안녕하세요, 스무 번째 X-Review입니다. 이번 논문은 2019년도 CVPR에 게재된 Guided Aggregation Net for End-to-end Stereo Matching 논문입니다. 그럼 바로 리뷰 시작하겠습니다 !
1. Introduction
stereo reconstruction은 스테레오 이미지 쌍에서 매칭된 pixel들 사이의 disparity를 계산함으로써 3D 기하학을 추정합니다. 이는 현실 세계의 다양한 문제로 인해 챌린징한 문제를 갖고 있는데, 예를 들어 occlusion이나 텍스쳐가 없는 넓은 영역(하늘이나 벽과 같은), 창문과 같은 반사되는 영역 그리고 물체의 얇은 영역과 반복되는 텍스쳐가 있는 경우가 있겠습니다. 전통적인 stereo recongstruction은 3가지 단계로 생각해볼 수 있는데, 먼저 matching cost를 계산하기 위한 특징 추출 단계를 거친 후, matching cost를 aggregation한 다음 disparity를 예측하게 됩니다. Feature 기반의 매칭은 앞에서 언급한 challenge한 상황에서 종종 모호한 결과를 보일 수 있는데, 모호한 결과라는 의미는 잘못된 매칭이 correct한 매칭보다 더 낮은 cost를 가질 수 있다는 의미힙니다. 그러므로 챌린징한 영역에서는 매칭 cost를 aggregation하는 과정이 정확한 disparity를 추정하기 위한 중요한 단계입니다.
이후에 dnn을 통해 matching cost를 계산한 후 전통적인 방식 기반의 cost aggregation을 하는 방법론들이 등장하게 됐는데, 이 조차도 여전히 텍스처가 없는 상황이나, 반사되는 영역, occluded 영역에서 좋은 성능을 내지 못하였습니다. 그래서 end-to-end로 동작하는 최초의 방법론인 DispNet이 등장하기도 하였고, 그 후엔 3D convolution을 사용하여 cost aggregation하는 GC-Net도 등장하기도 하였습니다. 저번에 리뷰한 PSMNet같은 경우도 많은 수의 3D convolution 층을 사용하여 cost를 aggregation하는 방법론이였습니다. 하지만, 3D convolution을 사용하게 되면 많은 양의 메모리가 필요할 뿐만 아니라 계산량도 많이 요구됩니다. 이를 해결하기 위해 down-sampling과 up-sampling을 하기도 하지만 이는 정확한 disparity map을 구하기 어려워집니다.
이런 방식들 중에는 전통적인 semi-global matching (이하 SGM)과 cost filtering이 존재하는데, 이들은 많은 산업 제품에 사용될정도로 robust하고 효율적으로 cost를 aggregation하는 방법론입니다. 다만, 미분가능하지 않기 때문에 쉽게 end-to-end로 학습하지 못한다는 단점이 있습니다. 본 논문에서 저자는 end-to-end stereo reconstruction을 위한 두 가지의 새로운 cost aggregation 층을 소개하는데, 이 layer들은 기존에 사용되던 3D convolution을 대채하기 위한 목적으로 제안된 것입니다. 제안된 layer들을 3D convolution 대신 사용함으로써 메모리와 계산량도 줄이며 정확도도 줄이게 됩니다. 먼저, semi-global guided aggregation layer(이하 SGA)를 제안하는데 이는 앞전에 소개한 전통적인 semi-global matching을 근사화한 것이며 미분가능하도록 하여 end-to-end로 동작할 수 있도록 하였습니다. 이는 전체 이미지에 대해 다른 여러 방향에서 matching cost를 aggregation하는 식으로 동작하며, 이로써 occluded 영역이나, large textureless 지역에서 정확한 추정을 할 수 있게 됩니다. 다른 방향이라고 하는 점이 모호할 수 있겠으나, 이는 method 부분에서 자세히 서술하도록 하겠습니다. 두 번째로 제안한 것은 local guided aggregation layer(이하 LGA)입니다. 이는 물체가 얇거나 물체의 edge 부분에서는 down-sampling 후 up-sampling 레이어를 통과하게 되면 디테일한 정보가 손실될 수 있는데 이를 복구하는데 도움을 주는 layer입니다.

