이런 분들께 이 논문을 추천드립니다.
- CLIP을 비디오에 적용하는 방식에 흥미가 있으신 분
- Video Text Retrieval에서 fine-grained와 coarse-grained를 모두 활용하는 cross-grained 방식이 궁굼하신 분
이 논문을 깊게 이해하려면 다음 지식이 필요합니다.
- Multi-modal contrastive learning에 대한 이해 (CLIP 리뷰 파트 1, 파트 2)
- Vision Transformer에 대한 이해 (ViT 리뷰)
- Retrieval Task에 대한 이해 (블로그)
안녕하세요. 백지오입니다.
스물 한 번째 X-REVIEW는 CLIP을 활용한 Video-Text Retrieval 논문인 X-CLIP입니다.
Video-Text Retrieval은 비디오와 텍스트를 각각 임베딩하여 벡터로 만든 후, 쿼리에 대한 유사도가 가장 높은 비디오들을 검색하는 task입니다. 이때, 기존 연구들은 비디오 전체와 텍스트 전체를 각각 하나의 벡터로 만들어 비교하는 coarse-grained 방식과 비디오와 텍스트를 구성하는 프레임과 단어들을 비교하는 fine-grained 방식이 주를 이뤘는데요. 드물게 두 방식을 모두 사용하는 cross-grained(= multi-grained) 방식이 있었는데, 이 연구는 cross-grained에 해당합니다.
본 논문에서는 multi-grained contrastive model인 X-CLIP을 제안합니다. 해당 모델은 먼저 coarse-grained feature를 통해 영상이나 쿼리 텍스트에 포함된 중요하지 않은 프레임들과 단어들을 억제하고, 이렇게 중요한 정보만 남은 fine-grained feature를 비교합니다. 비디오와 텍스트에서 중요하지 않은 정보를 필터링해줌으로써 noise로 작용하는 정보가 줄어들어 성능이 크게 향상되어 SOTA를 달성하였다고 합니다.
X-CLIP은 fine-grained와 coarse-grained 유사도를 모두 구한 뒤, instance-level 유사도로 병합(aggregation)하여 사용하는데요. 이를 위한 Attention Over Similarity Matrix (AOSM) 모듈을 제안합니다.
자세한 내용은 아래서 살펴보도록 하겠습니다.
Introduction
Video-Text Retrieval 연구가 활발히 진행되고 있으나, 대부분의 연구들은 fine-grained 혹은 coarse-grained 중 한 가지의 방식을 사용했다고 합니다. CLIP4Clip은 대표적인 coarse-grained 방법으로 이미지-텍스트에서 사전학습된 CLIP의 정보를 성공적으로 Video-Text Retrieval에 활용했지만, 전체 문장과 전체 비디오를 하나의 textual / video representation으로 임베딩하기 때문에 fine-grained interaction을 포착하는 능력이 부족한 약점이 있습니다.
한편 fine-grained이나 cross-grained 방식으로 꽤나 유망한 결과를 보여준 연구들도 있었지만, 저자들은 이들이 아직 부족하며, cross-grained에 연구할 만한 영역이 많이 남았다고 합니다.
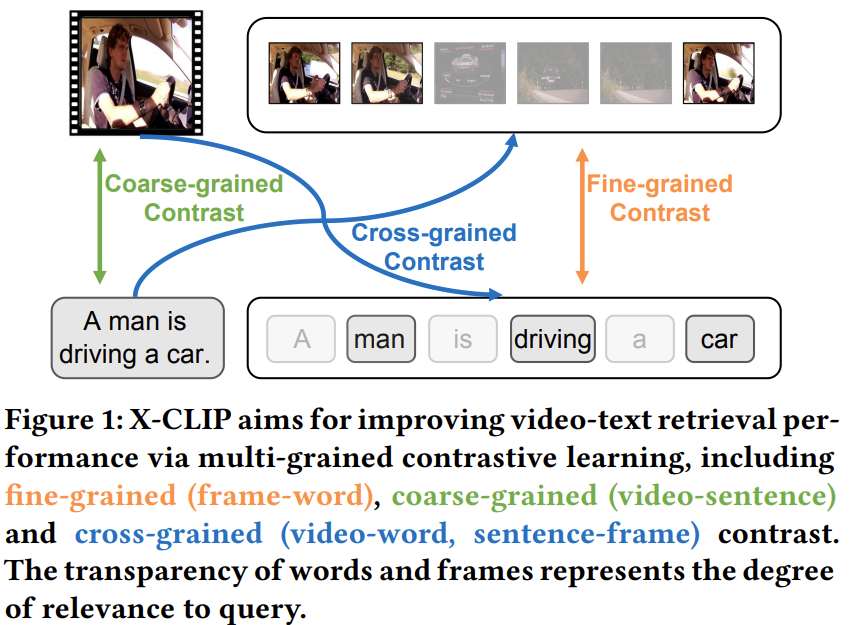
위 그림과 같이, 비디오는 여러 장의 프레임으로, 쿼리 텍스트인 문장은 여러 개의 단어로 구성됩니다. 이러한 프레임들과 단어들 중에는 위 그림에서 연하게 표현된 프레임과 단어들처럼 전체 의미에 별 의미가 없는 정보들도 있습니다.
