안녕하세요, 열일곱번째 X-Review 입니다. 이번 논문은 2023년도 ICCV에 게재된 Segment anything 논문 입니다. 그럼 바로 리뷰 시작하겠습니다 !
1. Introduction
대용량 데이터셋으로 학습한 LLM은 NLP 분야에서 우수한 zero shot / few-shot generalization 성능을 보이고 있습니다. 이런 Foundation model들은 Prompt engineering을 통해 여러 task에 대한 적절한 text 응답을 생성하도록 prompt하는 식으로 구현되곤 합니다.
본 논문의 목표는 image segmentation에서의 foundation model을 만들자라는 것입니다. 즉, 강력한 일반화를 가능하게 하는 task를 통해 promptable model을 개발하고 이를 대용량 데이터셋으로 사전학습 하는 것이 목표입니다. 또, 이렇게 개발한 모델을 가지고 여러 downtream segmentation 문제들을 풀고자 합니다.
이를 위해서는 저자들은 아래 3가지 질문을 던집니다.
- zero-shot 일반화를 가능하게 하는 task는 무엇인지 ?
- 적절한 model 구조는 무엇인지 ?
- 어떤 data가 1, 2의 task와 model에 적합한지 ?
저자들은 promptable segmentation task를 정의하는 것으로 시작합니다. 이 task는 flexible한 prompt를 지원하고 segmentation mask를 실시간으로 출력할 수 있는 model이 필요하겠죠. 또 이 모델을 학습하기 위해서는 다양하고 방대한 양의 data가 필요할 것입니다. 하지만, segmentation을 위한 대용량 데이터셋은 존재하지 않습니다. 저자들은 이런 문제를 해결하기 위해 “data engine”을 구축하였는데, 이는 본 논문의 모델을 활용하여 반복적으로 data를 모으고 이 모은 data로 모델을 개선하는 것을 의미합니다. 자세한 설명은 아래에 보충하도록 하겠습니다.
2. Segment Anything Task
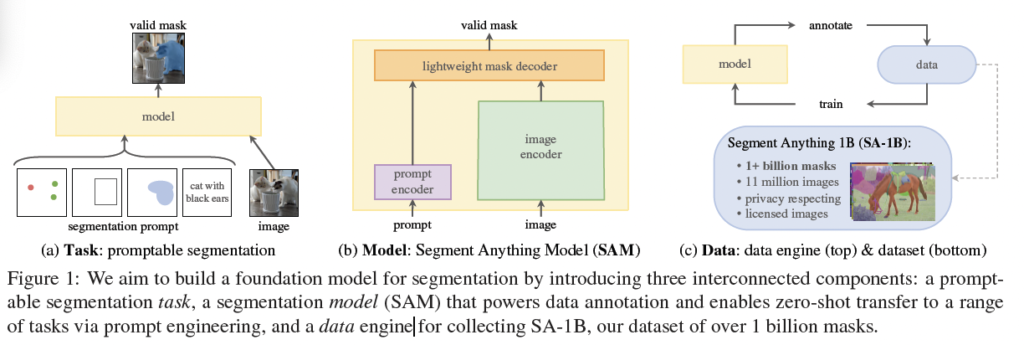
NLP에서는 다음 token을 예측하는 task를 사용하는 식으로 foundation model을 사전학습 하고 prompt engineering을 통해 다양한 downstream task 문제를 풀었습니다. 저자는 여기에서 영감을 받아서 segmentation에서의 foundation model을 만들 때 유사한 능력을 가진 task를 정의하고자 하였습니다.
Task
그래서 저자들은 NLP에서의 prompt 아이디어를 segmentation으로 변환하는데 여기서 prompt는 point, box, mask, text 등 일반적으로 이미지에서 segment할 대상을 나타내는 모든 정보가 될 수 있습니다. 그럼 promptable segmentation task는 위의 prompt 중 아무 prompt가 들어오더라도 유효한(valid) segmentation mask를 뱉어야 합니다. 즉, 모호한(ambiguous) prompt가 입력으로 들어왔을 때도 resonable한 mask를 출력해야 함을 의미합니다.

위의 [Figure 3]의 타조 그림들을 보았을 때 prompt는 타조 부리에 모호하게(ambiguous) 찍혀 있는 것을 볼 수 있습니다. 여기서 prompt는 point에 해당하겠죠. 이 타조 부리의 point는 타조 머리를 선택한 것인지, 타조 상체를 선택한 것인지, 혹은 타조 전체를 선택한 것인지 모호합니다. 이런 타조 부리 point와 같은 애매한 prompt가 들어오더라도 output은 얼굴, 상체, 몸동 중 적어도 하나에 대한 resonable한 mask여야 합니다.
이건 language model이 모호한 prompt에 대해 일관성있는 답변을 하는 것과 유사하다고 볼 수 있겠으며, 이 task를 선택한 이유는 prompt를 통해서 자연스러운 사전 학습과 downstream segmentation task로의 zero shot transfer를 위한 일반적인 방법으로 이어지기 때문입니다.
Pre-training
promptable segmentation task는 각 학습 이미지에 대해 일련의 prompt(point, box, mask 등)를 시뮬레이션 하고, 모델이 이에 대해 예측해 낸 mask는 gt와 비교하면서 학습하였습니다.
