제가 이번에 리뷰할 논문은 object의 자세 정보를 추정하는 데 있어, occlusion이 발생할 경우 object의 랜드마크를 찾기 어려워 발생하는 문제를 해결하고자 제안된 방법론 입니다.
Abstract
6D Pose estimation을 실제 환경에 적용하기 위해서는 occlusion에 대한 강인성을 확보해야 합니다. 6D Pose Estimation의 SOTA 방식들은 2D landmarks(keypoints)를 예측하고, 이후 3D 모델과 2D-3D correspondence로부터 6D pose를 추정하는 2-stage 방식을 사용합니다. 그러나 이러한 2-stage 방식은 일반화 과정에 학습에 포함되지 않은 occlusion이 발생하거나 feature에 노이즈가 포함될 경우 landamarks의 일관성이 떨어지는 문제가 발생할 경우 잘 작동하지 않을 수 있습니다. 이러한 문제를 해결하고자 저자들은 occluded-and-blackout batch augmentation방식을 제안하여 occlusion에 강인한 feature를 학습하고, multi-precision을 제안하여 정확하고 landmarks 예측과 일관성이 있는 representation을 학습할 수 있는 구조를 제안합니다. SOTA 알고리즘들과 평가를 진행하였고, LINEMOD와 YCB-Video에서 좋은 성능을 보였으며, 실험을 통해 저자들이 제안한 방식이 다른 방식에 비해 높은 데이터 효율성을 보인다는 것도 입증하였다고 합니다.
Introduction
객체의 pose 정보를 추정하는 것은 객체와의 상호작용을 하기 위해 중요한 task입니다. 저자들은 depth 정보를 활용할 경우, 해당 task가 더욱 단순해지지만, 항상 depth정보를 활용할 수 없다는 문제가 있으므로 단일 RGB 이미지만을 이용하여 pose 정보를 추정하는 연구를 수행하였습니다. 또한, pose estimation 연구의 경우 pose를 추정하는 단계(여기선 base estimator라 표현하겠습니다) 뿐만 아니라 더 정확한 pose를 예측하기 위해 refinement도 함께 수행하는 경우가 많은데, 저자들은 bse estimator에 집중하여 문제를 해결합니다.
또한, 객체의 pose 정보를 추정하기 위해 직접적인 regression 방식으로 문제를 해결하는 direct regression 방식이 있으나, 이는 occlusion이 발생할 경우 민감하게 반응하여 잘 작동하지 않습니다. 이러한 문제를 해결하고자 landmarks를 예측하여 2D-3D correspondences를 구한 뒤, PnP 알고리즘 등을 이용하여 pose를 추정하는 2-stage 방식이 연구되었습니다. 이러한 2-stage 방식은 pose를 추정함에 있어 landmark와 같은 추가적인 정보를 통해 더욱 다양한 정보를 포함할 수 있으며, outlier에 강인하게 작동할 수 있도록 RANSAC을 이용하여 PnP를 수행하는 등 부정확한 landmark에도 robust하게 작동이 가능합니다.
그러나, 2-stage 방식도 occlusion에 본질적으로 강인하지는 않습니다.(RANSAC을 포함한 PnP도 landmark에 노이즈가 포함되었을 때 강인하게 작동하는 것으로 occlusion을 염두에 둔 세팅이 아닙니다.) 따라서 최근 연구들은 강인성을 갖기 위해 pixel 수준이나 patch 수준의 예측결과들을 앙상블하여 최종적으로 pose를 추정하는 방식의 연구를 수행하였으나, 이러한 연구들은 일부 occlusion에 의한 부정확성 문제를 완화하라 수 있으나, landmark를 독립적으로 예측하는 네트워크의 특성상 새로운 occlusion이 발생할 경우 잘 작동하지 않습니다.
이러한 기존의 문제를 해결하고자 저자들은 심각한 occlusion에 강인하도록 occlusion-robust한 feature를 학습 방식을 제안합니다. 저자들은 Robust Object Pose Estimation(ROPE) 프레임워크를 제안하며, 이는 다양한 augmentation 방식을 포함하고 추가로 occlude-and-blackout batch augmentation이라는 새로운 방식을 소개합니다. 또한, 독립적으로 landmark를 예측하기보다는 객체의 모양과 일치하는 landmark를 생성할 수 있도록 학습 과정에 전체적인 pose representation을 학습할 수 있도록 하였다고 합니다. 이를 위해 multi-precision supervision 구조를 제안하며, 모델이 가려진 부분을 추정하는 능력을 향상시켜 더 정확하고 구조적으로 일관성 있는 예측이 가능하도록 학습하여 전체적인 pose representation 학습이 가능하도록 하였다고 합니다.
