
안녕하세요, 허재연입니다. 지난번 리뷰에 이어 Active Learning(AL) 논문을 들고 왔습니다. 이번 주 세미나에서 다뤘던 논문으로, AL 논문을 읽다 보면 자주 등장하는 방법론이므로 정리해두고자 합니다.
Active Learning은 데이터 부족 이슈를 해결하기 위해 연구되고 있는 분야 중 하나입니다. 우리에겐 항상 양질의 labeled data가 부족하고, 라벨링 코스트는 제한되어 있습니다. 일반적으로 데이터를 모으는 것보다는 annotation에 더 많은 비용이 소모되므로, 라벨러는 제한된 라벨링 비용을 고려하여 수집한 데이터 중 어떤 데이터들을 먼저 annotation 할지 선별해야 합니다. 이 때, 인공지능 모델에게 더 학습 효율이 좋은 unlabeled data subset을 고르는 것이 AL입니다.
AL 연구에는 크게 두 가지 연구 갈래가 있는데, 하나는 1. 모델이 예측하기 어려워하는 데이터가 더욱 가치있는 데이터일 것이라는 관점에서 문제를 해결하고자 하는 uncertainty 기반 연구와, 2. 전체 unlabeled pool의 분포를 잘 반영하는 subset이 좋은 데이터일 것이라는 관점에서 접근하는 diversity 기반 연구가 있습니다. uncertainty 기반 방법은 모델이 어려워하는 데이터에 집중하므로 추출한 subset에 데이터 편향이 발생할 수 있다는 한계가, diversity 기반 방법은 정작 추출한 데이터가 (uncertainty 기반 방법으로 추출한 데이터와 비교해) 딥러닝 학습 효율이 낮다는 한계가 있습니다. 물론 이 둘을 적절히 섞으려는 시도도 있습니다. 각각의 관점 방법론에 대해 제가 이전에 리뷰한 글들이 있으니, 각 방법들에 대해 더 궁금하신 분들은 이전 리뷰 (uncertainty 기반의 CEAL, diversity 기반의 Core-set)를 참고하시기 바랍니다.
제가 이번에 리뷰할 논문은 2019 CVPR에서 oral에 선정된 Learning Loss for Active Learning (LL4AL)이라는 논문입니다. 주저자는 우리 나라의 의료 영상 스타트업인 Lunit의 co-founder인 유동근 박사님이시고, 2저자는 KAIST RCV의 권인소 교수님이십니다. Learning Loss는 uncertainty 기반 AL프레임워크인데, 간단하면서도 기존의 한계를 해결하는 획기적인 방법을 제안해 AL 분야에서 꼭 읽어봐야 하는 방법론이라고 합니다. 이름 그대로 ‘Loss를 예측하고 학습하는’ 방법인데, 함께 살펴보겠습니다.
Introduction
introduction에서는 기존 방법론들의 한계를 짚고, 이를 개선하기 위한 저자의 방법론을 소개합니다. 지금도 마찬가지이지만, 논문이 발표된 시기에도 심층신경망 학습에 사용할 데이터가 턱없이 부족했습니다. 신경망의 성능은 아직 전혀 saturated되지 않았고, 더 많은, 더 질좋은 training data로 성능을 개선시킬 여지가 많았었습니다. 이런 문제를 어떻게든 개선해보고자 semi-supervised learning과 unsupervised learning 기법이 연구되고 있었지만, 이 방법론들은 결코 fully-supervised learning에는 미치지 못했습니다. semi-supervised같은 경우에는 labeled data의 비율이 높을수록 더 나은 성능을 보장했는데, 이는 결국 더 좋은 성능을 달성하기 위해서는 더 많은 labeled data가 필요하다는것을 의미한다고 합니다.
annotation cost는 target task가 무엇이냐에 따라 천차만별입니다. 단순 분류를 위한 클래스 라벨링은 비교적 비용이 낮은 편이지만, detection에서는 그보다 비용이 큰 detection box를 쳐야하고, segmentation은 픽셀 단위로 annotation을 해야 하므로 라벨링 비용이 훨씬 커지게 됩니다. 저자는 의료 영상 annotation 상황을 언급하는데, 이는 수년간 훈련한 전문의가 많은 시간을 들여야 하는 작업이므로 비용이 매우 크다고 합니다. 이렇게 annotation 예산이 제한되어 있는 상황에서 어떻게 라벨링하는게 좋을까요? 한가지 접근 방법은, 모델이 어려워하기에 라벨링 효율이 좋은 데이터를 선별하는 것일 겁니다. Active Learning은 informative 한 데이터가 더욱 모델 학습에 도움이 될 것이라는 아이디어를 가지고 고가치 데이터를 선별하고자 합니다.
저자는 Active Learning의 접근법으로uncertainty, diversity, expected model change 방법을 소개합니다. 위에서 소개했듯이 uncertainty 방법은 모델이 어려워하는(분류 문제에서 entropy 기반으로 데이터 불확실성을 측정하거나, 서포트 벡터와 결정경계간 거리를 이용) 데이터를 고가치 데이터로 간주하고, diversity 기반에서는 전체 unlabeled pool의 데이터 분포를 반영하는 data point를 선별하고자 합니다. expect model change법은 해당 데이터를 labeling했을 때 모델의 파라미터를 많이 수정할 것으로 예상되는 데이터를 고르고자 합니다(gradient 크기를 이용하는 등의 방법을 사용하는데, 비교적 모델을 많이 바꿀 수 있는 데이터가 고가치 데이터일것이라고 가정합니다).
하지만 대부분의 uncertainty법론은 너무 task-specific해서 다양한 태스크에 적용시키기에 한계가 있고(uncertainty를 측정하는데 분류 모델의 softmax의 output을 이용하는 등 task마다 이에 맞게 새로 설계해야 함), distribution(diversity)기반 방법들은 hard example을 이용하지 않는다는 단점이 있습니다. 이 이외에도 앙상블 방법(동일 네트워크를 여러 번 학습시키고 prediction의 분산을 측정해서 이용)과 베이지안 방법(층마다 dropout을 껴서 학습시키고 inference할때도 dropout을 끄지 않고 N번 feedforward해서 그 차이 측정)이 있긴 하지만 이들은 연산량이 너무 많아서 실제로 적용하기에는 무리가 있습니다. 저자는 이러한 기존 AL 방법들의 한계를 해소하고 싶어합니다.
심층 신경망은 task가 무엇이든, 얼마나 많은 task의 결합이든(regression+classification인 task에도 충분히 적용 가능), 얼마나 모델이 복잡하고 규모가 크든 하나의 loss값을 줄여나가면서 학습합니다. 저자는 이 점에서 task-agnostic한 Active Learning 방법을 생각해냈습니다. 각 data point의 loss를 예측하는게 가능하다면, 높은 loss를 가지는 데이터를 선별하는것이 가능할 것이고, 그렇게 선택된 데이터는 현재 모델의 학습에 효율이 좋을 것이라고 가정합니다. 이를 구현하기 위해 딥러닝 모델에 ‘loss prediction module’을 부착하고 해당 모듈이 input data point에 대한 loss를 예측하도록 학습시킵니다. 이 방법은 어떤 task의 모델에도 사용할 수 있습니다. 저자는 제안하는 방법론을 classification, regression(human pose estimation), classification+regression(object detection) task에 대해 검증했습니다. 이에 따라 저자는 본 논문의 contribution을 다음과 같이 요약합니다 :
- loss preediction module을 이용한 간단하고 효율적인, 최신 딥러닝 모델에 바로 적용시킬 수 있는 방법을 제안했다.
