안녕하세요, 2024년 신년맞이 첫 X-Review 입니다.
신년 맞이 세미나에서 제 연구 계획을 발표할 때
1) Test-Time Adaptation (TTA)
2) Sensor Fusion
이렇게 두 방향성으로 서베이, 공부를 할 것이라는 당찬 포부를 밝혔는데요,
아쉽게도 오늘 리뷰할 논문은 Unsupervised Domain Adaptation(UDA) 논문입니다.
논문 작업이 아직 진행중이라 아쉽게도 기존에 공부, 연구하던 task의 논문을 읽게 되었네요.
그럼 리뷰 시작하도록 하겠습니다.
1. Introduction
UDA 기법을 적용해서 Semantic Segmentation을 수행하는 논문들의 Introduction 서술 전반부 흐름은 거의 동일합니다. 풀고자 하는 Target Domain에서의 Data labeling 비용이 시간, 비용적으로 너무 비싸다는 것이죠.
그렇기 때문에 이와 같은 문제를 해결하고자 gt가 존재하는 큰 규모의 labeled source dataset 으로부터 우리가 풀고자 하는 unlabeled target dataset으로의 adaptation을 수행하게 됩니다. 이로써 target dataset에 annotation을 할 필요 없이, 성공적으로 target domain을 위한 모델을 만들 수 있게 되는 것이죠.
이와 같은 Unsupervised Domain Adaptation (UDA) 를 수행하는 연구들은 크게 두 가지의 흐름으로 진행됩니다. 우선 adversarial 학습 기법을 사용하는 것입니다. GAN에서 비롯된 Discriminator가 source 로부터 나온 예측값과 target 으로부터 나온 예측값을 구분하는 방향으로 학습이 진행됩니다. 최종적으로는 source의 예측과 target의 예측이 매우 유사하게, 즉 alignment(정렬) 이 유사하게 이루어지겠죠.
adversarial 기법으로 모델을 학습하게 되면 두 domain의 feature distribution을 구분할 수 없게, 즉 유사한 분포를 가지도록 학습이 됩니다. 하지만 또 다른 일각에서는 이렇게 두 domain의 global feature distribution을 유사하게 정렬시키는 것이 능사는 아니라고 주장하는 연구들이 등장하게 됩니다. 본 논문에서는 adversarial 기법을 사용한 global alignment를 수행하는 것이 target domain 내 서로 다른 class들의 feature 분포 구별력을 보장하지는 않는다고 합니다.
이 말이 무엇인가 함은, 애써 source와 target 사이의 분포를 globally하게 정렬했는데, adaptation 결과를 보니 정작 target domain 내 자동차 class와 사람 class의 feature 분포가 잘 구별되지 않는다는 것이죠. 이로 인해 일반화 성능도 낮아지게 된다고 합니다. 해당 내용에 해당하는 문장은 원문을 첨부하겠습니다.
However, even though the global feature distributions across domains become closer, it is not guaranteed that pixels attributing to different semantic categories in the target domain are well separated, leading to poor generalization ability and even inferior performance.
위와 같은 adversarial 기반의 기법이 target domain 내의 class distribution에 대한 고려가 부족했기 때문에, 이를 해결하고자 여러 연구들이 등장했습니다. 하지만 이러한 연구들은 source-target 사이에 대한 고려는 뒷전이였고, target domain내 intra-class 분포에만 초점을 뒀습니다. 그렇기 때문에 결과적으로 target domain의 여러 class에 대한 분포가 동일한 곳에 projection 되는 문제가 발생한다고 하네요.
저자는 그리하여 최종적으로 class-level의 정보를 잘 추출(?) 하기 위해 Prototypical Contrast Adaptation (ProCA) 라고 하는 기법을 제안합니다. 직관적으로, 서로 다른 domain일지라도 동일한 class에 대한 최종 feature 는 높은 유사성을 보인다는 가정을 하게 됩니다. 이렇나 가정을 기반으로 class별로 하나의 prototype을 설계하게 되고, 이는 간단하게 class를 대표하는 하나의 vector라고 생각하면 됩니다.