저자들은 refinement나 후처리를 하지 않고도 LINEMOD 데이터에서 탁월한 성능을 보였으며, YCB-Video 데이터에서는 refinement를 사용하지 않는 모든 방식들보다 좋은 성능을 보였고 refinement를 사용하는 방법론들과는 경쟁력 있는 성능을 보였다고 합니다. 또한, 실험을 통해 대량의 합성 데이터를 이용하는 방식보다 ROPE 방식이 데이터 효율적/임을 보였다고 합니다.
The ROPE framework
2-stage pose estimation 과정은 아래의 그림과 같습니다. 이미지 I와 Known 3D Point cloud \{ z_i \}^n_{i=1} 가 주어졌을 때, 이미지로부터 2D landmarks \{ x_i \}^n_{i=1} 를 예측하고, 2D-3D correspondence에 대하여 RANSAC을 활용한 PnP를 이용하여 해를 구하여 객체의 pose 정보를 예측합니다. 이때, landmark를 추정하는 부분과 pose를 구하는 2 단계로 이루어져 있어 2-stage 방식이라 하며, 저자들은 landmark prediction 과정에 집중하였습니다.
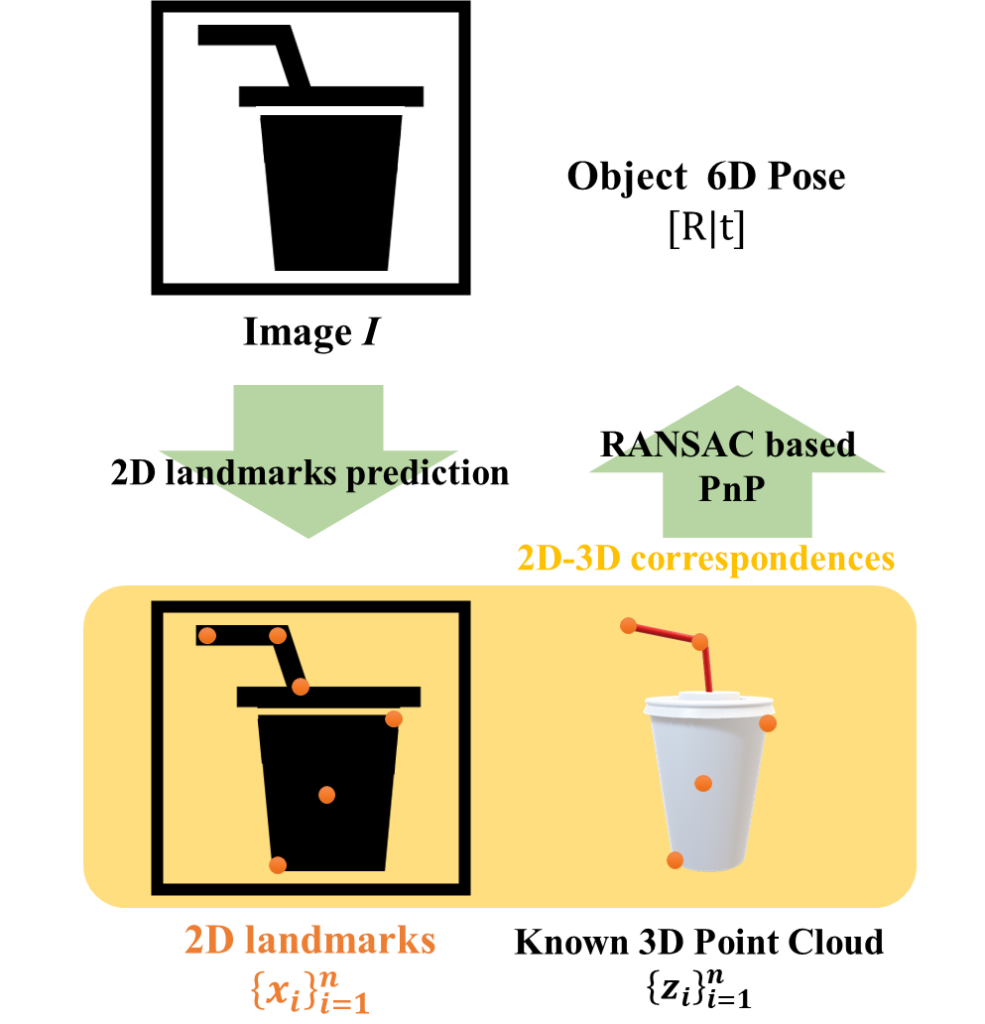
1. Robust landmark prediction
2D landmark를 구하기 위해 Mask R-CNN을 기반으로 하였으며, 이때 백본을 풍부한 semantic 정보를 유지하고, 공간적 정확도를 높여 고해상도의 feature map을 얻을 수 있도록 HRNet으로 변경하였다고 합니다. HRNet은 아래의 그림2와 같이 병렬적으로 네트워크를 구성하여 해상도를 유지할 수 있도록 한 백본 네트워크이며, 본 논문의 구체적인 네트워크 구조와 학습 방식은 아래의 그림3에서 확인하실 수 있습니다.

