안녕하세요, 열여덟번째 x-review 입니다. 이번 논문은 2023년도 CVPR에 게재된 CompletionFormer으로 컨볼루션과 트랜스포머를 함께 사용하는 Depth Completion 논문 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
현재 상용 깊이 센서로 널리 사용되고 있는 Kinect나 RealSense가 제공하는 depth map은 아직까지 노이즈가 존재하며 특히나 투명한 물체나 빛이 있는 곳, 혹은 어두운 곳으로 갈수록 노이즈의 정도는 심해지게 됩니다. 이러한 문제를 해결하기 위함이 depth completion으로 sparse하게 주어지는 depth map을 그에 대응하는 RGB 영상을 사용하여 완전한 depth map을 얻고자 하였습니다. depth completion에서 중요한 것은 누락된 픽셀 주변에서 유효한 값을 가지는 픽셀의 depth 값과의 유사성을 측정하는 것 입니다. 그러나 주어지는 depth map이 매우 sparse해서 유사성을 측정할만큼 주변 픽셀이 충분하지 않을 수 있기 때문에 로컬 뿐만 아니라 글로벌한 관점에서 픽셀 간의 공간상의 관계를 파악하고, 매우 멀리 있는 depth map 중에서도 유효한 값이 있다면 이웃 픽셀에서의 값과 융합하여 사용할 수 있는 방법이 필요한 상황 입니다.
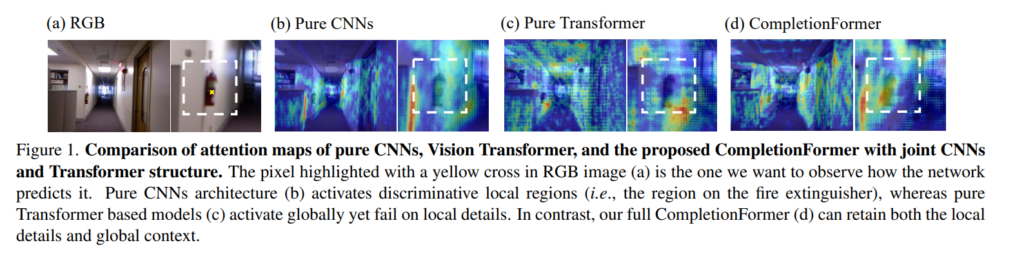
지금까지의 depth completion 방법론들은 보통 CNN이나 GNN을 사용하여 context한 정보를 얻고자 하였는데, 특정 사이즈의 커널을 사용하는 컨볼루션 레이너나 KNN 기반의 이웃을 가지는 그래프 모델의 경우 모두 오로지 local한 영역 내의 정보만을 가지면서 글로벌한 long range의 정보를 얻기에는 한계가 있습니다. 그래서 최근에 GuideFormer에서 transformer를 통해서 global한 특성을 얻을 수 있는 구조를 제안했지만 해당 구조는 또 반대로 vision trnaformer는 한개의 단계를 통해서 이미지 패치를 벡터를 변환시켜 로컬한 정보를 손실할 수 있다는 것 입니다. 이렇듯 단순하게 CNN/transformer을 따로 사용해보니 각각의 한계점을 Figure1과 같이 발견했고 유효한 depth 값이 어떤 거리에 분포되어 있든지 간에 CNN과 transformer을 융합해서 찾으면 로컬/글로벌 정보를 모두 사용하여 depth completion을 할 수 있을텐데 아직까지 그러한 연구가 depth completion에서는 진행되지 않았다고 합니다.