위 Figure 1은 (a)와 같은 입력 이미지가 들어왔을 때 기존 SOTA 방법론인 GC-Net과 본 논문에서 제안하는 방법론 간의 정성적인 비교를 보여줍니다. 저 입력 이미지 같은 경우에는 기타 부분이 large textureless하며 이는 챌린징한 영상이라고 볼 수 있겠습니다. 결과를 보면 (c)의 GA-Net이 (b)의 GC-Net보다 좋은 성능능을 보임을 확인할 수 있는데, GANet같은 경우 오직 2개의 GA 층과 2개의 3D convolution을 사용한 반면 GC-Net은 19개의 3D convolution 층을 사용하였습니다. 이때 한 GA 층은 3D conv의 1/100 계산 복잡도를 가지게 됩니다. 결국 GA-Net같은 경우 SOTA 방법론인 GC-Net보다 좋은 성능을 가지며 더 빠르게 동작하는 방법론이라고 할 수 있겠습니다.
2. Related Work
본 방법론이 전통적인 local, semi-global cost aggregation 알고리즘을 차용한 것이기에 짧게 local cost aggregation과 semi-global matching에 대해 살펴보고 가겠습니다.
2.1. Cost Aggregation
2.1.1. Local Cost Aggregation
cost volume C는 각 pixel 위치에서 각 disparity d에 대한 matching cost로 구성됩니다. 즉, H x W x D_{max}의 크기를 갖게 되며 각 disparity d에 대해서 slice해본다면 D_{max}개의 slice로 나눌 수 있겠습니다. 효율적으로 cost를 aggregation하는 방법론은 local cost filter 프레임워크인데, 이는 단순히 slice된 각 cost volume C(d)를 guided image filter를 통해 독립적으로 필터링 하는 것입니다. guided image filter는 edge를 보존하는 특성을 가지고 있는 필터입니다.
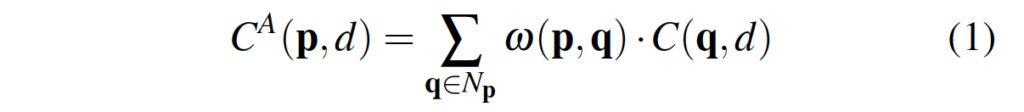
- C^A(p, d) : pixel p의 disparity d에 대한 aggregation cost
- w(p, q) : 픽셀 p와 q사이의 가중치
- C(q, d) : 픽셀 q의 시차 d에 대한 matching cost
disparity d인 경우에서 (x, y) 좌표에 위치한 픽셀 p에 대한 filtering은 위 식 (1)과 같이 진행되는데, p의 이웃픽셀들에 대해 가중합한 후 평균때리는 식으로 동작합니다. 이때 q는 같은 disparity d에 대한 slice에 위치해야겠죠. 이때 w(p, q)가 guided image filter를 통해 계산됩니다.
2.1.2. Semi-Global Matching
semi global matching 수식은 아래와 같습니다.
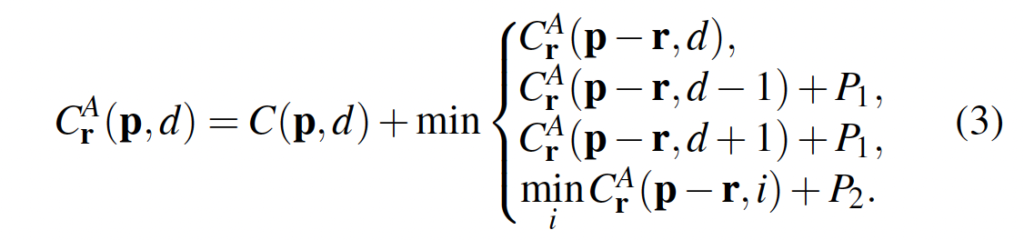
- C^A(p, d) : pixel p의 disparity d에 대한 aggregation cost
여기서는 방향이라는 개념이 등장하는데, 위 식에서 r이 방향에 해당합니다. SGM은 16가지 방향에서 1차원으로 matching cost를 aggregation하게 됩니다.
3. Guided Aggregation Net
3.1. Guided Aggregation Layers
PSMNet, GC-Net과 같이 당시 SOTA였던 end-to-end 스테레오 매칭 방법론 같은 경우 H x W x D_{max} x F(feature size) 크기의 cost volume을 사용했었습니다. 이는 두 스테레오 뷰에서 뽑은 feature들을 concat하는 식으로 생성한 것입니다. 이런 접근 방식과는 다르게 본 논문에서는 전통적인 semi-global과 local matching cost aggregation 방법론에서 영감을 받아 semi-global guided aggregation(SGA)와 local guided aggregation (LGA) layer를 제안하였습니다. 이 각각의 layer에 대해 알아보도록 하겠습니다.