이러한 방식은 interactive segmentation[(Deep interactive object selection), (Iteratively trained interactive segmentation*)*]에서 제안한 방식인데, 이 interactive segmentation 방법론은 충분하고 명확한 input에 대해서 valid한 mask를 예측하는 것이 목표였다면 본 논문에서는 모호한 prompt가 입력으로 들어오는 경우에도 항상 valid한 mask를 예측하는 것이 목표라는 차이가 있습니다.
zero-shot transfer
본 논문의 사전 학습 task는 모델이 inference time에서 어떤 prompt가 들어오더라도 적절한 응답을 할 수 있는 능력을 부여하기 때문에, downstream task는 적절한 prompt를 설정함으로써 해결할 수 있습니다. 예를 들어서 이미지에서 고양이에 대한 bbox가 쳐져 있는 경우 이 bbox를 모델에 input으로 넣기만 해도 고양이 segmentation이 가능하다는 것입니다.
3. Segment Anything Model
이제 Segment Anything Model, 이하 SAM에 대해 알아보도록 하겠습니다.
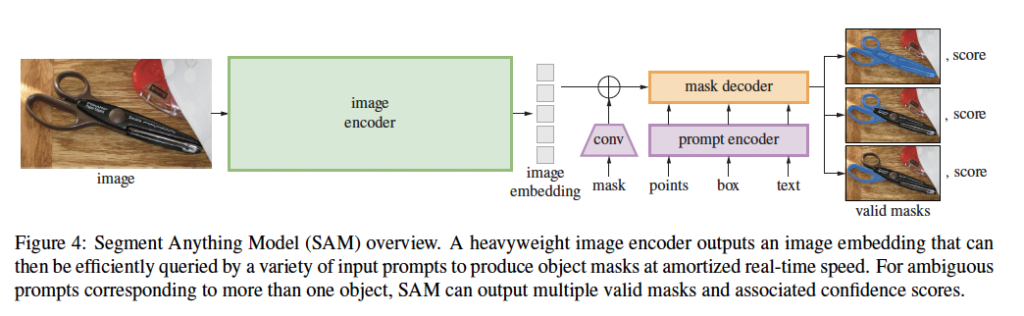
SAM은 위 그림 [Figure 4]와 같이 image encoder, a flexible prompt encoder, fast mask decoder로 3가지 구성 요소를 가지고 있습니다.
저자는 real time performance에 tradeoff가 있는 transformer vision 모델을 기반으로 모델을 구현하였습니다.
Image encoder
Image encoder는 고해상도의 이미지를 처리하기 위해 MAE(Masked Autoencoder)로 사전학습한 ViT 기반의 구조를 사용하였습니다. 이 Image encoder는 이미지 당 한번만 실행되며, 모델을 prompting하기 전에 적용됩니다.
Prompt encoder
Prompt encoder는 point, box, mask, text와 같은 prompt가 입력으로 들어왔을 때 prompt embedding을 출력하는 부분입니다. 이 prompt encoder는 위 그림에서 보라색 블럭에 해당합니다. 저자들은 여기서 prompt를 sparse한 것과 dense한 것으로 나누었습니다. point, boxes, text prompt는 sparse한 prompt에 해당하고, mask는 dense한 prompt로 본 것입니다. 여기서 Point나 box는 positional encoding처럼 표현하며, text는 CLIP의 text encoder를 사용하였습니다. Dense한 prompt인 mask는 convolution 연산을 한 후 image embedding과element-wise summation을 하는 식으로 동작합니다.
Mask decoder
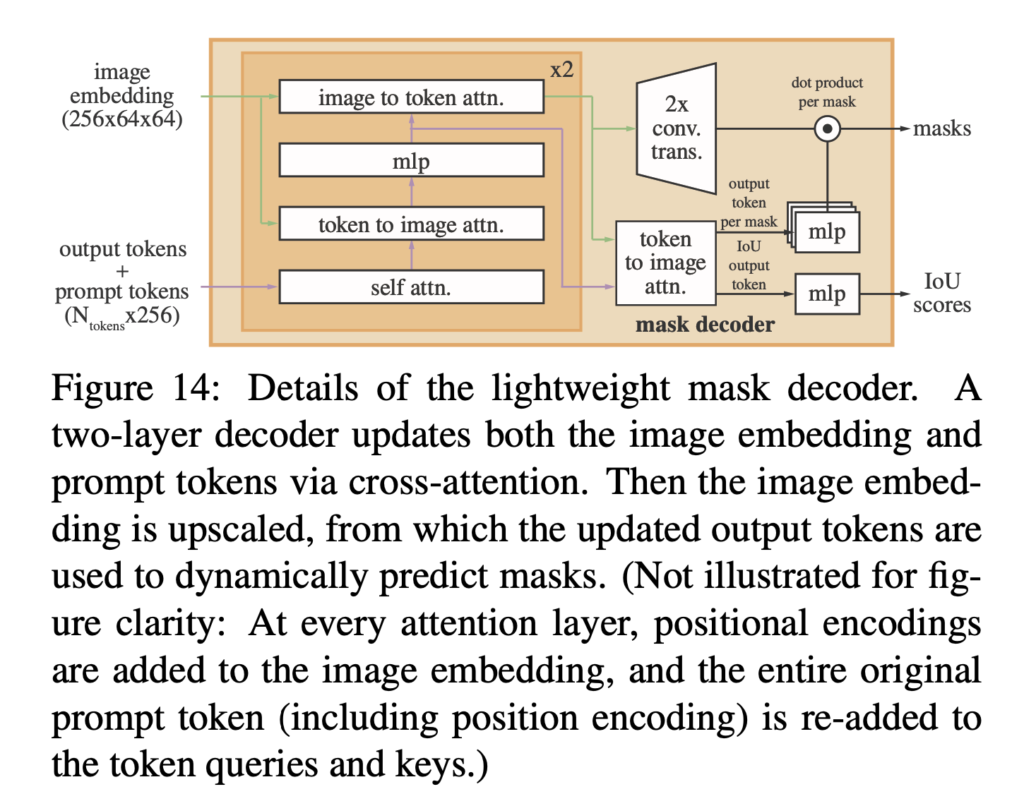
Mask decoder는 위의 Image encoder, Prompt encoder 이 두 encoder를 거치고 나온 embedding 값을 입력으로 segmentation map을 생성하는 부분입니다.
