제가 이번에 리뷰 할 논문은 RGB와 Depth에 동일한 backbone을 적용하는 Uni6D 논문의 후속 논문입니다. 이번에 6D 데이터 셋을 촬영할 때 스팀을 분사하여 노이즈를 추가할 경우 depth 이미지에서 상당한 노이즈가 생기는 것을 확인하였습니다. 해당 논문은 Instance-Inside/Outsied라는 두가지 노이즈를 구분하여 이를 해결하여 안정적인 학습이 가능하도록 제안된 논문으로, 그 중 Instance-Inside 노이즈를 depth 입력 데이터의 노이즈로 정의하고 있다는 점에서 활용이 가능할 것이라고 생각하여 리뷰하게 되었습니다.
Abstact
Uni6D는 6D pose estimation 방법론에서 RGB/Depth 이미지에 대하여 동일한 backbone을 적용하는 최초의 논문입니다. 저자들은 Uni6D의 성능 한계의 원인으로 Instance-Outside/Inside 노이즈라는 2가지를 원인으로 지적합니다. 저자들은 receptive field의 배경 영역에서 노이즈를 추가하고(Instance-Outside), depth 입력에 존재하는 노이즈를 무시하도록(Instance-Inside) 설계하였습니다. 본 논문에서는 객체 영역을 인식하는 1단계와 노이즈를 제거하는 2단계, 2-stage 방식으로 노이즈를 제거하며 6D Pose Estimation을 수행합니다. 이때 추론 효율성을 너무 헤치지 않으면서도 강인하게 노이즈를 제거할 수 있도록 네트워크를 구성하였다고 합니다.
Introduction
6D Pose Estimation은 로봇 조작 및 grasping, 자율 주행, 증강현실 등과 같은 활용을 위해 중요한 task입니다. 6D Pose란 방향과 위치 정보를 포함하며, RGB-D 센서가 저렴해지고 사용 가능해짐에 따라 RGB 정보 뿐만 아니라 직접적인 기하학적 정보를 제공할 수 있어 더욱 매력적인 데이터를 만들 수 있는 잠재력을 갖게 되었습니다. 그러나, 데이터 수집 과정에 물리적 노이즈를 필연적으로 포함하게 된다는 단점도 존재합니다.
RGB와 Depth 데이터의 차이로 인해 기존 연구들은 대부분 두 개의 backbone을 이용하여 별도로(RGB-2D CNN 네트워크/ Depth-PointNet,PointNet++ 등) 특징을 추출하였습니다. Uni6D는 추가적인 UV 정보를 활용하여 “projection breakedown”(pooling, crop 등의 spation transform으로 인해 projection 식이 깨지는 경우)를 해결하고자 하였으며, RGB와 Depth 데이터를 통합 CNN 백본을 이용하여 특징을 추출합니다. 그러나 Uni6D의 경우 간단한 파이프라인과 depth 데이터의 노이즈를 고려하지 않아 제한적인 성능을 보였습니다.
이러한 제한적인 성능의 원인으로 저자들은 Instance-Inside/Outside 노이즈라는 것을 발견하였으며, 여기서 Instance-Outside 노이즈는 RoI 기반의 6D Pose Estimation 방법론에 의해 정확하게 객체 영역을 찾지 못해 인스턴스 외의 부분에서 노이즈가 발생하는 것이며, Instance-Inside 노이즈는 depth 센서의 한계로 인해 인스턴스 내에 노이즈가 발생하는 것을 의미합니다.
