안녕하세요. 이번 주차 X-Review의 주제는 지난 세미나 때 말씀드렸듯, 제가 관심갖고 살펴보려한 task인 Temporal Sentence Grounding in Videos(TSGV)의 초창기 방법론입니다. 2020년도 CVPR에 게재되었으며, 서울대 한보형 교수님과 포항공대 조민수 교수님 연구실의 공동 연구 논문입니다.

이전에 TSGV를 제안한 최초의 논문에 대해 세미나를 한 번 진행한 적이 있었는데, 이후 해당 논문을 기점으로 본격적인 방법론들이 쏟아져나오게 되었습니다. 20년도 방법론이기에 최신 기법이라고는 볼 수 없지만, 연구가 어느정도 진행된 이후 논문이기 때문에 천천히 자세하게 살펴보겠습니다. 제목을 통해 알 수 있듯, 방법론의 대략적인 컨셉은 query feature와 비디오 feature 간 여러 level(local, global)에서의 매칭을 수행하며 구간을 정교화하는 것으로 보입니다.
1. Introduction
저희 팀이나 제가 이전에 다루던 비디오 task인 Video-to-video Retrieval이나 Temporal Action Localization의 경우 어디까지나 비디오 단독 모달만을 사용하게 됩니다. 물론 이번 Access에 저희가 제출한 논문은 Weakly-supervised Temporal Action Localization task를 해결하기 위해 text 정보를 임베딩하여 활용하긴 하지만, task 자체가 multi-modal을 다루고 있다고 보기엔 어렵습니다.
하지만 2020년도 이후부터 Video Question Answering, Video Captioning 등 비디오, text, 오디오 등의 여러 모달을 함께 활용하는 task들이 활발히 연구되기 시작하였습니다. 이와 동시에 TSGV(학계에선 Video Moment Retrieval과 동일한 task를 지칭합니다) 또한 17년도 이후 굉장히 활발히 연구되고 있는데 TSGV는 문장 text query가 던져졌을 때 해당 쿼리가 의미론적으로 지칭하는 구간을 비디오에서 찾아내야 합니다. 이전에 제가 다루던 Temporal Action Localization이 사람의 action 구간을 찾아냈었다면, 이젠 단순 action 대신 구체적으로 묘사되어있는 문장 표현이 발생하는 구간을 찾아야하기 때문에 더욱 어렵고 복잡하다고 볼 수 있습니다.
이러한 TSGV를 수행하는 본 논문의 핵심 컨셉은 text query로부터 여러개의 semantic phrases를 추출하고, 이 phrases들을 비디오와 여러 level의 granularity(local, global)에서 interaction을 수행하며 구간을 잘 학습하고 이후엔 찾아내는 것입니다. 그렇다면 여기서 semantic phrases는 무엇을 의미할까요?
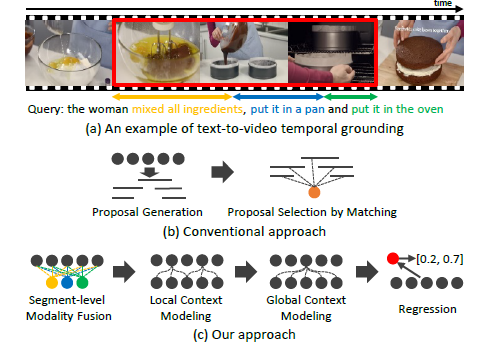
그림 1-(a)은 먼저 TSGV에 대한 간략한 설명을 보여주고 있습니다. 비디오와 해당 비디오의 특정 구간을 설명하는 text query(the woman mixed all ingredients, put it in a pan and put it in the oven)가 주어졌을 때, TSGV의 목표는 비디오에서 query가 발생하고 있는 시간 구간을 알아내는 것입니다. 그림에선 빨간 테두리친 시간 영역이 될 것입니다. 그림 1-(b)는 기존 연구들의 framework에 해당하는 scan-and-localize 방식입니다.
