안녕하세요 오늘은 생성형 모델로 유명한 GAN입니다. GAN이 어떻게 이미지를 생성해낼 수 있는지 왜 기존의 생성형 모델들이 아닌 GAN에 사람들이 관심을 갖게 되었는지 논문 리뷰를 통해 알아보겠습니다.
시작에 앞서 GAN의 이름에 한번 언급을 하고 넘어가자면, Generative ‘Adversarial’ Nets에서 Adversarial의 뜻은 ‘적대적인’이라는 뜻입니다. 한글로 직역하면 생성형 적대적인 네트워크인데, 이름에서의 ‘적대적인’이 GAN 모델에서 가장 중요한 개념입니다. 왜 Adversarial이 중요한지는 뒤에서 설명하도록 하겠습니다.
Introduction
현재까지의 딥러닝은 backpropagation, dropout 등등의 알고리즘을 베이스로한 dicrimitive models에 큰 성장을 만들어냈습니다(2014년 논문으로 이때에는 batch normalization, residual learning과 같은 개념이 등장하기 전이네요). 저자는 기존의 Generative모델은 최대 가능성 추정에서 발생하는 많은 확률 계산을 근사하기 어렵고 생성 컨텍스트에서 부분 선형 단위의 이점을 활용하기 어렵기 때문에 효과가 미비했다고 언급하며 Adversarial nets 프레임워크를 소개합니다. Adversarial net에 포함된 두가지 network를 간단히 소개하는데
첫번째는 Generative Model로 Input으로 주어진 데이터의 distribution을 파악하는 network로 Generative Model이 데이터의 distribution을 학습하여 학습한 distribution을 통해 가짜 데이터(논문에서 fake로 표현, 실제 이미지가 아닌 생성된 이미지)를 생성합니다.
두번째는 Discriminative Model로 이미지가 생성된 이미지인지 실제 이미지인지를 구별하는 모델입니다. 실제 데이터라면 1, 가짜 데이터라면 0으로 반환합니다. 따라서, 가짜 데이터 진짜 데이터를 구별함으로써 Generative Model이 가짜 이미지를 실제 이미지와 구별할 수 없게끔 하는 방향으로 유도합니다.
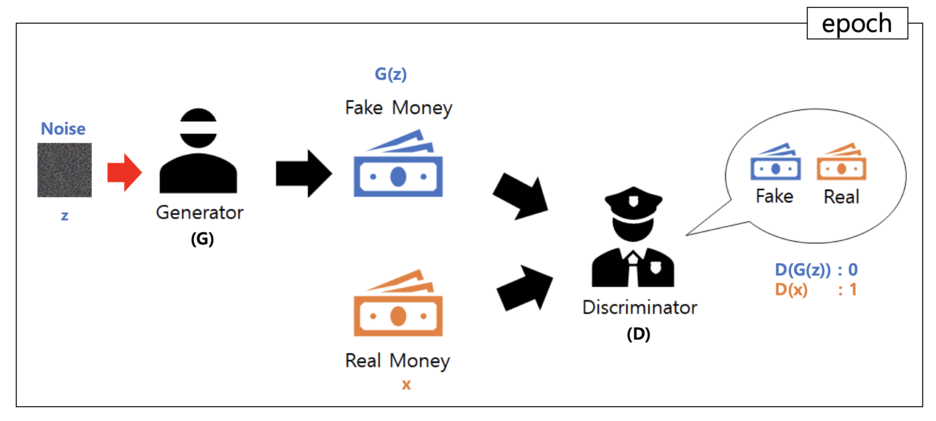
(위의 이미지는 논문에서 포함된 이미지가 아닌 이해를 돕기위한 이미지로 블로그에서 가져왔습니다.)
논문에서는 경찰과 위조지폐(가짜지폐)를 예시로 들며 모델을 설명합니다. Generative Model(위조범)이 위조 지폐를 잘 만들수록 Discriminative Model(경찰)이 실제 지폐와 위조 지폐를 구별하기 힘들어집니다. 경찰은 위조지폐를 더 잘 구별할 수 있도록 학습하고 위조범은 위조 지폐를 실제와 비슷하게 만드는 방법을 학습함으로 양쪽 모델의 성능을 올려 결과적으로 Discriminative Model이 출력한 확률값이 0.5에 가까워질수록 성능이 좋은 Generative Model를 만들 수 있게되는 것입니다. 물론 실제 생성형 모델로 GAN을 활용할때에는 Generative Model만을 이용하여 이미지를 생성합니다.
따라서 Adversarial의 적대적이라는 것은 Generative Model과 Discriminative Model이 서로 경쟁하는 것을 표현한 것이고, 경쟁을 통하여 성능이 좋은 Generative Model을 얻을 수 있습니다. 두 모델은 모두 Multilayer perceptron으로 구현했습니다.
