안녕하세요, 열아홉 번째 X-Review입니다. 이번 논문은 2018년도 ICCV에 게재된 Pyramid Stereo Matching논문입니다. 그럼 바로 리뷰 시작하겠습니다 !
1. Introduction
Stereo Matching은 서로 다른 시점의 stereo image가 있을 때 기준 영상에서의 한 point에 대한 동일한 point를 타겟 영상에서 찾는 과정입니다. 즉, disparity를 계산하여 depth 정보를 구하는 것이라고 이해하면 될 것 같습니다.
disparity는 좌.우 영상에서 한 쌍의 대응되는 pixel 사이의 수평 변위를 의미하는데, 왼쪽 이미지의 (x, y) 위치의 픽셀이 오른쪽 이미지의 (x-d, y)와 대응된다면, 이 pixel의 depth는 fB/d로 계산할 수 있습니다. 여기서 d, f, B는 각각 disparity, focal length, baseline입니다.
일반적인 stereo matching 파이프라인은 아래와 같습니다.
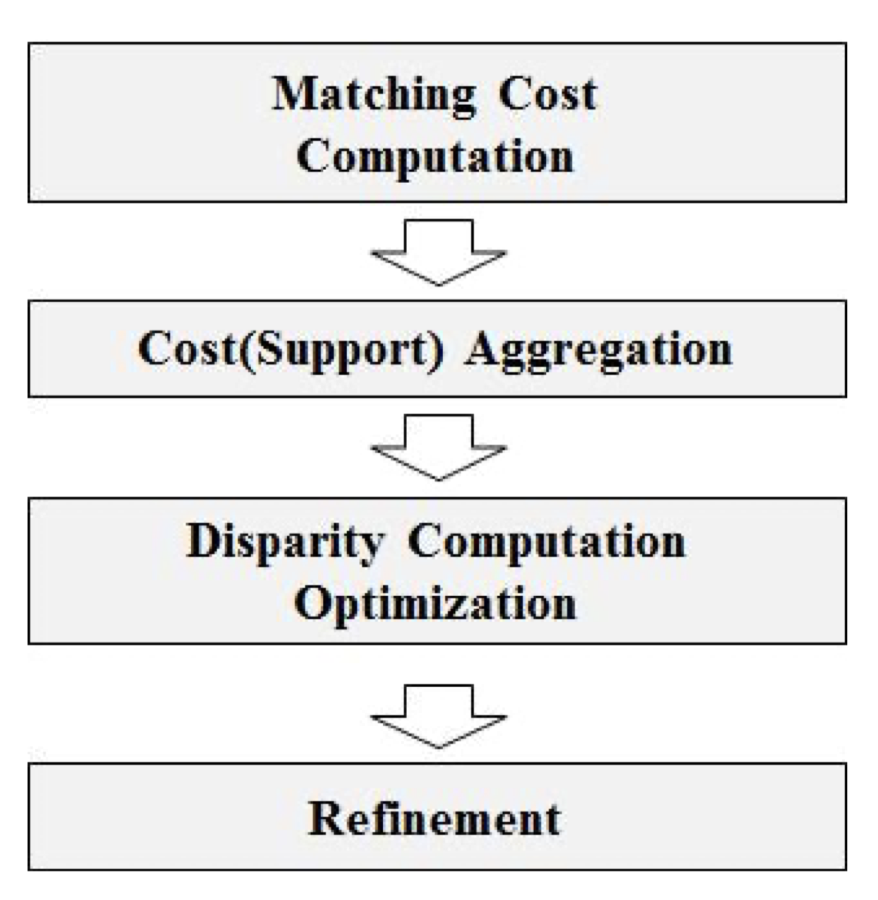
- Matching cost(매칭 비용) 계산
- Cost(비용) Aggregation
- Disparity Computation
- Refinement
순입니다.