이 방식은 각자의 알고리즘을 활용해 비디오로부터 여러 개의 proposal을 만들어내고(scan), 하나로 만든 query feature와의 matching을 통해 경계를 회귀하여 예측을 만들어냅니다. 핵심은 query 문장 내 다양한 fine-grained semantic을 무시한 채 단 하나의 global feature로 만들고 proposal들과의 matching을 수행한다는 점입니다. 이렇게 되면 query를 쪼개어 fine-grained level로 살펴보았을 때 포착할 수 있는 세부정보들이 무시될 수 있으며 localization에 최적이라고 보기 어려울 것입니다. 결국 저자가 이야기하는 semantic phrases는, 앞서 예로 들었던 text query를 의미를 가질만한 작은 단위인 [‘mixed all ingredients’, ‘put it in a pan’, ‘put it in the oven’](그림 1-(c)에서 색칠된 동그라미)을 의미합니다.
Text query를 위와 같은 단위로 쪼개었다면 해당 feature를 비디오와 매칭시키는 이후 단계가 진행됩니다. 먼저 phrase feature-segment level의 fusion을 통해 각 phrase에 가장 잘 상응하는 segment(video를 쪼갠 단위)를 강조할 수 있게 됩니다. 이후에는 local context modeling 과정을 수행하며 여러 phrase가 snippet보다는 조금 더 넓은 범위(local)와도 align되도록하며, 마지막으로 global context matching 과정은 phrase 서로 간의 관계도 모델링할 수 있도록 설계되어 있습니다. 이렇게 다양한 level에서 정합이 맞춰진 feature들을 aggregate하여 실제 비디오 상 query의 구간, 즉 ground truth 구간과의 regression을 수행합니다.
Introduction에는 정말 컨셉만이 작성되어있기 때문에, 위 과정에 대한 세부 사항은 Contribution을 정리한 뒤 Method에서 자세히 알아보겠습니다.
Contribution
- We introduce a sequential query attention module that extracts representations of multiple and distinct semantic phrases from a text query for the subsequent video-text interaction
- We present an effective local-global video-text interaction algorithm that models the relationship between video segments and semantic phrases in multiple level, thus enhancing final localization by regression
- Outperforms the SOTA by a large margin on both Charades-STA and ActivityNet Captions datasets
2. Method
2.1 Algorithm Overview
기본적인 notation으로 비디오는 V, text query는 Q이고 이에 상응하는 V 내 구간은 C로 표현됩니다. TSGV의 일반적인 objective function은 아래 수식 (1)과 같습니다.
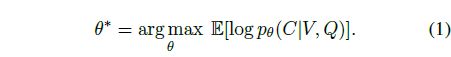
비디오 V와 text query Q가 주어졌을 때, 실제 구간 C가 예측될 확률을 최대화하는 파라미터 \theta를 찾는 것으로 해석할 수 있습니다. 이 때 Q는 그림 1-(a)에서 보았듯 일반적으로 여러 semantic phrase로 구성되며, 이를 의미론적으로 잘 쪼개어 활용한다면 global matching만 수행하는 방식에 비해 더욱 정교한 localization을 수행할 수 있을 것입니다.
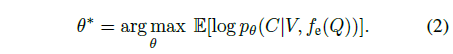
위 과정은 미분 가능하며 문장을 의미론적 단위(semantic phrases)로 쪼개어 multi-level의 interaction을 가능케하는 모듈 f_{e}(\cdot{})를 적용해 표현할 수 있으며 이는 수식 (2)와 같습니다.
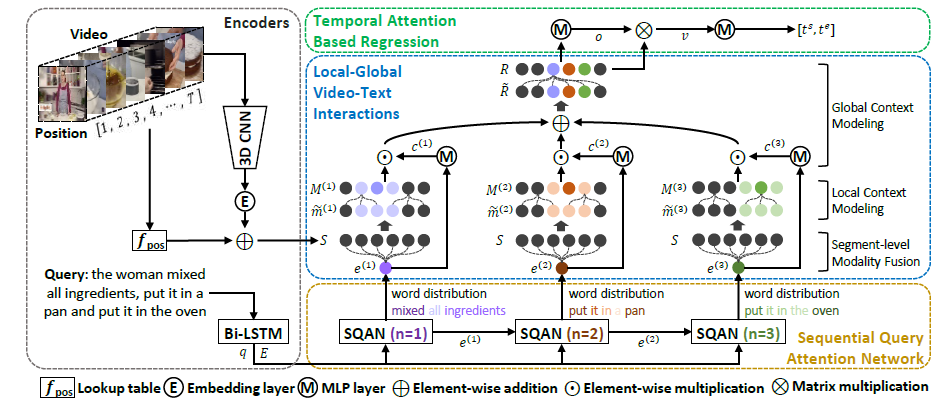
저자가 제안하는 방법론의 전체적 파이프라인은 위 그림 2와 같습니다. 먼저 V는 T개의 snippet으로 쪼개어져 각각의 feature를 만들어내고, text query Q는 단어로 쪼개져 word-level feature가, 또한 sentence-level feature가 추출됩니다. 다음으로 Sequential Query Attention Network(SQAN)를 통해 Q로부터 여러개의 semantic phrase를 얻어냅니다. 각각의 semantic phrase에 상응하는 semantic snippet은 앞서 Introduction에서 설명했듯 3단계로 구성되는 multi-level video-text interactions를 거쳐 semantic-aware segment feature를 생성하고 이를 구간 예측에 활용합니다.
