
안녕하세요, 허재연입니다. 이번에도 Active Learning(AL) 논문을 들고 왔습니다. CVPR 2018에 게재된 논문으로, Active Learning이 막 딥러닝에 접목되기 시작하던 시기의 논문입니다. CNN과 Active Learning을 최초로 결합했던 CEAL이 2017년 논문임을 감안하면 Deep Active Leaning의 초기 논문이라고 볼 수 있습니다. 그래서 논문의 내용에서도 지금은 크게 고려하지 않는 부분을 많이 다룹니다(SVM 등 기계 학습 기반 Active Learning을 언급 한다던가). 따라서 그런 내용은 자세히 다루지 않고 핵심적인 부분만 짚고 넘어가고자 합니다. Active Learning 논문을 읽다 보면 항상 Related Work에 언급되는 논문이고, citation도 현재 690으로 AL 분야의 논문 치고는 굉장히 높은 인용 수를 보이기 때문에 이번 기회에 읽어보게 되었습니다.
Active Learning은 deep learning의 실제 적용에 있어 허들이 되는 데이터 확보에 대한 문제를 해소하고자 합니다. 딥러닝 기술이 상당히 발달되어 이제 충분한 양의 데이터만 확보되면 높은 수준의 모델을 만들 수 있는데, 이런 데이터셋 취득에는 현실적으로 많은 시간 및 비용이 소모됩니다. 특히 데이터를 확보하는 것보다 학습에 필요한 label을 annotation하는 단계에서 더욱 그렇습니다. Active Learning은 모델 학습 효율이 좋은 고가치 데이터를 선별하는 방법을 연구합니다. 제한된 예산 안에서 가장 효율이 높은 데이터들을 확보하고자 합니다.
데이터의 가치를 판단하고 선별하는 수많은 습득함수(Acquisition Function)가 있지만, 크게 1. uncertainty 기반 방법론 계열과 2. diversity 기반 방법론 계열로 나눌 수 있습니다. 1.uncertainty 기반 방법론은 모델이 어려워하는 데이터가 학습 효율이 높은 데이터일 것이라는 관점으로 문제를 해결하고자 하며, 2.diversity 기반 방법론에서는 전체 데이터셋의 분포를 잘 반영하는 subset을 추출하고자 합니다. 이 둘을 함께 결합한 hybrid 기반 방법론들도 있습니다. 몇가지 대표적인 방법론들을 소개해 드리자면 다음과 같습니다 :
- Least Confidence, Margin Sampling, Entropy Sampling : 가장 기본적인 uncertainty 기반 방법입니다. classification task에서 모델의 예측 confidence(이미지 분류 CNN 모델을 예로 들면 softmax output의 분포) 및 Shannon의 entropy를 기준으로 불확실성이 높은 데이터를 선별합니다. 방법론이 간단하면서도 성능이 좋아서 AL에서 baseline으로 자주 등장합니다. 하지만 classification 이외의 task에는 적용하기 힘들다는 단점이 있습니다.
- Bayesian 방법 : 베이지안 네트워크를 active learning에 응용한 uncertainty 기반 방법론입니다. 논문 ‘Deep Bayesian Active Learning with Image Data’에서 Bayesian Uncertainty Estimation을 사용하는 방법론을 제안했습니다. 학습 시킬 때 모든 convolution layer 뒤에 MC dropout을 붙여서 학습 시킨 다음, inference 할 때도 dropout을 끄지 않고 N번 feedforward를 진행합니다. 그리고 이 N개 prediction의 variance를 이용해 uncertainty를 측정합니다. 이 또한 강력한 방법이지만, 모든 convolution 계층 뒤에 dropout을 붙이다 보니 학습 수렴이 매우 느리다는 단점이 있습니다. practical하지는 않은 편입니다.