3.1.1. Semi-Global Aggregation
전통적인 SGM은 matching cost를 다른 방향에서 반복적으로 aggregate하는 식으로 동작하는데, 이를 end-to-end로 학습가능한 모델에 접목하기는 어려운 점이 몇가지 있습니다.
먼저, SGM은 (P_1, P_2)와 같은 사전에 정의해줘야 하는 파라미터들이 많았는데, 이들을 간단하게 선택하기는 어렵다는 점입니다. 이 모든 파라미터들은 neural network에서 학습하기에는 불안정한 요소로 , 민감한 요인으로 작용할 수 있습니다. 다음으로, SGM에서의 cost aggregation과 패널티들은 다양한 조건에 맞게 조정되지 않고 모든 픽셀, 영역 및 이미지에 대해 고정되어 있다는 점입니다. 즉, 다양한 환경 조건에 유연하게 대응하지 못한다는 것이죠. 마지막 세번째로는, hard-minimum 선택으로 인해 깊이 추정에서 많은 평평한 표현이 발생합니다. 다시 말하자면 최종적으로 depth를 추정할 때 수직이나 경사가 있는 표면들을 무시하고 수평 표면이 생성된다는 문제가 발생할 수 있다는 것을 의미힙니다.
본 논문의 저자는 역전파 할 수 있는 새로운 semi-global cost aggregation step을 제안합니다. 이는 전통적인 SGM보다 훨씬 효과적이며 dnn 모델에서 사용될 수 있죠. 제안된 aggregation 단계는 아래 수식 4에서 살펴볼 수 있습니다.
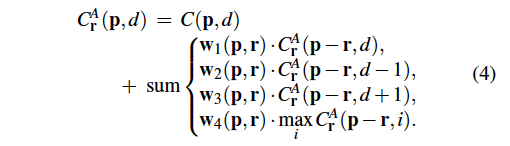
이는 전통적인 SGM과 3가지 방면에서 다른 점이 존재합니다. 먼저, 직접 사전에 정의해줘야 했던 파라미터들을 학습 가능하도록 만들었으며, 이를 matching cost의 패널티 계수와 가중치로 사용되도록 하였습니다. 그럼 이런 가중치들은 서로 다른 상황에서 adaptive하게 동작할 수 있겠죠. 두번째로 식 3에서 minimum 값을 선택해서 사용했던 것과는 다르게 식 4를 보면 가중합을 하도록 변경했다는 것을 확인할 수 있습니다. 이는 타 논문에서 사용한 방식을 인용한 것입니다. 마지막 세번째로 식3의 내부 식 마지막 줄에서 minimum 값을 사용하던 것을 maximum 값을 사용하도록 변경하였습니다. 이는 본 모델에서 학습 타겟이 matching cost를 최소화하는 것이 아닌 gt depth에서의 확률을 최대화하는 것이기 때문입니다.
추가로 저자는 식 3, 4를 통해 얻는 C^A_r(p, d)의 값이 굉장히 큰 값을 가질 수 있다는 점을 고려하여 가중치를 normalize하였습니다. 해당 식은 아래 식 5에서 확인할 수 있습니다.
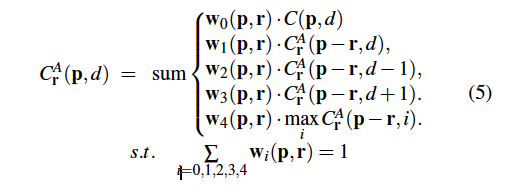
식을 보면 w_0, …. w_4의 가중치 합이 1이 되도록 정규화 되어 있는 것을 확인할 수 있습니다. 이 가중치들은 guidance subnet을 통해 얻어집니다. 이는 아래 Fig2에서 맨 위에 초록색 블록들을 의미합니다. 기존 SGM이 16개의 방향에서 aggregation을 수행한다고 했었는데, 제안된 방법은 이미지 전체에서 각 행, 열을 따라 왼쪽 오른쪽 위 아래 방향으로 총 4방향으로 aggregation을 수행합니다. Fig2에 (b)에서 확인할 수 있습니다. 그렇다면 식 5에서 방향 정보를 담고 있는 파라미터인 r에는 (0, 1), (0, -1), (1, 0), (-1, 0) 네 값중 하나가 들어가게 되겠죠.
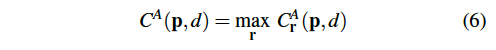
최종적인 C^A(p, d) 같은 경우는 식 6과 같이 네 방향 중에서 최대값을 선택하여 얻어집니다.