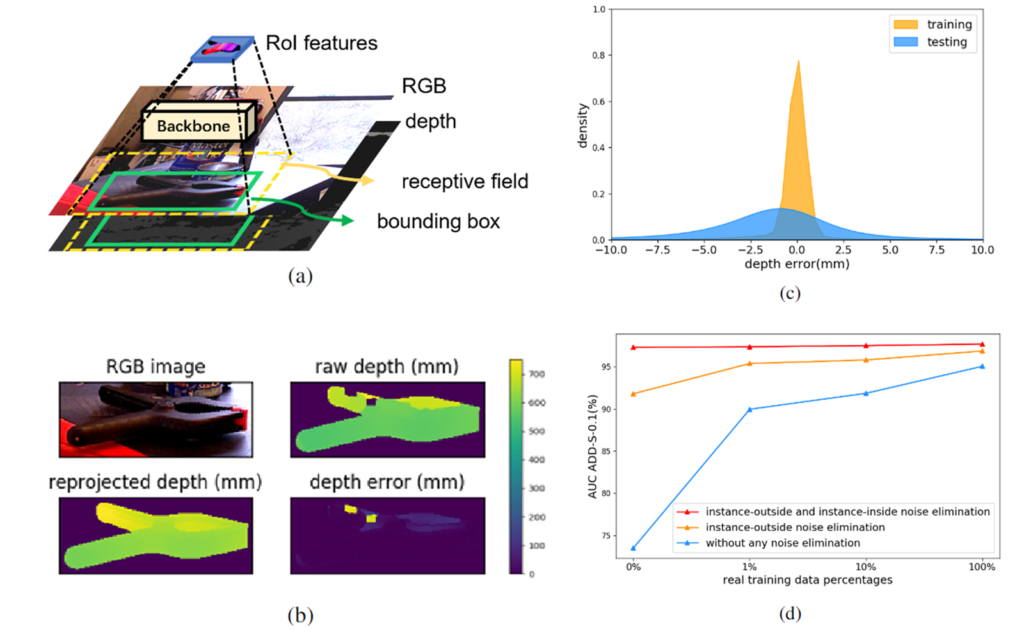
노이즈 영향을 정량적으로 확인하기 위해 YCB-Video 데이터에 depth reprojection 오차를 측정하여 나타낸 그래프가 [그림1]-(c)에 해당하며, 노이즈를 제거할 경우 점차 성능이 증가함을 [그림1]-(d)의 그래프를 통해 확인할 수 있습니다. 조금 더 구체적으로 노이즈를 제거한 방식에 대하여 설명하자면, 먼저 GT bounding box와 mask를 이용하여 instance-outside 노이즈를 제거하였으며, depth reprojection으로 구해진 depth 정보를 이용한 결과입니다. 이러한 실험을 통해 두가지 노이즈가 성능에 상당한 영향을 미치는 것을 확인하였습니다. 그러나, YCB-Video와 LINEMOD 같은 기존 데이터는 annotation cost가 높아 depth 노이즈가 포함되지 않는 합성 데이터를 많이 포함하고 있으나, test 데이터는 실제로 촬영한 데이터로 이루어져 노이즈가 포함되는 등 train-test 데이터의 gap이 발생하게 됩니다.
이러한 문제를 해결하기 위해 저자들은 Uni6Dv2라는 2단계의 denosing 6D pose estimation 방법론을 제안하였으며, Uni6Dv2는 instance segmentation mask를 이용하여 instance 영역을 구하고, 이후 단계에서 denosing module을 활용하여 depth를 수정하여 pose 추정 네트워크로 입력합니다. contribution을 정리하면:
- RoI 기반의 6d Pose estimation 방법론의 성능을 제한하는 다양한 유형의 노이즈를 찾아내고, 이를 Instance-Inside 노이즈와 Instance-Outside 노이즈로 구분
- 2-step의 denoising 파이프라인을 통해 기존 Uni6D 방법론의 노이즈를 제거
1단계는 instance segmentation을 통해 객체 외의 영역을 제거하며, 2단계는 노이즈 제거 모듈을 통해 depth 데이터에 포함된 노이즈 제거 - YCB-Video에 대하여 AUC ADD-S 평가지표에서 96.8%를 달성하여 SOTA 알고리즘인 FFB6D 대비 0.2%의 개선을 이루었으며, Uni6D 방법로에 대하여 학습 과정에 100% real 데이터를 이용할 경우 1.6%, real 데잍를 이용하지 않을 경우 20.1% 만큼 성능이 개선됨
Method
Uni6Dv2는 Uni6D의 확장 연구로, 위의 [그림2]가 Uni6D의 개요입니다. RGB-Depth 정보 뿐만 아니라 추가적인 데이터를 함께 입력으로 하여 공통된 CNN backbone을 통과하여 특징을 추출하는 방식입니다. Uni6D에 대한 간단한 설명으 한 뒤, 2가지 denoising 보듈에 대하여 설명하겠습니다.