그러나, 지금까지의 연구들은 이러한 프레임들이나 단어들을 필터링하는데 관심이 없었으며, 저자들은 이러한 불필요한 정보들을 필터링하여 정확도를 올릴 수 있었다고 합니다.
그림과 같이 먼저 coarse-grained feature를 통해 fine-grained feature에서 중요도가 떨어지는 영역들을 필터링하고, 중요한 정보들에 높은 가중치를 준 다음 유사도를 계산하여, 노이즈의 영향을 줄였습니다.
한편, 이러한 유사도 계산을 위해 instance-level의 유사도로 coarse-grained와 fine-grained 유사도를 병합하는 방법이 필요한데, 가장 단순하고 쉬운 방법은 Mean-Max 전략입니다. 이름을 보면 짐작하시겠지만, 단순히 각 프레임/단어들 간의 유사도를 평균과 최댓값 연산을 통해 합치는 방법입니다.
Mean의 경우 모든 프레임들과 단어들에 중요도와 관계없이 같은 가중치를 부여하며, Max 방법은 가장 중요한 단어만을 취급하여 모두 중요한 정보들을 활용하는데 적합하지 않습니다.
앞선 분석에 따라, 저자들은 end-to-end multi-grained contrast model인 X-CLIP을 제안합니다. X-CLIP은 modality-specific encoder를 통해 multi-grained visual and textual representation을 만들고, multi-grained contrast of features (video-sentece, video-word, sentence-frame, frame-word)를 고려하여 multi-grained 유사도 점수, 벡터, 행렬을 계산합니다. 이어서 불필요한 정보들을 필터링하고 유사도 점수들을 병합하기 위해 AOSM을 제안합니다.
이를 통해 저자들은 Video-Text Retrieval 데이터셋들에서 SOTA를 달성할 수 있었습니다.
Related Works
Vision-Language Pre-Training
VideoBERT, HERO, Frozen과 같이 video-text 데이터를 이용해 사전학습한 모델들은 이미지에는 존재하지 않는 시간적 정보를 학습할 수 있지만, Image-Text 데이터셋 대비 턱없이 부족한 Video-Text 데이터를 이용해 학습해야 하는 어려움이 있습니다.
한편, 자기지도학습 사전학습 모델인 BERT, 대규모 Image-Text pretraining 모델 CLIP의 등장에 따라 이미지 데이터에서 사전학습된 정보를 Video-Text Retrieval 분야에서 활용할 수 있는 CLIP4Clip과 같은 모델이 등장했습니다.
이 논문은 CLIP4Clip과 유사하게 image-text 사전학습 모델의 visual representation learning 능력을 빌려 Video Text Retrieval을 수행하고자 합니다. 그러나 X-CLIP은 CLIP4Clip과 달리, multi-grained video-text alignment function을 설계하여 video-text semantics를 더 잘 정렬할 수 있습니다.
Video-Text Retrieval
Video-Text Retrieval은 동영상 공유 플랫폼의 검색 기능 등 다양한 분야에 활용됩니다. 초기 연구들의 경우, 비디오로부터 face recognition, object recognition, audio processing 등으로 feature를 추출하고 이들을 비교했는데, 이러한 방법은 single-modal feature에 의존적이고 task-specific한 단점이 있었습니다.
따라서 최근 연구는 feature 추출부터 학습하는 end-to-end 모델이 주류인데, Multiple Instance Learning and Noise Contrastive Estimation, MIL-NCE를 통해 end-to-end video represenation learning 수행할 수 있는 모델들이 등장했습니다. 이어서 ClipBERT는 sparsely sampled video clip을 통해 end-to-end 학습하여 clip-level prediction을 수행하는 방법을 제안했고, Frozen은 video frame을 uniform sampling하여 end-to-end 학습하고 image-text, video-text 쌍 데이터 모두에서 학습할 수 있습니다. CLIP4Clip은 CLIP의 지식을 VTR에 잘 적용하고, 세 가지 video-sentence contrastive learning을 위한 유사도 계산법을 제안하기도 했습니다. 한편, cross-grained (video-word, sentence-frame) contrast를 활용하는 방법도 중요하지만, 이들은 상대적으로 연구가 덜 되었다고 합니다.