학습 과정은 간략합니다. 우선 UDA의 기본 세팅 상 source domain에 대해 미리 학습을 수행합니다. 이후 학습된 source domain에서 class별로 초기 prototype을 계산합니다. 위에서 말씀드렸다시피 source와 target domain의 최종 feature는 같은 class끼리 높은 유사성을 보인다는 가정이 있기 때문에 미리 계산된 source prototype과 target domain 예측 사이의 prototype-pixel contrastive learning을 통해 같은 class끼리는 가까워지고, 다른 class끼리는 멀어지는 방향으로 학습이 진행됩니다. 또한 target domain의 학습이 진행되면서 이에 맞게 prototype이 적절하게 update도 되구요. 이에 대한 자세한 사항은 method에서 설명드리겠습니다.
2. Method
위에서 설명드렸다시피 이전 방법론들은 source와 target의 분포 거리를 최소화함으로써 domain-invariant한, 공통적인 representation을 학습하고자 하였습니다. 하지만 이렇게 했을 시 target domain 내 class 끼리의 관계가 충분히 고려되지 않게 됩니다. 분리시켜야 하는데 말이죠. 이를 잘 나타내는 그림은 아래와 같습니다.
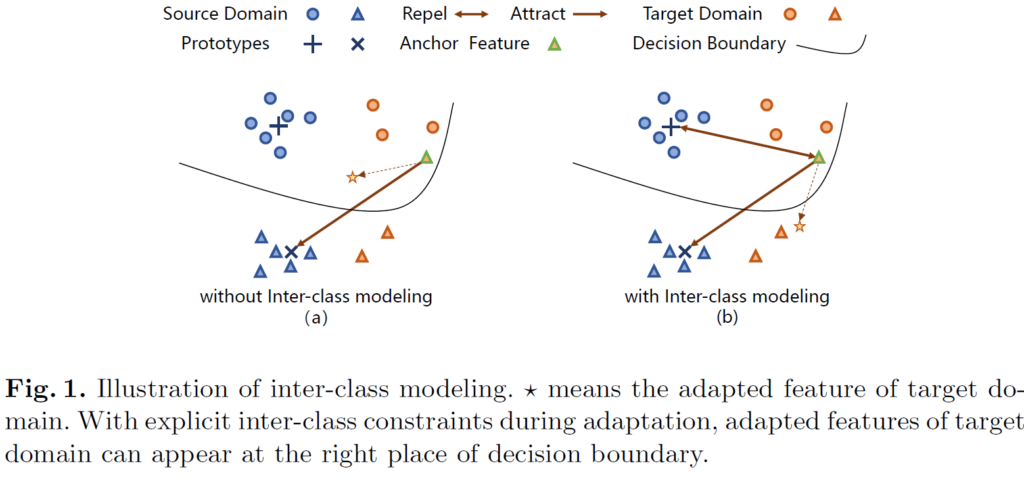
위 그림에서 (a)는 이전 방법론, (b)는 본 논문의 방법론입니다.
파랑색 동그라미, 세모는 source domain, 주황색은 target domain의 각 class별 feature 를 나타냅니다. 또한 + 표시는 동그라미 class에 대한 prototype을, x 표시는 세모 class에 대한 prototype을 나타내며, 이는 모델 학습 초기에 source domain에 대해 미리 계산된 채로 초기화됩니다. target domain에 대한 학습이 진행되면서 점차적으로 update가 수행되는데 이는 뒤에서 설명드리겠습니다.
아무튼 (a)와 (b) 그림에서 별 모양이 어느 방향으로 이동하는지를 비교해보시면 둘의 차이를 명확하게 아실 수 있을것입니다. (a)에 비해 (b)가 훨씬 더 class간의 관계(동그라미<->세모) 를 잘 고려해서 둘의 분포를 잘 분리시키게 됩니다. 또한 각 class 내부에서의 분포를 봐도 (b)가 훨씬 더 잘 한곳으로 모이는것을 볼 수 있습니다.
즉 다시말해, 본 논문의 방법론은 intra-class와 inter-class를 함께 고려한 기법을 설계했다고 보시면 됩니다.
2.1. Preliminaries
이전 UDA 논문들과 큰 세팅 틀은 동일합니다.
Segmentation 모델은 크게 feature를 추출하는 feature extracter \mathcal{F}와, 픽셀별로 어떤 class인지 분류해주는 한 층의 classifier \mathcal{C}로 구성됩니다. 그리고 \mathcal{F}와 \mathcal{C} 는 source와 target이 서로 parameter를 공유합니다.