Review of Uni6D
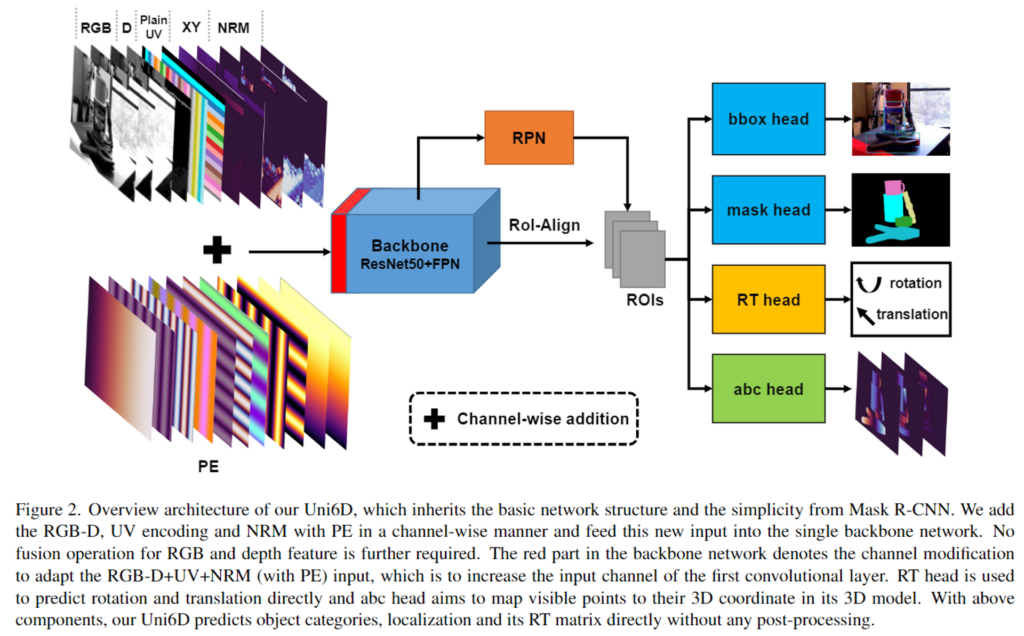
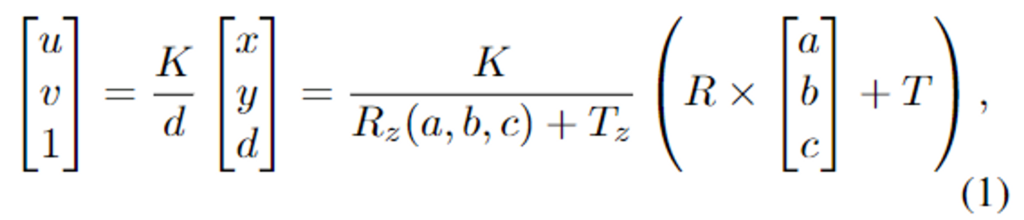
Uni6D는 CNN 파이프라인의 pooling, corp, ROI-Align 등의 spatial transformation으로 인해 projection 식(식1)이 깨지는 projection breakdown 문제를 해결하기 위해 depth의 법선벡터(NRM)이 있는 3D 공간(Plain UV,XY)를 RGB-D 데이터에 통합하여 한번에 특징을 추출합니다. Mask R-CNN 구조를 이용하여 rotation과 translation 파라미터를 추정하기 위한 RT head와 CAD 모델의 visible point (a,b,c)를 regression으로 구하는 abc head를 추가하여 6D Pose를 추정합니다. 그러나 이러한 Uni6D에 위에서 이야기한 두가지 noise를 고려하지 않아 성능이 제한적이였습니다. (Uni6D에 대한 더 자세한 내용은 이전 리뷰를 참고해주세요)
Comprehensive Denoising Pipeline
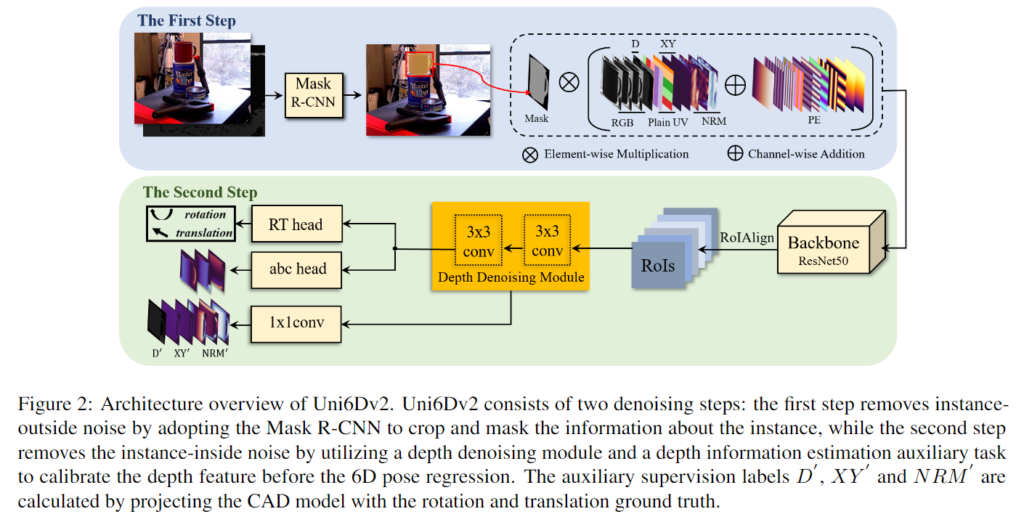
Instance-Outside/Inside 노이즈를 효과적으로 제거하기 위해 아래의 [그림3]과 같이 denoising 파이프라인을 제안합니다. Uni6D 로 pose를 추정하는 파이프라인을 기반으로 하며, 첫 번째 단계에서 Mask R-CNN을 이용하여 객체 외의 영역을 제거하는 방식으로 Instance-Outside noise를 해결하고, 두 번째 단계에서 depth noise 제거 모듈을 통해 Instasnce-Inside noise를 제거합니다. 두 번째 단계는 더 정확한 6D Pose를 regression할 수 있도록 하며 Uni6D의 RT head를 이용하여 직접적으로 6D Pose를 추정하는 동시에, abc head를 이용하여 보조적으로 CAD 모델의 좌표를 구합니다.
1. Instance-Outside Noise Elimination
instance 외의 영역을 사용하지 않는 것이 가장 간단한 노이즈 제거 방식입니다. 그러나, feature-level에서는 recieptive field로 인해 주변의 noise 영역을 완전히 제거하기 어렵습니다. 이러한 이유로, image-level에서 객체 외의 영역을 필터링해주어야 합니다. 이에 저자들은 Mask R-CNN의 output을 이용하여 배경 영역을 제외하였습니다. 이는 이미지 뿐만 아니라 Plain UV, XY. NRM, PE 모두에 적용하였습니다.