Method
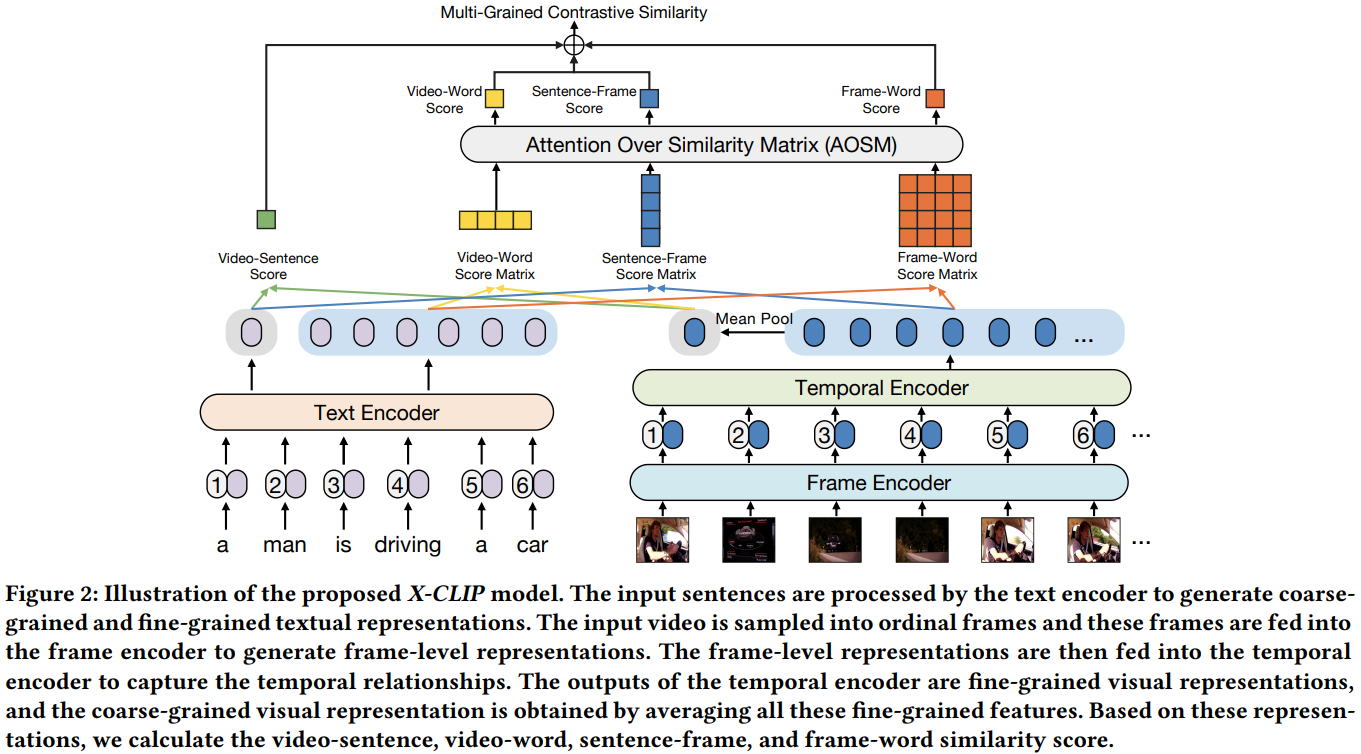
Feature Representation
먼저 비디오 $\hat{v}_i \in \hat{V}_i$에서 1초에 한장의 프레임을 샘플링합니다. 샘플링된 프레임들에서 CLIP visual encoder를 이용해 feature를 추출해줍니다. CLIP과 동일하게, CLIP의 12계층 ViT를 거친 마지막 출력에서 [CLS] 토큰 위치에 해당하는 feature가 frame-level feature $\bar{v}_{(i,j)} \in \bar{V}_i $로 간주됩니다.
이때, 각 frame-level feature들이 별도의 프레임에서 독립적으로 추출되었기 때문에, 프레임 사이의 관계를 고려하지 않습니다. 따라서 temporal encoder를 도입하여 프레임들 사이의 시간적 관계를 모델링해줍니다. temporal encoder는 temporal position encoding $P$를 사용하는 3계층 트랜스포머 인코더 구조입니다.
$$ V_i = \text{TransEnc}(\bar{V}_i + P)$$
최종적으로 $V_i = \[ v_{(i, 1)}, v_{(i, 2)}, \cdots, v_{(i,n)} \]$가 각 비디오 $\hat{v}_i$의 최종 frame-level (fine-grained) feature가 됩니다. $n$은 $v_i$의 프레임 수입니다. Video-level (coarse-grained) feature $v_i’ \in \mathbb{R}^{dim}$는 모든 frame-level feature $\hat{v}_i$의 평균으로 구할 수 있습니다.
$$ v_i’ = \frac{1}{n}\sum^n_j v_{(i, j)}$$
텍스트 역시 CLIP의 텍스트 인코더를 통해 인코딩합니다. sentence-level (corase-grained) textual feature는 $t_i’ \in \mathbb{R}^{dim}$이며, word-level(fine-grained) textual fefature는 $T_i = \[ t_{(i, 1)}, t_{(i, 2)}, \cdots, t_{(i, m)} \]$과 같이 나타냅니다. coarse-grained feature는 [EOS] 토큰의 출력이며 나머지는 각 단어에 대응하는 출력이 됩니다.
Multi-Grained Contrastive Learning
X-CLIP은 전술하였듯이 불필요한 정보들을 필터링하기 위한 multi-grained 구조로 이루어져 있습니다. 먼저 문장과 단어, 비디오와 프레임 사이의 유사도들을 행렬곱을 통해 구해줍니다.