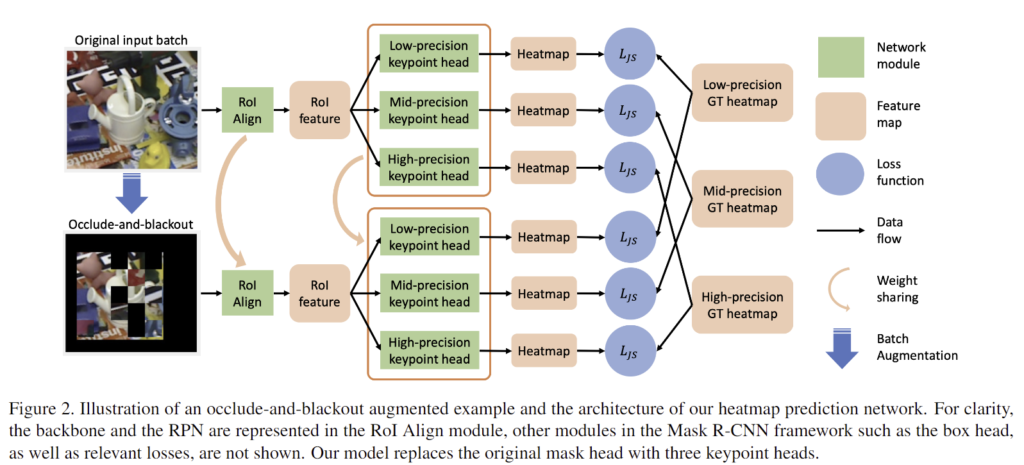
다음은 occlusion에 강인성과 landmark의 일관성을 높이기 위해 본 논문에서 제안한 2가지에 대한 설명입니다.
1.1 Occlude-and-blackout batch augmentation
3D object의 경우, 반대편의 landmarks가 가려질 수 밖에 없는 self-occlusion 문제가 존재합니다. 또한, 그 외의 다른 객체나 장면의 특성상 occlusion이 발생하기도 합니다. 이처럼 6D Pose Estimation을 실제로 활용하기 위해서는 이러한 서로 다른 종류의 occlusion에 강인하게 pose를 추정하는 것이 중요합니다. 저자들은 기존에 존재하는 (pose estimation을 위한 augmentation이 아님) augmentation 방식들(아래에 설명 참고)로부터 영감을 받아 Occlude-and-blackout Batch Augmentation (OBA)라는 occlusion에 강인하도록 새로운 augmentation 방식을 제안하였습니다.
Augmentations
- Random Erasing
입력 이미지에 랜덤한 크기의 bounding box만큼에 랜덤한 노이즈를 주어 학습시키는 방식

- hide-and-seek
patch를 매번 랜덤하게 지워 네트워크가 다양한 부분을 볼 수 있도록 함. 오른쪽 그림은 네트워크가 활성화 된 부분을 시각화 한 것으로, randomly hidden patches에 대한 결과가 더 넓은 영역에 집중한다는 것을 보인 것.

- batch augmentation
동일 배치 내에서 샘플 instance를 다른 데이터로 augmentation하는 방식
OBA
학습시 batch마다 rotation. scaling 등의 다양한 augmentation을 적용한 뒤, 추가적인 복사본을 포함시켜 배치를 늘리는 occlude and blackout을 수행합니다. 이는 hide-and-seek 방식과 유사하게 객체의 bounding box로 둘러써인 영역을 그리드로 나누고, 각 패치에 특정 확률마다 다른 이미지의 노이즈나 임의의 패치로 바꾸는 것입니다. 그 다음 bounding box 외의 모든 영역을 blackout하는 것으로 그림3에서 예시 이미지를 확인하실 수 있습니다.
해당 과정을 통해 무작위로 occlusion을 생성하여 네트워크가 객체의 일부분을 통해 pose 정보를 예측하도록 합니다. 이렇게 augmentation 된 이미지는 원본 이미지와 함께 네트워크로 들어가며, 동일한 GT pose를 이용하여 학습을 수행합니다. 이를 통해 저자들은 네트워크가 occlusion에 강인하고 배경에도 영향을 덜 받도록 학습되었다고 합니다.
해당 방식이 크게 새롭다고 느껴지지는 않지만…. 저자들에 따르면, occlusion을 발생시키는 것에 대한 정보를 학습 과정에 추가하여 성능을 높이는 연구가 있으나 실제 활용시에는 어떤 것이 occlusion을 발생시킬 지 알 수 없으므로 사전에 occlusion을 발생시키는 정보를 이용하는 방식에 비해 test set에서 일반화가 더 잘 된다고 합니다.
