안녕하세요, 허재연입니다. 요즘 6종 데이터셋에 대한 통일된 Active Learning 적용을 주제로 한 논문을 작성하고자 하고 있습니다. 6종 데이터 중 하나가 IoT(사물 인터넷) 데이터인데, 이와 관련된 논문을 찾아보다 읽어보게 되었습니다. 애초에 사물 인터넷 관련 데이터셋에 Active Learning 적용한 눈몬이 많지가 않은데, 이 논문은 그 중 하나 입니다. 인용수도 100이 넘기 때문에 관련 연구자들이 한 번 씩은 읽어봤을 것이라 생각하여 실험 세팅에 참고하고자 합니다.
사물 인터넷(Internet of Things)은 인터넷을 통해 데이터를 다른 기기 및 시스템과 연결/통신할 목적으로 센서, 소프트웨어, 기타 기술을 내장한 물리적 object(사물)의 네트워크를 의미합니다. 우리에게 익숙한 일반적 네트워크와는 형태나 동작, 특성, 동작 기기에서 다른 부분이 많습니다. 사물 인터넷이 동작하는 객체(사물)로는 가정용 전자기기, 스마트 팩토리의 산업용 도구, 애플 워치, 핸드폰, 다양한 센서 등 그 종류가 매우 다양합니다. 일반적으로는 저성능, 저전력의 edge device에서 동작하는 것을 고려하며, M2M(machine-to-machine)으로 동작하는 경우가 많습니다. 전자 및 통신 기술이 발달하며 많은 빅테크 기업에서는 꾸준히 세상 전체를 인터넷으로 연결하고자 시도하고 있습니다. 당장 우리 주변만 봐도 애플워치를 이용해 운동량을 측정하고, 핸드폰 어플로 집에 있는 가전제품을 제어할 수 있죠. 앞으로 점점 더 많은 센서 및 기기가 사물 인터넷으로 연결되어서 우리 삶을 더 편하게 만들어 줄 것이라 예상됩니다.
하지만 일반적으로 편리한 기술에 장점만 있지는 않습니다. 수많은 센서/기기가 인터넷을 통해 연결된다는 것은, 우리의 사소한 행동과 동선 하나가 전부 기록된다는 말과 같습니다. 이 기술을 악용하면 소설 1984처럼 통제 국가를 실현할 수도 있을 것이고, 그렇지 않더라도 해당 정보가 유출되면 개인정보 보안에 큰 타격을 입을 수 있을 것입니다. 일반 개인들이야 개인정보가 유출되는 선에서 끝날 수 있지만, 군사 및 국가 기밀 사항이 해킹으로 인해 유출된다면 피해가 클 것 입니다. 필연적으로 사물 인터넷에서는 보안이 매우 중요한 이슈가 되었고, 관련 연구 및 개발이 활발히 진행되고 있습니다.
이런 이슈 때문인지, 제가 서베이한 대부분의 active learning 관련 IoT 연구 및 데이터셋이 보안에 초점을 맞추고 있었습니다. 키워드도 대부분 Packet detection, Intrusion detection, Anomaly Detection, Malware classification 등이었으며, 각 task에 Active Learning을 적용 시킨 것들이었습니다. 이번에 리뷰 할 논문도 참신한 방법론을 제안한다기 보다는 intrusion detection에 AL을 접목해 보았다는 것에 의의가 있습니다.