3.1.2. Local Aggregation
이제 local guided aggregation (LGA) layer에 대해 소개하도록 하겠습니다. 이 layer는 얇은 물체와, 물체의 edge 부분에 대한 성능을 개선하기 위해 고안되었습니다. 스테레오 매칭 모델에서는 종종 다운샘플링과 업샘플링을 사용하는데, 이는 thin structure와 edge 부분을 흐리게 만들었죠. LGA layer같은 경우 여러 개의 guided filter를 학습하여 matching cost를 개선하고 thin structure에 대한 정보를 복구하는데 도움을 줍니다. 이 local aggregation은 아래 식과 같이 쓸 수 있습니다.
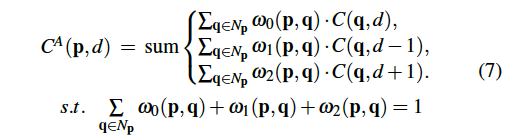
LGA에서는 cost volume의 서로 다른 slice들이 동일한 filtering/aggregation 기중치를 공유합니다. 이는 식 5의 SGA와 일치하죠. 여기서 slice는 cost volume의 세번째 차원에서 각 disparity 값으로 구성된 부분집합을 나타냅니다. LGA layer에서는 하나의K x K filter를 사용하는 전통적인 cost filter와는 다르게 각 pixel 위치 p에 대해 d, d-1, d+1에 대한 3가지 disparity에 대해 각각 k x k filter가 존재합니다. 이는 픽셀의 주변영역에서의 cost volume을 filtering하기 위한 것입니다.
3.2. Network Architecture
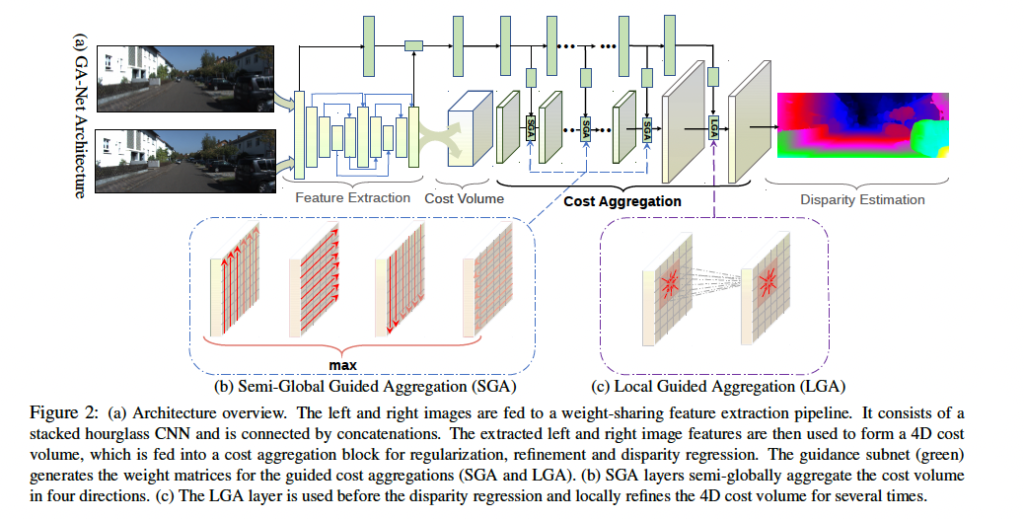
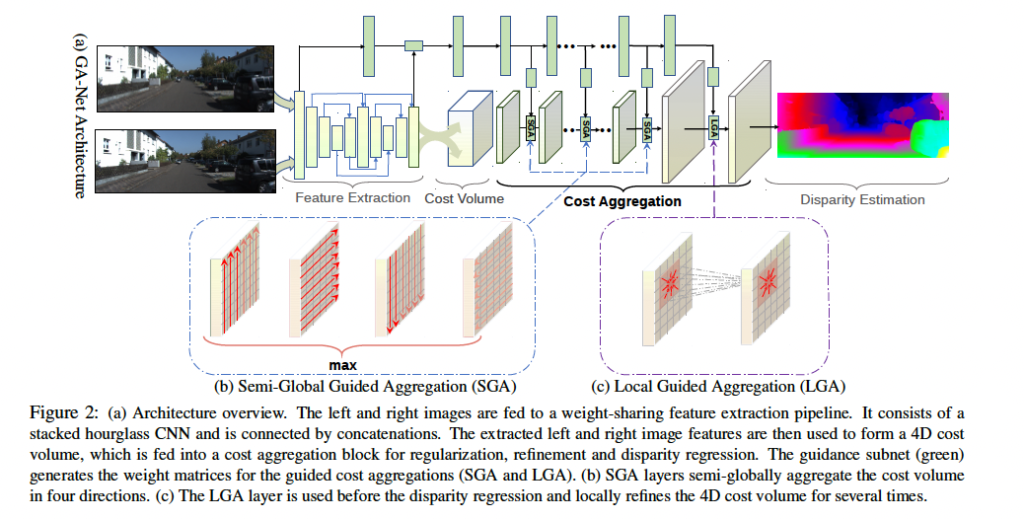
FIg 2에 보이는 것처럼 GA-Net은 4가지 파트로 구성되어 있습니다.
