안녕하세요, 열일곱번째 x-review 입니다. 이번 논문은 2018년도 CVPR에 게재된 Deep Depth Completion of a Single RGB-D Image이라는 Depth Completion 논문 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
Kinect와 realsense와 같은 상용 depth 센서들은 디바이스가 설정해놓은 최대, 최소 거리 내에 포함되지 않거나 scene의 표면이 너무 밝거나 투명한 경우에 대한 depth 값을 제공하지 못하게 됩니다. 이러한 depth값을 채워넣는 것이 depth completion의 목적이지만 당시까지만해도 depth inpainting이라고 해서 boundary 표면의 depth 값을 extrapolation하여 홀을 채우는 식의 hand crafted 방식이 일반적이었고 딥러닝 네트워크로는 컬러 정보에서 depth를 추정하는 방식이 새롭게 등장하고 있었다고 합니다. 이러한 당시의 연구들의 한계점들을 여러 관점에서 확인할 수 있는데요 먼저 데이터셋에 대해 생각해보면 촬영한 RGB-D 이미지 이외에 completion된 depth 이미지, 즉 GT depth map이 함께 제공되는 large scale의 데이터셋을 사용하기가 쉽지 않다는 것 입니다. 대부분의 depth completion 방법론에서는 RGB-D 센서로 촬영한 컬러 영상과 raw depth 이미지에 대해서 픽셀 레벨로 학습되고 있어서 누락된 영역에 대한 깊이 정보를 학습하는데에는 한계가 있었고 이러한 점을 해결하기 위해 본 논문에서는 RGB-D 이미지 real scene에서 large scale의 reconstruction을 통해 만든 누락된 값이 없는 depth map이 포함된 새로운 데이터셋을 제작하였습니다.

다음으로 depth representation 관점으로 보았을 때 위의 문제를 해결하기 위한 가장 나이브한 방식은 제작한 데이터셋을 supervision으로 RGB-D 영상에서 직접 regression하는 FC 네트워크를 형성하는 것 입니다. 그러나 이런 구조로는 Figure1의 첫번째보다 두번째 예시를 보았을 때 두번째 영상처럼 raw depth에 홀이 많을 경우에 비교적 제대로 completion하지 못하게 됩니다. 사실 컬러 영상만으로 정확한 depth 정보를 예측하는 것은 사람에게도 어려운 일이겠죠 .. 그래서 컬러 영상으로부터 더 쉽게 추정할 수 있는 로컬한 특성인 surface normal과 occlusion boundary를 뽑아내서 depth를 예측할 수 있도록 depth representation 네트워크를 설계하였습니다. 마지막으로 completion 할 딥러닝 네트워크 설계 관점으로 보았을 때 RGB-D 영상을 입력으로 depth를 완성하기 위해서 end-to-end로 네트워크를 제대로 설계한 이전 연구는 당시에 아직 없었다고 합니다. 왜냐하면 일반적으로 네트워크들이 모두 depth 정보를 추정할 때 주변 depth 값을 그대로 이용하거나 단순 보간하는 방법으로만 학습하기 때문에 역시나 큰 영역의 홀을 채워나가는 것이 어렵기 때문 입니다. 이에 대한 해결책으로 저자는 네트워크에 컬러 이미지만 입력으로 제공하는 방식을 선택하였는데, 이러한 방식으로 앞서 이야기하였듯 컬러 영상에서 로컬한 특징을 예측하고 global optimization으로 절대적인 depth 값을 예측할 수 있도록 설계하였습니다.