Active Learning(AL)은 양질의, 다량의 데이터를 더 적은 비용으로 얻기 위해 연구되고 있는 분야입니다. 최근에 딥러닝 기술의 발달로 수많은 문제가 딥러닝을 이용해 해결되고 있습니다. 하지만 딥러닝 모델의 압도적인 성능의 원천은 양질의, 대량의 데이터입니다. 딥러닝 모델은 기존의 기계 학습 방법론들보다 데이터에 크게 의존하며, 모델을 개선시키는 것보다 데이터를 추가하는 것으로 더 많은 성능 향상을 기대할 수 있습니다. 하지만 데이터셋을 확보하는 것은 비용과 시간이 많이 드는 작업입니다. 특히 데이터를 수집하는 것보다 해당 데이터에 대한 label을 annotation하는 것에 더 많은 비용과 시간이 듭니다. 이에 딥러닝 모델 학습 효율이 좋은, 고가치 데이터를 우선적으로 선별하여 annotation하고자 하는 연구가 주목받았고 해당 방법을 연구하는 분야가 Active Learning입니다(딥러닝 이후에 active learning이 처음 연구되기 시작된 것은 아닙니다. 딥러닝 이전에도 active learning이 꾸준히 연구되고 있었지만 더 많은 데이터를 필요로 하는 딥러닝이 발전함에 따라 그 필요성이 더 주목받고 있다고 생각하시면 될 것 같습니다). 전체 dataset 중 고가치 subset을 어떻게 선별해야 할 지에 대해 크게 1.uncertainty 기반 방법론과 2. diversity 기반 방법이 있습니다. 1. uncertainty 기반 방법은 최대한 informative한 데이터를 선별하고자 하는데, 모델이 어려워하는 데이터(model confidence가 낮은 데이터)가 학습 효율이 좋을 것이라는 관점에서 문제를 해결하고자 합니다. 실제로 활발히 연구되고 있는 영역이며, 꾸준히 준수한 성능의 방법론들이 제안되고 있습니다. 하지만 uncertainty 기반으로만 데이터를 선별하다 보니 전체 데이터셋의 분포를 반영하지 못하는, 편향된 샘플링을 하게 된다는 문제점이 있습니다. 2. diversity 기반 방법론은 전체 dataset의 분포를 반영하는 subset을 선별하고자 합니다. 하지만 반대로 모델이 어려워하는, informative한 데이터를 비교적 덜 선별하게 되는 단점이 있습니다.
이번에 리뷰할 논문은 위에서 간략하게 소개해드린, IoT의 infrusion detection에 대한 active learning 적용을 다룬 논문입니다. 리뷰 시작하겠습니다.
Abstract
사물 인터넷(IoT)은 우리 일상 생활에 점점 깊숙히 보편화되고 있지만, 고유한 보안 문제를 갖고 있습니다. 침입 탐지(intrusion detection)는 무선 IoT 네트워크의 보안에 매우 중요합니다. 저자는 본 논문에서 무선 침입 탐지를 위한 human-in-the-loop active learning에 대해 다룬다고 합니다. 먼저 무선 IoT 네트워크를 위한 침입 탐지 시스템(Intrusion Detection System. IDS)에 대한 근몬적인 문제를 제시하고, Active Learning의 기본 개념을 검토한 다음 무선 침입 탐지의 다양한 응용 분야에 활용할 것을 제안한다고 합니다. 머신러닝 기술이 침입 탐지에 널리 사용되고자 하지만 IoT의 침입 탐지에 human-in-loop 머신러닝 적용은 아직 초기 단계이므로 이 논문을 읽는 독자들이 active learning의 주요 개념을 이해하고 이 분야에 대한 추가 연구를 할 수 있기 바란다고 합니다.
Introduction
사물 인터넷은 소프트웨어, 센서, 전자 제품, 통신 모듈이 내장된 연결된 물리적 장치의 네트워크를 뜻합니다. 사물 인터넷은 네트워크 인프라를 통해 물리적 객체를 원격으로 감지하고 제어할 수 있게 해주며, 결과적으로 다양한 기기와 물리적 세계를 연결할 수 있습니다. 사물 인터넷은 기존 시스템의 효율성, 신뢰성, 정확성을 향상 시키는데 도움을 줄 수 있으며 최근 관련 연구가 활발하게 이루어지고 있다고 합니다. NB-IoT, WiFi, Bluetooth Low Energy 등의 무선 통신 기술들은 유연성, 저비용, 설치 및 유지보수의 간단함으로 IoT 장치를 연결하는 표준이 되었습니다. 무선 장치를 사무실이나 공장에 간편하게 설치해 연결할 수 있으며, LTE-A 및 5G 등의 이동통신 기술의 발달로 해당 기술의 상용화가 순조롭게 진행되고 많은 사용자에게 준수한 품질의 서비스를 제공할 수 있게 되었다고 합니다.