Mask decoder구조는 Transformer decoder block에 dynamic mask prediction head를 붙인 형태입니다. 이 mask decoder 내에서는 prompt embedding에 대해서 self-attention을 수행하고, image embedding과 양방향으로 cross-attention을 수행합니다.
[Figure 14] 그림과 같이 block을 2번 거친 후에는 image embedding은 upsampling되고, MLP는 output token을 dynamic linear classifier에 mapping하는 것을 볼 수 있습니다. 그 다음 각 image location에 대해 mask foreground 확률을 계산합니다.
Resolving ambiguity
앞단에서 언급한 모호한 prompt 입력이 들어왔을 때의 문제를 해결하기 위해 모델은 모호한(ambiguous) prompt가 주어지면 여러 valid한 mask를 예측해냅니다. 아래 그림과 같이 말이죠.
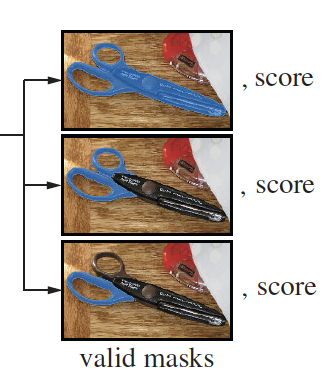
저자들은 3개의 mask가 출력되면 대부분의 케이스를 처리하기에 충분하다는 것을 발견하였습니다. (전체, 부분, 하위부분 이렇게 3개의 mask) 그리고 학습 중에는 이 세 mask 중 가장 loss가 작은 것만을 역전파 과정에서 사용합니다. mask의 순위를 매기기 위해서 모델은 confidence score를 예측하도록 하였습니다. (by estimated IoU)
Losses and training
Loss는 focal loss와 dice loss를 선형 결합하여 사용하였습니다.
4. Segment Anything Data Engine
Internet에는 segmentation mask가 충분하지 않기에 저자들은 data engine을 구축하여 11억 개의 mask dataset을 취득하였습니다. 이 데이터셋이름은 SA-1B입니다.
Data engine은 아래의 3가지 과정이 존재합니다.
- model-assisted manual annotation stage
- semi-automatic stage
- fully automatic stage
각 stage에 대해 하나씩 알아보도록 하겠습니다.
Assisted-manual stage
먼저 첫번째 stage인 model-assisted manual stage입니다. 여기서는 전통적인 우리가 잘 알고 있는 segmentation에서 dataset을 취득하는 과정과 동일하게 전문적인 어노테이터를 고용하여 foreground와 background object point를 클릭함으로써 마스크 라벨을 생성하도록 하였습니다.
이때 어노테이터들은 SAM 기반의 모델을 사용하는 브라우저 기반 툴을 사용하였는데, 이는 SAM 모델의 image encoder가 image들을 사전에 embedding 해놓은 상태로 라벨링을 진행한 것을 의미합니다. 그렇기에 어노테이터들은 이미지 한 장당 30초 내외의 시간이 걸렸다고 하네요.
이 첫 단계에서 사용된 SAM은 기존에 존재하던 공공 segmentation 데이터셋으로 학습시킨 것입니다. 이 과정을 진행하다 충분히 데이터가 어노테이션 되었다고 판단이 되면 SAM을 새로 어노테이션 된 mask를 가지고 재학습을 시켰으며, 이 과정을 6번 진행했습니다. 결과적으로 첫 stage에서는 12만장의 image에 대해 430만개의 mask를 모을 수 있었습니다.