2. Method
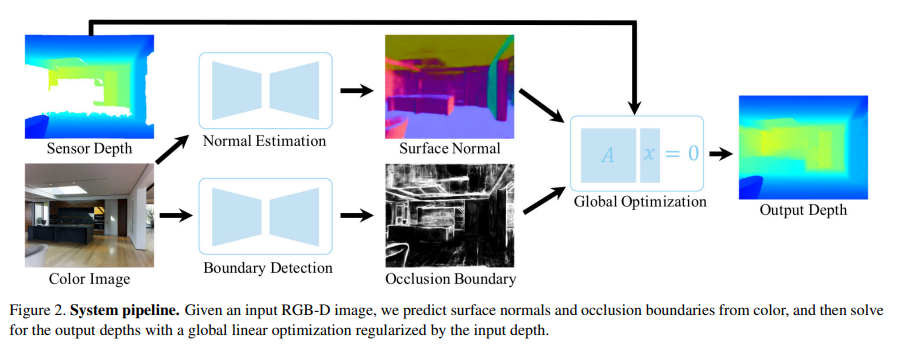
본 논문에서는 method를 설계할 때 1. 어떻게 depth completion을 위한 학습 데이터를 얻을 것인가? 2. depth representation을 어떻게 구성해야하나? 3. 컬러 영상과 depth 영상을 통해 completion할 정보를 어떻게 얻어야할 것인가? 총 3가지에 집중하였다고 합니다.
3.1. Dataset
먼저 GT depth map이 포함된 RGB-D 데이터셋을 얻는 과정 입니다. 가장 간단한 방식은 RGB-D 카메라로 영상을 취득한 후에 또 다른 depth 센서로 (논문에서는 고가의 depth sensor라고 표현하네요) 동일한 조건으로 촬영을 해서 RGB-D 이미지와 align을 맞추는 방식 입니다. 그러나 이러한 방식은 cost가 많이 들기에 가장 large scale로 공개된 데이터셋에서 조차 indoor scene이 매우 소수의 비율로 포함되어 있다고 합니다. 그래서 대신에 멀티뷰 RGB-D로 촬영한 기존에 존재하는 메쉬 형태의 reconstruction 구조를 활용하여 데이터셋을 생성하였습니다. 이런 형태로 구성되어 있는 대표적인 데이터셋이 Matterport3D와 ScanNet 등이 있고 그 중에 Matterport3D를 사용하였다고 합니다. 각 scene에 대한 global한 reconstruction에서 indoor이다 보니 room 단위로 공간이 존재하는데 room당 약 100만개에서 600만 개의 triangle mesh M을 추출합니다. 그리고 각 카메라 포즈에서 mesh M을 렌더링하여 완전한 depth map, 즉 GT depth map D*를 얻습니다. 이러한 과정을 통해 새로운 이미지를 촬영하지 않고 RGB-D → D* 를 모두 가진 set을 얻을 수 있게 됩니다.

추가적인 설명으로 Figure3을 보면서 얘기를 해보면 rendering depth 이미지가 항상 모든 영역이 채워져 있다고 보장할 순 없지만 비교적 비어있는 홀이 매우 적은데 이는 빨간색 점이 의미하는 포즈 정보, 다만 하나의 포즈 정보로만 이루어진게 아니라 모든 카메라 시점이 합쳐진 것이기 때문 입니다(노란색 점). 즉 한 뷰에서는 멀리 떨어져 있지만 다른 뷰에서 적정 범위 내에 있기에 완성될 수 있는 depth map을 얻을 수 있습니다. 특히 한 각도에서는 빛에 반사되어 보이지 않는 표면이 다른 각도에서는 반사되지 않고 촬영되어 렌더링한 depth를 보았을 때 depth 값이 채워져 있는 것을 확인할 수 있습니다. 이처럼 센서로 촬영했을 때 누락된 픽셀의 약 64.6%를 reconstruction을 통해 복원할 수 있다고 합니다. 또한 카메라에서 비교적 멀리 떨어져 있는 표면이 포함되어 있을 때 해당 뷰를 2D 평면으로 투영하게 되면 원본보다 더 높은 해상도의 픽셀을 제공할 수 있습니다. 마지막으로 렌더링한 depth 이미지는 일반적으로 raw depth 이미지보다 노이즈가 훨씬 적게 표현이 되는데, reconstruction 과정에서 여러 카메라 뷰에서의 노이즈가 존재하는 샘플 이미지들을 필터링과 평균값을 내어 합치기 때문에 기본적으로 reconsturciton된 결과는 노이즈가 많이 제거된 상태로 표현됩니다. 이는 노이즈가 많이 발생하는 4m 이상의 원거리 영역에 대해서 노이즈가 제거된 형태를 얻을 수 있기 때문에 큰 장점이라고 이야기할 수 있습니다.
