이번 주차 X-Review는 23년도 ICCV에 게재된 <UATVR: Uncertainty-Adaptive Text-Video Retrieval>이라는 논문입니다. 중국 바이두에서 연구된 논문이네요.
Text-Video Retrieval(이하 TVR)이라는 task는 비디오와 text 두 모달 간 공통의 embedding space를 학습하고, 한 모달에서의 쿼리가 들어왔을 때 상대 모달의 데이터로 구성된 데이터베이스 내 모든 샘플들과 유사도를 측정하여 가장 유사한 샘플을 찾아내는 검색 task에 해당합니다. 일반적으로는 비디오를 쿼리로 던져 text를 검색하는 v2t 검색 성능과 text를 쿼리로 던져 비디오를 검색하는 t2v 검색 성능을 모두 측정하여 비교합니다.

본 논문을 읽은 이유는, 현재 IEEE Access 논문 작업에 참고중인 Probabilistic Cross Modal Embedding(PCME)의 확률적 임베딩 파이프라인을 대부분 따라가며 기존 PCME의 영상 도메인을 비디오 도메인으로 확장하며 CLIP까지 함께 사용한 연구이기 때문입니다. TVR task 자체는 제가 연구중인 Weakly-Supervised Temporal Action Localization(WTAL)과는 좀 결이 다르지만 결국 저는 CLIP embedding space로부터 출발하여 WTAL을 video-text 간 공통의 embedding space 구축으로 풀고자 시도중이기에 충분히 참고할만한 논문이었습니다.
이전에 제가 X-Review와 세미나에서 다뤘던 아래 논문(ProViCo)을 알고계신다면 본 리뷰를 이해하는 것이 굉장히 수월하실 것입니다.
그럼 바로 Introduction을 살펴보며 기존 연구 대비 UATVR의 차별점을 짚어보겠습니다.
2. Introduction
지금껏 읽어왔던 비디오 관련 논문들의 시작은 항상 급부상하고 있는 비디오 플랫폼과 task에 대한 수요의 증가에 대한 이야기였습니다. 그래서 딱히 리뷰에까진 옮겨적지 않았었는데, TVR이야말로 저희가 실생활에서 가장 많이 적용되는 Video 관련 task 중 하나겠다는 생각이 들었습니다. YouTube에서 비디오를 검색하는 과정 자체가 T2V retrieval에 해당되는 것이겠죠. 지금까지 TVR task 논문을 딱히 읽어보려고 생각하진 않았는데, 이번 논문 작업을 하 video-text 멀티모달 간 학습에 흥미가 좀 생겨 앞으로도 종종 follow-up 할 계획입니다.
아무튼 다시 본문으로 돌아오자면, 21년도 이후 CLIP이나 Florence와 같은 거대 영상-text 사전학습 모델이 나온 뒤로 두 모달의 joint embedding space를 요하는 많은 task들이 득을 보게 되었습니다. 물론 VTR은 비디오를 다루기에 바로 적용하기엔 어렵지만 영상 도메인에서 구축되어있는 거대 모델들의 표현력을 비디오 도메인으로 확장시키려는 연구가 많았고, 이를 통해 few-, zero-shot 상황에서 높은 성능을 보여주며 사전학습 embedding space의 일반성을 입증하기도 하였었습니다. 제가 최근에 다룬 리뷰들도 대부분 그러한 흐름 속에 있었습니다.
기존 TVR 방법론들의 가장 단순한 프레임워크는 우선 비디오와 text를 각각 하나의 벡터로 표현해주며 시작합니다. 이후엔 어떤 비디오가 어떤 텍스트와 쌍을 이루는지, 반대로 어떤 텍스트가 어떤 비디오를 설명하고 있는 것인지에 대한 annotation 정보를 가지고 있기에 상대 모달에 있는 pair feature들 가깝게, pair가 아닌 feature들은 멀어지도록 학습을 수행하였습니다.
이후에 좀 더 발전하며 FILIP이나 ALBEF와 같은 multi-grained TVR 패러다임이 등장하게 됩니다. 앞서 설명한 가장 단순한 프레임워크에서는 비디오 프레임 별 feature를 추출해 이들을 시간 축에 대해 모두 평균내어 하나의 비디오 feature로 사용하였습니다. 하지만 이러한 feature는 검색되어야 하는 text와 관련 없는 프레임들까지 모두 평균 연산에 관여하기 때문에 최적이라고 보기엔 어렵습니다.
이러한 문제를 겪는 와중, multi-grained TVR 방법론들은 비디오를 더욱 짧은 단위의 클립, 주어진 text 문장을 더욱 작은 단위인 단어로 쪼개 다양한 level에서의 학습을 진행하였습니다. 예를 들면 sentence-frame, phrase-clip, word-frame 등의 다양한 세부 레벨에서 cross-modal interaction을 수행하게 되는 것이겠죠.
하지만 저자의 주장에 따르면 이와 같은 기존 방법론들이 적절한 비디오-text 매칭을 위한 최적의 granularity에 대해 고민하지 않고, 이를 정한다고 해도 비디오마다, 프레임마다, 문장마다, 단어마다 내재되어있는 uncertainty로 인해 어떤 level에서의 cross-modal interaction이 최적일지는 쉽게 결정할 수 없다고 이야기합니다.
데이터셋에 따라 비디오마다, 또 text마다 matching 되어야 하는 granularity가 다를 것입니다. 즉, 어떠한 데이터셋의 비디오에서는 프레임-단어 간의 연결이 잘 되어야 높은 성능을 달성할 수도 있고, 또 다른 데이터셋의 비디오에서는 비디오-문장 단위의 연결성이 중요할 수도 있는 것입니다. 하지만 좋은 TVR 모델은 어떠한 granularity이든, 이에 구애받지 않는 표현력을 갖춰 두 모달 간의 올바른 유사도 함수를 학습할 수 있어야 하는 것입니다.