가장 먼저 수행되는 매칭 비용 계산이란, 두 영상의 유사도를 pixel 단위로 측정하는 것을 의미합니다. 이 때 pixel 단위로 계산된 matching cost를 하나의 volume으로 쌓은 것을 cost volume이라고 하며, 두 번째 단계인 cost aggregation에서 cost volume의 정보를 aggregate해 계산된 cost 정보의 신뢰도를 높입니다.
cost aggregation 과정에서 신뢰도를 높인다는 것이 무슨말이냐 함은, cost volume 상에서는 실제로 서로 대응되는 픽셀들 사이에서 계산된 cost와 서로 대응되지 않은 pixel들 사이에서 계산된 cost의 차는 크지 않지만, cost aggregation 과정에서 주변에 대응된 pixel들의 cost를 합한 것과 대응되지 않은 pixel들의 cost를 합산한 것의 cost 차이는 커질 것이기 때문에 더 정확한 대응 pixel을 찾을 가능성이 높아지는 것을 의미합니다.
cost aggregation 과정 이후에는 aggregation된 cost volume에서 disparity를 계산하게 됩니다. 이 때 추정된 disparity는 카메라 초점 거리와 두 카메라 사이 거리인 baseline 정보를 통해 depth를 추정할 수 있게 되는 것입니다.
기존에는 hand-crafted feature 기반으로 stereo matching을 수행해왔지만, CNN이 등장하며 stereo matching 분야에도 접목되기 시작하였습니다. MC-CNN이 CNN을 스테레오 매칭에 활용한 첫 모델입니다. CNN은 기존 전통적인 스테레오 매칭 기법보다 정확도도 높고, 속도도 빨랐지만 occlusion이 존재하는 영역이나,반복되는 패턴이 있는 영역, texture가 없는 영역, 반사 표면과 같이 본질적으로 ill-posed(불완전한) 영역에서는 정확한 대응점을 찾기 힘들었습니다. 저자들은 이런 문제점이 존재하므로 찾고자 하는 지점에 global한 context 정보를 통합해 사용해야 한다고 주장합니다.
본 논문에서는 스테레오 매칭에서 global context 정보를 활용하기 위한 새로운 pyramid stereo matching Network(PSMNet)을 제안합니다. PSMNet은 spatial pyramid pooling(SPP)와 dilated convolution을 receptive field를 키우는데 사용합니다. SPP와 dilated convolution을 통해 PSMNet은 pixel level의 feature를 region-level의 feature로 확장할 수 있게 되었으며, 결과적으로 global feature와 local feature들을 결합하여 cost volume을 생성하는데 사용할 수 있는 것이죠.
또한, 저자들은 cost volume을 regularize하기 위한 stacked hourglass 3D CNN을 고안하였습니다. 이 stacted hourglass 3D CNN은 탑다운/바텀업 방식으로 cost volume을 반복적으로 처리해 global context 정보를 더 잘 활용할 수 있도록 하였습니다.
본 논문의 주요 contribution은 다음과 같습니다.
- 후처리가 필요없는 스테레오 매칭을 위한 end-to-end 학습 프레임워크 제안
- 이미지 feature에 global context 정보를 통합하기 위한 pyramid pooling module 제안
- cost volume의 context 정보를 확장하는 stacted hourglass 3D CNN 제안
- KITTI 데이터셋에서 SOTA
3. Pyramid Stereo Matching Network
global context를 효과적으로 통합하는 모듈인 SPP 모듈과 cost volume regularization을 위한 stacked hourglass 모듈에 대해 자세히 알아보도록 하겠습니다.
