transformer는 global relation을 잘 파악한다는 장점으로 인해 여러 분야에서 좋은 성능을 달성하였습니다. 여기까지는 우리가 익히 알고 있는 것과 같죠. 이렇듯 transformer가 좋은 성능을 달성하여 논문의 저자들은 transformer의 complementary knowledge를 기존 CNN 모델에 전이하여 CNN의 성능을 더 끌어올리고자 하였습니다.
그러나 기존 kd방법론을 직접적으로 transformer-cnn 구조에 적용할 수 없었다고 합니다. 이전까지는 homologous-architecture, 즉 cnn-cnn, transformer-transformer와 같이 동일 구조를 base로 하는 모델간의 knowledge distillation이 진행되었습니다. 따라서 대부분의 연구가 중간 레이어 혹은 output feature를 직접적으로 비교하여 teacher의 특징값을 모사하도록 학습되었는데요, 해당 방법론들은 cross-architecrture 시나리오에는 적합하지 않았다고 합니다.
이러한 문제를 해결하기 위해 저자들은 cross-architecture knowledge distillation method를 제안하였습니다. 각 레이어의 feature를 비교할 때 바로 비교하지 않고 partially cross attention projector와 group-wise linear projector를 사용하여 두 feature를 동일 공간에 투영하여 비교하였습니다.
Introduction
Knowledge distillation은 널리 사용되는 모델 경량화 기법 중 하나로, 일반적으로 large teacher 모델의 knowledge를 small student로 distill하는 teacher-student framework를 사용합니다. 여기서 teacher 모델은 어떤 task의 sota 모델이며, student는 edge환경 등에서 사용하기 위해 가볍게 설계된 모델을 사용하여 결론적으로 teacher의 성능을 student에서 내도록 학습합니다. 이때 knowledge는 보통 teacher의 softmax output이나 중간 레이어의 feature들을 의미합니다.
초창기 KD 방법론들은 CNN architecture에 초점을 맞추고 있었습니다. 또한 CUDA, TensorRT, NCNN등의 가속 라이브러리를 통해 edge 환경과 서버 환경에서 cnn 모델들은 하드웨어 친화적이하는 장점이 있어 여러 CNN 경량 모델들이 등장하였다고 합니다.
최근에는 Transformer가 널리 사용됨에 따라 여러 task의 sota들이 transformer 기반의 모델을 사용하게 되었는데요, Transformer는 많은 연산량과 제한된 가속 지원으로 특히 edge device에서의 활용이 제한적이었다고 합니다. 이에 따라, edge에서의 활용을 위해 Transformer 모델을 CNN 모델로 distill하고자 하였습니다.
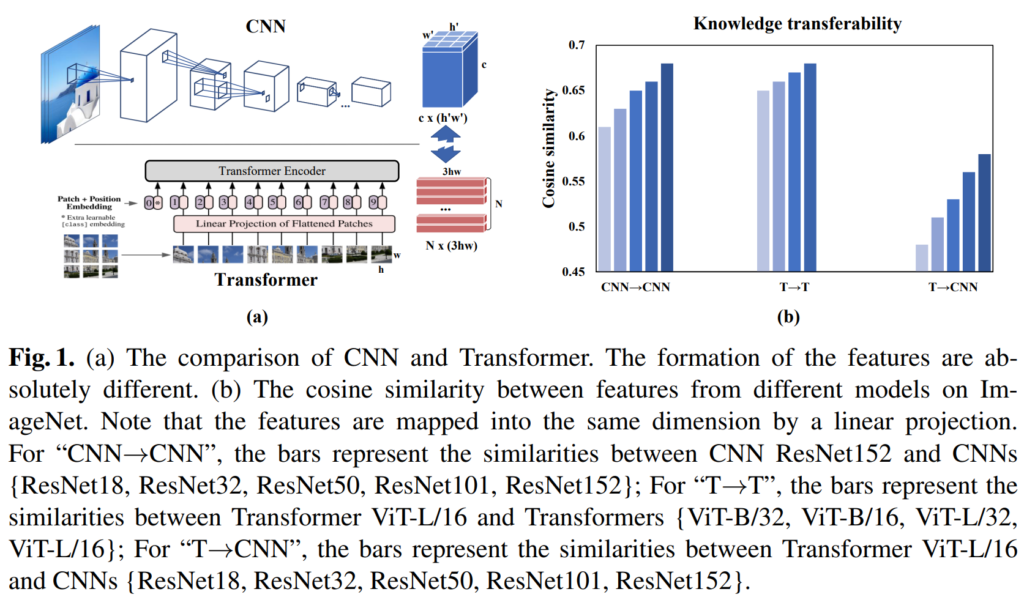
그러나, 기존 방법론들은 homologous-architecture KD, 즉 CNN → CNN 및 Transformer → Transformer에 집중하고 있으며, 이는 cross-architecture 시나리오에 적합하지 않았다고 합니다. Figure 1-(b)는 knowledge의 transferablilty를 나타내며, KD시 student와 teacher의 output feature 간의 코사인 유사도를 측정한 결과입니다. homologous-architecture인 경우에는 transferablilty가 0.6 – 0.7 사이이지만, cross-architecture 조건에서는 그보다 훨씬 낮은 것을 확인할 수 있습니다. 이를 통해 서로 다른 architecture간의 KD는 어려우며, 저자들은 이를 해결하기 위한 새로운 framework의 필요성을 주장하였습니다.