- feature extraction 블록
- cost aggregation
- cost aggregation weight를 생성하기 위한 guidance subnet (맨 위쪽 초록 block)
- disparity regression
특징 추출하는 block같은 경우 직전 리뷰한 PSMNet과 같이 stacked hourglass network를 사용하였습니다. 이 feature extraction block은 좌 우 이미지에 대해 공유되어 사용됩니다. 이후 좌 우 이미지에서 추출된 특징들을 사용하여 4D cost volume을 생성합니다. 이후 disparity를 regression하기 전 몇 개의 SGA layer를 태우고, LGA layer를 통과하는 것을 확인할 수 있습니다. 이는 thin한 structure에 대한 성능을 개선하고 cost volume을 구축하기 위해 수행한 다운샘플링으로 인한 정확도 손실을 복구하는 역할을 합니다. 또한 맨 위의 초록색 block인 guidance subnet을 통해 식 5, 식 7에서 사용되는 weight를 얻어낼 수 있습니다. 이 guidance subnet에는 한쪽 이미지가 입력으로 들어가게 됩니다. 이 guidance subnet은 몇 개의 2D convolution 층으로 구성되며 output은 GA layer를 위한 weight가 되겠죠.
3.3. Loss Function
손실함수로는 smooth L1 loss를 사용하였습니다. smooth l1이 l2 loss에 비해 disparity가 갑자기 변하는 지점에서 강인하며, 노이즈와 outlier에 덜 민감하기 때문이라고 합니다.
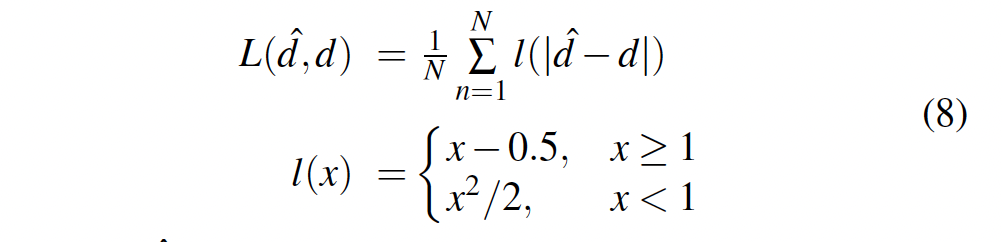
- \hat{d} : 예측한 disparity
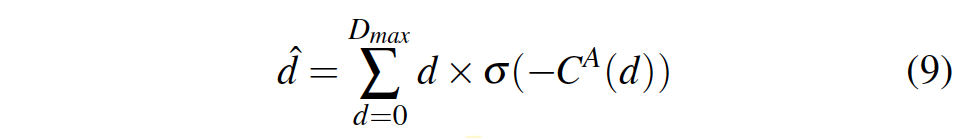
- σ() : softmax
4. Experiments
실험은 Scene Flow, KITTI 데이터셋에서 진행되었습니다.
4.1. Ablation Study
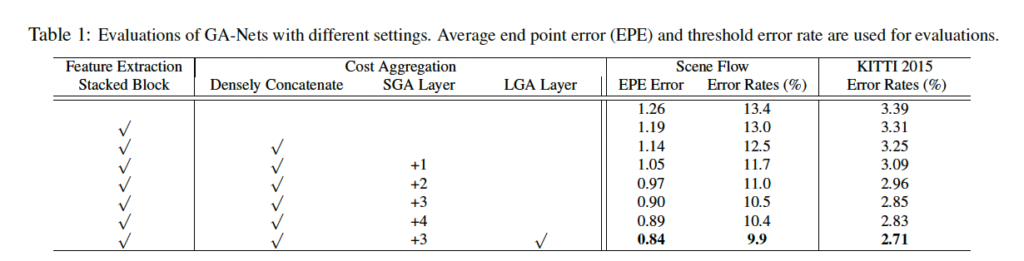
먼저 Ablation study인데, 최동 모든 모듈을 사용한 GA-Net 같은 경우 3D convolution layer만 사용한 baseline에 비하여 훨씬 더 좋은 성능을 보입니다.