- 최신 모델 구조에 접목해서 제안 방법론을 1. classification 2.regression, 3. classification+regression의 3가지 task에서 평가했다.
Method
overview
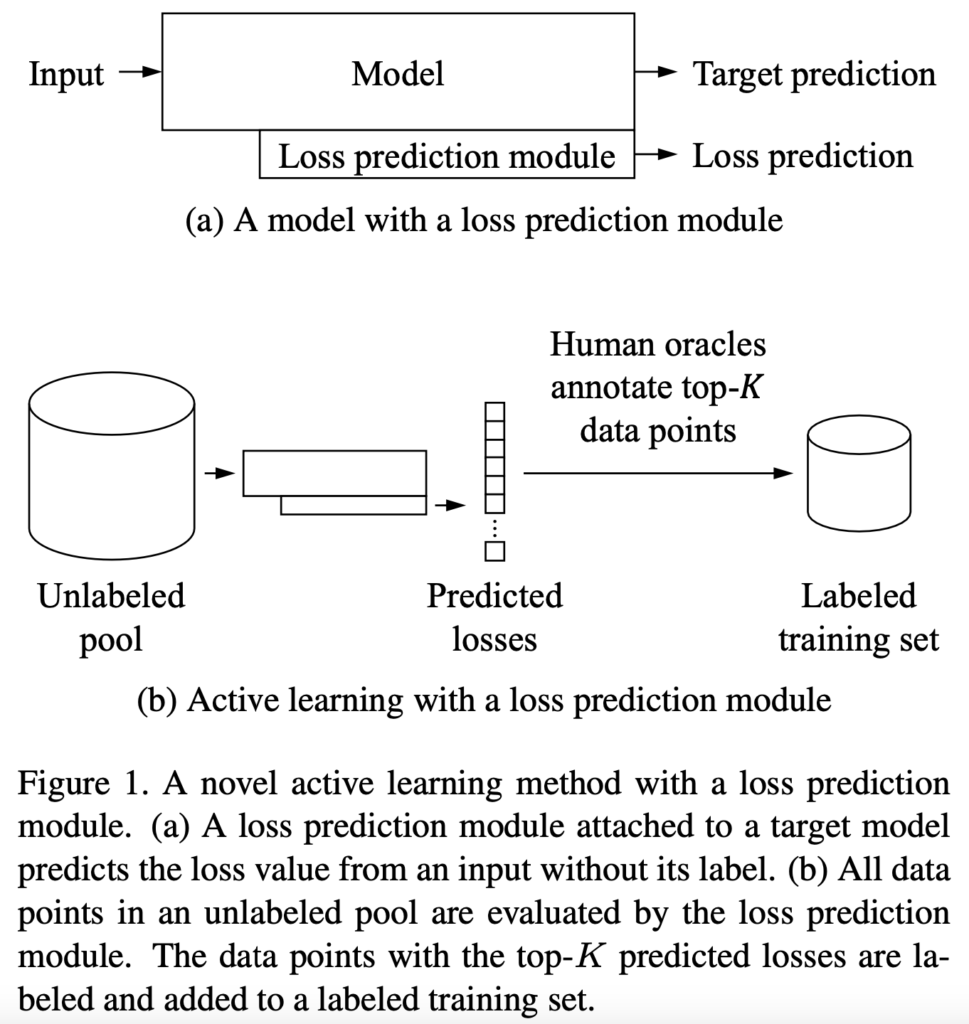
저자들은 Loss 자체를 예측하고 학습하고 예측하는 learning loss 라는 방법을 제안합니다. 원래 학습의 대상인 target 모델에 작은 loss prediction module을 붙여 해당 모듈이 loss를 예측하도록 하고 이 loss를 가지고 고라치 데이터를 선별합니다. unlabeled data 10개가 들어오면 loss prediction module은 라벨 없이 해당 데이터들이 어떤 loss를 가질지 예측하고, 10개의 loss를 sorting해서 top k개를 선택해 라벨링 한 다음 labeled training set에 추가합니다. 딥러닝 모델과 task가 아무리 복잡해도 결국 신경망을 최적화 할 때는 하나의 single scalar loss로 최적화를 진행하는데, loss의 최적화 과정에 집중하는 딥러닝의 기본으로 돌아간 접근법으로 볼 수 있겠습니다.
Loss prediction Module
loss prediction module은 target model의 loss를 모방해 학습하려 합니다. 저자들은 active learning에서 task-specific uncertainty를 정의하는 수고를 최소화하고, computational cost도 최소화 할 수 있도록 모듈을 구성하려고 했다고 합니다(점점 딥러닝 모델의 규모가 커지는데 이런 대규모 모델에도 무리없이 적용할 수 있게 하고자 했습니다). 이에 따라 1. target model보다 훨씬 작고 2. target model과 함께(jointly) 학습하는 module을 설계했습니다.
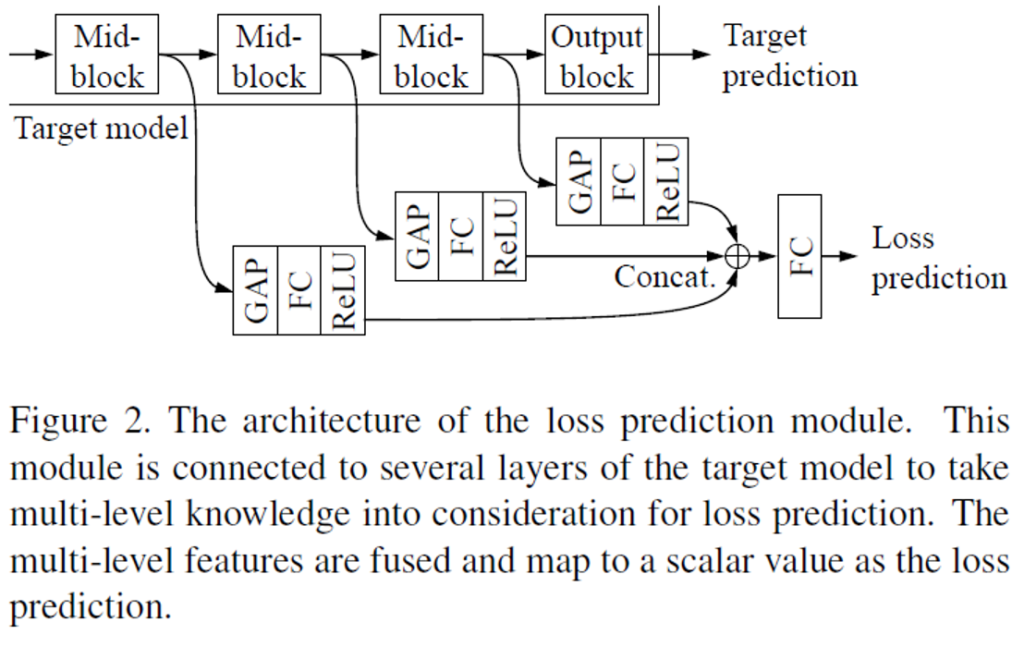
Fig2를 참고하면 loss prediction module이 어떻게 설계되었고 동작하는지 쉽게 이해할 수 있을 것입니다. 모델의 중간중간 mid-level block에서 multi layer feature map을 추출해서 다양한 수준의 정보를 고려하고자 하였습니다. 이 featuremap에 Global Average Pooling을 적용해 하나의 벡터로 편 다음에(feature map을 4D 텐서 형태가 아닌, 벡터로 압축해서 해당 정보를 사용하고자 한다고 생각하시면 됩니다) FC->ReLU를 거쳐 concatenation한 다음 최종적으로 FC를 다시 거쳐 Loss prediction을 수행하게 됩니다. 이 predicted loss를 GT loss와 비교해서 학습을 다시 진행하는데, predicted loss와 GT loss 간의 loss를 다시 구해서 이 최종 loss (predicted loss와 GT loss사이에서 구한 loss prediction loss)를 최적화하면서 학습을 진행하게 됩니다. 뭔가 비슷한 이름이 계속 나와서 헷갈릴 수 있다는 생각이 드는데, 다음 그림을 보면서 이해하시면 어렵지 않을 것입니다. 그림을 보며 다시 한번 과정을 되짚어보겠습니다.