그래서 본 논문에서 CNN 기반의 로컬한 특징과 트랜스포머 기반의 글로벌한 특징을 결합하여 보다 향상된 depth completion을 수행할 수 있는 피라미드 구조의 CompletionFormer을 제안하게 됩니다. 해당 모델을 설계하면서 저자가 부딪친 두 가지 문제가 있었는데 먼저 RGB와 depth 입력 영상 사이의 도메인 차이가 발생했다고 합니다. 그래서 네트워크 초반 단계에서 두 영상 정보를 임베딩하는 것을 제안하여 하나의 브랜치로 구성된 구조로 멀티 모달의 입력 정보를 다룰 수 있도록 하였습니다. 그리고 또 하나의 문제는 CNN과 트랜스포머를 통합하는 과정에서 발견한 두 구조의 근본적인 차이점이었습니다. 두 구조를 융합하는 다른 task(이미지 분류, 물체 검출)에서는 여러가지 관점에서 이미 연구가 진행되며 SOTA를 달성하곤 했지만 이러한 네트워크 구조를 depth completion에 직접적으로 적용하게 될 경우 높은 계산 비용과 낮은 성능을 보여준다고 합니다. depth completion에서도 높은 성능으로 끌어올리기 위해서 self attention과 컨볼루션을 함께 사용하는 것은 효과적이라는 것이 자명하기 때문에 저자는 컨볼루션에서 attention과 트랜스포머를 하나의 블럭에 합치고 이를 멀티 스케일로 설계하여 모델 구조의 basic unit으로 사용하고자 하였습니다. 그리고 트랜스포머에서는 피라미드 비전 트랜스포머의 구조에서 space reduction attention을 가져와 사용하여 트랜스포머 레이어를 경량화하였습니다. 대신 컨볼루션과 트랜스포머의 semantic한 차이가 크기 때문에 트랜스포머로 인해서 로컬한 정보가 손실될 수 있기 때문에 이를 보완하기 위해서 컨볼루션 레이어의 크기를 키워야 했기에 spatial과 channel attention을 추가적으로 도입하였습니다. 그 결과 추가적인 모듈 없이 컨볼루션과 트랜스포머 구조에서 얻을 수 있는 로컬/글로벌 정보를 모두 얻을 수 있었으며 하나의 블록에서 각 정보를 합치는 과정이 효과적으로 이루어질 수 있었습니다.
여기서 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 비전 트랜스포머와 컨볼루션 레이러를 하나의 블럭으로 합쳐 멀티 모달의 입력 정보에서 로컬 & 글로벌한 정보를 모두 사용하여 depth completion이 가능한 네트워크 구조 제안
- Joint Convlutional Attention and Transformer (JCAT) 블럭을 모델의 basic unit으로 설계하여 하나의 브랜치로 연결되어 있는 구조를 설계하여 현재 CNN/트랜스포머 기반 방법론보다 계산 비용이 줄어들고 효율적이라는 장점
- 매우 sparse한 depth map 입력이 들어오더라도 높은 성능을 보이며 depth copletion 데이터셋에서 SOTA 달성
2. Method
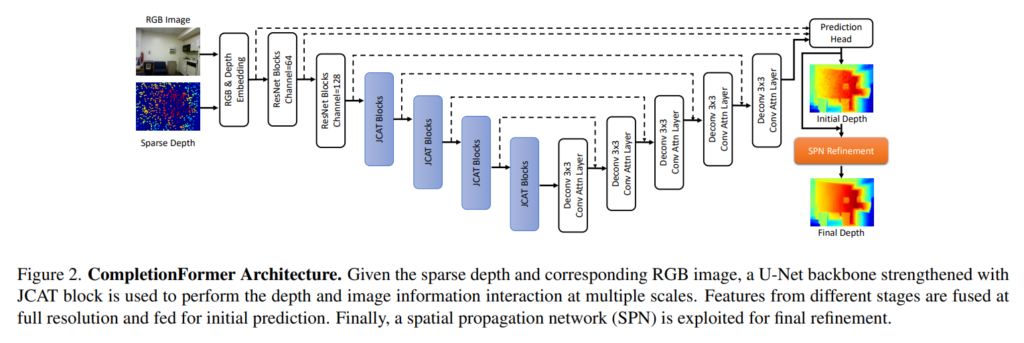
본 논문의 목표는 introduction에서도 이야기하였듯이 depth completion을 함에 있어서 유효한 depth가 존재하는 픽셀의 위치가 어디에 있든 상관없이 로컬/글로벌 정보를 모두 사용할 수 있는 구조를 설계하는 것 입니다. 전체적인 구조는 Fig2와 같으며 RGB와 depth 이미지를 임베딩하고 설계한 JCAT 블럭으로 구성된 백본을 통해 초기 depth를 예측하기 위한 특징을 추출하고 SPN(patial propagation network)를 통해 초기 예측 depth map을 refine하는 과정으로 이루어져 있습니다.