(보통 deeplab 모델을 사용하기 때문에, upconv로 구성된 decoder 대신 그냥 interpolation으로 upsampling이 수행됩니다)
학습은 우선 labeled source image를 사용해서 모델 (\mathcal{F}, \mathcal{C}) 을 학습시킵니다. 아래 cross-entropy loss를 사용해서 supervised 방식으로 말이죠.
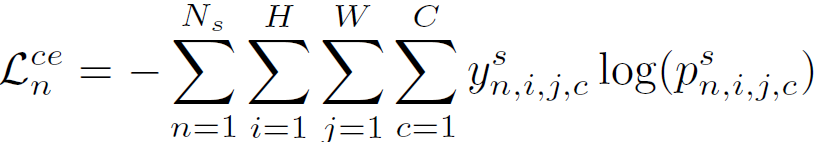
y^s는 source domain의 gt를, p^s는 source domain의 최종 예측을 나타냅니다.
2.2. Prototypical Contrastive Adaptation
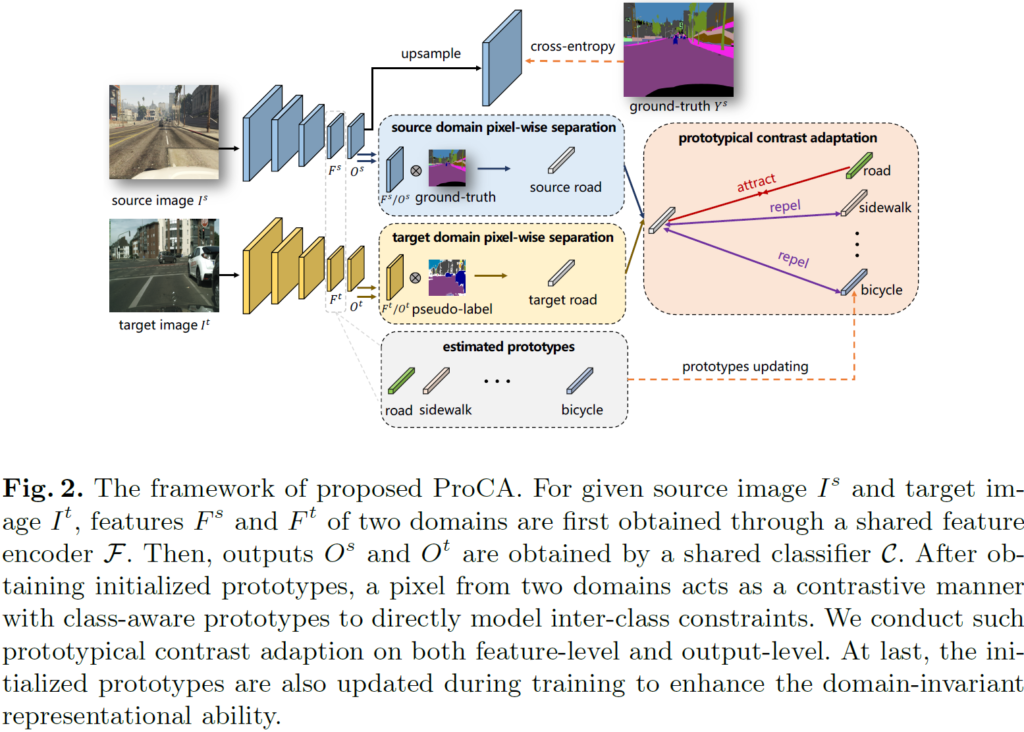
자 이렇게 2.1.절의 loss를 통해 모델을 우선 source domain에 대해 학습시켰습니다. 그럼 이제 이를 target domain으로 adaptation 해야하는데요, 이를 위한 전체 pipeline은 위 그림 2와 같고, 저자는 이를 ProCA(Prototype Contrastive Adaptation) 이라고 명명합니다.
ProCA는 prototype을 기반으로 한 contrastive learning을 수행하며, adaptation 수행 시 target domain 내의 intra-class 와 inter-class 관계를 동시에 고려하는 기법입니다.
이는 크게 아래의 3가지 단계로 동작합니다.
1) prototypes initialization
2) contrast adaptation
3) prototype updating
1) Prototype Initialization
source domain으로 학습된 모델로부터 초기 prototype을 계산(초기화) 할 수 있습니다. 아래 식으로 말이죠.