이렇듯 취득한 데이터셋은 117,516개의 RGB-D 이미지와 각 이미지가 촬영된 카메라 view에 대한 렌더링한 GT depth를 포함하고 있습니다.
3.2. Depth Representation
어떻게 depth completion을 위한 학습 데이터를 얻을 것인지에 대한 해답을 얻었으니 이제는 depth completion을 더 잘 해내기에 가장 적합한 기하학적인 representation이 무엇인지 고민해야 합니다. 가장 간단한 방식은 raw depth와 컬러 영상에서 completion된 depth를 regression하는 네트워크를 설계하는 것이지만 scene 내에서의 절대적인 depth 값을 알기 위해서는 포함되어 있는 물체들의 크기나 scene category 와 같은 부가적인 정보들이 필요할 수 있기 때문에 monocular 이미지에서 예측하기에는 어려움이 존재하였습니다. 그래서 각 픽셀에서의 표면에 대한 로컬한 특성을 예측하도록 training 한 다음에 예측 결과를 바탕으로 다시 글로벌한, 전체 영역 내에서의 depth를 다시 구하도록 하였습니다. 이전 연구들에서는 간접적으로 depth에 대한 representation을 제공해 주기 위해 여러 방법들을 제안했었는데, 본 논문에서는 이러한 representation으로 surface normal와 occlusion boundary를 예측하여 제공하는데에 초점을 맞추었습니다. normal은 미분한 표면의 속성으로 로컬한 이웃 픽셀들에 의존하여 생성되는데, 이는 컬러 영상에서 직접적으로 확인할 수 있는 조도 변화와 관련되어 있어 이전 연구들에서도 컬러 영상에서 surface normal을 예측하였을 때 좋은 결과를 얻어왔다고 합니다. 또한 occlusion boundary는 엣지와 같은 영역에 해당한 픽셀 로컬한 패턴을 생성할 수 있습니다.

여기서 sruface normal과 occlustion boundary를 어떻게 잘 예측해서 representation으로 제공할 것인지도 중요하지만 결국에는 예측한 representation들을 depth를 completion하기 위해 어떻게 사용할 것이냐가 포인트 입니다. 이전까지는 surface normal을 사용해서 reconstruction된 테이블 위의 물체가 놓여있을 때와 같은 수준에서 누락된 기하학적인 정보를 복구하는데 사용하였다고 합니다. 그러나 복잡한 scene의 monocular RGB-D 이미지에서 depth estimation이나 completion을 위해 surface normal을 사용한 전례는 없었다고 합니다. 어쩌면 당연하게도 surface normal와 occlustion boundary만으로 누락된 depth 값을 구하겠다는 것은 이론상으로도 불가능하며 특히 이미지에서 따로 떨어져 있는 여러 영역 사이의 depth 관계를 로컬한 특성만을 뽑아낸 두 가지의 representation만으로는 유추할 수 없는 상황 입니다. 예를 들면 Figure4의 (a)에서 초록색 점이 카메라이고, 카메라에서 가까운 표면이 창문이고, 뒤의 표면이 벽이라고 가정하면 surface normal만으로는 창문을 통해 보이는 창문 너머의 벽의 깊이를 유추하는 것이 불가능하다는 것 입니다. 왜냐하면 카메라 관점에서 보았을 때 전체 벽 중에서 카메라에 보이는 영역은 occlusiotn boundary(경계면)에 완전히 둘러싸여서 나머지 영역에 대한 깊이가 모호해지지만, 실제로는 Figure4(b)처럼 real scene에서 이미지의 한 부분이 occlusion boundary로 둘러싸여 있으면서 raw depth 값을 전혀 알 수 없는 경우는 또 드물다고 합니다. 결국에 저자는 예측한 occlusion boundary의 결과로 가중치가 부여된 surface normal과 raw depth에서의 regularization을 함께 이용하여 depth 영상의 누락된 큰 구멍을 완성하는 것이 최선일 것이라는 결론에 도달하게 되었고 실험을 통해서 이를 입증하였다고 합니다.