Video-Sentence Contrast. 먼저, coarse-grained similarity에 해당하는 비디오와 문장(전체 텍스트)의 유사도를 구해줍니다. video-level representation $v’ \in \mathbb R^{dim}$와 sentence-level representation $t’\in \mathbb R^{dim}$이 주어질 때, 아래와 같은 행렬곱으로 유사도를 구할 수 있습니다.
$$ S_{V-S} = (v’)^\top (t’)$$
$$S_{V-S}\in \mathbb R^1$$
Video-Word Contrast. 이어서, 비디오와 단어들의 유사도입니다. word-level representation vector $T\in \mathbb R^{m\times dim}$에 대한 행렬곱으로 구합니다. $m$은 단어의 수입니다.
$$ S_{V-W} = (Tv’)^\top$$
$$S_{V-W} \in \mathbb R^{1\times m}$$
Sentence-Frame Contrast. 위와 유사하게 이번에는 문장과 프레임들의 유사도입니다. $n$은 프레임의 수입니다.
$$S_{F-S} = \bar{V}t’$$
$$ S_{F-S} \in \mathbb R^{n\times1}$$
Frame-Word Contrast. 마지막은 fine-grained similarity에 해당하는 프레임들과 단어들의 유사도입니다.
$$S_{F-W} = \bar{V}T^\top $$
$$S_{F-W} \in \mathbb R^{n\times m}$$
Attention Over Similarity Matrix (AOSM)
Instance-level 유사도를 얻기 위해 앞서 얻은 Video-Word, Sentence-Frame, Frame-Word 유사도 행렬들을 병합해 주겠습니다. 이때, mean-max 방법 대신 어텐션을 사용해 중요한 영역과 그렇지 않은 영역에 다른 가중치를 부여해줄 것입니다.
먼저, 아래 식과 같이 $S_{V-W}\in \mathbb R^{1\times m}$와 $S_{F-S} \in \mathbb R^{n\times 1}$의 벡터들에 Softmax 함수를 적용하여 가중치로 만들고 $S_{V-W}$와 $S_{F-S}$에 각각 곱해 적용해줍니다. 이때, $\tau$는 softmax의 temperature 파라미터 입니다.
$$ S’_{V-W} = \sum^m_{i=1} \frac{\exp(S_{V-W(1, i)} /\tau)}{\sum^m_{j=1} \exp(S_{V-W(j,i)} / \tau)} S_{V-W(1,i)}$$
$$ S’_{F-S} = \sum^m_{i=1} \frac{\exp(S_{F-S(1, i)} /\tau)}{\sum^m_{j=1} \exp(S_{F-S(j,i)} / \tau)} S_{F-S(1,i)}$$
$S_{V-W}$는 비디오와 $m$개의 단어들의 유사도를 담은 벡터로, 여기에 softmax를 씌우면 비디오와 유사도가 높은(=비디오와 연관된 중요한) 단어에 높은 가중치가 부여됩니다. 이 가중치를 다시 $S_{V-W}$에 적용하여 중요한 단어의 값은 높이고, 중요하지 않은 단어의 값은 억제하는 것이죠. $S’_{F-S}$도 같은 원리입니다.
한편, $S_{F-W}\in \mathbb R^{n\times m}$ 행렬은 $n$개의 프레임과 $m$개의 단어들의 유사도를 담고 있으니, 해당 행렬에 대해서는 어텐션을 두번 적용해줘야 합니다. 첫번째는 fine-grained video-level and sentence-level 유사도 벡터를 얻기 위해 다음과 같이 적용됩니다.
$$ S_{vid} = \sum^n_{i=1} \frac{\exp(S_{F-W(i,*)}/\tau)}{\sum^n_{j=1} \exp(S_{F-W(j,*)}/\tau)}S_{F-W(i,*)}$$
$$ S_{sen} = \sum^m_{i=1} \frac{\exp(S_{F-W(*,i)}/\tau)}{\sum^m_{j=1} \exp(S_{F-W(*,j)}/\tau)}S_{F-W(*,i)}$$
$*$은 해당 차원의 모든 요소들을 의미합니다. $S_{vid}\in \mathbb R^{1\times m}$, $S_{sen} \in \mathbb R^{n\times 1}$은 각각 video-level, sentence-level 유사도 벡터가 되는데, 이게 무슨 의미인지 살펴봅시다.
$S_{vid} \in \mathbb R^{1\times m} $는 $m$개의 단어들에 대하여, $n$개의 프레임들에 대한 유사도가 병합되어 비디오와 $m$개 단어들의 유사도가 되고, $S_{sen} \in \mathbb R^{1\times m} $는 $n$개의 프레임들에 대하여, $m$개의 단어들에 대한 유사도가 병합되어 문장과 $n$개 프레임들의 유사도가 됩니다.
앞선 $S_{V-W}, S_{F-S}$와의 차이점은, 유사도가 비디오-단어, 프레임-문장의 비교로 구해지지 않고, 프레임-단어로 구한 뒤 병합된 것이라는 점 입니다.
