안녕하세요. 스물 두번째 리뷰입니다. 최근 작성 중인 Pedestrian Detection과는 별도로, 논문은 Few-shot (One or Few) Object Detection에 대한 관한 논문입니다. Few-shot Classification에 관한 연구는 성황리에 있는 반면, Object Detection은 아직 블루오션인데, 그러므로 2018년의 논문에 이어, 2019년 이제 일 년을 넘었네요. 최근 논문 관련 실험 및 중간 고사, 논문 관련 생각 정리 등으로 리뷰 논문을 한동안 읽지 못하였는데, 이번 주에는 “보통의 좋은 논문은 본인의 방법을 어떻게 Selling할까”의 측면에서 논문을 읽다보니, 새로운 면이 보이네요. 내일부터는 다시 논문 작업에 몰두해봐야겠습니다. 참, 처음 쓰려니 많은 분들이 도움을 줌에도 아직은 막막하네요.
1. Introduction
보통의 딥러닝 논문들이 그러하듯, 본 논문이 다루는 Task에 대한 필요성을 언급합니다. 핵심만 써놓은, 혹은 미사여구들을 통해 내용을 자세히 써놓은 논문들도 있지만, 본 논문에서 말하는 Task에 대한 필요성은 후자처럼 보입니다. 논문에 쓰인 말을 인용하며, 설명구로 풀어가보죠. “DNN은 성공을 이루었고, 이제는 어느정도 ‘Feature Extractors of Choic’ 단계 (마치 인공지능 시험에서 Kaggle에 다양한 Pytorch 모델을 불러와 학습 및 평가해보는)에 이르렀다. 그 성공은 데이터로부터 좋은 Feature를 학습하는 능력의 향상이며, 이 때 빼놓을 수 없는 점은 “좋은 데이터”와 동시에, 모델을 처음부터 학습하려면 (또는 Transfer-learning 한다한들 이전에는) 무엇보다 어마무시한 양의 학습 데이터를 필요로 한다는 점입니다.” 줄이면, DNN, CNN과 같은 DL은 Data-Driven Method임을 설명합니다.

이제, Few-shot의 필요성이 나오겠죠? 저자는 다음과 같이 말합니다. “많은 실용적인 측면에서, 몇 클래스들에 대해 Few한 양의 학습 샘플만으로 만족할만한 성능 (분류)이 나옴은 중요하지만, 어렵다.” 전적으로 동의합니다. Serving, Deploy 관점에서는 실용적인 측면을 고려해야하며, 이 때 새로운, 혹은 처음 보는 클래스에 대해 클래스를 분류하려면 기존의 모델은 이전의 클래스만큼의 데이터를 필요로합니다. 데이터가 적다면, Overfitting 될 수도 있고 혹은 극단적으로 한, 두 장의 데이터만 있다면 여전히 Background로 인식 (Weight의 변화에 영향을 주지 못하여)될 수도 있겠죠. 어찌 되었든, CIFAR 100에서 CIFAR 101을 만들려면, CIFAR 100 내 한 클래스에 해당하는 수 만큼의 영상이 있어야 한다는 것은 굉장한 취약점입니다.
그래도 최근의 연구들은 Few-shot learning에 대해, Classification에서의 성능을 많이 끌어올렸습니다. 특히 Few-shot이 중요한 Visual recognition 태스크에서는, Few-shot의 관점이 주된 관심사이죠. 그러나, Few-shot Object Detection에 대한 연구는 활발하지 못합니다. 그 이유는 Object Detection은 Classification 외 Localization을 요구하며, 이 때 Localization에서의 어려움을 극복하고 있지 못하고 있기 때문입니다. 자, 사실 본 논문에서도 Localization을 위한 Novel한 방식이 있느냐하면, 그것은 아닙니다. 2-Stage의 Faster R-CNN 계열의 모델을 통해 RoI에 많이 의존합니다.