1.2 Multi-precision supervision
heatmap 기반의 landmark prediction 네트워크는 학습 과정에 단일 GT 가우시안 heatmap을 이용하여 각 landmark 마다 별도록 학습을 진행합니다. 이때 landmark의 GT는 FPS(farthest point sampling) 알고리즘을 이용하여 구하며 11개의 keypoint를 이용합니다. 이러한 heatmap의 분산은 설정에 주의해야 하는 하이퍼파라미터이며, 분산이 작을 경우 각 landmark마다 예측 정확도가 뫂아질 수 있지만 occlusion이 발생하여 전체적인 객체의 pose에 대한 이해가 부족할 경우 landmark의 불일치로 인해 정확도가 크게 낮아질 수 있습니다. 이러한 문제를 해결하고자 저자들은 3개의 keypoint heads를 이용하여 다양한 분산으로 GT 가우시안 heatmap을 예측하는 Multi-Precision Supervision(MPS) 구조를 제안하였습니다.
Mask R-CNN을 통해 백본의 feature map이 RoI proposal과 정렬되고, RoI의 feature가 3가지의 keypoint head를 통과하여 다양한 분산의 heatmap을 생성합니다. 이때, 각 keypoint head는 8개의 convolution 레이어와 2개의 upsampling 레이어로 구성됩니다.
Training phase
학습 과정에는 GT heatmaps \Phi ^*는 2D landmarks x ^*를 중심으로 분산 \sigma^2만큼 분포하여 구해집니다. \sigma 는 8, 3, 1.5 픽셀을 low/mid/high precision target heatmaps \Phi ^*로 이용하였으며, 이에 대한 regression은 아래의 식(1)에 해당하는 loss 함수를 이용하여 학습합니다.
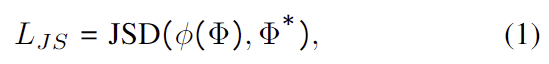
- JSD: Jensen-Shannon divergence[1]를 의미. 두 확률 분포사이의 거리를 나타내는 방식
- \phi(.): channel-wise softmax 함수를 의미
즉, 각 네트워크가 예측한 heatmap에 channel 별로 softmax를 취한 분포와 GT heatmaps 분포 사이의 거리를 loss로 이용합니다.
[1] Bent Fuglede and Flemming Topsoe. Jensen-shannon diver- gence and hilbert space embedding. In Proceedings of The International Symposium on Information Theory, 2004.
Testing phase
테스트 과정에는 landmark의 x 좌표를 구하기 위해 high-precision keypoint head에서 예측한 heatmap \Phi 만을 이용합니다. 이때 \Phi 에 단순히 argmax를 구하는 것이 아니라, 정규화된 heatmap \phi(\Phi) 을 구하여 공간에 대한 확률값을 x 좌표로 이용합니다. 이는 argmax를 취하는 방식에 비해 (1) continuous하므로 더 정확하고, (2) outlier 픽셀에 대해 대해 더 강인하다는 장점이 있습니다.
test과정에는 high-precision keypoint head만이 사용되지만, low/mid-precision keypoint head도 유의미한 역할을 수행합니다. 먼저, 학습 과정에 다양한 분산 정보를 제공하여 모델이 다양한 크기의 객체에 대응하는 데 도움을 주며, 분산에 대한 하이퍼파라미터를 설정하지 않아도 된다는 장점이 있습니다. 또한, mid-precision keypoint head의 경우 예측된 landmark를 필터링에 활용하여 pose 예측에 보조적인 역할을 합니다.(아래에서 추가로 설명) 마지막으로, MPS는 pose의 전체적인 representation을 학습하여 landmarks 일관성을 높이는 역할을 하며 이는 아래의 그림4를 통해 확인이 가능합니다.