- Learning Loss : LL4AL은 CVPR 2019에서 제안된 간단하면서도 강력한 uncertainty 방법으로, 딥러닝 학습이 결국 하나의 Loss값에서 시작된다는 점과 Loss가 큰 데이터는 uncertainty가 높을 것이라는 아이디어에서 착안해 제안된 방법론입니다. 본래 목적의 모델 아래 작은 loss prediction module을 붙여서 데이터의 loss값을 예측하도록 학습한 뒤, 데이터의 예상 loss를 기반으로 데이터의 불확신도를 판별합니다. 위 두 방법과 달리 (딥러닝은 어떤 task를 수행하더라도 loss값에서 경사하강법으로 역전파가 진행되니) 특정 task에 구애 받지 않으며, 학습에 필요한 computational cost도 낮다는 장점이 있습니다. 성능도 준수해서 이 또한 baseline으로 자주 등장합니다.
- Expected Model change : 모델을 가장 많이 변화시키는 데이터가 학습 효율이 높을 것이라는 관점의 접근법입니다. gradient의 크기를 예측하거나, 모델의 파라미터를 많이 업데이트 할 것으로 예상되는 데이터를 선별합니다.
- Core-set : diversity 기반 방법론인 core-set은 주변 데이터를 대표할 수 있는 중심점(core)들을 선별해서 전체 데이터 분포를 대표할 수 있는 subset을 추출하고자 합니다. 신경망의 feature space에만 의존하므로 classification이든 regression이든 Learning Loss처럼 task-agnostic하다는 장점이 있지만, 어려워하는 샘플을 전혀 고려하지 않고, unlabeled dataset의 크기가 너무 커지면 optimization이 굉장히 무거워진다는 단점이 있습니다.
오늘 다룰 논문은 uncertainty 기반 방법론으로 분류되는데, 하나의 single model을 이용해서 데이터의 uncertainty를 측정하는 기존 방법들과 달리 앙상블 방법으로 문제를 해결하고자 합니다. 짧게 요약하자면 동일 네트워크를 다르게 학습 시켜서 prediction의 variance를 측정해 이를 기반으로 uncertainty를 측정한다고 정리 할 수 있을 것 같네요. 방법론의 핵심은 사실 이게 전부입니다. 논문에서도 습득함수를 간단하게 언급하고 experiment로 넘어갑니다. 방법론이 간단하고 성능이 준수하긴 하지만, 아무래도 여러 모델을 학습시켜야 하니 연산량에 대한 부담이 있는 방법론입니다. 함께 살펴보겠습니다.
Methodology
딥러닝이 막 주목받기 시작하던 시기라서 그런지, introduction 부분은 대부분 딥러닝, CNN, image classification에 대해 다루고 Active Learning의 필요성에 대해 논합니다(위에서 설명한 부분과 동일한 내용입니다). 그리고 본 논문에서는 앙상블 기법에 대해 다룰 것이며 당시 SOTA인 베이지안 딥러닝 접근법(Monte Carlo Dropout)과 비교할 것이라며 method 부분으로 넘어갑니다.
Acquisition Function (Uncertainty Measure)
single network를 제외한, 여러 output을 산출할 수 있는 ensemble network와 MC-dropout network에서 uncertainty를 정량화하는 방법에는 1.Entropy, 2.Mutual Information, 3.Variance of Softmax Outputs, 4. Variation Ratio가 있습니다.
기본적으로 MC dropout의 베이지안 방법과, 여러 모델의 앙상블 방법에서 softmax vector는 다음과 같이 계산됩니다. 베이지안 방법에서 T번 forward pass를 하거나 앙상블 방법에서 T개의 모델을 사용했을 때, 확률값은 이들의 평균입니다. 아래 수식에서 x는 input이고, w는 weights값, c는 주어진 클래스입니다. uncertainty를 계산하는데 이용될 수 있겠죠?
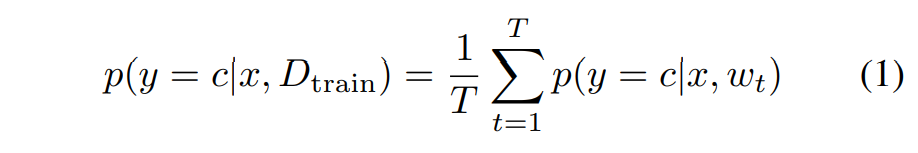
예측된 분류 확률 분포에서 가장 큰 Entropy를 갖는 data points를 선택하는게 자주 사용되는 방법이라고 합니다.