따라서 이 논문에서는 Transformer와 CNN 사이의 격차를 해소하기 위한 새로운 cross-architecture knowledge distillation 방법을 제안하였습니다. 특히 teacher가 transformer, student가 cnn인 상황에서 student가 teacher의 global 특징을 보다 잘 학습하도록 하는 데 중점을 두었습니다. 저자들은 partial cross attention (PCA) projector와 group-wise linear (GL) projector를 제안하여 서로 다른 두 architecture의 feature를 동일 space에서 mapping하도록 하였습니다. PCA는 student의 feature를 teacher의 transformer attention space에 mapping하여 student가 global relation을 학습할 수 있도록 하였고, GL은 student의 feature를 transformer의 feature space에 mapping하여 두 feature간의 formation을 직접적으로 완화하였다고 합니다. 추가적으로, cross-architecture framework의 불안정성을 완화하기 위해, cross-view robust training scheme을 제안하였습니다.
논문의 마지막에는 다양한 teachet-student를 활용한 실험 결과를 보였습니다. 실험에는 ImageNet-1k와 CIFAR-100사용한 classification을 진행하였습니다.
저자들이 밝힌 논문의 contribution을 말씀드리며 method로 넘어가겠습니다.
- We propose a cross-architecture knowledge distillation framework to distill excellent Transformer knowledge to guide CNN. In this framework, partially cross attention (PCA) projector and group-wise linear (GL) projector are designed to align the student feature space and promote the transferability between teacher features and student features.
- We propose a multi-view robust training scheme to improve the stability and robustness of the student network.
- Experimental results show that the proposed method is effective and outperforms 14 state-of-the-arts on both large-scale datasets and small-scale datasets.
Method
논문에서 제안하는 framework는 아래의 [그림 2]와 같습니다.
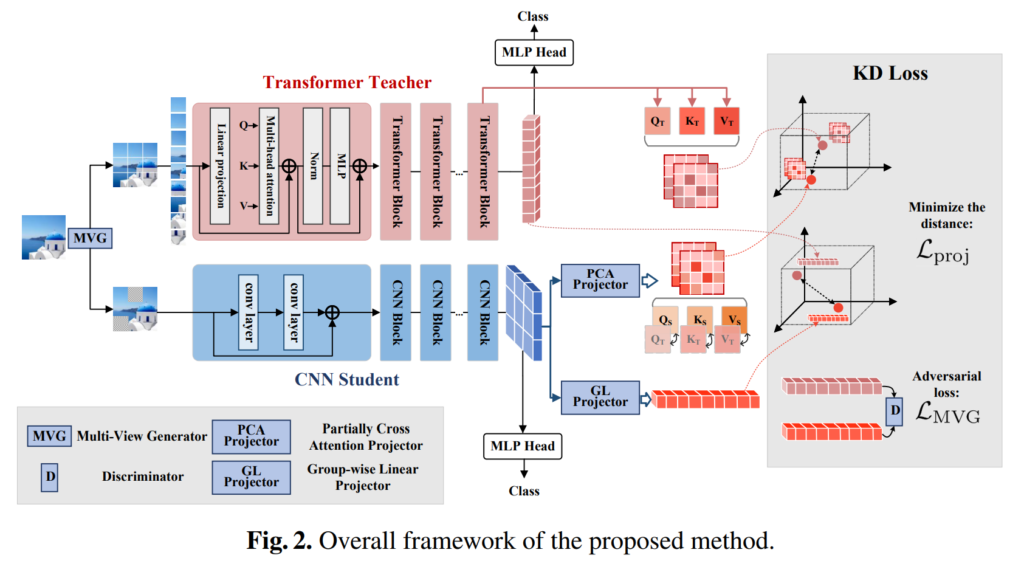