2. Instance-Inside Noise Elimination
Instance-Inside Noise는 [그림1]-(b)와 같이 depth 이미지 내의 홀이 생기거나 오차가 발생하여 생기는 노이즈로 6D Pose Estimation의 성능을 제한하는 원인입니다. 많이 사용되는 방식은 전처리 알고리즘[1]으로 depth hole을 채워 사용합니다. 해당 알고리즘은 extension을 이용하여 hole을 채우는 방식입니다. 그러나, 이러한 non-parametric 전처리 과정으로 채운 depth 값에는 여전히 오차가 존재합니다. 따라서 learnable한 depth denoising 모듈을 제안합니다.
**[1] Ku, J., Harakeh, A., and Waslander, S. L. (2018). In defense of classical image processing: Fast depth completion on the cpu. In 2018 15th Conference on Computer and Robot Vision (CRV), pages 16–22
RoI Align을 통해 추출된 feature에 depth denoising이 적용되며, 이때 denoising을 돕기 위해 보조적인 reconstruction 작업도 함께 진행합니다. 해당 모듈은 1×1 conv layer로 구성되어 noise가 없는 depth, XY, NRM을 동시에 추정하며, 이때 noise가 없는 depth, XY, NRM은 CAD모델을 re-projection하여 구합니다. re-projected label은 아래의 식(2)로 계산할 수 있습니다.
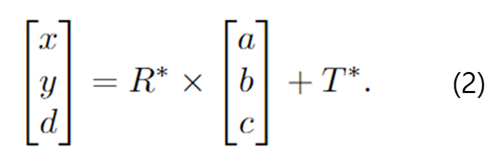
CAD 모델의 visible한 point (a,b,c)에 GT rotation matrix R*∈ SO(3)와 translation matrix T*∈ SO(3) 를 적용하여 카메라 좌표계에 대응되는 위치 (x, y, d)를 구하고 이렇게 구한 depth와 XY를 regression 하도록 모델을 학습합니다.
3. Loss function
먼저 Mask R-CNN은 기존의 loss를 이용하여 학습을 수행하였습니다. 그 다음, 파라미터를 freeze하여 두 번째 단계에서 RT regression loss, abc regression loss, 새로 도입한 depth denoising loss를 이용하여 각 head를 학습합니다.