그렇지만, 정말 Localization이 어려운지에 대한 의문이 드는 저는 데이터 측면에서 다시 접근해보겠습니다. Classification에 관한 데이터의 경우, 대게는 이미지 내 하나의 인스턴스만 존재합니다. 그리고 해당 인스턴스는 주로 이미지의 중앙부에, 눈에 띄는 사이즈로 존재합니다. 하지만 Object Detection의 데이터는, 인스턴스의 크기가 다양히 변화합니다. 동일한 사람이라해도, 카메라에 가까이 위치하는지, 멀리 위치하는 지에 따라 크게 보일 수도 혹은 작게 보일 수도 있죠. 그렇다면 들어오는 정보도 다를텐데, 이 때 모델은 Few-shot의 경우에도 RoI에서는 “인스턴스가 있음직한 위치”는 어느정도 캐치할 수 있습니다. 하지만 그 인스턴스에 대해서는 정보 양이 차이나다보니, 어떤 클래스인지에 대한 예측은 잘 하지 못합니다. 그렇기에 기존 Few-shot Object Detection은 주로 Faster R-CNN 계열의 모델로, RoI를 통해 들어오는 정보에 대해 Classification을 잘할 수 있는 방법을 고안합니다.
그렇다면 다시, Localization보다 Classification이 문제인 것일까요? 사실 위에서 말한 해당 인스턴스들은 주로 이미지의 중앙부에, 눈에 띄는 사이즈로 존재한다는 말을 돌려 말하면, 다른 말로는 Background에 대한 정보는 많지 않다는 것 입니다. 하지만 Detection에서는, Background를 Foreground와 구분해야하는 점이 핵심이죠. 또한 Background는 Foreground에 비해 Pixel 단위로 보아도 그 수가 훨씬 많습니다. 물론 위에서 말한 바와 같이 RoI가 이를 어느정도 해결해주지만, Query object가 항상 비슷한 형상을 가지지는 않기 때문에, 불확실성이 높은 예측을 보입니다. 종합하여 하고자 하는 말은, Few-shot Object Detection의 미사여구가 항상 “Localization이 어렵다”고 말하지만, 실제로는 Classification도 큰 문제라는 점입니다. 만약 Localization이 어렵다는 점을 말하고자한다면, 2-Stage보다는 1-Stage Detector를 사용할 때 이를 설명한다면 더욱 설득력이 있을 것으로 보이네요. 논문 작업하다보니 이런 점들도 보입니다.
이제 논문으로 돌아와, 저자는 Distance Metric Learning (DML)을 활용한 접근법을 보이고 Classification과 Detection 모두에서 성능적 효과를 보입니다. DML에 대해 간략히 설명하자면, Input 데이터들에 가장 적합한 형태의 Embedding space를 만드는 distance 기반 학습 알고리즘입니다. 주로 사용되는 Face recognition 태스크를 예로 들면, N차원의 데이터에서 동일 데이터끼리는 비슷한 Embedding space에 위치하게끔, 다른 데이터끼리는 구분되는 Distance를 갖도록 학습하는 방법입니다. 이렇게 설명하면, 지금쯤 Constrative learning이나 Tripplet loss가 생각나겠네요. 그 중 Tripplet loss가 DML의 핵심입니다. 이후 방법론에서 말하겠지만, 미리 소개하자면 저자는 Multi-mode (<-> Uni-mode: 하나의 Peak를 갖는 분포) 분포를 상정하고 DML을 진행합니다. 어려운 말이네요. 쉽게 풀어보자면, Uni-mode, 예를 들어 “개” 클래스에 대한 분포의 Peak가 하나가 아닌 (Gaussian 분포는 Peak가 하나입니다. 목적을 생각해보고 그래프를 그려보면 실제로 그렇죠) 다양한 Peak가 있다고 가정하는, 즉 각 객체들에 대한 다른 분포를 포함하면서도, Embedding space내 동일한 데이터는 가까운 거리에, 다른 데이터와는 먼 거리에 위치하게끔 학습한다는 의미입니다. 3클래스의 총 100개의 데이터가 있으면, 대표하는 세 지점만으로 DML을 하지 않고, 100개의 데이터에 대한 DML을 수행한다는 의미죠.