위 그림에서 상단의 Transformer는 Teacher, 아래의 CNN은 Student 모델입니다. Transformer Teacher {\Theta}^T 의 경우, 입력 샘플 x \in {\R}^{3 \times H \times W} 는 N 개의 patch \{{x_n \in \R^{3 \times H \times W} } \}^N_{n=1} 로 쪼개집니다. 이후 여러 transformer block을 통과한 후 transformer feature h_T \in \R^{3 \times H \times W}가 생성되며, 최종 예측값은 그림 2에서 보이는 것처럼 MLP Head를 통해 계산됩니다. CNN Student {/Theta}^S 의 경우, 전체 이미지를 통으로 입력받아 여러 CNN block을 거친 후, 최종적인 student feature h_S \in \R ^{c \times (h'w')}를 얻을 수 있습니다. 여기서 c는 채널 수이며, h′w′= {{HW}\over {2^{2s}}}입니다.
이미지에서 특징을 추출할 때 transformer와 CNN이 서로 다르게 동작하는 것을 확인할 수 있습니다. 이러한 Transformer와 CNN의 구조적 차이로 인해, 기존의 KD 방법을 사용하여 student feature가 teacher feature를 직접 모방하게 하는 것은 어렵습니다. 이 문제를 해결하기 위해, 저자들은 부분적인 cross attention (PCA) 프로젝터와 group-wise linear (GL) 프로젝터로 구성된 cross-architecture 프로젝터를 제안하였습니다.
Cross-architecture projector
Partially cross attention projector
PCA projector는 student feature를 transformer의 attention space에 mapping합니다. CNN feature space를 attention space에 mapping함으로써, 즉, student attention map과 teacher attention map 사이의 거리를 최소화함으로써 student 모델이 transformer의 global relation을 보다 원활이 학습할 수 있도록 하였다고 합니다.
PCA projector는 student의 CNN feature를 Query, Key, Value 행렬로 매핑한 다음 attention 메커니즘을 모방하도록 설계하였습니다. 보다 자세히 설명드리자면 3*3 conv 3개를 이용하여 Q, K, V를 각각 생성한 뒤 attention 연산을 적용하여 transformer output과 동일한 형태의 att map을 생성한 것입니다. 수식으로는 아래의 [ 수식 1 ], [ 수식2 ]와 같이 표현하였습니다.
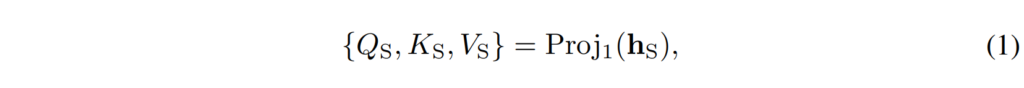
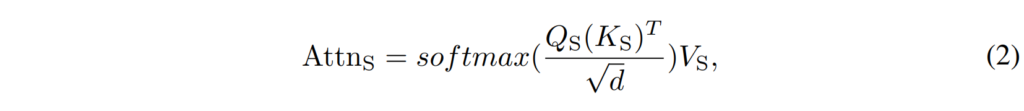
[ 수식2 ]에서 Attn_S 는 student의 feature map으로 생성된 attention map입니다. Attn_T 가 teacher의 transformer layer output이면, 두 Attn_T 와 Attn_S 를 직접적으로 비교하여 둘 사이의 거리를 최소화하는 방향으로 student를 학습할 수 있겠죠. 여기에 저자들은 student의 robustness를 향상시키기 위해, 원래의 Attn_S 대신 [ 수식 3 ]과 같이 PCAttn_S 를 사용하였습니다.
