이번에 소개드릴 논문은 ICCV2023에 게재된 EfficientViT라는 방법론입니다. backbone에 대한 논문이며, image classification 같은 task 대신 segmentation, super resolution과 같은 dense level prediction task에 초점을 맞추어 효율적이면서 성능도 우수한 ViT 기반 backbone을 제안한 논문입니다.
Intro
Dense-level prediction (e.g., Semantic Segmentation, Depth Estimation, Super Resolution) task들은 image classification과 달리 출력값을 원래의 입력 영상 해상도와 동일한 크기의 값으로 출력해야하기에 상당히 inference cost가 많이 드는 작업들입니다.
task를 수행하기 위한 연산과 네트워크 구조로 인해 이미 연산량이 많은 와중에 해당 task들에 입력 영상으로 들어가는 해상도는 대부분 512 이상의 고해상도 영상을 입력을 주로 받고 있습니다. 이는 많은 연구들이 고해상도의 영상을 입력으로 할 경우 모델이 영상의 문맥 정보 및 local detail 정보들을 잘 포착해서 더 좋은 성능의 결과들을 만들어내기 때문이죠.
즉, dense prediction task들의 연산량이 classification task와 비교해서 압도적으로 많을 수 밖에 없는 상황에서, image classification의 모델들을 encoder로 포팅하는 것은 상당히 비효율적이다라고 저자는 주장합니다. 다시 말하면 dense prediction task에 초점을 맞춘 효율적인 backbone이 필요하다는 것을 말하는 것이죠.
그렇다면 dense prediction task에 최적화된 백본을 만들기 위해서 고려해야할 가장 중요한 요소들은 무엇이 있을까요? 저자는 일단 semantic segmentation의 SOTA 방법론들을 살펴보니, 최근의 SOTA 방법론들이 공통적으로 구성하는 요소들이 바로 global receptive field와 multi-scale learning이라는 점이었습니다.
receptive field는 모델이 한번에 볼 수 있는 영역을 의미하는 것이니 잘 아실 것으로 이해하며, multi-scale learning에 대해서는 간단하게 소개드리면, 하나의 feature map에 대해 다양한 scale의 kernel size 혹은 dilated convolution 등을 사용하여 multi-scale로 연산된 feature map을 활용하는 것을 의미합니다. (그림1 참조)
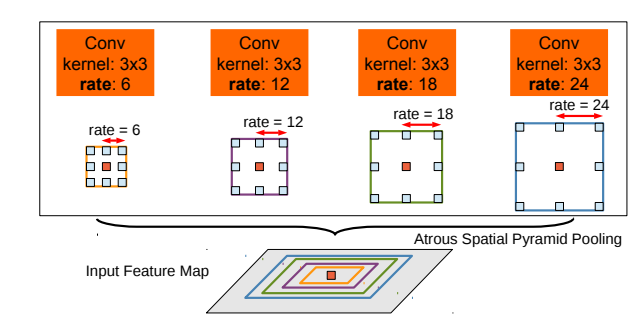
semantic segmentation의 SOTA 방법론으로 잘 알려진 SegFormer와 SegNeXt를 예로 들어보면, SegFormer는 ViT의 self-attention 기법을 통해 large receptive field를 잘 확보할 수 있었으며, SegNeXt의 경우 최대 21의 Kernel-size를 가지는 multi-branch module을 통해서 large receptive field 및 multi-scale learning을 수행할 수 있었다고 합니다.
이러한 방법론들이 Segmentation 모델의 최고 성능을 만들어낸 것이 맞지만, 효율성 측면에서는 많은 부분이 고려되지 못했다고 저자는 주장합니다. 예를 들어, Segformer의 softmax attention(저희가 알고 있는 transformer의 self-attention입니다.)은 feature map 해상도의 제곱에 해당하는 연산량을 가지고 있기 때문에, 상당히 많은 메모리와 추론 속도를 먹게 되므로, 고해상도 영상을 입력으로 하는 dense prediction task에서 상당히 비효율적입니다.