위 그림 1을 통해 기존 TVR 방법론의 uncertain matching problem에 대해 알아볼 수 있습니다. 사실 비디오를 좀 더 fine-grained 한 level에서 학습시키기 위해 쪼갠다면 이는 클립 또는 프레임이 되고, 마찬가지로 text(paragraph)를 쪼갠다면 sentence 내지는 word가 될것입니다. 하지만 위와 같이 사전에 정의된 특정 level(video-sentence, frame-word, clip-sentence 등등)에서의 다양한 매핑을 수행할 때 특정 level 끼리 만들어낸 조합 중 어떤 조합이 최적일지 알아내기 힘들 뿐더러 조합의 수는 고정적이기에 그 어떠한 조합도 실질적으로는 최적이 아닐 수 있다는 것인데, 기존 방법론들은 이러한 조합의 최적성 대해 고민하지 않고 있었다는 이야기입니다.
또한, 데이터를 확률적 분포로 바라보지 않는 모든 기존 방법론들은 deterministic approach라고 볼 수 있는데, 이러한 방법론들은 visual feature와 textual feature 간 일대일 매핑 및 학습만 가능합니다. 즉 하나의 비디오도 다양한 문장으로 표현할 수 있고, 한 문장이 다양한 모습의 비디오를 표현해줄 수도 있는 것인데 기존의 결정적 방법론들로는 이러한 상황과 같은 다양성을 모델링하기 힘들다는 것입니다.
위 두 가지 문제점을 다루기 위해 저자는 TVR에 learnable parameter와 확률적 임베딩을 적용합니다. Visual, Textual feature에 learnable parameter를 붙임으로써 uncertain matching problem의 원인인 특정 granularity로의 분할을 완화할 수 있으며, 확률적 임베딩을 통해 일대다 매을 가능케 하는 것입니다. 저자는 본 방법론인 Uncertainty-Adaptive Text-Video Retrieval을 줄여 UATVR이라 부릅니다.
우선 본 논문의 방법론 부분은 굉장히 쉽고 간단합니다. 앞서 언급한 각 문제점을 다루는 두 가지 모듈이 제안되었겠죠. 첫 번째는 Dynamic Semantic Adaptation(DSA) 모듈로, 단순히 CLIP encoder를 타고 나온 비디오와 text feature가 특정 granularity에 종속되지 않도록 learnable parameter를 일부 붙이고 다시 모델링하는 것입니다.
두 번째는 Distribution-based Uncertainty Adaptation(DUA) 모듈이고 여기서는 앞서 DSA 모듈에서 얻은 feature를 확률분포로 표현해줍니다. 기존에는 두 모달 모두 결정적 feature로 표현되어 일대일 매만이 가능했다면 이제는 특정 feature를 확률분포로 표현한 뒤 해당 분포에서 몇 개의 샘플을 추출해 일대다 매핑이 가능하도록 설계한 것입니다. 이를 통해 좀 더 일반성을 갖는 추론이 가능해질 것입니다.
이제 저자가 이야기하는 논문의 Contribution을 정리한 뒤 방법론으로 넘어가도록 하겠습니다.
Contribution
- Model video and text representations as probabilistic distributions and align them through multiple instance contrast in their common embedding space for uncertainty adaptive cross-modal matching
- Flexible high level reasoning by adding learnable tokens(parameters), allowing deterministic semantic uncertainty adaptation in videos/texts
- SOTA results across public benchmarks, including MSR-VTT, MSVD, VATEX, and DiDeMo
2. Method
가장 먼저 기존의 TVR 파이프라인을 가볍게 살펴보고, Introduction에서 잠시 이야기한 두 모듈(DSA, DUA)의 세부 사항을 순서대로 알아보겠습니다.
2.1 Preliminary
Problem Definition
기본적으로 TVR의 학습 중 목적은, 두 모달 간 지정된 pair에 대해서는 유사도 함수 s(\cdot{})가 높은 점수를, 이외에는 낮은 점수를 만들어내는 것입니다. Pair를 구성하는 text 정보 t_{i} \in{} \mathbb{R}^{N+1}, 비디오 정보 v_{i} \in{} \mathbb{R}^{M \times{} 3 \times{} H \times{} W}가 주어집니다. Text 문장은 총 N개의 단어, 비디오는 총 M개의 프레임으로 구성됩니다.
다시 정리하자면 t_{i} = [w_{i}^{0}, w_{i}^{1}, \cdots{}, w_{i}^{N}]으로 여기서 w_{i}^{0}는 해당 문장의 [CLS] 토큰을 의미합니다. 다음으로 v_{i} = [f_{i}^{1}, f_{i}^{2}, \cdots{}, f_{i}^{M}]에 해당하고 각 f_{i}^{m}는 i번째 비디오 내 m번째 프레임의 [CLS] 토큰에 해당합니다. Transformer 기반 encoder를 사용하는 상황을 가정하는 듯 합니다.
최종적으로 유사도 계산에 사용될 비디오 feature \boldsymbol{v_{i}}와 text feature \boldsymbol{t_{i}}는 아래 수식 (1), (2)와 같습니다. 수식 (3)은 두 모달 feature의 유사도를 의미하는데 여기서 <\cdot{}>은 단순 내적을 의미합니다. 수식엔 나와있지 않지만 두 feature를 normalize 후 내적한다고 하니 결국 수식 (3)은 cosine 유사도에 해당합니다.