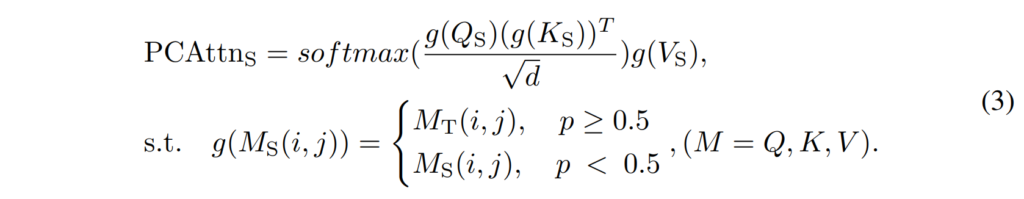
여기서 (i, j) 는 input matrix M의 index를 나타내는데요, 전체적인 수식을 살펴보자면 g(⋅)는 균일 분포에 따라 확률 p로 student의 Q_S, K_S, V_S matrix를 teacher의 해당 matrix로 대체합니다.
최종적인 PCA projection loss는 [수식 4]와 같이 구성되어 student가 attention space에서 teacher를 모방하도록 하였습니다.
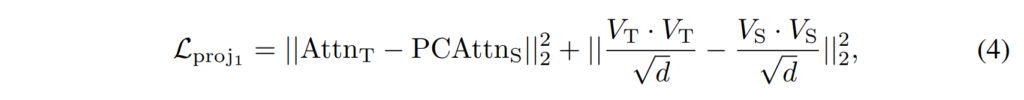
Group-wise linear projector
GL projector는 student의 feature h_S 을 Transformer의 feature space로 mapping합니다. 이때 여러 개의 fc 레이어를 통해 진행하며 mapping 된 feature는 [ 수식 5 ]와 같이 나타낼 수 있습니다.

224×224 크기의 일반적인 이미지 입력의 경우, h_S \R^{256 \times 196} 차원을 가지며, 매핑된 특징 h^’_S 는 \R^{196 \times 768} 차원이 됩니다. 이를 통해 각 픽셀이 원래 feature space에서 Transformer의 feature space로 mapping됩니다.
그러나 이러한 크기의 벡터간의 픽셀별 매핑을 위해서는 최소 196개의 FC 레이어가 필요하며, 이는 상당한 계산량을 요구합니다. 저자들은 이러한 높은 계산량을 줄이기 위해 4×4영역이 하나의 FC 레이어를 공유하는 group-wise 방법을 사용하여 FC 레이어의 수를 16개로 줄였습니다.
최종적으로는[ 수식 6 ]과 같이 GL projector를 통해 매핑된 student 네트워크의 특징 h^’_S 과 Transformer 네트워크의 feature h_T 사이의 거리를 최소화하도록 합니다. 이를 통해 student 네트워크가 Transformer의 특징을 보다 효과적으로 학습할 수 있도록 하였습니다.
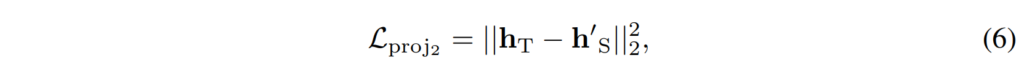
Cross-view robust training
teacher와 student의 구조적 차이로 인해, student가 robustness를 학습하는 것이 어려웠다고 하는데요, 이에 논문의 저자들은 student의 stability를 향상시키기 위한 cross-view robust training scheme을 제안하였습니다.
Cross-view robust training는 multi-view generator(MVG)와 이에 대응되는 multi-view adversarial discriminator로 구성되어 있는데요, 이 중 MVG는 [수식 7]과 같이 원본 이미지에 일정 확률로 다양한 transform을 적용합니다.