SegNeXt도 역시 kernel size를 21이나 키웠는데, 이러한 large kernel의 컨볼루션은 예외적인 지원을 하드웨어에서 적용해야만 빠른 효율성을 구할 수 있지만 이는 보통 하드웨어 디바이스에서 지원이 불가능한 경우가 대부분이라고 합니다.
따라서, 저자들은 dense prediction task를 수행하는데 있어 최적의 backbone 모듈을 만들고자 하였으며 결과적으로 multi-scale learning과 global receptive field를 모두 확보하면서 동시에 하드웨어에 적합한 연산 방식을 고려하는 것을 설계의 원칙으로 삼았다고 합니다.
그 결과 1) softmax 기반이 아닌, RELU Linear attention을 통해서 global receptive field를 확보하였고, 2) 컨볼루션 레이어를 적절히 섞어서 local information에 대한 부족한 부분을 보충하고, multi-scale linear attention module을 통해 RELU linear attention의 성능 한계를 극복하였다고 합니다.
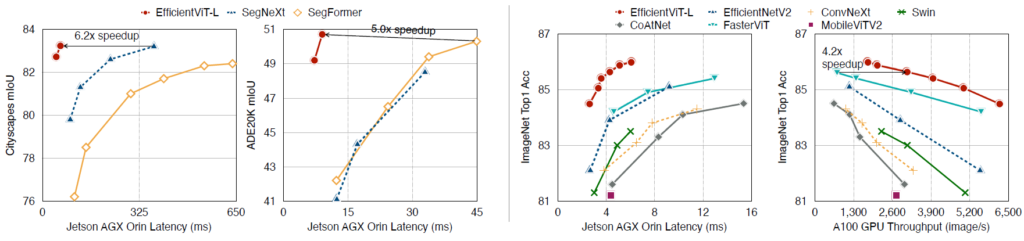
이러한 설계 끝에 만들어진 EfficientViT는 SegNeXt와 SegFormer와 비교하였을 때 성능은 비스샇거나 더 높으면서 속도는 5배 이상 빠른 모델을 만들 수 있다고 합니다.(그림2 참조)
Method
그럼 저자게 제안하는 EfficientViT에 대해서 더 자세히 알아보도록 하겠습니다. intro에서도 간단하게 설명드렸다시피 global receptive field와 multi-scale learning이 성능 관점에서 매우 중요하다고 볼 수 있다고 했습니다. 따라서 저자가 제안하는 multi-scale linear attention은 정확도와 효율성의 trade-off 밸런스를 잘 맞추도록 설계하였기 때문에, 성능적인 측면에서 multi-scale linear attention module은 global receptive field를 포착가능하며, multi-scale learning을 수행할 수 있어야만 합니다.
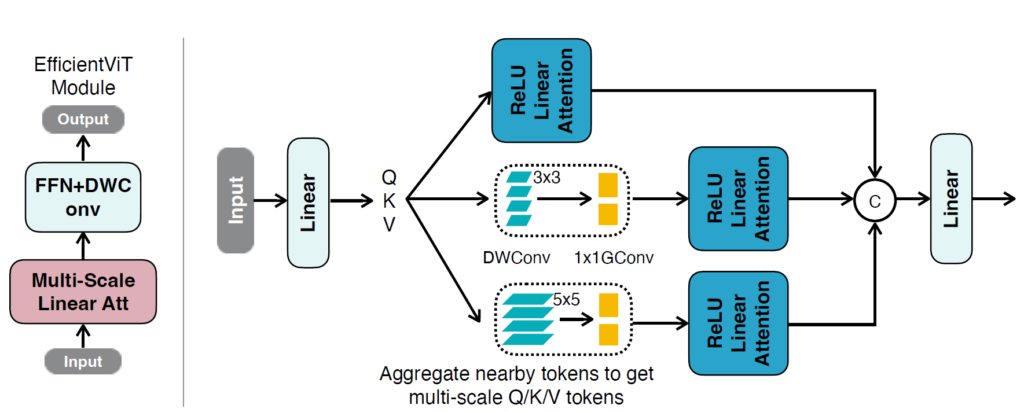
그림3은 저자가 제안하는 Multi-Scale Linear Attention이 어떻게 진행되는지를 보여줍니다. 일단 흔히 알고 있는 Transformer의 self-attention처럼 input에 대하여 Query, Key, Value를 만들고 그 다음에 Attention을 수행하는 구조로 보여집니다.