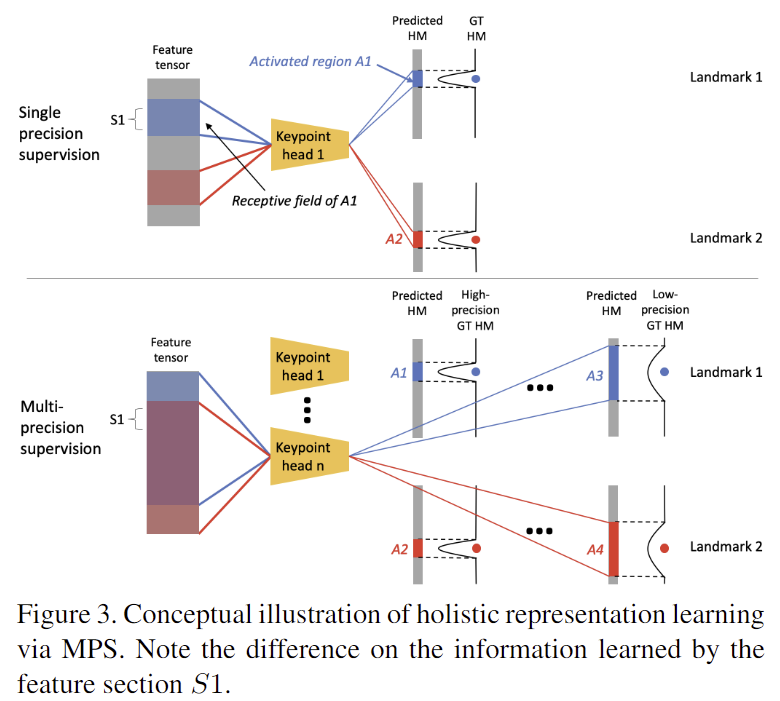
저자들은 그림 4를 통해, 각 부분이 landmark를 예측하는 데 필요한 정보를 학습할 뿐만 아니라 다른 landmark에 대한 지식을 통합하여 더 넓은 맥락을 이해함으로써 대상 물체의 pose 정보를 보다 총체적으로 representation을 학습할 수 있음을 보이고자 하였습니다.
- 상단의 예시는 single precision supervision 방식으로, 파란색에 해당하는 GT heatmap을 예측함에 있어 A1 영역만이 활성화(landmark 2에 해당하는 A2 영역은 고려되지 않음)
- 하단의 예시는 multi-precision supervision 방식으로, 파란색에 해당한은 GT heatmap을 예측할 때, A4에서 landmark 2에 해당하는 영역도 포함됨
2. Landmark filtering
다양한 pose estimation 방식은 pose를 예측시 최적화 혹은 학습 기반의 refinement 단계를 포함합니다. 이러한 후처리 과정을 통해 정확도를 높일 수 있으나, 연산량이 증가하여 실제 활용 측면에서는 과도한 후처리 연산을 줄여야 합니다. 따라서 저자들은 MPS의결과를 PnP로 넘기기 전에 고품질의 landmark 예측 결과를 선별합니다.
이미지 I 로부터 high-precision keypoint head의 예측 landmark 집합을 \{ x_i \} 라 하고, mid-precision keypoint head의 예측 landmark 집합을 \{ x_i^m \} 라 할 때, 아래의 식 (2)를 통해 조건에 해당하는 landmark를 선택하여 PnP의 해를 구합니다. 즉, high-precision 예측 결과를 mid-precision 예측 결과를 이용하여 검증하는 것입니다.
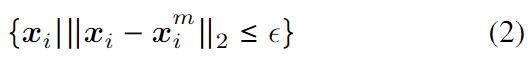
- \epsilon : 검증을 위한 임계값
- 만일 임계값을 넘는 x의 개수가 4개 미만일 경우, ||x_i -x_i^m||_2가 작은 값부터 4개 선택
Experiments
본 논문에서 제시한 ROPE를 검증하기 위해 RGB 이미지 기반의 pose estimation 방식의 SOTA 방법론들과 비교를 수행합니다.
Datasets and metrics
[Datasets]
- LINEMOD
기존 연구들과 동일한 설정을 이용.- 15% 학습, 85% 테스트
- 이미지들 사이의 rotation 값이 임계치 이상인 데이터들로 학습 데이터 선택
- 각 객체에 대하여 1312개의 렌더링 이미지를 추가로 사용
- Occluded-LINEMOD
전체 set을 test로 이용. LINEMOD 데이터(각 object 이미지와 렌더링 이미지)를 학습에 사용 - YCB-Video
기존 연구의 세팅을 따름.- 92개의 비디오 시퀀스 중 80개와 8만개의 합성 이미지를 학습에 이용
- 남은 12개의 sequence에서 2949개의 key frame을 테스트에 이용
[Meetrics]
- ADD(-S) metric
- 비대칭 객체에 대해 ADD, 대칭 객체에 대해 ADD-S를 계산
- ADD metric은 pose의 정확도를 추정하기 위해 GT pose와 예측된 Pose만큼 object 모델을 변환시킨 후, 각 point들 사이의 거리를 측정하여 object 모델의 직경에 10% 미만의 평균 오차를 가질 경우 제대로 예측한 것으로 판단하며,
- ADD-S는 대칭적인 객체에 대해서는 가까운 점을 기준으로 point 오차를 계산함
- AUC metric
- ADD(-S)의 임계값 변화에 따른 그래프를 그려 곡선의 아래 영역을 계산함
- 임계값은 0~10cm까지 변화함
Ablation studies
제안한 OBA와 MPS의 효용을 확인하기 위한 실험을 진행합니다.
a. Model variations
평가를 위해 2개의 변형 모델을 만듭니다.