Semi-automatic stage
두번째 단계에서는 모델이 무엇이든 segment할 수 있는 능력을 기를 수 있도록 mask를 다양하게 만들어내는 것을 목표로 삼았습니다. 여기서 어노테이터들은 덜 주목되는 object에 집중하고자 하였는데, SAM모델이 미리 이미지에 대해 confident score가 높은 마스크를 자동으로 생성해두면 어노테이터들은 미리 마스크가 채워진 이미지에 대해 추가적으로 어노테이션 되어 있지 않은 object에 대해 마스킹을 하는 작업을 하였습니다. 이 단계에서는 18만장의 이미지에 대해 590만 개의 mask를 얻을 수 있었습니다. 첫 번째 단계와 마찬가지로 SAM모델은 데이터가 새로 모일때마다 재학습되었습니다. (5번)
Fully automatic stage
마지막 stage에서는 fully automatic으로 어노테이션이 진행되었습니다. 즉, 사람이 어노테이션 하는 과정 없이 모델이 예측해 낸 mask만으로 어노테이션을 진행한 것입니다. 이는 앞선 두 가지 과정을 거쳤기 때문에 가능하다고 논문에서는 말합니다. 이 단계에서는 앞 두 단계와는 달리 모호한 prompt를 인식할 수 있는 모델을 개발하여 입력이 모호한 경우에도 valid한 마스크를 예측하도록 하였습니다. 마지막 fully automatic 단계에서는 11M개의 이미지에 대해서 총 11억 개의 mask를 생성하였습니다.
데이터 세트의 모든 11M 이미지에 완전 자동 마스크 생성을 적용하여 총 11억 개의 고품질 마스크를 생성했으며, 다음에서 결과 데이터 세트인 SA-1B에 대해 설명하고 분석합니다.
5. Segment Anything Dataset
이렇게 앞에 단계를 거쳐 생성된 segmentation 데이터셋 SA-1B에 대해 알아봅시다.

SA-1B 데이터셋의 예시는 위 [Figure-2]에서 확인해볼 수 있습니다.
Masks
11억개의 생성된 mask는 99.1%가 완전히 automatic하게 사람의 어노테이션 없이 생성되었습니다. 그렇기에 automatic하게 생성된 마스크의 품질이 어떤지는 굉장히 중요하겠죠. 그렇기에 어노테이션 전문가가 어노테이션 한 이미지와 automatic하게 생성한 이미지를 비교해보았는데, 결과가 크게 다르지 않았다고 합니다. 그렇기에 SA-1B 데이터셋에는 fully automatic하게 생성된 mask만 포함하였습니다.
Mask quality
mask의 quality를 평가하기 위해서 전체 이미지 중 랜덤으로 500개의 이미지를 샘플링한 후, 어노테이션 전문가에게 이 이미지들에 대해 어노테이션을 수행하도록 하였습니다. 이후 각 이미지에 존재하는 mask들간의 IoU를 계산한 결과 94%의 mask가 90%이상의 IoU를 가지며, 97%의 mask 쌍이 75%이상의 IoU를 가지는 결과를 보였습니다.
이전에 존재하던 기존 segmentation 데이터셋과 동일한 과정을 진행한 결과 mask에 대한 IoU는 85~91%로 나타났고 이를 보아서는 본 저자들이 생성해 낸 SA-1B 데이터셋은 기존 데이터셋의 mask와 quality가 크게 떨어지지 않다고 볼 수 있습니다.
Mask properties
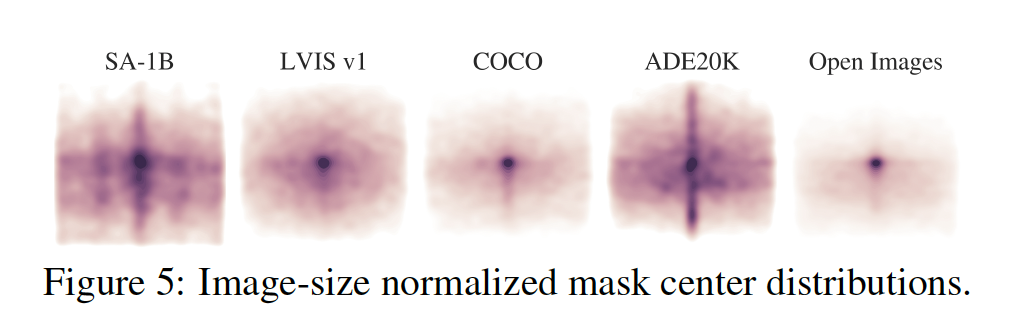
위 [Figure 5]는 SA-1B 데이터셋과 다른 기존 segmentation 데이터셋에서의 object 중심(center) 공간적 분포를 보여주는 그림입니다. SA-1B와 가장 유사한 분포를 가지는 데이터셋인 LVIS v1과 ADE20K와 비교했을 때 SA-1B는 이미지 모서리의 범위가 더 많은 것을 볼 수 있습니다.
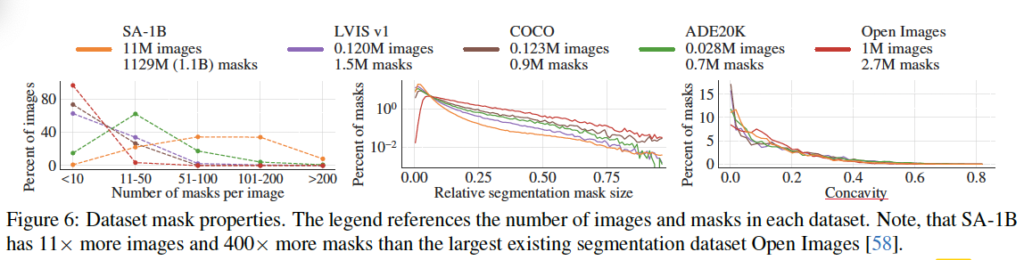
위 [Figure 6]은 데이터셋을 크기로 비교한 그래프입니다. 결과를 보면 SA-1B는 두번째로 가장 큰 데이터셋인 Open Images보다 11배 더 많은 이미지와 400배 더 많은 mask를 가지고 있습니다.