- RT regression loss: \mathcal{L}_{rt}
- \mathcal{O}: 3D 모델의 vertex 집합
- R/T: rotation/ translation 행렬
- *: GT를 의미
- m: \mathcal{O}의 점의 개수
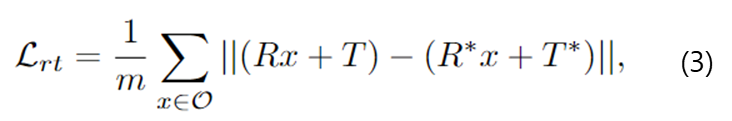
- abc regression loss: \mathcal{L}_{abc}
- (a,b,c): point의 좌표
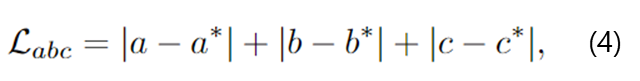
- depeth denoising loss: \mathcal{L}_{depth}
- (n_x,n_y,n_z) : depth로부터 계산된 depth normal 좌표
- (x, y) : 카메라 좌표계에서 보이는 영역의 좌표
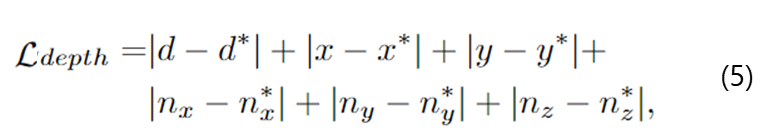
이렇게 구한 3가지 loss를 가중합하여 total loss를 구하여 학습을 수행합니다.
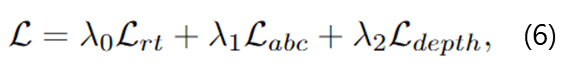
Experiments
Benchmark Dataset
- YCB-Video
- 21개의 YCB 객체에 대한 92개의 RGB-D 비디오(noise와 occlusion 포함)
- 학습데이터에 83.17%를 합성 데이터로 구성(기존 연구를 따름)
- LineMOD
- 13개의 low-texture 객체에 대한 13개의 비디오
- 학습 데이터의 99.71%를 합성 데이터로 구성(기존 연구를 따름)
- Occlusion LineMOD
- LineMOD 데이터로부터 확장된 데이터 셋
- 강하게 occlusion된 데이터로 구성되어 어려운 데이터 셋
Evaluation Metrics
- ADD
- m: 전체 vertex 개수
- x: \mathcal{O}의 개별적 vertex 의미
- [R, T]와 [R*,T*]: 예측 pose와 GT pose
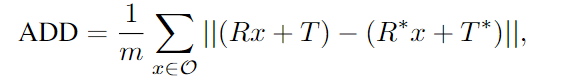
- ADD-S
- ADD 지표에 대하여, 대칭적인 객체의 경우 가까운 점 사이의 거리를 측정함
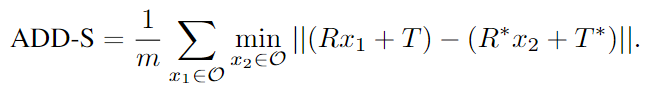
- AUC ADD(S)
- YCB-Video에 대한 평가지로 사용되며, 거리의 임계값을 0.1m까지 변경하며 그린 곡선의 아래 영역
- ADD(S)-0.1d