2.2 Encoders
저자가 제안하는 모듈에 들어갈 text와 비디오 feature를 생성하는 과정입니다.
Query encoding
총 L개의 단어로 구성되는 Q는 word embedding으로 전환된 뒤 Bidirectional-LSTM을 거쳐 word-level, sentence-level feature로 인코딩됩니다. l번째 단어의 embedding \textbf{w}_{l}은 아래 수식과 같이 양방향에서의 hidden state를 concat하여 생성됩니다.
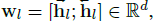
이후 sentence-level feature \textbf{w}_{q}는 거의 유사하게 양방향에서의 마지막 hidden state를 concat하여 생성됩니다. 이는 아래 수식과 같습니다.
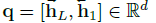
Video encoding
하나의 비디오 V에 존재하는 모든 프레임을 활용하기엔 memory cost가 굉장히 크며, 인접 프레임 간에는 중복되는 정보가 많기에 일반적으로 비디오 task에서는 프레임을 downsampling하여 3D encoder에 태워 사용합니다. TSGV에서도 비디오를 16프레임 단위로 쪼갠 뒤 3D encoder f_{V}에 태우는데, 이 때 절반에 해당하는 8프레임씩은 인접 segment와 겹치게 쪼갠 뒤 encoding하게 됩니다. 이러한 방식으로 비디오를 segment로 나누었을 때, 각자 다른 길이를 맞춰주기 위해 하나의 비디오 당 T개의 segment를 uniform sampling하고, 각 segment의 feature \textbf{S}는 아래와 같이 표현됩니다. 만약 비디오 길이가 짧아 T개를 추출할 수 없는 경우 부족한 영역은 0으로 채워진다고 합니다.
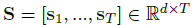
저자는 S를 생성하는 과정에서 기존 방법론들을 따라 positional encoding을 추가하였고 이는 아래 수식 (3)과 같습니다.
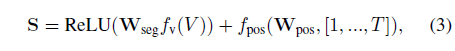
위 수식 (3)에 따르면, 실질적으로 후에 사용되는 video feature S는 3D encoder를 타고 나온 비디오 embedding f_{V}(V)에 FC layer + ReLU를 태운 뒤 positional encoding을 더해준 형태라고 이해할 수 있습니다. 저자에 따르면 positional encoding은 TSGV task가 temporal localization인 만큼 필수적인 과정이라고 하네요.
2.3 Sequential Query Attention Network (SQAN)
본 절부터가 본격적인 저자의 방법론 설명에 해당합니다.
SQAN은 앞서 설명한 수식 (2)의 f_{e}(\cdot{})입니다. f_{e}(\cdot{})는 저자의 의도에 맞게 query에서 중요 요소에 해당하는 actors, objects, actions 등을 더 잘 찾도록 하기 위해 문장을 쪼갤 수 있어야 합니다. 위와 같은 semantic phrase에 대한 GT는 없기에, 저자는 query 내 semantic phrase가 단어의 연속으로 구성된다는 가정을 깔게 됩니다.
하나의 Q에 존재하는 총 L개의 word-level feature E=[w_{1}, w_{2}, \cdots{}, w_{L}] \in{} \mathbb{R}^{d \times{} L}과 sentence-level feature q\in{}\mathbb{R}^{d}가 있을 때, 본 모듈에서의 목표는 고정된 개수 N개의 semantic phrase feature \{e^{(1)}, \cdots{}, e^{(N)}\}을 추출하는 것입니다.