이에 대해서 IoT 보안 관련 연구가 한편으로 계속되고 있습니다. IoT는 비용이 저렴하고 유연성이 뛰어나지만 기존 네트워크보다 취약하며 결과적으로 DoS공격과 같은 다양한 보안 문제에 노출되어 있다고 합니다. IoT에는 일반적으로 센서 노드가 고성능 하드웨어가 아니기 때문에 배터리 전력과 메모리 공간, 무선 채널 용량이 매우 제한적입니다. 또한 IoT의 각 노드는 IP주소를 가지므로 모든 사용자가 전 세계 어디 에서든 IoT노드와 통신할 수 있어서 사이버 보안 공격에 특히 취약하다고 합니다. 침입 탐지 시스템(IDS)이 네트워크 공격을 탐지하는데 효율적이지만, 사물 인터넷의 위와 같은 특성 때문에 IoT IDS 설계는 기존의 네트워크 IDS와 다르다고 합니다.
침입 탐지 기술은 크게 1. misuse-based methods, 2. anomaly-based methods, 3. hybrid methods 3가지 카테고리로 나눌 수 있다고 합니다. misuse-based 방법에서는 일단 도메인 지식이나 전문가의 경험 등의 정보를 바탕으로 signatures의 모음을 구축하고, incoming network data의 특정한 패턴을 찾아 데이터베이스에 있는 특정 signature와 매칭시키려고 시도합니다. 해당 방법은 database의 signature 중 적어도 하나와 일치하는 침입에 대해 효과적으로 탐지할 수 있으므로 false-positive의 가능성이 낮다고 합니다. 하지만 이 방법은 데이터베이스에 일치하는 패턴이 없을 때 침입을 탐지할 수 있기 때문에 공격자가 database의 signature들을 알고 있는 상황에서 높은 false-negative를 초래하게 될 수 있다고 하며, 따라서 이를 방지하기 위해 misuse-based IDS는 database의 signature를 주기적으로 업데이트해야 한다고 합니다. anomaly-based 방법은 먼저 정상적인 네트워크 패턴을 학습한 다음 이에 부합하지 않는네트워크(anomalies)를 식별하는 방법입니다. anomaly-based 방법은 기존에 잘 알려지지 않은 공격을 효과적으로 탐지할 수 있습니다. 더욱이 정상 네트워크를 기계가 학습하고 대부분의 경우 침입 탐지에 대한 명시적인 규칙이 제공되지 않기 때문에, 공격자가 규칙을 학습해서 탐지하기 어려운 공격 전략을 만들기가 어렵습니다. anomaly–based 방법의 단점으로는 이전에 본 적 없었더 ㄴ모든 동작이 이상치로 처리될 수 있기 때문에 대량의 잘못된 경보를 생성할 수 있다는 점이 있습니다. hybrid 접근법은 misuse-based 방법과 anomaly-based 방법을 결합해서 이 둘의 장점을 모두 취하고자 합니다. 실제로 대부분의 IDS 시스템은 false-positive rate와 false-negative rate 사이의 밸런스를 맞추고자 hybrid 방법을 이용한다고 합니다.
기계학습 기술이 이상 탐지를 위해 광범위하게 연구되고 있지만 침입 탐지에 실제로 적용하는 것은 제한적입니다. 실제 침입 탐지 시스템 설계에 충분한 학습 데이터가 부족하고 특정 시스템에 대한 도메인 지식이 필요하기 때문이라고 합니다. Active Learning은 제한된 양의 학습 샘플로부터 학습을 하고자 하는 기계 학습의 하위 분야입니다. 침입 탐지를 위한 레이블을 제공하는 것은 일반적으로 도메인 지식을 가진 사람이 수행 할 수 있고 시간이 많이 걸리기 때문에 IDS 설계에 (도메인 전문가의 경험과 기계 학습의 힘을 함께 활용할 수 있는)active learning 적용을 시도하는 것은 어찌 보면 당연한 일이며, 결과적으로 라벨링 비용을 크게 줄이고 침임 탐지를 위한 기계 학습 모델을 빠르게 구축할 수 있다고 합니다. 추가적으로 active learning framework는 기계 학습 모델이 빠르게 업데이트 할 수 있게 하므로 새로운 네트워크 공격에 대해 짧은 시간 내에 이를 반영하는것이 가능하다고 합니다.