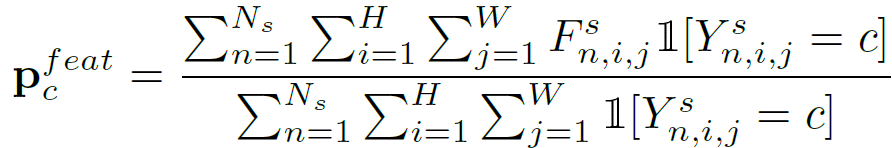
F^s는 source image가 \mathcal{F} 를 통과해서 얻어진 source domain feature를 의미합니다. 아직 원본 크기로 interpolation 되기 전인, feature map의 형태죠. 해당 feature map F^s 에서 각 class 별로 feature vector의 평균을 계산할 수 있고, 이것이 class c의 prototype 입니다.
예를 들어 원본 영상의 shape이 480×640이고, 이 영상이 \mathcal{F}를 통과해서 계산된 feature map F^s의 shape이 256x60x80 (C,H,W) 라고 한다면, class별 prototype은 각각 256×1 의 형태를 가지게 되고, class가 c개이므로 전체 prototype은 256 x c 의 형태를 가지게 되는것입니다.
2) Contrast Adaptation
source domain으로 부터 prototype을 초기화했으니, 이제는 이를 바탕으로 target domain에 대한 adaptation을 수행할 단계입니다.
target image I^t또한 \mathcal{F}를 통과해서 feature map F^t를 만들게 되고, 이는 앞서 미리 계산된 source prototype 과의 similarity 계산을 수행하게 됩니다.
(아래의 수식으로 계산이 가능한 이유는 앞서 설명드렸다시피 source와 target이 최종 feature level에서 높은 유사성을 가진다는 가정이 있기 때문입니다)
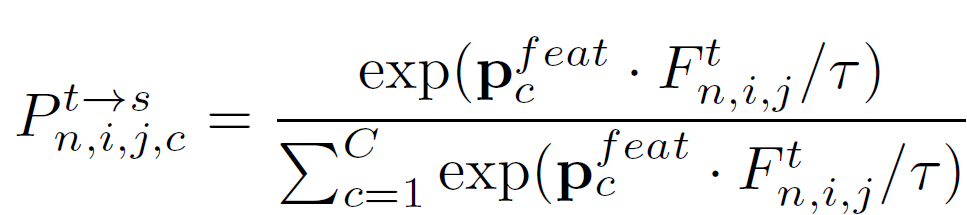
그리고 이렇게 계산된 similarity P^{t\rightarrow s}와, target domain을 위한 pseudo label \tilde{y}^t 사이의 cross-entropy loss를 통해 동일 class끼리는 cosine similarity가 커지는 방향으로(즉 두 벡터 사이 각이 작아지도록), 서로 다른 class 끼리는 cosine similarity가 작아지는 방향으로(즉 두 벡터 사이 각이 커지도록) 학습이 진행되게 됩니다.
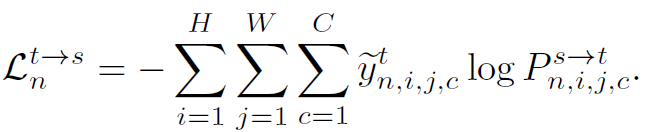
pseudo label\tilde{y}^t를 어떤 기준으로 설정하는지에 대한 연구는 self-training 기반 UDA 연구에서 수행합니다. 본 논문은 self-training 그 자체에 대해 연구하기 보다는, 기존 self-training based UDA 모델에 추가적으로 적용 가능한 learning method를 제안한 것이기에 pseudo label\tilde{y}^t의 생성 방식은 이전 연구들을 따릅니다. 이에 대한 실험도 존재하기 때문에 실험 섹션에서 참고 부탁드립니다.
source와 target이 최종 feature level에서 높은 유사성을 가진다는 가정이 있기 때문에, 위 loss 뿐만 아니라 아래 loss 를 계산할 수 있습니다. P^{s\rightarrow s} 는 prototype과 source feature map F^s 사이의 similarity 계산 결과입니다.
