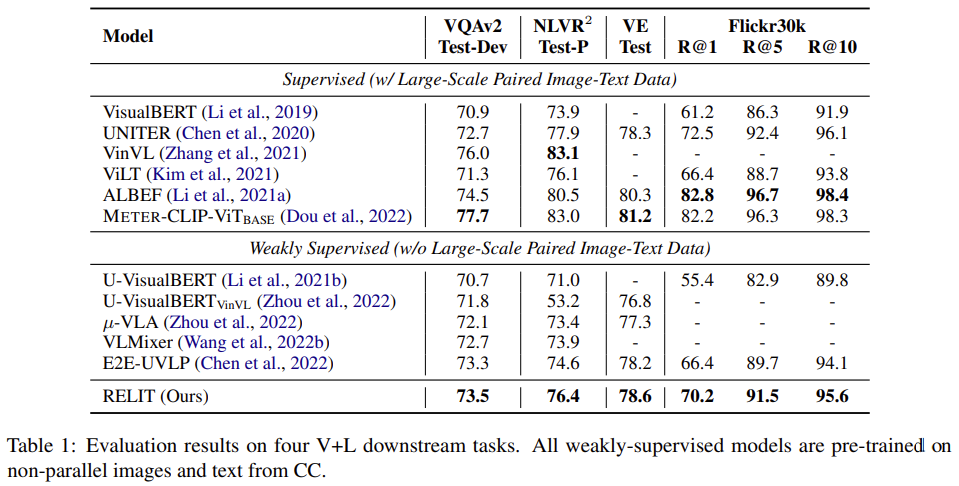
먼저 RELIT을 CC 데이터셋에서 학습한 다른 모델들과 비교한 결과 RELIT이 더 좋은 성능을 보였습니다. 그러나 완전히 라벨 없이 학습한 μ-VLA와 비교해서 성능 차이가 1-3 정도라, 이게 과연 라벨을 더 사용하고 유의미한 성능 향상인지 의문이 드네요. 다만 NLVR2과 Retrieval 성능이 높은 것이 instance-level의 cross-modal alignment를 잘한 결과라고 하는데 이 부분은 확실히 성능 향상이 조금 있긴 하네요.
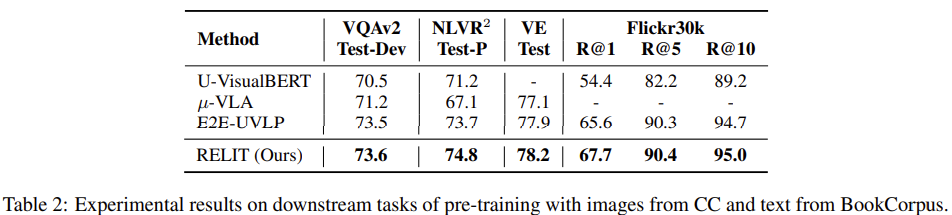
한편, 현실적인 설정으로 텍스트는 BC 데이터셋에서 가져온 경우의 성능입니다. 역시 성능이 전체적으로 약간 향상된 모양새네요. 그런데 이미지와 텍스트가 다른 데이터셋에서 왔는데 어떻게 anchor를 찾았는지에 대한 설명이 없어, 조금 더 알아봐야 할 것 같습니다.
Ablation Study
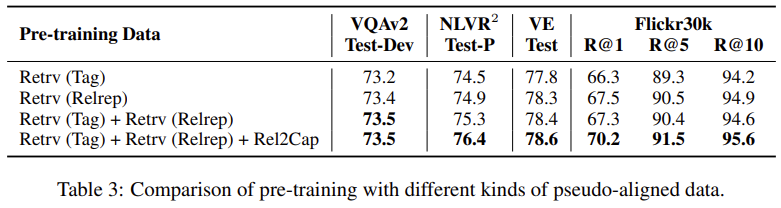
Ablation Study 결과입니다. tag 기반의 retrieval보다 relative representation 기반으로 retrieval을 수행하여 weakly aligned 데이터셋을 취득한 경우 성능이 약간 증가하는 모습을 보입니다. 두 가지 방법을 모두 사용하고, Rel2Cap까지 적용해 주니 성능이 큰 폭으로 상승하는데, Rel2Cap이 성능 향상에 꽤 큰 기여를 한 것 같습니다. 이로부터 CC 데이터셋에 noisy caption이 존재한다고 예측할 수 있다고 합니다.
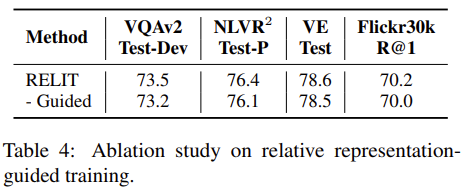
Relative representation guided training 방식에 대한 검증 결과입니다. 학습 과정에서 고품질 데이터에 더 집중하게 한 결과 성능이 미미하게 향상된 모양입니다.
Data Quality
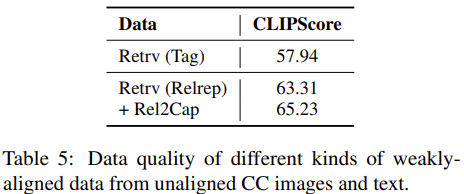
저자들은 CLIP-Score를 이용해 여러 가지 방법으로 weakly-align 된 CC 데이터의 align quality를 측정하였습니다. Relative Representation으로 align 한 결과가 tag 기반 방식보다 더 잘 weakly-align 된 모습을 보였고, 여기에 caption generator를 통해 noisy 한 caption을 대체해 주니 더욱 효과가 좋았습니다.
Effects of Anchor Selection
Relative Representation은 anchor 데이터들과의 관계로 데이터를 표현하기 때문에, anchor가 되는 데이터들의 다양성이 중요한데요. 결국 anchor로 사용되는 데이터 수를 늘릴수록 랜덤성에 의한 성능 편차는 줄어들고, 표현력을 상승하게 됩니다.
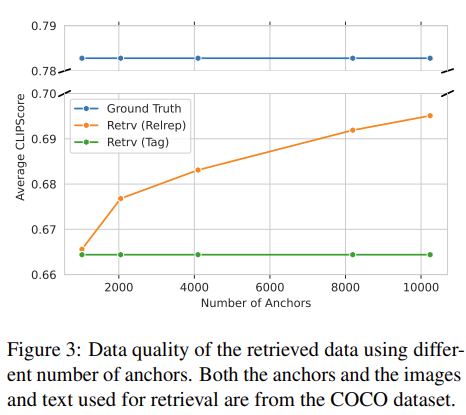
저자들은 anchor의 수에 따른 align의 품질 차이를 위 그림과 같이 시각화하였습니다. 그런데, 앵커가 되는 데이터와 이미지, 텍스트 데이터는 COCO 데이터셋에서 가져왔다고 합니다?! 앞에서 실험은 CC로 하다가, 아무 설명도 없이 COCO를 왜 도입한 것인지 굉장히 의아합니다.. anchor가 늘어날수록 align의 품질이 상승한다는, 자명해 보이는 사실을 왜 COCO에서 보인 걸까요..
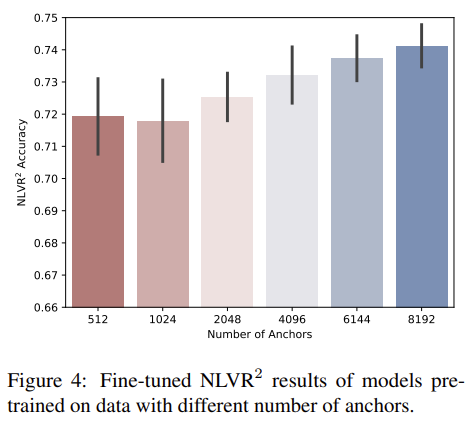
이어서 학습 시 anchor 수에 따른 NLVR2 성능 차이를 보여주기는 합니다만, 저자들이 유리한 실험 결과만 cherry pick 한 것 같다는 느낌을 지울 수가 없습니다. 아무튼 위 그림에서도, anchor 수의 증가에 따라 성능도 올라가고 성능의 변화폭도 줄어드는 모습입니다. 저자들은 anchor의 수를 더 올리면 성능이 자명하게 오르겠지만, 연산량과의 trade-off로 인해 8192를 사용했으며, 자신들의 방법이 scalability가 있다고 자랑합니다. 추가적인 연구는 future work로 남겨둔다고도 하네요. 킹받습니다..