Adversarial Nets
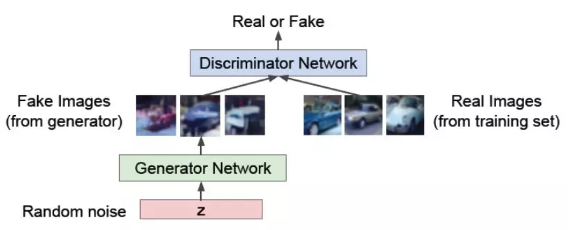
(위의 이미지는 GAN모델의 구조로 논문이 아닌 블로그에서 가져왔습니다.)
Adversarial Network의 구조는 Generator, Discriminator로 구성되어있습니다.
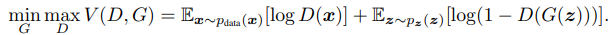
위 수식은 논문에서 제시한 학습을 위한 loss function입니다. Generator의 데이터 x에 대한 distribution을 pg , 인풋 노이즈를 pz(z), 그리고 G가 파라미터θg로 구성된 Generative model이라고 할때 데이터를 매핑시키는 것을 G(z; θg)라고 정의했습니다.
확률값을 0~1로 출력하는 Discriminative model은 D(x; θd)이고, D(x)는 인풋 x가 Generator에서 생성된 이미지가 아닌 pg로부터 온 확률을 의미합니다. 훈련 샘플과 G의 샘플 모두에 정확한 레이블을 할당할 확률을 최대화하는 것을 목표로 D를 훈련시킵니다. log(1 – D(G(z))를 최소화하기 위해 D와 G를 동시에 훈련시킵니다. 즉, D와 G는 값 함수 V(G, D)로 위의 수식처럼 min max로 나타낼 수 있습니다.
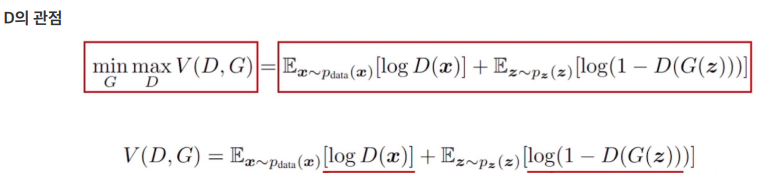
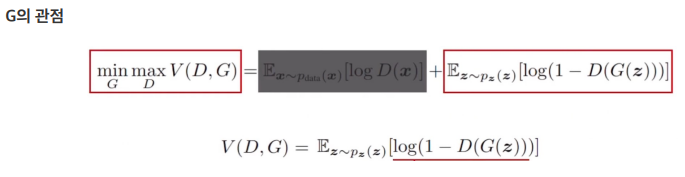
수식만으로는 이해가 어렵기 때문에 추가로 설명드리면, Discriminator는 real data는 1, fake data는 0을 구별하는 것을 목표로 이상적인 목표는 D(x)=1, D(G(x))=0을 출력하는 것입니다. 따라서 D(x), 1-D(G(z))의 값을 1로 만드는 것을 목표로 합니다. 따라서 log를 씌우는 것으로 0에 가까이 가도록 loss를 설정합니다. Generator는 Discriminator가 잘 구별하지 못하도록 하는 것을 목표로 Discriminator와 반대를 목표로 하죠. 이부분이 Adversarial하다고 할 수 있습니다. 따라서 1-D(G(z))의 값이 0에 가깝도록 합니다.
결과적으로 위의 loss function은 Generator(G)가 최소화(min)되도록, Discriminator(D)가 최대화(max)되도록 학습합니다.
Theoretical Result

Figure 1. 에서 검정색이 real data, 파란색이 fake data의 distribution이고 노이즈 z가 fake data를 real data의 distribution에 가까이가고 discriminator(파란색)이 0.5의 값을 항상 가질 수 있도록 학습합니다. 학습이 가장 이상적일때 0.5의 값은 real data, fake data의 확률이 0.5로 discriminator가 Generator로부터 생성된 이미지와 실제 이미지와 구별할 수 없다는 것을 의미하기 때문입니다.

Algorithm 1. 은 min max loss가 둘중 한 곳이 이득을 보게된다면 다른 곳은 손해를 보는 구조이기 때문에 Generator와 Discriminator를 동시에 학습하지 않습니다. Discriminator를 stochastic gradient를 통해 학습한 후에 학습한 Discriminator를 통하여 Generator를 stochastic gradient로 학습합니다. D는 ascending(최대화), G는 descending(최소화)시키면서 학습합니다.
추가로 논문에서는 GAN의 이론적 배경으로 두가지 명제를 제시합니다. GAN이 global optimum에 수렴할 수 있다는 것에 대한 내용과 그 global optimum이 unique하다는 것에 대한 내용입니다.