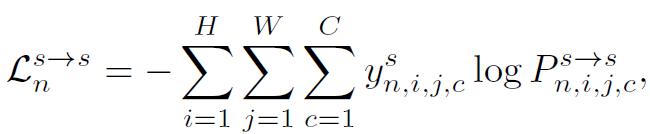
위 두 loss를 사용해서 target domain 학습을 위해 feature 단위의 contrastive learing 이 수행됩니다. 아래 식으로 말이죠.
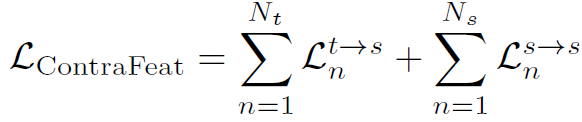
3) Prototypes Updating
현재 batch에 대해 source와 target 에서 예측한 current batch prototype p_c^{feat^s}, p_c^{feat^t} 를 hyperparam m을 사용해 결합하여 similarity 계산을 위한 prototype p_c^{feat}를 update 하게 됩니다.
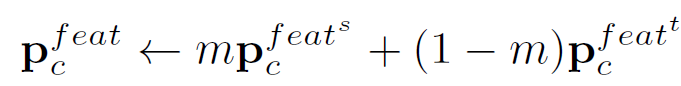
그런데 논문에서 m을 어떤 값으로 사용했는지는,, 나와있지 않네요 ㅜ
++ Label Space Adaptation
보통 prototype 은 channel 정보가 중요하기 때문에 feature extraction이 끝난 단계에서 계산을 수행합니다. 위의 L_{ContraFeat}가 이에 해당하죠.
부가적으로 저자들은 이와 같은 prototypical contrastive learning을 feature level 뿐만 아니라 output level에서도 적용했다고 합니다.
output level이라 함은 conv 연산을 통해 channel의 수가 class 갯수 c로 변경된 단계를 의미합니다.
이를 적용한 총 loss 식은 아래와 같겠죠.

3. Experiments
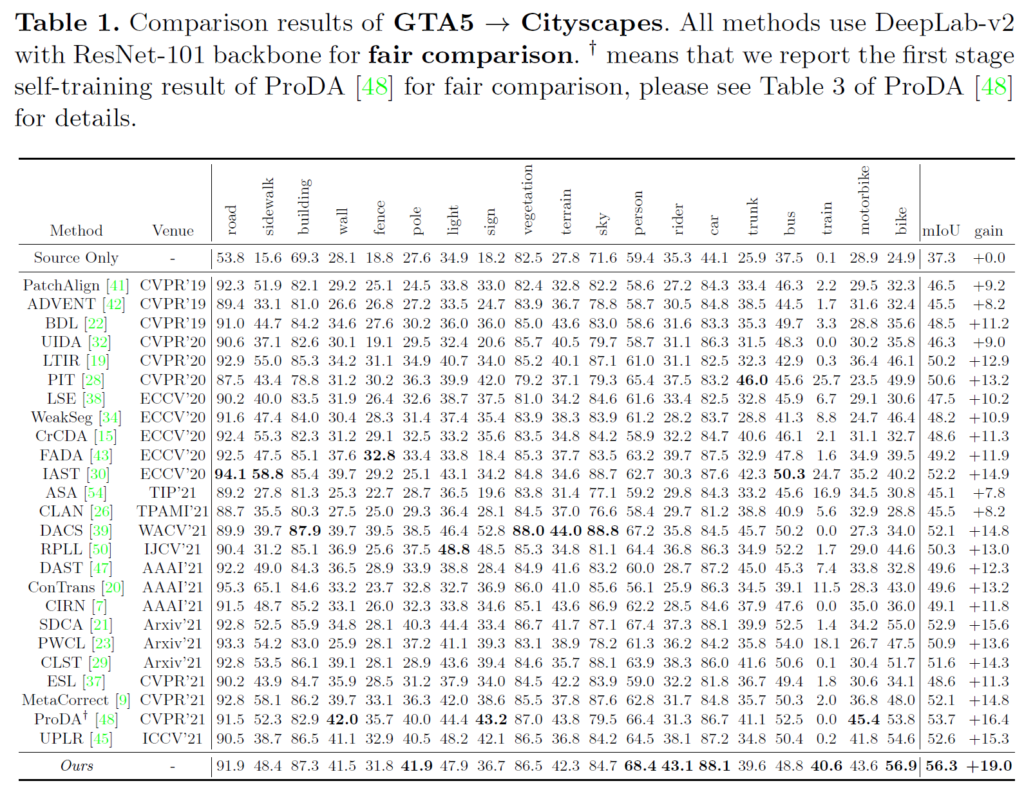
우선 UDA 분야의 대표 벤치마킹인,
GTA5 -> Cityscapes 로의 adaptation성능 결과입니다.