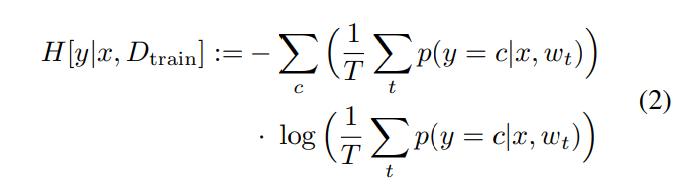
BALD(Bayesian active learning for classification and preference learning)라는 방법론에서는 data-point와 weights 간 mutual information를 이용합니다. 이 방법에서는 올바른 data label이 주어졌을 때, predicted label과 network 가중치 간 large mutual information을 가지는 data-points가 trained network에 큰 영향을 줄 것이라는 아이디어를 사용한다고 합니다. 해당 방법론에서는 엔트로피 값을 이용하여 측정하는데, cross-entropy 수식을 연상하며 뜯어보면 이해하기 편할 듯 합니다.
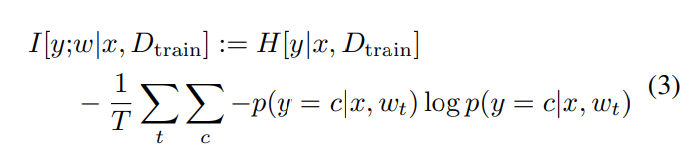
이 방법들 말고 앙상블이나 T번의 forward pass에 대해 softmax 출력벡터의 분산(Variance of the softmax output)도 acquisition function으로 사용될 수 있습니다.
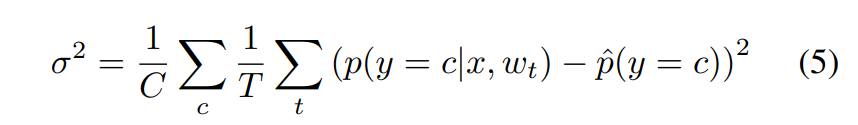
앙상블 네트워크는 single network와는 다르게 하나의 입력에 대해 여러 개의 output을 산출할 수 있습니다. 따라서 single network와는 또 다른 uncertainty 지표를 만들 수 있습니다. Variation Ratio는 여러 개의 output이 예측한 class 중 최빈값의 비율을 이용해 uncertainty를 측정하는 방법입니다. 이는 nominal variable의 분산을 측정한 것으로, model class prediction(softmax output)이 아닌 predicted class labels의 비율로 계산됩니다. Variation Ratio를 나타내는 아래 수식에서 fm은 model class category에 속하는 prediction의 수 입니다. 값이 클 수록 분산이 크다고 생각하시면 됩니다. 이 방법은 confidence값의 scale을 고려하지 않습니다. model prediction(예측 class에 대한 confidence값)을 활용하면 overconfidence 문제로 불확실성이 과소 평가될 우려가 있지만, variation ratio는 confidence값의 scale을 사용하지 않고 단순히 예측 결과만 따지기 때문에 overconfidence 문제에서 자유롭다는 장점이 있습니다. (현대의 딥러닝 모델은 특정 클래스에 대해 예측 확률을 과신하는 overconfidence 문제가 있고, 이 영향으로 불확실성이 과소평가 될 우려가 있습니다)
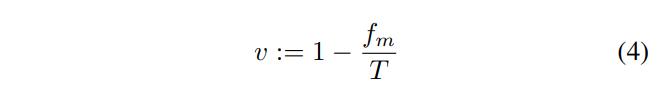
Experiments
해당 논문에서는 ensemble network 기반의 uncertainty estimation을 이용한 Active Learning이 Single Network와 MC-dropout 기반의 방법론보다 성능이 좋다는 것을 실험적으로 보입니다.