- MV1: w/OBA w/o MPS
원래의 ROPE에서 low/mid-precision keypoint head를 졔거하고 단일 head인 high-precision keypoint head만을 이용 - MV2: w/o OBA w/o MPS
MV1 모델에 추가로 OBA를 사용하지 않고 학습

위의 그림5는 Occluded-LINEMOD에 대한 평균 ADD(-S)와 정성적 결과를 나타냅니다. OBA와 MPS모두 사용하지 않을 경우 occlusion에 민감하게 반응하여 pose를 잘 추정하지 못하며, landmark prediction 결과도 불안정해지는 것을 보였습니다.(1행) 이를 통해 OBA가 occlusion에 강인하게 landmark를 예측할 수 있다는 것을 보였습니다.(1행2행 결과 비교) 또한 MV1 결과를 original 결과와 비교해보면 occlusion이 발생했을 때 구조적으로 더 정확하게 예측하는 것을 확인할 수 있습니다. (MV1 결과는 ape에서 유인원 피규어와 구조가 맞지 않으며, cat에서도 꼬리 형태에 집중하여 보면 구조가 맞지 않다는 것을 확인할 수 있습니다.) 이를 통해 저자들은 MPS에 전체적인 representation이 가능하여 occlusion이 발생해도 landmark 예측 결과가 향상되었다고 주장합니다.
b. Accuracy and coherence of landmarks
저자들은 MPS의 효과를 정량적으로 확인하기 위해 landmark 예측 정확성과 구조적 일관성을 정량화하고 비교하였습니다. 정확성은 아래의 식(3)으로 정의하였으며, 불일치에 대한 척도는 아래의 식(4)로 정의하였습니다.
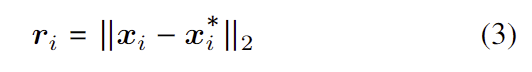
- 2D landmark에 대한 잔차
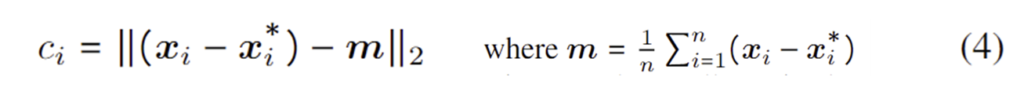
- 예측된 landmark에 대한 평균 오차와의 차이