평가지표로는 Error Rates(%)와 EPE Error를 사용하였는데, Error Rates(%)는 validation set에서의 MAE를 의미합니다. 즉, gt disparity와 예측한 disparity의 차이를 절대값으로 계산하여 얻어지는 성능이며 낮을수록 모델의 성능은 우수하다고 말할 수 있습니다. 또, EPE Error 같은 경우는 예측한 disparity와 gt disparity간의 픽셀 단위로 측정한 오차라고 보면 되겠습니다. Error Rates(%)와 마찬가지로 낮을수록 좋은 성능이겠죠.
4.2. Comparisons with SGMs and 3D Convolutions
SGA layer는 전통적인 방법론 SGM을 미분가능하도록 근사화한 것이였습니다.
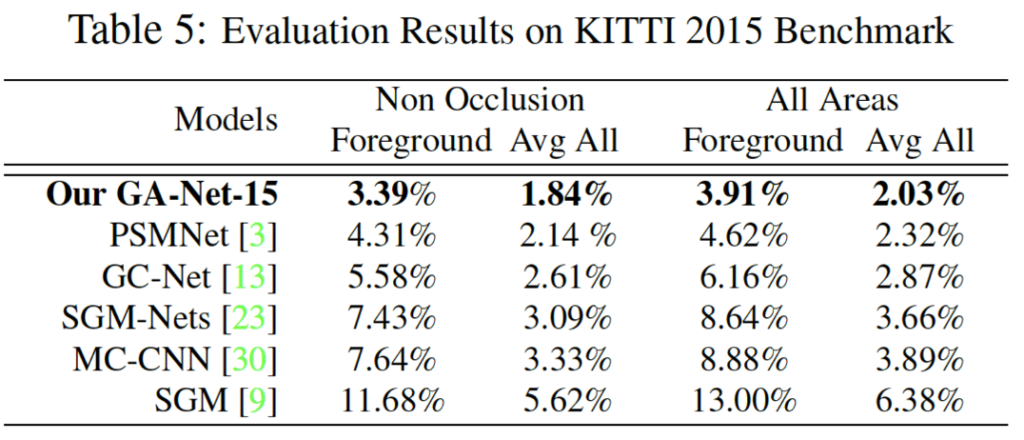
위 표 5를 보면 handcrafted 특징을 사용한 기존 SGM와 CNN 기반으로 추출한 특징을 사용한 MC-CNN과 비교해보았을 때 본 논문의 GA-Net은 훨씬 좋은 성능을 보입니다. 이는 SGA가 end-to-end로 학습가능한, 미리 사전에 정의해야 하는 파라미터가 없기 때문이라고 볼 수 있으며 SGA의 aggregation은 guidance subnet에서 얻어낸 weight을 사용하기 때문이라고 볼 수 있겠습니다.

또 기존 SGM과 비교해봤을 때 (b)와 같이 large textureless 영역에서 더 자연스러운 결과를 보입니다. 이는 기존 식 3의 hard minimum/maximum 선택 대신 식 5와 같이 soft 가중합을 사용한 결과로 보입니다.
4.3. Evaluations on Benchmarks
4.3.1. Scene Flow 데이터셋
Scene Flow 데이터셋은 합성 데이터셋으로서 35,454개의 학습 이미지와 4,370개의 테스트 이미지가 포함되어 있습니다.
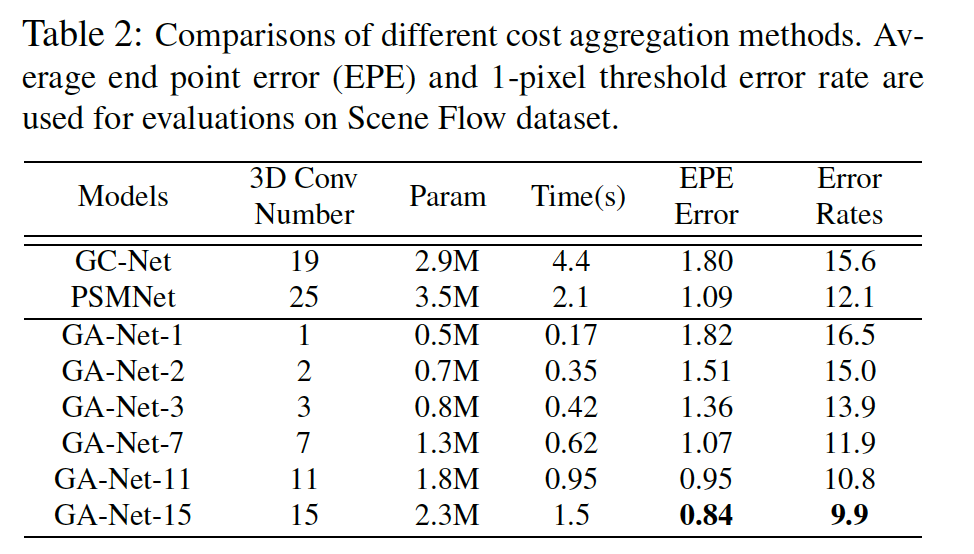
실험 결과는 위와 같습니다. 본 논문에서 제안한 GA-Net 같은 경우 당시 SOTA 방법론인 GC-Net과 PSMNet과 비교하였을 때 EPE Error와 Error Rates 두 평가지표에서 SOTA를 달성하였습니다.