왼쪽 그래프는 이미지 당 mask 분포를 보여주는 그래프고, 가운데 그래프는 mask 크기를 비교하는 그래프입니다. 예상한대로 본 논문의 데이터셋인 SA-1B가 이미지당 마스크 수가 많기에 크기가 작은 mask 수도 많은 것을 확인할 수 있습니다. 또 우측의 그래프는 mask concavity를 살펴보는 그래프인데, 이는 잘은 모르겠지만 mask 면적을 mask의 면적으로 나눈 값에서 1을 뺀 값이라고 합니다. . . 결론적으로 다른 데이터셋과 유사한 분포를 가지는 것으로 보아 비슷한 concavity(오목함)을 가진다고 할 수 있겠네요.
6. Zero-shot Transfer Experiments
이제 SAM을 사용한 zero-shot transfer 실험 결과를 살펴보겠습니다.

위 그림은 SAM의 zero-shot transfer능력을 평가할 때 사용된 23개의 데이터셋의 샘플들입니다.
실험 파트에서는 총 5가지 task에 대한 실험을 진행하였습니다.
6.1. Zero-Shot Single Point Valid Mask Evaluation
먼저 하나의 point prompt를 입력으로 받았을 때 object의 segmentation mask를 추출해내는 task입니다.
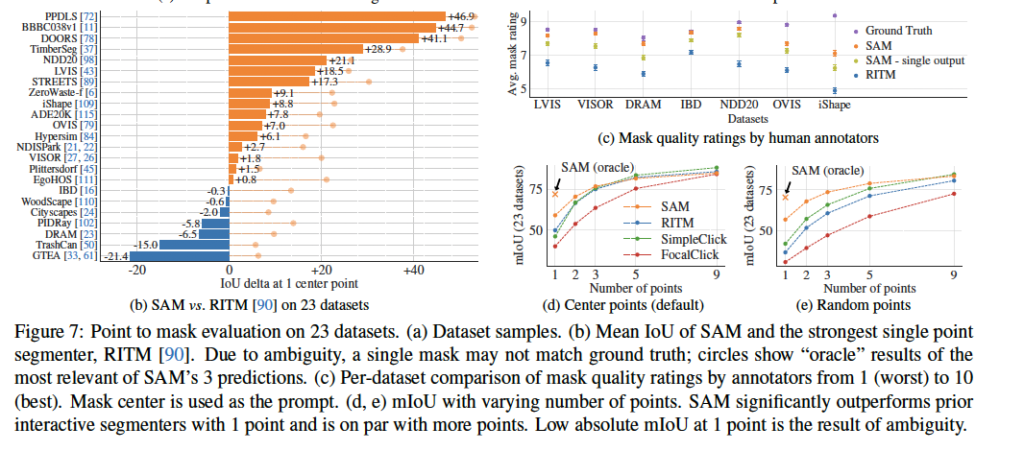
위 [Fig 7 – b] 결과를 보면 23개의 데이터셋 중 16개에서 RITM보다 좋은 성능을 보입니다. [Fig 7 – c ]는 human annotator들이 mask를 정성적으로 평가한 결과인데, 정성적 평가는 모든 데이터셋에서 RITM 보다 좋은 결과를 보이고 있습니다. [Fig 7 – d]는 몇개의 point를 prompt로 주는가에 따른 실험 결과인데, point를 많이 줄수록 모델가의 성능 차이는 미비하지만, 개수가 1개만 주어질 때는 SAM의 성능이 타 모델보다 훨씬 좋은 것을 볼 수 있습니다.
6.2. Zero-Shot Edge Detection
SAM을 사용하여 edge-detection도 하였는데, 이때는 이미지에 대해 segmentation을 수행한 다음 sobel filtering을 거치는 과정으로 edge를 검출하였다고 합니다.