이어서 Fine-grained instance-level 유사도 점수를 얻기 위해 두 벡터에 두번째 어텐션을 수행합니다.
$$S_{vid}’ = \sum^m_{i=1}\frac{\exp(S_{vid(1, i)}/\tau)}{\sum^m_{j=1}\exp(S_{vid(1,j)}/\tau)}S_{vid(1,i)}$$
$$S_{sen}’ = \sum^m_{i=1}\frac{\exp(S_{sen(i, 1)}/\tau)}{\sum^m_{j=1}\exp(S_{sen(j, 1)}/\tau)}S_{sen(i, 1)}$$
앞선 유사도들과 동일한 어텐션 과정으로 병합된 $S_{vid}’\in \mathbb R^1$, $S_{sen}’\in \mathbb R^1$는 fine-grained로부터 병합된 instance-level 유사도입니다. 최종적인 fine-grained 유사도 점수는 두 점수의 평균으로 구해집니다.
$$ S_{F-W}’ = (S_{vid}’ + S_{sen}’) / 2$$
Similarity Calculation
영상과 텍스트의 유사도 $s(v_i, t_i)$는 multi-grained로, 앞서 얻은 coarse-grained 유사도들과 fine-grained 유사도의 평균으로 계산됩니다.
$$s(v_i, t_i) = (S_{V-S} + S_{V-W}’ + S_{F-S}’ + S_{F-W}’)/4$$
Objective Function
$B$개의 비디오-텍스트 쌍이 배치로 주어질 때, $B\times B$ 크기의 유사도 행렬을 생성하게 되는데, 여기에 symmetric InfoNCE Loss를 적용하여 학습을 진행합니다.
$$ \mathcal L_{v2t} = -\frac{1}{B}\sum^B_{i=1} \log\frac{\exp(s(v_i, t_i))}{\sum^B_{j=1} \exp(s(v_i, t_j))}$$
$$ \mathcal L_{t2v} = -\frac{1}{B}\sum^B_{i=1} \log\frac{\exp(s(v_i, t_i))}{\sum^B_{j=1} \exp(s(v_j, t_i))}$$
$$ \mathcal L = \mathcal L_{v2t} + \mathcal L_{t2v}$$
Experiments
테스트는 VTR task에서 흔히 사용하는 MSR-VTT, MSVD, LSMDC, DiDeMo, ActivityNet 데이터셋으로 진행하였으며, video-paragraph retrieval task 시에는 텍스트들을 모두 concatenate하여 fair comparison 했다고 합니다.
실험은 4장의 V100 32GB GPU에서 진행했고, pytorch를 사용하였습니다. (코드도 공개되어 있네요.) 초기화는 공개된 CLIP 체크포인트를 사용했고, Adam 옵티마이저를 통해 학습을 진행하였습니다. learning rate decay는 코사인 스케쥴링을 사용했고 text encoder에는 $1e-7$, 그 외의 모듈들에는 $1e-4$의 learning rate를 적용했습니다. MSR-VTT, MSVD, LSMDC에서는 max token length 32, max frame length 12, batch size 300, 학습 에포크 3을 적용했고, DiDeMo와 ActivityNet은 영상이 길고 복잡하여 max token length 64, max frame length 64, batch size 64, 학습 에포크는 20을 적용했다고 합니다.
Ablation Study와 정성적 평가는 MSR-VTT에서 진행했고, 따로 언급하지 않았다면 베이스 모델은 CLIP ViT-B/32입니다. 모델의 표현력을 증가시키기 위해, video-sentence와 frame-word 유사도 점수를 계산할 때는 단위행렬로 초기화된 linear embedding을 사용하였고, 유사도 점수에도 단위행렬로 초기화한 FC layer를 붙여 모델의 표현력을 향상했다고 합니다. 유사도를 위에서 행렬곱으로 구해놓고 FC layer를 한번 더 태웠다니 이걸 왜 실험 파트에서 얘기하는지 잘 몰?루겠네요…
평가는 Recall@K(R@K, higher is better), median rank(MdR, lower is better), mean rank (MnR, lower is better)를 사용했다고 합니다.
Performance Comparison

먼저 MSR-VTT에서의 성능 비교입니다. 대규모 데이터셋에서 사전학습된 CLIP 기반의 모델들이 이전 모델들 대비 성능이 월등히 높네요. 기존 SOTA에 해당하는 CLIP4Clip-seqTransf 대비 X-CLIP이 2.9 더 높은 성능을 보이고 있습니다. 두 모델이 CLIP을 가져오고 temporal modeling을 하는 구조 자체는 거의 비슷한 만큼 저자들이 주장한 중요하지 않은 프레임의 억제가 효과가 있었음을 보여주는 것 같습니다. 저자들은 X-CLIP (ViT-B/32)가 ViT-B/16을 백본으로 사용하는 CLIP4Clip과 비빈다는 점을 강조하는데, 정말 그러네요. 놀랍습니다.