Intrusion detection for wireless internet of things
침입 탐지를 시스템에 대한 내부/외부 침입자의 유해한 활동을 탐지하는 것을 목표로 합니다. 대표적인 침입으로는 정보 수집, 도청, 유해 패킷 포워딩, 패킷 드랍 등이 있다고 합니다(훑고 넘어가기에 제가 각각이 무엇인지 정확하게 알지는 못합니다). 이러한 침입을 탐지하기 위해 IDS는 일반적으로 강력한 탐지 엔진인 reporting module과 센서 그룹으로 설계된다고 합니다. 센서들이 데이터를 수집하고, 탐지 엔진이 의심스러운 활동을 탐지하기 위해 수집된 정보를 분석합니다. 침입이 탐지되면 reporting module이 경보를 울립니다.
IoT에는 몇 가지 특징이 있습니다. 첫 번째로는 무선 센서 네트워크와 다르게 IoT에는 IoT 네트워크를 인터넷과 연결하는 edge node가 있습니다. 두 번째로 IoT의 센서 노드는 (신뢰 할 수 없는)인터넷에 직접 연결되고 IP주소로 글로벌하게 식별되기 때문에 IoT는 인터넷 침입에 취약합니다. 마지막으로, IoT node는 (edge device에서 동작하므로) 활용 자원이 제약되고 lossy link를 통해 연결됩니다. 이러한 특징 때문에 IoT를 위한 IDS 구축이 쉽지 않다고 합니다.
침입 탐지를 네트워크의 중앙에서 할 것인지, 아니면 분산해서 할 것인지에 따라서도 구분할 수 있습니다. centralized 형식으로 배치하면 구현이 쉽고 외부 침입을 잘 탐지할 수 있으며 뛰어난 성능의 프로세서가 필요한 반면, distributed 형식으로 배치하면 고장에 비교적 강건하고 내부 침입을 잘 탐지할 수 있고 전체 비용이 증가한다는 특징이 있습니다. 이 둘의 특징을 모두 조합하려는 hybrid 형식도 있습니다(모든 cluster head에 탐지 agent를 배치하거나, 라우터에 central agent를 배치하고 slave agents를 다른 노드에 배치하는 형식).
Active Learning for anomaly detection
기계학습 및 딥러닝 학습에는 정제된 데이터가 필요합니다. 하지만 annotation 작업에는 상당한 비용이 발생합니다. 이 문제를 해결하기 위해 active learning이 제안되었습니다. AL은 가능한 적은 labeled instance를 이용하여 높은 정확도를 얻도록 해서 labeled data를 얻는데 최소한의 비용이 들도록 하는 것을 목표로 합니다. active learning 시스템에서는 모델이 초기 labeled dataset을 가지고 학습하고, 라벨랑할 데이터들을 쿼리하고, AL으로 선별한 unlabeled data를 사람이 라벨링하고, 라벨링한 데이터를 labeled set에 추가하고, 이 데이터로 다시 모델을 학습하고.. 를 반복합니다. 시스템이 원하는 정확도를 달성하거나 예산을 모두 다 사용했으면 학습 프로세스를 중단합니다. 라벨링할 데이터를 신중하게 선택해서 AL이 고전적 ML 알고리즘보다 훨씬 적은 labeled data로 동일한 정확도를 달성할 수 있다고 합니다.