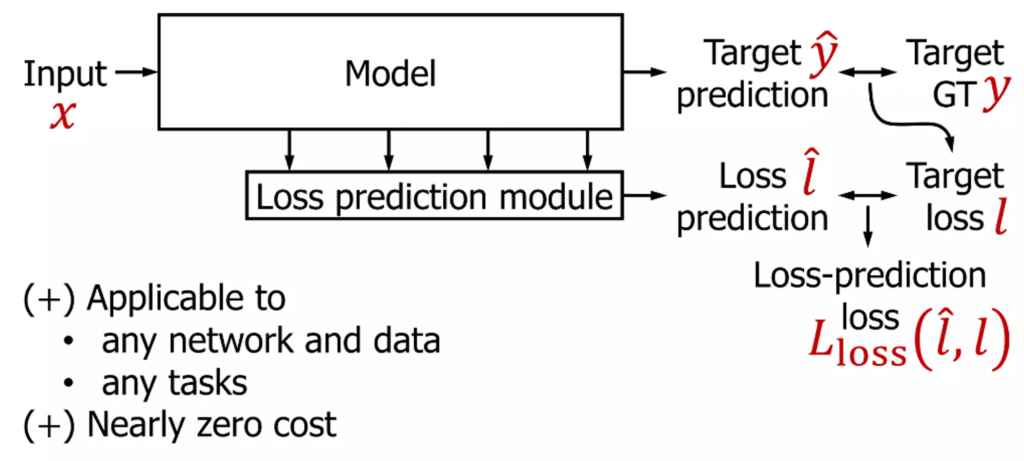
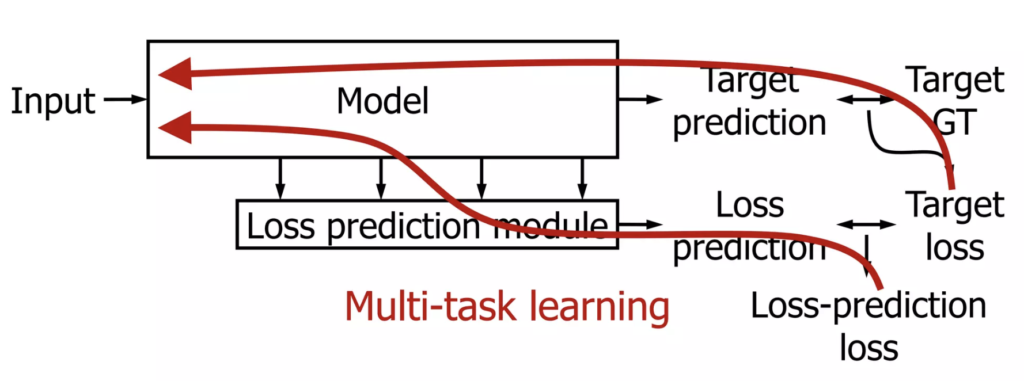
labeled dataset에는 target GT가 있습니다. 그러므로 target task를 진행하면서 target loss를 계산할 수 있습니다. 원래 우리는 이 target loss로부터 backpropagation을 해서 모델 학습을 진행하게 됩니다. 저자들은 이 target model에 Loss prediction module을 추가합니다. 이 친구는 로스를 예측하는 하나의 스칼라값(loss prediction. predicted loss.)을 출력합니다. 이 loss prediction은 target loss를 GT로 학습이 진행됩니다. 최종적으로는 loss prediction과 Target Loss를 비교해서 Loss를 predict하는 loss(Loss prediction loss)를 새로 구하게 됩니다. 그럼 해당 모델은 Loss-prediction loss와 target loss를 합한 최종 loss를 가지고 Multi-task learning을 하면 된다. 이렇게 학습한 네트워크는 1. 어떤 network, 어떤 data, 어떤 task에도 적용할 수 있으며, 2. loss prediction을 얻을 때 중간 mid-level feature를 몇 개 가져와서 feed-forward 하는것이기 때문에 cost가 낮다는 장점이 있습니다.
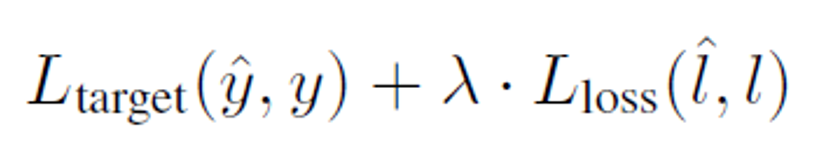
Loss 설계
Loss-prediction loss를 최적화 하는 과정에서 Loss prediction module을 학습할 수 있습니다. 그럼 Loss-prediction loss는 어떻게 설계해야 할까요? 직관적으로는 간단한 회귀식인 MSE 를 이용할 수 있을 것으로 보입니다. 하지만 저자는 MSE를 이용해서 학습을 이용했을 때 학습이 원할하게 되지 않았다고 합니다. 이는 Loss prediction이 학습에 대한 GT로 참고하는 target loss가 계속 학습을 진행하면서 작아지기 때문입니다.