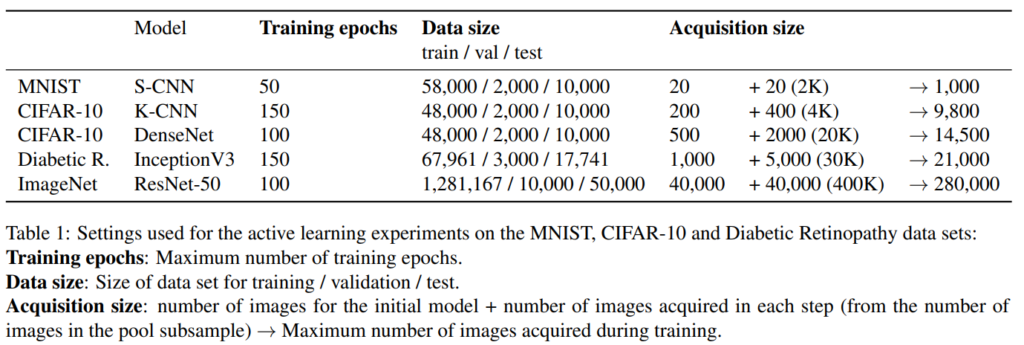
실험 세팅은 위와 같습니다. 데이터셋으로는 MNIST, CIFAR-10, ImageNet, Diabetic R이 사용되었으며 각 데이터셋에 따라 약간씩 다른 모델이 적용되었습니다(데이터셋의 크기와 복잡도를 고려한 것 같습니다). MNIST의 S-CNN은 2개의 convolutional layer와 1개의 dense layer로 구성된 모델이고, K-CNN은 4개의 convolutional layer와 1개의 dense layer로 구성된 모델입니다. 추가적으로 DenseNet121(bottleneck을 사용한 k=12버전)과 inceptionnV3, ResNet50이 사용되었습니다. acquisition size는 initial set의 크기와 step마다 추가하는 데이터 개수, 그리고 학습 과정 중 이용하는 전체 이미지 개수를 나타냅니다. Results는 5번 반복의 평균을 냈으며, MC dropout에 대해서는 25번의 forward passes를 이용했습니다. 각각의 앙상블에서는 (초기화만 다르게 된) 5개의 동일한 구조의 모델을 사용했다고 합니다.
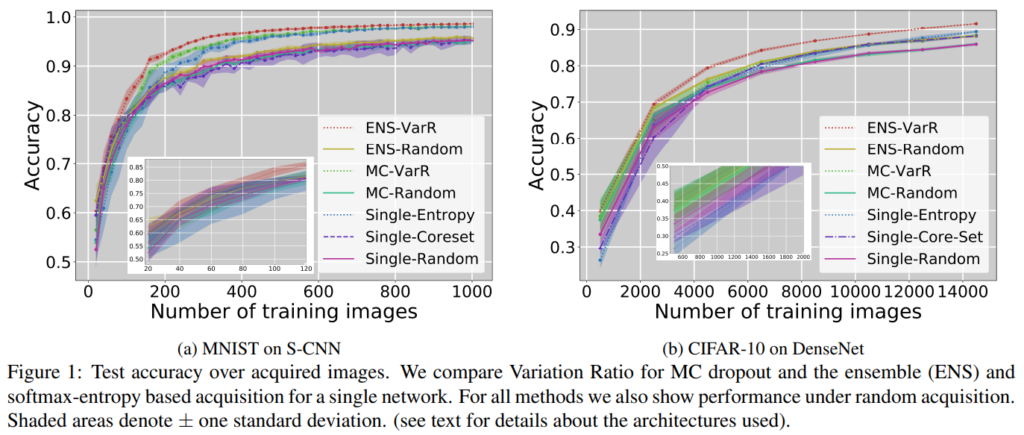
위 그래프에서는 MC dropout network와 ensemble network에서 Variation Ratio(VarR)를 사용했을 때 및 단일 네트워크에서의 softmax-entropy 기반 데이터 선별법을 사용했을 때의 성능을 비교했습니다. MNIST와 CIFAR에 대해서 ensemble-based 접근법이 다른 방법보다 확실히 성능이 좋습니다. single network를 사용하는 경우에 가장 성능이 낮았으며, 특히 core-set과 같은 representation 기반(distribution 기반 이라고도 합니다)의 습득 방법을 사용했을 때 성능이 매우 저조합니다.