3.1. Network Architecture
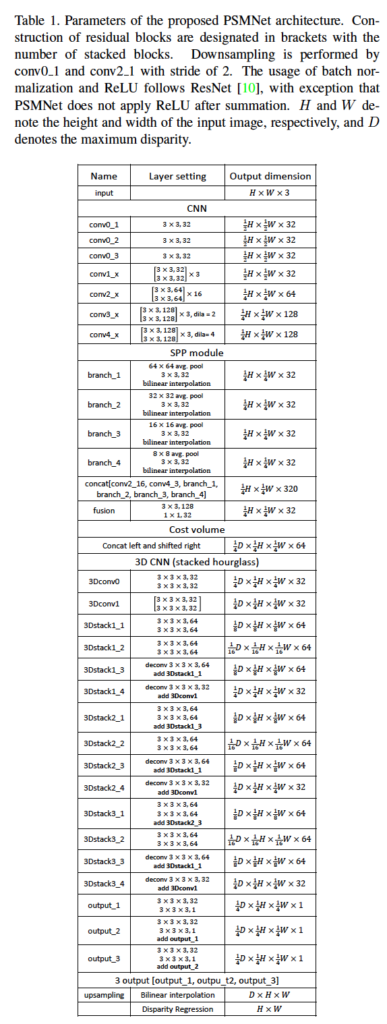
PSMNet의 파라미터는 위 표 1에서 자세히 확인해볼 수 있습니다. ResNet에서 첫 번째 컨볼루션 레이어에 7×7 사이즈의 큰 필터를 적용한 것과 달리, 세 개의 3×3 사이즈의 필터를 통해 더 깊은 네트워크를 구성하였습니다. 또한 conv3_x, conv4_x의 경우 dilated 컨볼루션을 사용하여 receptive field를 확대하였습니다. CNN을 통과하고 나온 feature map의 경우 원본 영상의 1/4이며, 이는 바로 SPP 모듈의 입력으로 들어가 영상의 context 정보를 얻습니다. 이후 SPP 모듈을 타고 나온 좌 우 두 feature map에서 cost volume을 통합하고 3D CNN을 통과하게 됩니다. cost volume은 앞에서 말한 것처럼 픽셀 단위로 계산된 matching cost를 하나의 volume으로 쌓은 것을 의미합니다. 3D CNN을 통과하고 나오면 regression을 통해 최종적으로 disparity map을 계산해내게 됩니다.
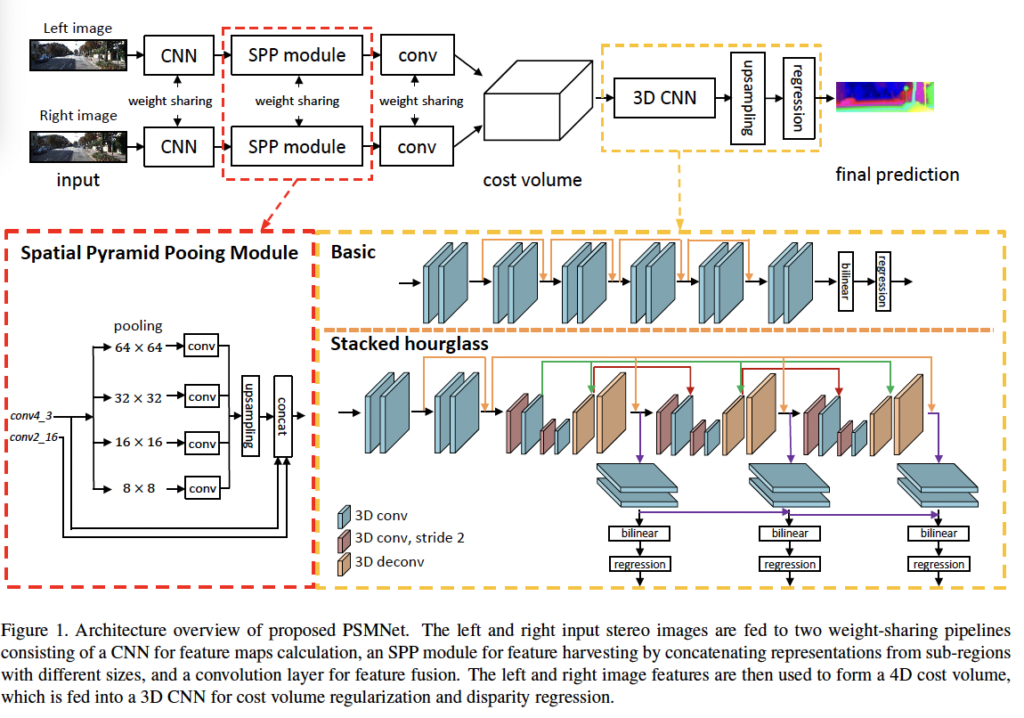
방금 설명한 PSMNet의 아키텍처는 위 fig 1에서 확인할 수 있습니다. SPP 모듈, cost volume, 3D CNN, disparity regression에 대해서는 아래에서 자세히 살펴보도록 하겠습니다.