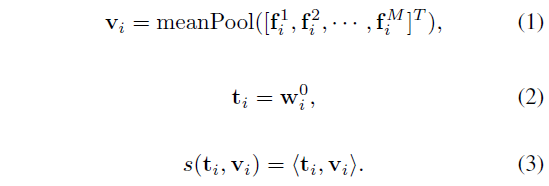
수식 (3)까지의 과정을 통해 각 모달의 데이터를 featurize 후 유사도까지 구할 수 있었으니 이제는 가지고 있는 pair label을 이용해 학습하면 됩니다. 하나의 미니배치 크기를 B라고 하였을 때, 두 모달 간 대칭적인 CE Loss는 아래 수식 (4), (5)와 같습니다.
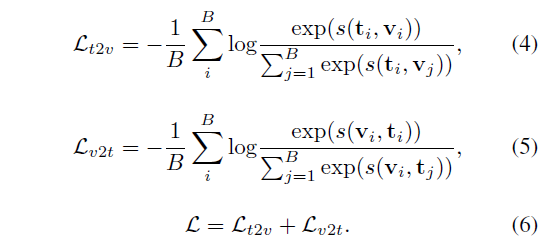
i, j 인덱스를 유념하며 수식 (4), (5)를 보면 결국 B \times{} B 형태의 유사도 매트릭스 내 대각 원소, 즉 pair를 구성하는 feature 간의 유사도를 최대화해준다는 점을 알 수 있습니다. 수식 (6)은 최종 loss \mathcal{L}로, 비디오를 기준으로 배치 내 모든 text feature와의 loss \mathcal{L}_{v2t}와 text를 기준으로 하 배치 내 모든 비디오와의 loss \mathcal{L}_{t2v}를 더해주는 모습이네요.
Fine-grained Interactions
앞서까지 본 내용은 가장 naive한 TVR 파이프라인이었습니다. 수식 (1)과 같이 비디오 feature를 기술할 때 모든 프레임의 [CLS] 토큰을 평균 내어버리면, 비디오에는 실제로 text feature가 담고 있는 정보 이외 다른 부분들까지 모두 반영되며 유사도를 구할 때 일종의 noise로 작용하게 될 것입니다. 그래서 이후 방법론들은 multi-grained cross-modal interaction 기법을 제안하였었습니다. 본 논문의 방법론인 UATVR도 multi-grained cross-modal interaction 기법의 파이프라인을 베이스라인으로 삼고 있습니다.
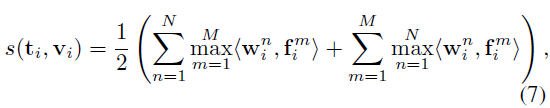
이 파이프라인에선 비디오와 text 간 유사도를 구하는 방식이 달라집니다. 수식 (7)에는 단어 개수 인덱스 n과 프레임 개수 인덱스 m이 등장합니다. 첫 번째 텀을 기준으로 해석해보면, 먼저 하나의 단어가 비디오의 모든 프레임과 갖는 유사도를 계산해줍니다. 이후 가장 큰 유사도 값을 해당 단어와 비디오의 유사도로 두고, 이를 text feature 내 모든 단어에 대해 수행해 합해줍니다.
이를 반복하는 과정에서 단어 개수가 많거나 비디오 프레임이 많은 경우 유사도가 커지기에 평균 내어 사용한다고 합니다. 아무튼 수식 (7)에서의 핵심은 비디오는 프레임으로, 문장은 단어로 쪼개 하나 낮은 level에서의 유사도를 고려하였다는 점입니다.
이제 기존 방법론과 베이스라인에 대한 간단한 설명은 마쳤으니, UATVR에서 제안하는 두 가지 모듈에 대해 살펴보겠습니다.
2.2 Dynamic Semantic Adaptation
저자가 언급한 첫 번째 문제점은 어떠한 level의 entity 조합이 최적인지 찾는 것은 힘들다는 uncertain matching problem이었습니다. 조합도 조합이지만 비디오를 클립 또는 프레임으로, text를 문장 또는 단어라는 결정적 단위로 내려 aggregate 해야 한다는 점이 애초에 최적일 것인지에 대한 의문을 제기하는 것입니다. 따라서 저자는 learnable parameter를 활용한 다양한 level에서의 동적 aggregation 방식을 DSA 모듈에서 제안합니다.
프레임 feature와 word feature 각각을 backbone 모델에 태워 얻은 \{\boldsymbol{f_{i}}\}_{m=1}^{M}와 word feature \{\boldsymbol{w_{i}}\}_{n=1}^{N}에 추가적인 learnable parameter C_{t}개, C_{v}개씩 붙여줍니다.
각 모달 feature에 learnable parameter를 붙인 후에 CLIP4Clip에서 제안한 SeqTransformer를 태워 learnable parameter가 붙은 형태의 feature에 attention 연산을 한 번 적용해줍니다. SeqTransformer는 일반적으로 저희가 아는 Transformer 형태와 같으며, CLIP4Clip에서 제안할 때 여러 접근법들을 구분하기 위해 Sequential이라는 단어를 붙인 것입니다.
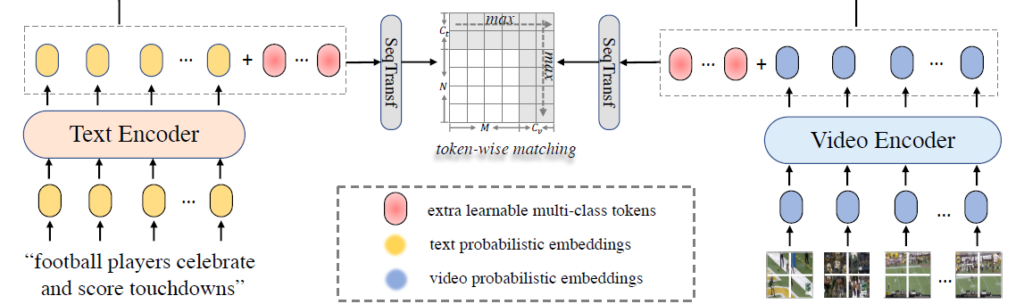
위 그림은 제가 앞서 설명한 흐름과 동일합니다.