저자들은 추가로 COCO 데이터셋에서 다양한 anchor selection 방식을 실험해 보았는데, K-means 군집화를 수행한 후, 매 사이클마다 각 군집에서 하나의 샘플을 뽑은 diverse와, 이미 선택한 anchor들의 평균과 가장 가까운 데이터를 greedy algorithm으로 선정한 non-diverse 방법을 비교해 봤습니다. 이것도 당연히 anchor가 다양할수록 표현력이 늘기 때문에 diverse가 좋은 것인데… 도대체 왜 넣은 걸까요…
Case Study

마지막으로 저자들은 자신들이 제안한 방법이 tag 기반의 방법보다 더 정확한 caption을 retrieval 한다며 위와 같은 정성적 결과들을 보였습니다. 이어서 Rel2Cap이 저품질의 캡션을 더 나은 캡션으로 대체하는 것도 정성적 결과로 첨부하였는데요.

두 가지 그림에 같은 샘플을 넣었다는 것이 애초에 cherry picking임을 숨길 생각이 없는 것 같습니다.
Conclusion
본 논문에서는 기존 UVLP 방법들이 tag 기반으로 cross-modal alignment를 수행하는 것에는 한계가 있다며 차라리 라벨을 일부 활용해서 relative representation을 사용하여 WVLP로 문제를 풀어보고자 하였습니다. Relative Representation을 통해 최대한 고품질의 weakly-aligned 데이터셋을 만들고, 저품질 캡션들은 언어 모델을 통해 아예 새로 만들어주기까지 하여 기존 방법들에 비해 성능 향상을 이룰 수 있었습니다.
다만 본 논문에 많은 아쉬움이 남는 점은 아래와 같습니다.
- 기존 tag 기반 UVLP 방법론들의 한계에 대한 충분한 설득 없이 task를 WVLP로 바꿔버린 점.
- task를 전환하여 라벨을 사용하였음에도 불구하고 설득력 있는 성능 향상을 보이지 못한 점.
- Relative Representation이 tag에 비해 전체적인 문맥을 고려할 수 있고 우월하다는 주장에 대해서도 약간의 성능 향상 외에 근거가 없다는 점.
- 몇 가지 방법론을 성능 향상을 위해 무작정 접목한 것처럼 보일 정도로 설명 없이 적용한 점.
- 전체적인 실험 섹션의 설득력 부족, 난해한 서술과 긴 분량
서베이 중인 분야 최신 논문이다 보니 읽기는 읽었습니다만… 여러모로 당황스러운 논문이었던 것 같습니다. 새로운 경험 했네요.
리뷰는 여기까지입니다.
감사합니다.