3.3. Network Architecture and Training
그러면 surface normal과 occlusion boundary를 사용해야한다는 것은 알겠으나 제대로 예측하기 위한 네트워크를 어떻게 설계해야 할까요? 본 논문에서는 normal 추정과 boundary 검출에서 모두 우수한 성능을 보였던 구조를 사용하였는데, 이는 VGG16을 백본으로 하는 FC 네트워크로 이루어져 있고 reconstruction한 mesh에서 계산된 GT surface normal과 silhouette 경계를 가지고 네트워크를 train하게 됩니다.
What loss should be used to train the network?
네트워크의 주된 목표는 취득한 raw depth에서는 누락된 영역을 컬러 영상에서의 normal을 예측하도록 하는 것 입니다. 그러한 범위의 픽셀은 대부분 카메라와 멀리 떨어져 있거나 투명하거나 혹은 빛나는 영역이기에 픽셀의 특성이 다른 영역과 차이가 있을 가능성이 높기 때문에 네트워크가 이러한 픽셀에 대해서 normal을 regression 할 수 있어야 한다고 생각할 수 있지만, 픽셀이 hole일 경우보다 아닌 경우가 훨씬 많기 때문에 데이터가 매우 제한적이고 hole에 대해서만 train하는 것과 모든 픽셀에 대해서 train하는 것 중 무엇이 더 효과적인지 명확하지 않았기에 두 케이스에 대해 모두 테스트해보았다고 합니다.
테스트하기에 앞서 누락되지 않은 영역(observed)을 raw depth map과 렌더링한 mesh에서 모두 depth 정보가 있는 픽셀로 정의하였고 누락된 영역(unobserved)을 렌더링한 mesh에는 depth 정보가 존재하는데 raw depth에는 depth 값이 없는 픽셀로 정의하였습니다. observed, unobserved, both 이렇게 세 경우로 나누어서 실험해본 결과 누락 여부와 관계없이 모든 픽셀을 사용했을 때가 따로따로 나누어서 사용한 것보다 높은 성능을 보였다고 합니다.

What image channels should be input to the network?
그럼 네트워크의 입력으로는 어떤 데이터가 적합할까요? RGB-D 이미지에서 surface normal을 예측하기에 가장 좋은 방법은 RGB-D 채널을 모두 제공하고 3차원의 normal 벡터를 regression하도록 설계하는 것이라고 생각할 수도 있지만 실제로는 이러한 방식은 unobserved 픽셀에 대한 normal을 예측하는 성능이 loss에 어떤 픽셀이 포함되었는지에 관계없이 매우 좋지 않은 것을 확인하였다고 합니다. raw depth로 train한 네트워크는 주로 depth로부터 normal을 직접 계산하도록 학습되는데 이는 정작 depth 값이 누락된 경우에 컬러 영상으로부터 normal을 예측하는 방법을 제대로 학습하지 못하다고 저자는 추측하고 있습니다. 오히려 단순 컬러 영상만을 사용하였을 때 normal을 더 잘 예측하도록 학습이 되는데 예를 들면 Figure5에서 raw depth의 unobserved 영역에 대해서 컬러 영상만으로 예측한 normal이 depth를 사용했을 때보다 정확하며 더불어 컬러와 depth를 모두 사용했을 때 보다도 나은 모습을 확인할 수 있습니다. representation 네트워크에서는 컬러 영상만 사용하고 다음 파트에서 다룰 optimization에서 raw depth의 observed depth만 정규화로 사용하였는데 저자는 depth가 없는 예측과 depth가 있는 optimization으로 분리할 수 있기에 매우 참신한 구조라고 주장하고 있습니다. 이러한 주장에 대해서 컬러 영상만 사용하기 때문에 다른 depth sensor에 맞게 재학습할 필요가 없고 sparse한 depth 샘플을 포함하여 다양한 depth 샘플을 정규화할 수 있도록 optimization을 일반화할 수 있다는 점을 근거로 삼고 있습니다.