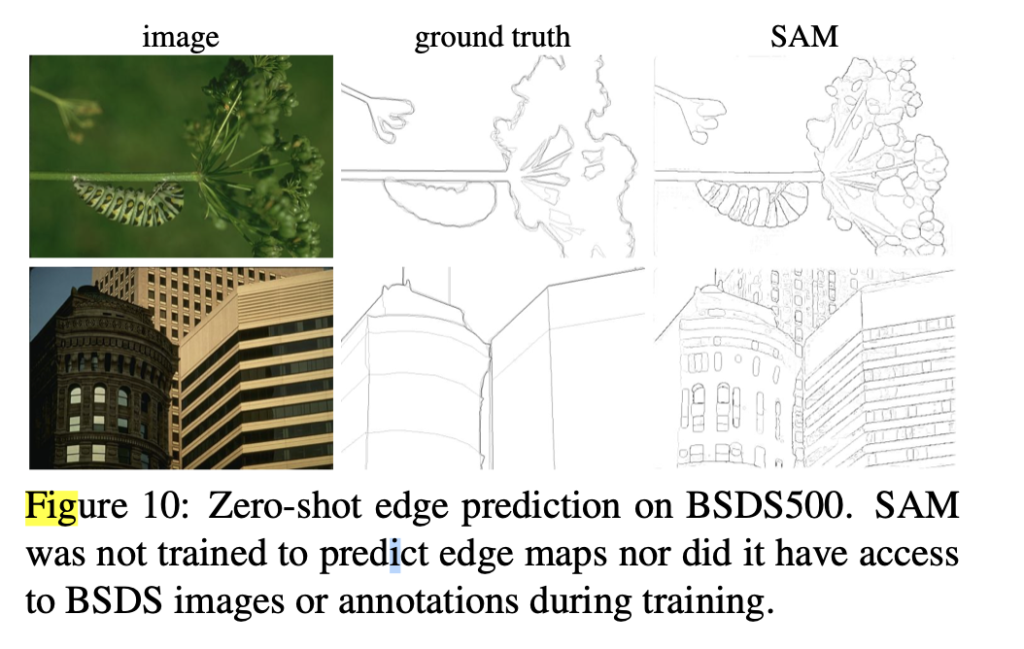
[Fig 10] 결과를 보면 SAM은 edge detection을 하도록 학습하지 않았음에도 불구하고 edge map을 잘 생성해 내는 것을 보입니다.
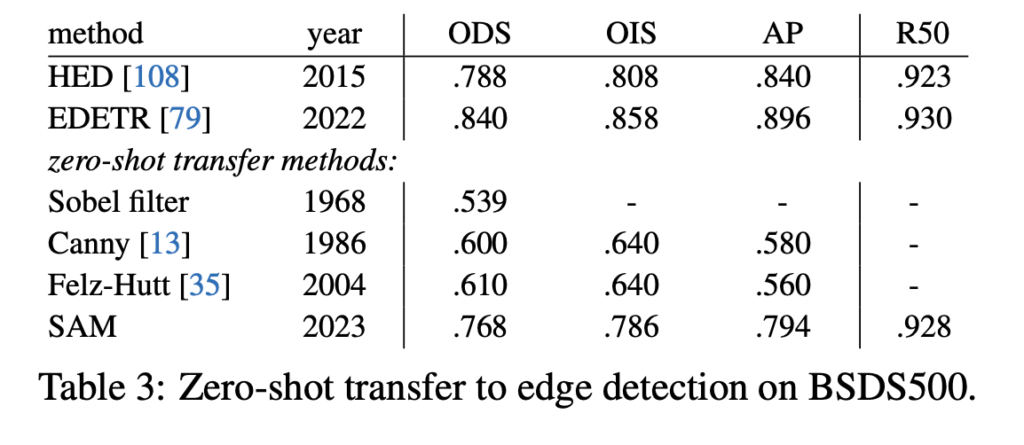
[Table 3]은 이에 대한 정량적 결과입니다. 기존 딥러닝 방법론인 EDETR과 비교했을 때는 성능이 좀 떨어지지만, 이전의 zero-shot transfer 방법론들 보다는 훨씬 좋은 성능을 보입니다.
6.3. Zero-Shot Object Proposals
다음으로 object proposals generation이라고 하는 task에 대한 실험입니다.
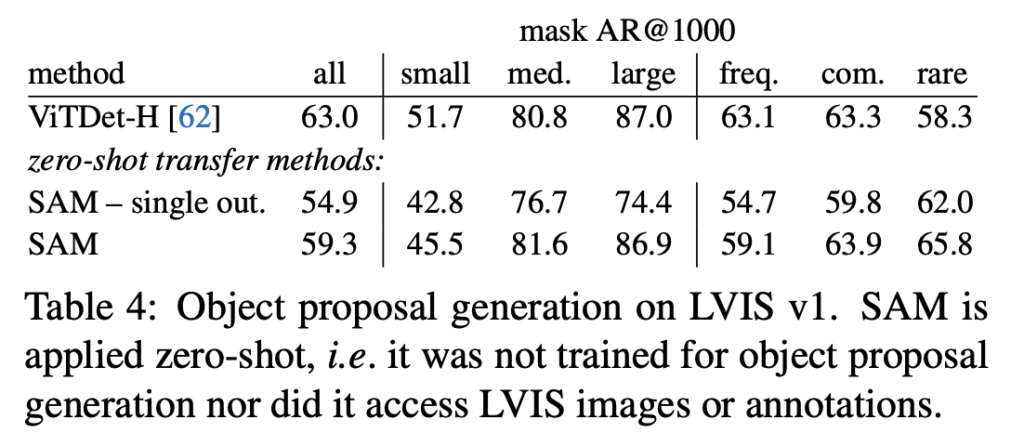
[Table 4] 결과를 보면 ViTDet-H detector와 성능을 비교했을 때 SAM의 성능은 조금 떨어지지만, rare한 class에 대해서는 VitDet-H보다 더 좋은 성능을 보이고 있습니다.
6.4. Zero-Shot Instance Segmentation
방금 전 실험인 object proposals에서 얻어낸 box를 prompt로 사용하여 segmentation을 진행한 결과입니다.

결과를 보면 ViTDet-H보다 좋지 않은 box로 segmentation을 수행했음에도 성능이 비슷한 것을 보여줍니다.