하지만 여기서 Q/K/V token들에 대해 multi-scale kernel size를 가지는 DWConvolution과 1×1 conv를 연산하는 depthwise separable convolution 연산을 취하여 multi-scale learning을 수행하는 것으로 보여집니다.
그리고 ReLU Linear Attention이라는 것이 저희가 알고 있는 Self-attention을 수행하는 곳으로 보여지는데, 해당 부분이 상당히 중요하니 바로 아래서 더 자세히 알아보겠습니다.
Enable Global Receptive Field with ReLU Linear Attention
만약 입력 feature map x \in \mathcal{R}^{N \times f} 가 있다고 할 때 일반적으로 많이 사용하는 transformer의 self-attention을 다음과 같이 표현할 수 있습니다.
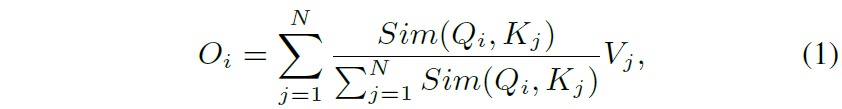
여기서 Q와 K와 V는 각각 x에다가 fc layer를 태워서 만든 것으로 이해하시면 됩니다. Sim() 함수는 두 행렬의 유사도를 측정하는 함수로 보통 아래 수식과 같이 Query Key 간에 내적 후 softmax를 취하곤 하죠.
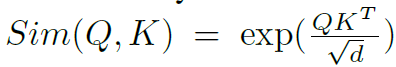
여기서 Sim function을 위와 같이 softmax를 활용하는 self-attention을 softmax attention이라고 명칭할 것입니다. 아무튼 이러한 soft attention에서 우리는 이와 유사하지만 조금 다른 Sim function을 정의할 수 있는데, 바로 ReLU activation function입니다.
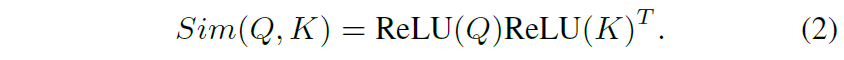
즉 수식2와 같이 Sim을 Query와 Key에 각각 ReLU activation을 적용한 후, 둘 사이에 내적을 하는 것으로 바꿔버리는 것이죠. 이렇게 하게 될 경우 수식1의 self-attention 수식을 아래와 같이 다시 쓸 수 있습니다.
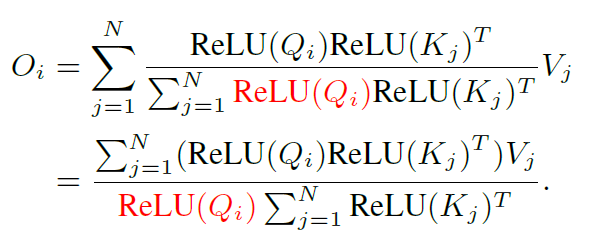
여기서 시그마는 j에 대하여 적용된 것이기 때문에, i번째에 대한 Query는 상수 취급을 받아서 시그마 바깥으로 보낼 수가 있게 되며 이를 나타낸 것이 분모에 붉은색 텀을 의미합니다.
그 다음에는 행렬곱의 결합법칙을 통해서 계산복잡도와 메모리를 N제곱에서 N으로 낮출 수 있도록 할 수 있습니다.