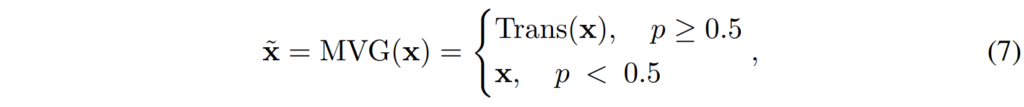
이렇게 변형된 이미지는 student에 입력됩니다. 그 후, teacher 네트워크의 feature h_T 와 변형된 이미지에서 추출한 student의 feature h'_S 를 구별하기 위해 multi-view adversarial discriminator가 구축됩니다. cross-view robust training은 discriminator를 혼동시켜 robust한 student feature를 얻는 것을 목적으로 하며, discriminator의 loss는 [수식 8]과 같이 계산됩니다
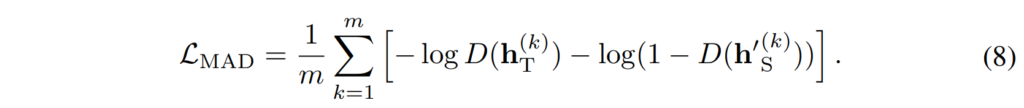
여기서 D( ⋅ ) 는 multi-view adversarial discriminator를 나타냅니다. adversarial training의 generator인 student 네트워크의 경우, [수식 9]와 같은 loss를 추가적으로 적용하게 됩니다.
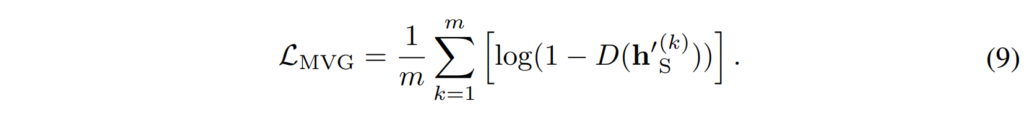
최종적인 학습을 위한 Loss는 [수식 10]과 같이 정의되었습니다.
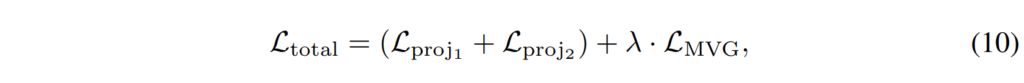
Experiments
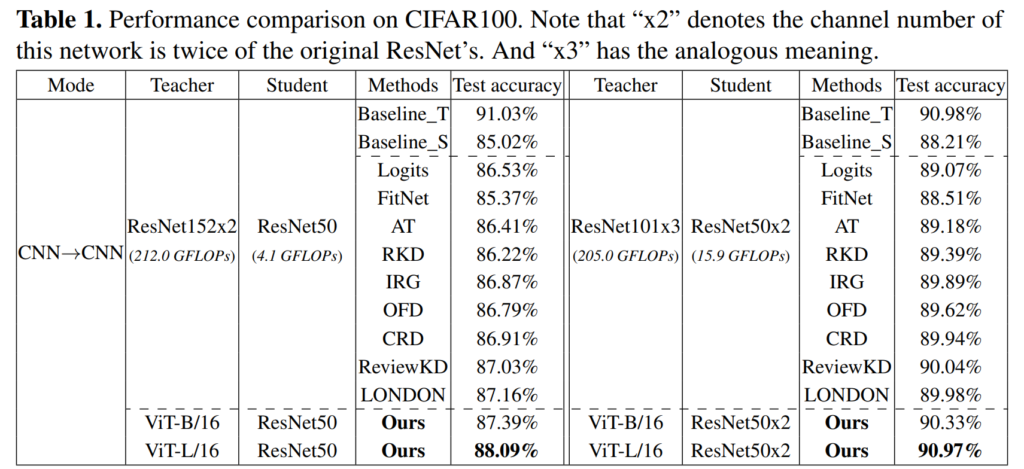
본격적인 실험에 들어가기 앞서 실험에 사용된 데이터셋과 backbone 네트워크를 먼저 설명드리겠습니다. 데이터셋은 Cifar-100과 ImageNet1k를 사용하였습니다.