3. RepMet Architecture
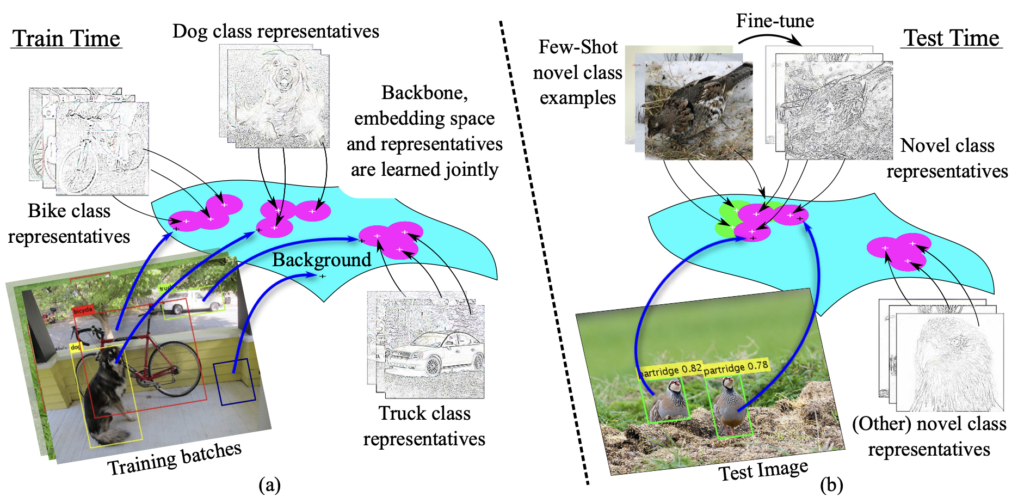
Introduction에서 Related Works (DML, Few-shot learning)에 대해 많이 소개하였으니, 바로 방법론을 보겠습니다. 위 Figure는 본 논문의 핵심입니다. 해당 Figure를 이해했다면, 본 논문의 동작 과정을 모두 이해했다고 볼 수 있습니다. 우선, 저자가 제안하는 subnet architecture는 DML (Distance Metric Learning) 임베딩과 임베딩 공간 내 Feature vector가 특정 클래스에 속할 확률을 계산하도록 학습합니다. 이 때 임베딩 공간 내에서는 Multi-modal mixture distribution, 모델링하려는 classification이나 detectioin에 관한 특성들 (색상, 형태, 질감)을 혼합하여 모델링한 분보를 고려합니다. subnet이 DML 기반으로 클래스에 속할 확률을 계산하니, 이 subnet이 결국 detector의 classfication head에 붙게 됩니다. 외에도 DML 기반으로 설계되었으므로 저자는 backbone 네트워크에도 함께 학습시켜, 임베딩 Feature를 생성하는 부분을 학습시키게 함으로써 Feature와 classification간의 연관성을 학습시킬 수 있습니다.
우선 이미지가 주어지면, Backbone에 의해 생성된 Feature vector가 있을 것이며, 이를 몇몇의 FC Layer로 구성된 DML 임베딩 모듈의 입력으로 사용합니다. 임베딩 모듈의 출력으로 나온 Feature vector는 입력의 vector보다 훨씬 작은 크기의 임베딩 Feature를 갖게 됩니다. 저자는 이후 Representatives, 즉 Feature vector외에도 학습된 Parameter들의 집합 vector를 Representatives로 명하며 이들이 임베딩 공간 내에서 어떤 역할을 하는지에 대해 언급하는데, 예를 들어 강아지 클래스를 나타내는 벡터들 중 하나는 강아지의 얼굴을 나타내는 (Mode) 반면, 다른 벡터는 강아지의 다리를 나타내는 (Mode)일 수 있으니, 임베딩 공간 내 해당 Mode들을 혼합한 분포를 만들어 이 분포를 통해 강아지와 다른 클래스를 구분하도록 학습합니다. 즉, 저자는 한 클래스를 나타내는 다양한 Vector를 활용하되, 활용하는 방식으로 각 Vector의 Mode로 불리는 Feature vector들을 결합한 분포를 만들어내고 이 분포를 통해 분류하는 방법을 학습하면서 Few 클래스에 대해서도 효과적으로 “분포에 대한 분류를” 해내고자 합니다.