3.2. Spatial Pyramid Pooling Module
먼저 Spatial Pyramid Polling Module, 이하 SPP 모듈입니다. 영상 내의 pixel intensity 만으로는 context관계를 판단하기 어렵습니다. 그렇기에 객체의 context 정보가 풍부한 feature는 occlusion이 존재하는 영역이나,반복되는 패턴이 있는 영역, texture가 없는 영역 등과 같은 ill-posed(불완전한) 영역에서의 추정에 도움이 됩니다. 본 연구에서는 객체와 그 객체의 하위 영역 사이의 관계를 SPP 모듈을 통해 학습함으로써 계층적 context 정보를 통합하고자 하였습니다. 구체적으로 객체가 자동차라면 자동차의 하위 영역인 창문이나, 타이어 등과 자동차 사이의 관계를 학습하도록 하는 것입니다.
Fig 1에서 확인할 수 있듯이 저자들은 네 개의 고정된 크기의 average pooling 블록으로 SPP 모듈을 구성하였습니다. 이후 1×1 컨볼루션을 거쳐 feature map들의 차원 수를 줄이고 upsampling한 후 최종적으로 concat하여 최종 SPP feature map이 생성됩니다.
3.3. Cost Volume
이전 연구인 MC-CNN 방법론과 GCNet 방법론들이 cost volume을 구축하는 접근 방식은 dnn을 통해 matching cost 추정을 학습하기 위해 단순히 왼쪽과 오른쪽의 feature를 concat하는 것이었습니다. 이를 따라 본 논문에서는 SPP를 통과하고 나온 좌, 우 feature map을 각 disparity level 별로 concat함으로써 cost volume을 형성하였습니다. 결과적으로 height x width x disparity x feature size 모양의 4D cost volume이 생성됩니다.
3.4. 3D CNN
앞서 SPP 모듈은 다양한 크기의 feature map을 통해 계층적 context 정보를 얻어내는 모듈이라고 하였습니다. 이 모듈을 통해 다양한 레벨의 feature를 포함하게 되면서 스테레오 매칭을 용이하게 하죠. 이를 통과해 나온 feature map으로 cost volume을 생성하였으면, 이후의 단계는 cost aggregation입니다. 저자는 공간적 차원뿐만 아니라 disparity 차원에 따른 feature 정보를 aggregate하기 위해 cost volume 정규화를 위한 두 종류의 3D CNN 구조를 제안하였습니다. Fig 1에서 노란색 점선 박스가 이에 해당하는데, 위 부분이 Basic 구조이고 아래가 stacked hourglass 구조입니다. Basic 구조는 그림에서 볼 수 있듯이 residual block을 사용하였으며, 12개의 3x3x3 컨볼루션이 포함되어 있습니다. 이후 선형보간을 통해 cost volume을 HxWxD 크기로 업샘플링한 후, regression을 통해 HxW 크기의 disparity map을 계산해 냅니다.
또한 더 많은 context 정보를 학습하기 위해 basic 구조 뿐만 아니라 반복적으로 하향, 상향 구조를 반복하는 stacked hourglass(모래시계) 구조의 3D CNN 구조도 제안하였습니다. stacked hourglass 아키텍처는 세 개의 주요 모래시계(인코더-디코더) 네트워크가 있으며, 각 네트워크마다 disparity map을 생성해냅니다. 그럼 총 3개의 disparity map이 생성되겠으며, loss도 3입니다. 학습 중 total loss는 세 loss의 가중합으로 계산되며, 평가 단계에서 최종 disparity map은 세 disparity map중 마지막 map입니다.
3.5. Disparity Regression
저자들은 disparity map을 추정하기 위해 disparity를 regression 하였습니다. 각 disparity d의 확률은 소프트맥스 연산을 취하고 나온 cost c_d로부터 계산됩니다. 계산된 disparity \hat{d}는 확률에 따른 가중치를 부여한 각 disparity d의 합으로 아래 식 1과 같습니다.