3.1. RGB and Depth Embedding
먼저 depth completion에서 멀티 모달 정보를 네트워크의 초기 단계에 합칠 경우에는 2가지 장점이 존재하는데 먼저 각 픽셀에 대한 정보에 RGB와 depth에서 얻은 정보가 모두 포함되어 있어 잘못된 값으로 측정된 픽셀에 대해서 유사도에 따라 유효한 값을 가지는 depth로 조정될 수 있습니다. 두번째는 정보를 합친 이후부터는 하나의 브랜치로 네트워크를 설계할 수 있어 더 효율적이어진다는 것 입니다. 그래서 sparse depth map과 RGB 이미지를 인코딩하기 위한 두 개의 독립적인 컨볼루션을 사용한 후에 두 출력값을 연결하여 또 다른 컨볼루션 레이어를 통과하게 하여 두 도메인의 정보가 모두 포함되어 있는 raw feature을 얻을 수 있습니다.
3.2. Joint Convoltional Attention and Transformer Encoder
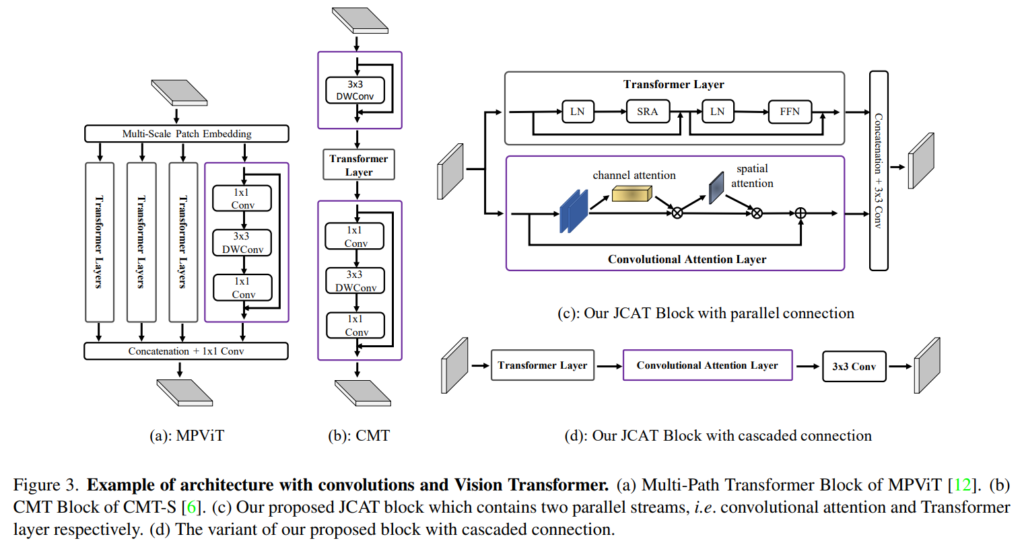
컨볼루션과 트랜스포머 구조를 융합하기 위해서 이미지 분류와 물체 검출 task에서는 Figure3의 (a), (b)와 같이 self attention과 컨볼루션을 합친 MPViT와 CMT 구조를 설계하였습니다. 일반적으로 융합은 두 구조를 병렬적으로 구성하거나 cacade 형식으로 구현할 수 있는데 이러한 설계를 기반으로 CompletionFormer에서도 Figure3의 (c), (d)와 같이 두 가지의 구조를 제안하고 있습니다. 계산 비용을 줄이면서도 정확한 depth completion 결과를 위해서 MPViT에서처럼 트랜스포머 기반의 구조를 여러개의 경로로 만들지는 않고 단일 경로로 포함시켰고 컨볼루션 기반의 구조는 spatial-channel attention을 통해서 표현력을 높이고자 하였습니다. 또한 본 논문의 인코더는 다섯 단계로 이루어져 있는데, 첫번째 다계에서는 트랜스포머 레이어에서 발생하는 계산, 메모리 비용을 줄이기 위해서 ResNet34 구조를 사용하여 해상도가 1/2로 줄어든 feature map F_1을 출력값으로 받게 되고 그 다음 4개의 단계는 basic unit으로 제안하는 JCAT 블록으로 이루어져 있습니다. 첫번째 단계를 제외하고 각 단계에서 (i \in \{2, 3, 4, 5\}) 패치 임베딩 모듈과 JCAT 블록으로 구성되어 있습니다. 패치 임베딩 모듈은 이전 단계(i -1)의 feature map(F_{i-1}을 2×2 크기의 패치로 나누고 kernel size는 3×3, stride를 2로 설정하여 실제로 F_{i - 1}은 해상도가 절반으로 감소하고 본래 입력 이미지 대비 해상도가 \{1/4, 1/8, 1/16, 1/32\}인 피라미드 형태의 feature map \{F_2, F_3, F_4, F_5\}를 얻을 수 있습니다.