4.3.2. KITTI 2012 and 2015 Datasets
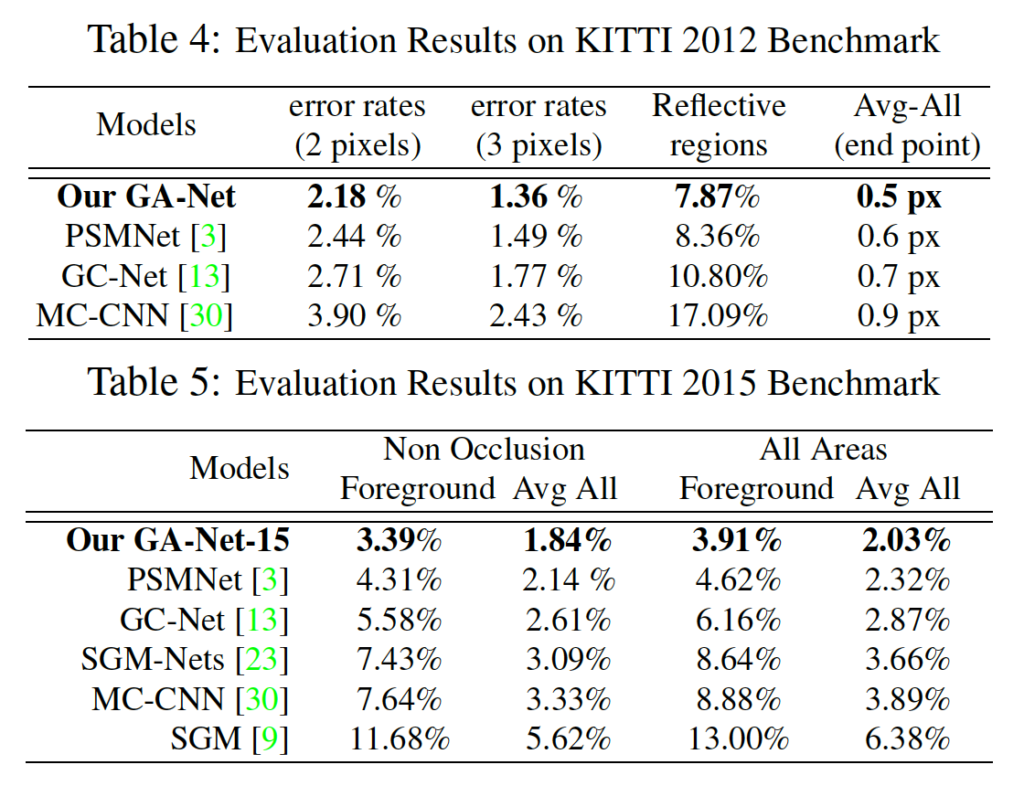
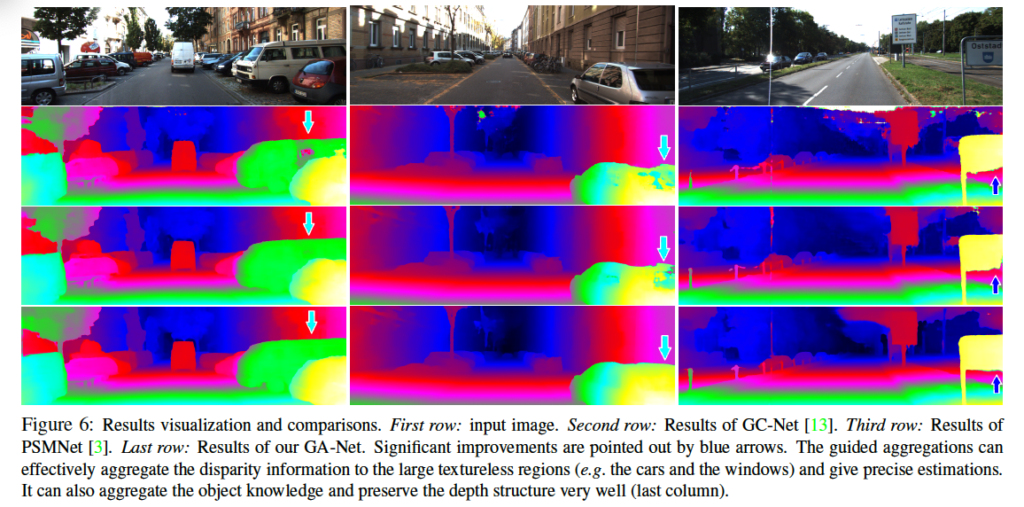
KITTI 데이터셋에 대한 결과는 표 4, 5에서 확인할 수 있습니다. 두 데이터셋에 대해 SOTA를 달성하였으며, GA-Net은 반사되는 영역에 대한 성능도 가장 좋은 것을 볼 수 있습니다. 아래 Figure 6은 이에 대한 정성적인 결과로 disparity를 추정하기 챌린지한 경우인 텍스처가 없는 경우와 반사되는 영역에 있어서 타 방법론인 PSMNet과 GC-Net의 결과에 비해 좋은 결과를 보입니다.
안녕하세요, 정윤서 연구원님. 좋은 리뷰 감사합니다. matching cost 부분에서 질문이 있습니다. 제가 해당 분야를 잘 몰라서 그런지, matching cost와 cost aggregation이 무엇인지 잘 이해되지 않습니다. Related Work에 나와있긴 한데, 수식만 봐서는 이해가 힘드네요. matching cost가 손실함수에 포함되는 건가요? 그럼 cost를 최적화해서 학습을 진행한다는 뜻인가요? 손실함수를 보면 disparity에 대한 L1인것 같아서 그것도 아닌것 같은데.. 설명해주시면 감사하겠습니다!
안녕하세요 ! 댓글 감사합니다.
matching cost란 두 영상의 유사도를 pixel 단위로 측정하는 것을 의미하며 이를 하나의 볼륨으로 쌓은 것을 cost volume이라고 합니다. 이 cost volume의 정보를 aggregate해 계산된 cost 정보의 신뢰도를 높이는 과정이 cost aggregation 과정이라고 보면 될 것 같습니다. 이 cost aggregation 과정으로 나온 값들을 통해 disparity를 예측하게 되며 이를 최적화해 학습을 진행하게 됩니다.