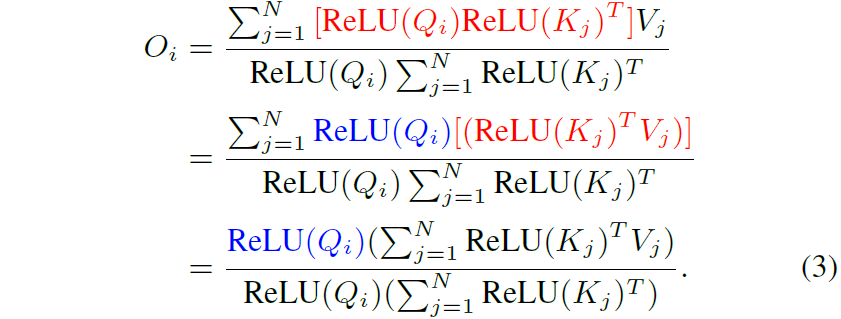
위에서부터 차근차근 살펴보시면, ReLU(Q)와 ReLU(K)에 대해 분모에서 그랬던 것처럼 분자의 ReLU(Q)도 시그마 바깥으로 보낼 수가 있게 됩니다(파란색 텀). 그리고 ReLU(K)는 Value와 함께 내적연산을 수행하면 되는 것이죠.
이렇게 Key, KeyValue 내적을 한번 구해놓으면 그 이후에는 Query에 대하여 모두 적용하면 되기에 연산량이 확 줄어든다는 내용입니다. shape 관점에서 더 쉽게 설명드리면, 기존에는 Query와 Key의 내적을 통해서 N x f * f x N == N x N의 행렬이 만들어지게 되는데, 이때 N이 영상의 HW에 해당하기에 제곱에 해당하는 메모리와 연산량이 요구됩니다.
하지만 수식3과 같이 Key와 Value가 먼저 내적 연산이 되는 것이다보니 f x N * N x f == f x f 꼴로 feature map의 채널의 제곱 사이즈의 행렬이 나오게 되며 해당 행렬을 Qeury (N x f)와 내적하는 것이기 때문에 결과적으로 N에 Linear하다고 볼 수 있게 되는 것이죠.
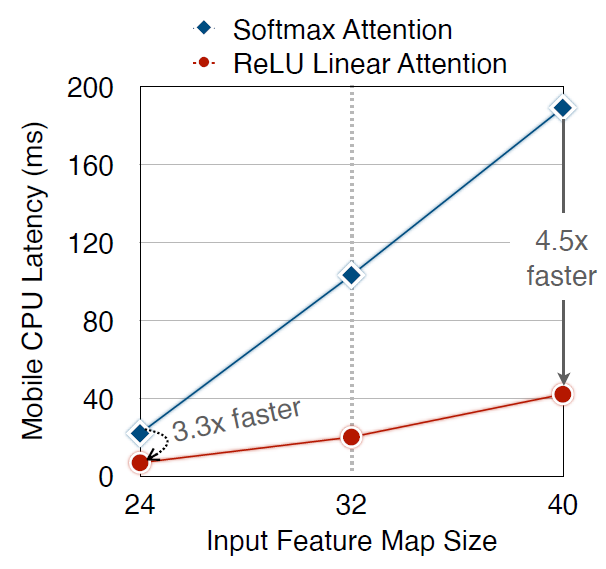
실제로 이렇게 연산을 하게 될 경우에 입력으로 사용되는 feature map의 사이즈에 따라서 mobile cpu latency가 softmax attention과 비교하여 최대 4.5배 더 빠르다고 합니다.(그림4 참조)
Address ReLU Linear Attention’s Limitations
하지만 이러한 ReLU Linear Attention도 한계점이 명확하게 존재합니다. 아무래도 ReLU 기반의 attention은 non-linear하기 때문에, softmax와 달리 보다 집중된 attention map을 만들기 어려워하며 이는 곧 local information을 포착하기 어려움을 의미하다고 합니다.