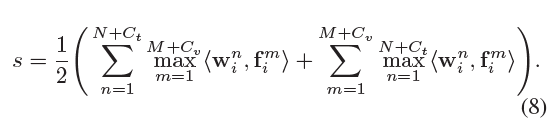
수식 (8)은 DSA 모듈에 적용되는 유사도 연산 방식입니다. 이는 수식 (7)에서 Fine-grained 접근법이 제안한 유사도 연산 방식과 거의 유사하지만 C_{t}개, C_{v}개의 추가된 learnable parameter들이 포함된다는 점이 다릅니다.
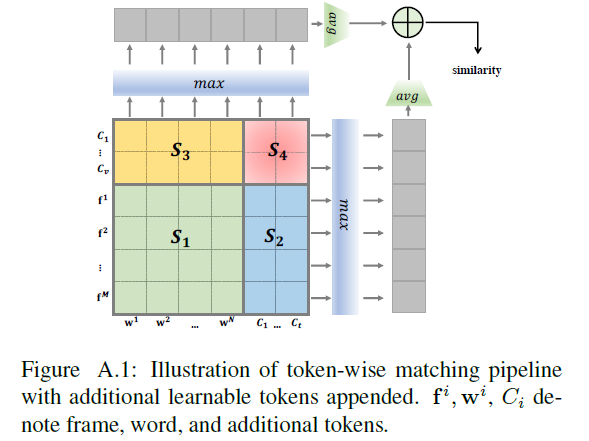
Appendix에 첨부된 그림 A.1은 수식 (8)을 시각화한 것으로, learnable parameter의 관여 여부에 따라 Similarity matrix의 영역을 S_{1}, S_{2}, S_{3}, S_{4}로 나눠볼 수 있습니다. 위 영역 별 성능은 추후 실험 부분에서 다루도록 하겠습니다.
2.3 Adaptive Distribution Matching (DUA module)
앞 절에서 설명한 DSA 모듈로 애매한 level 및 최적의 entity 조합 문제를 어느정도 해결하였습니다. 하지만 저자가 두 번째로 언급한 문제인 TVR task에서의 one-to-many mapping의 부재는 여전히 존재하는 상황입니다. 하나의 비디오를 쿼리로 던졌을 때 이를 설명할 수 있는 text는 셀 수 없이 많고, 반대로 하나의 text를 쿼리로 던졌을 때 이를 표현하는 비디오도 굉장히 많을 것입니다. 그렇기 때문에 기존 one-to-one 방식이 다양성 및 일반성 측면에서 부족하다고 이야기하는 것입니다.
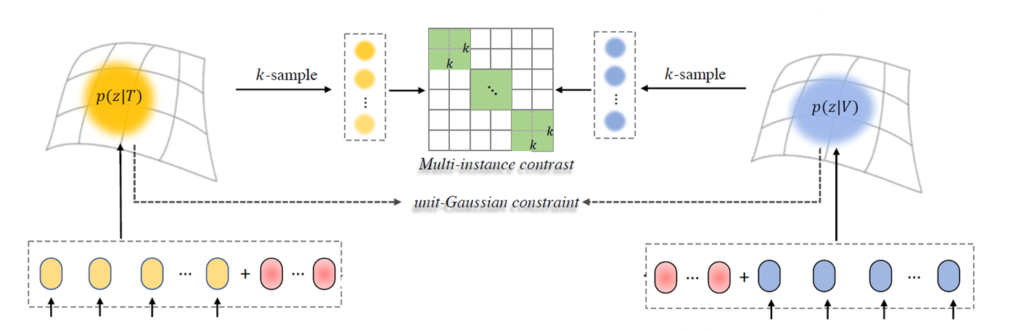
우선 DUA 모듈의 입력은 CLIP encoder로부터 나온 deterministic text/비디오 feature입니다. 이 때는 DSA 모듈에서 적용하였던 learnable parameter들은 제외되고 text는 N개, 비디오는 M개의 토큰만을 사용합니다. 저자는 이를 caption feature \boldsymbol{t_{i}}와 비디오 feature \boldsymbol{v_{i}}로 표현하고 있습니다.
이제 일대다 매핑을 만들어주기 위해 \boldsymbol{t_{i}}, \boldsymbol{v_{i}}를 각각의 확률분포 p(z|t_{i}), p(z|v_{i})로 표현해주어야 합니다. z는 확률적 임베딩 공간을 의미하는 것입니다. 일반적으로 이와 같은 확률적 임베딩은 결정적 feature가 정규 분포를 따를 것으로 가정하고 평균 \mu{}와 표준편차 \sigma{}를 추정하게 됩니다. 제가 지금껏 follow-up한 딥러닝 기반의 확률적 임베딩 방법론들은 아래 수식 (9)와 같이 FC layer를 통해 이들을 추정해줍니다.
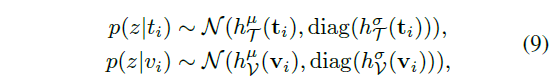
수식 (9)에서 h^{\mu{}}는 평균을 만들어내는 head로, FC + LN + L2 normalization으로 구성됩니다. 또한 h^{\sigma{}}는 표준편차를 만들어내는 head로 이후 연산에서 분포가 깨지는 것을 방지하기 위해 단순 FC layer로만 구성됩니다. 이 형태는 확률적 임베딩 방법론의 전신인 PCME 또는 이전에 설명드렸던 논문인 ProViCo와 완전히 동일합니다.