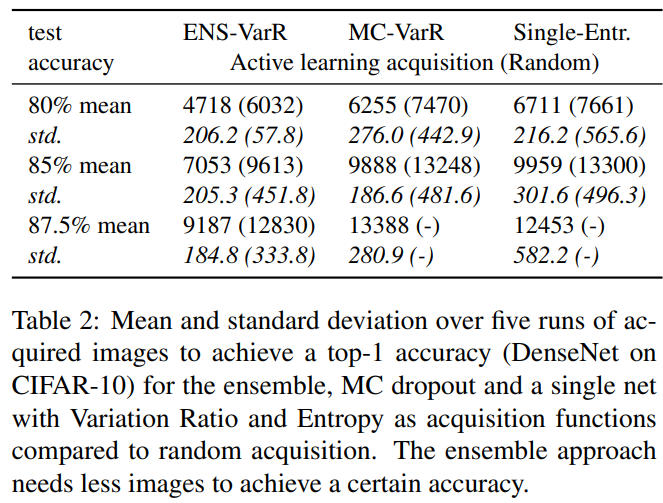
Table 2는 80%, 85%, 86%(CIFAR-10에서의 DenseNet)의 top-1 정확도를 달성하는데 필요한 labeled images의 5번 실행에 대한 평균/표준편차를 나타낸 것입니다. ENS-VarR이 엔트로피 기반 single network 접근법과 비교해 85%의 accuracy를 달성하는데 평균 2906(29.2%)개 이미지가 덜 필요합니다.
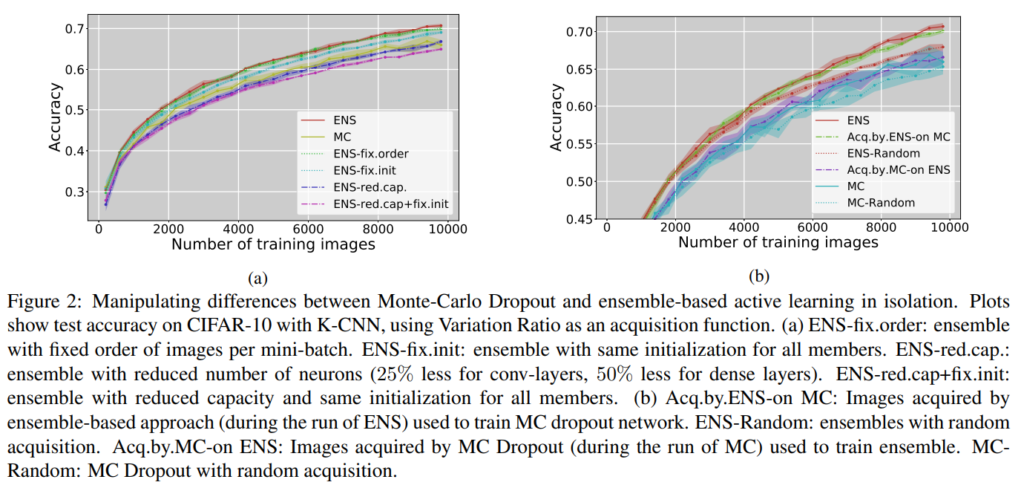
MC dropout network와 ensemble network에 대한 추가적인 실험입니다. (a)실험을 통해 다음 사실을 알 수 있습니다 :
1. MC dropout의 forward pass의 수(2,3,5 .. 100)를 변화시켜보고, ensemble member의 수(2,3,7)를 변화시키면서 비교했을 때 앙상블 멤버 수 변화는 매우 작은 영향만 끼쳤고, 어떻게 하더라도 ensemble network가 MC-dropout network의 성능을 크게 능가하였다.