이제 JCAT 블록이 무엇인지에 대해 알아보자면, 우선 Figure3의 (c)와 (d)처럼 병렬식 또는 cascade 방식 두 가지에서 선택적으로 구성할 수 있습니다. 트랜스포머 레이어는 multi head 구조의 spatial-reduction attention (SRA) 레이와 FNN로 이루어져 피라미드 비전 트랜스포머 구조를 활용하여 효율적인 구조를 따르고자 하였습니다. 해당 블럭으로 이전 단계에서의 feature map F \in \mathbb{R}^{H_i \times W_i \times C}가 입력으로 들어오면 Layer normalization으로 feature map을 벡터 토큰인 X \in \mathbb{R}^{N \times C}으로 flatten하게 됩니다. 여기서 N은 토큰의 수인데 H_i \times W_i와 크기가 같으니 즉 F의 모든 픽셀 수를 의미하게 되겠죠. 이제 linear transformation W^Q, W^K를 이용하여 토큰 X를 쿼리 Q, 키 K, 벡터 V에 투영하는데 여기서 메모리 비용을 줄이기 위해서 K와 V의 spatial 스케일을 줄인 다음에 식(1)과 같이 self attention을 계산하게 됩니다.
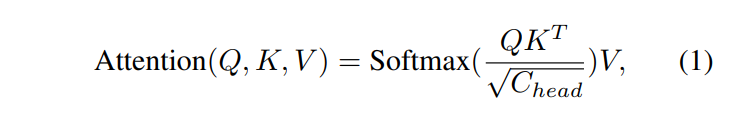
- C_{head} : SRA에서 각각의 attention 헤드의 채널 차원
식(1)에 따르면 전체 입력 feature mapF의 각 토큰은 자신을 포함한 모든 토큰과 matching 되는데 이러한 self attention이 depth completin에서는 네트워크의 receptieve field를 각 트랜스포머 레이어에서 전체 이미지로 확장할 수 있고 attention이 진행되는 각 토큰이 depth와 RGB 이미지 정보를 모두 포함하고 있기 때문에 self attention은 각 픽셀의 유사도를 appearance 측면 뿐만 아니라 내적 계산을 통해서 depth와도 비교할 수 있게 됩니다. 따라서 전체 이미지의 영역에 이르는 유효한 depth 정보를 얻을 수 있어 잘못 측정된 픽셀의 값을 재할당할 수 있는 것 입니다.