결국 총 L개의 단어를 훑으며 N번의 단계를 거치는 상황인데, 각 단계마다 guidance vector g^{(n)} \in{} \mathbb{R}^{d}이 존재합니다. 이는 아래 수식 (4)와 같습니다.
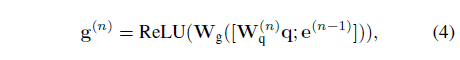
단계 별 guidance vector가 존재하는 이유는, text query Q 문장에서 구별력 있는, 즉 의미 있는 절이 semantic phrase로 선별되어야 하기에 각 단계에서 이전 단계에서의 정보를 함께 고려하며 sequential하게 모델링해주기 위함입니다. 다시 수식 (4)로 돌아가 각 단계에서의 guidance vector g^{(n)}은 간단하게 만들어줍니다. 우선 sentence-level feature q에 linear transform을 거치고 이전 단계에서의 guidance vector g^{(n-1)}과 concat해줍니다. 이에 다시 FC layer + ReLU를 적용하는 것이 전부입니다. 수식에서 sentence-level feature q에 적용되는 linear transformation 가중치 W_{q}는 단계마다 다르게 들어가는 것을 볼 수 있습니다. 저자에 따르면 이를 통해 쿼리의 다양한 aspect를 고려해주기 위해 위와 같은 구조를 선택했다고 하네요.
위 과정을 거쳐 얻은 guidance vector를 활용해 현재인 n번째 단계의 semantic phrase feature e^{(n)}을 만들어줄 수 있습니다. 이 과정은 아래 수식 (5), (6), (7)과 같은데, 설명과 함께 하나씩 살펴보겠습니다.
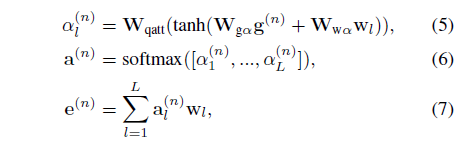
수식 (7)을 먼저 보면, 현재 단계에서의 semantic phrase feature e^{(n)}은 총 L개 word-level feature들의 weighted sum 형태인 것을 알 수 있습니다. Weighting을 위한 attention score들은 수식 (6)에서 softmax를 타고 나온 것으로, 결국 n번째 단계에서 l번째 단어에 대한 수식 (5)의 attention weight \alpha_{l}^{(n)}이 어떻게 정의되는지가 중요할 것입니다.
수식 (5)를 보면 앞선 수식 (4)를 통해 얻은 현재 단계에서의 guidance vector g^{(n)}과 word feature w_{l}을 각각 linear transformation 한 후 더하고 tanh 함수를 한 번 거쳐줍니다. 이후 마지막으로 FC layer를 한 번 더 태우고 총 L개에 대한 softmax를 취해 현재 단계에서 현재 단어에 대한 confidence score a^{(n)}을 만들어내게 되는 것입니다.
2.4 Local-Global Video-Text Interactions
앞선 절의 수식 (7)까지를 통해 총 N개 단계 각각에서의 semantic phrase feature들을 얻을 수 있었습니다. 본 절에서 수행하는 video-text interaction이 TSGV의 일반적인 파이프라인에서 성능을 좌우하는 가장 중요한 단계라고 볼 수 있습니다. 여기서는 segment-level modality fusion, local context modeling, global context modeling을 수행해주는데, segment-level modality fusion, local context modeling은 각각의 semantic phrase를 내부적으로 이해하는 과정, global context modeling은 여러 semantic phrase간 관계를 이해하는 과정에 해당합니다.
Individual semantic phrase understanding
각 semantic phrase의 내부적인 이해를 위해 저자는 아래 두 가지를 수행합니다. 목적은 이렇게 명시되어있지만 이를 달성하는 이유는 결국 비디오와 text query 간 올바른 interaction이라는 것이 중요합니다.
- Segment-level modality fusion
- Local context modeling
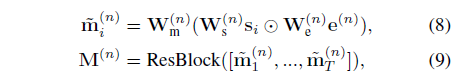
각 단계는 수식 (8), (9) 각각에 해당합니다. 이는 아래 그림 2-1에서 파란 점선 박스 중 아래 두 가지 단계라고 볼 수 있습니다. 첫 번째 단계는 segment-level modality fusion입니다. 본 단계에서는 가장 naive한 localization을 수행하는데, 각각의 semantic phrase와 잘 상응하는 segment들이 highlight되고, 큰 관계가 없는 segment들은 suppress되길 기대합니다.