- 객체의 지름의 10%를 임계치로 설정하여 ADD(S)의 오차를 이용하여 정확도 측정(오차가 임계치 이하일 경우 정답, 이상일 경우 오답으로 )
Evaluation on YCB-Video Dataset
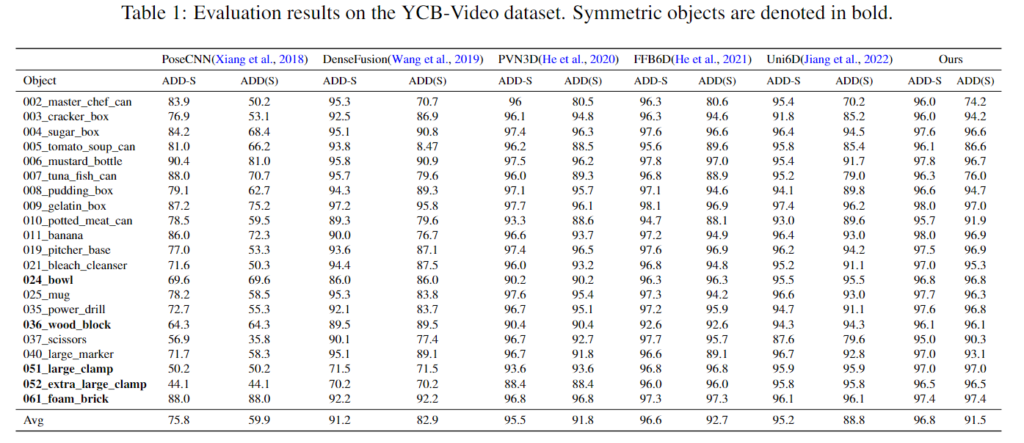
위의 Table 1을 통해 YCB-Video에 대한 Uni6Dv2의 카테고리 별 성능은 기존 방법론들과 비교했을 때 SOTA를 달성하였으며, Uni6D와 비교하였을 때 대부분의 성능이 개선되었음을 확인할 수 있습니다. 특히, Uni6Dv2의 경우 적은 픽셀로 구성된 객체들에 대해 잘 작동하는 것을 확인할 수 있습니다. (e.g. 037_scissors에서 ADD-S 7.36%, ADD(S) 9.72% 개선됨) 아래는 정성적 결과로, SOTA 방법론인 FFB6D와 이전 연구인 Uni6D와 비교한 결과입니다. 저자들은노이즈가 많을 때 더 정확하고 강인하게 작동한다고 주장합니다. 2열의 흰색 bounding box안의 객체를 통해 기존 SOTA 알고리즘에서는 잘못 예측한 결과를 해당 방법론에서는 잘 예측한다는 것을 확인할 수 있으며, 3~5번째 열의 경우 bounding box 안의 예측된 pose 결과를 보았을 때, FFB6D보다 정확한 Pose 정보 예측이 가능함을 확인할 수 있습니다.

Evaluation on LineMOD Dataset
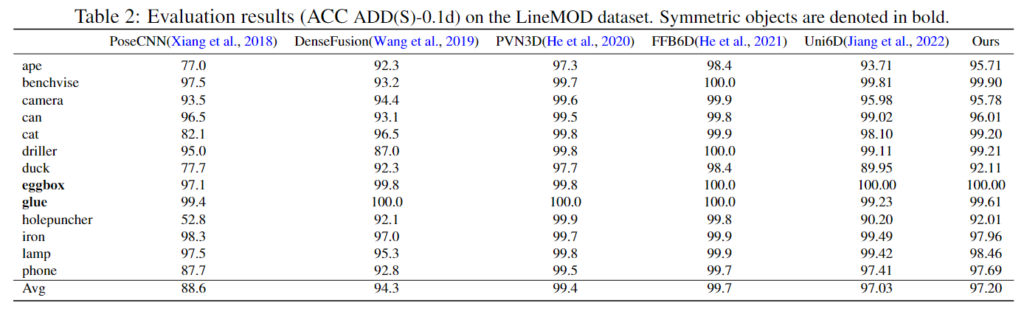
위의 Table 2를 통해 LineMOD데이터에서 저자들의 방법론과 다른 SOTA 알고리즘을 비교하였습니다. Uni6D에 비해 개선된 성능을 보였으나 다른 방법론 대비 SOTA를 달성하지는 못하였으며, 저자들은 LineMOD 데이터의 경우 occlusion이 발생하지 않아(데이터 셋의 특징으로, 중심 객체에 대하여 가려지지 않도록 촬영 및 annotaion을 수행함) Uni6D 대비 성능 개선 폭이 작았다고 주장합니다. 아래의 [그림5]는 정성적 실험 결과로 미세하게 예측 결과가 더 좋은 것을 확인할 수 있습니다.

Evaluatio on Occlusion LineMOD dataset
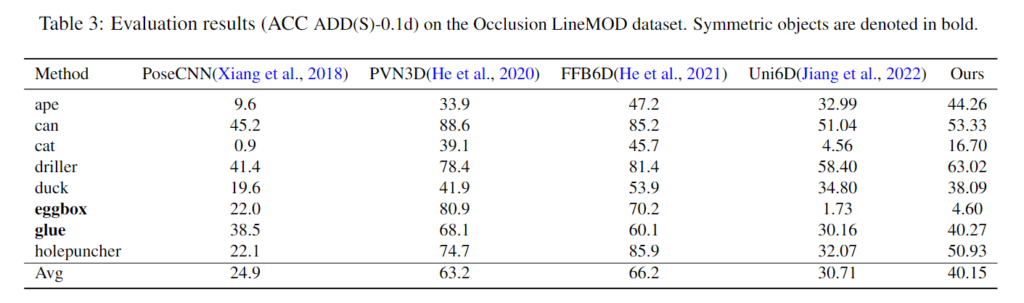
위의 Table 3은 Occlusion LineMOD에 대한 정량적 결과로, occlusion 된 장면에 대한 평가가 가능합니다. Uni6D와 비교하여 ACC ADD(S)-0.1d에 서 9.44% 성능 개선이 되었으며, 모든 카테고리에서 개선이 이루어졌습니다.