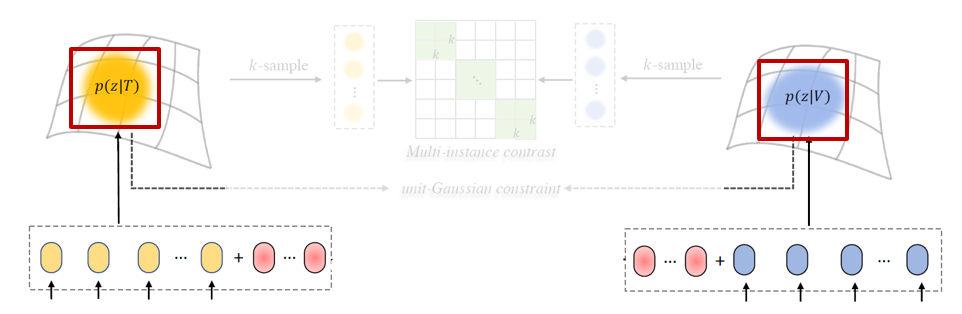
현재 위 그림과 같이 결정적 feature들을 붉은 박스 쳐진 확률적 분포로 표현한 상태입니다. 하지만 이는 어디까지나 분포에 해당하기 때문에 실제 학습의 대상이 될 sample들을 분포로부터 가져오는 과정이 필요합니다.
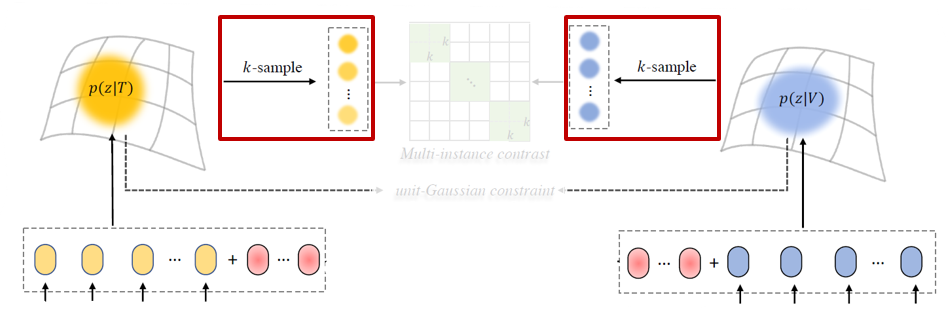
위 그림에서 붉은 박스 쳐진 부분이 확률분포로부터 학습의 대상 instance들을 샘플링 해오는 부분입니다. 이러한 샘플링 과정 중에서의 원활한 backpropagation을 위해, reparameterization trick이 사용됩니다. 각 모달로부터 독립 항등 분포를 따르는 샘플 K개를 가져올 예정입니다.
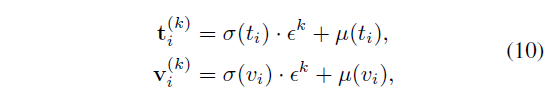
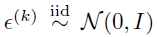
Reparameterization trick이 말은 어렵지만 사실 수식 (10)에 해당합니다. 우선 단위 정규분포로부터 독립 항등 분포를 따르는 K개의 {\epsilon{}}_{k=1}^{K}를 추출합니다. Text feature를 기준으로 보면, 확률분포의 평균 \mu{}(t_{i})를 기준으로 확률분포의 표준편차 \sigma{}(t_{i})에 작은 변동을 갖는 수 \epsilon{}^{k}를 곱해 더해주게 됩니다.
이 수식은 결국 확률분포 p(z|t_{i})로부터 평균을 기준으로 조금씩 변형된 샘플 feature K개를 만들어낸다고 해석할 수 있습니다. \epsilon{}^{k}가 독립 항등 분포를 따르기에 얻어낸 샘플들 t_{i}^{(k)}도 기존 확률분포로부터 독립 항등 분포를 따라 샘플링 되었다는 것을 이해할 수 있습니다.
이제 확률분포로부터 학습의 대상이 될 샘플을 얻는 과정까지 모두 마쳤으니, 샘플들에 대한 pos, neg group을 지정하고 학습을 수행하면 끝입니다.
우선 기존의 방법론들은 pos, neg 샘플을 지정한 후 Soft Contrastive Loss를 적용하였습니다. 이는 아래 ProViCo 수식 (8), (9)를 통해 알아볼 수 있습니다.
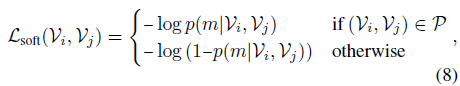
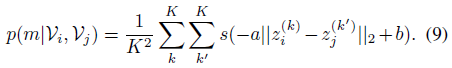
ProViCo는 두 비디오 간 분포를 최적화하기 때문에, Monte-Carlo 추정 기법에 따라 각 비디오 분포에서 샘플링한 K개 끼리의 matching probability를 수식 (9)와 같이 L2 distance를 기반으로 측정하는 것을 볼 수 있습니다. 하지만 저자에 따르면, 이와 같은 방식을 TVR에 적용했을 때 좋은 성능이 나오지 않아 기존 TVR 방법론들처럼 두 feature의 내적을 통한 유사도로 Multi Instance NCE Loss로 학습했다고 합니다. 이에 대한 ablation은 실험 부분에서 살펴보겠습니다.