이제 컨볼루션 레이어를 살펴볼텐데요, 컨볼루션 레이어에서는 channel과 spatial attention을 통해서 CNN의 표현력을 향상시키고 로컬한 영역에 대해서 정확한 attention이 가능해지며 노이즈를 줄이고자 하였습니다. 뿐만 아니라 이러한 attention을 컨볼루션과 트랜스포머의 semantic한 차이 관점에서 생각해보면 attention을 통해서 컨볼루션 레이어의 모델링 용량이 커지게 되어 컨볼루션 레이어 경로가 트랜스포머에서 제공하는 중요한 정보에 집중하면서 불필요한 정보를 억제할 수 있게 됩니다. 이렇게 컨볼루션과 트랜스포머 경로를 거친 특징을 3×3 컨볼루션 레이어로 합쳐서 다음 블록 혹은 단계로 보내는 과정을 반복하게 됩니다.
3.3. Decoder
디코더에서는 각 인코더 레이어의 출력을 skip connection을 통해서 해당 디코더 레이어로 연결됩니다. 여러 스케일의 feature map을 이용하기 위해서 이전 디코더 단계의 특징을 현재 디컨볼루션 단계에서 사용하기 위해 현재 스케일로 업샘플링하고 컨볼루션 self attention을 활용하여 channel-spatial 차원에서의 특징을 융합하는데 도움을 주고자 하였습니다. 마지막으로 디코더까지 거친 최종 예측 결과는 1단계의 ResNet34의 출력 결과, 그리고 RGB와 depth의 임베딩 모듈의 raw feature와 합쳐져prediction head의 입력으로 들어가게 됩니다.
3.4. SPN Refinement and Loss Function
prediction head를 거친 결과로 completion된 depth map이 출력되지만 당연하게도 무조건 정확에 가까운 depth 값으로 보완되지 않을 수도 있습니다. 이러한 경우를 고려하여 spatial propagation 네트워크(SPN)로 보통 refinement를 진행한다고 합니다. 최근 연구로는 주로 이 spatial propagation 네트워크를 고정된 로컬 영역에서 로컬하지 않은 영역으로의 propagation이 될 수 있도록 설계하는 것을 중점적으로 진행된다고 합니다. SPN 중에 보편적으로 사용되는 네트워크가 CSPN++인데 해당 모델은 계산 비용이 많이 소모되기 때문에 non-local spatial propagation 네트워크(NLSPN) 구조를 refinement에 사용하였다고 합니다.
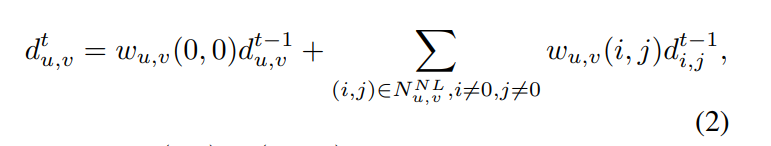
- D^t = (d^t_{u, v}) \in \mathbb(R)^{H \times W} : t 단계에서 spatial propagation에 의해 업데이트된 2D depth map
- d^{t-1}_{u,v} : 픽셀 (u,v)의 depth 값
- w_{u,v}(i,j) : w_{u,v}(i,j) \in (-1,1), 기준이 되는 픽셀 (u,v)와 그 픽셀의 이웃 픽셀인 (i,j)의 유사도 가중치
- w_{u,v}(0,0) = 본래 깊이인 d^{t-1}_{u,v}가 얼마나 보존되는지
식(2)는 local이 아니라고 정의된 픽셀 N^{NL}_{u,v}와 단계 t에서 d^t_{u,v}의 propagation을 정의합니다. 유사도 가중치인 w는 디코더에 의해서 출력이 되는 값인데 디코더의 예측 confidence map에 의해서 변형되어서 유사도가 얼마나 큰지와는 상관없이 confidence가 낮은 픽셀이 이웃으로 propagation되는 것을 방지하기 위해 사용합니다. K 단계까지 propagation이 끝나면 최종적으로 refine된 depth map인 D_K를 얻을 수 있고 최종적으로 L1과 L2 loss를 합친 loss인 식(3)을 계산하여 네트워크 학습이 이루어지게 됩니다.