Time Efficiency
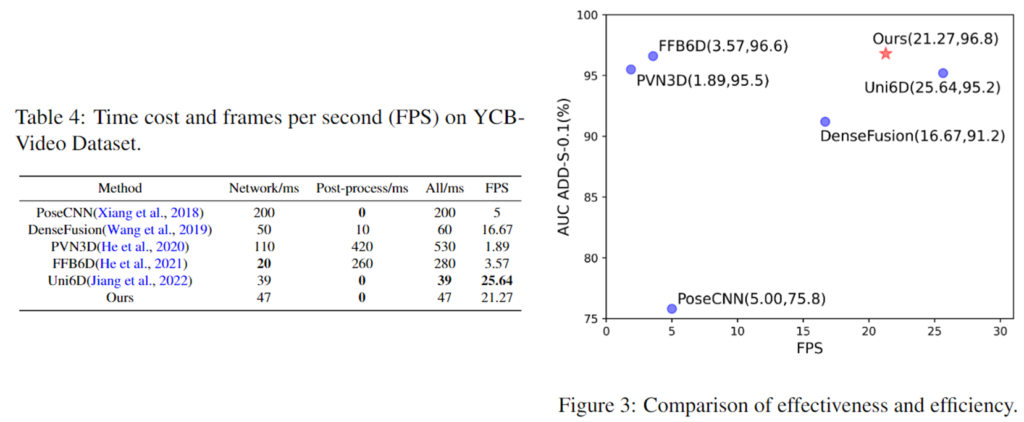
위의 Table4와 그래프는 추론 속도를 기존 방법론들과 비교한 결과 입니다. FFB6D에 비해 6배 빠른 21.27FPS를 달성하였으며, Uni6D와 비교하였을 때 17% 효율이 하락한 데 반해 상당한 성능 개선이 이루어졌습니다.
Ablation study
본 논문에서 핵심인 denoising에 대한 ablation study 결과입니다.
1. Effect on Noise Elimination
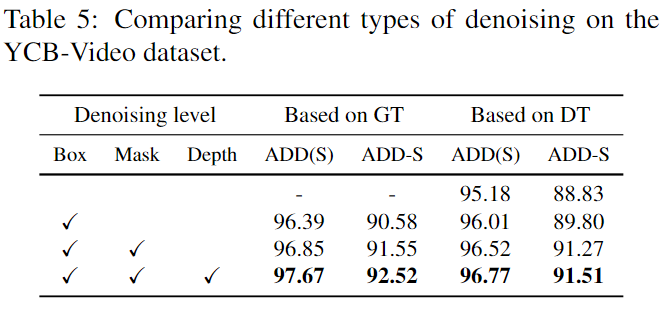
위의 Table 5의 Box는 Instance-Outside 노이즈를 제거하기 위해 예측된 bounding box를 이용하여 객체 영역을 crop하는 것, Mask는 예측된 객체 영역 외의 모든 부분을 필터링하는 것이며, Depth는 depth denoising 모듈의 사용 여부를 의미합니다. 또한, Based on GT는 pose regression 모델을 학습하기 위해 GT 마스크와 bounding box, CAD 모델을 reprojection하여 GT로 이용한 것을 의미하며 상한이 되고, Based on DT는 예측 결과를 이용한 결과입니다. 두 방식 모두 noise를 제거하는 방식이 추감됨에 따라 성능이 개선되는 것을 확인할 수 있습니다.
2. Comparison of Denoising Strategies
다음은 noise 제거 방식에 대한 효과를 조사하기 위해 다양한 노이즈 제거 방식과 비교한 결과입니다.