3.4. Optimization
해당 파트는 surface normal 이미지 N과 occlusion boundary B를 예측한 후의 과정을 살펴보고 있습니다.
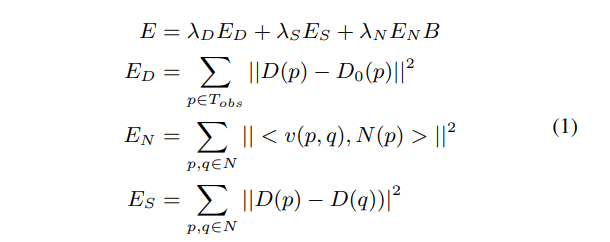
surface normal 이미지 N과 occlusion boundary 이미지 B를 예측한 후에 깊이 이미지 D를 완성하게 되는데 여기서 E_D는 픽셀 p에서 예측한 depth D_{(p)}와 raw detph D_{0(p)} 사이의 거리를 측정한 것이고 E_N은 예측한 depth와 surface normal N_{(p)} 사이의 consistency를 측정하며 E_S는 인접한 픽셀 간에 동일한 깊이를 갖도록 계산됩니다. B는 0에서 1 사이의 값을 가지며 픽셀이 occlusion boundary에 있을 것으로 예측되는 확률 B_{(p)}에 따라서 normal 항의 가중치를 낮추는 역할을 합니다. 해당 function의 최종 해는 근사화된 objective function에 대한 global한 최소값으로 원래는 E_N에서 surface normal과의 내적에 필요한 접선 벡터 v(p, q)의 정규화 때문에 비선형 함수이지만 벡터 정규화를 생략하면 해당 항을 선형식으로 근사화할 수 있게 됩니다. 이런 선형적인 접근은 optimization에 매우 중요한데 surface normal과 occlustion boudnary는 표면의 기하학적 저어보 대한 로컬한 특성만 가지고 있기 때문에 상대적으로 추정하기가 쉽지만 global한 optimization을 거쳐야만 이런 로컬한 예측 결과를 결합하여 모든 픽셀의 절대적인 depth를 완성할 수 있게 됩니다.
4. Experimental Results
4.1. Ablation Studies
What data should be input to the network?

Table1은 설계한 네트워크에서 가장 적합하게 작동할 수 있는 입력 데이터의 경우를 보기 위한 실험 결과 입니다. 직관적으로 생각했을 때 컬러 영상와 depth 영상을 모두 사용하는게 좋을 것이라고 생각할 수 있지만 method에서도 정성적으로 보았듯이 컬러 영상만 주어졌을 때가 surface normal을 더 잘 예측할 수 있으며 depth 추정 결과도 두 영상을 모두 사용하였을 때보다 나은 결과를 보이는 것을 확인할 수 있습니다.