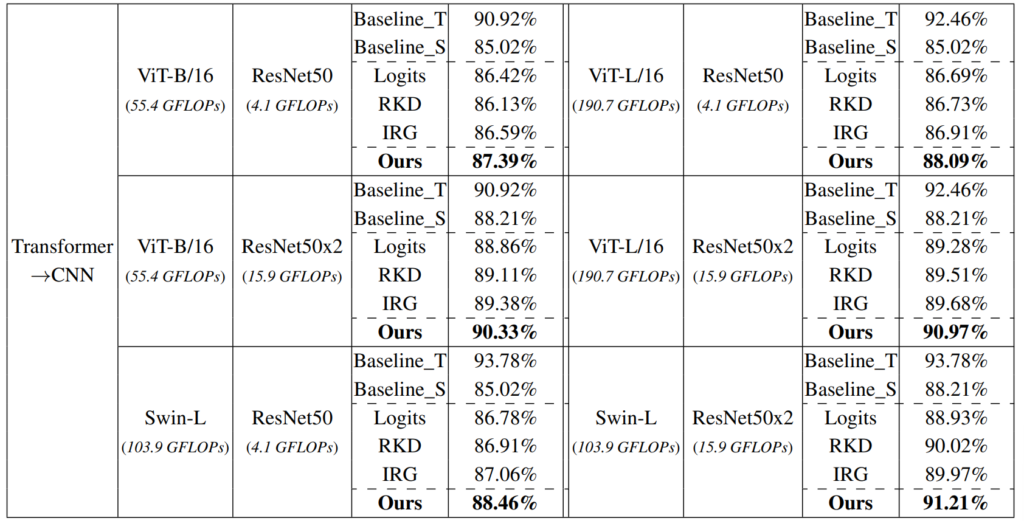
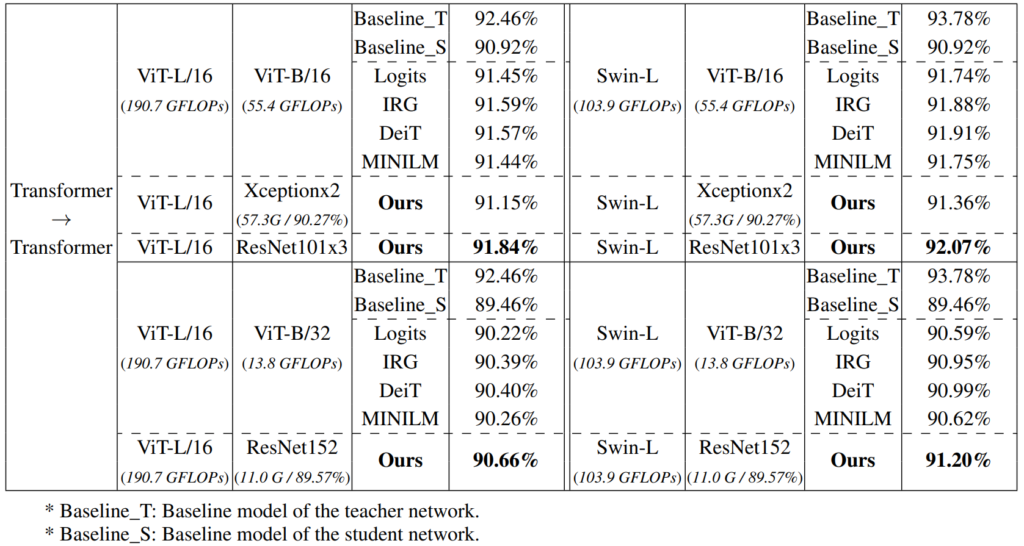
위 방법론이 KD이다보니 teacher와 student를 어떤 구조로 두는지가 중요하며, 논문에서는 teacher와 student의 구조에 따라 CNN-CNN, Transformer-CNN, Transformer-Transformer의 세 가지로 나눠 분석하였습니다.
안녕하세요 혜원님 좋은 리뷰 감사합니다.
본 논문에서 서로 다른 architecture에서의 KD 방법론을 적용시키는게 상당히 흥미로웠습니다. teacher output/intermediate features을 직접 모방하는 대신, ‘cross attention projector’ 와 ‘group-wise linear projector’ 같은 방법이 소개되었는데 몇 가지 질문이 있습니다.
1. 본문 “i,j)는 input matrix M의 index를 나타내는데요, 전체적인 수식을 살펴보자면 g(⋅)는 균일 분포에 따라 확률 p로 student의 matrix를 teacher의 해당 matrix로 대체합니다.”의 부분에서 g는 어떤 조건 없이 랜덤하게 50%의 확률로 선택되는 것이고 이러한 방법을 적용시키는 이유는 모델의 robustness을 위함이 맞는 것이죠??
2. Cross-view robust training에서 generator와 discriminator까지 적용시켜 학습시키는게 무척 흥미로운 것 같습니다. 그런데 본문에서 최종 학습 Loss(수식 10)를 보면 generator Loss만 포함되어있고 discriminator loss는 빠져있는데 discriminator는 어떻게 학습시키는 건가요??
감사합니다.