6.5. Zero-shot Text-to-Mask
마지막으로 text를 prompt로 주었을 때의 실험 결과입니다. 이때는 유일하게 정량적 실험 table이 존재하지 않네요 . .
text prompt를 주기 위해서는 annotation을 새로 해야 하기 때문에, CLIP의 이미지 인코더를 사용하여 뽑아낸 임베딩을 prompt로 넣었습니다.

[Fig 12]는 이에 대한 정성적 결과입니다. 저자들이 말하기로는 SAM은 “a wheel”과 같이 간단한 text prompt 뿐만 아니라 “beaver tooth grille”과 같은 문구를 기반으로도 object를 segmentation을 해낼 수 있었다고 합니다.
또 왼쪽의 wiper를 prompt로 주었을 때는 잘 segmentation해내지 못했지만 추가적으로 point를 prompt로 주었을 때는 잘 예측을 해내는 것을 볼 수 있습니다.
안녕하세요. 좋은 리뷰 감사합니다.
읽으면서 저자들의 생각이 굉장히 흥미로웠던 것 같습니다. foundation model을 만들기 위해서는 어떻게 해야 하는지 굉장히 체계적으로 잘 풀어내서 읽는데 재밌었습니다. 궁금한 점은 interactive segmentation에서 제안한 방식을 사용하는데 interactive segmentation 방법론은 명확한 input에서 valid한 mask를 예측하는 것이 목표인데 본 논문은 모호한 prompt가 입력으로 들어왔을 때 항상 valid한 mask를 예측한다는 목표가 다름에도 불구하도 잘 작동한다는 것이 궁금하네요. 윤서님께서는 그 이유에 대해서 어떻게 생각하시나요?
감사합니다.
안녕하세요. 댓글 감사합니다.
mask를 출력할 때 object의 전체, 부분, 하위부분 이렇게 3개의 mask를 출력하도록 했기 때문이라고 생각합니다. 또,,, 큰 규모의 데이터로 학습하기도 했구요,,,,,
안녕하세요 ! 좋은 리뷰 감사합니다.
본 논문의 저자들이 만든 데이터셋인 SA-1B을 기존에 존재하던 타 segmentation 데이터셋과 비교하는 부분에서 concavity를 비교하는 부분이 있던데, 이 concavity는 왜 mask 면적을 mask 면적으로 나눈 값에서 1을 뺀 값으로 구할수 있는지 궁금합니다. 이 concavity라는 것이 무엇인가요 ?
또, Figure 7의 (b)가 하나의 point prompt를 입력으로 받았을 때 object의 segmentation mask를 추출해내는 task에 대한 실험 결과로 보이는데, 그래프에 보이는 주황색 점은 무엇을 의미하는 것인가요 ?
감사합니다.
안녕하세요. 댓글 감사합니다.
Concavity란,,,, 얼마나 오목한지?(concave한지)를 나타내는 척도라고 보면 되겠습니다. 잘은 모르겠지만, 동그란 공같은 물체는 오목한 부분이 없다고 할 수 있고 별 모양같은건 좀 오목한 부분이 많다고 할 수 있는데, 이렇게 concavity가 높을수록 더 객체가 복잡한 모양이겠죠. 그래서 데이터셋끼리 이를 비교하여 얼마나 복잡한?? 다양한 형태의 객체를 포함한 데이터셋인지를 보려고한 것 같습니다. . .
또, figure7 (b)에서 주황색 점은 SAM의 3가지 prediction 중에 가장 높은 성능을 보인 mask 결과입니다.
안녕하세요, 정윤서 연구원님, 좋은 리뷰 감사합니다. 제가 평소에 읽던 분야가 아니라 제가 정확하게 이해했는지는 모르겠는데.. 결국 segmentation에 대한 foundation 모델을 만들기 위해 MAE를 이용해 어느정도 visual recognition task에 대한 표현력을 갖춘 모델을 만들고자 하는 것으로 이해하면 될까요?
foundation model이 정확하게 무엇인지에 대해서도 궁금합니다. 어느정도 vision에 대한 표현력을 가지고 있어서, zero-shot이나 few-sho에 적용해도 무리가 없는 모델로 이해했는데, 올바르게 이해한 것인지 궁금합니다. 해당 물음에 대한 답변 남겨주시면 감사하겠습니다.
안녕하세요. 댓글 감사합니다.
segmentation에 대한 foundation 모델을 만들기 위해 MAE를 이용해 어느정도 visual recognition task에 대한 표현력을 갖춘 모델을 만들고자 하는 것으로 이해하면 될까요?
→ 음 . . 네 맞습니다.
foundation model이 정확하게 무엇인지에 대해서도 궁금합니다.
→ foundation model이란,,, 특정 task에 국한되지 않구 다양한 task에서 좋은 성능을 보일 수도 있도록 대규모 데이터셋으로 학습해 좀 일반화된 representation을 학습한 모델입니다.
안녕하세요 정윤서 연구원님 좋은 리뷰 감사합니다.
개인적으로 읽으면서 흥미로웠던 부분은 data engine이었는데요, 하나의 모델을 초기에는 labeled 데이터로 supervised로 학습하고, 중반에는 human annotator, 후반에는 모델이 자동으로 labeling을 진행하여, 최종적으로는 모델의 예측값으로만 annotation을 진행한 것이 인상적이었습니다.