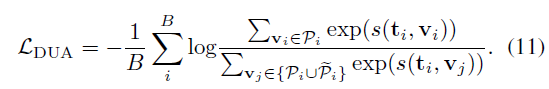
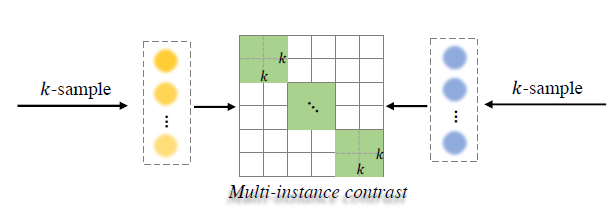
결론적으로 DUA 모듈에서 사용하 Multi Instance NCE Loss는 수식 (11)과 같습니다. Text feature를 기준으로 하는 positive set \mathcal{P}_{i}는 pair를 이루는 비디오의 확률분포에서 샘플링한 K개의 샘플들입니다. Negative set \tilde{\mathcal{P}}_{i}는 미니배치 크기 B 내 \mathcal{P}_{i}의 여집합입니다. 이를 시각화하면 아래 그림과 같습니다. 초록색이 같은 pair로부터 얻었기에 유사도를 최대화해야하는 영역이겠죠.
2.4 Total Objectives
마지막으로 확률분포의 표준편차 \sigma{}가 0으로 붕괴되는 것을 방지하기 위해 기존 PCME나 ProViCo 등에서도 적용해주었던 단위 정규분포와의 KL Divergence Loss, 수식 (12)도 함께 사용하였습니다.
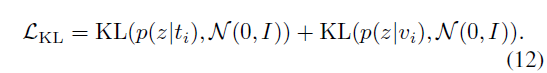
이에 따라 UATVR 학습에 사용되는 최종 loss \mathcal{L}은 아래 수식 (13)과 같습니다.
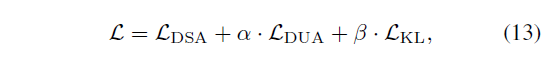
수식 (13)에서 \mathcal{L}_{DSA}는 앞서 설명한 유사도 수식 (8)을 적용한 수식 (6)에 해당합니다. 나머지 각각은 수식 (11), (12)와 같습니다.
3. Experiments
UATVR의 벤치마킹은 MSR-VTT, MSVD, DiDeMo, VATEX 데이터셋에서 이루어졌습니다. 평가지표로는 retireval의 결과 상위 K개 중 실제 GT의 존재 여부를 따지는 Recall@K(R@K)와, Ranking list의 GT 순위 중위값인 Median Rank(MdR), 평균값인 Mean Rank(MnR)가 사용되었습니다.
UATVR은 기본적으로 ViT/B-16 backbone의 CLIP image, text encoder를 사용하였습니다.
3.1 Ablation Study
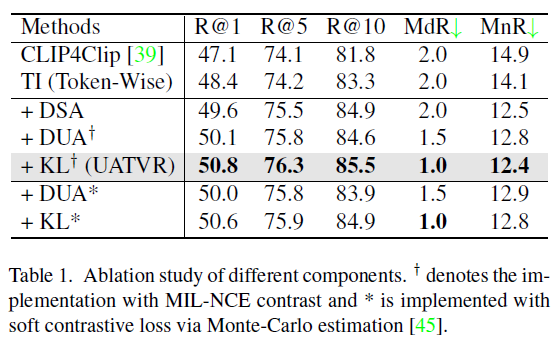
우선 대표적인 TVR 데이터셋인 MSR-VTT에서의 module-wise ablation 성능입니다. 모듈 별 loss가 하나이기에 loss ablation으로도 볼 수 있을 것입니다. 베이스라인이 되는 TI 방법론은 UATVR에서 learnable parameter와 probabilistic embedding, KL Div loss가 추가되지 않은 성능이라고 보면 됩니다. 우선 각 모듈 모두 다양한 평가지표에서 베이스라인 대비 성능 향상을 불러오는 것을 볼 수 있습니다.
볼 만한 결과로는 Multi-Instance InfoNCE Loss를 적용한 \text{KL}^{\dagger{}}와 Soft Contrastive Loss를 적용한 \text{KL}^{*}의 성능 차이입니다. 둘의 차이라고 함은 유사도 매트릭스를 형성할 때 내적값을 사용할지, -(L2 거리)를 사용할지의 차이라고 보면 됩니다. 사실 이 부분은 실험적 결과라 저자들도 별다른 분석을 내놓고 있지는 않습니다.
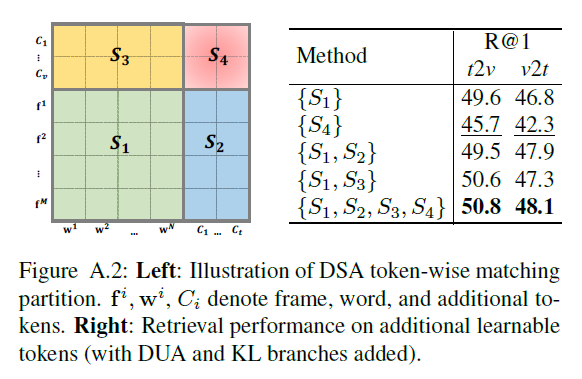
다음은 Appendix에 실려있는 그림 A.2입니다. 이는 learnable parameter를 적용한 DSA 모듈에서의 ablation 실험입니다. 왼쪽 matrix에서 \mathcal{S}_{1}은 CLIP feature끼리 형성한 유사도 매트릭스 영역, \mathcal{S}_{2}, \mathcal{S}_{3}는 각 모달의 CLIP feature와 상대 모달의 learnable parameter끼리 형성한 영역, \mathcal{S}_{4}는 두 모달의 learnable parameter끼리 형성한 영역에 해당합니다.