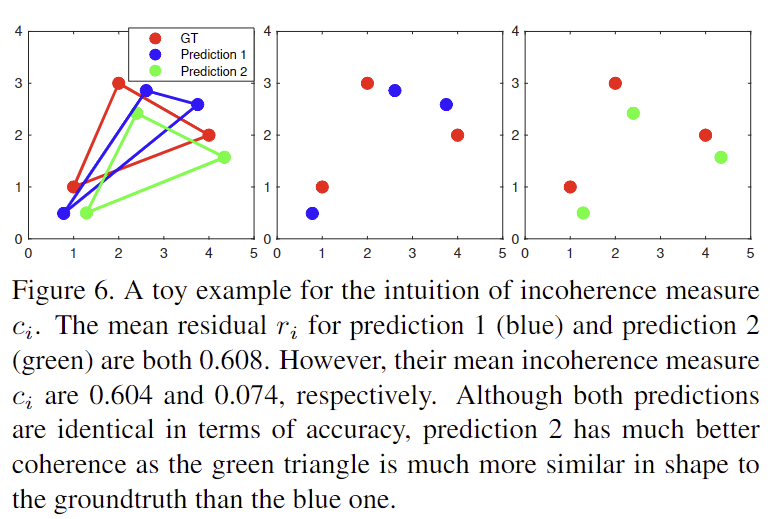
- c_i가 작을수록 예측 결과 x_i가 일관적이며 구조도 일관적 (아래의 그림6을 통해 예시 확인 가능)
- MPS를 적용함으로써 평균 잔차가 주었음을 아래의 그림 7에서 확인 가능
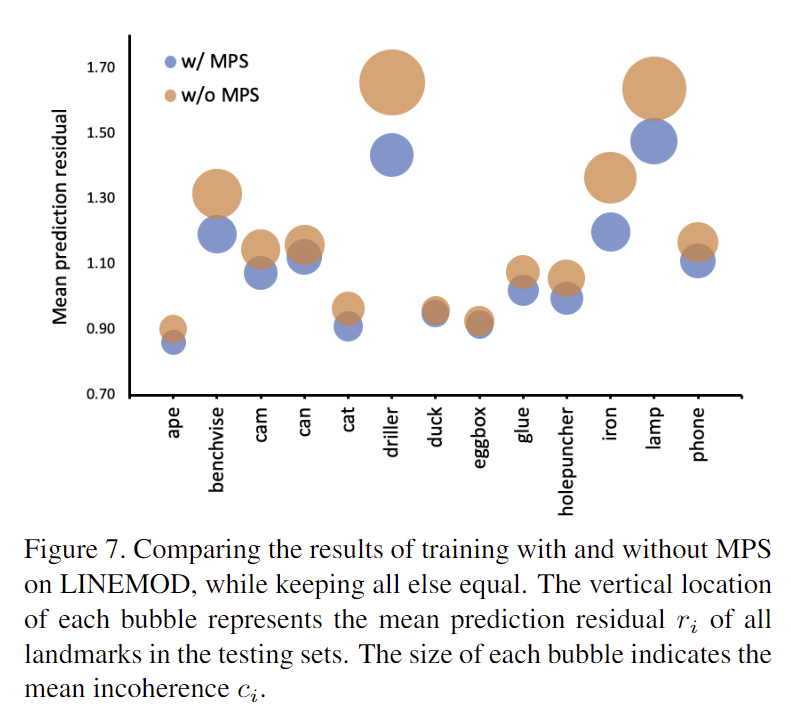

SOTA와 비교 실험
- LINEMOD에 대한 결과
refinement 유무에 따라 2개의 그룹으로 구분하여 Table 1에 리포팅하였으며, ADD(-S)에 대해 대부분의 객체에서 SOTA, 평균적으로도 최대성능을 달성하였다(glue만 약간 낮은 성능). 무엇보다 refienment를 수행한 방법론들보다 더 좋은 성능을 보여 ROPE의 정확도가 좋음을 보였다.
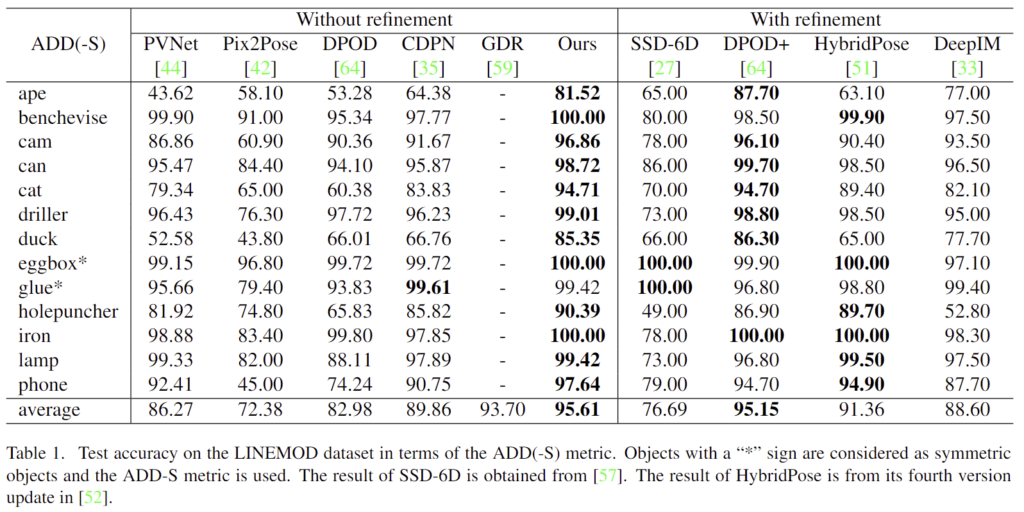
- Occluded-LINEMOD
마찬가지로 refinement 유무로 구분하였으며, Table 2에 결과를 리포팅하였다. SOTA 방법론과 비교하였을 때 2번째로 우수한 성능을 보입니다. GDR보다 성능이 낮은 이유에 대한 분석이 포함되어있지 않아습니다. Occlusion에 강인한 방법론을 제시한 만큼, occluded-LINEMOD에서 GDR보다 성능이 낮은 이유에 대한 분석이 포함되어있어야 한다고 생각하여, 해당 부분에 대한 분석이 없는 것이 아쉽습니다…
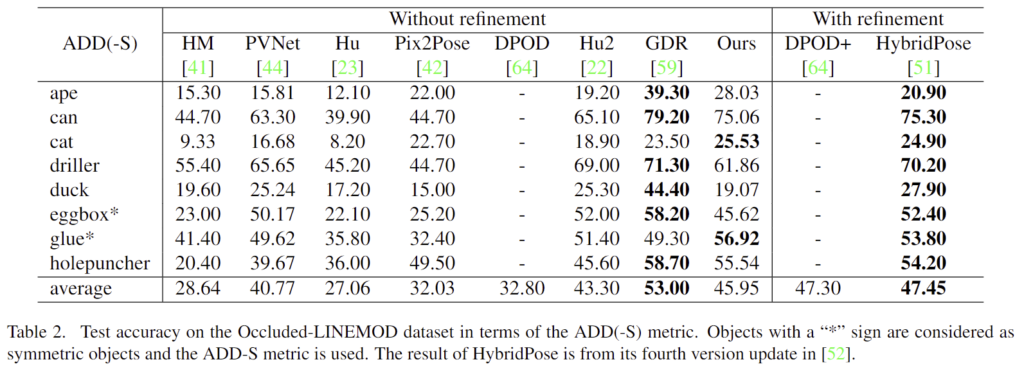
- YCB-Video
Table 3에 YCB-Video에 대한 결과를 리포팅하였습니다. ADD(-S) metric에 대해 refinement를 수행하지 않은 방법론들에 비해 좋은 성능을 보이는 것을 확인하였습니다. 그러나 YCB-Video에 대해 많이 사용하는 AUC of ADD(-S) metric에서는 refinement를 사용하지 않은 경우에서 SOTA 성능이 아니며 이에 대한 분석도 없어서 더 아쉽습니다….