리뷰 잘 읽었습니다.
‘pixel p의 disparity d에 대한 aggregation cost’ 라는 표현이 있는데 이 부분을 조금 더 풀어서 설명해주실 수 있을까요?? 해당 분야에 대해 잘 몰라서 그런지 aggregation이라는 단어가 잘 와닿지 않습니다.
그리고 D_max 는 무엇을 뜻하는 건가요???
감사합니다.
안녕하세요 ! 댓글 감사합니다.
D_max는 사전에 미리 설정한 disaprity의 최대값입니다.
matching cost를 계산한 후, 이 cost값들을 쌓아 cost volume을 만들게 되고 이 cost volume filtering을 통해 cost volume의 noise를 없애는 단계가 cost aggregation 과정이라고 보면 되겠습니다.
초기 cost volume상에서는 실제 서로 대응되는 픽셀들 사이에서 계산된 비용과 서로 대응되지 않은 픽셀들 사이에서 계산된 비용의 차는 크기 않지만, cost aggregation 과정에서 주변에 대응된 픽셀들을 합산한 것과 대응되지 않은 픽셀들의 비용을 합산한 것의 비용 차는 커지게 됩니다. 그렇게 되면 정확한 대응 픽셀을 탐색할 가능성은 높아집니ㄷ아.
안녕하세요 리뷰 잘 읽었습니다.
Related work에 언급해주신 local cost aggregation 같은 경우 cost volume shape이 W x H x D로 3D였는데, 아래에 네트워크 구조를 설명해주실 때는 4D cost volume을 생성한다고 나와있더군요. 흠.. 4D cost volume의 shape은 어떻게 되나요?
감사합니다
안녕하세요. 댓글 감사합니다.
4D cost volume은 H x W x D x F(feature sizes) 크기로, dispairty 레벨에서 왼쪽 이미지 feature와 오른쪽 이미지 feature를 concat해서 만들어집니다.