특정 영역만을 사용했을 때의 성능이 그림에서 오른쪽 표와 같습니다. 볼 만한 점은 조합할 entity의 level을 전적으로 학습에 맡긴 \mathcal{S}_{4}에서의 성능이 기존 TI 방법론인 \mathcal{S}_{1}보다 떨어진다는 점입니다. 하지만 \mathcal{S}_{2}, \mathcal{S}_{3} 영역에서 학습되며 찾은 최적의 entity가 실제 \mathcal{S}_{1}, \mathcal{S}_{2}, \mathcal{S}_{3}, \mathcal{S}_{4}를 모두 사용했을 때, 저자의 의도에 맞게 불확실했던 최적의 level을 어느 정도 찾아주며 높은 성능을 달성한 것을 볼 수 있습니다.
3.2 Comparison with State-of-the-arts
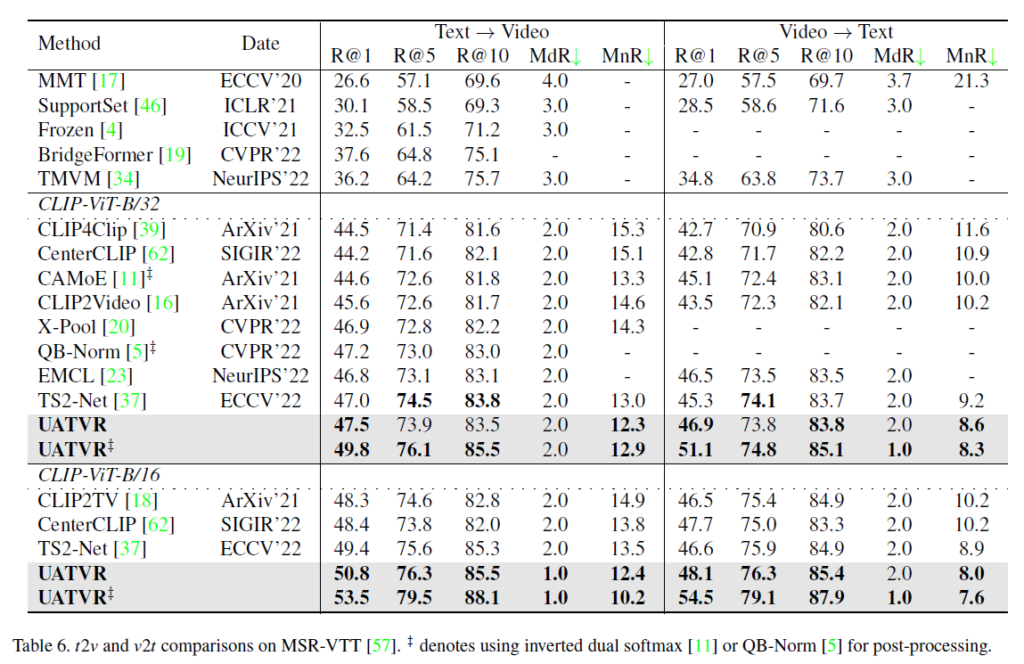
표 6은 MSR-VTT 데이터셋에서의 성능입니다. 기본적으로 CLIP을 사용하지 않은 상단 5개의 방법론에 비해 아래 CLIP 기반 방법론들이 훨씬 높은 성능을 보여주는 점을 알 수 있습니다. \ddagger{}가 붙은 성능은 기존에 제안되었던 후처리방식인 QB-Norm, Dual softmax를 적용한 성능인데, 이를 적용하지 않아도 기존 방법론들보다 더욱 높은 성능을 달성하고 있습니다.
Recall 값에서의 성능 향상도 존재하지만, MdR, MnR에서의 향상이 기존에 비해 두드러지는 것을 볼 수 있습니다. 이를 통해 UATVR이 잘못된 샘플을 높은 순위에 위치시키는 것을 최소화하였고 이는 헷갈리는 샘플에 대한 강인함을 학습하였다고도 해석할 수 있습니다.
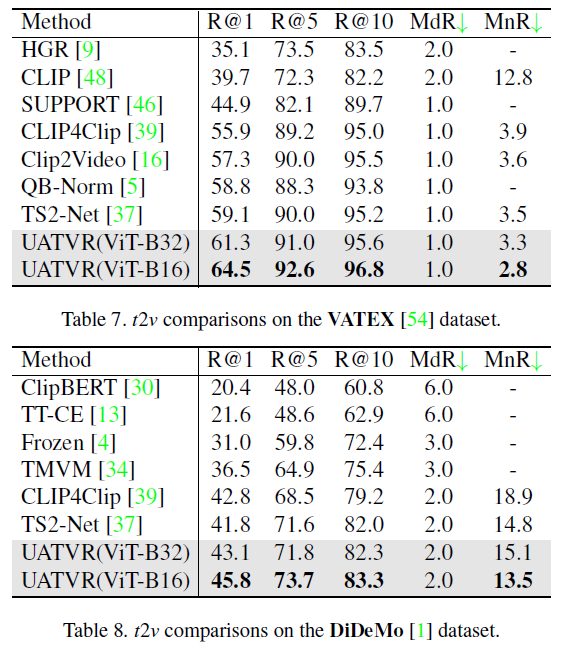
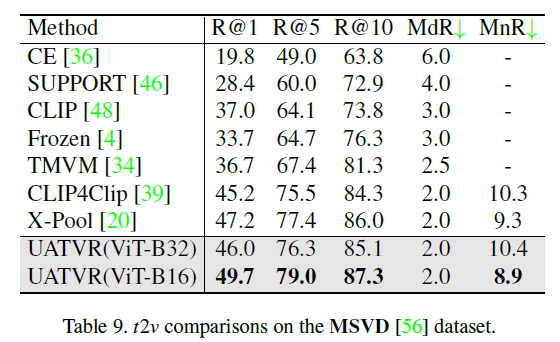
위 표 7, 8, 9는 나머지 데이터셋에 대한 벤치마크 성능이고, 마찬가지로 대부분의 평가지표에서 가장 높은 성능을 달성하고 있습니다.
3.3 Qualitative Results
다음으로는 정성적 결과입니다.