먼저 Instance-Outside noise 제거 방식을 비교하기 위해 feature-level과 image-level을 비교하였습니다. feature-level denoising은 feature 수준에서 객체 영역만 남기는 것으로 receptive-field의 영향으로 인해 noise가 완전히 제거되지 않아 성능이 더 낮은 결과를 보였습니다. 이에 반해 image-level의 denoising을 적용할 경우 성능이 개선되었으며, instance segmentation 모듈에 UV 정보를 입력하지 않아도 되므로 instance segmentation 네트워크에 부정적 영향을 주는 것을 피할 수 있다는 장점도 있습니다.(위의 Table7에서 instance segmentation에 UV정보가 포함될 경우 성능이 저하됨을 확인함)

다음은 Instance-Inside 노이즈 제거를 위해 reprojected depth, XY, NRM을 학습에 추가한 결과입니다. 모든 정보를 활용하는 것이 가장 높은 성능을 보여줌을 확인하였습니다.
3. Advantage of Reducing Real Data Requirements
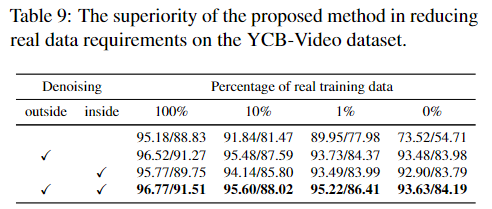
위의 Table 8은 noise 제거 방식의 장점을 확인하기 위해 real data의 비율을 1%,10% 무작위로 샘플링하고 합성데이터와 함께 학습을 수행한 결과입니다. 두가지 denoising을 모두 적용한는 것이 모두 좋은 성능을 보이는 것을 확인하였습니다. 또한, 모두 합성데이터로만 이루어진 0%에 대한 실험 결과도 instance denoising을 적용하는 것이 좋은 성능을 보이는 것을 확인할 수 있는 데, 이는 예측된 mask가 부정확하므로 instance-inside noise를 제거하는 과정이 효과를 보인다는 것으로 이해할 수 있습니다.
Denoising on Other RoI-Based Methods
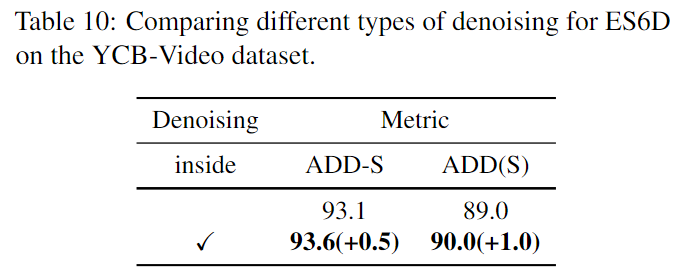
다른 RoI 기반 방법론에 저자들의 denoising 방식을 적용한 결과로 성능이 개선된 것을 확인할 수 있습니다.
Conclusion
본 논문을 통해 저자들은 Uni6D에 denoising을 추가하어 성능 개선을 이루었습니다. 이를 위해 instance-outside noise와 instance-inside noise를 발견하였으며, 이를 해결하고자 2단계의 denoising 파이프라인을 구성하였습니다. 또한 다양한 실험을 통해 저자들이 제안한 방식이 효율적으로 빠르고 강인한 6D Pose를 구할 수 있음을 실험적으로 보였습니다.
우선 본 논문의 denoising 방식이 너무 단순하다는 것이 아쉬운 점이였으며, 저자들도 연구의 한계점으로 적용한 denoising 방식이 개선되어야 한다고 이야기합니다. 그래도 depth에 대한 denoing 학습을 위한 방법론을 적용해볼 만 하다는 생각이 듭니다.
안녕하세요, 이승현 연구원님 좋은 리뷰 감사합니다.
결국 이 논문에서는 6d pose estimation에서 발생하는 inside/outside 노이즈를 제거하는 방법론을 제안하였으며, outside noise는 mask-rcnn을 이용하여 instance이외 배경을 제거하고, inside noise는 learnable depth denoising을 통해 보완한 것이라고 이해하였습니다.
리뷰를 읽고 몇 가지 질문이 있는데요, 먼저 instance noise가 무엇인지 직관적으로는 이해하였으나 구체적으로 어떤 것인지 잘 모르겠습니다. 어떤 물체의 pose를 예측할 때 해당 물체 이외의 depth와 rgb정보를 의미하는 것일까요?
리뷰를 읽어보았을 때 이 논문의 가장 핵심적인 부분이 instance-inside noise elimination이라고 이해하였습니다. 해당 방법론은 denoising 모듈의 learnable parameter를 학습하는데, 학습에 사용되는 gt는 cad 모델을 projection하여 생성한 depth값이며, noisy한 센서값이 gt를 regression한다고 이해하면 되는 걸까요?