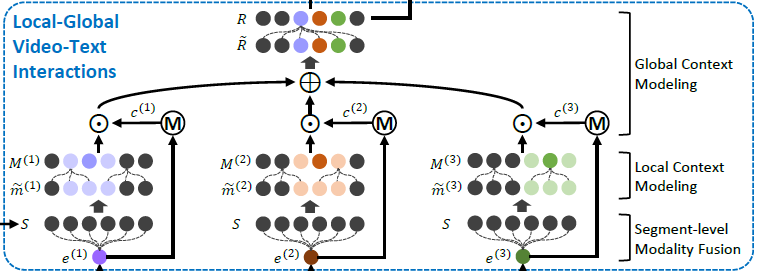
수식 (8)을 보면 n번째 단계, i번째 segment의 multi-modal feature \tilde{m}_{i}^{(n)}은 현재 semantic phrase와 segment를 각각 linear transform 한 뒤 아다마르 곱 연산을 해준 형태입니다. 결국 두 모달 간 가장 naive한 interaction은 아다마르 곱으로 표현해주었고 이 과정을 통해 각 segment가 현재 semantic phrase에 얼마나 잘 상응하는지 알 수 있을 것입니다. 하지만 이와 같은 segment-level modality fusion 과정에 관여하는 하나의 segment는 16프레임에 해당하기 때문에 현재 semantic phrase가 담고 있는 좀 더 긴 시간 영역의 정보를 전부 표현하기엔 부족합니다. 즉, semantic phrase와 좀 더 넓은 범위의 segment 집합(local) 간의 interaction이 필요하다는 것입니다.
이를 위해 적용한 것이 local context modeling 입니다. 이는 수식 (9)에 해당하며, 별다른 모듈이 특별하게 붙은 것은 아니고 2개의 temporal conv layer로 구성된 Residual Block(ResBlock)이 적용된 것입니다. 이 ResBlock이 단일 segment에 비해 좀 더 넓은 local 영역을 본다고 이야기할 수 있는 이유는, ResBlock을 구성하는 temporal conv의 kernel size가 15로 지정되어있기 때문입니다. 총 T개의 segment feature 중 15개 씩 엮어 다시 연산함으로써 앞서 수식 (8)에서 snippet-level로 수행되던 interaction의 범위를 다시 좀 더 넓은 범위에서 modeling해주는 것입니다.
수식 (8), (9)를 통해 얻은 n번째 semantics-specific segment feature M^{(n)}\in{}\mathbb{R}^{d \times{} T}는 각 단계에서의 semantic phrase와 모든 segment간 관계가 local하게 고려된 feature라고 볼 수 있습니다.
Relation modeling between semantic phrases
위 절까지 수행하여 얻은 N개의 semantics-specific segment features \{M^{(1)}, \cdots{}, M^{(N)}\}은 N개의 semantic phrases 서로 간의 관계를 고려하지 않은 상태입니다. 각 단계마다 독립적인 weight를 적용해주며 내부적인 연산만을 수행했었죠.
하지만 query text와 비디오의 segment 각각 문맥 정보와 시간적 정보를 가지고 있기 때문에, 현재 단계보다 하나 더 global한 정보를 모델링해줄 필요가 있습니다. 예를 들어 아까 예시로 사용했던 query(the woman mixed all ingredients, put it in a pan and put it in the oven)에서 두 번 등장하는 ‘it‘은 앞 절을 봐야 무엇을 의미하는지 알 수 있고, 문장 상에서의 거리나 비디오 상에서의 시간적 거리가 멀기에 좀 더 global한 정보를 모델링해줄 필요가 있다고 이야기하는 것입니다.