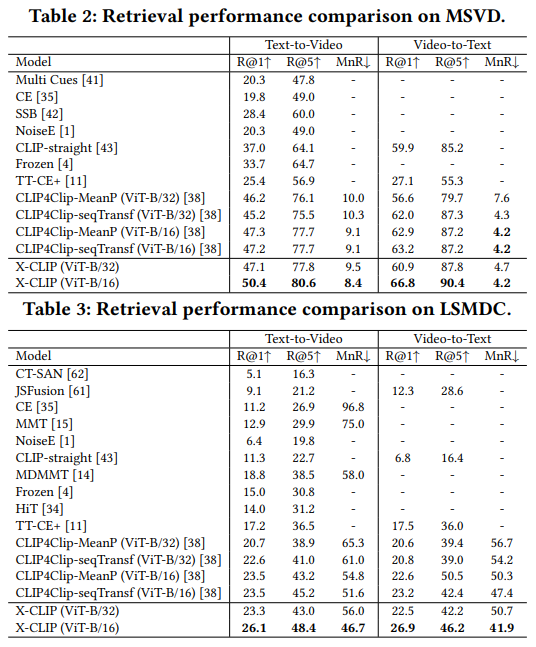
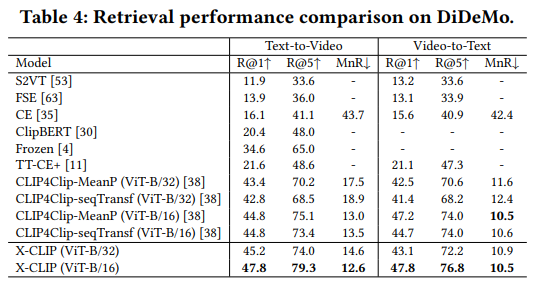
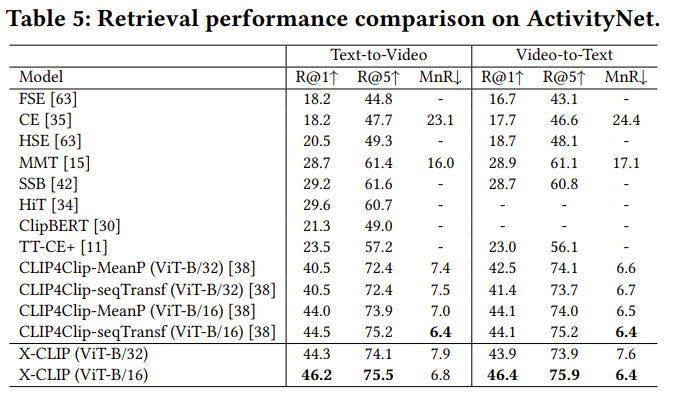
이어지는 다른 데이터셋에서의 비교도 비슷한 결과를 보여줍니다. X-CLIP이 VTR에서 큰 성능 향상을 보여주고, 특히 Text-to-Video 성능이 많이 오른 편이라고 합니다.
Ablation Study
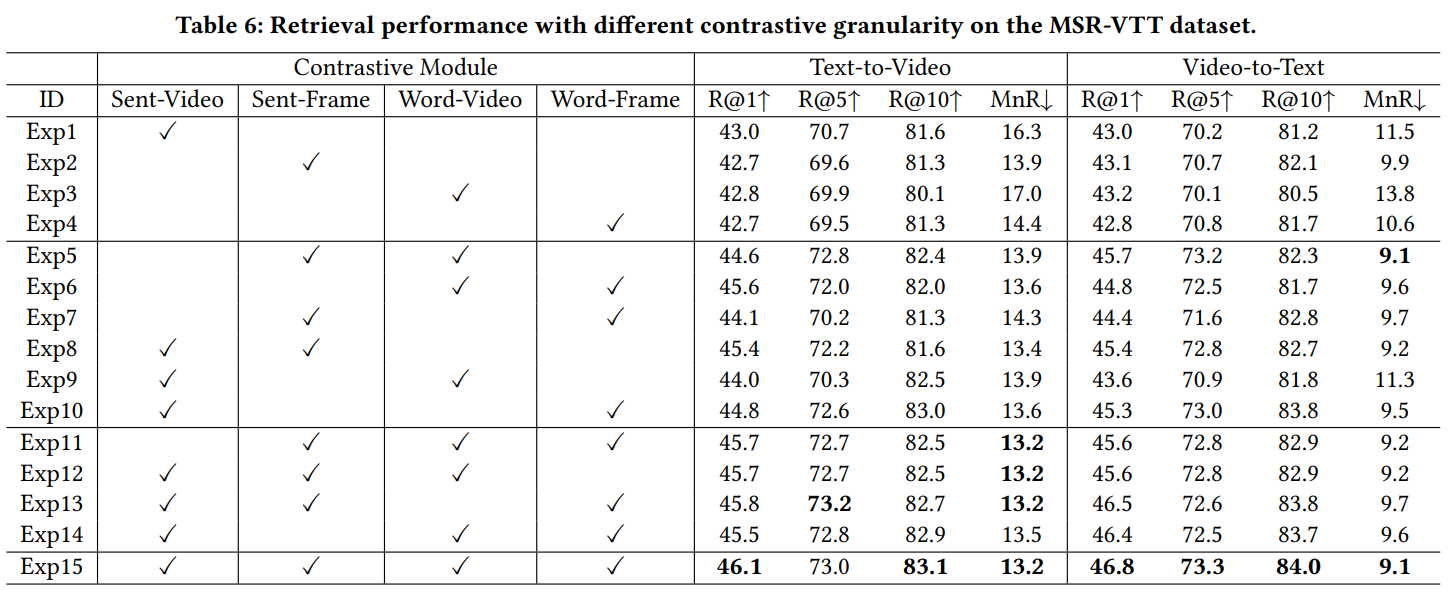
저자들은 각 contrastive module의 포함 여부에 따른 실험을 진행했습니다. 그 결과 적용하는 contrastive module이 증가할수록 성능 역시 증가하는 모습을 보였는데, 각 모듈이 retrieval 수행 시 다른 역할을 수행하는 것으로 보인다고 합니다. 당연하다면 당연한 결과이지만, 새삼 신기하기도 합니다.