그림5를 살펴보면, Softmax attention은 non-linear similarity function이기에 보다 sharp distribution을 가지는 반면에, ReLU는 attention score의 distribution이 상당히 넓게 퍼져있는 것을 볼 수 있으며, 이러한 점들은 모델이 local information을 포착하는데 한계점을 가진다고 지적합니다.
그래서 저자들은 부족한 local information은 FFN에 DWConv를 적절히 섞어서 보완하였다고 합니다. 그리고 small-kernel depthwise-separable convolution을 통해 Q,K,V 토큰을 multi-scale로 만들어 ReLU attention을 수행함으로써 이 부분들을 더 보완할 수 있었다고 합니다.
multi-scale을 만드는 과정에서 저자는 연산 효율성을 고려하기 위해, 모든 DWConv는 하나의 DWConv로 통합되고, 1×1 conv의 경우에는 하나의 1×1 group convolution으로 통합시켰다고 합니다. 구체적으로 #헤드에 대해 3x#의 그룹으로 구성하였으며 각 그룹별로 채널의 개수는 d로 설정하였다고 하네요.
EfficientViT Architecture
그럼 EffcientViT의 전체 architecture는 어떻게 생겼는지 알아보겠습니다.
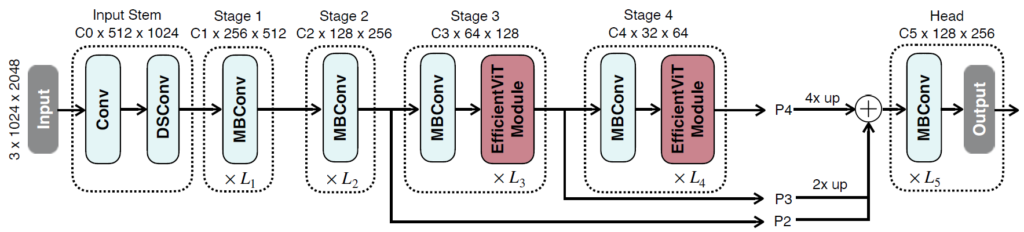
그림6을 살펴보시면 일반적인 backbone들과 비슷하게 Input Stem과 Stage 1~4로 구성이 되는 것을 확인하실 수 있습니다. 여기서 모델의 효율성을 위해 Attention 연산을 수행하는 EfficientViT Module은 16배, 32배 down sampling이 되는 Stage 3,4에서만 진행되는 것을 확인하실 수 있습니다.
다만 본 backbone은 image classification이 아닌 semantic segmentation과 같은 dense prediction task에 초점을 맞춘 것이기 때문에, stage3의 4에서의 output 결과들이 bilinear interpolation과 1×1 conv를 통해 1/8 resolution scale로 upsampling이 된 후 Stage2의 output과 element-wise sum으로 더해진다고 합니다.
그리고 각 Stage 별로 MBConv라고 표기된 부분들이 있는데, 해당 모듈은 본 논문에서 제안한 것은 아니고, EfficientNet에서 활용하는 기본 구조라고 합니다. 대충 Depthwise Separable Convolution과 SENet의 Squeeze and Extention module을 적절히 섞은 구조라고 하는데, 모델의 효율성과 성능을 고려한 구조라고 이해하시면 되겠습니다.
Experiments
그럼 실험결과들에 대해 살펴보고 리뷰 마무리 짓도록 하겠습니다. 가장 먼저 ablation study에 대해서 살펴보겠습니다.