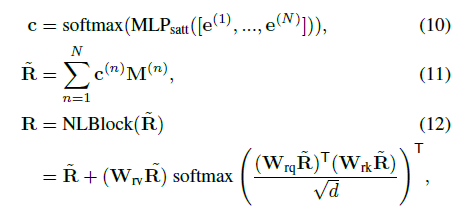
이는 수식 (10), (11), (12)에 따라 진행됩니다. 우선 수식 (10)을 통해 총 N개의 semantic phrase feature들의 score를 추출하게 됩니다. 이 attention score들은 수식 (11)에서 각 단계의 segment feature M^{(n)}에 가중치로서 적용되며 이후에는 넓은 범위의 global context를 주입해주기 위해 Non-Local block(NLBlock)의 입력으로 들어가게 됩니다.
Non-local network는 CNN 연산에서도 공간 축 또는 시간 축에 대한 long range dependency를 다룰 수 있도록 설계되었으며 영상의 공간축 또는 영상 간 temporal 축에 대해 타 영역과 유사도를 구해 비슷한 영역일수록 수식에서도 알 수 있듯 NLBlock의 연산 자체는 self-attention과 동일합니다. 하지만 입력값에 타 영역(여기서는 타 semantic phrases)과의 response가 고려되어있기 때문에 Non-Local Block이라 명시한 것으로 보입니다. 결과적으로 본 모듈을 통해 \text{MLP}_{satt}를 통해 얻은 attention score로 N개의 semantic phrases 간 관계를 고려하였고, self-attention을 통해 global하게 타 semantic phrases 및 이를 통해 생성한 segment feature 간의 관계를 global하게 고려해줄 수 있게 되었습니다.
2.5 Temporal Attention based Regression
이제 여러 과정을 통해 local context, global context를 multi-modal feature R에 담았으니 이를 이용해 구간을 예측해야합니다. 이 과정은 아래 수식과 같습니다.
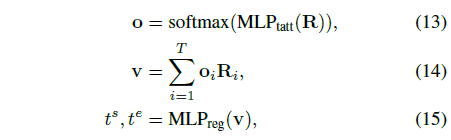
최종적으로 수식 (15)에서는 \text{MLP}_{reg}를 통해 하나의 비디오와 query 쌍에 대한 시작, 끝 구간을 예측하고 있습니다. 이 때 수식 (14)에 따르면 v는 수식 (13)으로부터 얻은 attention score를 활용한 시간축에 대한 가중합으로 구성되는 것을 알 수 있습니다. 사실 논문의 방법론 내내 FC layer와 이를 활용한 attention score들이 계속 적용되고 있는데, 딱히 어떠한 목적이나 저자의 고찰이 담겨있지는 않습니다. 마지막 예측을 만들어내기 전 다시 한 번 suppress를 진행해주는 듯한 모습입니다.
2.6 Training
이제 학습에 사용되는 loss들을 정리하고 실험 부분으로 넘어가겠습니다.
- \mathcal{L} = \mathcal{L}_{reg}+\mathcal{L}_{tag}+\mathcal{L}_{dqa}
\mathcal{L}_{reg}: Location regression loss
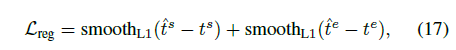
TSGV에도 weakly-supervised가 존재하지만 현재는 Fully-supervised이므로 학습 중 query에 대한 GT 시간 구간을 활용할 수 있습니다. \mathcal{L}_{reg}는 [0, 1]사이로 정규화된 시간 구간과 모델의 예측 시간 구간을 smooth L1 loss로 regression하는 역할을 수행합니다. TSGV 학습을 위한 가장 기본적인 loss인 것으로 보입니다.
\mathcal{L}_{tag}: Temporal attention guidance loss
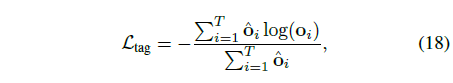
수식 (13)에서 추출한 temporal 축에 대한 attention score o는 위에서 이야기한대로 예측 이전 segment-wise로 곱해지는 중요한 attention 값입니다. 학습 중 실제 GT 구간을 알고있으니, o가 해당 분포를 따라가도록 위 수식 (18)과 같이 학습시킬 수 있습니다. \hat{o}_{i}의 경우 i번째 segment가 GT 구간 내라면 1, 아니면 0이 부여됩니다. 수식을 통해 실제 GT 구간의 o_{i}값이 커지도록 학습됨을 알 수 있습니다.