명제1: G가 고정되어 있을때, 이상적인 D는 위의 수식과 같습니다.
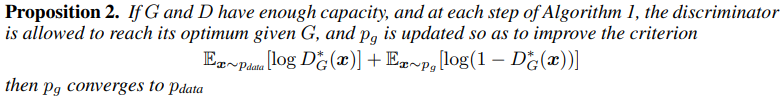
명제2: G와 D가 충분한 공간을 가지고 있다면, 알고리즘 1의 각 단계에서 D가 주어진 G에서 최적에 도달하도록 하고, Pg는 criterion을 개선하기 위해 업데이트됩니다.
Experiments
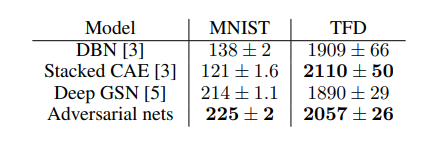
생성형 지표의 평가모델은 Parzan window-based log-likelihood estimates로 G로 생성한 데이터를 Gaussian Parzen Window를 맞춘 후 데이터 분포의 로그 우도를 측정한다고 합니다. 이때 당시에는 생성형 모델의 평가지표가 모델의 성능이 얼마나 좋은지를 잘 나타낸다고는 볼 수 없다고 할 수 있습니다. 그래서 저자는 실제 결과를 정성적으로도 첨부했습니다.

생성된 이미지는 선별해서 고른 것이 아닌 모두 랜덤하게 가져왔다고 밝혔고, 여기서 노란색은이 실제 데이터로 단순히 실제 데이터와 똑같이 만드는 것이 아닌 있을법한 이미지를 잘 만든다고 설명합니다.

추가로 선형적으로 interpolation해서 왼쪽의 그림을 예시고 왼쪽으로 갈수록 1의 분포에 가깝게, 오른쪽으로 갈수록 5에 가깝게 만드는 것으로 GAN모델이 다른 모델과 다르게 실제로 있을 법한 이미지를 잘 생성한다고 할 수 있습니다.
Conclusion
GAN모델의 논문을 읽으며 생성형 모델에 적대적인 관계의 두 모델을 활용하여 모델을 설계한 부분이 굉장이 인상적이었습니다. 이론적 배경부분에서 Proposition은 아직 이해가 부족하여 제대로 설명하지 못한 것 같아 아쉽네요. 공부해서 추후에 더 자세한 내용 추가하도록 하겠습니다.
감사합니다.
안녕하세요. 박성준 연구원님.
리뷰 잘 읽었습니다. 몇가지 질문 드리겠습니다.
1. 그림 3에서 뭔가를 선형적으로 interpolation 했다고 하는데, 무엇을 interpolation한 것이고 왜 그림이 달라지는 건가요?
2. 이건 정답이 있는 질문은 아니고 성준님의 의견이 궁굼한 것인데요. Generator 모델이 특정 클래스의 이미지 (예를들어, MNIST에서 1이나 2)를 생성하도록 하려면 어떤 방법을 사용해 볼 수 있을까요?
감사합니다.
+ 지난주 리뷰에도 질문 드렸는데.. 답글 달아주세요.. 기다리고 있어요.. ?
지오님 좋은 답변 감사합니다.
1. 그림 3에서의 선형적인 interpolation은 왼쪽 이미지의 속성을 나타내는 벡터 z_1, 오른쪽 이미지의 속성을 나타내는 벡터 z_2가 있다고 할 때 두 벡터의 끝점 사이의 위치에 보간한 것을 의미합니다. 예시를 들어 z_1이 (0,0), z_2가 (10,0)이라고 가정했을 때 두 이미지 사이의 이미지들은 (1,0),(2,0),(3,0)… (9,0)과 같이 보간됩니다. 앞서 언급한 것처럼 z는 이미지의 속성을 나타내므로 상대적 위치에 따라 각 이미지의 속성을 반영하는 비율이 달라집니다.
2. 이미지의 속성을 나타내는 벡터z가 존재할 때, z와 임베딩 공간 상에서의 거리가 가까울수록 해당 이미지의 속성을 많이 가지게되므로 특정 클래스의 이미지를 나타내는 벡터z와 거리가 가까운 벡터z를 생성하는 것으로 이미지를 생성할 수 있을 것 같습니다.
안녕하세요 성준님~ 좋은 리뷰 감사합니다
리뷰를 보니 Gan이 상당히 좋고 획기적인 모델인 것 같습니다. 하지만 Gan은 초기 모델인 만큼 한계점도 많을 것 같은데 논문에서 언급된 한계점이나 성준님이 알고 계신 것들이 있는지 알려주시면 감사하겠습니다~
의철님 좋은 답변 감사합니다.