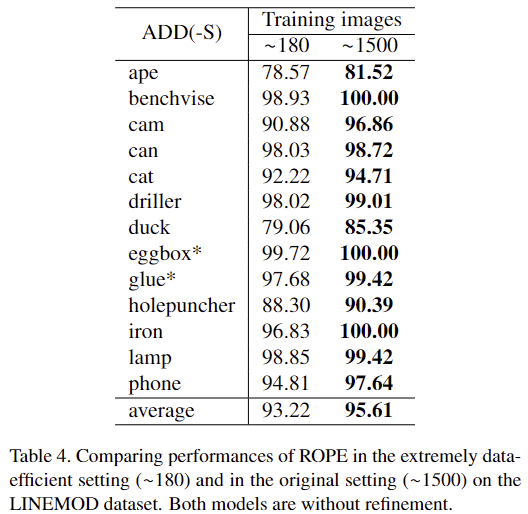
Data efficiency
LINEMOD 데이터는 각 객체에 대하여 약 1200장의 이미지가 존재하며 이중 약 15%인 180여장의 이미지를 학습에 이용합니다. 학습 데이터가 적다는 문제를 해결하고자 많은 방법론이 합성 데이터를 생성하며, 저자들도 약 1312장의 합성데이터를 생성하여 이용하지만, 데이터 효율성을 평가하기 위해 학습 과정에 약 180장의 이미지만을 사용하여 평가를 진행하였습니다. 아래의 Table 4에서 확인할 수 있듯이 기준 방식보다 약간 낮은 ADD(-S) 성능을 보이지만, 그럼에도 불구하고 SOTA 알고리즘인 GDR 방식의 성능인 93.7%에 가까운 93.22%의 정확도를 보이는 것을 확인하였다. 이를 통해 저자들의 방식이 적은 데이터로도 잘 작동하는 데이터 효율성이 높다는 것을 실험적으로 보였습니다.
Conclusion
ROPE 프레임워크를 제안하여 occlusion에 강인한 pose estimation 방식을 제안하였습니다. occlusion에 강인하도록 학습하기 위해 OBA augmentation 방식을 제안하였으며, MPS 구조를 통해 전체적인 pose representation을 학습할 수 있도록 하였고, 3가지 벤치마크에 대한 평가를 통해 refinement를 수행하지 않아도 좋은 성능을 보이는 것을 확인하였고, 추가로 데이터 효율성도 높다는 것을 실험적으로 보였습니다.
좋은 리뷰 감사합니다!!
몇가지 질문 남기고 갈게요!
1. Bbox를 기준으로 OBA를 수행한다고 이해했습니다만 그림 3의 예시는 bbox에 fit 시킨건 아닌 것 같이 그려져서 헷갈립니다. 조금 더 자세하게 설명 부탁드립니다!
2. 읽다보니 헷갈리는 부분이 해당 기법은 2d-3d 기반의 방식이지 않나요? 2d-3d 간 특성은 어디서 배우는 걸까요?
안녕하세요 승현 연구원님!
좋은 리뷰 감사합니다.
정말 이해하기 쉽게 잘 써주셔서 이해하는 데 도움 많이 받고 갑니다!
궁금한 게 하나 있는데요 occlude-blackout augmentation에서 물체에 대한 바운딩 박스 바깥에 있는 background에 대해 전체를 black out 시켜서 배경으로 부터 영향을 덜 받게 하는데 이게 자세를 추정하고자 하는 그 물체 자체에 대해서 집중하도록 하기 위함이라고 이해하면 될까요?
감사합니다.
질문 감사합니다.
Occlude-and-blackout batch augmentation 과정은 occlusion에 강인하도록 하는 게 목적이다보니, 물체 자체에 집중하기 위한 의도도 있지만, 인위적으로 occlusion과같이 물체의 일부 영역이 보이지 않는 데이터를 만들어 학습한 것으로 이해하였습니다.