2. ensemble 방법론이 제대로 효과를 보기 위해서는 random initialization과 충분한 capacity가 보장되어야 한다(표기를 살펴보면 다음과 같습니다. ENS-fix.order : 학습을 진행할 때 배치를 random suffle 하지 않고 fix order해서 고정된 순서로 배치 학습한 것. fix.init : 각 앙상블 모델을 random initialization해서 진행한 것이 아니라 동일한 initialization을 적용해서 학습. red.cap : 모델 크기를 줄이고 실험 진행. 결과를 보면 random initialization을 적용하고, fixed order를 적용하지 않고, random suffling을 적용하고 capacity를 줄이지 않았을 때 AL 성능이 가장 좋았다고 합니다)
앞에서의 비교는 single network와 ensemble을 비교한 것이기 때문에 올바른 비교로 볼 수 없어서, (b)에서는 classification model과 query model을 분리하여 실험을 진행했다고 합니다. 앙상블 네트워크의 variation ratio를 통해서 라벨링을 하였을 때 MC dropout의 성능 또한 올라가며, 그냥 앙상블 네트워크로 쿼리도 하고 분류도 하였을 때 가장 성능이 좋았다고 합니다. 앙상블 모델이 분류를 잘 할 뿐만 아니라 쿼리의 질 또한 앙상블을 사용하였을 때 좋다는 결론을 도출하게 됩니다.
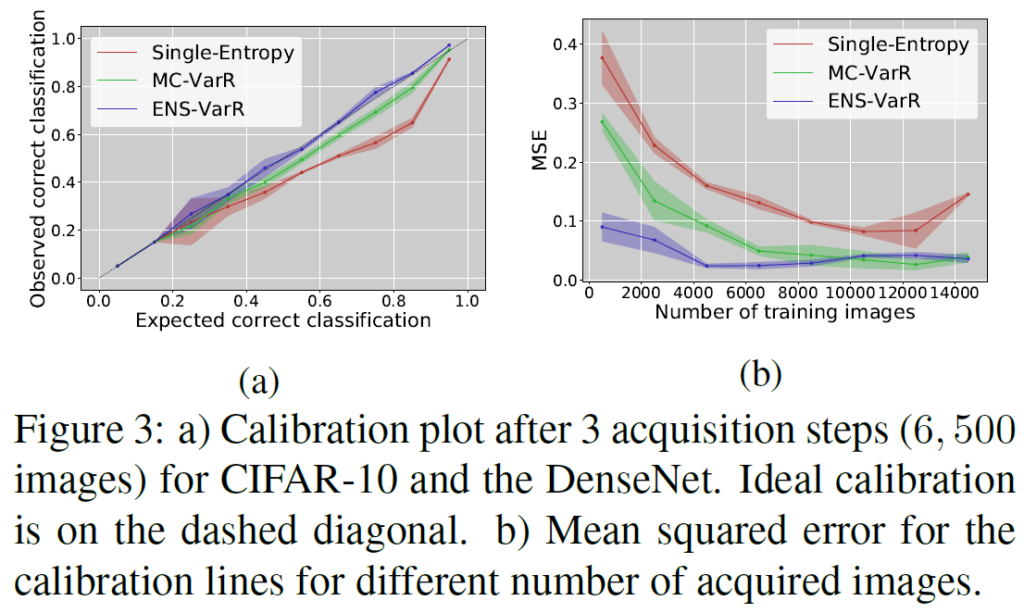
추가적인 실험으로는 캘리브레이션 성능을 측정합니다. 캘리브레이션이 좋을 수록 모델의 예측(softmax output)이 실제 정확도 분포와 유사하다고 생각하시면 되겠습니다(overconfidence 문제가 적어지겠죠). 해당 내용에 관심 있으신 분은 [ICML 2017] On Calibration of Modern Neural Networks라는 논문을 참고하시면 좋을 것 같습니다.