GAN의 구조는 Discriminator와 Generator가 상호작용을 하며 학습을 하는 것이 아니라 따로 학습을 하게 되며 둘의 학습의 정도의 차이가 있을 수 있습니다. 이를테면 Generator의 학습이 끝난 시점에 Discriminator의 학습이 끝나지 않는 것과 같은 경우를 말할 수 있습니다. 논문에서는 이를 synchronized가 되지 않아 한쪽이 collapse하는 문제라고 언급하고 있으며 위와 같은 문제가 발생하면 generator가 같은 이미지만을 생성하게되는 문제가 생깁니다.
안녕하세요, 좋은 리뷰 감사합니다.
GAN의 전반적인 내용을 잘 다루어주셔서 잘 읽었습니다.
해당 논문에 대한 의문점이 생겨 질문을 몇가지만 드리고자 합니다.
1. Discriminator와 Generator 모델 둘 다 MLP를 통해 구현이 되었다고 하셨는데, 저희가 아는 단순한 MLP구조인건지 아니면 backbone 모델은 GAN에 적합한 어떤 conv layer로부터 classifier 파트만 MLP로 구성되어 있는건지 궁금합니다.
2. 마지막 실험 섹션에서 MNIST와 TFD 데이터셋에서 실험을 진행했는데 TFD에서의 수치가 매우 높은데 해당 평가지표로 사용되는 log likelihood 수치가 각 셋에 대해 차이가 크네요. 데이터셋을 봤을 때 숫자와 사람에 대해서 저렇게 차이가 나는 이유는 무엇인지 궁금하네요.
감사합니다.
희진님 좋은 답변 감사합니다.
1. GAN은 2014년도에 제안된 생성형 모델로 당시에는 CNN에 대한 이해가 적은 시기로 논문에서 구현한 GAN은 저희가 아는 단순한 MLP구조로 구현되었습니다. 후속 연구들은 CNN을 활용한 것으로 알고 있습니다만 제가 직접 논문을 읽어보지는 않아 구체적으로 어떤 모델을 어떤 구조로 사용했는지에 대한 것은 잘 모르겠네요.
2. 논문에서 직접 차이가 나는 이유에 대해 언급하지는 않아 제 생각을 말씀드리겠습니다. GAN이 사용한 평가지표는 생성된 이미지의 분포와 원래 이미지의 분포가 어느정도 비슷한지 측정하는 지표지만 이미지의 경우 고차원공간이라 이미지를 저차원 공간으로 변경한 후 분포를 구하게 됩니다. 선형적인 이미지의 숫자와 달리 사람의 얼굴의 경우, 저차원으로 변경하는 과정에서 복잡한 특징들이 단순화되고 모든 데이터셋이 얼굴 중앙으로 crop되어 있는 TFD의 특성상 실제 데이터와 생성된 데이터의 분포가 비슷해져 수치가 높게 나타난 것으로 생각됩니다.
안녕하세요 박성준 연구원님 좋은 리뷰 감사합니다.
리뷰를 읽고 궁금증이 있어 몇 가지 질문 드리겠습니다.
GAN의 이론적 배경으로 제시된 두 proposition 중 첫 번째로 제시된 D*_G는 GAN이 수렴하게 되는 global optimum을 나타낸 것인가요? 해당 수식은 원본 데이터 + 생성 데이터에서 원본 데이터의 비율을 나타낸 것이 맞는지도 궁금합니다… 수식에 나타난 각 인자의 의미도 설명해주시면 좋을 것 같습니다…
GAN의 성능을 평가하기 위해 논문에서는 로그 우도를 사용하였으나, 이는 적절한 평가 지표가 아니라고 언급해 주셨습니다. 그럼 개인적인 궁금증인데 이후 생성 모델 연구에서는 어떤 모델의 평가 지표를 사용하는지 궁금합니다. 아직까지 이렇다 할 정량적 기준이 없는 것일까요?
혜원님 좋은 답변 감사합니다.
D*_G는 주어진 Generator에 대한 이상적인 Discriminator를 나타냅니다. p는 비율을 나타내는 것이 아닌 원본 데이터의 확률 분포를 P_data, 생성 데이터의 확률 분포를 p_g로 표현했습니다. 제가 인자에 대한 설명을 하지않아 이해가 어려움이 있었던 점 사과드립니다. 각 인자에 대한 설명도 추가하도록 하겠습니다. 생성형 모델의 평가지표는 생성 이미지와 원본 이미지의 집합의 거리 차이를 이용하여 평가하는 FID(Fechet Inception Distance), 생성 이미지 집합의 품질과 다양성을 고려하는 IS(Inception Score), 픽셀 간 비교 대신 생성 이미지의 대비, 구조, 휘도를 비교하는 SSIM(Structural Similarity Index Map)등 여러 평가지표가 후속 연구를 통해 제안되었고, 현재에는 정량적 기준이 있다기보다는 여러 평가지표을 통해 상호평가하는 것으로 알고있습니다.