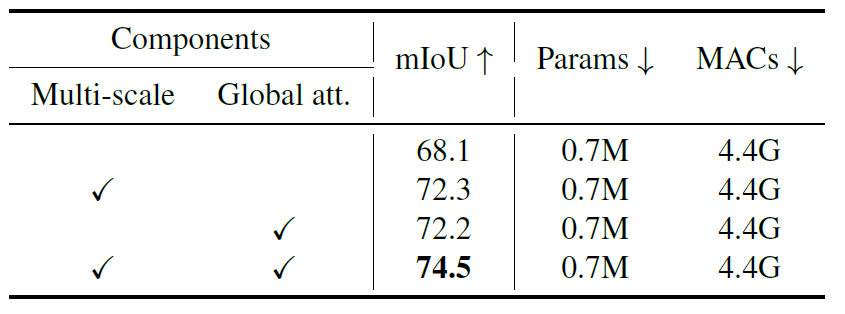
Multi-scale은 Multi-scale Learning을 위해 Q/K/V 각각에게 3×3, 5×5 커널 사이지를 가지는 DWConv를 태워서 ReLU Linear Attention을 수행한 것을 의미하며, Global Attention은 말그대로 ReLU Linear Attention 사용 여부를 말하는 것으로 보여집니다. 보시다시피 각각의 모듈들은 Cityscape의 Semantic Segmentation에서 중요한 성능 향상을 보여주고 있습니다.
그리고 각각의 모듈들의 존재 여부가 다름에도 parameter 수와 MACs(multiplication and accumulation count)의 값이 모두 같은 것을 볼 수 있는데, 이는 각 모듈이 추가됨으로써 늘어나는 연산량에 따라 성능이 향상된 것이 아니냐는 의심을 피하기 위해, 모두 동일히 맞춰주기 위하여 모델의 width를 키워주었다고 합니다.
아무튼 여기서 중요한 점은, multi-scale learning과 global attention은 dense prediction task에서 상당히 중요한 역할을 한다는 점이며, 저자가 제안하는 EfficientViT module이 그 역할들을 충실히 수행해주고 있다는 점입니다.
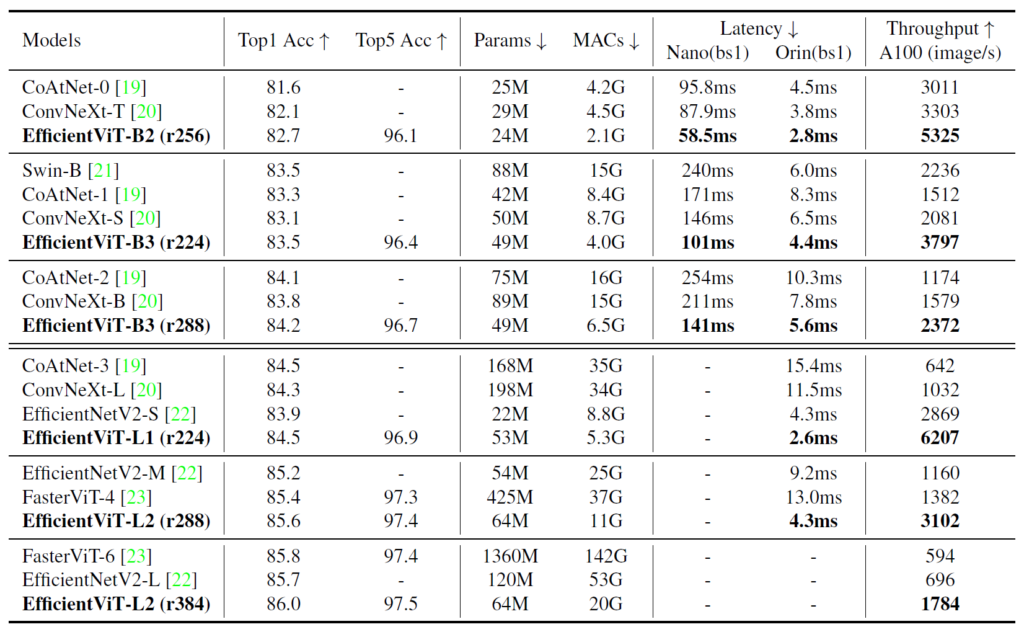
다음은 ImageNet classification에 대한 성능입니다. 아무래도 backbone 연구이기 때문에, dense prediction task에 초점을 맞추었다고 해도 classification에 대한 table을 전혀 넣지 않을 수가 없었던 모양입니다.