또한 실험 1과 같이 coarse-grained한 비교만 수행하는 것보다, fine-grained한 비교가 하나라도 들어가는 실험 8,9가 성능이 많이 향상되는 것으로 보아 각각이 상호 보완적인 역할을 할 수 있는 것으로 보인다고 합니다.
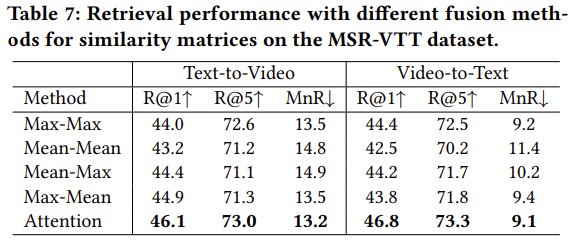
저자들은 이어서 AOSM 모듈의 유효성을 확인하기 위해 기존의 유사도 병합 방식들과 비교를 수행하였습니다. 그 결과 Attention 기반의 AOSM이 확실히 좋은 성능을 보여줬습니다. 모든 프레임과 단어들에 같은 가중치를 주는 Mean-Mean 방식이 가장 성능이 안 좋았고, 가장 중요한 프레임(단어)를 선정하는 Max가 포함된 방법이 그나마 나은 성능을 보였다는 점에서 저자들은 이 또한 중요하지 않은 프레임(단어)를 제거하는 것의 유효성을 드러내는 것일 수 있다고 합니다.
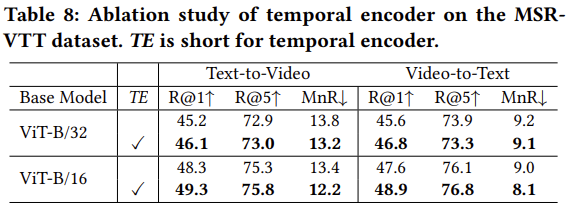
이어서 Temporal Encoder에 대한 비교입니다. 이건 좀 당연하게도 없는 것보다 있는 것이 더 좋네요.
Effect of Temperature Parameter

AOSM 모듈에서 사용하는 $\tau$에 대한 실험입니다. temperature가 0.01 이상이 되면 조금씩 성능이 감소했다는데, $\tau$가 너무 크면 유사도 점수의 노이즈가 너무 많이 개입하고 $\tau$가 너무 작으면, 일부 중요한 유사도 점수가 무시되는 것으로 보인다고 합니다. temperature 값이야 워낙 분석하기 힘든 것이 알려져있어서, 여기에도 별다른 깊은 고찰은 없군요.
정성적 결과

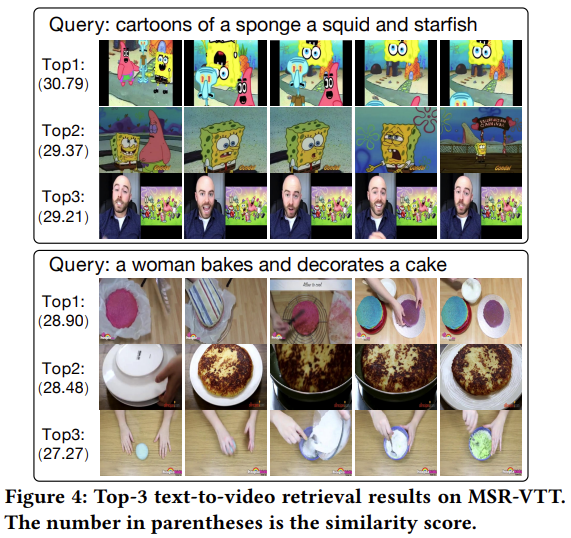
그림 3, 4에서 각각 Video-Text Retrieval과 Text-Video Retrieval의 예시를 보였습니다. 그림 4의 첫번째 예시를 보면, 모두 스폰지밥 애니메이션이지만, 두번째와 세번째 영상에는 오징어(징징이)가 나오지 않는데 이런 디테일까지 잘 고려한 것인지 올바른 답을 고른 모습입니다.