4.2. Comparison to Baseline Methods
Comparison to Depth Estimation Methods
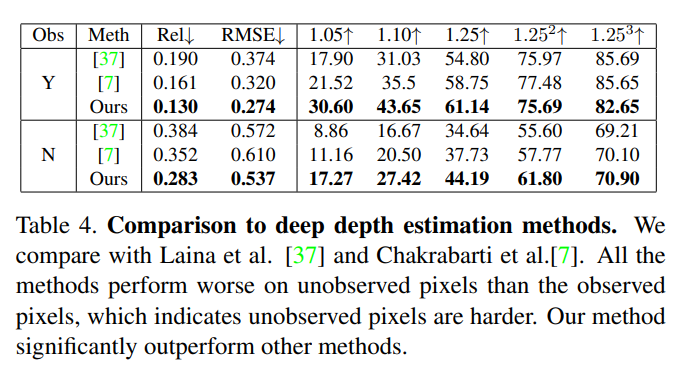
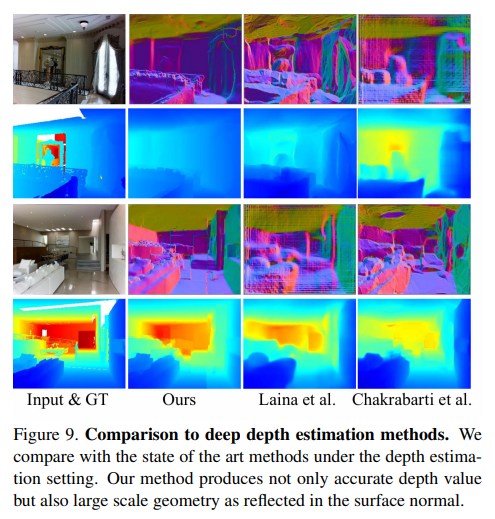
본 논문의 방법론을 depth estimation 방법론들과 비교한 실험 결과로 depth estimation에서 본 논문과 가장 유사한 방식을 제안하는 [7] method와 NYUv2 데이터셋에서 당시 SOTA였던 [37] method을 비교 모델로 삼았다고 합니다. depth estimation task는 입력 데이터로 depth가 들어가지 않는다는 차이점이 존재하기 때문에 최대한 동일한 설정을 갖추기 위해 컬러 영상만 입력으로 사용한 다음에 랜덤하게 하나의 픽셀을 임의로 선택해서 실제 depth와 일치하도록 output depth 이미지의 scale을 일정하게 조정하게 됩니다. 이를 통해 전체적인 scale보다는 예측한 depth 이미지의 shape을 예측하여 비교하는데 초점을 맞출 수 있게 된다고 합니다.
이러한 세팅으로 실험한 정량적 결과가 Table4이고 정성적 결과는 Figure 9를 나타냅니다. Table4를 먼저 보면 평가 픽셀의 예측된 depth 여부 (Y, N)와 상관없이 본 논문의 방법론이 다른 방법들보다 23~40% 가량 더 좋은 결과를 보이는 것을 확인할 수 있는데, 이러한 결과는 surface normal을 예측하는 것이 depth estimation에서도 긍적적인 접근임을 보여주고 있습니다. 정성적 결과를 보면 raw depth에서 단 한 개의 픽셀만이 주어졌을 때 조차도 Ours가 scene의 구조와 디테일적인 복원에 있어서 가장 잘 수행되고 있다는 것을 확인할 수 있습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
먼저 궁금한 점은 사용한 데이터셋은 논문에서 자체적으로 취득한 데이터셋만으로 실험을 진행한 것인지 궁금합니다. 두번째는 representation으로 surface normal과 occlusion boundary 두 가지를 논문에서 제안한 것 같은데 방법론의 모든 설명이 surface normal에 초점이 맞추어진 상태로 설명이 되고 있는 것 같아서 occlusion boundary의 메커니즘에 대한 설명은 논문에 포함되어 있지 않았나요 ?