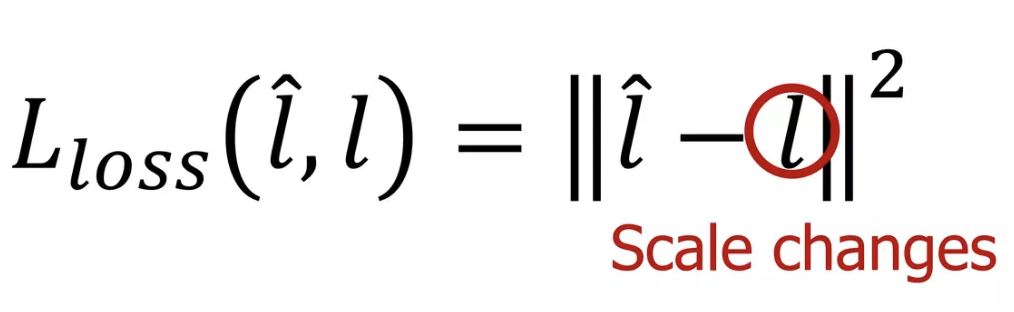
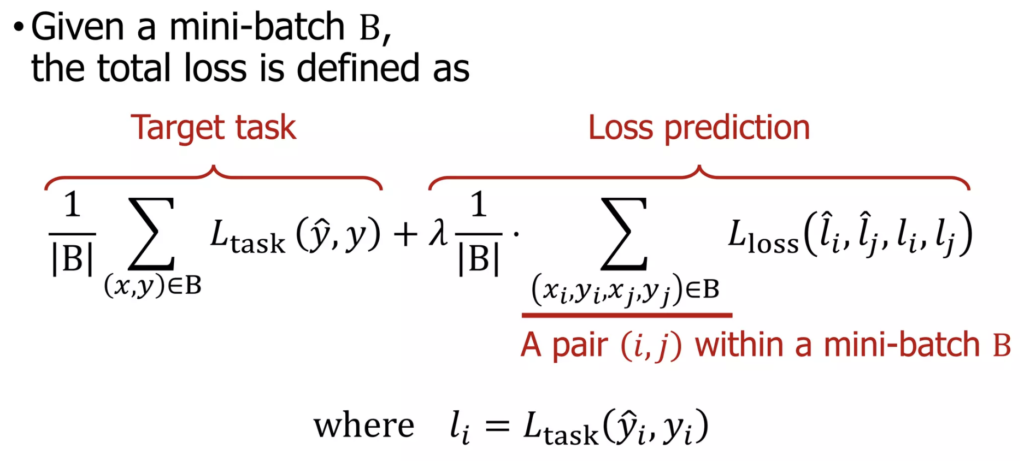
따라서 Loss-prediction loss가 적절히 동작하기 위해선 l값(Target loss)의 scale변화를 무시할 필요가 있다고 합니다. 저자는 sample pair를 비교하는 것으로 이 문제를 해결했습니다. 미니 배치 B개의 샘플을 뽑으면, 2개씩 sample을 짝을 지어서 B/2개의 data pair를 만듭니다. (미니배치 B는 짝수여야 하겠죠?)이제 이 loss prediction의 pair간 차이를 이용해 loss prediction moule을 학습할 수 있습니다. 이 방식을 이용해 loss prediction module이 전반적인 scale 변화에 영향을 받지 않을 수 있었다고 합니다. 최종적으로 loss prediction module의 loss 함수는 다음과 같이 정의됩니다 :
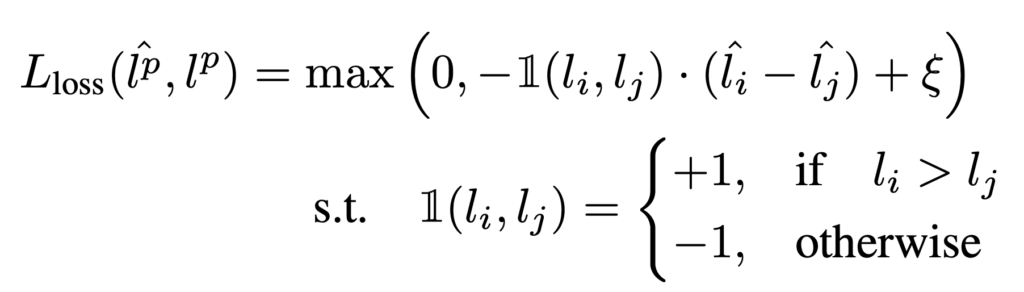
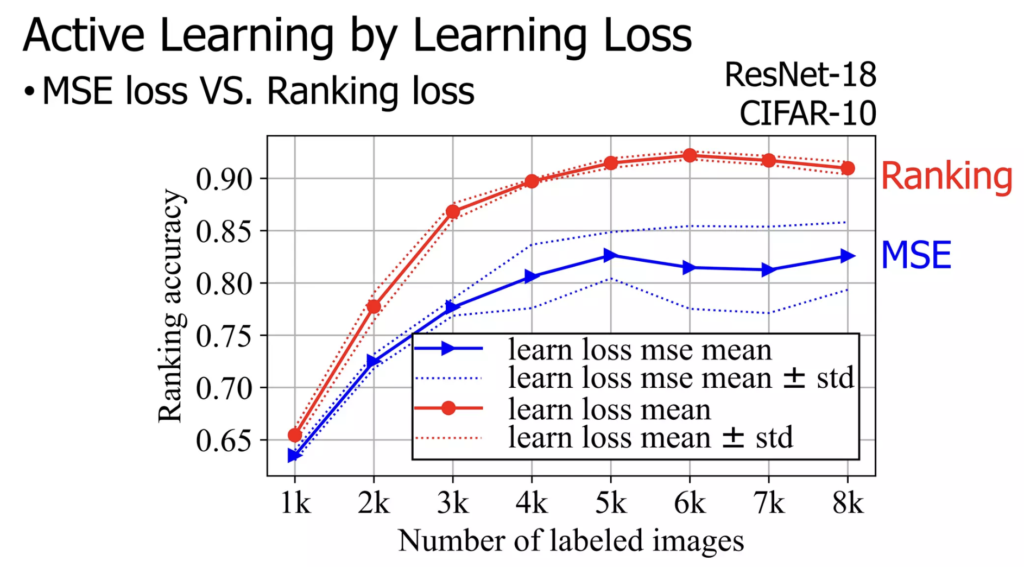
ξ값은 사전에 정의된 positive margin인데, 두 loss의 차이가 ξ만큼 차이가 날 때 고려하기 위해 도입했다고 생각하시면 됩니다(논문에서는 1로 설정했다고 합니다). 코드 구현상으로는 단순히 PyTorch의 nn.MarginRankingLoss를 이용했다고 합니다. 해당 loss에 관심 있으신 문은 documentation을 직접 참고해도 좋을 것 같습니다. 이제 이 L_loss가 잘 학습이 진행된다면, loss prediction module은 sample간 loss 크기를 잘 비교해 ranking을 잘 매길 수 있게 될 것입니다. 이는 다음 실험에서 확인할 수 있었습니다.
앞서 LL4AL의 최종 학습 Loss는 target loss와 loss prediction loss의 합으로 구성된다고 했습니다. 이를 약간 더 자세히 풀어 작성하면 다음과 같이 표현할 수 있습니다(λ값은 1로 설정했다고 합니다). 다음의 loss를 이용해 multi-task learning을 수행 할 수 있습니다.
Experiment
저자는 본인이 제안하는 방법론이 task-agnostic하고 기존 SOTA 성능을 뛰어넘는것을 보이기 위해 classifcation, human pose estimation, object detection 3가지 task에 대해 실험을 수행했습니다. 다음과 같이 간략하게 요약할 수 있습니다. 이미지 분류에는 ResNet18을 사용하여 CIFAR-10데이터셋에 대해 실험을 수행했고, Object detection task에서는 우리에게 익숙한 SSD를 사용하여 PASCAL 데이터셋에 대해 실험을 수행했습니다. 마지막으로 regression task에도 적용해보기 위해 Computer Vision의 대표적인 회귀 문제인 Human pose estimation에 대해서도 적용해보았다고 합니다. 모델은 Stacked Hourglass Networks를 사용하고 데이터셋으로는 MPII를 사용했다고 하는데, 해당 task에 대해서는 제가 잘 몰라서 그냥 당시 주로 사용되는 것을 사용했구나.. 하고 넘어갔습니다.