위 실험 결과에서 인상깊게 볼 만한 점은 pole, person, rider, train, bike 와 같은 class 입니다.
이들은 매우 challenging한 class로 이전 방법론들에서 예측 성능이 매우 낮았던 class들입니다.
이말은 즉슨 class들 끼리의 distribution이 명확하게 구분되지 않았다는 것인데요,
본 논문의 첫번째 figure에서 알 수 있다시피 ProCA를 통해서 intra-class뿐만 아니라 inter-class의 분포까지 고려한 학습을 진행함으로써 훨씬 더 좋은 성능 향상을 이루어낸 것을 볼 수 있습니다.
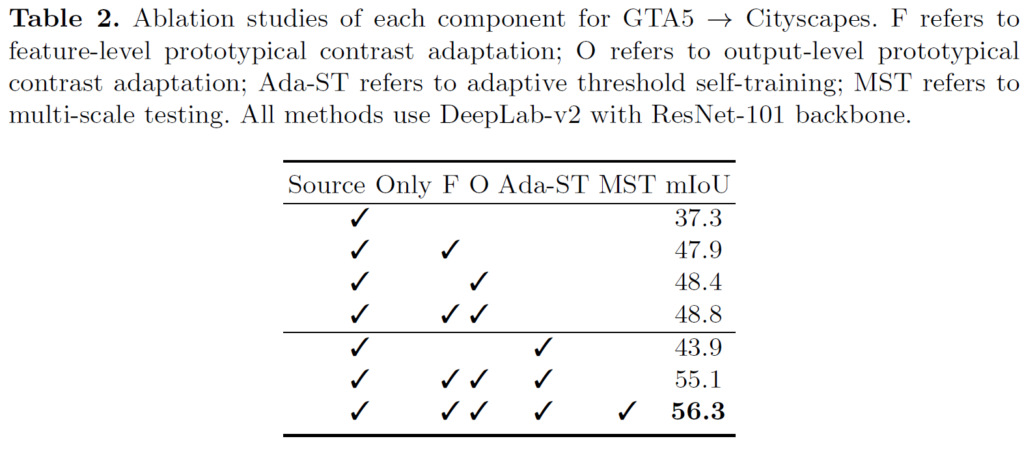
위 table의 첫번째 row는 adaptation이 수행되지 않은,
즉 source 에서 학습된 모델을 바로 target에 적용했을 때의 성능입니다.
또한 F, O를 둘 다 적용한,
L_{ContraFeat}와 L_{ContraOut}를 모두 적용해서 feature level 뿐만 아니라 output level에서도 contrastive learning 을 적용했을 때 48.8 이라는 성능을 보여줍니다..
이에 더해 기존 self-training 기법인 Ada-ST와의 결합,
그리고 multi-scale에서의 예측을 통해 최종적으로 56.3이라는 성능을 보여주고 있습니다.
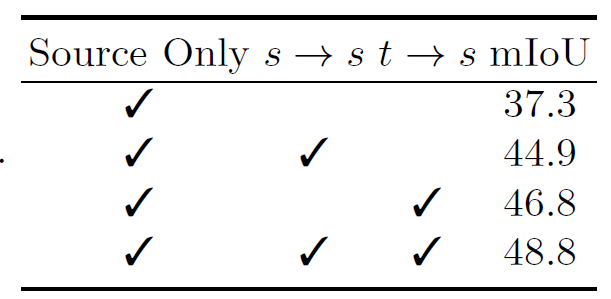
위 표는 prototypical contrastive adaptation 의 방향과 관련된 실험입니다.
source->source 방향으로의 ProCA 수행 시 7.6의 성능 향상을,
target->source 방향으로의 ProCA 수행 시 9.5의 향상을 보여줍니다.
정말 드라마틱한 향상이네요…
둘을 조합했을 때 48.8의 최종 성능이 달성됩니다.