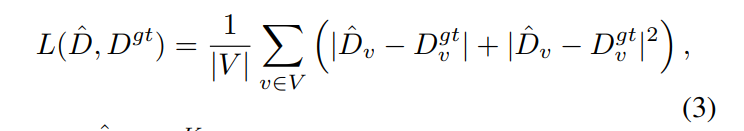
- \hat{D} = D^K : refine network까지 거쳐 예측한 Depth map
- V : D^{gt}에서 유효한 값을 가진 픽셀의 집합
3. Experiments
3.1. Comparison with SOTA Methods
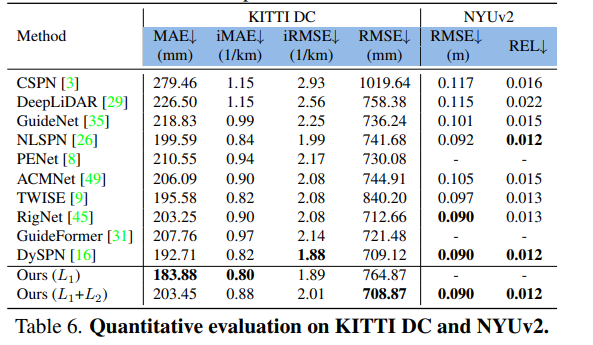

먼저 이전 SOTA 모델과의 비교 실험을 진행하였는데, 사용한 데이터셋은 NYUv2와 KITTI depth completion 데이터셋 입니다. 먼저 NYUv2에서는 가장 높은 성능을 달성한 것을 확인할 수 있습니다. KITTI 데이터셋의 결과를 보면 4개의 평가 메트릭 중 L1 loss만을 사용하였을 때는 MAE와 iMAE에서 가장 좋은 결과를 얻었고 논문에서 설명하였던대로 L1과 L2 loss를 함께 사용하였을 때는 RMSE에서 가장 높은 성능을 보이고 있습니다. Figure5는 KITTI 데이터셋에서의 정성적인 depth map 결과로 컨볼루션과 트랜스포머 구조를 모두 사용함으로써 두번째, 네번째 행에서 확인할 수 있듯이 depth가 없거나 텍스처 정보가 없었던 물체, 혹은 멀리 떨어진 기둥과 나무 줄기 같이 매우 작은 물체에 대해서 더 나은 성능을 나타내는 것을 확인할 수 있습니다.
3.2. Ablation Studies and Analysis
NYUv2 데이터셋에서의 ablation study 결과 입니다.
Cascade vs Parallel Connection
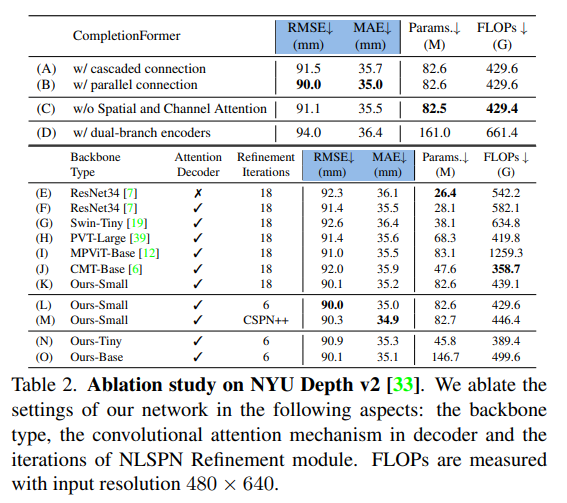
Table2의 (A), (B)는 method 파트에서 JCAT 구조를 병렬적으로 만들거나 cascade로 구성할 수 있다고 하였는데 두 구조 사이의 성능 차이를 보여주는 실험 입니다. 표에서 알 수 있듯이 cacade가 병렬 구성에 비해 성능이 낮은 것을 볼 수 있는데 이는 (I), (J) 비교 실험에서 CMT 기반이 MPViT 기반보다 RMSE가 떨어지는 것과 동일한 경향성을 보여주고 있습니다. 병렬로 구성하는 것이 depth completion에서 서로 다른 특징 정보를 가진 두 stream 간의 상호 작용에 있어서 더 적절한 구조라고 분석할 수 있을 것 같습니다. 해당 실험의 결과에 따라 최종 구조는 병렬 형태를 선택했다고 하네요.