각 실험에 대한 learning loss 하이퍼파라미터는 최대한 동일하게 설정했다고 합니다(따라서 세부적인 engineering을 통해 더욱 성능을 개선할 수 있습니다)
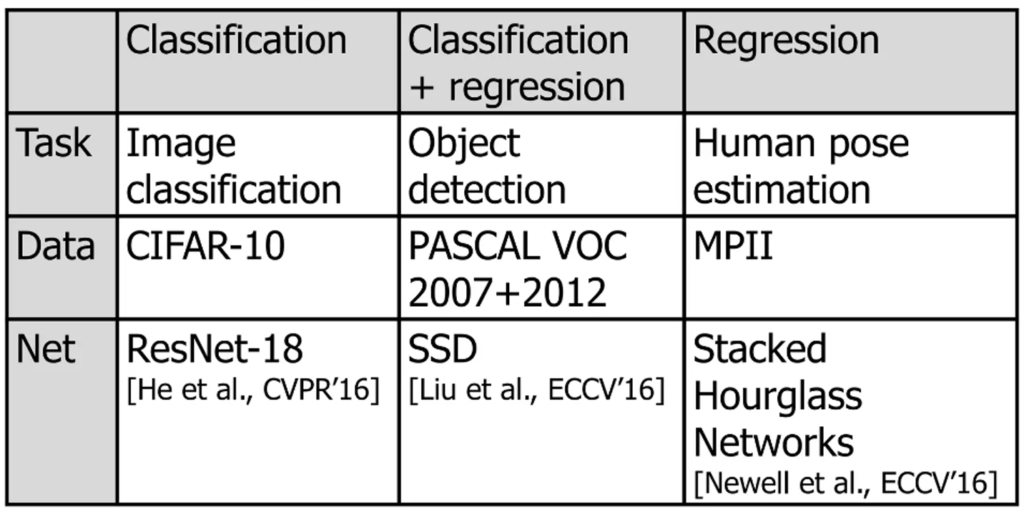
Image classification
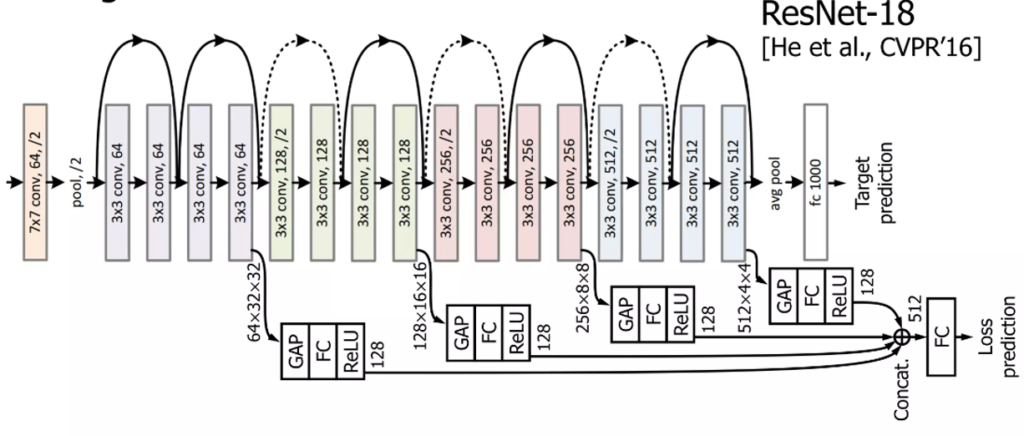
image classification에서는 ResNet18에 loss prediction module을 부착했습니다. ResNet18은 첫번째 convolution 이후 4개의 basic block으로 구성되는데, 각각 모듈에서 feature map을 추출해서 loss prediction module에 사용하였습니다. 첫 번째 convolution은 이미지 사이즈를 맞추기 위해 stride 1의 3×3 convolution으로 대체하였고, maxpooling layer는 제거되었습니다.
실험은 random에 대한 고려를 위해 5번 수행되었으며 그 평균을 reporting하였다고 합니다.
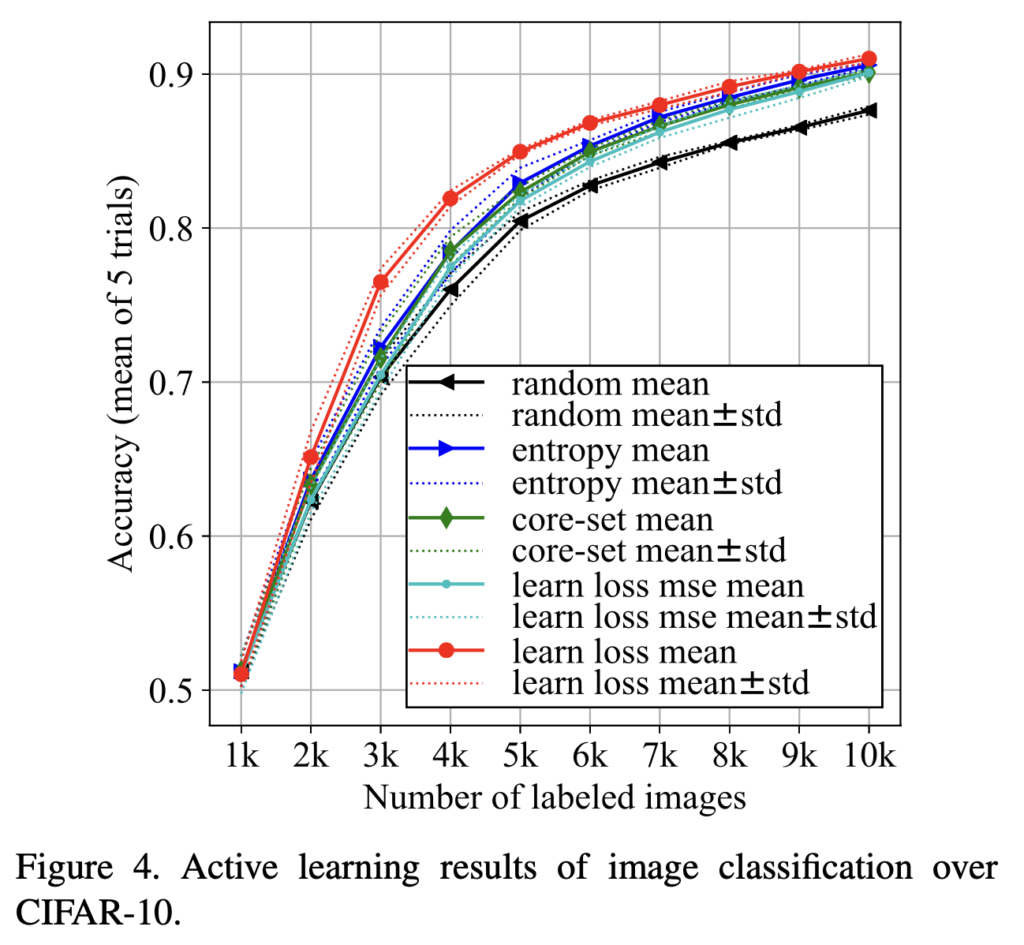