그런에 fully automatic stage에서 ‘이전 단계와는 달리 모호한 prompt를 인식할 수 있는 모델’을 추가하였다고 하는데요, 해당 모델은 Resolving ambiguity 부분에서 언급하신 여러 개의 valid mask를 예측하는 것을 의미하나요? 그렇다면 이전 단계에서는 해당 모듈 없이 학습한 것이 되는데 그 이유는 무엇인지도 궁금합니다.
마지막으로 model의 예측값으로 labeling을 진행한다는 것이 psudo labeling과 비슷해 보이기도 하는데 해당 방법론은 모델의 정확도가 떨어질 경우 label에 노이즈가 발생하게 되므로 mask의 quality 또한 중요할 것 같습니다. 그런데 기존 데이터셋(아마 human annotated 데이터셋이겠죠…?)는 85~91%IoU를 가진다고 하셨는데 생성된 label은 약 3%정도가 75%미만의 IoU를 가지는 것을 보아 어느 정도는 정확도가 떨어지는 라벨이 생성된 것 같습니다. 해당 관점에서 논문에 언급된 점은 없는지도 궁금합니다.
fully automatic stage에서 ‘이전 단계와는 달리 모호한 prompt를 인식할 수 있는 모델’을 추가하였다고 하는데요, 해당 모델은 Resolving ambiguity 부분에서 언급하신 여러 개의 valid mask를 예측하는 것을 의미하나요? 그렇다면 이전 단계에서는 해당 모듈 없이 학습한 것이 되는데 그 이유는 무엇인지도 궁금합니다.
→ 초중반 단계에서는 모델이 일반적인 segmentation task를 학습하는데 집중하도록 한 것 같습니다. 모호하지 않고 명확한 prompt부터 인식하도록 하여 모델의 인식 능력을 키운 것 같아요.
마지막으로 model의 예측값으로 labeling을 진행한다는 것이 psudo labeling과 비슷해 보이기도 하는데 해당 방법론은 모델의 정확도가 떨어질 경우 label에 노이즈가 발생하게 되므로 mask의 quality 또한 중요할 것 같습니다. 그런데 기존 데이터셋(아마 human annotated 데이터셋이겠죠…?)는 85~91%IoU를 가진다고 하셨는데 생성된 label은 약 3%정도가 75%미만의 IoU를 가지는 것을 보아 어느 정도는 정확도가 떨어지는 라벨이 생성된 것 같습니다. 해당 관점에서 논문에 언급된 점은 없는지도 궁금합니다.
→ 추가로 human annotator들이 mask quality를 평가했는데요, random으로 sampling한 500개의 이미지에서 약 50000개의 mask를 사용해 전문 annotator가 모델이 예측한 mask의 퀄리티를 향상시키도록 했습니다. 이후, human annotator들이 생성한 mask와 model이 생성한 mask사이의 IoU를 계산해서 quality를 평가했는데요, 94%이상의 mask 쌍들이 90%이상의 IoU를 갖는 결과를 보였다고 합니다 .
안녕하세요 윤서님 오래전에 쓰신 글을 읽게 되었네요,, 리뷰 감사합니다
혹시 모델이 모호한 prompt에 대해 여러 valid한 mask를 예측할 때, 각 mask를 어떻게 정의하는지에 대한 규칙(?)이 있나요? 전체, 부분, 하위 부분을 구체적으로 어떻게 구분하는지 궁금합니다!!
안녕하세요. 댓글 감사합니다.
SAM은 모호한 prompt에 대해 최대 3개의 valid한 mask를 예측하는데, 이를 전체, 부분, 하위 부분처럼 명시적으로 라벨링을 하지는 않습니다. 대신에 이 포함 관계가 있는 서로 다른 크기의 mask를 동시에 뽑아내고 각 mask에 IoU 기반의 confidence score를 부여해서, 학습 시에는 multiple choice learning 방식을 적용해 여러 후보 GT와 IoU가 가장 높은 mask에 대해서만 loss를 계산하는 식으로 했습니다.
안녕하세요 윤서님 리뷰 잘 읽고 갑니다. 읽다 궁금한 것 몇 가지 물어볼게요
1. mask를 프롬프트로 주는 경우 마스크의 일부를 그려주면 해당 객체에 해당하는 전체 마스크를 반환하는 건가?
2. 모호한 프롬프트에 대해서 기존 방법에서 출력하는 invalid mask의 예시로는 어떤 게 있는지가 궁금합니다.
3. valid한 mask가 3개 정도 나오고 confidence score를 기준으로 valid한 mask 중에 순위를 매겨 최종 mask가 결정되는 것으로 이해하였는데요 실제 각 프롬프트 마다 mask의 confidence score가 높기 위해서는 어떠해야 하는 건가요?
감사합니다~!
안녕하세요. 댓글 감사합니다.
1. 넵 맞습니다.
2. invalid mask 예로는, click한 지점과 전혀 무관한 object가 선택되거나, 의미 없는 배경이나 노이즈 패턴이 mask output으로 나온다던가 하는 경우가 있겠습니다.
3. mask마다의 confidence score는 GT와의 IoU가 높으면 됩니다.