\mathcal{L}_{dqa}: Distinct query attention loss
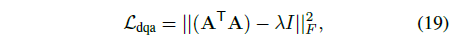
수식 (19)에서 A \in{} \mathbb{R}^{L \times{} N}는 N개 단계 각각에서 얻은 attention을 쿼리에 각각 곱한 후 이들을 concat한 feature이고 F는 frobenius norm(matrix의 L2-norm과 동일)을 의미합니다. 저희 Access 논문 작업 때도 text feature가 서로 달라지도록 동일한 형태의 loss를 준적이 있는데, 이곳저곳에서 다양하게 활용되는 것 같습니다. 결과적으로 \mathcal{L}_{dqa}의 효과는 A가 orthogonal 해지도록, 즉 attention weight들이 극단적으로 보았을 땐 one-hot vector에 가까우저ㅣ며 선별된 N개의 semantic phrases들이 서로 다른 영역에 집중하도록 만들어주는 것이라고 볼 수 있습니다. 수식에서 \lambda{}는 [0, 1] 사이의 값으로, 1에 가까울수록 orthogonal해진다고 이해할 수 있습니다.
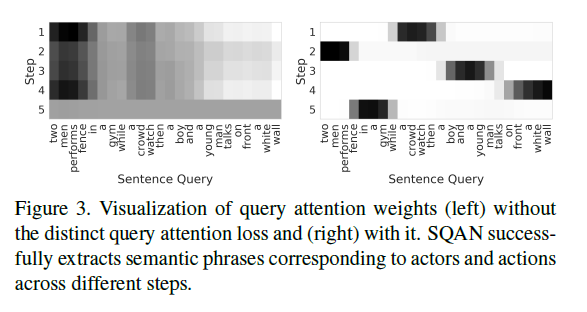
그림 3의 좌우를 비교함으로써 \mathcal{L}_{dqa}의 효과를 비교할 수 있고 체리피킹일 수 있겠지만 사람이 보았을 때도 꽤나 유의미한 단위의 절로 나누고 있는 것을 볼 수 있습니다.
앞선 두 가지의 loss는 단순히 실제 query에 상응하는 구간에 대한 GT를 가지고있기 때문에 쉽게 적용할 수 있었던 loss들이고, 세 번째 loss가 저자의 모듈에만 붙일 수 있는 loss였습니다. 각 loss가 어떤 효과를 보여주는지는 ablation study를 통해 알아보겠습니다.
3. Experiments
먼저 TSGV에서 벤치마킹하는 대표적인 데이터셋과 평가지표 등을 간단히 정리하고 넘어가겠습니다.
3.1 Datasets
Charades-STA
기존 Charades 데이터셋 중 TSGV task를 위해 샘플링된 데이터셋으로, 학습과 테스트 셋에는 각각 12,408, 3,720개의 구간-text 쌍이 존재합니다. 하나의 비디오는 평균 30초이며 하나의 query에 대한 최대 비디오 구간은 10초입니다.
ActivityNet Captions
본 데이터셋은 TSGV 또는 dense captioning을 위해 활용되는 데이터셋입니다. 한 비디오당 평균 3.65개의 query 구간을 가지고 있으며 한 쿼리의 길이는 평균 13.48단어입니다.
3.2 Metrics
TSGV 벤치마킹에는 두 가지 평가지표가 사용됩니다. 하나는 Recall@tIoU로 모델이 예측한 구간과 실제 정답 구간의 tIoU threshold를 여러 값으로 조절해가며 TP를 측정했을 때의 Recall 값을 의미합니다. 두 번째는 mean averaged tIoU로, tIoU {0.3, 0.5, 0.7}을 기준으로 TP를 측정했을 때 얻는 예측 구간과 실제 구간의 평균 tIoU의 평균입니다.
*참고로 3D encoder는 I3D와 C3D를 이용해 실험했다고 합니다.