빨간색 선이 저자가 제안하는 learning loss의 성능이고, 검은색 선은 random sampling했을 때입니다. 기존 방법론들보다 성능이 상당히 높은 것을 확인할 수 있습니다(random sampling과 비교하면 최종 성능에서 3.37%의 개선이 이루어졌는데, backbone을 ResNet18에서 ResNet121로 바꿔서 빡세게 튜닝해도 2.02%의 성능 개선을 이루는것과 비교해보면 데이터 선택만 잘해도 모델을 뜯어고치는것보다 좋은 성능 개선을 달성할 수 있다고 합니다). 눈에 띄는 것은 diversity 기반 방법론인 core-set이 entropy를 이용한 Uncertainty 방법보다 성능이 좋지 않다는 것인데, 이는 core-set 논문에 reporting되어있는 성능과 상당히 다릅니다(core-set 원문이 성능 뻥튀기를 위해 체리픽을 한 것이 아닌가 하는 생각이 드네요)
Object Detection
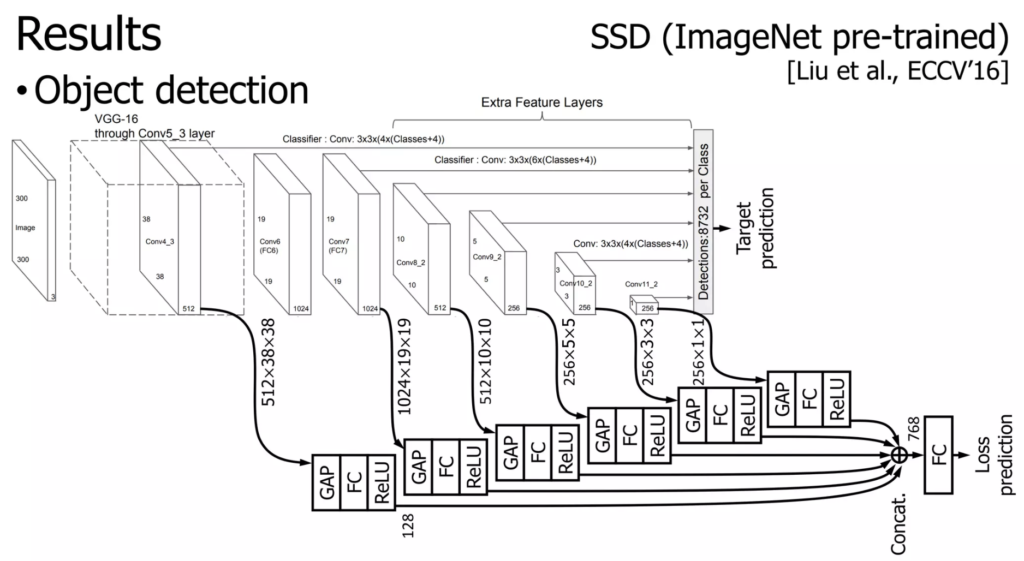
object detection 실험은 SSD에 loss prediction module을 붙여 PASCAL VOC 데이터에 대해 수행되었습니다. 실험은 3번 반복 수행했고 3번에 대한 평균을 내었다고 합니다.
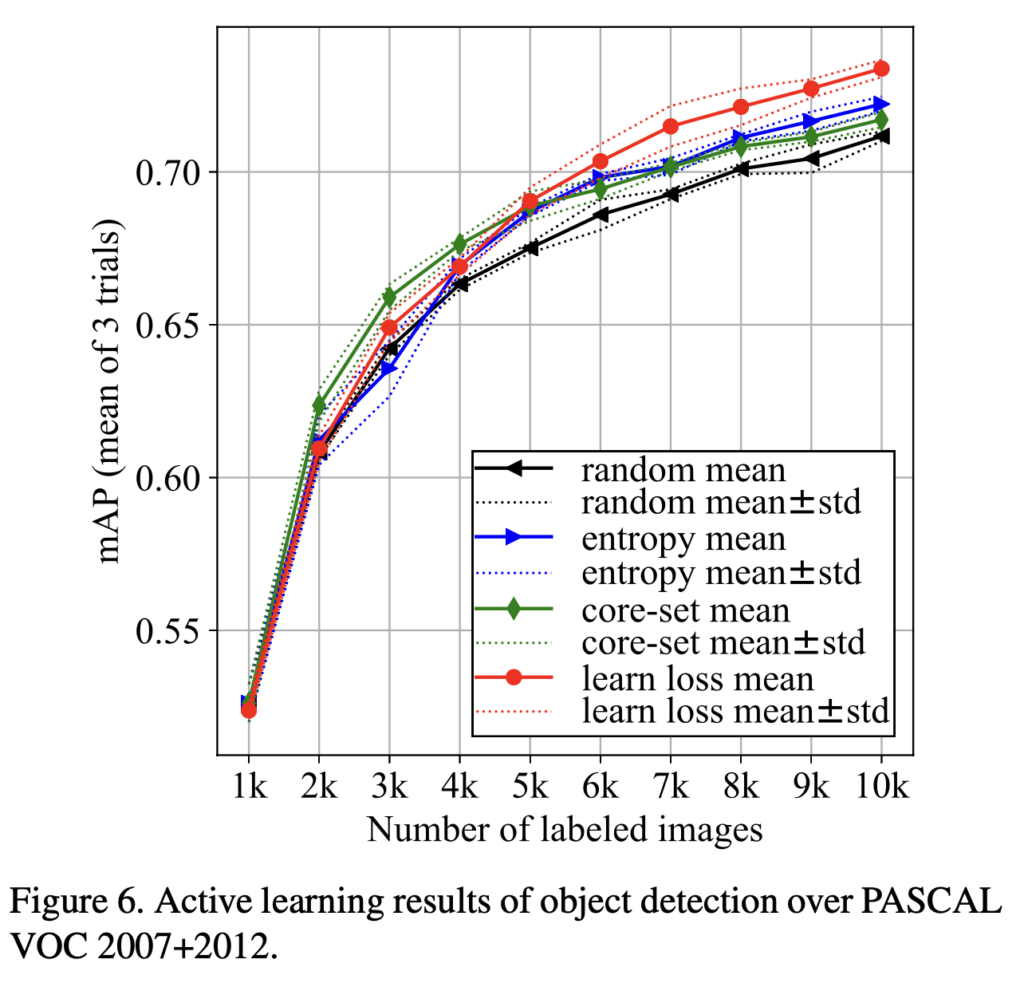
초기 성능이 타 방법론을 압도하진 않지만 10k개의 라벨링된 이미지에 대해선 다른 방법보다 높은 mAP를 달성하는데 성공했습니다.