구현 상으로 보면, Representatives Vector는 DML-based subnet에서 N개의 클래스, K개의 Mode, 그리고 각 Mode 당 e 차원을 갖는 FC Layer의 weight에 해당합니다. FC Layer는 고정된 입력 값인 1을 받아 가중치를 생성하여 Representatives Vector를 생성합니다. 학습 중에는 Gradient가 FC Layer로 전달되며 이에 따라 Representatives vector도 업데이트되게 됩니다. 이제 임베딩 벡터 E에 대해, subnet은 E와 Representatives Vector 간 거리를 계산하는데 사용되는 N * K * e의 텐서를 만듭니다. 이제 이 거리를 통해 모델은 임베딩 공간 내 얼마나 잘 학습하고 있는지 (특정 클래스가 잘 모여있는지, Representatives VEctor와 E간의 거리는 가까운지)를 학습합니다. 이후의 글은 이 과정에 대한 수학적인 과정인데, 사실 현재까지의 과정이 머릿속에 딱 와닿지도 않고, 수학적인 글이 이해하기에 너무 어려워서.. 읽어봤을 때 이 DML-based subnet 덕분에 Background 임베딩 Feature들이 거리 기반으로 잘 분류될 수 있다는 것을 말하네요. Loss또한 Triplelet Loss 형태를 취하며 Background로 classification되는 Feature에 대해 더 가중치를 부여하는 것으로 보입니다. 다음 번에 해당 분야의 논문을 더 읽어본 이후, 다시 접해봐야겠네요..ㅎㅎ. 우선 실험에서 보겠습니다.
4. Experiments

호다닥 실험파트로 넘어왔습니다. 위 Figure 1의 (a)는 Inception V3 백본에 FC레이어 2층을 사용한 DML 기반의 classification과, FPN+DCN 구조의 deformable ROI-align의 detection 백본으로 구성되어 있습니다.
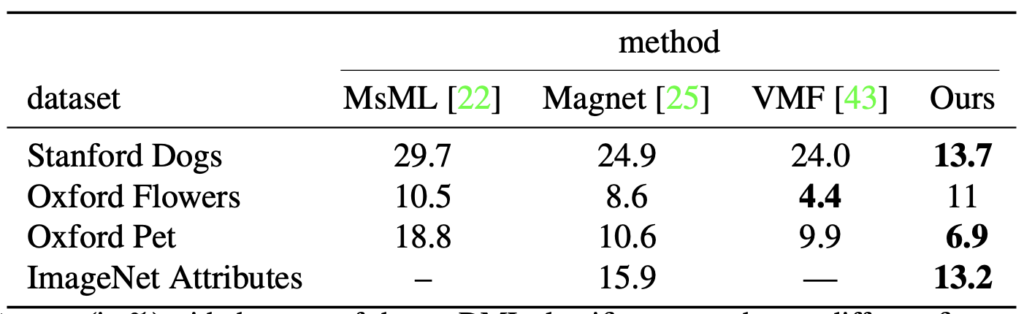
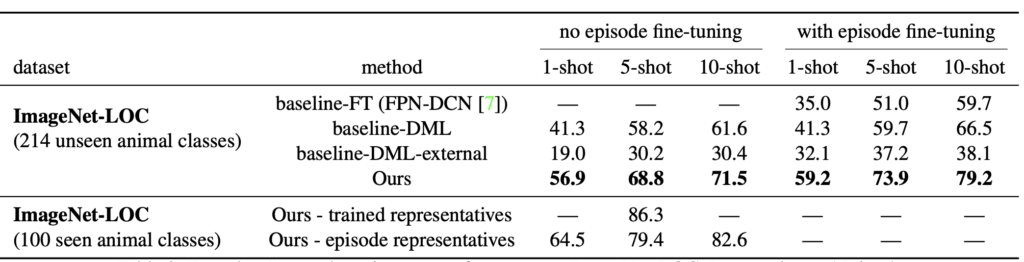
우선 저자는 다른 DML classification 모델과의 성능 비교를 하였는데, 단지 FC Layer 2층을 사용했음에도 학습단에서 임베딩 공간 내 DML을 같이 붙여 test error(%, 낮을 수록 좋음)가 적어진 모습을 볼 수 있습니다.