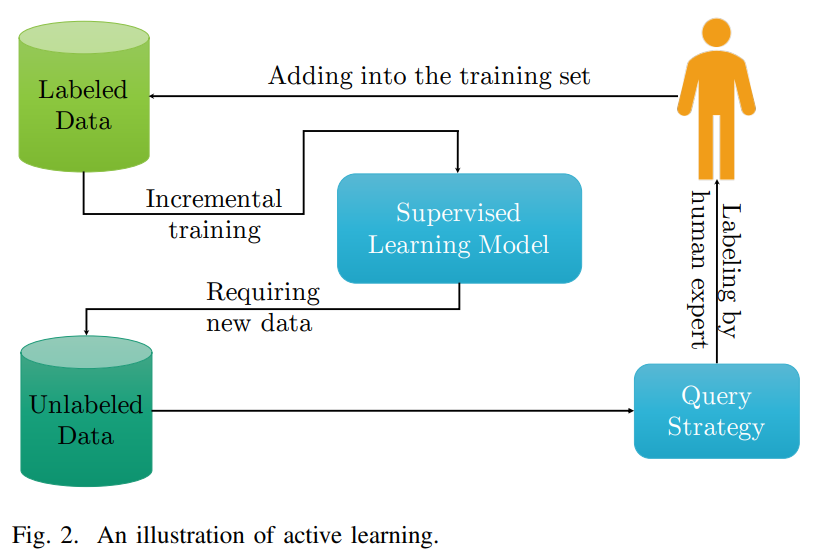
Active Learning은 stream-based 샘플링 방식과 pool-based 샘플링 방식으로 분류할 수 있습니다. stream-based 방법은 실제 분포에서 데이터를 한번에 하나씩 샘플링한 다음 learner가 각 데이터에 대해 annotation을 요청할지 말지를 결정합니다. 딥러닝 이전 기계학습 방법에서는 꽤 사용했던 방법 같은데, 배치 단위 학습을 하는 딥러닝에는 stream-based 방법이 맞지 않습니다. pool-based 샘플링에서는 unlabeled data pool에서 query engine이 라벨링할 데이터 풀을 골라 human annotator에게 라벨링을 부탁합니다. 이 때, 어떤 데이터를 쿼리할 것인지 다양한 방법이 있습니다. 본 논문에서는 uncertainty sampling, query-by-committe, expected model change등을 다룹니다.
- uncertainty sample : 위에서 설명했든, uncertainty sampling은 모델의 confidence가 작은 데이터가 더욱 informative할 것이라는 가정으로 데이터를 선별합니다. 이 방법은 least confidence, entropy 등 다양한 방법으로 uncertainty를 측정할 수 있습니다. least confidence는 특정 데이터의 class별 confidence 중 가장 높은 confidence의 수치가 작은 데이터를 우선적으로 선별합니다. entorpy는 섀년의 정보이론에서 다루는 entropy로, 각 class별 confidence가 비슷할수록 entropy값이 커지게 됩니다. 2진 분류라면 2개 클래스의 확률이 각각 0.5일 때 가장 큰 entropy값을 가지게 되겠죠. margin sampling 방법은 (top1 confidence – top2 confidence)값이 margin을 기준으로 데이터로 선별합니다. 모델이 확신하지 못하는 데이터일수록 마진 값이 작은 것이니 이러한 데이터를 우선적으로 선별합니다.
- Query-by-Committee (QBC) : QBC는 committee를 고려하여 데이터를 샘플링하는데, 여기서 committee는 학습 모델로 이루어져 있습니다. 동일 데이터에 대해 여러 학습 모델이 다른 예측을 하게 된다면 해당 데이터가 고가치 데이터일 것으로 간주하고 샘플링하게 됩니다.
- Expected Model Change : expected model change 방법은 이름에서 알 수 있듯 현재 모델의 파라미터를 가장 많이 변경시키는 data instance를 선택합니다. 일반적으로 이는 예상되는 gradient의 크기로 측정되며, 이는 gradient descent방법을 사용하는 학습법에 광범위하게 적용할 수 있습니다. 각 instance에 라벨이 지정되고 training set에 추가된 이후에는 각 instance에 대해 gradient를 계산할 수 있지만, query 단계에서는 실제 label을 알 수 없으므로 gradient의 예측값이 사용되고, 가장 큰 expected gradient를 가진 데이터가 선별됩니다. 이 방법은 되도록 모델을 많이 변화하도록 하는 데이터를 선별하고자 하는데, 이를 통해 중복되는 데이터를 선택하는 것을 피할 수 있기 때문입니다. 하지만 실제 문제에서의 feature space가 isotropic하지 않을 수 있어서 조건에 제대로 맞지 않는 구성 요소로 시스템 성능이 크게 저하될 수 있다는 단점이 있다고 합니다
- Expected Error Reduction : 이 방법은 위 방법과 느낌이 비슷한데, generalization error가 얼마나 감소할지 측정합니다. 해당 쿼리 전략에서는 우선 기존 labeled training set과 함께 각 data instance에 대해 모델을 훈련한 다음 나머지 unlabeled instance의 예상 오류를 계산하고 가장 작은 expected loss를 가진 data instance가 선택됩니다.