결과적으로 말하면, Fig 3.(a) 그림에서 그래프가 대각선 라인에 붙어있을수록 calibration 성능이 좋다고 생각하시면 됩니다. Fig 3.(b)는 MSE로 calibration 성능을 측정한 것인데, 성능 측정을 통해 ENS-VarR 방법에서의 uncertainty estimation 정확성을 평가했다고 생각하시면 됩니다. 실제로 ENS-VarR이 가장 높은 calibration 성능을 보임을 확인할 수 있습니다. 라벨링된 이미지(학습 데이터)가 많이 늘어나면 MC dropout을 사용하는것도 calibration이 어느 정도 잘 되는 것을 확인할 수 있는데, image가 적을 때는 MC dropout이 확연하게 Ensemble보다 MSE가 큽니다.
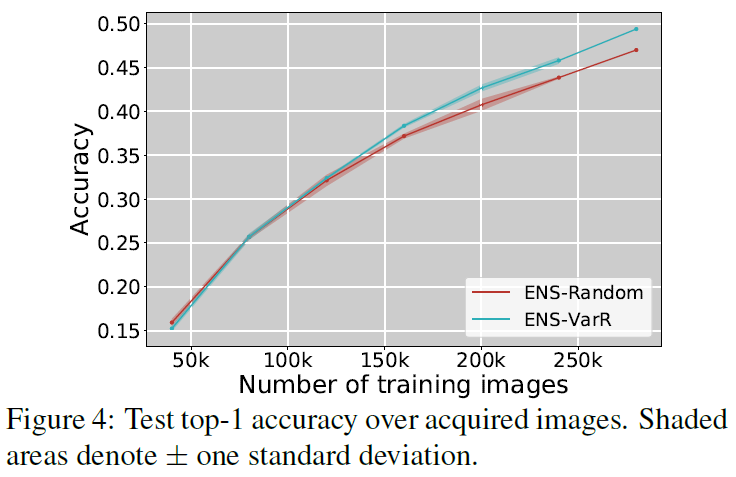
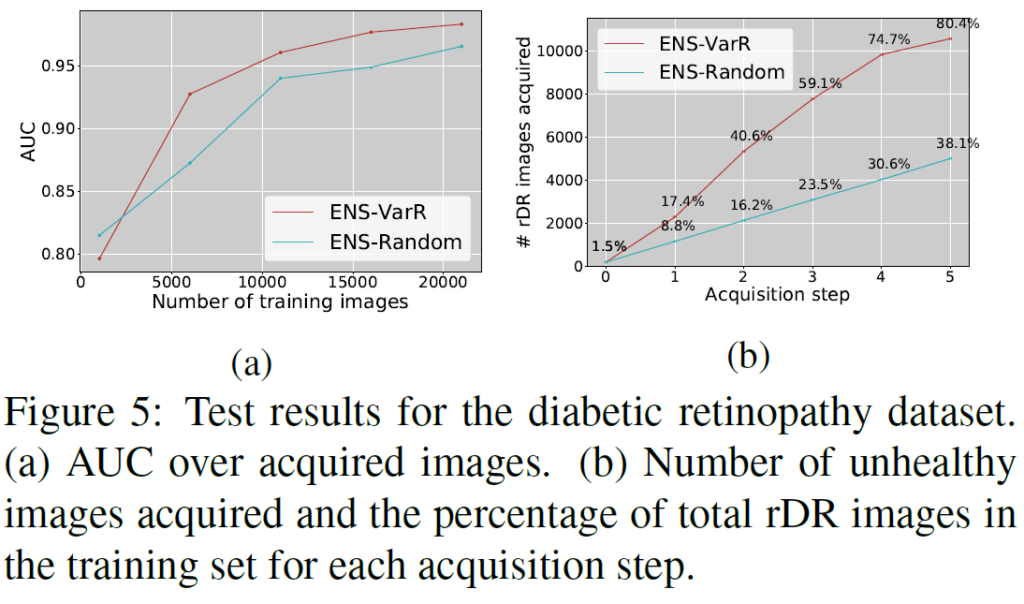
마지막으로는 ImageNet과 Diabetic retinopathy dataset에서 추가적인 실험을 수행했는데, 여기서는 방법론별로 비교 실험을 모두 수행하지는 않고 Ensenble-VarR와 Ensemble-Random의 성능을 비교합니다. Ensemble-Variation Ratio를 활용했을 때 두 데이터셋에서 모두 Active Learning 성능이 확연히 좋아지는것을 확인할 수 있습니다. diabetic retinopathy의 경우 class imbalance가 심한 binary classification인데, ENS-VarR을 적용하니 적은 class의 데이터가 많이 뽑히는것을 확인할 수 있습니다.