Spatial and Channel Attention in JCAT block
(c)는 CompletionFormer에서 JCAT 블럭의 컨볼루션 레이어에 spatial channel attention을 추가했다고 하였는데 그러한 부가적인 attention 없이 일반적인 컨볼루션와 트랜스포머를 합쳤을 때 성능 드랍이 얼마나 일어나는지를 확인하기 위한 실험 입니다. 일반 컨볼루션만 사용했을 때 RMSE가 90.0에서 91.1로 증가하는 것을 통해 두 구조를 합칠 때 컨볼루션의 용량을 늘리는 것이 중요하다는 결과를 도출할 수 있다고 합니다. (비록 FLOPs가 미세하게 증가하지만 이는 무시할 수 있을만한 정도이기에 용량을 늘리는 것이 더 적합하다고 합니다.)
Single or Dual branch Encoder
본 논문에서 꽤나 강조하였던 단일 브랜치 구조의 영향을 증명하기 위한 실험 입니다. (D)가 RGB와 depth 정보를 별도로 인코딩하는 dual 브랜치 구조로 구성하여 테스트하였는데 두 브랜치 간에 특징 정보를 얻기 위해서 브랜치의 끝에 spatial channal attention을 포함하였습니다. 그러나 단일 브랜치 구조(B)에 비해서 좋지 않은 결과를 보였는데, 이는 네트워크의 초기 단계에 멀티 모달 입력으로 오는 정보를 함께 포함하여 전달하는 본 논문의 최종 구조가 훨씬 효과적이면서 효율적인 구조라는 것을 강조할 수 있는 결과라고 볼 수 있습니다.
좋은 논문 리뷰 감사합니다.
몇 가지만 질문하고 갈게요!
1. 초기 레이어에서 두 모달을 합치는 장점이 잘못된 값에 유사도에 따라 유효한 값으로 조정될 수 있다고 하셨는데 주장만 펼치기에는 받아들이기 힘든 주장인 것 같습니다… 저자가 따로 뒷받침 할 수 있는 자료들을 제시했을 것 같은데 혹시 있나요?
1-1. 그리고 기존 깊이 보완 연구에서은 입력으로 들어간 깊이 정보 중 이미 존재하는 값들에 대해서는 loss 계산을 수행하지 않는 경우가 많습니다. 해당 기법은 모든 값에서 loss를 계산하는 것 일 까요?
2. 깊이 보완 연구들에서는 대부분 깊이 정보에 대해 전처리 과정을 진행합니다. 해당 기법은 어떤 전처리를 수행했나요?
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. 본 논문에서는 두 모달리티의 정보를 초기 레이어에서 합치는 것의 장점을 ablation study의 single or dual branch Encoder 실험으로 보여주고 있는데요, 저자가 말하기를 두 모달리티의 특징을 따로 인코딩할 경우에는 추가적인 spatial channel attention을 추가함에도 불구하고 하나의 브랜치로 인코딩할 때보다 성능이 낮다는 것을 보여주면서 초기 단계에 두 정보를 임베딩하는 것이 훨씬 효과적이라고 이야기하고 있습니다.
1-1. 제가 이해하기로는 gt를 기준으로 gt에서 존재하는 값들의 픽셀에 대해서는 모두 로스를 계산하고 있습니다.
2. 전처리 과정이 정확히 어떤걸 말씀하시는지 제가 이해를 잘 못 했습니다만 .. 해당 논문에서 전처리에 대한 언급은 없었습니다.
감사합니다.
좋은 리뷰 감사합니다.
depth completion 과정에 유효한 depth 정보를 local/global 관점에서 모두 고려하고자 새로운 구조를 제안한 것으로 이해하였습니다.