또 rendering depth map을 구하는 과정에서 Figure 3의 빨간색 점에서는 멀리 떨어져 있지만 다른 뷰에서 적정 범위 내에 있기에 완성될 수 있는 depth map을 얻을 수 있다고 말씀해주셨는데 결국 rendering을 할 때는 그 자리에서의 카메라 pose를 사용한다고 이해를 했는데 어떻게 해당 뷰가 아니라 다른 뷰에서만 적정 범위 내에 있어도 예시처럼 깨끗한 depth map을 얻을 수 있는 것인지 추가적으로 설명해주시면 감사할 것 같습니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
먼저 사용한 데이터셋은 논문에서 취득한 데이터셋으로 실험을 진행한 것이 맞습니다. 그리고 두번째 질문은 논문에서도 언급했던 내용인데 모든 메커니즘을 surface normal에 초점을 맞추어 설명하되 occlusion boundary도 동일한 구조로 진행되었다고 언급하고 있습니다.
그리고 reconstruction을 통해서 한 scene에 대한 전체적인 구조와 pose를 얻었기 때문에 2D depth map으로 projection할 경우 위치는 하나의 고정적인 pose를 사용하지만 정보는 모든 view에서 얻어온 것이기 때문에 그러한 정보를 바탕으로 깨끗한 depth map을 얻을 수 있게 됩니다.
손건화 연구원님, 좋은 리뷰 감사합니다. 결국 기존 RGB-D depth completion을 개선하기 위해 누락된 값을 보충하는 데이터셋을 잘 구성해서(동일한 조건에서 촬영한 다른 데이터) 이를 이용해 보완했다고 이해했습니다. 결국 현금 박치기와 노가다가 답이군요 ..
본문에 대한 질문이 있는데, 해당 리뷰에는 ‘surface normal’이라는 표현이 자주 사용됩니다. 컬러 영상으로 더 쉽게 추정할 수 있는 로컬 특성이라는 설명이 있긴 하지만, 제가 해당 분야에 익숙하지 않다보니 직관적으로 이해하기 힘들었습니다. 혹시 surface normal이 무엇인지 추가적인 설명을 해 주실 수 있으실까요?
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
우선 Surface normal은 각 픽셀에 대한 벡터를 계산하게 되는데 물체 표면의 한 점에서 수직인 방향 벡터를 나타냅니다 . 평평한 평면에는 surface normal이 수직을 향하겠지만 곡면에서는 곡면의 방향을 따르게 될텐데요, 이때 조도 변화에 따라서 어떤 방향으로 나아갈지가 정해지기 때문에 조도 변화와 깊은 연관이 있다고 표현 합니다. 이를 왜 사용하는지를 생각해보면 depth에서 값이 누락되는 이유 중 하나가 빛이 포함되어 있을 때 depth 값에 대한 표현이 현저히 떨어지는데 이러한 빛의 변화에 따라 변화하는 정보를 컬러 영상에서 얻음으로써 completion을 위한 추가적인 정보로 넣어줄 수 있기 때문입니다.
안녕하세요 손건화 연구원님 좋은 리뷰 감사합니다.
[그림 2]의 model pipeline에서 궁금한 점이 있습니다. 제가 이해한 바로는 normal estimation과 boundary detection을 통해 각각 surface map과 occlusion boundary를 생성한 뒤 생성된 정보와 raw depth를 바탕으로 completion을 진행한다는 것입니다. 이때 전체 모델이 e2e로 학습된다면 모델의 input은 raw sensor depth와 rgb이미지이고, output은 dense한 depth map이 되는데 그렇다면 중간 단계인 normal estimator와 boundary detection 모델의 학습은 어떻게 이루어지는지 잘 이해되지 않는데 해당 부분을 설명해 주실 수 있을까요?
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
surface normal과 boundary occlusion을 예측을 위한 네트워크는 본문에서 언급하였듯이 검출에서 모두 우수한 성능을 보였던 이전 연구에서의 구조를 그대로 사용하였는데, 이는 VGG16을 백본으로 하는 FC 네트워크로 이루어져 있고 reconstruction한 mesh에서 계산된 GT surface normal과 silhouette 경계를 가지고 네트워크를 train하게 된다고 논문에서 간략하게 설명하고 있습니다.