- Information Density : uncertainty sampling이나 QBC 등의 방법에서는 확신도가 작은 데이터를 선택하는 것에만 관심이 있기 때문에 outlier들을 우선적으로 선택하기 쉽습니다. 하지만 이렇게 선별된 인스턴스들은 분포의 끝에 있기 때문에 다른 인스턴스를 전혀 대표할 수 없습니다. 이 문제를 해결하기 위해 정보 밀도(informatino density)를 도입하여 기본 쿼리 전략을 수정할 수 있습니다. 이 방법은 데이터 간 거리를 측정하여 각 인스턴스의 대표성을 고려하게 됩니다. 위에서 언급한 diversity 기반 방법과 비슷한 맥락이라고 생각하시면 됩니다. density strategy를 사용해서 system은 informativeness와 representativeness를 적절히 고려해 instance를 선별할 수 있습니다.
Active Learning in Intrusion Detection
기계 학습 기반 침입 탐지 기술에서, 탐지 모델은 attack data와 normal data를 모두 포함하는 training data set으로 훈련됩니다. 해당 모델은 침입 탐지 성능을 유지하고 새로운 유형의 공격에 대응하기 위해 주기적으로 업데이트 되어야 합니다. 하지만, 기계 학습을 침입 탐지에 적용하는 것은 너무 방대한 양의 (다양한 침입 탐지 시나리오에 대한) labeled training data를 필요로 한다는 단점이 있고, 적절한 공격 데이터를 취득하는 것은 도메인 전문가의 의지해야 하기 때문에 시간과 비용이 많이 듭니다. 특히 무선 사물인터넷에 대한 침입 탐지를 고안하는 것은 사물인터넷의 특징(전력 제한, 메모리 제한, 낮은 컴퓨팅 능력 등등) 때문에 더욱 어렵다고 합니다. 게다가 다양한 무선 IoT 노드 간의 무선 채널 용량이 제한되어 있기 때문에 많은 양의 훈련 데이터 수집이 어렵다고 합니다. 결과적으로, 무선 IoT 네트워크에서 많은 양의 침입 데이터를 수집하는 것은 매우 어렵습니다.
unlabeled data에서 가장 유용한 데이터를 선별하는 데에 있어, active learning은 라벨링 비용을 줄일 수 있어 도메인 전문가의 지식과 기계 학습의 힘을 효율적으로 통합하는데 사용될 수 있다고 합니다. 특히 구조적 단순함과 계산 효율로 인해 AL 기반 IDS에서 uncertainty sampling이 가장 일반적으로 사용되는 querying framework라고 합니다. uncertainty sampling strategy에서, IDS는 가장 top confidence가 낮은 data instance를 선별합니다. 이 데이터는 인간 전문가에 의해 라벨링 되어서 training set에 추가 돼서 침입 탐지 모델을 업데이트 하는 데에 사용됩니다. 이런 모델로는 SVM이나 신경망 등을 사용할 수 있습니다. uncertainty sampling이 AL 기반 IDS에 좋은 성능과 낮은 계산 비용을 보장하지만, QBC나 information density와 같은 다른 전략 또한 고려할 수 있습니다.
IDS 구축에 많은 기계 학습 기법이 사용되었지만, Active Learning을 이용한 사례는 적었으며, 그 중 대부분은 uncertainty sampling을 사용했다고 합니다. 특히 당시에 IoT IDS 구축에 active learning을 논의한 이전 연구가 없었다고 합니다.
Experiment
논문 끝에 실험이 제시되어 있기는 하지만, 실험이 상당히 빈약합니다. 같이 한 번 보도록 하겠습니다.