보시면 제안하는 방법론이 다른 기존의 백본들, Swin이나 ConvNeXt와 비교하여 비슷한 성능을 보이거나 조금 더 좋은 성능을 보여주고 있습니다. 결국 성능적인 측면에서만 보면 엄청 막 유의미한가 라고 보여지긴 하지만, 실제 모델의 사이즈 및 추론속도 관점에서 보면 상당히 빠르고 효율적으로 동작하는 것을 확인할 수 있습니다.
결국 비슷하거나 조금 더 좋은 성능에 굉장히 빠른 추론 속도를 보여준다는 점에서 해당 논문이 매우 매력적인 것이 아닌가 합니다.
다음은 Semantic Segmentation에 대한 SoTA 방법론들과의 비교 입니다.
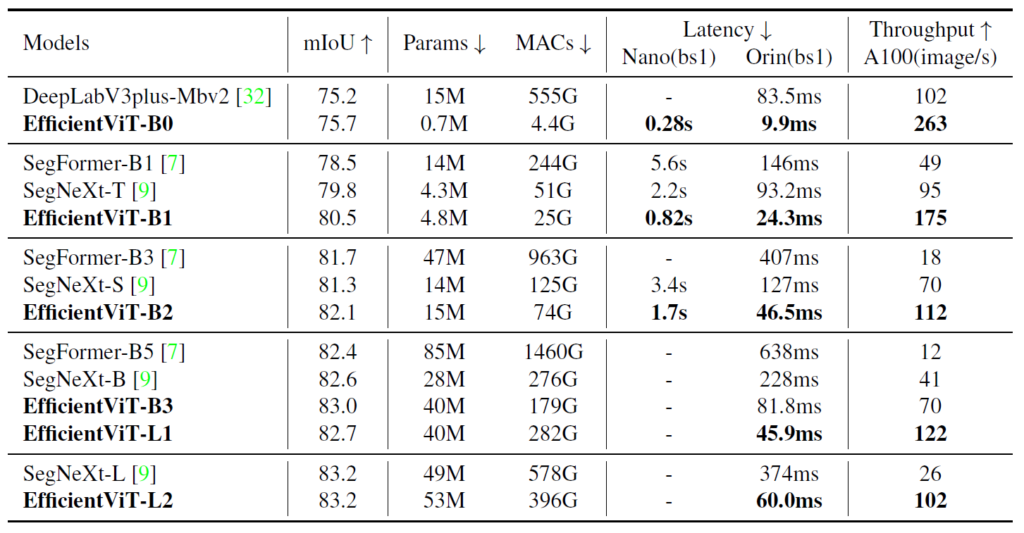
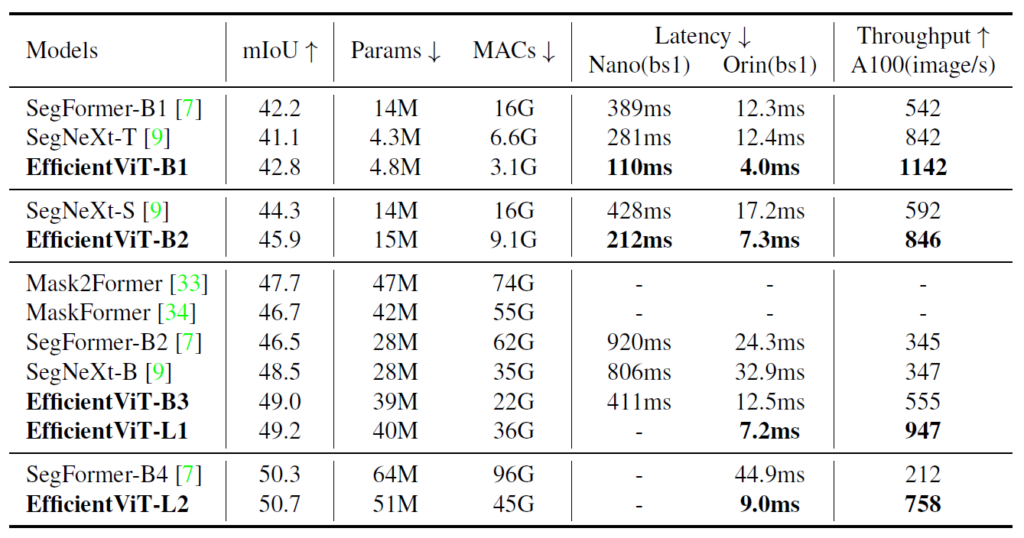
보시면 EfficientViT가 SegNeXt와 비교해서 파라미터 수는 비슷하지만 MAC은 훨씬 작은 것을 볼 수 있고 따라서 1초에 처리할 수 있는 영상수도 훨씬 많은 것을 알 수 있습니다. 이렇게 가볍고 빠른 반면에 성능은 항상 더 좋은 모습을 보여주는 것이 매우 매력적으로 보여지네요.