3.3 Comparison with Other Methods
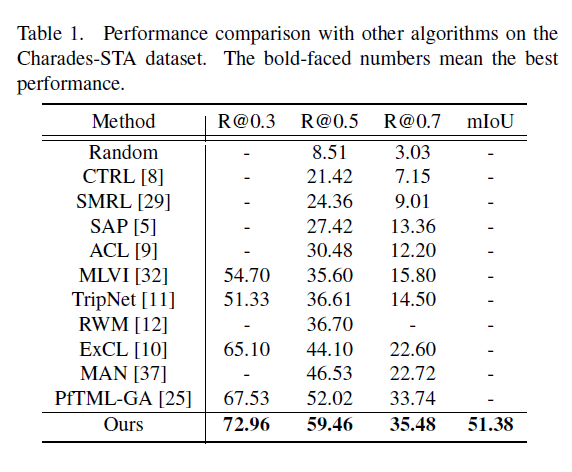
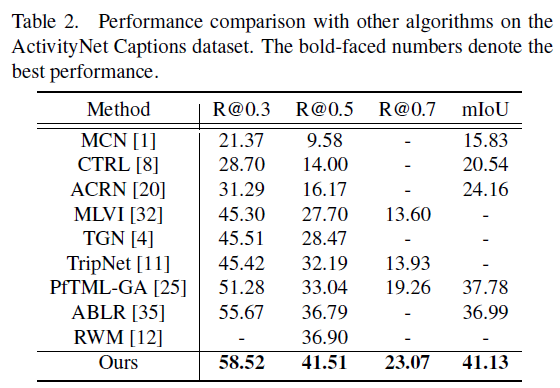
표 1, 2는 각 벤치마크 데이터셋에 대한 성능 비교 표입니다. 두 데이터셋 모두에서 유의미한 성능 향상을 보여주고 있고, 주어지는 text query를 의미론적으로 쪼개어 모델링하는 방법론은 본 논문이 처음이기에 이것이 유의미하게 동작했다고 생각합니다.
3.4 Ablation Studies

표 3은 loss 및 모델 구조에 대한 ablation입니다. 본 논문이 제안하는 방법론의 이름이 LGI에 해당하여 첫 번째 행이 가장 높은 성능을 보여주고 있습니다. LGI-SQAN은 기존 모델에서 SQAN 구조를 제외하였을 때의 성능입니다. SQAN을 제외한다면 semantic phrase를 추출할 수 없고 그 대신 sentence-level의 feature를 통째로 사용하여 localization한 경우를 의미합니다. 그래도 local-global 차원의 context modeling은 유지된 상태입니다.
결과를 보면 확실히 temporal annotation을 활용하는 loss들이 유의미한 성능 향상을 보여주고 있습니다. 또한 LGI-SQAN은 이미 기존 SOTA의 성능을 뛰어넘으며 저자가 주장하는 local, global context modeling 자체가 유의미했음을 알 수 있습니다.
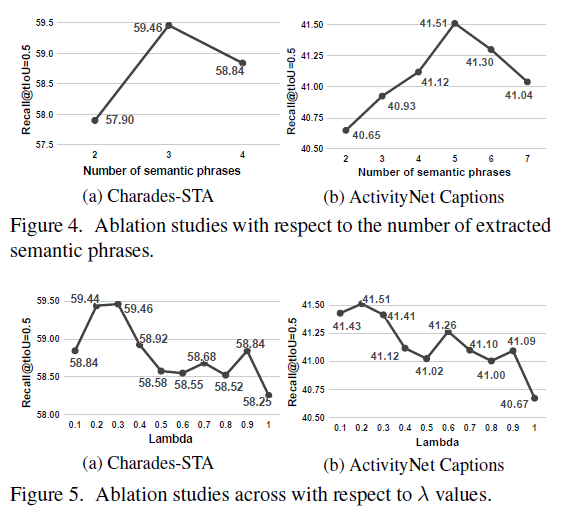
그림 5는 중요한 하이퍼파라미터 두 가지에 대한 ablation 성능입니다. 각각 추출하는 semantic phrases의 개수와 \mathcal{L}_{dqa}에 사용되는 \lambda{}입니다. 각 변수를 조정할 때마다 성능 차이가 꽤나 큰 것을 볼 수 있습니다.
본문에 추가적인 실험들이 있으니, 궁금하신 분들은 논문을 참고하시거나 추가적으로 궁금한 부분에 대해 질문 주시면 답변 드리도록 하겠습니다.
Conclusion
방법론 차원에서 거의 처음 읽은 논문이라 리뷰가 전체적으로 긴 번역문 느낌이 되어버린 것 같습니다. 이제부터 최신 방법론까지 follow-up 하며 리뷰를 작성할 예정이니, 추후에는 더욱 자세한 설명과 저만의 고찰을 담아 리뷰를 작성해보도록 하겠습니다. 읽어주셔서 감사합니다.