저자들은 침입 탐지에 대해 AL을 적용한 것과, random selection 한 것을 비교했습니다. 데이터셋은 KDD1999 데이터셋과 AWID 데이터셋이 사용되었고, 80%가 training set, 20%가 test set으로 사용되었습니다. KDD는 연구에 사용되는 데이터이고, AWID는 실제 WiFi환경에서 취득된 데이터라고 합니다. 저는 처음 보는 데이터이고, 침입 탐지에 자주 사용되는 데이터셋 같습니다. 그래프를 보겠습니다.
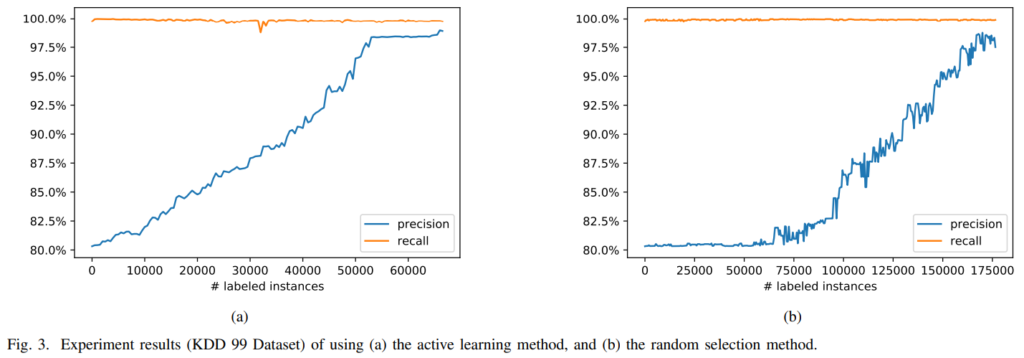
일단, 가로축이 통일되어 있지 않습니다. 그래프를 보실 때 유의하시기 바랍니다. 해당 그래프는 KDD 99 데이터셋에 대해 적용한 결과입니다. (a)는 AL을 적용한 것이고, (b)는 random sampling한 것입니다. AL을 적용한 그래프가 확연하게 빨리 precision이 증가하는 것을 확인할 수 있습니다.
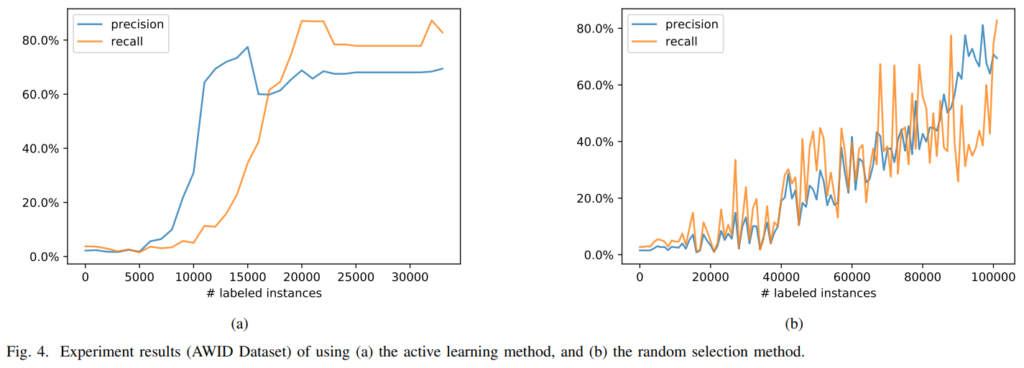
AWID 데이터셋에 대한 성능입니다. 역시 가로축이 통일되어 있지 않음에 주의하시고, (a)AL을 적용했을 때가 (b)random sampling보다 훨씬 빨리 좋은 성능을 달성하는 것을 확인할 수 있습니다. 좀 당황스러운 것이, 무슨 모델을 적용했는지 자세한 설명이 있지도 않고 특히 Fig3과 Fig4의 recall에 대한 설명이 부재합니다(…) 두 데이터셋에서, 그리고 AL 적용 여부에 따라 완전 다르게 recall이 뽑히는데 왜 관련된 설명이 한 문장도 없는 건지 이해하기 어렵습니다. 제가 예전 IoT-23 dataset에 DNN을 적용했던 기억을 떠올려보면, Fig3에서 recall이 100%로 고정되어있는 것은 binary classification에서 모델이 그냥 한 쪽(True)로 찍는 상태로 시작했기 때문이 아닐까 싶네요.