Conclusion
본 논문에서는 video-text retreival을 위한 end-to-end multi-grained contrastive model인 X-CLIP을 제안했습니다. 본 모델은 비디오를 coarse-grained와 fine-grained representation으로 인코딩하고, fine-grained, coarse-grained, cross-grained contrast를 수행합니다. 이러한 multi-grained contrast와 AOSM 모듈을 통해, 검색에 중요하지 않은 프레임과 단어들을 제거하고 좋은 성능을 보였습니다.
이 task를 보면서 저희 팀의 근본 task인 Video to Video Retrieval task가 생각이 많이 났는데, 아마 VTR에서도 fine-grained가 연산량이 훨씬 클 것 같은데, 그런 부분은 고려한 논문인지 궁굼증이 생기는 논문이었습니다. 나중에 찾아봐야겠네요.
감사합니다!
백지오 연구원님, 좋은 리뷰 감사합니다. 항상 비디오 데이터를 벡터 하나로 추출하면 그 내부에 있는 temporal 한 정보와 scene 별 중요도가 제대로 고려되는가 궁금증이 있었는데, 이를 잘 다루기 위해 corase-grained 와 fine-grained를 적절히 섞었다는 것이 인상깊었습니다.
평가 메트릭에 대해 질문이 있는데요, Recall@K와 median rank, mean rank가 각각 어떻게 측정되는지 간략하게 알려주실 수 있을까요?
감사합니다.
안녕하세요. 허재연 연구원님.
Recall@K는 주어진 쿼리와 유사도가 높은 K개의 샘플 중, 실제로 쿼리와 유사한 TP 샘플의 갯수를 TP + FN으로 나눈 값 입니다. median rank와 mean rank는 각 쿼리와 유사한 영상이 검색 결과에서 갖는 순위(rank)의 중간값과 평균으로, 유사한 영상의 순위가 낮을 수록 좋으므로 낮으면 좋은 결과입니다.
감사합니다.
안녕하세요 백지오 연구원님, 좋은 리뷰 감사합니다.
비디오, 텍스트 전체를 하나의 임베딩으로 만드는 coarse grained 방식의 V-S score, 각 frame과 단어를 각각 임베딩한 fine-grained 방식의 F-W score, 그리고 서로 다른 sparsity 간의 V-S score, S-F score를 모두 사용한 것이 인상적이었습니다. 리뷰를 읽고 든 생각이지만 이걸 다 계산하려면 상당한 computational cost가 들 것 같네요…
개인적으로 궁금한 것이 있는데 Temporal encoder의 역할이 무엇인지 궁금합니다. frame간 positional encoding을 제공해 준다고 하셨는데 frame encoder 자체가 transformer 기반 모델이므로 positional encoding을 포함하고 있지 않나요?
그리고 AOSM설명 부분의 S’_{V-W}에서 softmax(S_{V-W}) 수식의 분모가 S_{F-S}가 맞는지도 궁금합니다… 아마 단순 오타인 것 같습니다만…
안녕하세요. 천혜원 연구원님.
오타 수정했습니다! 확인 감사합니다.
Frame encoder의 경우 각 프레임을 임베딩하는 ViT로, 해당 모델에서 사용하는 positional은 말 그대로 한 프레임 안에서 각 패치의 공간적 정보를 의미합니다.
한편, temporal encoder는 각 프레임의 representation vector를 토큰 삼아 동영상의 시간적 정보를 인코딩하는 역할로, 여기서 positional은 공간이 아니라 시간적인 정보를 의미합니다.
Frame encoder가 각 프레임을 독립적으로 인코딩하는데 본 논문의 구조 그림에서는 마치 한번에 인코딩하는 것처럼 보이게 그려놔서 조금 오해의 소지가 있네요.
댓글 감사합니다!
안녕하세요 좋은 리뷰 감사합니다.
현재 작업중인 OTT 제안서에도 grounding을 위해 CLIP을 사용하며 coarse-grained에서 fine-grained로 넘어가야한다는 이야기를 하는 중인데, 역시 Retrieval 쪽에서는 이미 활발히 연구되고있는 부분이었군요.
한 가지 궁금한 것은 TVR task가 Text-Video, Video-Text 두 가지 retrieval을 수행하는데, 특히 Text-Video가 많이 오른 경우에 대해 저자가 그 원인이나 논리적 이유를 이야기해준 것이 있나요? 사실 정량적 결과라고 해도 분석하기 어려운 부분이라고 생각이 들어서, 저자의 생각이 언급되어있는지 궁금하여 질문 드립니다.
안녕하세요. 김현우 연구원님.
댓글 감사합니다.
답변을 드리고자 논문을 다시 읽어보니, text-retrieval에서 성능이 많이 오른 것이 아니라 text-retrieval에서 기존 SOTA인 CLIP4Clip보다 성능이 많이 향상되었다는 것을 제가 요약하며 잘못 정리한 것 같습니다.
혼란을 드려 죄송합니다. ?
감사합니다!