Segment Anything
본 논문이 더 재밌었던 점은, 자신들이 제안하는 백본으로 SAM을 수행할 경우 유사한 성능에 훨씬 가볍고 빠르게 추론이 가능하다는 점입니다. 먼저 SAM의 Encoder로는 기존 사전학습된 SAM의 ViT-Huge 모델의 embedding feature를 train target으로 삼아 학습을 시켰으며 prompt encoder와 mask decoder는 기존의 것을 그대로 활용하였다고 합니다.
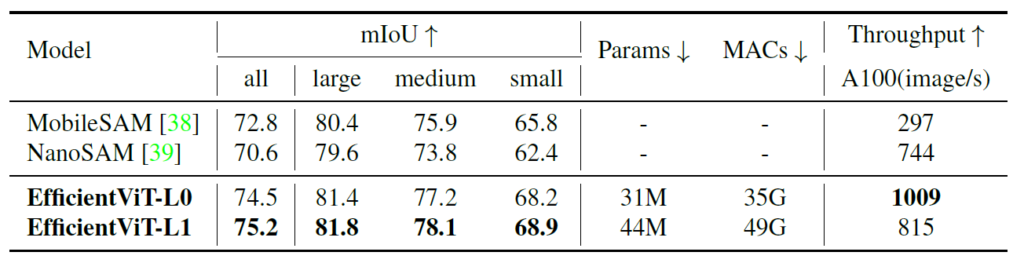
그 결과 COCOVal2017에서 zero-shot learning으로 MobileSAM, NanoSAM보다 더 좋은 성능을 기록하면서 throughput은 더 빠르게 가져갈 수 있었다고 합니다.

그리고 위에 그림과 같이 실제 ViT-Huge 기반의 SAM은 12 FPS가 나오는 반면, EfficientNet은 1009FPS가 나온다는 점에서 유사한 결과에 상당히 빠른 추론속도를 보여준 것을 확인할 수 있습니다.
결론
Dense Level Prediction을 수행할 때 ReLU Linear Attention을 활용하는 것이 좋아보이네요.
안녕하세요 신정민 연구원님 좋은 리뷰 감사합니다.
[그림3]의 오른쪽 부분을 보면 input을 Q, K, V로 나누어서 각각 ReLU Linear Attention을 진행하는 것으로 보이는데요, 그렇다면 이때 Q를 attention모듈에 입력하면 모듈 내에서 다시 q,k,v로 나뉘어 sim(q,k)*v가 진행되는 건가요? 그리고 Q, K, V가 각각 relu attention적용된 결과를 concat한 뒤 linear를 태운 것이 결과값으로 출력된다면 Q,K,V로 attention을 진행하는 것이 아니라 그냥 fusion하는 것이 아닌지 의문입니다.