Conclusion
해당 논문에서는 무선 사물인터넷 네트워크의 침입 탐지에 active learning 적용에 대해 다루었습니다. 사물인터넷에는 보안이 중요한 이슈이기 때문에 침입 탐지는 주요한 연구 주제에고, 기계 학습을 활용한 침입 탐지 프레임워크에 AL을 적절히 도입하면 더욱 효율적인 pipeline을 구축 할 수 있다고 합니다. 실험을 통해 AL이 효율성을 높일 수 있다는 것을 보였습니다.
IoT 실험 세팅에 대한 고려 사항이나 소스를 얻을 수 있을까 해서 읽어 본 논문인데, 메이저 학회가 아니어서 그런지, 아니면 2018년 논문이어서 그런지 아쉬운 부분이 많은 논문이었습니다. 특별한 novelty가 있는 것도 아니고 코드도 공개되어 있지 않은 것 같고 실험도 빈약하며 실험에 대한 의미 있는 해석도 부재합니다. 해당 분야 관련 논문이 별로 없어서 읽어보긴 했는데, 임팩트가 있는 논문은 아니었습니다. IoT 보안 관련 background에 대한 정보를 얻을 수 있었던 것에 만족해야 할 것 같습니다. 평소에 읽던 탑티어 논문들이 얼마나 잘 정리된 글이었는지 이 글을 읽으면서 다시 느끼게 되었습니다
리뷰 마무리하도록 하겠습니다. 읽어주셔서 감사합니다.
안녕하세요 허재연 연구원님 좋은 리뷰 감사합니다.
처음 IoT 데이터셋이라는 단어를 들었을 때 IoT가 포함하는 범위가 상당히 넓을 것 같은데 그렇다면 구체적으로 어떤 데이터일지 궁금했습니다. 결국 IoT 네트워크의 보안 위협을 감지하는 데이터셋에 관한 것이었군요.
실험 부분에서 질문이 있는데요, 결국 논문에서 수행한 task인 intrusion detection은 침입 여부를 분류하는 binary classification에 해당하는 것이라고 보면 되나요?
그리고 [그림 3]의 recall이 100%로 고정된 이유가 시작 시 모든 sample를 true로 판단하는 상태로 시작하였기 때문이라고 하셨는데 그렇다면 labeled instance가 30000인 지점에서 recall이 잠시 drop되는 현상은 왜 발생하는 것인지 궁금합니다.
천혜원 연구원님, 좋은 질문 주셔서 감사합니다. 사실 질문 주신 내용들에 대한 언급이 논문에 전혀 나와 있지 않아서 정확한 답변을 드리기 힘들지만, 나름 제 해석으로 대신 답변드리겠습니다.
1. 실험에 대한 설명에는 없지만, 그 이전에 계속 classification으로 문제를 다루는 듯한 언급이 있기 때문에 classification task로 이해하시면 될 것 같습니다. 별다른 추가적인 class 없이 intrusion 여부만 판단하므로 binary classification이라고 봐도 되겠네요.
2. Fig3과 Fig4에 보면 recall이 상당히 다른 양상을 띄는데, 이런 그래프에 대한 해석이나 코멘트가 전무합니다. 별다른 코드가 공개되어 있는 것 같지도 않습니다. 따라서 정확히 알 수 없지만, 저는 다음과 같이 해석했습니다. 일단 시작할 때는 모델이 한쪽으로 찍는 경향이 있어 recall이 100으로 고정되지만 학습을 진행함에 따라 반대쪽 예측도 할 수 있는 상태가 될 것입니다. 이런 경향은 accuracy가 50% 부근일 때 두드러지겠죠. 따라서 해당 지점 근처에서 hard sample에 대해 False로 잘못 찍는 경우가 발생해 recall drop이 일시적으로 발생하지 않나 싶습니다. 학습을 진행함에 따라 이런 모델의 불확실함 정도는 해소되겠죠. 저의 해석이기 때문에 정답이 아닐 수도 있지만, 추가적인 정보를 얻기 힘든 상황에서는 이 해석이 그나마 함리적이라고 생각됩니다.
감사합니다.