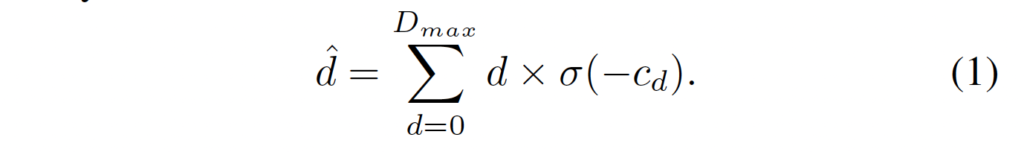
3.6. Loss
disparity regression으로 인해 저자는 PSMNet을 학습하기 위한 loss로 smooth_{L1} loss를 사용하였습니다.
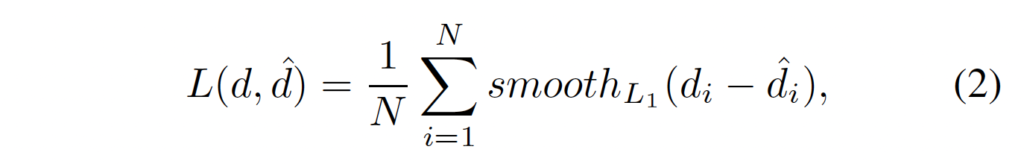
- N : 라벨이 있는 픽셀 수
- d : GT disparity
- \hat{d} : 예측한 disparity
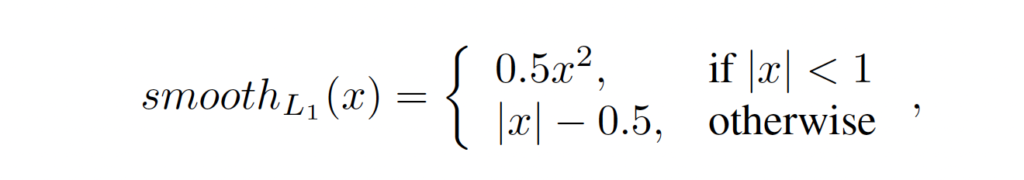
4. Experiments
4.1. Experiment Details
실험은 SceneFlow, KITTI 2012, KITTI 2015 3개의 스테레오 데이터셋에서 수행하였습니다.
- SceneFlow
SceneFlow는 35,454개의 학습 이미지와 4,370개의 평가 이미지로 구성된 합성 데이터셋입니다.
- KITTI 2015
KITTI 2015는 주행중인 자동차 거리 view가 포함된 실제 데이터셋으로, LiDar를 사용하여 얻은 sparse한 gt disparity가 포함된 200개의 학습용 스테레오 이미지쌍과 gt disparity가 없는 200개의 평가 이미지 쌍으로 구성됩니다.
- KITTI 2012KITTI 2012는 마찬가지로 주행 중인 자동차의 거리 view가 포함된 실제 데이터셋으로 194개의 학습용 스테레오 이미지쌍과 195개의 평가 이미지로 구성됩니다.
KITTI 의 학습데이터셋 양이 많지 않다보니 SceneFlow 데이터셋에서 사전학습 후 KITTI에서 Fine-tuning하였습니다.
4.2. KITTI 2015
Ablation Study for PSMNet
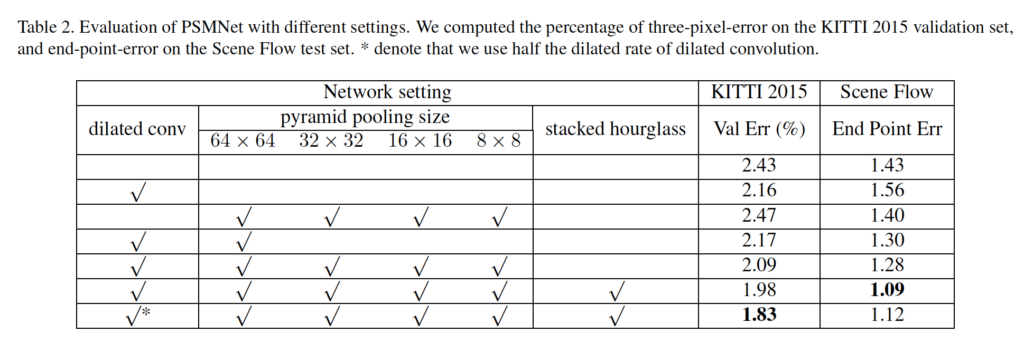
위 표는 dilated conv, pyramid pooling size, stacked hourglass에 대한 ablation study 결과입니다.