그림 4는 추가했던 learnable parameter의 효과를 알아보기 위한 정성적 결과입니다. 주어진 text 쿼리에 대해 저자가 제안한 유사도 연산 과정 수식 (8)에 따른 프레임의 attention weight를 색과 함께 표시하고 있고, 비디오를 쿼리로 던졌을 때 각 text 쿼리에 대한 attention weight를 아래에 함께 적어두었습니다.
특히 아래 비디오 예시에서 대조되는 (2)와 (3) 쿼리에 알맞게 프레임 별 attention 값도 구별력 있게 추출하는 것을 볼 수 있습니다. 또한 쿼리 (1)과 (3)을 비교했을 때 비디오를 설명하는 데에 있어 좀 더 적합한 (1)에 토큰이 좀 더 높은 점수를 주는 것을 볼 수 있습니다.
4. Conclusion
기존에는 확률적 임베딩을 사용한 Image-Text Retrieval(PCME, CVPR 2021), 확률적 임베딩을 사용한 Self-supervised Video Representation Learning(ProViCo, CVPR 2022), 확률적 임베딩을 사용하며 CLIP으로 text prompt의 도움을 함께 받은 Dense Prediction(PPL, CVPR 2023) 방법론들이 있었습니다.
이러한 흐름 속 UATVR이 최초로 Text-Video의 공통 embedding space를 구축하기 위한 CLIP과 확률적 임베딩을 동시에 활용한 방법론이었습니다. 이는 제가 연구하고 있는 WTAL의 방향성과 비슷하지만 temporal annotation이 없다는 점, snippet-level에서의 dense한 localization을 수행해야 한다는 점에서 WTAL에 이를 적용하는 것이 조금 더 난이도 있는 상황으로 판단되네요.
아무튼 왜 확률적 임베딩을 적용해야하는지에 대한 탄탄한 문제 정의와 시각화가 있었기에 방법론이 간단했음에도 좋은 학회에 게재될 수 있었다는 생각이 드는 논문이었습니다.
이상으로 리뷰 마치겠습니다. 감사합니다.
안녕하세요. 김현우 연구원님
좋은 리뷰 감사합니다.
정리가 깔끔하기도 하고 전부터 김현우 연구원님이 관련된 논문을 많이 소개해주셔서, 아주 간단한 질문만 있는데요.
수식 7에서 (좌측 텀 기준) max함수로 각 단어와 프레임의 유사도 중 가장 높은 것을 고르고, sum만 해주는 것으로 보이는데 설명에는 평균을 내어 사용한다고 되어있는데 식에서 생략이 된 것인가요?
Ablation Study에서 L2 거리를 사용한 모델과 코사인 유사도를 사용한 모델의 성능 차이가 그렇게 크지는 않은 것 같은데, L2 거리와 코사인 유사도를 사용한 ablation을 진행한 다른 논문도 보신 적이 있으실까요? 있으시다면 한번 찾아보고 비교해보고 싶습니다.
새삼 확률적 임베딩이 23년도에 많은 주목을 받은 논문임을 실감하게 하는 것 같습니다.
감사합니다!
안녕하세요.
1) 말씀해주신대로 수식에는 평균연산이 생략되어있는 것이 맞습니다. N, M이 클수록 유사도가 절대적으로 크게 나올 확률이 높기에 평균을 낸다는 이야기는 논문 글에만 표현이 되어있습니다.
2) 사실 feature를 확률분포로 보낸 뒤 얻은 K개의 샘플들끼리는 제가 읽었던 논문은 모두 -(L2 거리)를 사용하였고, 이 연산 방식에 대한 ablation 실험은 본 적이 없습니다. 그래도 저희 논문 연구 과정중에서 CAS 생성 시 -(L2 거리)를 score로 사용해본 적이 있는데, scale의 문제였는지 성능이 꽤 크게 떨어지는 결과를 본 적은 있었습니다.
안녕하세요 김현우 연구원님 좋은 리뷰 감사합니다.
dynamic semeantic adaptation는 어떤 granularity의 조합이 가장 최적의 pair를 구성할 수 있는지 알아내는 것이라고 이해하였습니다. 그런데 [DAS 모듈]과 [그림 A.1]을 보면 text 에서는 단어 단위로 추출한 임베딩이, video에서는 프레임 단위로 추출한 임베딩 간의 유사도만을 비교하는 것으로 보이는데요, 그렇다면 전체 video나 sentence 단위의 similarity는 고려하지 않는 것인가요? 그리고 feature에 붙인 learnable parameter의 역할이 무엇인지도 궁금합니다. 해당 부분이 학습을 통해 coarse한 feature가 되도록 하는 것일까요?
안녕하세요.
베이스라인 방법론에서 사용된 유사도 연산 방식인 수식 (7)만 사용한다면 단어-프레임 레벨의 entity 조합만 고려하는 것이 맞습니다.
이 흐름을 두 번째 질문과 연결해서 설명드리자면, 기존 베이스라인 방식에 비해 좀 더 유연한 level에서의 token을 생성하기 위해 UATVR에서는 learnable parmeter를 사용했다고 생각하시면 됩니다.
단어-프레임이 최적인지, 문장-프레임이 최적인지, 단어-비디오가 최적인지 등등을 알 수 없다는 것이 저자가 이야기하는 uncertain matching problem입니다.
이 때 learnable token이 단어도 비디오도 프레임도 아닌 그 어딘가 최적의 granularity를 찾도록 학습되길 기대하는 것이기 때문에, 말씀해주신대로 마냥 coarse로 간다고 이야기하기보단 coarse로 갈수도 있고 fine-grained로 갈 수도 있는 학습에 전적으로 의존하는 것이 목적이라고 생각하시면 됩니다.