Human pose estimation
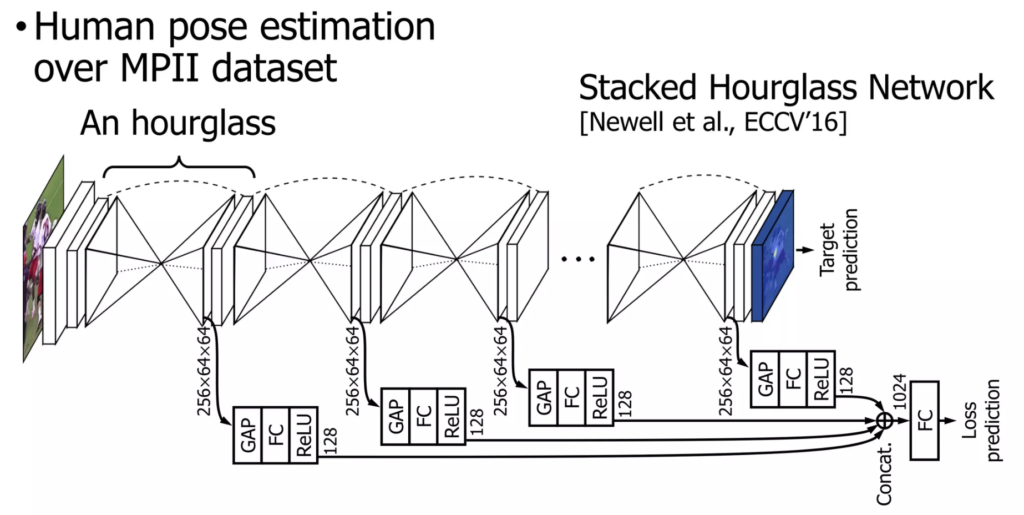
human pose estimation은 관절을 기준으로 사람의 자세를 추정하는 task로, 대표적인 컴퓨터비전의 regression task라고 합니다. Hourglass module을 쌓은, stacked hourglass network를 사용해서 MPII 데이터셋을 사용했다고 합니다.
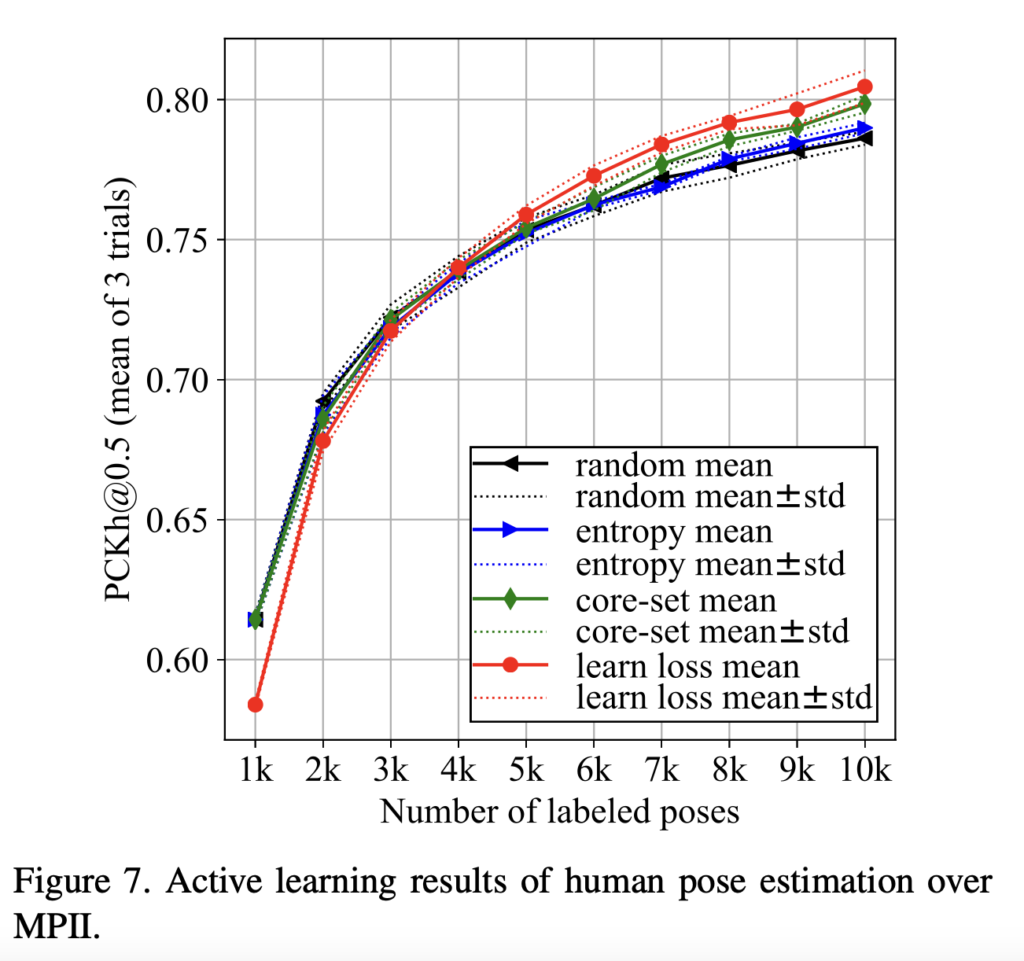
해당 task에서도 learning loss가 가장 높은 성능을 보여주었습니다.
Conclusion
Learning loss는 기존 active learning은 한계를 체계적으로 분석해 기존와 다른, 새로운 방법으로 이를 극복했습니다. 프레임워크가 간단하고 computational cost도 낮으며, 다양한 task에 폭넓게 적용 가능합니다. 저자는 논문 끝에서 데이터의 분포를 제대로 반영하지 못했다는 한계가 있다고 지적했으며, 이후에 이 문제가 해결되길 바란다고 했습니다. 논문의 접근법에서 배워갈 점이 많습니다. 이후 AL 논문을 읽을 때 저자의 관점을 참고할 수 있을 것 같습니다.
감사합니다.
안녕하세요 허재연 연구원님 좋은 리뷰 감사합니다.
결국 Learning Loss라는 것은 uncertainty기반 AL framework로, task-specific한 기존 uncertainty based AL을 범용적으로 사용 가능하도록 하기 위해 loss 자체를 예측하도록 하였다고 이해하였습니다.
Loss prediction loss부분에서 질문이 있는데요, 한 batch 내에 B개의 sample을 뽑아 pair를 구성한다고 설명해 주셨는데, 그렇다면 batch 내의 모든 데이터에 대해 loss를 계산하지 않고 b개를 선정하여 loss를 계산하게 되는 것인지, 만약 그렇다면 pairing은 어떤 기준으로 진행되는 지도 궁금합니다. 아니면 batch 내의 모든 경우의 pair를 고려하여 loss를 계산하는 것인가요?
안녕하세요, 천혜원 연구원님. 질문주신 부분에 대한 답변 드리겠습니다.