평가지표로는 val Err(%)와 End Point Err를 사용하였는데, val error는 validation set에서의 MAE를 의미합니다. 즉, gt disparity와 예측한 disparity의 차이를 절대값으로 계산하여 얻어지는 성능이며 낮을수록 모델의 성능은 우수하다고 말할 수 있습니다. 또, EPE(End-point-error)같은 경우는 예측한 disparity와 gt disparity간의 픽셀 단위로 측정한 오차라고 보면 되겠습니다. val error와 마찬가지로 낮을수록 좋은 성능이겠죠.
ablation study 결과를 보면, dilated convolution은 단독으로 사용했을 때는 Scene Flow에서 오히려 성능 하락이 발생한 것을 확인할 수 있습니다. 저자는 이에 대해 dilated conv는 SPP 모듈과 함께 사용했을 때 더 잘 동작한다고 말합니다. 실제로 stacked hourglass까지 모두 사용한 결과를 보면 에러율이 꽤 떨어진 것을 확인할 수 있습니다.
Ablation study for Loss Weight
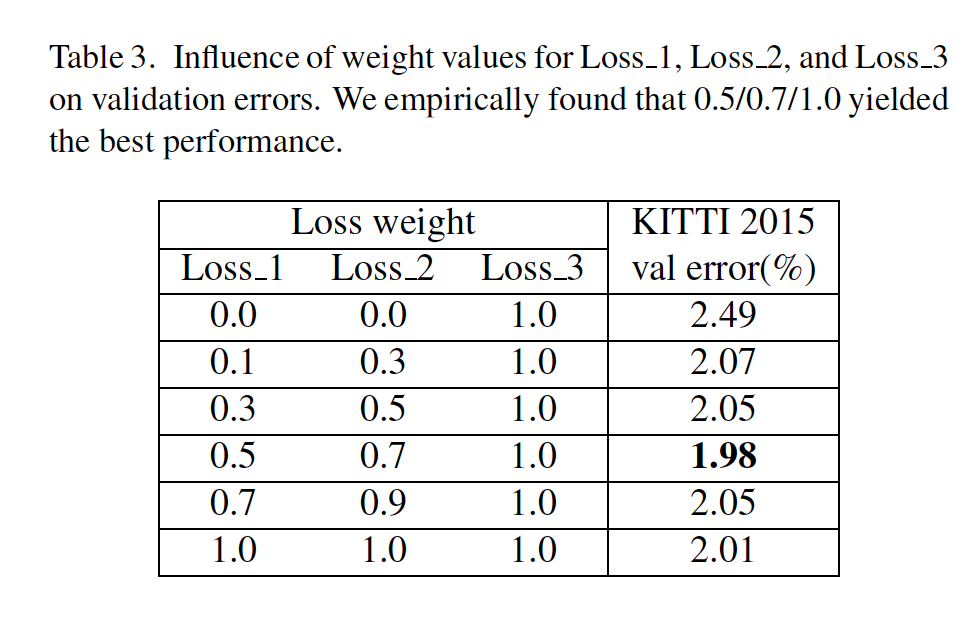
다음은 loss weight에 대한 ablation study인데, 가중치를 0.5, 0.7, 1.0으로 주었을 때 가장 좋은 성능을 보였습니다.
Results on Leaderboard
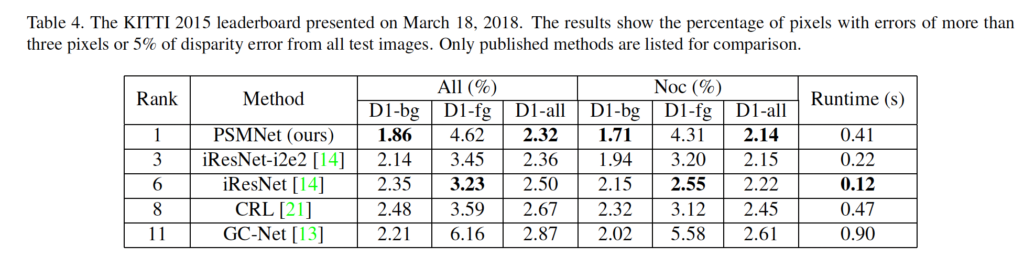
타 방법론과의 성능 비교 결과입니다. 평가 지표는 3 pixel error를 사용하는데, 이는 예측한 disparity와 gt disparity의 차이가 3픽셀 미만인 픽셀의 비율을 나타냅니다. 오차율이 낮을수록 우수한 성능을 보인다고 해석하면 되겠습니다.