Conclusion
본 논문에서는 결국 다양한 실험을 통해 Active Learning을 진행할 때 Ensemble Network를 활용하면 성능이 향상되는 것을 보였습니다. 습득함수로 Variation Ratio를 사용하는 것이 좋은 성능을 보이며, 결국 방법론별 성능 비교를 진행했을 때 ENS-Variation Ratio 방법이 가장 높은 성능을 보였습니다. 분류 모델과 쿼리 모델을 분리하여 진행한 실험에서도 ENS-VarR을 통해 데이터를 선별하는 것이 좋았으며, model calibration을 측정하였을 때도 ENS-VarR이 가장 높은 성능을 보임을 알 수 있었습니다(특히 학습에 사용할 labeled data가 적을 때 그랬으며, 이는 overconfidence 문제에서 자유롭다는 것을 의미합니다).
논문이 나온 지 좀 됐지만 나쁘지 않은 성능을 보이는 방법론이었습니다. 하지만 앞에서 설명했다시피, 이 방법론은 학습 코스트가 꽤 크기 때문에 practical한 방법인지는 다시 한 번 고민해봐야 할 것 같습니다.
감사합니다.
안녕하세요. 허재연 연구원님.
좋은 리뷰 감사합니다.
간단한 질문이 있는데요. 논문에서 기존 sota인 MC-dropout과 비교를 수행하는데 그럼 해당 방법은 어떤 방법인지 간단히 소개해주실 수 있으실까요? 단순히 baseline 방법론이라기에는 비중이 좀 있는 것 같은데, 제가 배경지식이 없어 확 와닿지 않네요.
감사합니다!
리뷰 초반 Learning Loss 바로 위에 설명 드린 Bayesian 방법입니다. 학습 시킬 때 모든 convolution layer 뒤에 MC dropout을 붙여서 학습 시킨 다음, inference 할 때도 dropout을 끄지 않고 N번 feedforward를 진행합니다. 그리고 이 N개 prediction의 variance를 이용해 uncertainty를 측정하는 방법입니다.
안녕하세요 재연님 좋은 리뷰 감사합니다!
본문에서 BALD 방법론에 대해 설명해주신 부분에서 질문이 있습니다. predicted label과 network 가중치 간의 mutual information이 높다는 것은 어떤 의미로 해석할 수 있을까요?? mutual information이 높을 수록 Uncertainty가 높은 데이터라고 해석해야될까요? 데이터와 가중치 간의 관계를 고려하다보니 뭔가 오버피팅 되었다는 느낌으로 생각이 드는데 이렇게 생각하니 Uncertainty와 연관지을 수가 없어서 질문드립니다.
간단하게 요약하면 바로 위 (2)번 수식과 같이 entropy가 큰 걸 uncertainty가 높다고 보고 쿼리하는 것으로 생각하면 됩니다. 층마다 dropout을 붙여 모델이 stochastic하게 forward pass했을 때 input에서부터 softmax까지 high variance인 데이터가 다른 클래스에 할당될 가능성이 크다는 뜻입니다.
해당 방법론이 궁금하시다면 이전에 홍주영 연구원님께서 다룬 리뷰가 있으니 참고해보시면 좋을 것 같습니다 : http://server.rcv.sejong.ac.kr:8080/2023/05/14/icml-2017-deep-bayesian-active-learning-with-image-data/