해당 질문은 Loss 설계 부분을 보시고 질문을 주신 것 같은데, 해당 부분에서 B는 미니배치 사이즈를 의미합니다. 즉 mini-batch size를 B=512라고 하면 데이터를 랜덤하게 2개씩 짝지어서 B/2=256개의 pair를 만든다고 생각하시면 될 것 같습니다.
pair를 만든 후, 이 pair간의 loss ranking 비교를 하는 학습을 진행한다고 이해하시면 될 것 같습니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
굉장히 심플하면서도 강력한 방법론이 아닌가 리뷰를 읽으며 생각하였습니다. 재밌네요. loss 설계 부분에서 질문이 있는데, 미니 배치 B개의 샘플을 뽑아 2개씩 짝을 지어서 pair간 차이를 이용하여 loss를 측정하는 방법이 너무 나이브하지 않나? 라는 생각을 하게되는데요. 왜나면 우연히 큰 값이랑 작은 값이랑 pair가 되어서 크게 나올 수도 있고 작게 나올 수도 있는건데 즉, pair를 어떻게 하느냐에 따라서 Loss 값이 매우 다르게 나올거 같은데 이 pair는 고정되는 건가요? 어떻게 pair를 형성하는 건가요? (랜덤인지, 따로 규칙이 있는지 궁금합니다)
감사합니다
안녕하세요, 김주연 연구원님, 아무래도 loss 설계 부분이 기존에 자주 사용되는 것이 아니라 이해가 쉽지 않을 수 있다는 생각이 듭니다. 질문 주신 부분에 대해 추가적인 설명 드리겠습니다.
일단 결론부터 말씀드리면, pair (i,j) 는 랜덤하게 짝지어집니다. 그리고 i에 대한 예측 loss l_i와 j에 대한 예측 loss l_j의 ranking 비교를 하게 됩니다. 김주연 연구원님이 댓글로 ‘너무 나이브한 비교’라고 표현하셨는데, 바로 그 점이 저자가 원했던 것입니다. loss값 자체를 정확하게 맞추려고 하면 안 됩니다. 그렇게 loss를 설계하면 예측 loss는 target loss값을 학습하는게 아니라, 점점 target loss값이 감소하는 경향 자체를 학습하게 됩니다. 이를 피하기 해서는 scale변화를 완전히 무시할 수 있는 loss가 필요합니다.
정확한 이해를 위해 본래 목적으로 돌아와 봅시다. 저희가 궁극적으로 하고자 하는 것은 ‘전체 sample 중 loss가 높을 것으로 예상되는 샘플을 선별하고 싶다’ 입니다. loss값 자체를 맞출 필요가 없습니다. k개의 샘플을 선별하고 싶다면 샘플들을 sorting해서 top-K개만 선택할 수 있으면 됩니다. 즉, 대소 비교 능력만 충분히 갖추면 됩니다. 저자는 값을 정확하게 맞추려는 regression 계열 loss 대신 MarginRankingLoss를 적용함으로써 해당 목적을 달성할 수 있었다고 합니다. (학습을 통해 ranking을 잘 매기는 능력은 본문 Loss 설계 부분에서 Ranking accuracy 부분을 참고해주시기 바랍니다. 학습을 통해 ranking을 상당히 잘 맞출 수 있음을 알 수 있습니다)
추가적으로, mini-batch size B=128라고 가정하면, 64개의 pair가 만들어지게 됩니다. ranking accuracy가 90%만 되어도 60개 정도의 sample들을 잘 비교할 수 있습니다. 이 정도 수의 pair를 정확히 예측할 수 있다면 통계적으로 의미 있는 숫자라는 생각이 듭니다.
충분한 답변이 되었으면 좋겠습니다. 추가적인 궁금증 있으시다면 다시 질문 주시기 바랍니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
loss prediction loss를 설계하는 과정에서 MSE를 사용했을 때 발생하는 문제를 해결하기 위해서는 Target loss의 scale 변화를 무시할 필요가 있다고 했는데, 잘 와닿지 않다 좀 더 구체적으로 설명해주실 수 있나요 ? sample pair를 비교하는 것은 어떻게 이 scale 변화를 무시하게 되는 것인가요 ?
감사합니다.
안녕하세요, 정윤서 연구원님, 좋은 질문 주셔서 감사합니다. 아무래도 일반적으로 사용되는 방식이 아니기 때문에 저도 해당 부분을 처음 읽고 이해하는게 쉽지 않았었습니다. 추가적인 설명 드리겠습니다.
target loss값을 GT로 사용해서 loss를 예측하는 모듈을 설계하고자 할 때, 가장 간단하고 직관적인 방법은 MSE 등의 방법을 이용해 ‘loss값 자체를 예측’하는 것일겁니다. 하지만 저자는 해당 방법으로 좋은 결과를 얻을 수 없었다고 합니다(기존 SOTA 방법론들보다는 낮은 성능을 얻었습니다). 저자는 그 이유를 MSE를 사용하게 되면 target task loss l이 학습될수록 작아져서 loss 예측값이 l의 scale만 따라가는 경향을 보이기 때문이라고 분석합니다. target task loss의 값을 정확히 예측하는것이 아니라 해당 값이 점점 작아지는 scale 변화만 따라가게 되는 것입니다. 결국 저자는 scale 변화를 무시할 수 있는 방법을 찾아보았고, MarginRankingLoss를 도입하게 되었습니다.
해당 방법은 ‘loss 값 자체를 예측하는 것이 아닌, 예측 loss의 대소 비교 능력만 갖추는 것’ 입니다. minibatch size B의 sample을 이용하고자 할 때, B/2개의 pair를 구성해서 B/2번의 비교를 하게 되는 것입니다. 대소 비교를 할 줄 알면 scale 변화를 알고 있다는 뜻 아니야? 라고 생각하실 수도 있지만, loss의 ‘값’ 자체에 집중하는 것이 아니라 ranking하는 것이 집중하게 되어서 scale 변화를 무시할 수 있게 된다고 이해하면 될 것 같습니다.
정확한 이해를 위해 원래 목적으로 돌아와 볼게요. 저자가 궁극적으로 loss prediction으로 하고 싶은 것은 ‘전체 sample 중 loss값이 높을 것으로 예상되는 샘플들을 선별’하는 것입니다. loss값 자체를 맞출 필요는 없지요. k개의 샘플을 선별하고 싶다면 전체 sampling을 prediction loss 순서대로 sorting한 다음 top-K개를 선택할 수 있으면 됩니다. 바꿔 말하면 대소 비교 능력만 갖추면 충분합니다. target loss값의 scale 변화를 무시할 수 있으면서, 동시에 충분한 ranking 능력을 갖출 수 있게 하는 loss로 MarginRankingLoss를 선택했다고 이해하시면 좋을 것 같습니다. 결국 128개의 샘플이 들어오면 128개의 loss를 예측해서 sorting 한 다음 top-K개를 선택해서 라벨링하고 labeled training set에 추가하게 됩니다.
추가적인 설명을 더 드리자면, 백만개의 전체 데이터 중 1000개의 sample을 쿼리하고자 할 때, 가장 높은 loss의 1000개를 바로 선별하지는 않습니다. 전체 데이터에서 uncertainty가 가장 높은 데이터를 뽑아보면, 막상 해당 데이터들은 매우 noisy해서 애초에 분류가 불가능하거나 서로 매우 비슷한 데이터가 뽑히게 된다고 합니다. 데이터 분포를 완전 무시하게 되죠. 실제로는 random하게 샘플링한 subset에서 uncertainty를 정렬한 다음 top-K개를 선별하는 것을 반복한다고 생각하시면 될 것 같습니다.
좋은 질문 주셔서 감사합니다.