해당 논문과 관련하여 몇가지 질문이 있습니다.
1. RGB와 Depth 정보를 초기에 합칠 경우, 잘못 측정된 픽셀에 대해 depth로 조정이 가능하다고 하셨는데,
depth가 정확하게 작동하고 RGB 이미지가 잘작동하지 않는 경우는 어떤 경우가 있을 지 궁금합니다.(빛 반사가 이에 해당하나요..?? 그렇다면 해당 논문에서 이야기하는 depth는 ToF 방식의 depth만을 의미하는 것인지 궁금합니다..)
또한, 오히려 잘못된 픽셀 정보를 depth가 보완하는 것이 아니라 depth에도 악영향을 끼칠 수 있을 것으로 보이는데,
저자들은 이를 어떻게 판단하였는지 근거가 궁금합니다.
2. 또한, JCAT 구조를 병렬적이나 cascade 방식으로 구성할 수 있다고 하셨는데 실험적으로 cascade 방식에서 더 좋은 성능을 보인다고 하셨는데, cascade 방식의 경우 convolutional attention layer가 transformer의 앞이 아닌 뒤에 오는 이유가 궁금합니다. 또한 병렬적으로 구성하는 방식이 cascade 방식으로 구성하는 것 보다 일반적으로 좋은 성능을 보인다는 것으로 이해하였는데, 이는 구조성 어떠한 이유인지 분석이 있는 지 궁금합니다.
안녕하세요. 좋은 리뷰 감사합니다.
refinement를 위해서 SPN을 사용했다고 말씀해주셨는데 이 propagation이라는 것이 실제 픽셀 개념에서 이웃이라고 판단할 수 있는 범위를 넘어선 픽셀들의 depth 정보까지 이용하고 싶은데 그때 무작위로 모든 픽셀을 사용하는 것이 아니라 현재 픽셀과 유효한 관계를 가진 영역들을 선별하기 위해서 사용한다고 이해해도 될까요 . . ? propagation 된다는 것이 정확하게 이해가 되지 않아 추가적인 설명 해주시면 감사하겠습니다.
또, 처음에 ResNet34가 아니라 특별한 이유가 없다면 다른 백본을 사용해도 된다고 생각이 드는데 혹시 다른 백본 네트워크를 이용한 ablation study는 없었나요??
마지막으로 실험에서 사용한 평가 메트릭에 대한 질문인데 RMSE/iRMSE처럼 앞에 i가 붙은 것은 어떤 차이가 있으며 REL이라는 메트릭은 어떤 기준으로 평가하는 것인지 궁금합니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
propagation이라는 것은 depth를 주변 픽셀로 전파하는 작업으로 depth completion을 수행하는 원리가 주변 픽셀 값의 정보를 이용하게 되는데 이때 local 영역이라고 해서 무조건적으로 completion에 도움을 주는 것도 아니고, 멀리 있는 픽셀이라고 해서 completion에 영향을 미치지 않는 것이 아니므로 상관관계가 낮은 local 픽셀은 피하면서 유효한 값을 가지는 non local한 픽셀이 있다면 집중할 수 있도록 하는 것이 본 논문에서 refinement로 사용하는 NLSPN의 핵심 내용 입니다.
그리고 백본 네트워크에 대한 ablation study가 Table2에 (E)-(J)까지의 실험인데요, pure한 CNN과 트랜스포머 구조, 그리고 기존의 CNN+트랜스포머 구조를 가진 백본 네트워크와의 비교 실험을 진행했는데 본 논문의 방법론이 가장 높은 성능을 보였다고 합니다.
마지막으로 i가 붙은것은 기존 메트릭의 inverse 형태를 의미하며 REL은 실제 값과 예측 값 사이의 차이를 구하고 평균을 낸 값으로 작을 수록 두 값 사이의 차이가 작기 때문에 성능이 높다고 평가할 수 있는 메트릭 입니다.
감사합니다.