빨리 논문 작업을 끝내고 TTA 분야 서베이도 하고싶고,
코드도 좀 돌려보고 싶네요..ㅎ
이만 리뷰 마치겠습니다. 감사합니다.
안녕하세요. 권석준 연구원님.
좋은 리뷰 감사합니다.
몇가지 궁굼한 점이 있어 질문드립니다.
1. 마지막 실험에서 source->source는 Source에서 사전학습된 모델을 추가로 해당 도메인에서 학습한 것인가요?
2. 같은 클래스 간의 feature를 유사하게 만드는 것이 방법론의 핵심인 것 같은데, 그렇다면 결국 새로운 도메인에서 이전 도메인과 같은 클래스에 대한 라벨이 필요하게 되고, 그걸 pseudo-label을 이용하는 것 같은데, 이러한 방법의 경우 도메인 차이가 커지면 아예 적용이 불가할 것 같은데, 혹시 잘 사용되나요?
감사합니다.
1. 아, 마지막 실험 내 source->source의 의미는 2.2절 내 2) Contrast Adaptation 에서 L^ {s->s}의 사용을 의미합니다.
2. 지오님께서 말씀하시는 ‘도메인 차이가 커지면’ 이라는 말이 즉 도메인 차이가 커서 source와 target의 보유 class마저 다른 상황이라고 이해했습니다.
사실 UDA task의 벤치마킹으로 사용되는 source와 target dataset은 보통 자율주행 scene으로 class정보가 모두 동일합니다./
그런데 또 생각해보니 실제 기술을 효과적으로 활용하기 위해서는 class정보가 다른 상황에서도 잘 working해야 할텐데,, 그런 class 관련된 연구들도 시간 나면 찾아봐야겠네요.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
본문에서 말씀하신 pseudo label 생성 방법이 실험 부분에서의 Ada-ST에 해당하는 것인가요?
Unsupervised 기반 task이다보니 pseudo label의 quality에 큰 영향을 받을 것 같은데(물론 본 연구의 초점이 pseudo label 개선은 아니지만), 문득 생각해보니 비디오의 action localization 연구에서는 다른 연구의 pseudo label 생성 방식을 따르는것은 물론 최종 예측값을 pseudo label 삼아 자신들의 방법론을 시작하는 연구들이 최근에 많았습니다.
혹시 권석준 연구원님이 하시는 task에는 그런 방식은 사용되지 않나요?
넵 Ada-ST가 맞습니다.
pseudo label을 어떤 식으로 thresholding 하면서 생성할 것인지에 대한 연구도 실제 UDA 분야에서 많이 연구되고 있습니다. self-training 기반의 UDA 연구라고 불리죠. 실제로 domain adaptation이 진행되면서 source가 target에게 전달하는 pseudo label의 quality가 큰 영향을 좌지우지하기 때문에 이렇게 따로 연구 분야가 탄생하지 않았나 싶습니다.
마지막에 하신 질문에대해서는 음,,, 사실 정확히 이해는 하지 못했습니다만,
제가 읽고 있는 이런 learning method를 제안하는 연구들의 경우 실제 task (segmentation) 를 수행하는 모델은 deeplab-v2로 고정한 채로 오로지 학습 기법만을 제안해서 성능 향상을 리포팅합니다. 그렇기 때문에 타 모델의 예측값을 pseudo label삼아서 자신의 방법론을 시작하는 연구들은 딱히 UDA 연구에서 추구하는 learning method 설계와 본질이 조금 다른 것 같습니다.
감사합니다.
리뷰 잘 보았고 질문이 있어서 남깁니다.
제가 이해한 바로는 먼저 source domain에서 prototype을 처음 초기화하고 그 다음 target domain에서의 feature map이 source domain에서 초기화된 prototype을 활용해 segmentation 수행하는 것 같은데 맞나요?
그러다가 점차 학습을 진행하는 과정 중에 초기 prototype에 대하여 source domain의 prototype과 target domain에 prototype도 m/1-m 비율로 섞어서 update하는 것 같고요. 그러면 여기서 궁금한 것이 모델 학습 때 target domain image 뿐만 아니라 source domain image도 함께 사용하는 건가요?
아니면 source domain의 prototype이라는 것이 그저 EMA처럼 예전의 prototype값을 일정 비율 계속 가져다가 사용한다는 의미로 보면 되나요?
(구두답변 완료)