결과는 크게 All과 Noc으로 나눌 수 있는데, All은 오차를 추정할 때 모든 픽셀을 고려하였음을 의미하며 Noc은 non-occluded 영역의 픽셀만 고려하였음을 의미합니다. 이들 아래의 D1-bg, D1-fg, D1-all은 각각 오차 추정에서 배경, 전경, 모든 영역의 픽셀을 고려한 것입니다. PSMNet은 fg에서 타 방법론과 비교했을 때 꽤나 낮은 성능을 보입니다. 반면 bg일 때는 가장 우수한 성능을 보이네요. 종합적으로 배경 영역이 전경 영역보다 훨씬 많다보니 가장 적은 3픽셀 오차율을 달성한 것으로 보입니다.
Qualitative evaluation

위 Fig2는 PSMNet과 GC-Net, MC-CNN에 의해 추정된 disparity map과 그에 따른 error map을 보여주는 그림입니다. 그림에서 노란색 화살표로 표시된 부분이 저자가 말하는 ill-posed 영역(정확한 disparity를 추정하기 어려운 영역)인데요, GC-Net, MC-CNN보다 PSMNet이 해당 영역에서 disparity를 더 정확하게 예측하는 것을 정성적으로 확인할 수 있습니다.
4.3. Scene Flow
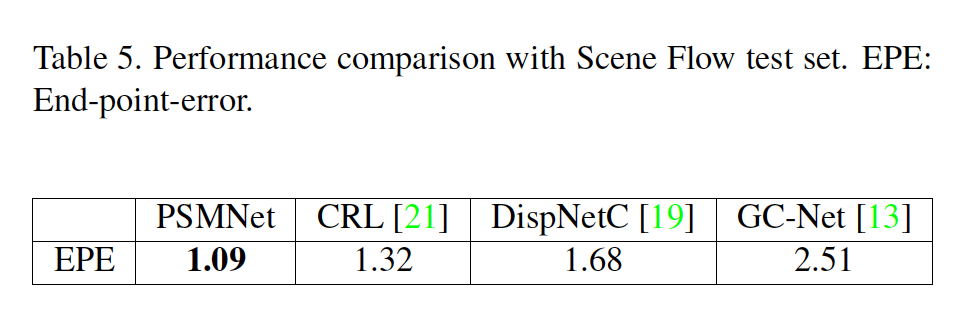
Scene Flow에서의 테스트 결과인데, PSMNet의 EPE가 1.09로 가장 낮은 낮네요.

위 Fig3은 Scene Flow에서의 정성적 결과입니다.
안녕하세요. 좋은 리뷰 감사합니다.
ablation study에서 마지막 행의 *는 무엇을 의미하는 것인가요 ?
또, KITTI 2015 성능 리포팅에서 foreground에 대한 성능이 타 방법론과 비교했을 때 유독 많이 낮은 이유에 대한 고찰이 있는지 궁금합니다. 이는 feature에 global context 정보를 통합하기 위해 사용한 pooling 모듈이 영향 때문인건가요 ?
마지막으로 리뷰에는 loss로 gt와 예측한 disparity간의 smooth l1 loss를 사용했다고 하셨는데, 이외의 다른 loss는 사용하지 않는 것인지 궁금합니다.
감사합니다 !
안녕하세요 . 댓글 감사합니다 !!
1. *는 dilated convolution의 dilated rate를 절반으로 줄인 모델입니다.
2. SPP와 dilated convolution을 사용하여 큰 receptive field를 사용하다보니 local context보다는 global context만을 고려하게 되어 foreground에 대한 성능이 좀 떨어지지 않나 생각해봅니다. .
3. 오직 smooth l1 loss만을 사용합니다.