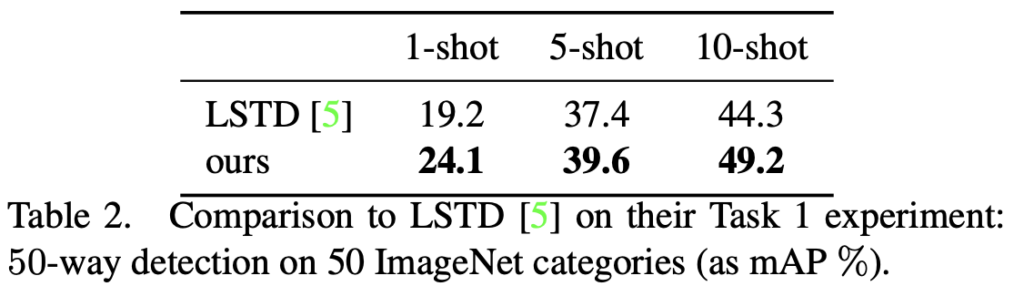
Detection 성능은, 이전 리뷰한 LSTD (Faster RCNN과 SSD의 구조를 합친 Fine-tuning 모델)에 비해 50-way N-shot 실험에서 성능이 오른 모습을 볼 수 있습니다. 저자는 이에 대해 Subnet 덕분임과 동시에, 학습 방식이 Episode learning을 통해 학습했기 때문으로 말합니다.
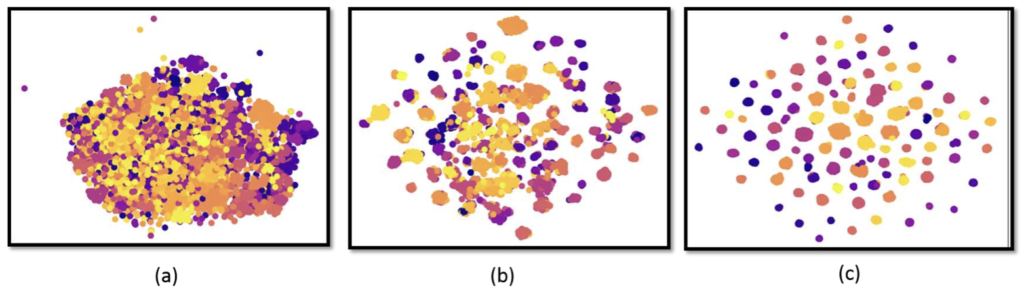
위 classification 성능 실험에서 Oxford flowers에 대한 성능은 별로 좋지 않은 모습을 보이는데, 저자는 이에 대해 t-SNE를 통해, iteration이 늘어가며 representatives의 임베딩 공간 내 분포를 시각화하여 way (class)의 개수가 많음에도 학습이 진행됨에 따라 어느정도 차별화된 분포를 보이나, 클래스가 많아 그 정도가 부족하다고 설명하고 있습니다. N-way가 많은 것도 문제인데, N-shot이 많아 아직 부족하다는 입장이네요.
Ablation study에 대해, episode learning의 학습 방법에 따른 성능 증가를 보입니다. Episode learning을 통해 모델이 다양한 경우를 학습할 수 있다보니, 특히 본 모델에서 임베딩 공간 내 representatives를 통한 few-shot classification이 더욱 효과적임을 알 수 있습니다. 사실 본 논문을 읽으면서도 아직 이해가 안된 부분이 너무 많네요. 머릿속에서 직관적으로 오지 않아 힘들었던 것 같습니다.. 추후에 다시읽어봐야겠네요. 감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
object detection에 few-shot 기반의 방법론을 적용하는 것에 대해 이전에 이상인 연구원님과 이야기를 나눴었는데 그때 언급하셨던 문제 중 localization error에 대해 한계가 있어 2-stage를 통한 RoI가 localization error를 그나마 줄이는 역할을 한다고 했던 기억이 있네요. 이번 논문 같은 경우는 제안된 RepMet 아키텍처가 few-shot 기반으로 RoI 대신 Localization error와 classification에도 강인하게 작동하도록 embedding feature를 만들어 이러한 representation을 바탕으로 학습을 진행하는 1-stage로 설계됐다로 이해했는데 해당 내용이 맞는지 궁금합니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
representatives vector는 결국 fc layer의 weight에 해당하는 것 같은데, 왜 fc layer의 weigth를 representatives vector로 표현하고 있는 것인가요 ? ? 다른 방식은 사용할 수 없는건가요 ? 또, loss가 triplet loss 형태를 취하고 있다고 했는데 triplet loss와 다른 부분이 무엇인가요 loss에 대한 언급이 이거밖에 없어서. . . . 더 자세히 설명해주실 수 있나요 ? 일반적으로 triplet loss는 positive, negative 샘플 간의 거리를 고려하여 학습한다면 본 논문 같은 경우에는 한 클래스와 그 나머지 클래스의 mode ? 간의 거리를 고려하는 것인지 . . 궁금합니다.
감사합니다.